في مقالات سابقة ، كتبوا بالفعل عن كيفية عمل تقنية التعرف على النص لدينا:
حتى عام 2018 ، تم ترتيب التعرف على الأحرف اليابانية والصينية بنفس الطريقة: باستخدام المصنفات النقطية والميزات في المقام الأول. ولكن مع الاعتراف بالهيروغليفية ، هناك صعوبات:
- وهناك عدد كبير من الطبقات التي تحتاج إلى التمييز.
- شخصية الجهاز أكثر تعقيدا ككل.

من الصعب أن نقول بشكل لا لبس فيه عدد الأحرف في الأبجدية الصينية في الكتابة ، كما أنه من الدقة حساب عدد الكلمات باللغة الروسية. ولكن في معظم الأحيان في الكتابة الصينية ~ يتم استخدام 10000 حرفا. معهم حدنا من عدد الطبقات المستخدمة في الاعتراف.
تؤدي كل من المشكلات الموضحة أعلاه أيضًا إلى حقيقة أنه لتحقيق جودة عالية ، يتعين عليك استخدام عدد كبير من الميزات وأن هذه الميزات نفسها يتم حسابها على صور الأحرف الطويلة.
حتى لا تؤدي هذه المشكلات إلى تباطؤ حاد في نظام التعرف بالكامل ، كان علي استخدام الكثير من الأساليب البحثية ، التي تهدف في المقام الأول إلى قطع عدد كبير من الهيروغليفية بسرعة ، والتي لا تبدو هذه الصورة بالتأكيد. ما زال لم يساعد في النهاية ، لكننا أردنا أن نصل التكنولوجيا إلى مستوى جديد تمامًا.
بدأنا في دراسة إمكانية تطبيق الشبكات العصبية التلافيفية من أجل زيادة جودة وسرعة التعرف على الهيروغليفية. أردت استبدال الوحدة بأكملها للتعرف على شخصية واحدة لهذه اللغات بمساعدة الشبكات العصبية. في هذه المقالة ، سنصف كيف نجحنا في النهاية.
طريقة بسيطة: شبكة ملتوية واحدة للتعرف على جميع الحروف الهيروغليفية
بشكل عام ، استخدام الشبكات التلافيفية للتعرف على الأحرف ليس فكرة جديدة على الإطلاق.
تاريخيا ، كانت تستخدم لأول مرة على وجه التحديد لهذه المهمة في عام 1998. صحيح ، ثم لم تكن هذه الحروف المطبوعة ، ولكن الحروف والأرقام الإنجليزية المكتوبة بخط اليد.
على مدار 20 عامًا ، قفزت التكنولوجيا في مجال التعليم العميق إلى الأمام. بما في ذلك أبنية أكثر تقدما وأساليب جديدة للتعلم.
الهندسة المعمارية المعروضة في الرسم البياني أعلاه (LeNet) ، في الواقع ، واليوم مناسبة تمامًا لمهام بسيطة مثل التعرف على النص المطبوع. "بسيط" أسميها مقارنة بمهام رؤية الكمبيوتر الأخرى مثل البحث عن الوجوه والتعرف عليها.
يبدو أن الحل ليس أكثر بساطة. نأخذ شبكة عصبية ، عينة من الهيروغليفية المسمى ونقوم بتدريبها على مشكلة التصنيف. لسوء الحظ ، اتضح أن كل شيء ليس بهذه البساطة. جميع التعديلات الممكنة على LeNet لمهمة تصنيف 10000 الهيروغليفية لم توفر جودة كافية (على الأقل مماثلة لنظام التعرف لدينا بالفعل).
لتحقيق الجودة المطلوبة ، كان علينا أن نفكر في أبنية أكثر عمقًا وتعقيدًا: WideResNet ، SqueezeNet ، إلخ. بفضل مساعدتهم ، كان من الممكن تحقيق مستوى الجودة المطلوب ، لكنهم أعطوا انخفاضًا قويًا في السرعة - 3-5 مرات مقارنة بالخوارزمية الأساسية على وحدة المعالجة المركزية.
