عندما أفكر في كيفية عمل عملاء RPC الساذجين ، أتذكر مزحة:
المحكمة.
"المتهم ، لماذا قتلت امرأة؟"
- أنا في الحافلة ، الموصل يقترب من المرأة ، مطالبًا بشراء تذكرة. المرأة فتحت حقيبتها ، أخرجت حقيبتها ، أغلقت حقيبتها ، فتحت حقيبتها ، أغلقت حقيبتها ، فتحت حقيبتها ، وضعت حقيبتها هناك ، أغلقت حقيبتها ، فتحت حقيبتها ، أخذت مالتها ، فتحت حقيبتها ، فتحت حقيبتها ، فتحت حقيبتها ، أغلقت محفظتها ، فتحت محفظتها ، وضعت محفظتها هناك.
- وماذا؟
- أعطاها المراقب المالي تذكرة. امرأة فتحت حقيبتها ، أخرجت حقيبتها ، أغلقت حقيبتها ، فتحت حقيبتها ، أغلقت حقيبتها ، فتحت حقيبتها ، وضعت حقيبتها هناك ، أغلقت حقيبتها ، فتحت حقيبتها ، وضعت تذكرتها هناك ، أغلقت حقيبتها ، فتحت حقيبتها ، فتحت حقيبتها ، فتحت حقيبتها ، ضع المحفظه هناك ، أغلق المحفظه ، فتح المحفظه ، وضع المحفظه فيه ، أغلق المحفظه.
"خذ التغيير" ، جاء صوت وحدة التحكم. المرأة ... فتحت حقيبتها ...
"نعم ، لا يكفي قتلها" المدعي العام لا يقف.
"لقد فعلت ذلك."
© S. Altov

يحدث نفس الشيء تقريبًا في عملية الاستجابة للطلب ، إذا ما اقتربت من ذلك بطريقة تافهة:
- تكتب عملية المستخدم طلبًا مسلسلاً إلى المقبس ، وتقوم بنسخه فعليًا إلى المخزن المؤقت للمقبس على مستوى نظام التشغيل ؛
هذه عملية صعبة إلى حد ما ، لأن من الضروري إجراء تبديل للسياق (حتى لو كان "سهلًا") ؛ - عندما يبدو لنظام التشغيل أنه يمكن كتابة شيء ما على الشبكة ، يتم تكوين حزمة (يتم نسخ الطلب مرة أخرى) وإرسالها إلى بطاقة الشبكة ؛
- بطاقة الشبكة يكتب الحزمة إلى الشبكة (ربما بعد التخزين المؤقت) ؛
- (على طول الطريق ، يمكن تخزين حزمة عدة مرات في أجهزة التوجيه) ؛
- أخيرًا ، تصل الحزمة إلى المضيف الوجهة ويتم تخزينها مؤقتًا على بطاقة الشبكة ؛
- ترسل بطاقة الشبكة إخطارًا إلى نظام التشغيل ، وعندما يجد نظام التشغيل الوقت ، تقوم بنسخ الحزمة إلى المخزن المؤقت الخاص بها وتعيين إشارة جاهزة على واصف الملف ؛
- (لا يزال يتعين عليك تذكر إرسال ACK ردًا) ؛
- بعد مرور بعض الوقت ، يدرك تطبيق الخادم أن الواصف جاهز (باستخدام epoll) ، وينسخ الطلب في يوم ما في المخزن المؤقت للتطبيق ؛
- وأخيرًا ، يعالج تطبيق الخادم الطلب.
كما تعلم ، يتم إرسال الاستجابة بنفس الطريقة تمامًا فقط في الاتجاه المعاكس. وبالتالي ، يقضي كل طلب وقتًا ملحوظًا على نظام التشغيل لصيانته ، ويقضي كل استجابة نفس الوقت مرة أخرى.
أصبح هذا ملحوظًا بشكل خاص بعد Meltdown / Specter ، نظرًا لأن التصحيحات التي تم إصدارها أدت إلى زيادة كبيرة في تكلفة مكالمات النظام. في أوائل كانون الثاني (يناير) 2018 ، بدأت مجموعة Redis لدينا فجأة في استهلاك وحدة المعالجة المركزية مرة واحدة ونصف إلى مرتين ، لأن طبقت أمازون تصحيحات kernel المناسبة لتغطية هذه الثغرات الأمنية. (صحيح ، طبقت أمازون إصدارًا جديدًا من التصحيح بعد ذلك بقليل ، وانخفض استهلاك وحدة المعالجة المركزية إلى المستويات السابقة تقريبًا. ولكن الموصل بدأ بالفعل في التولد.)
