من إعداد: ألكساندر فيريلين xscrew - مؤلف ، رئيس خدمة البنية التحتية للشبكة ، ليونيد Klyuyev - محرر
نستمر في
تعريفك بالهيكل الداخلي لـ
Yandex.Cloud . اليوم سوف نتحدث عن الشبكات - سنخبرك بكيفية عمل البنية التحتية للشبكة ، ولماذا تستخدم نموذج MPLS الذي لا يحظى بشعبية بالنسبة لمراكز البيانات ، وما هي القرارات المعقدة الأخرى التي اتخذناها في عملية بناء شبكة سحابية ، وكيفية إدارتها ونوع المراقبة التي نستخدمها.
تتكون الشبكة في السحابة من ثلاث طبقات. الطبقة السفلية هي البنية التحتية المذكورة بالفعل. هذه شبكة "حديدية" فعلية داخل مراكز البيانات ، وبين مراكز البيانات وفي أماكن الاتصال بالشبكات الخارجية. شبكة افتراضية مبنية على أعلى البنية التحتية للشبكة ، وخدمات شبكة مبنية على قمة الشبكة الافتراضية. هذه البنية ليست متجانسة: تتقاطع الطبقات ، وتتفاعل خدمات الشبكة والشبكة الافتراضية مباشرة مع البنية التحتية للشبكة. نظرًا لأن الشبكة الافتراضية غالبًا ما يطلق عليها تراكب ، فإننا ندعو عادةً إلى البنية التحتية للشبكة.

الآن تتمركز البنية التحتية السحابية في المنطقة الوسطى من روسيا وتتضمن ثلاث مناطق وصول - أي ثلاثة مراكز بيانات مستقلة موزعة جغرافياً. مستقل - مستقل عن الآخر في سياق الشبكات والأنظمة الهندسية والكهربائية ، إلخ.
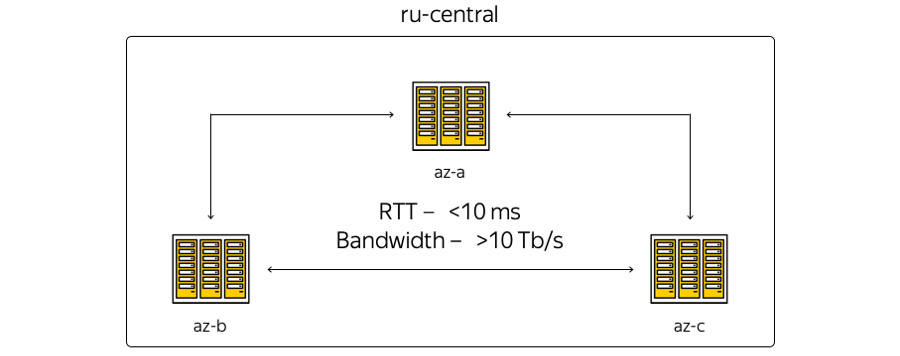
حول الخصائص. جغرافية موقع مراكز البيانات هي أن وقت الرحلة ذهابًا وإيابًا (RTT) لوقت الرحلة ذهابًا وإيابًا بينهما هو دائمًا 6-7 مللي ثانية. لقد تجاوزت السعة الإجمالية للقنوات بالفعل 10 تيرا بايت وتنمو باستمرار ، لأن Yandex لديها شبكة الألياف البصرية الخاصة بها بين المناطق. نظرًا لأننا لا نستأجر قنوات الاتصال ، يمكننا بسرعة زيادة قدرة الشريط بين البلدان النامية: يستخدم كل منها معدات الإرسال المتعدد الطيفية.
هنا هو التمثيل الأكثر تخطيطا للمناطق:
الواقع ، بدوره ، مختلف قليلاً:
إليكم شبكة العمود الفقري الحالية في ياندكس في المنطقة. تعمل جميع خدمات Yandex فوقها ، ويتم استخدام جزء من الشبكة بواسطة السحابة. (هذه صورة للاستخدام الداخلي ، وبالتالي ، يتم إخفاء معلومات الخدمة بشكل متعمد. ومع ذلك ، من الممكن تقدير عدد العقد والاتصال.) كان قرار استخدام الشبكة الأساسية منطقيًا: لم نتمكن من اختراع أي شيء ، ولكن إعادة استخدام البنية التحتية الحالية - "عانت" على مدار سنوات التطوير.
