في هذه المقالة ، أود أن أتحدث عن الطريقة التي أنشأنا بها نظام البحث عن الملابس المشابهة (الملابس والأكياس والحقائب بشكل أكثر دقة) من الصور الفوتوغرافية. هذا هو ، من حيث الأعمال ، خدمة توصية تعتمد على الشبكات العصبية.
مثل معظم حلول تقنية المعلومات الحديثة ، يمكننا مقارنة تطوير نظامنا بتجميع مُنشئ Lego ، عندما نأخذ الكثير من التفاصيل الصغيرة والتعليمات وننشئ نموذجًا جاهزًا من هذا. في ما يلي هذه التعليمات: ما هي التفاصيل التي يجب اتخاذها وكيفية تطبيقها حتى تتمكن وحدة معالجة الرسومات الخاصة بك من تحديد منتجات مماثلة من صورة ، ستجدها في هذه المقالة.
ما الأجزاء التي يتكون منها نظامنا:
- كاشف وتصنيف الملابس والأحذية والحقائب على الصور ؛
- الزاحف أو المفهرس أو الوحدة النمطية للعمل مع الكتالوجات الإلكترونية للمخازن ؛
- وحدة بحث الصور المتشابهة ؛
- JSON-API للتفاعل المريح مع أي جهاز وخدمة ؛
- واجهة الويب أو تطبيق الهاتف المحمول لعرض النتائج.
في نهاية المقال ، سنصف كل "المشطّات" التي خططنا فيها أثناء التطوير والتوصيات حول كيفية تحييدها.
بيان المشكلة وإنشاء أداة الدهن
تبدو المهمة وحالة الاستخدام الرئيسية للنظام بسيطة وواضحة للغاية:
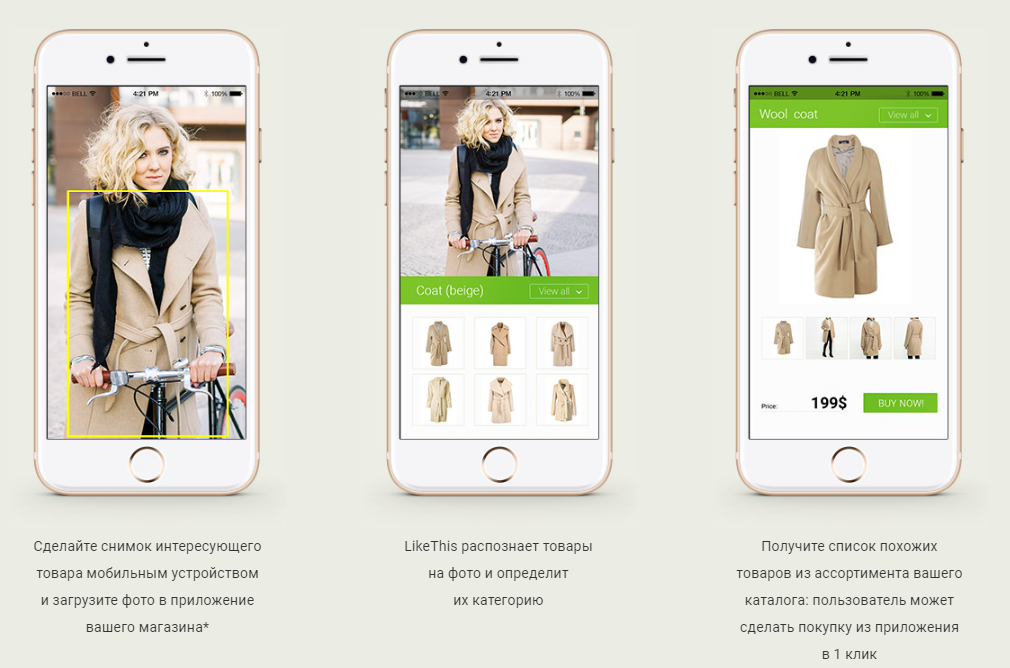
- يقدم المستخدم إلى المدخل (على سبيل المثال ، من خلال تطبيق الهاتف المحمول) صورة فيها مواد من الملابس و / أو الحقائب و / أو الأحذية ؛
- يحدد النظام (يكتشف) كل هذه الأشياء ؛
- يجد لكل منهم أكثر المنتجات المماثلة (ذات الصلة) في المتاجر الحقيقية على الإنترنت ؛
- يمنح منتجات المستخدم القدرة على الانتقال إلى صفحة منتج معين للشراء.