لسوء الحظ ، تعمل جميع موصلات Go المعروفة إلى Redis و Memcached تمامًا مثل هذا: الموصل ينشئ تجمع اتصال ، وعندما يحتاج إلى إرسال طلب ، فإنه يستخرج اتصالًا من التجمع ، ويكتب طلبًا واحدًا ثم ينتظر استجابة. (من المحزن بشكل خاص أن الرابط لـ Memcached كتبه براد فيتزباتريك نفسه.) وبعض الموصلات لديها مثل هذا التنفيذ غير الناجح لهذا التجمع بحيث تصبح عملية إزالة الاتصال من البوتات عبارة عن روبوتات في حد ذاتها.
هناك طريقتان لتخفيف هذا العمل الشاق الخاص بإعادة توجيه الطلب / الاستجابة:
- استخدم الوصول المباشر إلى بطاقة الشبكة: DPDK ، netmap ، PF_RING ، إلخ.
- لا ترسل كل طلب / استجابة كحزمة منفصلة ، ولكن قم بدمجها ، إن أمكن ، في حزم أكبر ، أي نشر النفقات العامة للعمل مع الشبكة لعدة طلبات. معا أكثر متعة!
الخيار الأول ، بالطبع ، ممكن. ولكن ، أولاً ، هذا خاص بالشجاعة ، حيث يتعين عليك كتابة تطبيق TCP / IP بنفسك (على سبيل المثال ، كما هو الحال في ScyllaDB). وثانياً ، بهذه الطريقة نسهل الموقف فقط على جانب واحد - على الجانب الذي نكتبه لأنفسنا. لا أريد إعادة كتابة Redis (حتى الآن) ، لذلك ستستهلك الخوادم نفس المبلغ ، حتى لو كان العميل يستخدم DPDK الرائع.
الخيار الثاني أبسط بكثير ، والأهم من ذلك ، يسهل الموقف على العميل والخادم على الفور. على سبيل المثال ، تفتخر قاعدة بيانات واحدة في الذاكرة أنها يمكن أن تخدم ملايين RPS ، في حين أن Redis لا يمكنها خدمة بضع مئات من الآلاف . ومع ذلك ، فإن هذا النجاح ليس هو تطبيق القاعدة الموجودة في الذاكرة بقدر ما هو القرار الذي تم قبوله من قبل بأن البروتوكول سيكون غير متزامن تمامًا ، ويجب على العملاء استخدام هذا التزامن كلما كان ذلك ممكنًا. ما الذي ينفذه العديد من العملاء (خاصةً تلك المستخدمة في المعايير) بنجاح عن طريق إرسال الطلبات عبر اتصال TCP واحد ، وإذا أمكن ، إرسالهم إلى الشبكة معًا.
توضح مقالة معروفة أن Redis يمكنه أيضًا تقديم مليون رد في الثانية في حالة استخدام خطوط الأنابيب. تشير الخبرة الشخصية في تطوير قصص الذاكرة أيضًا إلى أن توصيل الأنابيب يقلل بشكل كبير من استهلاك وحدة المعالجة المركزية SYS ويسمح لك باستخدام المعالج والشبكة بشكل أكثر كفاءة.
والسؤال الوحيد هو كيفية استخدام خطوط الأنابيب ، إذا كانت طلبات التطبيق في Redis تأتي غالبًا في وقت واحد؟ وإذا كان هناك خادم واحد مفقودًا ويستخدم Redis Cluster مع عدد كبير من القطع ، فإنه حتى عند مواجهة حزمة من الطلبات ، يتم تقسيمها إلى طلبات فردية لكل قشرة.
الجواب ، بالطبع ، "واضح": قم بجمع الأنابيب الضمني من خلال جمع الطلبات من جميع goroutines التي تعمل بالتوازي مع خادم Redis واحد وإرسالها عبر اتصال واحد.
بالمناسبة ، وضع الأنابيب الضمنية ليس نادرًا جدًا في الموصلات بلغات أخرى: nodejs node_redis و C # RedisBoost و python aioredis وغيرها الكثير. تتم كتابة العديد من هذه الموصلات أعلى حلقات الأحداث ، وبالتالي يبدو أن تجميع الطلبات من "تدفقات الحساب" المتوازية أمر طبيعي. في Go ، يتم الترويج لاستخدام واجهات متزامنة ، وعلى ما يبدو ، لأن قلة من الناس يقررون تنظيم "حلقة" خاصة بهم.
أردنا استخدام Redis بأكبر قدر ممكن من الكفاءة ، وبالتالي قررنا كتابة موصل "أفضل" (tm) جديد: RedisPipe .