ما هو الفرق بين الصورة الأولى والثانية؟ بادئ ذي بدء ، لا ترتبط مناطق الوصول ارتباطًا مباشرًا: تقع المواقع التقنية بينها. لا تحتوي المواقع على أجهزة الخادم - يتم وضع أجهزة الشبكة فقط لضمان الاتصال بها. ترتبط نقاط التواجد التي يتصل بها Yandex and Cloud بالعالم الخارجي بمواقع تقنية. جميع نقاط التواجد تعمل في المنطقة بأكملها. بالمناسبة ، من المهم ملاحظة أنه من وجهة نظر الوصول الخارجي من الإنترنت ، فإن جميع مناطق الوصول إلى السحاب متساوية. وبعبارة أخرى ، فهي توفر نفس التوصيلية - أي نفس السرعة والإنتاجية ، وكذلك الكمون المنخفض على حد سواء.
بالإضافة إلى ذلك ، هناك معدات في نقاط التواجد ، والتي - إذا كانت هناك موارد محلية ورغبة في توسيع البنية التحتية المحلية مع تسهيلات سحابية - يمكن للعملاء الاتصال من خلال قناة مضمونة. يمكن القيام بذلك بمساعدة الشركاء أو وحدك.
يتم استخدام الشبكة الأساسية بواسطة السحابة كوسيلة لنقل MPLS.
MPLS
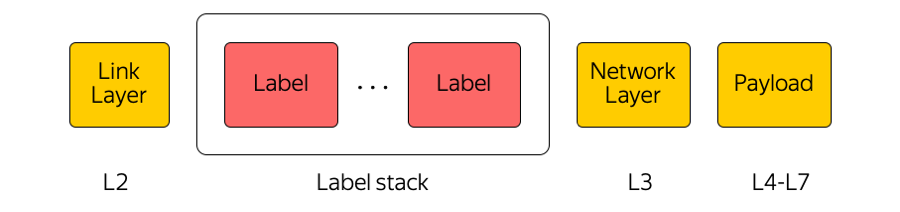
تبديل الملصقات المتعددة البروتوكولات عبارة عن تقنية تستخدم على نطاق واسع في صناعتنا. على سبيل المثال ، عندما يتم نقل الحزمة بين مناطق الوصول أو بين منطقة الوصول والإنترنت ، فإن معدات النقل لا تهتم إلا بالتسمية العليا ، "لا تفكر" حول ما تحتها. بهذه الطريقة ، تسمح لك MPLS بإخفاء تعقيد السحابة عن طبقة النقل. بشكل عام ، نحن في السحابة مغرمون جدًا بـ MPLS. لقد جعلناها جزءًا من المستوى الأدنى ونستخدمها مباشرةً في مصنع التبديل في مركز البيانات:

(في الواقع ، هناك الكثير من الارتباطات المتوازية بين مفاتيح أوراق الشجر والعمود الفقري.)
لماذا MPLS؟
صحيح أن MPLS لا توجد على الإطلاق في شبكات مراكز البيانات. في كثير من الأحيان تستخدم تقنيات مختلفة تماما.
نحن نستخدم MPLS لعدة أسباب. أولاً ، وجدنا أنه من المناسب توحيد تقنيات طائرة التحكم وطائرة البيانات. هذا هو ، بدلاً من بعض البروتوكولات في شبكة مركز البيانات والبروتوكولات الأخرى في الشبكة الأساسية وتقاطع هذه البروتوكولات - MPLS واحد. وبالتالي ، قمنا بتوحيد المكدس التكنولوجي وتقليل تعقيد الشبكة.
ثانياً ، في السحابة ، نستخدم العديد من أجهزة الشبكات ، مثل Cloud Gateway و Network Load Balancer. يحتاجون إلى التواصل مع بعضهم البعض ، وإرسال حركة المرور إلى الإنترنت والعكس بالعكس. يمكن تحجيم أجهزة الشبكة هذه أفقياً مع زيادة الحمل ، وبما أن السحابة مبنية وفقًا لنموذج التقارب الفائق ، يمكن إطلاقها في أي مكان تمامًا من وجهة نظر الشبكة في مركز البيانات ، أي في مجموعة موارد مشتركة.
