هذا المقال كتب بالاشتراك مع ananaskelly .
مقدمة
مرحباً بالجميع يا هبر! من خلال العمل في مركز تقنية الكلام في سانت بطرسبرغ ، اكتسبنا خبرة قليلة في حل مشكلات تصنيف الأحداث الصوتية واكتشافها وقررنا أننا على استعداد لمشاركتها معك. الغرض من هذه المقالة هو تعريفك ببعض المهام والتحدث عن مسابقة معالجة الصوت التلقائية DCASE 2018 . لإخبارك بالمسابقة ، سنفعل دون الصيغ والتعاريف المعقدة المتعلقة بالتعلم الآلي ، وبالتالي سيتم فهم المعنى العام للمقال من قبل جمهور واسع .
بالنسبة لأولئك الذين انجذبوا إلى مجموعة المصنف ، قمنا بإعداد رمز python صغير ، ومن خلال الرابط على github يمكنك العثور على جهاز كمبيوتر محمول حيث ، باستخدام المسار الثاني لمسابقة DCASE كمثال ، نقوم بإنشاء شبكة تلافيفية بسيطة على keras لتصنيف الملفات الصوتية. هناك نتحدث قليلاً عن الشبكة والميزات المستخدمة للتدريب ، وكيفية استخدام بنية بسيطة للحصول على نتيجة قريبة من الأساس ( MAP @ 3 = 0.6).
بالإضافة إلى ذلك ، سيتم شرح الطرق الأساسية لحل المشكلات (خط الأساس) التي اقترحها المنظمون هنا. أيضًا في المستقبل ، سيكون هناك العديد من المقالات التي سنتحدث فيها بمزيد من التفصيل وبالتفصيل عن تجربتنا في المشاركة في المسابقة وحول الحلول المقترحة من قبل المشاركين الآخرين في المسابقة. روابط لهذه المواد سوف تظهر تدريجيا هنا.
بالتأكيد ، كثير من الناس ليس لديهم أي فكرة على الإطلاق عن نوع من "DCASE" ، لذلك دعونا نتعرف على نوع الفاكهة التي يتم تناولها وما يتم تناولها به. تُعقد مسابقة " DCASE " سنويًا ، وتُخصص كل عام العديد من المهام لحل المشكلات في مجال تصنيف التسجيلات الصوتية واكتشاف الأحداث الصوتية. يمكن لأي شخص المشاركة في المسابقة ، فهو مجاني ، ولهذا يكفي التسجيل ببساطة على الموقع كمشارك. كنتيجة للمنافسة ، يتم عقد مؤتمر حول نفس الموضوعات ، ولكن على عكس المنافسة نفسها ، فإن المشاركة فيها مدفوعة بالفعل ، ولن نتحدث عنها بعد الآن. لا يتم الاعتماد على المكافآت للحصول على أفضل القرارات ، ولكن هناك استثناءات (على سبيل المثال ، المهمة الثالثة في 2018). اقترح المنظمون هذا العام المهام الخمس التالية:
- تصنيف المشاهد الصوتية (مقسمة إلى 3 مهام فرعية)
أ. مجموعات بيانات التدريب والاختبار المسجلة على نفس الجهاز
B. التدريب ومجموعات اختبار البيانات المسجلة على أجهزة مختلفة
ج- التدريب مسموح باستخدام البيانات التي لا يقدمها المنظمون - تصنيف الأحداث الصوتية
- كشف الغناء الطيور
- الكشف عن الأحداث الصوتية في المنزل باستخدام مجموعة بيانات ضعيفة التسمية
- تصنيف النشاط المنزلي في الغرفة وفقًا للتسجيل متعدد القنوات
حول الكشف والتصنيف
كما نرى ، فإن أسماء جميع المهام تحتوي على واحدة من كلمتين: "الاكتشاف" أو "التصنيف". دعنا نوضح ما هو الفرق بين هذه المفاهيم بحيث لا يوجد التباس.