كيفية جعل الأنابيب الضمنية؟
المخطط الأساسي:
- لا يقوم Goroutines بمنطق التطبيق بكتابة الطلبات مباشرة إلى الشبكة ، ولكن يتم تمريرها إلى جامع goroutine ؛
- إذا أمكن ، يجمع المجمع مجموعة من الطلبات ويكتبها على الشبكة ويمررها إلى قارئ goroutine ؛
- يقوم قارئ Goroutine بقراءة الردود الواردة من الشبكة ومقارنتها بالطلبات المقابلة وإخطار goroutines بالمنطق حول الإجابة التي وصلت.
هناك حاجة إلى إخطار حول الاستجابة. سيقول مبرمج Go الماكرة بالتأكيد: "من خلال القناة!"
ولكن هذا ليس هو التزامن الممكن الوحيد البدائي وليس الأكثر كفاءة حتى في بيئة التشغيل. ونظرًا لأن الأشخاص المختلفين لديهم احتياجات مختلفة ، فسوف نجعل الآلية قابلة للتوسعة ، مما يسمح للمستخدم بتنفيذ الواجهة (دعنا نسميها Future ):
type Future interface { Resolve(val interface{}) }
وبعد ذلك سيبدو المخطط الأساسي كما يلي:
type future struct { req Request fut Future } type Conn struct { c net.Conn futmtx sync.Mutex wfutures []future futtimer *time.Timer rfutures chan []future } func (c *Conn) Send(r Request, f Future) { c.futmtx.Lock() defer c.futmtx.Unlock() c.wfutures = append(c.wfutures, future{req: r, fut: f}) if len(c.wfutures) == 1 { futtimer.Reset(100*time.Microsecond) } } func (c *Conn) writer() { for range c.futtimer.C { c.futmtx.Lock() futures, c.wfutures = c.wfutures, nil c.futmtx.Unlock() var b []byte for _, ft := range futures { b = AppendRequest(b, ft.req) } _, _err := ccWrite(b) c.rfutures <- futures } } func (c *Conn) reader() { rd := bufio.NewReader(cc) var futures []future for { response, _err := ParseResponse(rd) if len(futures) == 0 { futures = <- c.rfutures } futures[0].fut.Resolve(response) futures = futures[1:] } }
بالطبع ، هذا رمز مبسط للغاية. تم الحذف:
- إنشاء اتصال ؛
- أنا / س مهلات
- قراءة / كتابة معالجة الأخطاء ؛
- إعادة تأسيس الاتصال ؛
- القدرة على إلغاء الطلب قبل إرساله إلى الشبكة ؛
- تحسين تخصيص الذاكرة (إعادة استخدام صفيف المخزن المؤقت والعقود المستقبلية).
أي خطأ إدخال / إخراج (بما في ذلك مهلة) في الكود الحقيقي يؤدي إلى حل جميع الأخطاء المستقبلية المطابقة للطلبات المرسلة والانتظار لإرسالها.
طبقة الاتصال غير متورطة في إعادة محاولة الطلب ، وإذا كان ذلك ضروريًا (وممكن) لإعادة محاولة الطلب ، فيمكن القيام بذلك بمستوى أعلى من التجريد (على سبيل المثال ، في تنفيذ دعم Redis Cluster الموضح أدناه).
ملاحظة. في البداية ، بدت الدائرة أكثر تعقيدًا قليلاً. ولكن في عملية التجارب المبسطة لهذا الخيار.
ملاحظة 2. يتم فرض متطلبات صارمة للغاية على طريقة Future.Resolve: يجب أن تكون في أسرع وقت ممكن ، من الناحية العملية غير محظورة وفي أي حال من الأحوال الذعر. هذا يرجع إلى حقيقة أنه يتم استدعاء متزامن في دورة القارئ ، وأي "الفرامل" سيؤدي حتما إلى التدهور. تنفيذ Future.Resolve يجب القيام الحد الأدنى الضروري من الإجراءات الخطية: لإيقاظ توقع ؛ ربما معالجة الخطأ وإرسال إعادة محاولة غير متزامن (المستخدمة في تطبيق دعم نظام المجموعة).
تأثير
معيار جيد هو نصف المقال!
معيار جيد هو أقرب ما يمكن لمكافحة الاستخدام من حيث الآثار الملاحظة. وهذا ليس بالأمر السهل.
خيار القياس ، الذي يبدو لي ، يشبه إلى حد كبير الخيار الحقيقي:
- "البرنامج النصي" الرئيسي يحاكي 5 عملاء متوازيين ،
- في كل "عميل" ، مقابل 300-1000 rps "مطلوب" ، يتم تشغيل goroutine (يتم تشغيل 3 gorutins مقابل 1000 rps ، يتم تشغيل 124 gorutins مقابل 128000 rps) ،
- يستخدم gorutin نسخة منفصلة من محددات الأسعار ويرسل الطلبات في سلسلة عشوائية - من 5 إلى 15 طلبًا.
