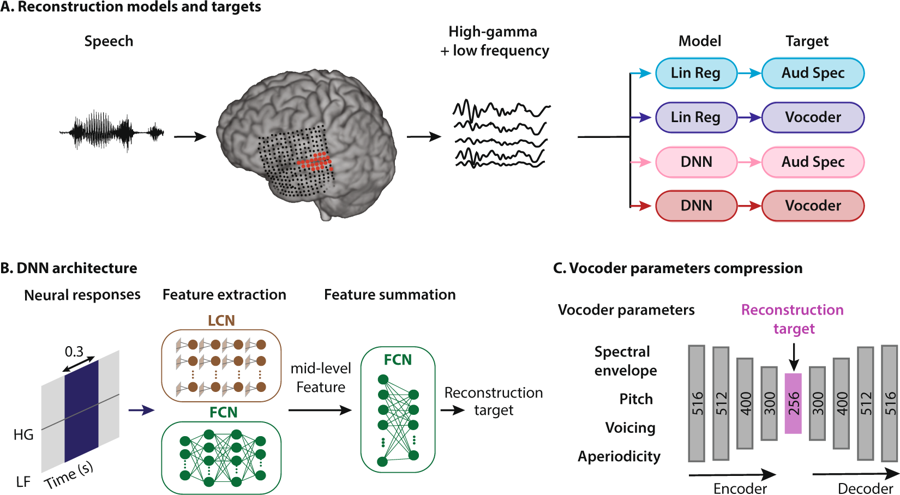
 مخطط طريقة إعادة بناء الكلام. شخص يستمع إلى الكلمات ، ونتيجة لذلك ، يتم تنشيط الخلايا العصبية في قشرة السمع. يتم تفسير البيانات بأربع طرق: من خلال الجمع بين نوعين من نماذج الانحدار ونوعين من تمثيل الكلام ، ثم يدخلون إلى نظام الشبكة العصبية لاستخراج الميزات التي يتم استخدامها لاحقًا لتكوين معلمات مشفر الصوت
مخطط طريقة إعادة بناء الكلام. شخص يستمع إلى الكلمات ، ونتيجة لذلك ، يتم تنشيط الخلايا العصبية في قشرة السمع. يتم تفسير البيانات بأربع طرق: من خلال الجمع بين نوعين من نماذج الانحدار ونوعين من تمثيل الكلام ، ثم يدخلون إلى نظام الشبكة العصبية لاستخراج الميزات التي يتم استخدامها لاحقًا لتكوين معلمات مشفر الصوتكان مهندسو الأعصاب في جامعة كولومبيا (الولايات المتحدة الأمريكية) أول من قام
بإنشاء نظام يقوم بترجمة الأفكار الإنسانية إلى خطاب يمكن فهمه ويمكن تمييزه ، إليك
التسجيل الصوتي للكلمات (mp3) التي تم تجميعها من خلال نشاط الدماغ.
من خلال مراقبة النشاط في القشرة السمعية ، يستعيد النظام الكلمات التي يسمعها الشخص بوضوح غير مسبوق. بالطبع ، ليس هذا هو سجل الأفكار بالمعنى الحرفي للكلمة ، ولكن تم اتخاذ خطوة مهمة في هذا الاتجاه. في الواقع ، توجد أنماط مماثلة من نشاط الدماغ في القشرة الدماغية عندما يتخيل الشخص أنه يستمع إلى الكلام ، أو عندما يتحدث عقلياً الكلمات.
هذا التقدم العلمي باستخدام تقنيات الذكاء الاصطناعي يجعلنا أقرب إلى إنشاء واجهات عصبية فعالة تربط الكمبيوتر مباشرة بالدماغ. كما سيساعد الأشخاص الذين لا يستطيعون التحدث وأولئك الذين يتعافون من السكتة الدماغية أو لسبب آخر غير قادرين بشكل مؤقت أو دائم على التحدث بالكلمات للتواصل.