قد يتساءل شخص ما: "ما الهدف من قياس سرعة الشبكة على وحدة المعالجة المركزية ، إذا كان يعمل بشكل أسرع بكثير على معالج الرسومات (GPU)"؟ هنا يجدر الإدلاء بملاحظة بشأن حقيقة أن سرعة الخوارزمية على وحدة المعالجة المركزية مهمة بالنسبة لنا بشكل أساسي. نحن نعمل على تطوير التكنولوجيا لمجموعة كبيرة من منتجات ABBYY. في أكبر عدد من السيناريوهات ، يتم التعرف على جانب العميل ، ولا يمكننا أن نعرف أنه يحتوي على وحدة معالجة الرسومات.
لذلك ، في النهاية ، توصلنا إلى المشكلة التالية: شبكة عصبية واحدة للتعرف على جميع الشخصيات اعتمادًا على اختيار الهندسة المعمارية تعمل بشكل سيء للغاية أو بطيء جدًا.
مستويين الشبكة العصبية الهيروغليفية نموذج الاعتراف
كان علي أن أبحث عن طريقة أخرى. في نفس الوقت ، لم أكن أريد التخلي عن الشبكات العصبية. يبدو أن المشكلة الأكبر كانت في عدد هائل من الفصول ، بسببها كان من الضروري بناء شبكات للهندسة المعمارية المعقدة. لذلك ، قررنا أننا لن نقوم بتدريب شبكة لعدد كبير من الفصول ، أي للأبجدية بأكملها ، ولكن بدلاً من ذلك سنقوم بتدريب العديد من الشبكات على عدد صغير من الفصول (مجموعات فرعية من الأبجدية).
في التفاصيل العامة ، تم تقديم النظام المثالي على النحو التالي: يتم تقسيم الأبجدية إلى مجموعات من الشخصيات المتشابهة. تصنف شبكة المستوى الأول مجموعة الحروف التي تنتمي إليها صورة معينة. لكل مجموعة ، بدورها ، يتم تدريب شبكة المستوى الثاني ، والتي تنتج التصنيف النهائي داخل كل مجموعة.
صورة قابلة للنقر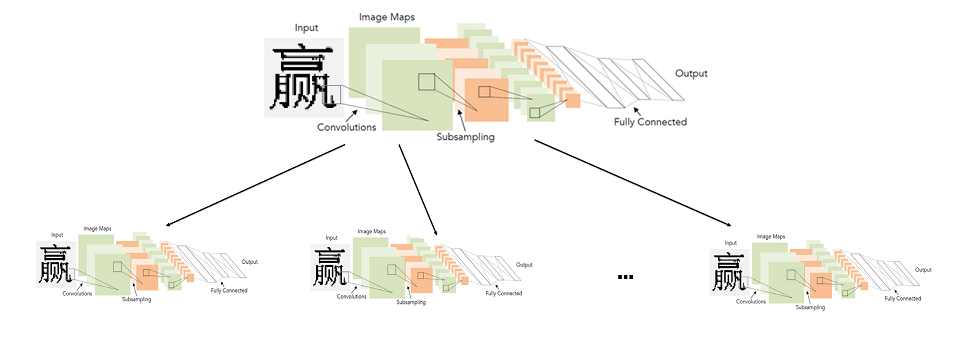
وبالتالي ، نجعل التصنيف النهائي من خلال إطلاق شبكتين: الأول يحدد شبكة المستوى الثاني التي سيتم إطلاقها ، والثاني يقوم بالفعل بتصنيف نهائي.
في الواقع ، النقطة الأساسية هنا هي كيفية تقسيم الأحرف إلى مجموعات بحيث يمكن جعل شبكة المستوى الأول دقيقة وسريعة.
بناء مصنف المستوى الأول
لفهم رموز الشبكة التي يسهل تمييزها والأكثر صعوبة ، من الأسهل النظر إلى العلامات المميزة لرموز معينة. للقيام بذلك ، أخذنا شبكة مصنّفة ، تم تدريبنا على التمييز بين جميع أحرف الأبجدية بجودة جيدة ونظرنا إلى إحصائيات التنشيط الخاصة بالطبقة قبل الأخيرة من هذه الشبكة - بدأنا في النظر في تمثيلات الميزة النهائية التي تتلقاها الشبكة لجميع الأحرف.