تتيح لنا عشوائية سلسلة الاستعلامات تحقيق توزيع عشوائي للسلسلة في الجدول الزمني ، وهو ما يعكس بشكل صحيح الحمل الحقيقي.
النص المخفيالخيارات الخاطئة كانت:
أ) استخدم محدد معدل واحد لجميع gorutins لـ "العميل" وانتقل إليه لكل طلب - وهذا يؤدي إلى استهلاك مفرط لوحدة المعالجة المركزية بواسطة محدد السعر نفسه ، بالإضافة إلى زيادة وقت دوران goroutin ، مما يقلل من أداء RedisPipe بمعدل rps متوسط (ولكن بشكل غير مفهوم) يحسن في ارتفاع) ؛
ب) استخدام محدد معدل واحد لجميع gorutins من "العميل" وإرسال الطلبات في سلسلة - محدد معدل هو بالفعل لا يأكل كثيرا وحدة المعالجة المركزية ، ولكن التناوب goroutines في الوقت المناسب يزيد فقط ؛
ج) استخدم محدد معدل لكل goroutine ، لكن أرسل نفس السلسلة من 10 طلبات - في هذا السيناريو ، تستيقظ goroutines في وقت واحد جدًا ، مما يحسن نتائج RedisPipe بشكل غير عادل.
تم إجراء الاختبار على مثيل AWS c5-2xlarge رباعي النواة. إصدار Redis هو 5.0.
نسبة كثافة الاستعلام المطلوبة ، والكثافة الناتجة الناتجة والمستهلكة بواسطة وحدة المعالجة المركزية الفجل:
| rps المقصود | ريديجو
rps /٪ cpu | redispipe لا تنتظر
rps /٪ cpu | redispipe 50µs
rps /٪ cpu | redispipe 150µs
rps /٪ cpu |
|---|
| 1000 * 5 | 5015/7٪ | 5015/6٪ | 5015/6٪ | 5015/6٪ |
| 2000 * 5 | 10022/11 ٪ | 10022/10 ٪ | 10022/10 ٪ | 10022/10 ٪ |
| 4000 * 5 | 20036/21 ٪ | 20036/18 ٪ | 20035/17 ٪ | 20035/15 ٪ |
| 8000 * 5 | 40020/45 ٪ | 40062/37 ٪ | 40060/26 ٪ | 40056/19 ٪ |
| 16000 * 5 | 79994/71 ٪ | 80102/58 ٪ | 80096/33 ٪ | 80090/23 ٪ |
| 32000 * 5 | 159590/96 ٪ | 160 180/80 ٪ | 160167/39 ٪ | 160 150/29 ٪ |
| 64000 * 5 | 187774/99 ٪ | 320 313/98 ٪ | 320283/47 ٪ | 320258/37 ٪ |
| 92000 * 5 | 183206/99 ٪ | 480،443 / 97٪ | 480407/52 ٪ | 480 366/42 ٪ |
| 128000 * 5 | 179744/99 ٪ | 640484/97 ٪ | 640488/55 ٪ | 640428/46 ٪ |
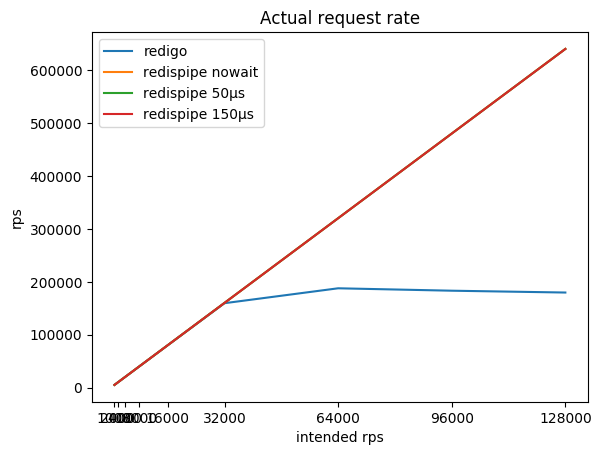
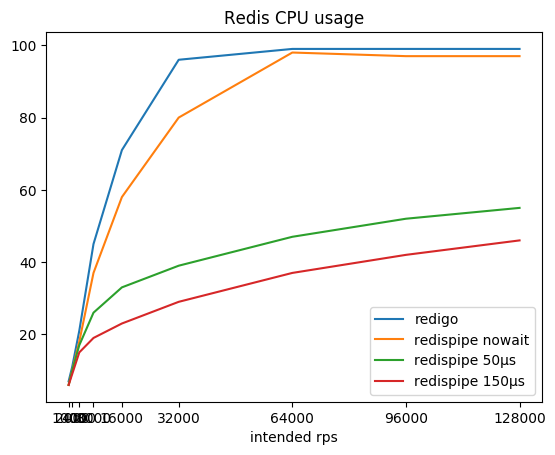
يمكنك ملاحظة أنه مع وجود موصل يعمل وفقًا للمخطط الكلاسيكي (طلب / استجابة + تجمع اتصال) ، فإن Redis سريعًا يستهلك لب المعالج ، وبعد ذلك يصبح من المستحيل الحصول على أكثر من 190 كيلو بت في الثانية.