لقد أثبتت عقود من البحث أن أنماط التحكم في النشاط تظهر في المخ أثناء عملية التحدث أو حتى الكلام العقلي. بالإضافة إلى ذلك ، ينشأ نمط إشارة متميز (ويمكن التعرف عليه) عندما نستمع إلى شخص ما أو نتخيل أننا نستمع. يحاول الخبراء منذ فترة طويلة تسجيل هذه الأنماط وفك تشفيرها من أجل "تحرير" أفكار الشخص من الجمجمة - وترجمتها تلقائيًا إلى شكل شفهي.
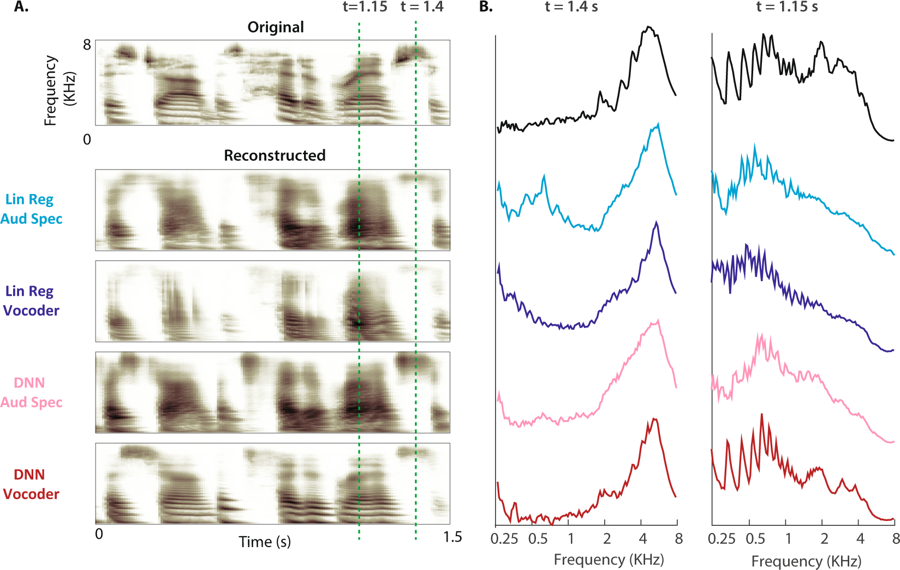 (أ) يظهر الطيفية الأصلية لعينة الكلام أعلاه. وترد أدناه الطيفية السمعية أعيد بناؤها من النماذج الأربعة أدناه. (ب) قدرة شدة نطاقات التردد أثناء عدم التنبيه (t = 1.4 s) والكلام الصوتي (t = 1.15 s: تظهر الفجوة بخطوط متقطعة من أجل المخطط الطيفي الأصلي لأربع عمليات إعادة بناء)
(أ) يظهر الطيفية الأصلية لعينة الكلام أعلاه. وترد أدناه الطيفية السمعية أعيد بناؤها من النماذج الأربعة أدناه. (ب) قدرة شدة نطاقات التردد أثناء عدم التنبيه (t = 1.4 s) والكلام الصوتي (t = 1.15 s: تظهر الفجوة بخطوط متقطعة من أجل المخطط الطيفي الأصلي لأربع عمليات إعادة بناء)"هذه هي نفس التكنولوجيا التي يستخدمها Amazon Echo و Apple Siri للإجابة شفهياً على أسئلتنا" ،
توضح الدكتورة نعمة Mesgarani ، المؤلفة الرئيسية للصحيفة. لتعليم المشفر الصوتي لتفسير نشاط الدماغ ، وجد الخبراء خمسة مرضى يعانون من الصرع الذين خضعوا بالفعل لجراحة في المخ. طُلب منهم الاستماع إلى الجمل التي صدرت عن أشخاص مختلفين ، في حين قاس الأقطاب نشاط الدماغ ، والذي تمت معالجته بواسطة أربعة نماذج. هذه الأنماط العصبية تدرس مشفر صوتي. ثم طلب الباحثون من نفس المرضى الاستماع إلى كيفية نطق المتحدثين للأرقام من 0 إلى 9 ، بتسجيل إشارات المخ التي يمكن تمريرها عبر مشفر الصوت. يتم تحليل الصوت الناتج من مشفر الصوت استجابة لهذه الإشارات ومسحها من قبل العديد من الشبكات العصبية.
