الدخول
في هذه المقالة سأتحدث عن خوارزمية هوفمان المعروفة ، وكذلك تطبيقها في ضغط البيانات.
نتيجة لذلك ، سنكتب أرشيفي بسيط. كان هناك بالفعل
مقال حول هذا الموضوع عن حبري ، لكن دون تطبيق عملي. إن المادة النظرية للوظيفة الحالية مأخوذة من دروس علوم الكمبيوتر بالمدرسة وكتاب روبرت لافور "هياكل البيانات والخوارزميات في جافا". لذلك ، كل شيء تحت الخفض!
القليل من التفكير
في ملف نص عادي ، يتم ترميز حرف واحد بثمانية بتات (ترميز ASCII) أو 16 (ترميز Unicode). كذلك سننظر في ترميز ASCII. على سبيل المثال ، خذ السطر s1 = "SUSIE تقول إنه أمر سهل \ n". في المجموع ، هناك 22 حرفًا في السطر ، بالطبع ، بما في ذلك المسافات وحرف السطر الجديد - '\ n'. سيزن الملف الذي يحتوي على هذا الخط 22 * 8 = 176 بت. السؤال الذي يطرح نفسه على الفور: هل من المنطقي استخدام كل 8 بت لتشفير حرف واحد؟ نحن لا نستخدم جميع أحرف ASCII. حتى لو تم استخدامها ، فسيكون من المنطقي بالنسبة للحرف الأكثر تكرارا - S - إعطاء أقصر رمز ممكن ، ولأحرف الحرف - T (أو U ، أو \ \ ') - لإعطاء رمز أكثر أصالة. هذه هي خوارزمية هوفمان: تحتاج إلى العثور على أفضل خيار ترميز ، حيث سيكون الملف أقل وزنًا. من الطبيعي تمامًا أن تختلف أطوال الشفرات لأحرف مختلفة - وهذا هو أساس الخوارزمية.
الترميز
لماذا لا تمنح الحرف "S" رمزًا ، على سبيل المثال ، طوله 1 بت: 0 أو 1. فليكن 1. ثم سنمنح ثاني أكثر الأحرف التي تمت مواجهتها - "(فضاء) - 0. تخيل أنك بدأت في فك تشفير رسالتك - السلسلة المشفرة s1 - وترى أن الكود يبدأ بـ 1. فما العمل: هل هو حرف S ، أم هو شخصية أخرى ، على سبيل المثال A؟ لذلك ، تنشأ قاعدة مهمة:
لا ينبغي أن يكون رمز البادئة من آخرهذه القاعدة هي المفتاح في الخوارزمية. لذلك ، يبدأ إنشاء الشفرة بجدول التردد ، الذي يشير إلى التردد (عدد مرات الحدوث) لكل حرف:
يجب تشفير الأحرف التي تحتوي على أكبر عدد من الأحداث مع أصغر عدد
ممكن من وحدات البت. سأقدم مثالًا على أحد جداول التعليمات البرمجية الممكنة:
وبالتالي ، ستبدو الرسالة المشفرة كما يلي:
10 01111 10 110 1111 00 10 010 1110 10 00 110 0110 00 110 10 00 1111 010 10 1110 01110
فصلت رمز كل حرف بمسافة. هذا لن يحدث بالفعل في ملف مضغوط!
السؤال الذي يطرح نفسه:
كيف أتت هذه الملحمة برمز ؟ كيف تنشئ جدول أكواد؟ هذا سوف يناقش أدناه.
بناء شجرة هوفمان
هنا أشجار البحث الثنائية تأتي لإنقاذ. لا تقلق ، فهناك طرق البحث والإدخال والحذف غير مطلوبة. هنا هو هيكل شجرة في جافا:
public class Node { private int frequence; private char letter; private Node leftChild; private Node rightChild; ... }
class BinaryTree { private Node root; public BinaryTree() { root = new Node(); } public BinaryTree(Node root) { this.root = root; } ... }
هذا ليس رمزًا كاملاً ، والكود الكامل سيكون أدناه.
هنا خوارزمية بناء الشجرة نفسها:
- إنشاء كائن عقدة لكل حرف من الرسالة (السطر s1). في حالتنا ، سيكون هناك 9 عقد (كائنات عقدة). تتكون كل عقدة من حقلين للبيانات: الرمز والتردد
- إنشاء كائن شجرة (BinaryTree) لكل من عقده العقد. تصبح العقدة جذر الشجرة.
- الصق هذه الأشجار في قائمة الانتظار ذات الأولوية. كلما كان التردد أقل ، كلما زادت الأولوية. وبالتالي ، عند الاستخراج ، يتم تحديد dervo دائمًا بأقل تردد.
بعد ذلك ، عليك القيام بما يلي دوريًا:
- استخرج شجرتين من قائمة انتظار الأولوية واجعلهما من نسل العقدة الجديدة (العقدة التي تم إنشاؤها حديثًا بدون خطاب). تردد العقدة الجديدة يساوي مجموع ترددات شجرتين متحدرين.