يسمح لك RedisPipe بالضغط على كل الطاقة المطلوبة من Redis. وكلما توقفنا مؤقتًا لجمع الطلبات المتوازية ، قل استهلاك Redis لوحدة المعالجة المركزية. يتم الحصول على فائدة ملموسة بالفعل من 4krps من العميل (20krps في المجموع) إذا تم استخدام وقفة من 150 ميكروثانية.
حتى إذا لم يتم استخدام الإيقاف المؤقت بشكل صريح عندما يقع Redis على وحدة المعالجة المركزية ، فإن التأخير يظهر بمفرده. بالإضافة إلى ذلك ، تبدأ الطلبات في التخزين المؤقت بواسطة نظام التشغيل. هذا يسمح لـ RedisPipe بزيادة عدد الطلبات التي تم تنفيذها بنجاح عندما يقوم الموصل الكلاسيكي بخفض أقدامه بالفعل.
هذه هي النتيجة الرئيسية ، والتي كانت مطلوبة لإنشاء رابط جديد.
ماذا ، إذن ، يحدث مع استهلاك وحدة المعالجة المركزية على العميل ومع الطلبات المتأخرة؟
| rps المقصود | ريديجو
٪ cpu / ms | redispipe nowait
٪ cpu / ms | redispipe 50ms
٪ cpu / ms | redispipe 150ms
٪ cpu / ms |
|---|
| 1000 * 5 | 13 / 0.03 | 20 / 0.04 | 46 / 0.16 | 44 / 0.26 |
| 2000 * 5 | 25 / 0.03 | 33 / 0.04 | 77 / 0.16 | 71 / 0.26 |
| 4000 * 5 | 48 / 0.03 | 60 / 0.04 | 124 / 0.16 | 107 / 0.26 |
| 8000 * 5 | 94 / 0.03 | 119 / 0.04 | 178 / 0.15 | 141 / 0.26 |
| 16000 * 5 | 184 / 0.04 | 206 / 0.04 | 228 / 0.15 | 177 / 0.25 |
| 32000 * 5 | 341 / 0.08 | 322 / 0.05 | 280 / 0.15 | 226 / 0.26 |
| 64000 * 5 | 316 / 1.88 | 469 / 0.08 | 345 / 0.16 | 307 / 0.26 |
| 92000 * 5 | 313 / 2.88 | 511 / 0.16 | 398 / 0.17 | 366 / 0.27 |
| 128000 * 5 | 312 / 3.54 | 509 / 0.37 | 441 / 0.19 | 418 / 0.29 |
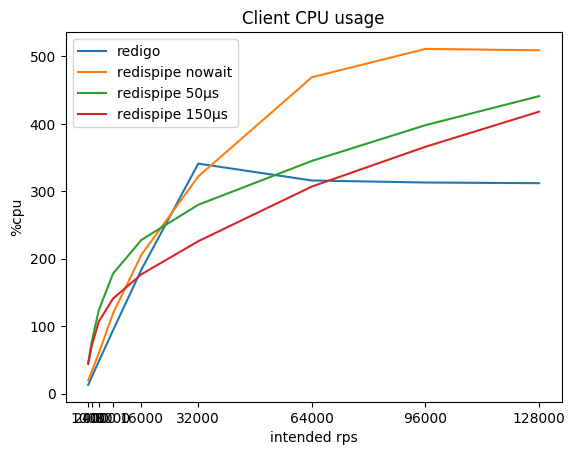
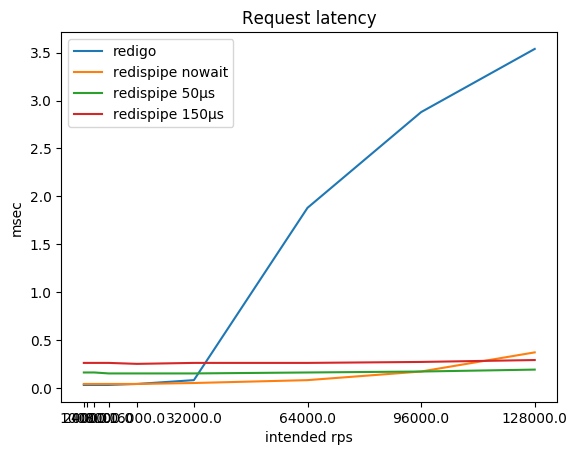
قد تلاحظ أنه في rps الصغيرة يستهلك RedisPipe نفسه وحدة المعالجة المركزية أكثر من "المنافس" ، خاصة إذا تم استخدام وقفة صغيرة. ويرجع ذلك أساسًا إلى تطبيق أجهزة ضبط الوقت في Go وتنفيذ مكالمات النظام المستخدمة في نظام التشغيل (على نظام Linux ، وهي futexsleep) ، حيث أن الاختلاف في وضع "no pause" أقل بكثير.