ببساطة ، إن هدف نظامنا هو الإجابة على السؤال الشهير: "وليس لديك نفس الشيء ، فقط باستخدام أزرار أم اللؤلؤ؟"
قبل الاندفاع إلى مجموعة الترميز والتمييز والتدريب للشبكات العصبية ، تحتاج إلى تحديد الفئات التي ستكون داخل نظامك بشكل واضح ، أي تلك الفئات التي ستكتشفها الشبكة العصبية. من المهم أن نفهم أنه كلما كانت قائمة الفئات أوسع وأكثر تفصيلاً ، كلما كانت أكثر شمولية ، نظرًا لأنه يمكن دائمًا دمج عدد كبير من الفئات الصغيرة الضيقة مثل الفستان المصغر ، الفستان القصير ، الفستان القصير بلمسة واحدة في فئة واحدة من الفستان ولكن ليس العكس. بمعنى آخر ، يجب أن يتم تفكيك وتجميع أداة التصنيف في بداية المشروع ، حتى لا تتم إعادة العمل نفسه بعد ثلاث مرات. قمنا بتجميع أداة الدهن ، مع الأخذ كأساس للعديد من المتاجر الكبرى ، مثل Lamoda.ru و Amazon.com ، وحاولنا جعلها واسعة قدر الإمكان من جهة ، وبأكثر تنوع ممكن ، من ناحية أخرى ، لتسهيل ربط فئات الكاشف بفئات مختلفة المتاجر عبر الإنترنت (سأخبرك المزيد حول كيفية إنشاء هذه المجموعة في قسم الزاحف والفهرس). هنا مثال على ما حدث.
 فئات المثال
فئات المثاليضم الكتالوج الخاص بنا حاليًا 205 فئات فقط: ملابس نسائية ، ملابس رجالية ، أحذية نسائية ، أحذية رجالية ، حقائب ، ملابس للمواليد الجدد. النسخة الكاملة من مصنف لدينا متاح
في الرابط .
مفهرس أو وحدة للعمل مع كتالوجات إلكترونية من المتاجر
من أجل البحث عن منتجات مماثلة في المستقبل ، نحتاج إلى إنشاء قاعدة شاملة لما نبحث عنه. في تجربتنا ، تعتمد جودة البحث عن صور مشابهة بشكل مباشر على حجم قاعدة البحث ، التي يجب أن تتجاوز 100 كيلو بايت على الأقل ، ويفضل أن تكون الصور 1M. إذا قمت بإضافة 1-2 متجر صغير عبر الإنترنت إلى قاعدة البيانات ، فمن المرجح أنك لن تحصل على نتائج رائعة ببساطة لأنه في 80٪ من الحالات لا يوجد شيء مشابه فعليًا للعنصر المرغوب في الكتالوج الخاص بك.
لذلك ، لإنشاء قاعدة بيانات كبيرة من الصور تحتاج إلى معالجة النشرات المصورة لمختلف المتاجر عبر الإنترنت ، هذا ما تتضمنه هذه العملية:
- تحتاج أولاً إلى العثور على موجزات XML للمخازن عبر الإنترنت ، وعادةً ما يمكنك العثور عليها إما مجانًا على الإنترنت ، أو من خلال الطلب من المتجر نفسه ، أو في مجمعات مختلفة مثل Admitad ؛
- تتم معالجة (تحليل) الخلاصة بواسطة برنامج خاص - يقوم الزاحف ، الذي يقوم بتنزيل جميع الصور من الخلاصة ، بوضعها على القرص الصلب (وبشكل أكثر دقة ، على شبكة التخزين التي يتصل بها الخادم الخاص بك) ، يكتب جميع المعلومات الوصفية حول البضائع الموجودة في قاعدة البيانات ؛
- ثم يتم إطلاق عملية أخرى - المفهرس ، الذي يحسب متجهات الميزة الثنائية ثنائية الأبعاد لكل صورة. يمكنك الجمع بين الزاحف والمفهرس في وحدة نمطية واحدة أو برنامج واحد ، لكننا طورنا تاريخيا أن هذه كانت عمليات مختلفة. كان هذا بسبب حقيقة أننا في البداية قمنا بحساب الواصفات (التجزئة) لكل صورة موزعة على أسطول كبير من الآلات ، حيث كانت هذه عملية كثيفة الاستخدام للموارد. إذا كنت تعمل فقط مع الشبكات العصبية ، فهذا يعني أن الجهاز الأول المزود بوحدة معالجة الرسومات (GPU) يكفي لك ؛
- تتم كتابة المتجهات الثنائية في قاعدة البيانات ، ويتم الانتهاء من جميع العمليات وفويلا - قاعدة بيانات المنتج الخاص بك جاهزة لمزيد من البحث ؛
- ولكن لا تزال هناك خدعة واحدة: نظرًا لأن جميع المتاجر بها كتالوجات مختلفة مع فئات مختلفة بداخلها ، فأنت بحاجة إلى مقارنة فئات جميع الخلاصات المضمنة في قاعدة البيانات الخاصة بك مع فئات كاشف (أكثر دقة ، المصنف) للبضائع ، ونحن نسمي هذا عملية التعيين. هذا روتين يدوي ، لكنه عمل مفيد للغاية ، حيث يقوم المشغل ، الذي يقوم يدويًا بتحرير ملف XML عادي ، بمقارنة فئات الخلاصة في قاعدة البيانات مع فئات الكاشف. هذه هي النتيجة:
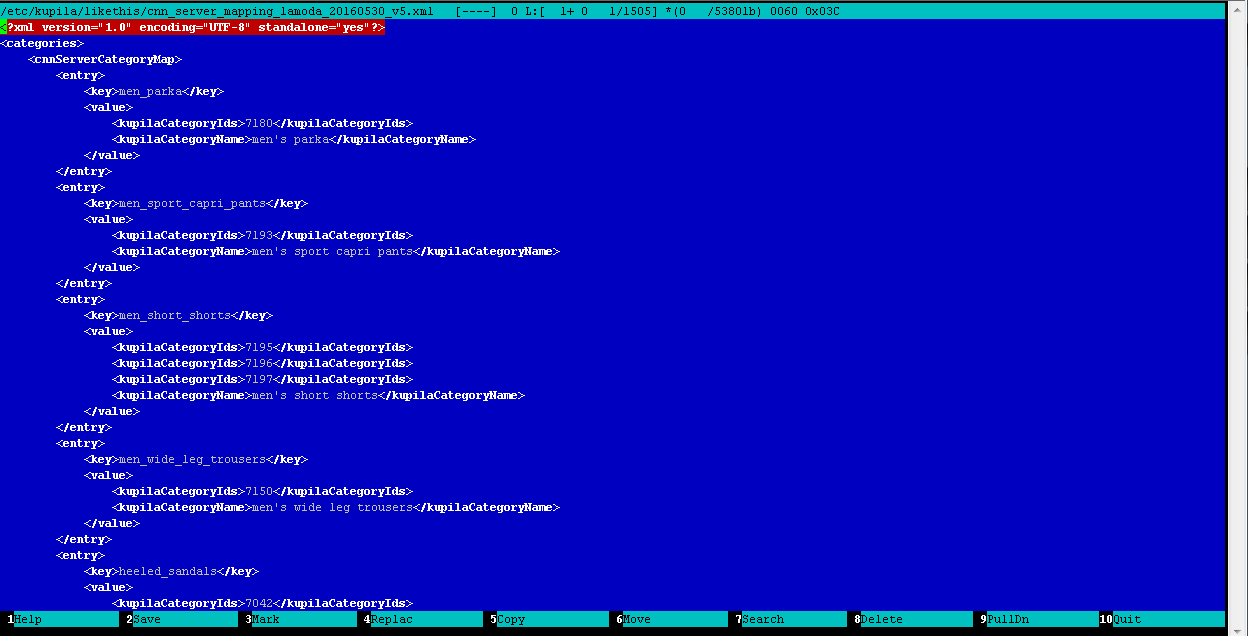 مثال لملف تعيين الفئة: مصنف الكتالوج
مثال لملف تعيين الفئة: مصنف الكتالوجكشف وتصنيف
من أجل العثور على شيء مشابه لما عثرت عليه عيننا في الصورة ، نحتاج إلى الكشف عن هذا "الشيء" أولاً (أي لتحديد الكائن وتحديده). لقد قطعنا شوطًا طويلًا في إنشاء كاشف ، بدءًا من تدريب مجموعات OpenCV التي لم تنجح على الإطلاق في هذه المهمة ، وتنتهي بالتكنولوجيا الحديثة لاكتشاف وتصنيف
R-FCN والمصنف على أساس شبكة
ResNet العصبية.