- لهذه العقدة ، قم بإنشاء شجرة ذات جذر في هذه العقدة. الصق هذه الشجرة مرة أخرى في قائمة انتظار الأولوية. (نظرًا لأن الشجرة لها تردد جديد ، فمن المرجح أن تصل إلى مكان جديد في قائمة الانتظار)
- تابع الخطوتين 1 و 2 حتى تبقى شجرة واحدة فقط في قائمة الانتظار - شجرة هوفمان
النظر في هذه الخوارزمية على الخط s1:

هنا ، يشير الرمز "lf" (linefeed) إلى الانتقال إلى سطر جديد ، "sp" (مسافة) هي مسافة.
ما التالي؟
لقد حصلنا على شجرة هوفمان. حسنا حسنا. وماذا تفعل به؟
لن يأخذوها مجانًا ، وبعد ذلك ، يتعين عليك تتبع جميع المسارات الممكنة من الجذر إلى أوراق الشجرة. دعنا نوافق على تعيين الحافة 0 إذا كانت تؤدي إلى السليل الأيسر و 1 إذا إلى الحافة اليمنى. بالمعنى الدقيق للكلمة ، في هذه الرموز ، رمز الرمز هو المسار من جذر الشجرة إلى الورقة التي تحتوي على هذا الرمز نفسه.
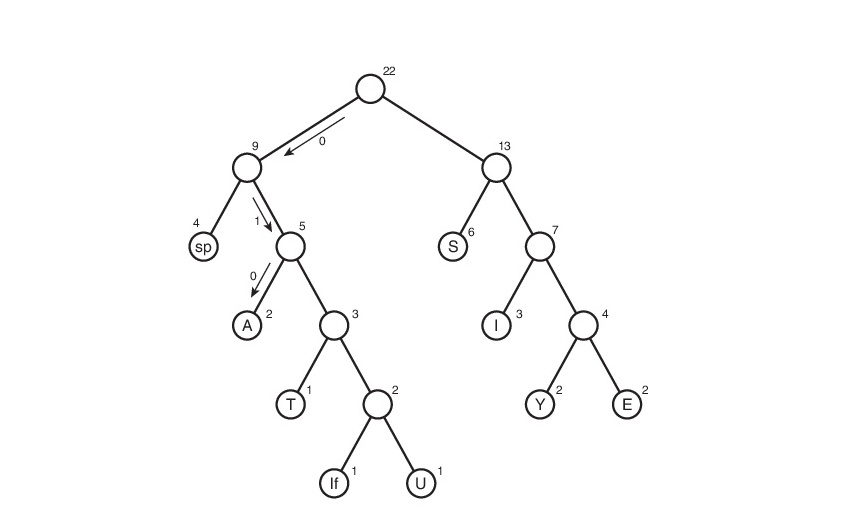
وبالتالي ، تحول جدول الرموز. لاحظ أنه إذا أخذنا في الاعتبار هذا الجدول ، يمكننا أن نستنتج حول "وزن" كل حرف - هذا هو طول الكود الخاص به. ثم يزن الملف المضغوط: 2 * 3 + 2 * 4 + 3 * 3 + 6 * 2 + 1 * 4 + 1 * 5 + 2 * 4 + 4 * 2 + 1 * 5 = 65 بت. في البداية ، كان وزنه 176 بت. لذلك ، قمنا بتخفيضه بقدر 176/65 = 2.7 مرة! ولكن هذا هو اليوتوبيا. من غير المرجح الحصول على مثل هذا المعامل. لماذا؟ وسيتم مناقشة هذا في وقت لاحق قليلا.
فك التشفير
حسنًا ، ربما يكون أبسط شيء هو فك التشفير. أعتقد أن الكثير منكم خمن أنه من المستحيل إنشاء ملف مضغوط ببساطة دون أي إشارة إلى كيفية تشفيره - لن نتمكن من فك تشفيره! نعم ، كان من الصعب علي أن أدرك ذلك ، لكن كان عليّ إنشاء ملف نصي table.txt مع جدول ضغط:
01110 00 A010 E1111 I110 S10 T0110 U01111 Y1110
سجل الجدول في شكل "حرف" "رمز الحرف". لماذا 01110 بدون شخصية؟ في الواقع ، يكون ذلك برمز ، فقط أدوات java التي استخدمها عند الإخراج إلى ملف ، يتم تحويل حرف السطر الجديد - '\ n' - إلى سطر جديد (بغض النظر عن مدى غباءه). لذلك ، السطر الفارغ أعلاه هو رمز الكود 01110. بالنسبة للرمز 00 ، فإن الحرف هو مسافة في بداية السطر. يجب أن أقول على الفور أن طريقة تخزين هذا الجدول لدينا قد تدعي أنها غير عقلانية. لكنها بسيطة لفهم وتنفيذ. يسرني أن أسمع توصياتكم في التعليقات المتعلقة بالتحسين.