في الوقت نفسه ، علمنا أن الصورة يجب أن يكون هناك شيء مثل التالي:
هذا مثال بسيط لحالة تصنيف مجموعة من الأرقام المكتوبة بخط اليد (MNIST) إلى 10 فئات. على الطبقة المخفية قبل الأخيرة ، والتي تذهب قبل التصنيف ، لا يوجد سوى 2 من الخلايا العصبية ، مما يجعل إحصائيات التنشيط الخاصة بهم سهلة العرض على المستوى. تقابل كل نقطة على الرسم البياني بعض الأمثلة من عينة الاختبار. يتوافق لون النقطة مع فئة معينة.
في حالتنا ، كان البعد الخاص بمساحة الميزة أكبر من 128 في المثال ، وقمنا بتشغيل مجموعة من الصور من عينة اختبار وتلقى متجهًا مميزًا لكل صورة. بعد ذلك ، تم تطبيعها (مقسوما على الطول). من الصورة أعلاه ، من الواضح لماذا هذا يستحق القيام به. قمنا بتجميع المتجهات المعيارية بطريقة KMeans. حصلنا على تفصيل للعينة إلى مجموعات من الصور المتشابهة (من وجهة نظر الشبكة).
ولكن في النهاية ، كنا بحاجة إلى تقسيم الأبجدية إلى مجموعات ، وليس قسمًا من عينة الاختبار. ولكن ليس من الصعب الحصول على الجزء الأول: يكفي تعيين تسمية كل فئة إلى الكتلة التي تحتوي على معظم صور هذه الفئة. في معظم الحالات ، بطبيعة الحال ، سوف ينتهي الفصل بأكمله داخل كتلة واحدة.
حسنًا ، هذا كل شيء ، حصلنا على قسم من الأبجدية بأكملها إلى مجموعات من الشخصيات المتشابهة. ثم يبقى اختيار بنية بسيطة وتدريب المصنف على التمييز بين هذه المجموعات.
فيما يلي مثال على 6 مجموعات عشوائية تم الحصول عليها بتقسيم الأبجدية المصدر بالكامل إلى 500 مجموعة:
بناء المصنفات المستوى الثاني
بعد ذلك ، تحتاج إلى تحديد مجموعات الأحرف المستهدفة التي ستتعلمها مصنفات المستوى الثاني. يبدو أن الإجابة واضحة - يجب أن تكون مجموعات من الشخصيات تم الحصول عليها في الخطوة السابقة. هذا سوف ينجح ، ولكن ليس دائما بجودة جيدة.
والحقيقة هي أن المصنف من المستوى الأول يرتكب أخطاء في أي حال ، ويمكن تعويضها جزئيا عن طريق بناء مجموعات من المستوى الثاني على النحو التالي:
- نصلح عينة منفصلة معينة من صور الرموز (لا تشارك في التدريب أو في الاختبار) ؛
- نقوم بتشغيل هذه العينة من خلال مصنف مدرّب من المستوى الأول ، مع وضع علامة على كل صورة بتسمية هذا المصنف (تسمية المجموعة) ؛
- بالنسبة لكل رمز ، فإننا نعتبر كل المجموعات الممكنة التي ينتمي إليها مصنف المستوى الأول في صور هذا الرمز ؛
- أضف هذا الرمز إلى جميع المجموعات حتى يتم الوصول إلى درجة التغطية المطلوبة T_acc ؛
- نحن نعتبر المجموعات النهائية للرموز مجموعات مستهدفة من المستوى الثاني ، والتي سيتم تدريب المصنفين عليها.
على سبيل المثال ، تم تعيين صور الرمز "A" بواسطة مصنف المستوى الأول 980 مرة للمجموعة الخامسة ، 19 مرة للمجموعة الثانية ومرة واحدة للمجموعة السادسة. في المجموع لدينا 1000 صورة لهذا الرمز.
ثم يمكننا إضافة الرمز "A" إلى المجموعة الخامسة والحصول على تغطية بنسبة 98 ٪ من هذا الرمز. يمكننا أن نعزوها إلى المجموعة الخامسة والثانية والحصول على تغطية بنسبة 99.9 ٪. ويمكننا أن نعزوها على الفور إلى المجموعات (5 ، 2 ، 6) والحصول على تغطية 100 ٪.