نظرًا لأن البيانات التي تم استخدامها للتدريب والاختبار (ما يسمى عينات التدريب والاختبار) ، فقد التقطنا جميع أنواع الصور من الإنترنت:
- البحث على صور جوجل / ياندكس.
- مجموعات البيانات المحددة من قِبل جهة خارجية ؛
- الشبكات الاجتماعية
- مواقع مجلة الأزياء.
- محلات الانترنت للملابس والأحذية والحقائب.
تم تنفيذ العلامات باستخدام أداة samopisny ، وكانت نتيجة الترميز عبارة عن مجموعات من الصور وملفات * .seg لهم ، والتي تخزن إحداثيات الكائنات وتسميات الفئات لهم. في المتوسط ، تم تصنيف 100 إلى 200 صورة لكل فئة ، وكان إجمالي عدد الصور في 205 فئة 65000 صورة.
بعد أن تكون عينات التدريب والاختبار جاهزة ، قمنا بفحص مزدوج للترميز ، مع إعطاء كل الصور لمشغل آخر. هذا سمح لنا بتصفية عدد كبير من الأخطاء التي تؤثر بشدة على جودة تدريب الشبكة العصبية ، أي الكاشف والمصنف. ثم نبدأ في تدريب الشبكة العصبية باستخدام الأدوات القياسية و "خلع" اللقطة التالية للشبكة العصبية "في حرارة اليوم" في غضون بضعة أيام. في المتوسط ، فإن مدة تدريب الكاشف والمصنف على حجم بيانات 65000 صورة على وحدة معالجة الرسومات Titan X تبلغ حوالي 3 أيام.
يجب التحقق من وجود شبكة عصبية جاهزة بطريقة أو بأخرى للتأكد من جودتها ، أي لتقييم ما إذا كان الإصدار الحالي من الشبكة أصبح أفضل من الإصدار السابق وبأي كمية. كيف فعلنا ذلك:
- تكونت عينة الاختبار من 12000 صورة وتم وضعها بنفس طريقة التدريب تمامًا ؛
- لقد كتبنا أداة صغيرة قامت بتشغيل عينة الاختبار بأكملها عبر الكاشف وقمت بتجميع جدول من هذا النوع (النسخة الكاملة من الجدول متاحة هنا ) ؛
- تتم إضافة هذا الجدول إلى Excel في علامة تبويب جديدة ومقارنته بالجدول السابق يدويًا أو باستخدام صيغ Excel المضمنة ؛
- عند الخرج ، نحصل على المؤشرات العامة للكشف عن TPR / FPR والمصنف في النظام بأكمله وفي كل فئة على حدة.
 مثال على جدول تقرير عن جودة كاشف المصنف
مثال على جدول تقرير عن جودة كاشف المصنفصور مماثلة وحدة البحث
بعد أن اكتشفنا عناصر خزانة الملابس في الصورة ، نبدأ تشغيل محرك البحث عن صور مماثلة ، وإليك كيفية عملها:
- بالنسبة لجميع أجزاء الصورة المقطوعة (السلع المكتشفة) ، يتم حساب متجهات المعالم الثنائية للشبكة العصبية 128 بت في الشكل واللون (من أين أتوا ، انظر أدناه) ؛
- يتم بالفعل تحميل نفس المتجهات التي تم حسابها مسبقًا في مرحلة الفهرسة لجميع صور البضائع المخزنة في قاعدة البيانات في ذاكرة الوصول العشوائي بالكمبيوتر (نظرًا للبحث عن تلك المشابهة ، سيكون من الضروري إجراء عدد كبير من عمليات البحث والمقارنات الزوجية ، قمنا بتحميل قاعدة البيانات بأكملها على الفور في الذاكرة ، مما سمح لنا بزيادة سرعة البحث هي عشرات المرات ، في حين أن قاعدة حوالي 100 ألف منتج لا تتعدى 2-3 غيغابايت من ذاكرة الوصول العشوائي) ؛
- تأتي معاملات البحث لهذه الفئة من الواجهة أو من الخصائص الثابتة ، على سبيل المثال ، في فئة "اللباس" ، نحن نبحث في اللون أكثر من الشكل (على سبيل المثال ، البحث من 8 إلى 2 لون) ، وفي فئة "الأحذية ذات الكعب العالي" 1 - 1 - لون الشكل لأن كل من الشكل واللون لا تقل أهمية هنا ؛
- علاوة على ذلك ، تتم مقارنة متجهات المحصول (الأجزاء) من صورة الإدخال في أزواج مع الصورة من قاعدة البيانات ، مع مراعاة المعاملات (تتم مقارنة مسافة هامينغ بين المتجهات) ؛
- نتيجةً لذلك ، يتم تشكيل مجموعة من المنتجات المماثلة من قاعدة البيانات لكل جزء منتج مقطوع ، ويتم تخصيص وزن لكل منتج (وفقًا لمعادلة بسيطة ، مع مراعاة التطبيع ، بحيث تكون جميع الأوزان في النطاق من 0 إلى 1) لإمكانية الإخراج إلى الواجهة ، وكذلك للحصول على مزيد من الفرز
- يتم عرض مجموعة من المنتجات المماثلة في الواجهة عبر الويب JSON-API.