تخيل أن لدينا تسجيل صوتي ينبح عليه كلب في لحظة ما ، وقطة تلو الأخرى في مكان آخر ، وببساطة لا توجد أحداث أخرى هناك. ثم إذا أردنا أن نفهم بالضبط متى تحدث هذه الأحداث ، فإننا نحتاج إلى حل مشكلة اكتشاف حدث صوتي. هذا هو ، نحن بحاجة إلى معرفة أوقات البداية والنهاية لكل حدث. بعد حل مشكلة الاكتشاف ، سنعرف بالضبط وقت حدوث الأحداث ، لكننا لا نعرف من يتم تحديد الأصوات التي تم العثور عليها بالضبط - ثم نحتاج إلى حل مشكلة التصنيف ، أي تحديد ما حدث بالضبط في الفترة الزمنية المحددة.
لفهم وصف مهام المسابقة ، ستكون هذه الأمثلة كافية ، مما يعني أن الجزء التمهيدي قد اكتمل ، ويمكننا الانتقال إلى وصف تفصيلي للمهام ذاتها.
المسار 1. تصنيف المشاهد الصوتية
تتمثل المهمة الأولى في تحديد البيئة (المشهد الصوتي) التي تم تسجيل الصوت بها ، على سبيل المثال ، "محطة المترو" أو "المطار" أو "شارع المشاة". يمكن أن يكون حل هذه المشكلة مفيدًا في تقييم البيئة باستخدام نظام الذكاء الاصطناعي ، على سبيل المثال ، في السيارات ذات الطيار الآلي.
في هذه المهمة ، تم تقديم TUT Urban Acoustic Scenes 2018 و TUT Urban Acoustic Scenes 2018 مجموعات البيانات المتنقلة ، التي أعدتها جامعة تامبيري للتكنولوجيا (فنلندا) ، للتدريب. ويرد وصف مفصل لإعداد مجموعة البيانات ، وكذلك الحل الأساسي ، في المقالة .
في المجموع ، تم تقديم 10 مشاهد صوتية للمسابقة ، والتي كان على المشاركين التنبؤ بها.
المهمة الفرعية أ
كما قلنا سابقًا ، تنقسم المهمة إلى 3 مهام فرعية ، يختلف كل منها في جودة التسجيلات الصوتية. على سبيل المثال ، في القسم الفرعي أ ، تم استخدام الميكروفونات الخاصة للتسجيل ، والتي كانت موجودة في الأذنين البشرية. وهكذا ، تم تسجيل ستيريو أقرب إلى تصور الإنسان للصوت. أتيحت للمشاركين الفرصة لاستخدام هذا النهج للتسجيل من أجل تحسين جودة التعرف على المشهد الصوتي.
المهمة الفرعية ب
في المهمة الفرعية B ، تم استخدام أجهزة أخرى (على سبيل المثال ، الهواتف المحمولة) للتسجيل. تم تحويل البيانات من المهمة الفرعية A إلى تنسيق أحادي ، وتم تقليل تردد أخذ العينات ، ولا يوجد محاكاة لـ "مسموعة" الصوت من قبل شخص ما في مجموعة البيانات لهذه المهمة ، ولكن هناك المزيد من البيانات للتدريب.
المهمة الفرعية C
مجموعة البيانات للمهمة الفرعية C هي نفسها الموجودة في المهمة الفرعية A ، ولكن في حل هذه المشكلة ، يُسمح باستخدام أي بيانات خارجية يمكن للمشارك العثور عليها. الهدف من حل هذه المشكلة هو معرفة ما إذا كان من الممكن تحسين النتيجة التي تم الحصول عليها في المهمة الفرعية A باستخدام بيانات جهة خارجية.
تم تقييم جودة القرارات على هذا المسار من خلال مقياس الدقة .