مع نمو rps ، يتم تعويض مقدار الحمل لأجهزة ضبط الوقت عن طريق انخفاض الحمل للاتصال بالشبكة ، وبعد 16 كيلوبت في الثانية لكل عميل ، باستخدام RedisPipe مع إيقاف مؤقت قدره 150 ميكروثانية يبدأ في تحقيق فوائد ملموسة.
بالطبع ، بعد أن استقر Redis على وحدة المعالجة المركزية (CPU) ، يبدأ زمن الوصول المتأخر للطلبات باستخدام الموصل الكلاسيكي. ومع ذلك ، لست متأكدًا من أنك في العادة تحقق 180 كيلوبت في الثانية من مثيل Redis. ولكن إذا كان الأمر كذلك ، ضع في اعتبارك أنك قد تواجه مشكلات.
طالما أن Redis لا يعمل في وحدة المعالجة المركزية ، فإن زمن الاستجابة ، بالطبع ، يعاني من استخدام توقف مؤقت. وضعت هذه التسوية عمدا في الموصل. ومع ذلك ، فإن هذه المقايضة تكون ملحوظة فقط إذا كان Redis والعميل على نفس المضيف الفعلي. وفقًا لطوبولوجيا الشبكة ، يمكن أن تكون رحلة ذهابًا وإيابًا إلى مضيف مجاور من مائة ثانية إلى ميلي ثانية واحدة. وفقًا لذلك ، يصبح الفرق في التأخير بالفعل بدلاً من تسع مرات (0.26 / 0.03) ثلاث مرات (0.36 / 0.13) أو يتم قياسه فقط بعشرات من المئة (1.26 / 1.03).
في عبء العمل الخاص بنا ، عندما يتم استخدام Redis كذاكرة تخزين مؤقت ، يكون التوقع الكلي للردود من قاعدة البيانات مع تفريغ ذاكرة التخزين المؤقت أكبر من التوقع الإجمالي لاستجابات Redis ، لأنه يُعتقد أن الزيادة في التأخير ليست كبيرة.
والنتيجة الإيجابية الرئيسية هي التسامح مع تحميل النمو: إذا زاد الحمل على الخدمة فجأة مرات N ، لن تستهلك Redis وحدة المعالجة المركزية في نفس مرات N أكثر. لتحمل أربعة أضعاف الحمل من 160 كيلو بت في الثانية إلى 640 كيلو بت في الثانية ، أنفق Redis فقط 1.6 ضعف وحدة المعالجة المركزية ، وزيادة الاستهلاك من 29 إلى 46 ٪. هذا يسمح لنا ألا نخاف أن ينحني ريديس فجأة. لن يتم تحديد قابلية التوسع للتطبيق من خلال تشغيل الموصل وتكلفة اتصال الشبكة (اقرأ: تكاليف وحدة المعالجة المركزية SYS).
ملاحظة. رمز المؤشر يعمل بقيم صغيرة. لمسح ضميري ، كررت الاختبار بقيم بحجم 768 بايت. زاد استهلاك وحدة المعالجة المركزية بواسطة الفجل زيادة ملحوظة (تصل إلى 66٪ في توقف مؤقت قدره 150 150s) ، وينخفض سقف الموصل الكلاسيكي إلى 170 كيلو بت في الثانية. لكن كل النسب المرصودة ظلت كما هي ، وبالتالي الاستنتاجات.
الكتلة
للتحجيم نستخدم Redis Cluster . هذا يتيح لنا استخدام Redis ليس فقط كذاكرة تخزين مؤقت ، ولكن أيضًا كخزن متقلب وفي نفس الوقت لا نفقد البيانات عند توسيع / ضغط مجموعة.
يستخدم Redis Cluster مبدأ العميل الذكي ، أي يجب على العميل مراقبة حالة الكتلة نفسها ، والاستجابة للأخطاء الإضافية التي يتم إرجاعها بواسطة "الفجل" عندما تنتقل "الباقة" من مثيل إلى آخر.