في جوهرها ، يحدد T_acc بعض التوازن بين السرعة والجودة. كلما كان الأمر أعلى ، كلما كانت أعلى جودة هي الجودة النهائية للتصنيف ، ولكن الأكبر سيكون هو الفئات المستهدفة من المستوى الثاني وأكثر صعوبة التصنيف في المستوى الثاني.
تدل الممارسة على أنه حتى مع T_acc = 1 ، فإن الزيادة في حجم المجموعات نتيجة لإجراء التجديد الموصوف أعلاه ليست كبيرة - في المتوسط ، حوالي 2 مرات. من الواضح أن هذا سيعتمد بشكل مباشر على جودة مصنف المستوى الأول المدربين.
فيما يلي مثال على كيفية عمل هذا الإكمال لأحد المجموعات من القسم نفسه إلى 500 مجموعة ، والتي كانت أعلى:
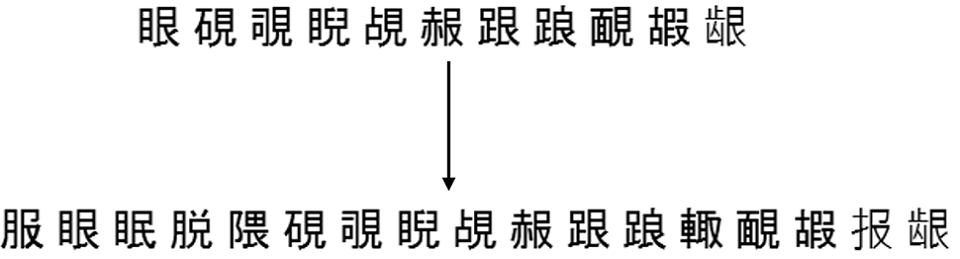
نموذج تضمين النتائج
عملت النماذج ذات المستوى الثاني المدربة بشكل أسرع وأفضل من المصنفات المستخدمة سابقًا. في الواقع ، لم يكن من السهل للغاية "تكوين صداقات" مع نفس الرسم البياني للتقسيم الخطي (GLD). للقيام بذلك ، اضطررت لتدريس النموذج بشكل منفصل لتمييز الأحرف عن أخطاء تقسيم البيانات والخطأ المسبقة (لإعادة الثقة المنخفضة في هذه الحالات).
النتيجة النهائية للتضمين في خوارزمية التعرّف الكامل على المستندات أدناه (تم الحصول عليها في مجموعة المستندات الصينية واليابانية) ، تتم الإشارة إلى السرعة للخوارزمية الكاملة:
قمنا بتحسين الجودة والتسارع في الوضع العادي والسريع ، مع نقل كل التعرف على الأحرف إلى الشبكات العصبية.
قليلا عن الاعتراف نهاية إلى نهاية
حتى الآن ، تستخدم معظم أنظمة التعرف الضوئي على الحروف المعروفة بشكل عام (نفس Tesseract من Google) بنية النهاية للشبكات العصبية من النهاية إلى النهاية للتعرف على السلاسل أو شظاياها ككل. ولكن هنا استخدمنا الشبكات العصبية كبديل لوحدة التعرف على الأحرف الفردية. هذا ليس صدفة.
والحقيقة هي أن تجزئة السلسلة إلى حروف باللغة الصينية واليابانية المطبوعة ليست مشكلة كبيرة بسبب الطباعة
أحادية المسافة . في هذا الصدد ، لا يؤدي استخدام التعرّف من طرف إلى طرف لهذه اللغات على تحسين الجودة إلى حد كبير ، ولكنه أبطأ بكثير (على الأقل في وحدة المعالجة المركزية). بشكل عام ، ليس من الواضح كيفية استخدام النهج المقترح من مستويين في السياق من النهاية إلى النهاية.
على العكس من ذلك ، هناك لغات يمثل فيها التقسيم الخطي إلى أحرف مشكلة رئيسية. أمثلة صريحة هي العربية والهندية. بالنسبة إلى اللغة العربية ، على سبيل المثال ، يتم بالفعل دراسة الحلول الشاملة معنا بشكل نشط. لكن هذه قصة مختلفة تماما.
أليكسي Zhuravlev ، رئيس مجموعة التكنولوجيات الجديدة التعرف الضوئي على الحروف