وبالتالي ، يمكن أن تبدأ هذه الأجهزة خلف أي منفذ لمفتاح الحامل حيث يوجد الخادم ، وتبدأ في الاتصال عبر MPLS مع بقية البنية التحتية. المشكلة الوحيدة في بناء مثل هذه الهندسة المعمارية كانت ناقوس الخطر.
إنذار
مكدس بروتوكول MPLS الكلاسيكي معقد للغاية. هذا ، بالمناسبة ، هو أحد أسباب عدم انتشار MPLS في شبكات مراكز البيانات.
بدوره ، لم نستخدم IGP (بروتوكول البوابة الداخلية) أو LDP (بروتوكول توزيع الملصقات) أو بروتوكولات توزيع الملصقات الأخرى. يستخدم فقط BGP (بروتوكول بوابة الحدود) تسمية أحادية الإرسال. يقوم كل جهاز يعمل ، على سبيل المثال ، كجهاز افتراضي ، بإنشاء جلسة BGP قبل مفتاح Leaf المثبت على الحامل.
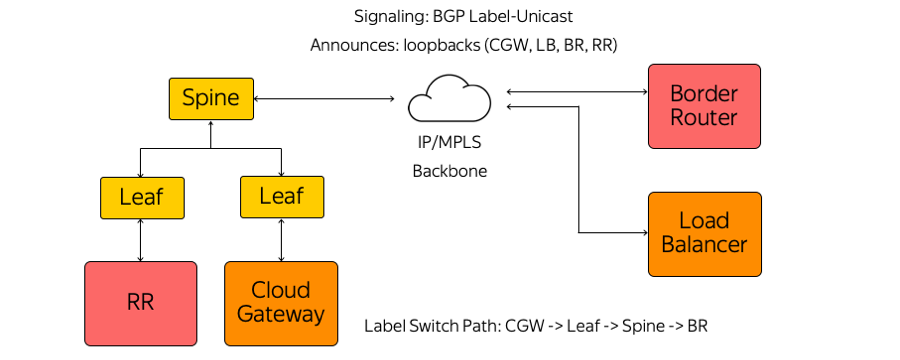
تم بناء جلسة BGP في عنوان معروف مسبقًا. ليست هناك حاجة لتكوين المفتاح تلقائيًا لتشغيل كل جهاز. جميع مفاتيح هي مسبقا ومتناسقة.
ضمن جلسة عمل BGP ، يرسل كل جهاز استرجاعًا خاصًا به ويتلقى استرجاعات لبقية الأجهزة التي سيحتاجها لتبادل الحركة. ومن أمثلة هذه الأجهزة عدة أنواع من عاكسات الطريق وأجهزة التوجيه الحدودية والأجهزة الأخرى. نتيجة لذلك ، تظهر معلومات حول كيفية الوصول إلى بعضها البعض على الأجهزة. من "بوابة السحاب" إلى مفتاح "ليف" ومفتاح "سبين" والشبكة إلى جهاز التوجيه الحدودي ، تم بناء مسار تبديل الملصق. المحولات هي مفاتيح L3 تتصرف مثل موجه تبديل التسمية ولا تعرف التعقيد المحيط بها.
لقد سمحت لنا MPLS على جميع مستويات شبكتنا ، من بين أشياء أخرى ، باستخدام مفهوم Eat Dogfood الخاص بك.
أكل dogfood الخاصة بك
من وجهة نظر الشبكة ، يعني هذا المفهوم أننا نعيش في نفس البنية التحتية التي نقدمها للمستخدم. فيما يلي مخططات للرفوف في مناطق إمكانية الوصول:

سحابة المضيف يأخذ الحمل من المستخدم ، يحتوي على أجهزته الافتراضية. وبشكل حرفي ، يمكن للمضيف المجاور في الحامل أن يحمل حمل البنية التحتية من وجهة نظر الشبكة ، بما في ذلك عاكسات المسار والإدارة وخوادم المراقبة وما إلى ذلك.