يتم تدريب الشبكات العصبية لتشكيل ناقلات الشبكة العصبية في الشكل واللون على النحو التالي.
- لتدريب الشبكة العصبية في الشكل ، نلتقط جميع الصور المميزة ، ونقطع الشظايا وفقًا للترميز ونوزعها في مجلدات وفقًا للفئة: أي جميع السترات الصوفية في مجلد واحد ، وكل القمصان في مجلد آخر ، وجميع الأحذية ذات الكعب العالي في المجلد الثالث ، إلخ. د. بعد ذلك ، نقوم بتدريب مصنف عادي بناءً على هذه العينة. وبالتالي ، نحن نوع من "شرح" إلى الشبكة العصبية فهمنا لشكل الكائن.
- لتدريب الشبكة العصبية بالألوان ، نلتقط جميع الصور المميزة ، ونقطع الشظايا وفقًا للترميز ونوزعها في مجلدات وفقًا للون: أي وضع جميع القمصان والأحذية والحقائب وما إلى ذلك في المجلد "الأخضر". اللون الأخضر (نتيجة لذلك ، تتراكم أي كائنات ذات لون أخضر بشكل عام في مجلد واحد) ، في المجلد "الذي تم تجريده" نضع كل الأشياء في شريط ، وفي المجلد "الأحمر والأبيض" كل الأشياء ذات اللون الأحمر والأبيض. بعد ذلك ، نقوم بتدريب مصنف منفصل لهذه الفئات ، كما لو كان "يشرح" للشبكة العصبية فهمها للون شيء ما.
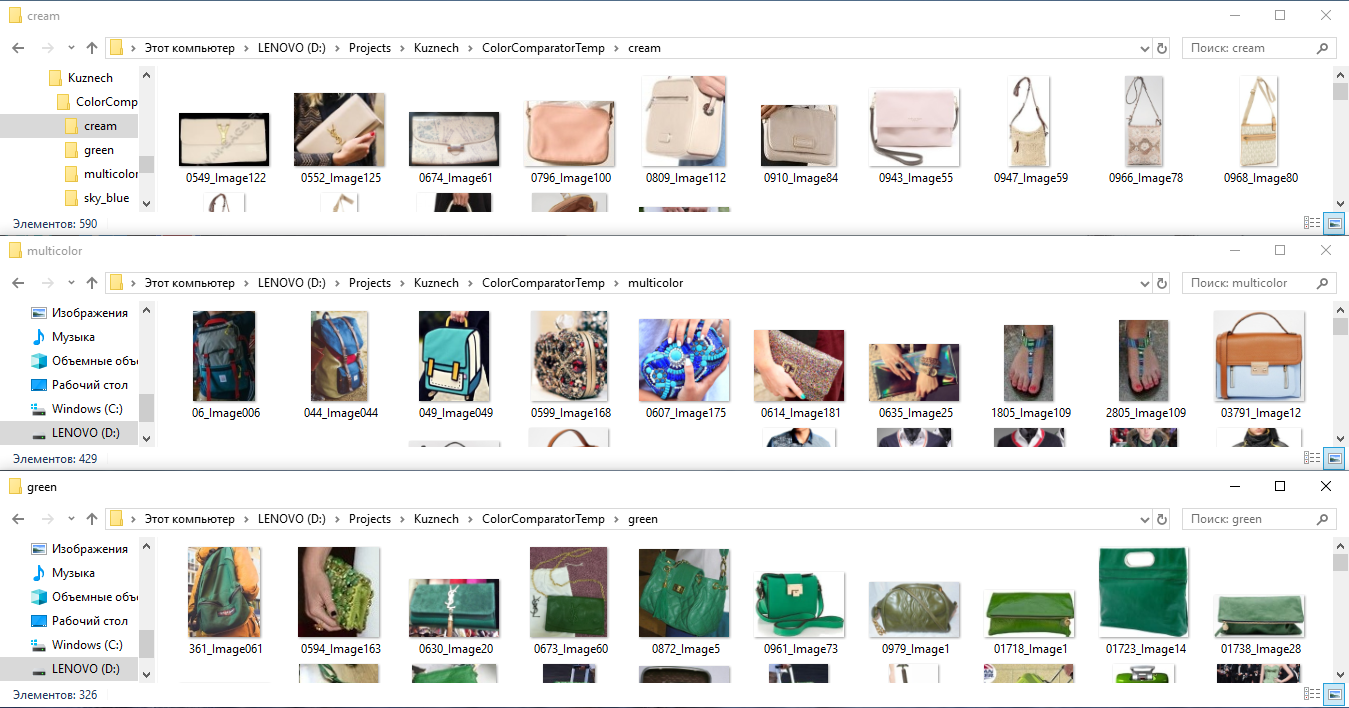 مثال على تمييز الصور حسب اللون للحصول على متجهات الشبكة العصبية للعلامات حسب اللون.
مثال على تمييز الصور حسب اللون للحصول على متجهات الشبكة العصبية للعلامات حسب اللون.ومن المثير للاهتمام ، أن مثل هذه التقنية تعمل بشكل جيد حتى على الخلفيات المعقدة ، أي عندما يتم قطع شظايا الأشياء ليس بشكل واضح على طول الخط (القناع) ، ولكن على طول إطار مستطيل ، وهو ما حددته العلامة.
