قال بيل كينيدي في محاضرة عن دورة
برمجة Ultimate Go الرائعة:
يسعى العديد من المطورين إلى تحسين التعليمات البرمجية الخاصة بهم. يأخذون خطًا ويعيدون كتابته ، قائلين إن هذا سيصبح أسرع. تحتاج إلى التوقف. لا يمكن القول إن هذا الرمز أو هذا الرمز أسرع إلا بعد تحديده ووضع المعايير. الكهانة ليست هي الطريقة الصحيحة لكتابة الكود.
لقد أردت منذ فترة طويلة أن أظهر بمثال عملي كيف يمكن أن يعمل هذا. وفي اليوم الآخر ، تم لفت انتباهي إلى الكود التالي ، والذي يمكن استخدامه فقط كمثال:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber) tempList := model.BuildsList{} for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchURLs = b.ReversePatchURLs b.ExtractedSize = b.RPatchExtractedSize tempList = append(tempList, b) }
هنا ، في جميع عناصر شريحة
builds التي تم إرجاعها من قاعدة البيانات ، يتم استبدال
PatchURLs بـ
ReversePatchURLs ،
ExtractedSize by
RPatchExtractedSize ويتم إجراء عكس - يتم تغيير ترتيب العناصر بحيث يصبح العنصر الأخير هو الأول والأخير.
في رأيي ، شفرة المصدر معقدة بعض الشيء ويمكن قراءتها. ينفذ هذا الرمز خوارزمية بسيطة تتكون من جزأين منطقيين: تغيير عناصر الشريحة والفرز. ولكن حتى يقوم المبرمج بعزل هذين العنصرين ، فسوف يستغرق الأمر بعض الوقت.
على الرغم من حقيقة أن كلا الجزأين مهمين ، إلا أن الكود العكسي لم يتم التأكيد عليه كما نود. وهي منتشرة في ثلاثة أسطر تمزيقها: تهيئة شريحة جديدة ، وتكرار شريحة موجودة بترتيب عكسي ، وإضافة عنصر إلى نهاية شريحة جديدة. ومع ذلك ، لا يمكن للمرء أن يتجاهل المزايا التي لا شك فيها لهذا الكود: الكود يعمل واختبر ، والتحدث بموضوعية ، إنه مناسب تمامًا. لا يمكن أن يكون التصور الشخصي للرمز من قبل مطور فردي ذريعة لإعادة كتابته. لسوء الحظ أو لحسن الحظ ، نحن لا نعيد كتابة الشفرة لمجرد أننا لا نحبها (أو كما يحدث غالبًا لأنه ببساطة ليس عيبنا ، انظر
عيب فادح ).
ولكن ماذا لو تمكنا ليس فقط من تحسين تصور الكود ، ولكن أيضا تسريع بشكل كبير؟ هذه مسألة مختلفة تماما. يمكنك تقديم عدة خوارزميات بديلة تؤدي الوظيفة المضمنة في التعليمات البرمجية.
الخيار الأول: التكرار على جميع العناصر في حلقة
النطاق ؛ لعكس الشريحة الأصلية في كل تكرار ، أضف عنصرًا إلى بداية الصفيف النهائي. لذلك يمكننا التخلص من التعقيد ، للمتغير
i ، استخدام الدالة
len ، ومن الصعب إدراك التكرار على العناصر من النهاية ، وكذلك تقليل مقدار الكود بواسطة سطرين (من سبعة أسطر إلى خمسة) ، وكلما قل احتمال السماح لها خطأ.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*store.Build{build}, tempList...) }
بعد إزالة تعداد الشرائح من النهاية ، ميزنا بوضوح بين عمليات تغيير العناصر (الصف الثالث) وعكس الصفيف الأصلي (الصف الرابع).