لماذا تم ذلك؟ كان هناك إغراء لتشغيل عاكسات المسار وجميع عناصر البنية التحتية في قطاع منفصل يتحمل الأخطاء. ثم ، إذا تعطل جزء المستخدم في مكان ما في مركز البيانات ، فستستمر خوادم البنية الأساسية في إدارة البنية الأساسية للشبكة بالكامل. ولكن يبدو أن هذا النهج شرير بالنسبة لنا - إذا لم نثق في بنيتنا الأساسية ، فكيف يمكننا أن نوفرها لعملائنا؟ بعد كل شيء ، تعمل كل الشبكات السحابية تمامًا ، وجميع الشبكات الافتراضية وخدمات المستخدم والسحابة فوقها.
لذلك ، تخلينا عن جزء منفصل. تعمل عناصر البنية التحتية الخاصة بنا في نفس هيكل الشبكة واتصال الشبكة. بطبيعة الحال ، يتم تشغيلهم في حالة ثلاثية - تمامًا مثل إطلاق عملائنا لخدماتهم في السحابة.
مصنع IP / MPLS
فيما يلي مثال تخطيطي لإحدى مناطق التوفر:
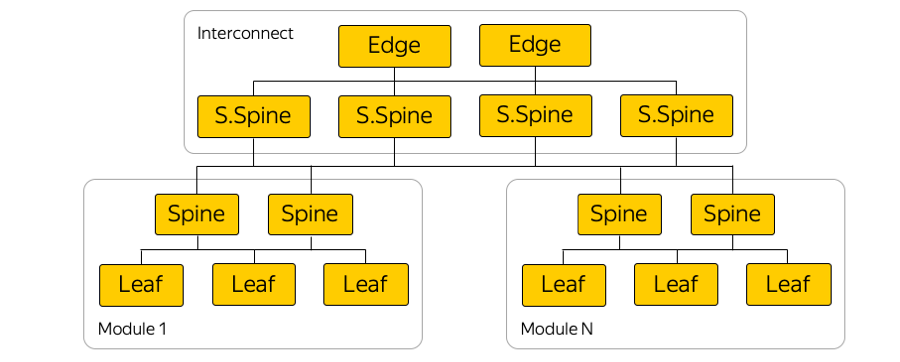
يوجد في كل منطقة توفر حوالي خمس وحدات ، وفي كل وحدة حوالي مائة رف. أوراق - مفاتيح مثبتة على حامل ، يتم توصيلها داخل الوحدة الخاصة بهم عن طريق مستوى العمود الفقري ، ويتم توفير اتصال بين الوحدات من خلال شبكة الاتصال. هذا هو المستوى التالي ، والذي يشتمل على ما يسمى بمفاتيح Super-Spines و Edge ، والتي تربط بالفعل مناطق الوصول. لقد تخلينا عمداً عن L2 ، نحن نتحدث فقط عن اتصال L3 IP / MPLS. يستخدم BGP لتوزيع معلومات التوجيه.
في الواقع ، هناك اتصالات موازية أكثر بكثير مما في الصورة. مثل هذا العدد الكبير من اتصالات ECMP (متعدد المسارات المتساوية التكلفة) يفرض متطلبات مراقبة خاصة. بالإضافة إلى ذلك ، هناك حدود غير متوقعة للوهلة الأولى في المعدات - على سبيل المثال ، عدد مجموعات ECMP.
اتصال الخادم
نظرًا للاستثمارات القوية ، تقوم Yandex بإنشاء الخدمات بطريقة لا تؤدي أبدًا إلى فشل خادم واحد أو حامل خادم أو وحدة نمطية أو حتى مركز بيانات كامل إلى توقف تام للخدمة. إذا واجهنا أي نوع من مشاكل الشبكة - لنفترض أن مفتاح الرف المثبت معطوب - فلن يرى المستخدمون الخارجيون ذلك مطلقًا.
Yandex.Cloud هي حالة خاصة. لا يمكننا إملاء العميل على كيفية بناء خدماته الخاصة ، وقررنا تسوية نقطة الفشل المحتملة هذه. لذلك ، يتم توصيل جميع الخوادم في السحابة بمفتاحين مثبتين على حامل.
كما أننا لا نستخدم أي بروتوكولات احتياطية على مستوى L2 ، لكننا بدأنا على الفور استخدام L3 فقط مع BGP - مرة أخرى ، لأسباب توحيد البروتوكول. يوفر هذا الاتصال لكل خدمة اتصال IPv4 و IPv6: تعمل بعض الخدمات على IPv4 ، وبعض الخدمات عبر IPv6.