خط الأساس لهذه المهمة هو شبكة عصبية تلافيفية من طبقتين تتعلم من لوغاريتمات برامج طيفية صغيرة من البيانات الصوتية الأصلية. يستخدم الهيكل المقترح تقنيات BatchNormalization و Dropout القياسية. يمكن رؤية الكود على جيثب هنا .
المسار 2. تصنيف الأحداث الصوتية
في هذه المهمة ، يُقترح إنشاء نظام يصنف الأحداث الصوتية. يمكن أن يكون هذا النظام إضافة إلى المنازل الذكية ، أو زيادة الأمن في الأماكن المزدحمة ، أو تسهيل الحياة للأشخاص الذين يعانون من ضعف السمع.
تتكون مجموعة البيانات لهذه المهمة من ملفات مأخوذة من مجموعة بيانات Freesound والموسومة باستخدام علامات من مجموعة AudioSet من Google. بمزيد من التفصيل ، يتم وصف عملية إعداد مجموعة البيانات بمقال أعده منظمو المسابقة.
دعنا نعود إلى المهمة نفسها ، التي لديها العديد من الميزات.
أولاً ، كان على المشاركين إنشاء نموذج قادر على تحديد الاختلافات بين الأحداث الصوتية ذات الطبيعة المختلفة جدًا. تنقسم مجموعة البيانات إلى فئة 41 ، فهي تقدم مختلف الآلات الموسيقية والأصوات التي أدلى بها البشر والحيوانات والأصوات المحلية وأكثر من ذلك.
ثانياً ، بالإضافة إلى العلامات المعتادة للبيانات ، هناك أيضًا معلومات إضافية حول التحقق من الملصق يدويًا. أي أن المشاركين يعرفون أي ملفات من مجموعة البيانات تم فحصها بواسطة الشخص للتأكد من توافقها مع التسمية ، وأيها لم يتم التحقق منها. كما أظهرت الممارسة ، حصل المشاركون الذين استخدموا هذه المعلومات الإضافية بطريقة ما على جوائز في حل هذه المشكلة.
بالإضافة إلى ذلك ، يجب القول أن مدة السجلات في مجموعة البيانات تختلف اختلافًا كبيرًا: من 0.3 ثانية إلى 30 ثانية. في هذه المشكلة ، يختلف أيضًا حجم البيانات لكل فصل ، والتي يحتاج النموذج إلى تدريب عليها. من الأفضل أن يصور هذا رسمًا بيانيًا ، وهو رمز البناء المأخوذ من هنا .
كما ترون من الرسم البياني ، فإن الترميز اليدوي للفصول المقدمة غير متوازن أيضًا ، مما يضيف صعوبة إذا كنت تريد استخدام هذه المعلومات عند نماذج التدريب.
تم تقييم النتائج في هذا المسار باستخدام مقياس الدقة المتوسط (Mean Mean Precision، MAP @ 3) ، ويمكن العثور على عرض بسيط إلى حد ما لحساب هذا المقياس بالأمثلة والرمز هنا .
المسار 3. الكشف عن الغناء الطيور
المسار التالي هو الكشف عن birdong. تنشأ مشكلة مماثلة ، على سبيل المثال ، في أنظمة مختلفة من الرصد التلقائي للحياة البرية - هذه هي الخطوة الأولى في معالجة البيانات قبل ، على سبيل المثال ، التصنيف. غالبًا ما تحتاج هذه الأنظمة إلى ضبط ، وهي غير مستقرة في الظروف الصوتية الجديدة ، وبالتالي فإن الهدف من هذا المسار هو استدعاء قوة التعلم الآلي في حل هذه المشكلات.
هذا المسار هو نسخة موسعة من مسابقة "Bird Audio Detection challenge" التي نظمتها جامعة سانت ماري في لندن في 2017/2018. للمهتمين ، يمكنك قراءة المقال من مؤلفي المسابقة ، والذي يوفر تفاصيل حول تكوين البيانات ، وتنظيم المسابقة نفسها وتحليل القرارات المتخذة.