وفقًا لذلك ، يجب على العميل الاحتفاظ باتصالات بجميع مثيلات Redis في الكتلة وإصدار اتصال بالمطلب المطلوب لكل طلب. وكان في هذا المكان أن العميل المستخدم من قبل (لن نشير الإصبع) قد تم شده كثيراً. قام المؤلف ، الذي بالغ في تقدير تسويق Go (CSP ، القنوات ، goroutines) ، بتنفيذ تزامن العمل مع حالة الكتلة من خلال إرسال عمليات الاسترجاعات إلى goroutine المركزية. لقد أصبح هذا botnek خطيرة بالنسبة لنا. كتصحيح مؤقت ، اضطررنا إلى تشغيل أربعة عملاء إلى مجموعة واحدة ، كل منهم بدوره ، جمع ما يصل إلى مئات الاتصالات في التجمع لكل مثيل من Redis.
وفقا لذلك ، تم تكليف الموصل الجديد لمنع هذا الخطأ. يتم إجراء كل التفاعل مع حالة الكتلة على مسار تنفيذ الاستعلام بأمان قدر الإمكان:
- الحالة العنقودية غير قابلة للتطبيق عملياً ، وليس الطفرات العديدة التي تنكه الذرات
- يحدث الوصول إلى الحالة باستخدام atomic.StorePointer / atomic.LoadPointer ، وبالتالي يمكن الحصول عليه دون حظر.
وبالتالي ، حتى أثناء تحديث حالة الكتلة ، يمكن أن تستخدم الطلبات الحالة السابقة دون خوف من الانتظار على القفل.
يتم تحديث حالة الكتلة كل 5 ثوان. ولكن إذا كان هناك شك في عدم استقرار نظام المجموعة ، فسيتم فرض التحديث:
func (c *Cluster) control() { t := time.NewTicker(c.opts.CheckInterval) defer t.Stop()
إذا كانت استجابة MOVED أو ASK المستلمة من الفجل تحتوي على عنوان غير معروف ، فسيتم بدء الإضافة غير المتزامنة إلى التكوين. (أنا آسف ، لم أكن قد اكتشفت كيفية تبسيط الكود ، لأنه هنا الرابط .) لم يكن الأمر بدون استخدام الأقفال ، لكن تم أخذها لفترة قصيرة من الزمن. ويتحقق التوقع الرئيسي عن طريق حفظ رد الاتصال في الصفيف - في المستقبل ، وجهة نظر جانبية.
يتم تأسيس الاتصالات لجميع مثيلات Redis ، وللأسياد ، وللعبيد. بناءً على السياسة المفضلة ونوع الطلب (القراءة أو الكتابة) ، يمكن إرسال الطلب إلى السيد والعبد. يأخذ هذا في الاعتبار "حيوية" المثيل ، والذي يتكون من كل من المعلومات التي تم الحصول عليها عند تحديث حالة الكتلة والحالة الحالية للاتصال.
func (c *Cluster) connForSlot(slot uint16, policy ReplicaPolicyEnum) (*redisconn.Connection, *errorx.Error) { var conn *redisconn.Connection cfg := c.getConfig() shard := cfg.slot2shard(slot) nodes := cfg.nodes var addr string switch policy { case MasterOnly: addr = shard.addr[0]
هناك RoundRobinSeed.Current() خفي. RoundRobinSeed.Current() . هذا ، من ناحية ، هو مصدر العشوائية ، ومن ناحية أخرى ، العشوائية التي لا تتغير بشكل متكرر. إذا قمت بتحديد اتصال جديد لكل طلب ، فإن هذا يقلل من كفاءة خطوط الأنابيب. هذا هو السبب في أن التطبيق الافتراضي يغير قيمة الحالي كل بضع عشرات من المللي ثانية. من أجل الحصول على تراكبات أقل في الوقت المحدد ، يختار كل مضيف الفاصل الزمني الخاص به.
كما تتذكر ، يستخدم الاتصال مفهوم Future للطلبات غير المتزامنة. يستخدم نظام المجموعة نفس المفهوم: يلتف مستقبل مخصص بمفهوم متفاوت المسافات ، ويتم تغذية ذلك الاتصال.