فعليًا ، يتم توصيل كل خادم بواجهتين من 25 جيجابت. إليك صورة من مركز البيانات:

هنا ترى مفتاحين مثبتين على حامل مع منافذ سعة 100 جيجابت. تكون كابلات الاختراق مرئية ، حيث تقسم منفذ 100 جيجابت للمحول إلى 4 منافذ بحجم 25 جيجابت لكل خادم. نسمي هذه الكابلات "هيدرا".
إدارة البنية التحتية
لا تحتوي البنية الأساسية للشبكة السحابية على أي حلول لإدارة الملكية: كل الأنظمة إما مفتوحة المصدر مع تخصيص لـ Cloud أو مكتوبة ذاتيًا بالكامل.
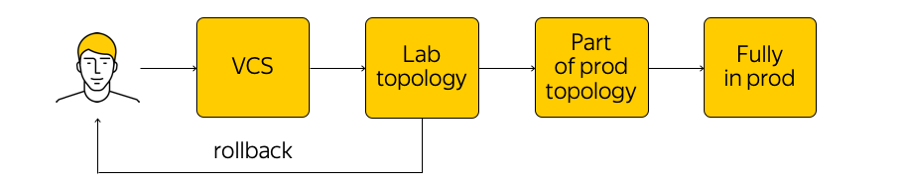
كيف تتم إدارة هذه البنية التحتية؟ هذا ليس محظورًا في السحابة ، لكن من المحبذ للغاية الذهاب إلى جهاز الشبكة وإجراء أي تعديلات. هناك الحالة الحالية للنظام ، ونحن بحاجة إلى تطبيق التغييرات: تعال إلى حالة جديدة مستهدفة. "قم بتشغيل برنامج نصي" عبر جميع الغدد ، وقم بتغيير شيء ما في التكوين - يجب ألا تقوم بذلك. بدلاً من ذلك ، نقوم بإجراء تغييرات على القوالب ، على مصدر واحد لنظام الحقيقة ، ونلزم تغييرنا على نظام التحكم في الإصدار. هذا أمر مريح للغاية ، لأنه يمكنك دائمًا القيام بالتراجع ، والنظر إلى السجل ، ومعرفة من المسؤول عن الالتزام ، إلخ.
عندما أجرينا التغييرات ، يتم إنشاء التكوينات ونطرحها في طوبولوجيا الاختبارات المعملية. من منظور الشبكة ، هذه سحابة صغيرة تعيد كل الإنتاج الحالي تمامًا. سنرى على الفور ما إذا كانت التغييرات المطلوبة تقطع شيئًا: أولاً ، من خلال المراقبة ، وثانياً ، من خلال ردود فعل المستخدمين الداخليين لدينا.
إذا كانت المراقبة تقول أن كل شيء هادئ ، فإننا سنستمر في الظهور - لكننا نطبق التغيير فقط على جزء من الهيكل (اثنان أو أكثر من إمكانية الوصول "ليس لهم الحق" في كسره لنفس السبب). بالإضافة إلى ذلك ، نواصل المراقبة عن كثب. هذه عملية معقدة إلى حد ما ، والتي سنتحدث عنها أدناه.
بعد التأكد من أن كل شيء على ما يرام ، نطبق التغيير على الإنتاج بأكمله. في أي وقت ، يمكنك التراجع والعودة إلى الحالة السابقة للشبكة ، وتعقب المشكلة وحلها بسرعة.
الرصد
نحن بحاجة إلى مراقبة مختلفة. أحد أكثر الأشياء المرغوبة هو مراقبة الاتصال من طرف إلى طرف. في أي وقت ، يجب أن يكون كل خادم قادراً على التواصل مع أي خادم آخر. والحقيقة هي أنه إذا كانت هناك مشكلة في مكان ما ، فنحن نريد معرفة أين بالضبط في أقرب وقت ممكن (أي الخوادم التي تواجه مشاكل في الوصول إلى بعضها البعض). إن ضمان الاتصال من طرف إلى طرف هو شاغلنا الأساسي.
