
يوم جيد.
في الممارسة العملية ، غالبًا ما تواجه مهام بعيدة عن خوارزميات ML المعقدة ، ولكن في نفس الوقت لا تقل أهمية وإلحاحًا عن العمل.
دعونا نتحدث عن واحد منهم.
تتلخص المهمة في توزيع (النشر ، rasplitovat - المصطلح العملي للشركة لا ينضب) بيانات بعض الجدول المستهدف مع تجميعات (القيم الإجمالية) على جدول أكثر تفصيلاً.
على سبيل المثال ، تحتاج الإدارة التجارية إلى تفصيل الخطة السنوية المتفق عليها على مستوى العلامة التجارية - بالتفصيل للمنتجات ، لكي يقوم المسوقون بتوزيع ميزانية التسويق السنوية حسب البلد ، وإدارة التخطيط والاقتصاد لتحليل نفقات الأعمال العامة من قبل مراكز المسؤولية المالية ، إلخ. الخ
إذا كنت تشعر أن مثل هذه المهام تلوح في الأفق بالفعل أمامك في الأفق أو تعامل بالفعل أولئك الذين عانوا من هذه المهام ، فعندئذ أطلب قطة.
النظر في مثال حقيقي:
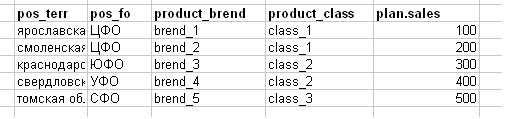
إنهم يخفضون خطة المبيعات كمهمة كما في الصورة أدناه (لقد قمت بتعمد جعل المثال مبسطًا ، في الواقع - لافتة إكسل 100-200 ميغابايت).
شرح العنوان:
- pos_terr-region (region) للمخرج
- pos_fo - المقاطعة الفيدرالية للمخرج (على سبيل المثال ، المقاطعة الفيدرالية المركزية - المقاطعة الفيدرالية الوسطى)
- product_brend - ماركة المنتج
- product_class - فئة المنتج
- plan.sales هي خطة مبيعات لأي شيء.
ويطلبون ، على سبيل المثال ، كسر طاولتهم الضخمة (في إطار مثال أطفالنا ، إنه بالطبع أكثر تواضعا) - لقناة المبيعات. بالنسبة للسؤال - وفقًا للمنطق الذي يجب تفصيله ، أحصل على الإجابة: "لكن أحصل على إحصاءات المبيعات الفعلية للربع الرابع من هذا العام ومثل هذه السنة ، احصل على المشاركات الفعلية من القنوات بنسبة٪ لكل سطر من الخطة وقسمها على هذه الأجزاء من خط الخطة".
في الواقع ، هذا هو الجواب الأكثر شيوعا في مثل هذه المهام ...
حتى الآن ، يبدو أن كل شيء بسيط بما فيه الكفاية.
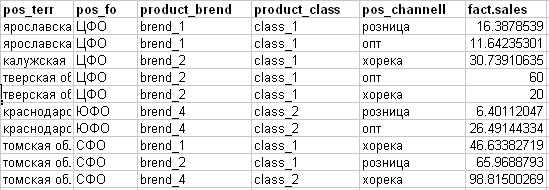
أحصل على هذه الحقيقة (انظر الصورة أدناه):
- pos_channell - قناة المبيعات (السمة المستهدفة للخطة)
- fact.sales - المبيعات الفعلية لشيء ما.
استنادًا إلى النهج الذي تم الحصول عليه في "النشر" على مثال السطر الأول من الخطة ، سنقوم بتقسيمه على أساس حقيقة مثل هذا:

ومع ذلك ، إذا قارنا الحقيقة بخطة اللوحة بأكملها من أجل فهم ما إذا كان من الممكن "قطع" جميع أسطر الخطة بشكلٍ كافٍ في الأسهم ، فسوف نحصل على الصورة التالية: (الأخضر - تزامنت جميع سمات خط الخطة مع الحقيقة ، الخلايا الصفراء غير متطابقة).
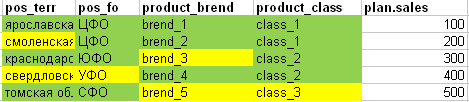
- في السطر الأول من الخطة ، توجد جميع الحقول بالكامل في الحقيقة.
- في السطر الثاني من الخطة ، لم يتم العثور على المنطقة المقابلة في الحقيقة
- الخط الثالث من الخطة لا يكفي في حقيقة العلامة التجارية
- الخط الرابع للخطة لا يكفي في حقيقة الإقليم والمنطقة الفيدرالية
- يفتقر السطر الخامس من الخطة إلى العلامة التجارية والفئة.
