
الشبكات الاجتماعية هي واحدة من منتجات الإنترنت الأكثر شعبية اليوم وأحد مصادر البيانات الرئيسية للتحليل. داخل الشبكات الاجتماعية نفسها ، تعتبر المهمة الأكثر صعوبة وإثارة للاهتمام في مجال علم البيانات هي تشكيل موجز الأخبار. في الواقع ، من أجل تلبية الطلبات المتزايدة للمستخدم لجودة وأهمية المحتوى ، من الضروري معرفة كيفية جمع المعلومات من العديد من المصادر ، وحساب توقعات رد فعل المستخدم والتوازن بين عشرات المقاييس المتنافسة في اختبار A / B. كما أن وجود كميات كبيرة من البيانات وأعباء العمل العالية والمتطلبات الصارمة لسرعة الاستجابة تجعل المهمة أكثر إثارة للاهتمام.
يبدو أن مهام التصنيف قد تمت دراستها بالفعل على مدار اليوم ، ولكن إذا نظرت عن كثب ، فليس بهذه البساطة. المحتوى في الخلاصة غير متجانس للغاية - هذه صورة للأصدقاء والمذكرات ومقاطع الفيديو الفيروسية والقراءات الطويلة والبوب العلمي. من أجل تجميع كل شيء ، تحتاج إلى المعرفة من مختلف المجالات: رؤية الكمبيوتر ، والعمل مع النصوص ، وأنظمة التوصية ، وبدون الفشل ، أدوات التخزين ومعالجة البيانات المحملة للغاية. إن العثور على شخص واحد بكل المهارات أمر صعب للغاية اليوم ، لذا فإن فرز الشريط هو في الحقيقة مهمة جماعية.
بدأت
Odnoklassniki في تجربة خوارزميات ترتيب الشريط المختلفة في عام 2012 ، وفي عام 2014 ، انضم التعلم الآلي أيضًا إلى هذه العملية. أصبح هذا ممكنًا ، أولاً وقبل كل شيء ، بفضل التقدم المحرز في مجال التقنيات للعمل مع تدفقات البيانات.
بمجرد البدء في جمع عروض الكائنات وسماتها في
Kafka وتجميع السجلات باستخدام
Samza ، تمكنا من إنشاء مجموعة بيانات لنماذج التدريب
وحساب أكثر الميزات
" جذبًا " : كائنات Click Click Rate وتوقعات نظام التوصية "بناءً على"
عمل الزملاء من LinkedIn .

سرعان ما أصبح من الواضح أن العمود الفقري للإنحدار اللوجستي لا يمكنه إخراج الشريط وحده ، لأن المستخدم يمكن أن يكون له رد فعل متنوع للغاية: فئة ، تعليق ، نقرة ، إخفاء ، وما إلى ذلك ، ويمكن أن يكون المحتوى مختلفًا تمامًا - صورة صديق أو منشور مجموعة أو vidosik منقوش من صديق. كل رد فعل لكل نوع من أنواع المحتوى له خصوصية خاصة به وقيمته التجارية. ونتيجة لذلك ، توصلنا إلى مفهوم "
مصفوفة الانحدار اللوجستي ": تم تصميم نموذج منفصل لكل نوع من أنواع المحتوى ولكل رد فعل ، ومن ثم يتم مضاعفة توقعاتهم بمصفوفة للوزن تتكون من الأيدي بناءً على أولويات العمل الحالية.
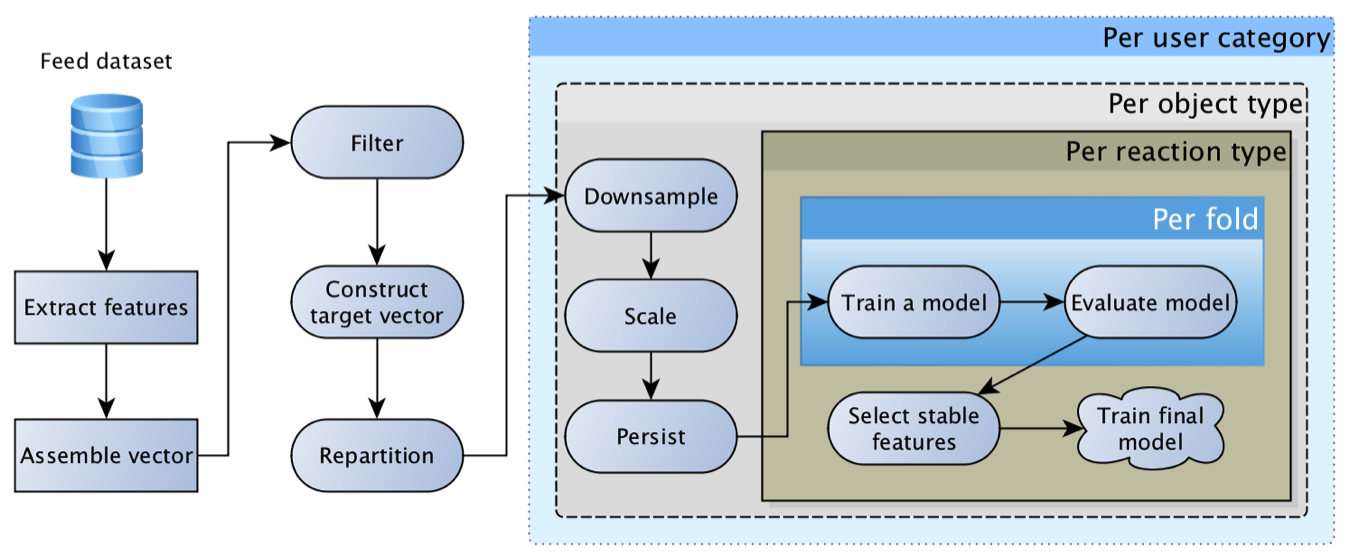
كان هذا النموذج قابلاً للتطبيق للغاية ولوقت طويل كان النموذج الرئيسي. بمرور الوقت ، اكتسبت ميزات أكثر إثارة للاهتمام: للكائنات ، للمستخدمين ، للمؤلفين ، لعلاقة المستخدم مع المؤلف ، لأولئك الذين تفاعلوا مع الكائن ، إلخ. ونتيجة لذلك ، فإن المحاولات الأولى لاستبدال الانحدار بشبكة عصبية انتهت بـ "ميزات حزينة للغاية ، والشبكة لا تعطي دفعة قوية".