لماذا التفاف المستقبل مخصص؟ أولاً ، في وضع الكتلة ، تُرجع كلمة "الفجل" "أخطاء" رائعة MOVED وأسأل بمعلومات أين تذهب للمفتاح الذي تحتاجه ، وبعد تلقي هذا الخطأ ، تحتاج إلى تكرار الطلب إلى مضيف آخر. ثانياً ، نظرًا لأننا ما زلنا بحاجة إلى تطبيق منطق إعادة التوجيه ، فلماذا لا يتم تضمين محاولة إعادة الطلب مع وجود خطأ في الإدخال / الإخراج (بالطبع ، فقط إذا كان طلب القراءة):
type request struct { c *Cluster req Request cb Future slot uint16 policy ReplicaPolicyEnum mayRetry bool } func (c *Cluster) SendWithPolicy(policy ReplicaPolicyEnum, req Request, cb Future) { slot := redisclusterutil.ReqSlot(req) policy = c.fixPolicy(slot, req, policy) conn, err := c.connForSlot(slot, policy, nil) if err != nil { cb.Resolve(err) return } r := &request{ c: c, req: req, cb: cb, slot: slot, policy: policy, mayRetry: policy != MasterOnly || redis.ReplicaSafe(req.Cmd), } conn.Send(req, r, 0) } func (r *request) Resolve(res interface{}, _ uint64) { err := redis.AsErrorx(res) if err == nil { r.resolve(res) return } switch { case err.IsOfType(redis.ErrIO): if !r.mayRetry {
هذا هو أيضا رمز مبسط. تم حذف القيود المفروضة على عدد مرات إعادة المحاولة ، وحفظ الاتصالات التي تنطوي على مشاكل ، وما إلى ذلك.
الراحة
طلبات غير متزامنة ، المستقبل هو superkule! لكن غير مريح بشكل رهيب.
الواجهة هي أهم شيء. يمكنك بيع أي شيء إذا كان لديه واجهة لطيفة. هذا هو السبب في اكتساب Redis و MongoDB شعبيتهما.
لذلك ، يجب تحويل طلباتنا غير المتزامنة إلى متزامن.
لا يبدو AsError أصلية للحصول على خطأ. ولكن أنا أحب ذلك ، ل في رأيي ، تكون النتيجة هي Result<T,Error> ، و AsError هو نمط مطابقة ersatz.
العيوب
ولكن ، لسوء الحظ ، هناك ذبابة في مرهم في هذا الرفاه.
لا يتضمن بروتوكول Redis طلبات إعادة ترتيب. وفي الوقت نفسه ، لديه طلبات حظر مثل BLPOP ، BRPOP.
هذا هو الفشل.
كما تعلم ، إذا تم حظر هذا الطلب ، فسيتم حظر جميع الطلبات التي تتبعه. وليس هناك ما يجب القيام به حيال ذلك.
بعد نقاش طويل ، تقرر حظر استخدام هذه الطلبات في RedisPipe.
بالطبع ، إذا كنت بحاجة إليها حقًا ، فيمكنك: فضح المعلمة ScriptMode: true ، وهذا كل شيء على ضميرك.
البدائل
في الواقع ، لا يزال هناك بديل لم أذكره ، ولكن ما فكر به القراء على دراية به ، هو ملك نظام ذاكرة التخزين المؤقت العنقودية twemproxy.
يفعل لـ Redis ما يفعله الموصل لدينا: إنه يحول "طلب / استجابة" خام وبدون رقة إلى "مد الأنابيب" اللطيف.
لكن twemproxy نفسها ستعاني من حقيقة أنه سيتعين عليه العمل على نظام "طلب / استجابة". هذه المرة. وثانياً ، نستخدم "الفجل" وكذلك "التخزين غير الموثوق" وأحيانًا نقوم بتغيير حجم الكتلة. و twemproxy لا يسهل مهمة إعادة التوازن بأي طريقة ويتطلب ، بالإضافة إلى ذلك ، إعادة تشغيل عند تغيير تكوين الكتلة.
التأثير
لم يكن لدي وقت لكتابة مقال ، وقد انتهت بالفعل موجات RedisPipe. تم اعتماد تصحيح في Radix.v3 يضيف خطوط الأنابيب إلى حمام السباحة الخاص بهم:
تحقق من RedisPipe ومعرفة ما إذا كان يمكن دمج استراتيجيتها المتمثلة في خطوط الأنابيب / الخلط الضمني
خطوط الأنابيب التلقائي للأوامر في بركة
إنهم أقل شدة من حيث السرعة (وفقًا لمعاييرهم ، لكنني لن أقول ذلك بالتأكيد). لكن مصلحتهم هي أنه يمكنهم إرسال أوامر الحظر إلى الاتصالات الأخرى من التجمع.
الخاتمة
لقد مر عامًا قريبًا على ذلك ، تساهم RedisPipe في فعالية خدمتنا.
وتحسبًا لأي "أيام حارة" ، فإن أحد الموارد التي لا تسبب سعاتها القلق هو وحدة المعالجة المركزية على خوادم Redis.
مستودع
المعيار