الفكرة الرئيسية للخيار الثاني هي زيادة تنوع العناصر والفرز. أولاً ، نفرز العناصر ونغيرها ، ثم نفرز الشريحة بواسطة عملية منفصلة. ستتطلب هذه الطريقة تطبيقًا إضافيًا لواجهة الفرز الخاصة بالشريحة ، ولكنها ستزيد من إمكانية القراءة وتفصل تمامًا وعزل العكس عن العناصر المتغيرة ،
وستشير طريقة
العكس بالتأكيد إلى النتيجة المرجوة للقارئ.
var tempList []*store.Build for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(sort.IntSlice(keys)))
الخيار الثالث هو تكرار للخيار الثاني ، لكن
يتم استخدام
sort.Slice للفرز ، مما يزيد من مقدار الشفرة بسطر واحد ، لكنه يتجنب التطبيق الإضافي لواجهة الفرز.
for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id })
للوهلة الأولى ، من حيث التعقيد الداخلي ، فإن عدد التكرارات والوظائف المطبقة والرمز الأولي والخوارزمية الأولى قريبان ؛ قد يبدو الخياران الثاني والثالث أكثر صعوبة ، ولكن من المستحيل أن نقول بشكل لا لبس فيه أي من الخيارات الأربعة هو الأفضل.
لذلك ، منعنا أنفسنا من اتخاذ قرارات بناءً على افتراضات لا تدعمها الأدلة ، ولكن من الواضح أن الأكثر إثارة للاهتمام هنا هو كيف تتصرف وظيفة الإلحاق عند إضافة عنصر إلى النهاية وبداية الشريحة. بعد كل شيء ، في الواقع ، هذه الوظيفة ليست بسيطة كما يبدو.
تعمل
الإلحاق كما يلي : إما أن تضيف عنصرًا جديدًا إلى الشريحة الموجودة إذا كانت سعتها أكبر من الطول الإجمالي ، أو تحتفظ في الذاكرة بمكان لشريحة جديدة ، ونسخ البيانات من الشريحة الأولى فيه ، وإضافة بيانات الثانية وإرجاع عنصر جديد كنتيجة لذلك شريحة.
فارق بسيط الأكثر إثارة للاهتمام في عمل هذه الوظيفة هو الخوارزمية المستخدمة في حجز الذاكرة لصفيف جديد. نظرًا لأن أغلى عملية هي تخصيص جزء جديد من الذاكرة ، فقد جعل مطورو Go خدعة صغيرة لجعل عملية
التذييل أرخص. في البداية ، من أجل عدم حجز الذاكرة من جديد في كل مرة يتم فيها إضافة عنصر ، يتم تخصيص مقدار الذاكرة بهامش معين - مرتين الأصلي ، ولكن بعد عدد معين من العناصر ، لا يصبح حجم قسم الذاكرة المحجوزة حديثًا أكثر من مرتين ، ولكن بنسبة 25٪.
بالنظر إلى الفهم الجديد لوظيفة
الإلحاق ، فإن الإجابة على السؤال: "ما سيكون أسرع: إضافة عنصر واحد إلى نهاية شريحة موجودة أو إضافة شريحة موجودة إلى شريحة من عنصر واحد؟" - بالفعل أكثر شفافية. يمكن افتراض أنه في الحالة الثانية ، مقارنة بالحالة الأولى ، سيكون هناك المزيد من عمليات تخصيص الذاكرة ، والتي سوف تؤثر بشكل مباشر على سرعة العمل.
لذلك اقتربنا بسلاسة من المعايير. بمساعدة المعايير ، يمكنك تقييم تحميل الخوارزمية على أهم الموارد ، مثل وقت التشغيل وذاكرة الوصول العشوائي.