ومع ذلك ، العودة إلى مهمة DCASE. قدم المنظمون ست مجموعات بيانات - ثلاث للتدريب ، وثلاثة للاختبار - كلها مختلفة تمامًا - تم تسجيلها في ظروف صوتية مختلفة ، باستخدام أجهزة تسجيل متنوعة ، على خلفية هناك ضوضاء مختلفة. وبالتالي ، فإن الرسالة الرئيسية هي أن النموذج لا ينبغي أن يعتمد على البيئة أو أن يكون قادرًا على التكيف معها. على الرغم من حقيقة أن الاسم يعني "الاكتشاف" ، فإن المهمة ليست تحديد حدود الحدث ، ولكن في تصنيف بسيط - الحل النهائي هو نوع من المصنف الثنائي الذي يتلقى إدخال صوتي قصير ويقرر ما إذا كان هناك طائر يغني عليه أم لا. . تم استخدام متري AUC لتقييم الدقة.
في الغالب ، حاول المشاركون تحقيق التعميم والتكيف من خلال زيادة البيانات المختلفة. يصف أحد الأوامر تطبيق التقنيات المختلفة - تغيير دقة التردد في الميزات المستخرجة ، والتقليل الأولي للضوضاء ، وطريقة التكيف القائمة على محاذاة إحصاءات الترتيب الثاني لمجموعات البيانات المختلفة. ومع ذلك ، فإن هذه الأساليب ، وكذلك الأنواع المختلفة من التعزيز ، تعطي زيادة بسيطة للغاية عن الحل الأساسي ، كما يلاحظ العديد من المشاركين.
كحل أساسي ، أعد المؤلفون تعديلًا للحل الأكثر نجاحًا من مسابقة "Bird Audio Detection Challenge" الأصلية. الرمز ، كالعادة ، متاح على جيثب .
المسار 4. الكشف عن الأحداث الصوتية في المنزل باستخدام مجموعة بيانات ضعيفة التسمية.
في المسار الرابع ، تم بالفعل حل مشكلة الكشف مباشرةً. تم تزويد المشاركين بمجموعة بيانات صغيرة نسبيًا من البيانات الموسومة - ما مجموعه 1578 تسجيلًا صوتيًا لكل 10 ثوانٍ ، مع تمييز فئة فقط: من المعروف أن الملف يحتوي على حدث واحد أو أكثر من هذه الفئات ، ولكن لا يوجد ترميز مؤقت. بالإضافة إلى ذلك ، تم توفير مجموعتين كبيرتين من البيانات غير المخصصة - 14412 ملفًا تحتوي على أحداث مستهدفة من نفس الفئات كما في عينات التدريب والاختبار ، بالإضافة إلى 39999 ملفًا يحتوي على أحداث تعسفية لم يتم تضمينها في الأهداف. جميع البيانات هي مجموعة فرعية من مجموعة البيانات السمعية الضخمة التي جمعتها جوجل .
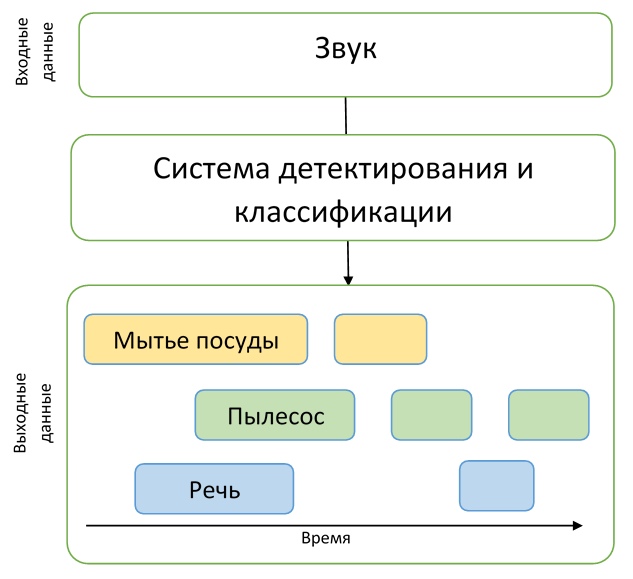
وبالتالي ، يحتاج المشاركون إلى إنشاء نموذج قادر على التعلم من البيانات ذات العلامات الضعيفة للعثور على طوابع زمنية لبداية ونهاية الأحداث (قد تتقاطع الأحداث) ، ومحاولة تحسينها باستخدام كمية كبيرة من البيانات الإضافية غير المميزة. بالإضافة إلى ذلك ، تجدر الإشارة إلى أنه تم استخدام مقياس صارم إلى حد ما في هذا المسار - كان من الضروري التنبؤ بالتسميات الزمنية للأحداث بدقة 200 مللي ثانية. بشكل عام ، كان على المشاركين حل مهمة صعبة إلى حد ما تتمثل في إنشاء نموذج مناسب ، مع عدم وجود بيانات جيدة للتدريب عملياً.