يعتمد البحث عن المتشابهات على استخراج متجهات المعالم الثنائية من الشبكة العصبية بهذه الطريقة: يتم أخذ مخرجات الطبقة قبل الأخيرة وضغطها وتطبيعها وتثبيتها. في عملنا ، ضغطنا على ناقل 128 بت. يمكنك القيام بذلك بطريقة مختلفة بعض الشيء ، على سبيل المثال ، كما هو موضح في مقالة Yahoo مكتوب بعنوان "
التعلم العميق من رموز تجزئة ثنائية لاسترجاع الصورة السريعة " ، ولكن جوهر كل الخوارزميات هو نفسه - يتم البحث عن صور مشابهة للصورة من خلال مقارنة الخصائص التي تعمل الشبكة العصبية داخل الطبقات.
في البداية ، كتقنية للبحث عن صور مماثلة ، استخدمنا تجزئات أو واصفات للصورة تعتمد (بشكل أكثر دقة محسوبة) على خوارزميات رياضية معينة ، مثل عامل التشغيل Sobel (أو تجزئة الكنتور) ، أو خوارزمية SIFT (أو نقاط المفرد) ، أو تخطيط رسم بياني زوايا ، أو مقارنة عدد الزوايا في صورة . لقد نجحت هذه التقنية وأعطت بعض النتائج المعقولة إلى حد ما ، لكن التجزئات لا تتطابق مع أي تقنية مقارنة بالبحث عن صور مماثلة استنادًا إلى الخصائص التي تخصصها شبكة عصبية. إذا حاولت توضيح الفرق في كلمتين ، فإن خوارزمية مقارنة الصور القائمة على التجزئة هي "آلة حاسبة" تم تكوينها لمقارنة الصور باستخدام بعض الصيغة وتعمل بشكل مستمر. المقارنة باستخدام ميزات من شبكة عصبية هي "ذكاء اصطناعي" ، يتم تدريبه من قبل شخص لحل مشكلة معينة بطريقة معينة. يمكنك إعطاء مثال قذر: إذا كنت تبحث عن كنزات تجزئة باللونين الأبيض والأسود ، فمن المرجح أن تجد كل الأشياء بالأبيض والأسود كأشياء مماثلة. وإذا قمت بالبحث باستخدام شبكة عصبية ، فقم بما يلي:
- في الأماكن الأولى سوف تجد جميع السترات ذات الخطوط السوداء والبيضاء ،
- ثم كل البلوزات بالأبيض والأسود
- ثم كل السترات المخططة.