كما قال بانيكوفسكي: "رأيت الشورى ، ورأى - فهي ذهبية ..."

أذهب إلى عميل العمل وأوضح مثال السطر الثاني ، ما نوع النهج الذي يراه في مثل هذه الحالات؟
أحصل على الإجابة: "في الحالات التي يتعذر فيها حساب حصة القنوات للعلامة التجارية رقم 2 في منطقة سمولينسك (مع الأخذ في الاعتبار حقيقة أن لدينا منطقة سمولينسك في المنطقة المركزية الفيدرالية المركزية - المنطقة الفيدرالية المركزية) - ثم كسر هذا الخط وفقًا لهيكل القنوات داخل المنطقة الفيدرالية المركزية بأكملها!"
أي بالنسبة لـ {Smolensk region + brand_2} نقوم بتجميع الحقيقة على مستوى المنطقة الفيدرالية المركزية ونفصل منطقة Smolensk عن شيء مثل هذا:

بالعودة وهضم ما سمعته ، أحاول التعميم على إرشادي أكثر شمولية:
إذا لم تكن هناك بيانات على المستوى الحالي من التفاصيل لجدول الحقائق ، ثم قبل حساب المشاركات للحقل الهدف (قناة المبيعات) ، سنقوم بتجميع جدول الحقائق حتى السمة التسلسل الهرمي أعلاه.
هذا ، إن لم يكن للإقليم ، فإننا نجمع الحقيقة إلى مستوى هرمي أعلى - أسهم لنفس المقاطعة الفيدرالية المركزية كما هو الحال في الخطة. إن لم يكن للعلامة التجارية ، فهناك فئة من المنتجات في التسلسل الهرمي أعلاه - وبناءً على ذلك ، نقوم بإعادة فرز المشاركات لنفس الفئة وما إلى ذلك.
أي نحن نجمع بين الخطة والحقيقة في حقول الاقتران التي نعتبر من خلالها الأسهم في الواقع وفي كل تكرار وفقًا للخطة غير الموزعة المتبقية ، نقوم بتقليل تكوين حقول الاقتران على التوالي.
هناك نموذج توزيع بيانات معين يلوح في الأفق هنا:
- نوزع الخطة في الواقع على أساس المصادفة الكاملة للحقول المقابلة
- نحصل على خطة مقطوعة (نجمعها في النتيجة المتوسطة) وخطة غير منقطعة (لا تتطابق جميع الخطوط)
- نأخذ خطة غير منقطعة ونقسمها في الواقع إلى مستوى هرمي أعلى (أي ، نتخلى عن مجال معين من اقتران هذين الجدولين ونجمع الحقيقة دون هذا الحقل لحساب المشاركات)
- نحصل على خطة مقطوعة (نضيفها إلى النتيجة المتوسطة) وخطة غير منقطعة (لا تتطابق جميع الخطوط)
- ونكرر نفس الخطوات حتى لا توجد خطة "غير محلولة".
بشكل عام ، لا يلزمنا أي شخص بإزالة حقول العقبات باستمرار داخل التسلسل الهرمي. على سبيل المثال ، لقد أزلنا بالفعل العلامة التجارية والمنطقة من حقول العقبات ووزعنا الخطة المتبقية حسب: product_class (التسلسل الهرمي أعلى العلامة التجارية) + Fed.krug (التسلسل الهرمي أعلى الإقليم). وما زال هناك بعض الرصيد غير المخصص للخطة.
علاوة على ذلك ، يمكننا إزالة من حقول اقتران إما فئة المنتج أو المنطقة الفيدرالية ، كما لم تعد مضمنة في التسلسل الهرمي لبعضهم البعض.
بالنظر إلى أن هناك العديد من الصفوف والحقول في هذه الجداول - ما يصل إلى مليون القيام بهذه التلاعب بيديك - المهمة ليست الأكثر متعة.
وبالنظر إلى أن المهام من هذا النوع تأتي إلي بانتظام في نهاية كل عام (الموافقة على ميزانيات العام المقبل في مجلس الإدارة) ، كان عليك ترجمة هذه العملية إلى نوع من القوالب العالمية المرنة.
وبما أن معظم الوقت أعمل مع البيانات من خلال R - التنفيذ هو نفسه على ذلك.