استندت معظم الحلول إلى شبكات التكرار التلافيفي - وهي بنية شائعة إلى حد ما في مجال اكتشاف الأحداث الصوتية مؤخرًا (يمكن قراءة مثال هنا ).
يستند الحل الأساسي من المؤلفين ، أيضًا على الشبكات العودية التلافيفية ، إلى نموذجين. النماذج لها نفس البنية تقريبًا: ثلاثة طبقة تلافيفية وواحدة تكرارية. الفرق الوحيد هو شبكات الإخراج. تم تدريب النموذج الأول على ترميز البيانات غير المخصصة لتوسيع مجموعة البيانات الأصلية - وبالتالي ، في المخرجات ، لدينا فصول موجودة في ملف الحدث. والثاني هو لحل مشكلة الاكتشاف مباشرة ، أي عند الإخراج نحصل على علامات مؤقتة للملف. رمز الرابط .
المسار 5. تصنيف النشاط المنزلي في الغرفة وفقًا للتسجيل متعدد القنوات.
اختلف المسار الأخير عن المقاطع الأخرى بشكل أساسي حيث عرض على المشاركين تسجيلات متعددة القنوات. كانت المهمة نفسها في التصنيف: من الضروري التنبؤ بفئة الأحداث التي وقعت في السجل. على عكس المسار السابق ، فإن المهمة أبسط إلى حد ما - من المعروف أن هناك حدثًا واحدًا فقط في السجل.
يتم تمثيل مجموعة البيانات بحوالي 200 ساعة من التسجيلات على مجموعة ميكروفون خطي مكونة من 4 ميكروفونات. الأحداث هي جميع أنواع الأنشطة اليومية - الطهي وغسل الصحون والنشاط الاجتماعي (التحدث على الهاتف والزيارة والمحادثة الشخصية) ، وما إلى ذلك ، كما يتم تسليط الضوء على فئة غياب أي أحداث.
يؤكد مؤلفو المسار على أن شروط المهمة بسيطة نسبيًا بحيث يركز المشاركون مباشرةً على استخدام المعلومات المكانية من التسجيلات متعددة القنوات. كما أتيحت للمشاركين الفرصة لاستخدام بيانات إضافية ونماذج مدربة مسبقًا. تم تقييم الجودة وفقا لقياس F1.
كحل أساسي ، اقترح مؤلفو المسار شبكة تلافيفية بسيطة مع طبقتين تلافيفي. في حلها ، لم يتم استخدام المعلومات المكانية - تم استخدام البيانات من أربعة ميكروفونات للتدريب بشكل مستقل ، وكان متوسط التوقعات خلال الاختبار. الوصف والرمز متاحان في الرابط .
الخاتمة
في المقال ، حاولنا التحدث بإيجاز عن اكتشاف الأحداث الصوتية وعن مسابقة مثل DCASE. ربما كانوا قادرين على الاهتمام بشخص ما للمشاركة في عام 2019 - تبدأ المسابقة في مارس.