يسرد كل خادم مجموعة من جميع الخوادم التي يجب أن تكون قادرة على التواصل في أي وقت معين. يأخذ الخادم مجموعة فرعية عشوائية من هذه المجموعة ويرسل حزم ICMP و TCP و UDP إلى جميع الأجهزة المحددة. يقوم هذا بالتحقق مما إذا كانت هناك خسائر على الشبكة ، وما إذا كان التأخير قد زاد ، وما إلى ذلك. "يتم استدعاء" الشبكة بالكامل داخل إحدى مناطق الوصول وفيما بينها. يتم إرسال النتائج إلى نظام مركزي يصورها لنا.
إليك ما تبدو عليه النتائج عندما لا يكون كل شيء جيدًا:
هنا يمكنك معرفة شرائح الشبكة التي توجد بها مشكلة (في هذه الحالة ، A و B) وحيث كل شيء على ما يرام (A و D). يمكن عرض خوادم محددة ، ومفاتيح مثبتة على حامل ، ووحدات ، ومناطق توفر كاملة هنا. إذا أصبح أي مما سبق مصدر المشكلة ، فسنراها في الوقت الفعلي.
بالإضافة إلى ذلك ، هناك مراقبة الحدث. نحن نراقب عن كثب جميع الاتصالات ، ومستويات الإشارة على أجهزة الإرسال والاستقبال ، وجلسات BGP ، وما إلى ذلك. لنفترض أن ثلاث جلسات BGP بنيت من قطاع الشبكة ، تمت مقاطعة واحدة منها في الليل. إذا قمنا بإعداد المراقبة بحيث يكون سقوط جلسة عمل واحدة لـ BGP أمرًا بالغ الأهمية بالنسبة لنا ويستطيع الانتظار حتى الصباح ، فلن تستيقظ المراقبة مهندسي الشبكات. ولكن إذا سقطت الثانية من الجلسات الثلاث ، يتصل المهندس تلقائيًا.
بالإضافة إلى مراقبة الأحداث من البداية إلى النهاية ، نستخدم مجموعة مركزية من السجلات وتحليلها في الوقت الفعلي والتحليلات اللاحقة. يمكنك رؤية الارتباطات وتحديد المشكلات ومعرفة ما كان يحدث على معدات الشبكة.
موضوع المراقبة كبير بما فيه الكفاية ، هناك مجال كبير للتحسينات. أريد أن أحضر النظام إلى أتمتة أكبر وشفاء حقيقي.
ما التالي؟
لدينا العديد من الخطط. من الضروري تحسين أنظمة التحكم والمراقبة والتبديل في مصانع IP / MPLS وغير ذلك الكثير.
ونحن نتطلع بنشاط نحو مفاتيح مربع أبيض. هذا جهاز "مكواة" جاهز ، وهو مفتاح يمكنك من خلاله تشغيل برنامجك. أولاً ، إذا تم تنفيذ كل شيء بشكل صحيح ، فسيكون من الممكن "معالجة" المحولات بنفس الطريقة التي تتم بها الخوادم ، وإنشاء عملية CI / CD مريحة حقًا ، وبدء تكوينات تدريجية ، إلخ.
ثانياً ، إذا كانت هناك أية مشكلات ، فمن الأفضل الاحتفاظ بمجموعة من المهندسين والمطورين الذين سيقومون بإصلاح هذه المشكلات بدلاً من الانتظار وقتًا طويلاً لإصلاح من البائع.
من أجل أن ينجح كل شيء ، يجري العمل في اتجاهين:
- قللنا بدرجة كبيرة من تعقيد مصنع IP / MPLS. من ناحية ، أصبح مستوى الشبكة الافتراضية وأدوات التشغيل الآلي من هذا ، على العكس من ذلك ، أكثر تعقيدًا بعض الشيء. من ناحية أخرى ، أصبحت الشبكة التحتية نفسها أسهل. بمعنى آخر ، هناك "قدر" معين من التعقيد لا يمكن حفظه. يمكن "طرحه" من مستوى إلى آخر - على سبيل المثال ، بين مستويات الشبكة أو من مستوى الشبكة إلى مستوى التطبيق. ويمكنك توزيع هذا التعقيد بشكل صحيح ، والذي نحاول القيام به.
- وبالطبع ، نحن بصدد الانتهاء من مجموعة أدواتنا لإدارة البنية التحتية بأكملها.
هذا هو كل ما أردنا التحدث عن البنية التحتية لشبكتنا.
إليك رابط لقناة Cloud Telegram مع الأخبار والنصائح.