أولاً ، نحتاج إلى كتابة دالة سحرية عالمية ستأخذ جدولًا أساسيًا (basetab) مع بيانات عن انهيار (في مثالنا ، خطة) وجدول لحساب المشاركات (sharetab) استنادًا إلى "رأينا" البيانات (في مثالنا ، حقيقة). ولكن يجب أن تفهم الوظيفة أيضًا ما يجب القيام به مع هذه الكائنات ، لذلك ستقبل الدالة أيضًا متجه أسماء الحقول المزدوجة (merge.vrs) - أي تلك الحقول التي تم تسميتها بشكل متطابق في كلا الجدولين وستسمح لنا بتوصيل جدول واحد بالأخرى بهذه الحقول التي يعمل فيها (أي الصلة الصحيحة). أيضًا ، يجب أن تفهم الوظيفة أي عمود من الجدول الأساسي يجب أن يؤخذ في التوزيع (basetab.value) وعلى أساس أي حقل لحساب المشاركات (sharetab.value). حسنًا ، والأهم من ذلك - ما الذي يجب اتخاذه للحقل الناتج (sharetab.targetvars) ، في حالتنا ، نريد أن نوضح تفاصيل الخطة من خلال قناة المبيعات من الحقيقة.
بالمناسبة ، هذا sharetab.targetvars المتغير ليس عشوائيًا في صيغة الجمع الخاصة بي - فقد لا يكون حقلًا واحدًا بل هو ناقل لأسماء الحقول ، في الحالات التي تحتاج فيها إلى إضافة حقل واحد إلى جدول أساسي من جدول المشاركة ولكن عدة مرات في الحال (على سبيل المثال ، بناءً على الحقيقة ، لا يمكنك تقسيم الخطة فقط من خلال قناة المبيعات ولكن أيضًا من خلال اسم المنتجات المدرجة في العلامة التجارية).
نعم ، وحالة أخرى :) يجب أن تكون وظيفتي محلية وقابلة للقراءة قدر الإمكان ، دون أي مبنى متعدد الطوابق على شاشتين (أنا حقًا لا أحب الوظائف الكبيرة).
في الحالة الأخيرة ، تتوافق حزمة dplyr الشعبية بأقصى قدر ممكن من الراحة ، وبالنظر إلى أن مشغلي خطوط الأنابيب يجب أن يفهموا الأسماء النصية للحقول التي تم تخفيضها في الوظيفة ، فإن
تقييم ستاندارت لم يكن بدون.
هنا هذا الطفل (لا يحسب التعليقات الداخلية):
fn_distr <- function(sharetab, sharetab.value, sharetab.targetvars, basetab, basetab.value, merge.vrs,level.txt=NA) { # sharetab - = # sharetab.value - - # sharetab.targetvars - - # basetab - = # basetab.value - # merge.vrs - 2- # level.txt - . ( merge.vrs) require(dplyr) sharetab.value <- as.name(sharetab.value) basetab.value <- as.name(basetab.value) if(is.na(level.txt )){level.txt <- paste0(merge.vrs,collapse = ",")} result <- sharetab %>% group_by(.dots = c(merge.vrs, sharetab.targetvars)) %>% summarise(sharetab.sum = sum(!!sharetab.value)) %>% ungroup %>% group_by(.dots = merge.vrs) %>% mutate(sharetab.share = sharetab.sum / sum(sharetab.sum)) %>% ungroup %>% right_join(y = basetab, by = merge.vrs) %>% mutate(distributed.result = !!basetab.value * sharetab.share, level = level.txt) %>% select(-sharetab.sum,-sharetab.share) return(result) }
عند الإخراج ، يجب أن تقوم الدالة بإرجاع data.frame من اتحاد جدولين مع تلك الأسطر للخطة + حقيقة حيث كان من الممكن تقسيم الخطة على الإصدار الحالي من حقول الإقران ، مع الأسطر الأصلية للخطة (وحقيقة فارغة) في الأسطر التي لا يمكن فيها تقسيم الخطة في التكرار الحالي.
أي أن النتيجة التي أرجعتها الدالة بعد التكرار الأول (كسر السطر الأول من خطة منطقة ياروسلافل) ستبدو كما يلي:
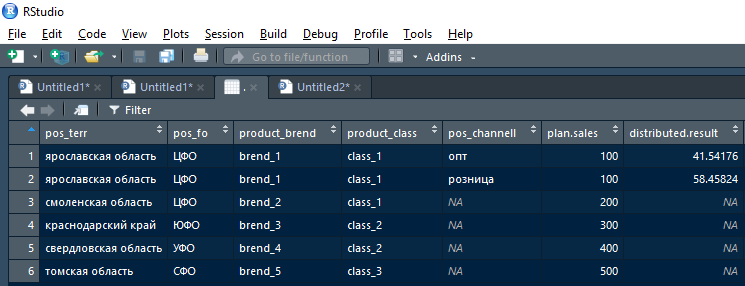
علاوة على ذلك ، يمكن أن تؤخذ هذه النتيجة عن طريق الموزعة غير الفارغة. النتيجة في النتيجة التراكمية وبواسطة (NA) الموزعة - result - أرسل إلى التكرار النموذجي التالي ، ولكن موزعة حسب الأسهم على مستوى هرمي أعلى.