نتيجة للمعالجة عند إخراج الشبكة العصبية ، تم استلام صوت روبوت ، مما يدل على سلسلة من الأرقام. لاختبار دقة التعرف ، تم إعطاء الناس للاستماع إلى الأصوات التي تم تجميعها من خلال نشاط الدماغ الخاص بهم: "لقد وجدنا أنه يمكن للناس فهم وتكرار الأصوات في 75 ٪ من الحالات ، وهي نسبة أعلى بكثير وتتجاوز أي محاولات سابقة" ، قال الدكتور مسغاراني.
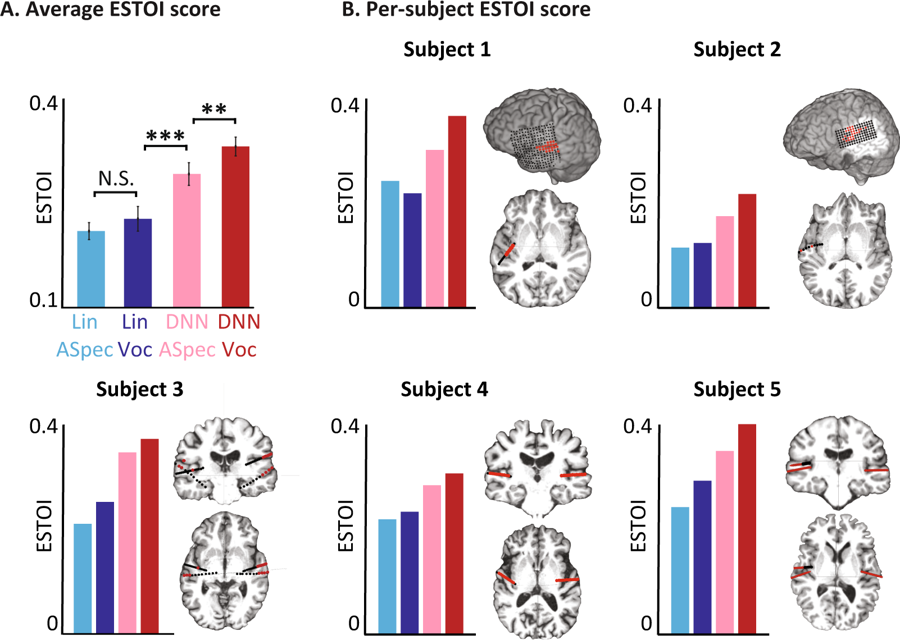 التصنيفات الموضوعية لنماذج مختلفة. (أ) متوسط النتيجة ESTOI لجميع المواد للنماذج الأربعة. ب) تغطية وموقع الأقطاب والنتيجة ESTOI لكل من الأشخاص الخمسة. كل شخص لديه أعلى درجة ESTOI لمشفر صوت DNN من النماذج الأخرى.
التصنيفات الموضوعية لنماذج مختلفة. (أ) متوسط النتيجة ESTOI لجميع المواد للنماذج الأربعة. ب) تغطية وموقع الأقطاب والنتيجة ESTOI لكل من الأشخاص الخمسة. كل شخص لديه أعلى درجة ESTOI لمشفر صوت DNN من النماذج الأخرى.يخطط العلماء الآن لتكرار التجربة بكلمات وجمل أكثر تعقيدًا. بالإضافة إلى ذلك ، سيتم إجراء نفس الاختبارات لإشارات الدماغ عندما يتخيل الشخص ما يقوله. في النهاية ، يأملون في أن يصبح النظام جزءًا من عملية الزرع ، الأمر الذي يترجم أفكار مرتديها مباشرة إلى كلمات.
تم
نشر المقال العلمي في 29 يناير 2019 في المجال العام في مجلة
Scientific Reports (doi: 10.1038 / s41598-018-37359-z).
لقد تم
إتاحة كود البرنامج لإجراء التحليل الصوتي ، وحساب السعات عالية التردد وإعادة بناء الطيف السمعي
للجمهور .