في هذه الحالة ، غالبًا ما يتم توفير الدعم الملموس من وجهة نظر نشاط المستخدم من خلال التحسينات الفنية وليس الخوارزمية: استجمع عددًا أكبر من المرشحين للترتيب وتتبع حقائق العرض بدقة أكبر وتحسين سرعة استجابة الخوارزمية وتعميق سجل التصفح. غالبًا ما أسفرت هذه التحسينات عن وحدات ، وأحيانًا زيادة في النشاط بنسبة عشرات ، في حين أن تحديث النموذج وإضافة ميزة غالبًا ما زاد من عشرة في المئة زيادة.

كانت هناك صعوبة منفصلة في تجارب تحديث النموذج تتمثل في إعادة توازن المحتوى - توزيع توقعات النموذج "الجديد" غالبًا ما يختلف اختلافًا كبيرًا عن سابقه ، مما أدى إلى إعادة توزيع حركة المرور والتغذية المرتدة. نتيجة لذلك ، يصعب تقييم جودة النموذج الجديد ، حيث إنك تحتاج أولاً إلى معايرة رصيد المحتوى (كرر عملية تعيين أوزان المصفوفة لأغراض العمل). بعد دراسة
تجربة الزملاء من Facebook ، أدركنا أن النموذج
يحتاج إلى معايرة ، وتم إضافة الانحدار متساوي التوتر على رأس الانحدار اللوجستي :).
غالبًا ما نمر بالإحباط - في عملية إعداد سمات المحتوى الجديدة - قد يؤدي النموذج البسيط الذي يستخدم التقنيات التعاونية الأساسية إلى منح 80٪ أو حتى 90٪ من النتيجة ، في حين أن شبكة عصبية عصرية مدربة لمدة أسبوع على وحدات معالجة رسومات عالية التكلفة ، ولكنها تكتشف القطط والسيارات بشكل مثالي المقاييس فقط في الرقم الثالث. غالبًا ما يمكن ملاحظة تأثير مماثل عند تطبيق النماذج المواضيعية و fastText وغيرها من الزخارف. لقد نجحنا في التغلب على الإحباط من خلال النظر في التحقق من الصحة من الزاوية اليمنى: يتحسن أداء الخوارزميات التعاونية بشكل كبير مع تراكم المعلومات حول الكائن ، بينما في الكائنات "الطازجة" ، تعطي سمات المحتوى دفعة ملموسة.
ولكن ، بالطبع ، في يوم من الأيام ، يجب تحسين نتائج الانحدار اللوجستي ، وقد تم إحراز تقدم من خلال تطبيق
XGBoost-Spark الذي تم إصداره مؤخرًا.
لم يكن التكامل
سهلاً ، ولكن في النهاية ، أصبح النموذج أخيرًا عصريًا وشبابًا ، ونمت المقاييس بنسبة مئوية.
بالتأكيد ، يمكن استخراج مزيد من المعرفة من البيانات ويمكن الوصول إلى ترتيب الشريط إلى مستوى جديد - واليوم يتمتع الجميع بفرصة تجربة هذه المهمة غير التافهة في مسابقة
SNA Hackathon 2019 . تجري المسابقة على مرحلتين: من 7 فبراير إلى 15 مارس ، قم بتنزيل الحل لإحدى المهام الثلاث. بعد 15 مارس ، سيتم تلخيص النتائج الوسيطة ، وسيتلقى 15 شخصًا من أعلى المتصدرين لكل مهمة دعوات إلى المرحلة الثانية ، والتي ستعقد في الفترة من 30 مارس إلى 1 أبريل في مكتب مجموعة Mail.ru في موسكو. بالإضافة إلى ذلك ، ستتلقى الدعوة إلى المرحلة الثانية ثلاثة أشخاص يتصدرون التصنيف في نهاية 23 فبراير.
لماذا هناك ثلاث مهام؟ كجزء من المرحلة عبر الإنترنت ، نقدم ثلاث مجموعات من البيانات ، يقدم كل منها جانبًا واحدًا فقط من الجوانب: الصورة أو النص أو المعلومات حول مجموعة متنوعة من السمات التعاونية. وفقط في المرحلة الثانية ، عندما يجتمع الخبراء في مختلف المجالات ، سيتم الكشف عن مجموعة البيانات العامة ، مما يتيح لك العثور على نقاط للتآزر بين الطرق المختلفة.
مهتم في مهمة؟ انضم إلى
SNA Hackathon :)