كل السحر والراحة هي أن العمل يتم في نفس النوع من الكتل ووظيفة عالمية واحدة ، كل ما هو مطلوب في كل خطوة (التكرار) هو تصحيح دمج الدمج. ناقلات ومراقبة كيف يقوم السحر بكل هذا العمل الشاق من أجلك:

نعم ، لقد نسيت شيئًا بسيطًا: إذا حدث خطأ ما ، وفي النهاية حصلنا على خطة معطوبة لن تكون في مجموعها مساوية للخطة قبل الانهيار - سيكون من الصعب تتبع أي خطأ حدث فيه التكرار.
لذلك ، نحن نوفر كل التكرار مع المجموع الاختباري:
(_)-(___ )-(___.)=0
الآن دعونا نحاول تشغيل مثالنا من خلال قالب التوزيع ومعرفة ما نحصل عليه في الإخراج.
أولاً ، الحصول على البيانات المصدر:
library(dplyr) plan <- data_frame(pos_terr = c(" ", " ", " ", " ", " "), pos_fo = c("", "", "", "", ""), product_brend = c("brend_1", "brend_2", "brend_3", "brend_4", "brend_5"), product_class = c("class_1", "class_1", "class_2", "class_2", "class_3"), plan.sales = c(100, 200, 300, 400, 500)) fact <- data_frame(pos_terr = c(" ", " ", " ", " ", " "," ", " ", " ", " ", " "), pos_fo = c("", "","","", "", "", "", "", "", ""), product_brend = c("brend_1", "brend_1", "brend_2", "brend_2","brend_2", "brend_4", "brend_4", "brend_1", "brend_2", "brend_4"), product_class = c("class_1", "class_1", "class_1","class_1","class_1", "class_2", "class_2", "class_1", "class_1", "class_2"), pos_channell = c("", "", "","", "", "", "", "", "", ""), fact.sales = c(16.38, 11.64, 30.73,60, 20, 6.40, 26.49, 46.63, 65.96, 98.81)) </soure> ( ) . <source> plan.remain <- plan result.total <- data_frame()
1. نوزع بواسطة Terr ، FD (مقاطعة فيدرالية) ، والعلامة التجارية ، والطبقة merge.fields <- c("pos_terr","pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) # - plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) # = cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 2. نوزع بواسطة pho ، والعلامة التجارية ، والطبقة (وهذا هو ، نتخلى عن الأراضي في الواقع)
2. نوزع بواسطة pho ، والعلامة التجارية ، والطبقة (وهذا هو ، نتخلى عن الأراضي في الواقع)الفرق الوحيد من الكتلة الأولى هو أنها تقصر بشكل طفيف merge.fields عن طريق إزالة pos_terr فيه
merge.fields <- c("pos_fo","product_brend", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
3. توزيع بواسطة pho ، الطبقة merge.fields <- c("pos_fo", "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
4. توزيع حسب الفئة merge.fields <- c( "product_class") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
 5. توزيع بواسطة FD
5. توزيع بواسطة FD merge.fields <- c( "pos_fo") result.current <- fn_distr(sharetab = fact,sharetab.value = "fact.sales",sharetab.targetvars = "pos_channell", basetab = plan.remain,basetab.value = "plan.sales",merge.vrs = merge.fields) result.total <- result.current %>% filter(!is.na(distributed.result)) %>% select(-plan.sales) %>% bind_rows(result.total) plan.remain <- result.current %>% filter(is.na(distributed.result)) %>% select(colnames(plan)) cat(" :",sum(plan.remain$plan.sales)+sum(result.total$distributed.result)-sum(plan$plan.sales),"\n", " :",nrow(plan.remain)," ")
كما ترون ، لا توجد خطة "غير منشورة" وحساب الخطة الموزعة يساوي المخطط الأصلي.

وإليكم النتيجة مع قنوات المبيعات (في العمود الأيمن ، تعرض الدالة الحقول التي كان اقترانها / تجميعها ، حتى نفهم فيما بعد من أين جاء هذا التوزيع):

هذا كل شيء. لم تكن المقالة صغيرة جدًا ، ولكن يوجد نص توضيحي أكثر من الشفرة نفسها.
آمل أن يوفر هذا النهج المرن الوقت والأعصاب ليس لي فقط :-)
شكرا لاهتمامكم