دعنا نكتب معيارًا لتقييم الخوارزميات الأربعة ، وفي نفس الوقت سنقيِّم ما يمكن أن يعطيه النمو من رفض (من أجل فهم مقدار الوقت الإجمالي الذي يقضيه الفرز تمامًا). رمز المعيار:
package services import ( "testing" "sort" ) type Build struct { Id int ExtractedSize int64 PatchUrls string ReversePatchUrls string RPatchExtractedSize int64 } type Builds []*Build func (a Builds) Len() int { return len(a) } func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id } func prepare() Builds { var builds Builds for i := 0; i < 100000; i++ { builds = append(builds, &Build{Id: i}) } return builds } func BenchmarkF1(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for i := len(builds) - 1; i >= 0; i-- { b := builds[i] b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize tempList = append(tempList, b) } } } func BenchmarkF2(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { var tempList Builds copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize tempList = append([]*Build{build}, tempList...) } } } func BenchmarkF3(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Sort(sort.Reverse(builds)) } } func BenchmarkF4(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } sort.Slice(builds, func(i int, j int) bool { return builds[i].Id > builds[j].Id }) } } func BenchmarkF5(b *testing.B) { data := prepare() builds := make(Builds, len(data)) b.ResetTimer() for i := 0; i < bN; i++ { copy(builds, data) for _, build := range builds { build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize } } }
بدء
الاختبار باستخدام الأمر
go test -bench =. بنشم .
يتم عرض نتائج العمليات الحسابية للشرائح 10 و 100 و 1000 و 10 000 و 100 000 في الرسم البياني أدناه ، حيث F1 هي الخوارزمية الأولية ، F2 هي إضافة العنصر إلى بداية الصفيف ، F3 هو استخدام
sort.Rever هو