JSON-API للتفاعل المريح مع أي جهاز وخدمة
لقد أنشأنا WEB-JSON-API بسيطة ومناسبة لتوصيل نظامنا بأي أجهزة وأنظمة ، والتي ، بالطبع ، ليست أي ابتكار ، بل هي معيار تطوير قوي جيد.
واجهة الويب أو تطبيقات الهاتف المحمول لعرض النتائج
للتحقق بصريًا من النتائج ، وكذلك لإظهار النظام للعملاء ، قمنا بتطوير واجهات بسيطة:
الأخطاء التي ارتكبت في المشروع
- في البداية ، من الضروري تحديد المهمة بشكل أكثر وضوحًا ، وبناءً على المهمة ، يتم تحديد صور فوتوغرافية للتخطيط. إذا كنت بحاجة إلى البحث عن صور UGC (المحتوى الذي ينشئه المستخدم) - فهذه حالة واحدة وأمثلة للتخطيط. إذا كنت بحاجة إلى البحث عن الصور من المجلات اللامعة ، فهذه حالة مختلفة ، وإذا كنت بحاجة إلى البحث عن الصور حيث يوجد كائن واحد كبير على خلفية بيضاء ، فهذه قصة منفصلة وعينة مختلفة تمامًا. لقد خلطنا كل ذلك في كومة واحدة ، مما أثر على جودة كاشف المصنف.
- في الصور الفوتوغرافية ، يجب عليك دائمًا وضع علامة على جميع الكائنات ، على الأقل من حقيقة أنه على الأقل يناسب مهمتك بطريقة ما ، على سبيل المثال ، عند اختيار مجموعة خزانة ملابس مماثلة ، كان عليك تحديد جميع الملحقات على الفور (الخرز ، النظارات ، الأساور ، إلخ) ، الرأس القبعات ، الخ لأن لدينا الآن مجموعة تدريب ضخمة ، من أجل إضافة فئة أخرى نحتاج إلى إعادة توزيع جميع الصور ، وهذا عمل ضخم للغاية.
- من الأفضل القيام بالاكتشاف من خلال شبكة الأقنعة ، والانتقال إلى Mask-CNN والحل الحديث القائم على Detectron هو أحد مجالات تطوير النظام.
- سيكون من الجيد أن تقرر على الفور كيف ستحدد جودة اختيار الصور المتشابهة - هناك طريقتان: "عن طريق العين" وهذه هي الطريقة الأبسط والأرخص والطريقة الثانية - "العلمية" ، عندما تقوم بجمع البيانات من "الخبراء" (الأشخاص ، الذي أختبره خوارزمية البحث المماثلة الخاصة بك) وبناءً على هذه البيانات ، قم بتكوين عينة اختبار وكتالوج مخصصًا للبحث عن صور مماثلة. هذه الطريقة جيدة من الناحية النظرية وتبدو مقنعة إلى حد ما (لنفسك وللعملاء) ، ولكن في الممارسة العملية ، يعد تنفيذها صعبًا ومكلفًا للغاية.
الخلاصة وخطط التطوير الأخرى
هذه التكنولوجيا جاهزة تمامًا ومناسبة للاستخدام ، وتعمل الآن في أحد عملائنا في المتجر عبر الإنترنت كخدمة توصية. أيضًا ، في الآونة الأخيرة ، شرعنا في تطوير نظام مماثل في صناعة أخرى (أي أننا نعمل الآن مع أنواع أخرى من السلع).
من الخطط الفورية: نقل الشبكة إلى Mask-CNN ، وكذلك إعادة تمييز الصور ووضع علامات عليها لتحسين جودة كاشف المصنف.
في الختام ، أود أن أقول إنه وفقًا لمشاعرنا ، فإن مثل هذه التكنولوجيا والشبكات العصبية العامة قادرة على حل ما يصل إلى 80٪ من المهام المعقدة والفكرية للغاية التي يجتمع بها دماغنا يوميًا. والسؤال الوحيد هو من هو أول من قام بتنفيذ مثل هذه التقنية وتفريغ شخص من العمل الروتيني ، مما أتاح له مساحة للإبداع والتنمية ، وهو في رأينا الهدف الأعلى للإنسان!
المراجع