من السهل جدًا فك شفرة هذا الجدول. تذكر القاعدة التي كنا نسترشد بها عند إنشاء الترميز:
يجب أن لا يوجد كود بادئة أخرىهذا هو المكان الذي تلعب فيه دور تسهيل. لقد قرأنا شيئًا فشيئًا بشكل متتابع ، وبمجرد أن تتطابق السلسلة المستلمة d ، التي تتكون من وحدات بت للقراءة ، مع الترميز المطابق لحرف الحرف ، نعرف على الفور أن حرف الحرف كان مشفرًا (وفقط!). بعد ذلك ، نكتب حرفًا في سطر فك التشفير (السطر الذي يحتوي على الرسالة التي تم فك شفرتها) ، ونصف السطر d ، ثم نقرأ الملف المشفر.
التنفيذ
حان الوقت
لإذلال الكود الخاص بي عن طريق كتابة أرشيف. دعنا نسميها ضاغط.
لنبدأ من البداية. أولاً ، نكتب فئة العقدة:
public class Node { private int frequence;
الآن الشجرة:
class BinaryTree { private Node root; public BinaryTree() { root = new Node(); } public BinaryTree(Node root) { this.root = root; } public int getFrequence() { return root.getFrequence(); } public Node getRoot() { return root; } }
قائمة انتظار الأولوية:
import java.util.ArrayList;
الفئة التي تنشئ شجرة هوفمان:
public class HuffmanTree { private final byte ENCODING_TABLE_SIZE = 127;
الفئة التي تحتوي على الترميز / فك التشفير:
public class HuffmanOperator { private final byte ENCODING_TABLE_SIZE = 127;
الفصل الذي يسهل الكتابة إلى ملف:
import java.io.File; import java.io.PrintWriter; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.Closeable; public class FileOutputHelper implements Closeable { private File outputFile; private FileOutputStream fileOutputStream; public FileOutputHelper(File file) throws FileNotFoundException { outputFile = file; fileOutputStream = new FileOutputStream(outputFile); } public void writeByte(byte msg) throws IOException { fileOutputStream.write(msg); } public void writeBytes(byte[] msg) throws IOException { fileOutputStream.write(msg); } public void writeString(String msg) { try (PrintWriter pw = new PrintWriter(outputFile)) { pw.write(msg); } catch (FileNotFoundException e) { System.out.println(" , !"); } } @Override public void close() throws IOException { fileOutputStream.close(); } public void finalize() throws IOException { close(); } }
الفصل الذي يسهل القراءة من ملف:
import java.io.FileInputStream; import java.io.EOFException; import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.Closeable; import java.io.File; import java.io.IOException; public class FileInputHelper implements Closeable { private FileInputStream fileInputStream; private BufferedReader fileBufferedReader; public FileInputHelper(File file) throws IOException { fileInputStream = new FileInputStream(file); fileBufferedReader = new BufferedReader(new InputStreamReader(fileInputStream)); } public byte readByte() throws IOException { int cur = fileInputStream.read(); if (cur == -1)
حسنا ، والفئة الرئيسية:
import java.io.File; import java.nio.charset.MalformedInputException; import java.io.FileNotFoundException; import java.io.IOException; import java.nio.file.Files; import java.nio.file.NoSuchFileException; import java.nio.file.Paths; import java.util.List; import java.io.EOFException; public class Main { private static final byte ENCODING_TABLE_SIZE = 127; public static void main(String[] args) throws IOException { try {
ملف التعليمات readme.txt متروك لك لكتابة نفسك :-)
الخاتمة
ربما هذا هو كل ما أردت قوله. إذا كان لديك ما تقوله حول
عدم كفاءة التحسينات في الشفرة والخوارزمية وأي تحسين بشكل عام ، فلا تتردد في الكتابة. إذا أسأت فهم شيء ما ، فاكتب أيضًا. سأكون سعيداً أن أسمع منك في التعليقات!
PS
نعم ، نعم ، ما زلت هنا ، لأنني لم أنس معاملته. بالنسبة للسلسلة s1 ، يزن جدول الترميز 48 بايت - أكثر بكثير من الملف الأصلي ، ولم ينسوا أي أصفار إضافية (عدد الأصفار المضافة 7) => ستكون نسبة الضغط أقل من واحدة: 176 / (65 + 48 * 8 + 7) = 0.38. إذا لاحظت هذا أيضًا ، فأنت
لست جيدًا
في وجهك . نعم ، سيكون هذا التطبيق غير فعال للغاية بالنسبة للملفات الصغيرة. ولكن ماذا يحدث للملفات الكبيرة؟ تتجاوز أحجام الملفات حجم جدول الترميز. هنا الخوارزمية تعمل كما ينبغي! على سبيل المثال ، بالنسبة إلى
المونولوج Faust ، يعطي أرشيف الأرشيف معاملًا حقيقيًا (غير مثالي) يساوي 1.46 - مرة واحدة ونصف تقريبًا! ونعم ، كان من المفترض أن يكون الملف باللغة الإنجليزية.