الفرز. ، F5 - رفض الفرز.
وقت التشغيل عدد تخصيصات الذاكرة
عدد تخصيصات الذاكرة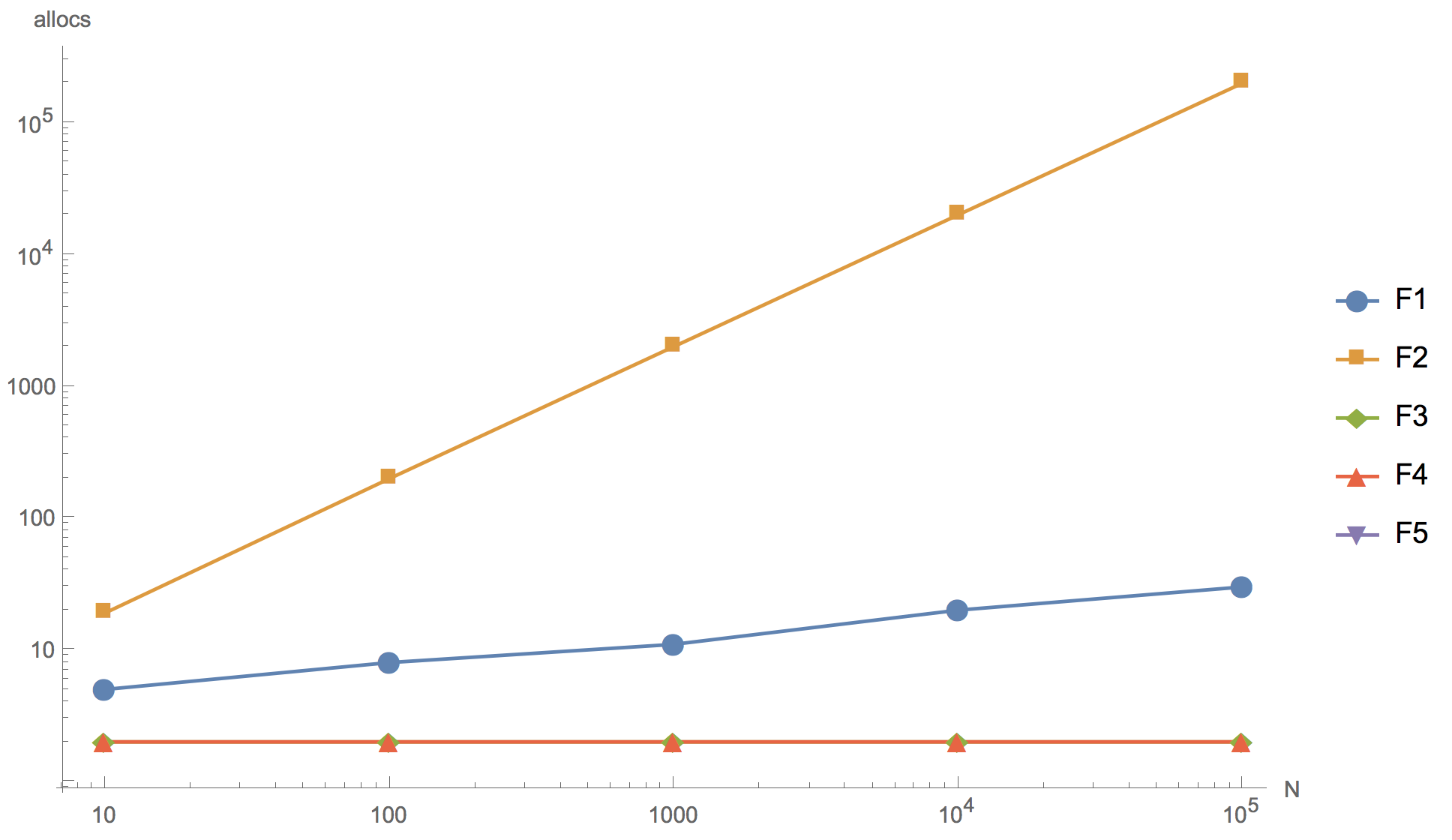
كما ترون من الرسم البياني ، يمكنك زيادة المصفوفة ، لكن النتيجة النهائية يمكن تمييزها من حيث المبدأ على شريحة من 10 عناصر.
لا يمكن لأي من الخوارزميات البديلة المقترحة (F2 ، F3 ، F4) أن تتجاوز الخوارزمية الأصلية (F1) في السرعة. على الرغم من حقيقة أن جميع ما عدا F2 لديها تخصيصات ذاكرة أقل من الأصلي. تبين أن الخوارزمية الأولى (F2) مع إضافة عنصر إلى بداية الشريحة هي الأكثر فاعلية: كما هو متوقع ، يوجد بها الكثير من عمليات تخصيص الذاكرة ، لدرجة أنه من المستحيل تمامًا استخدامها في تطوير المنتج. الخوارزمية التي تستخدم وظيفة الفرز العكسي المدمجة (F3) أبطأ بكثير من الخوارزمية الأصلية.
وخوارزمية الفرز فقط لـ
sort.Slice قابلة للمقارنة في السرعة مع الخوارزمية الأصلية ، لكنها أقل شأناً من ذلك.
يمكنك أيضًا ملاحظة أن رفض الفرز (F5) يعطي تسارعًا كبيرًا. لذلك ، إذا كنت تريد حقًا إعادة كتابة التعليمات البرمجية ، يمكنك الانتقال في هذا الاتجاه ، على سبيل المثال ، رفع شريحة
الإنشاءات الأولية من قاعدة البيانات ، واستخدام الفرز حسب المعرف DESC بدلاً من ASC في الطلب. ولكن في الوقت نفسه ، نحن مضطرون إلى تجاوز حدود قسم الكود المدروس ، مما يستلزم إدخال تغييرات متعددة.
الاستنتاجات
اكتب المعايير.
من غير المنطقي أن تقضي وقتك في التفكير فيما إذا كان كود معين سيكون أسرع. يمكن أن تكون المعلومات الواردة من الإنترنت ، وأحكام الزملاء وغيرهم ، بغض النظر عن مدى موثوقيتهم ، بمثابة حجج مساعدة ، ولكن يجب أن يظل دور كبير القضاة ، الذي يقرر ما إذا كان خوارزمية جديدة أم لا ، مع المعايير.
Go هي فقط للوهلة الأولى لغة بسيطة إلى حد ما. تنطبق قاعدة 80⁄20 الشاملة هنا. تمثل هذه٪ 20 التفاصيل الدقيقة للبنية الداخلية للغة ، والتي تميز معرفتها المبتدئ عن المطور ذي الخبرة. ممارسة كتابة المعايير لحل أسئلتك هي واحدة من أرخص الطرق وأكثرها فعالية للحصول على إجابة وفهم أعمق للبنية الداخلية ومبادئ لغة Go.