
في المقال السابق ، تحدثنا عن مشكلة التعلم الآلي مثل الأمثلة المعادية وبعض أنواع الهجمات التي تسمح بتوليدها. سوف تركز هذه المقالة على خوارزميات الحماية من هذا النوع من التأثير والتوصيات الخاصة باختبار النماذج.
الحماية
بادئ ذي بدء ، دعونا نوضح على الفور نقطة واحدة - من المستحيل الدفاع تمامًا ضد هذا التأثير ، وهذا أمر طبيعي تمامًا. في الواقع ، إذا نجحنا في حل مشكلة الأمثلة المعادية تمامًا ، فسوف نحل في وقت واحد مشكلة بناء طائرة مفرطة مثالية ، والتي ، بالطبع ، لا يمكن القيام بها بدون مجموعة بيانات عامة.
هناك مرحلتان للدفاع عن نموذج التعلم الآلي:
التعلم - نحن نعلم خوارزمية لدينا للرد بشكل صحيح على أمثلة الخصومة.
العملية - نحن نحاول اكتشاف مثال عدواني خلال مرحلة تشغيل النموذج.
تجدر الإشارة على الفور إلى أنه يمكنك التعامل مع أساليب الحماية المقدمة في هذه المقالة باستخدام Adversarial Robustness Toolbox من IBM.
التدريب العدائي

إذا سألت شخصًا على دراية بمشكلة الخصومة بالأمثلة ، فإن السؤال التالي: "كيف تحمي نفسك من هذا التأثير؟" ، ثم بكلمات 9 من كل 10 أشخاص سيقولون: "دعنا نضيف الكائنات التي تم إنشاؤها إلى مجموعة التدريب". تم اقتراح هذا النهج على الفور في المقالة الخصائص المثيرة للشبكات العصبية في عام 2013. في هذه المقالة تم وصف هذه المشكلة لأول مرة وهجوم L-BFGS ، والذي يسمح بتلقي أمثلة معادية.
هذه الطريقة بسيطة جدا. نحن ننتج أمثلة عدائية باستخدام أنواع مختلفة من الهجمات وإضافتها إلى التدريب الذي تم تحديده في كل تكرار ، وبالتالي زيادة "مقاومة" نموذج الخصومة للأمثلة.
إن عيوب هذه الطريقة واضحة تمامًا: في كل تكرار من التدريب ، لكل مثال ، يمكننا إنشاء عدد كبير جدًا من الأمثلة ، على التوالي ، ويزيد وقت تصميم النماذج عدة مرات.
يمكنك تطبيق هذه الطريقة باستخدام مكتبة ART-IBM على النحو التالي.
from art.defences.adversarial_trainer import AdversarialTrainer trainer = AdversarialTrainer(model, attacks) trainer.fit(x_train, y_train)
زيادة البيانات الغوسية
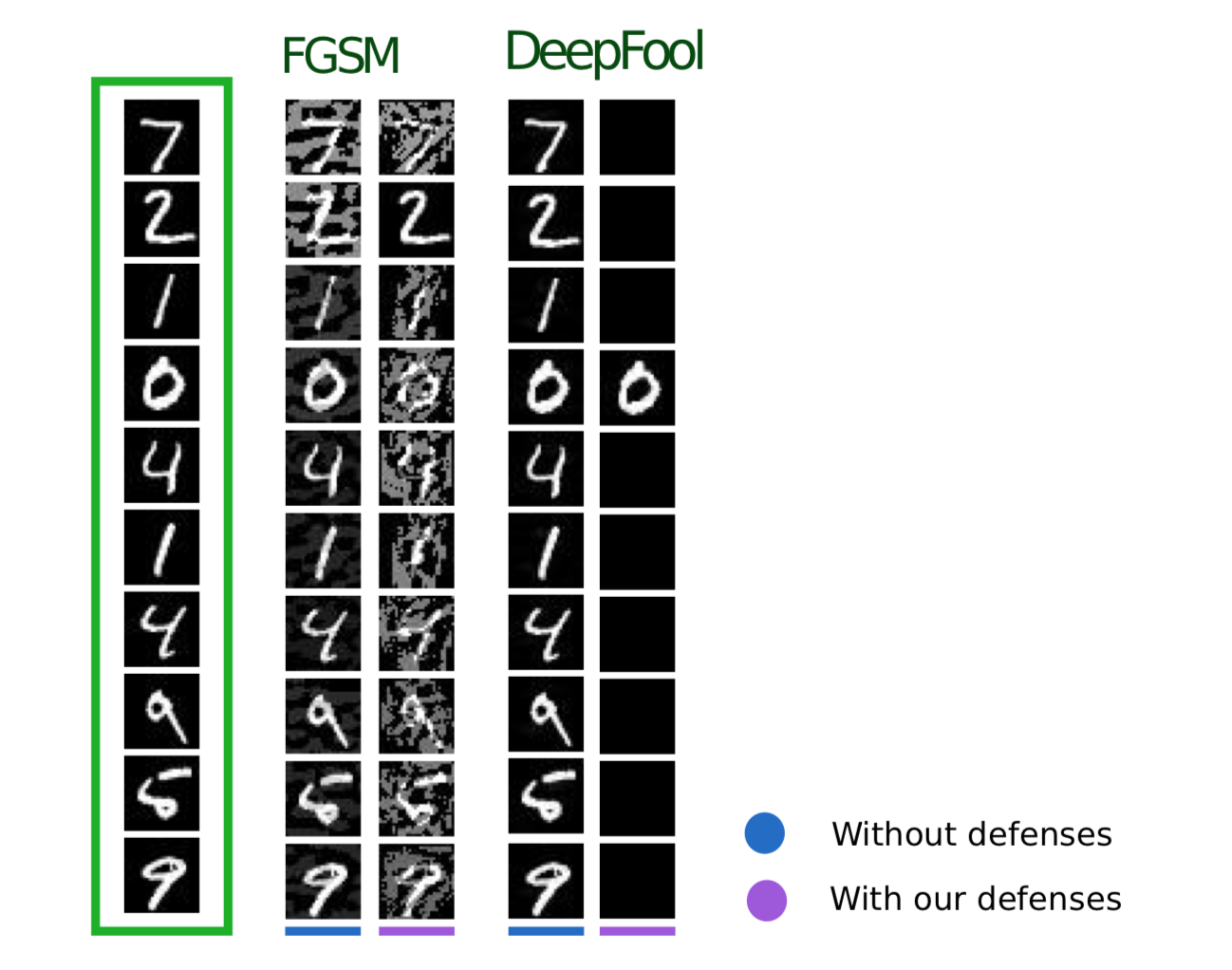
تستخدم الطريقة التالية ، الموضحة في مقالة " فعالية الدفاعات ضد الهجمات العدوانية" ، منطقًا مشابهًا: تقترح أيضًا إضافة كائنات إضافية إلى مجموعة التدريب ، ولكن على عكس التدريب المتقدم ، فإن هذه الكائنات ليست أمثلة على خصوم ، ولكنها كائنات مجموعة تدريب صاخبة قليلاً (يتم استخدام Gaussian كضوضاء الضوضاء ، وبالتالي اسم الأسلوب). وفي الواقع ، يبدو هذا منطقيًا للغاية ، لأن المشكلة الرئيسية للنماذج هي بالتحديد ضعف مناعة الضوضاء لديهم.
تُظهر هذه الطريقة نتائج مشابهة للتدريب المنافس ، بينما تقضي وقتًا أقل في تكوين أشياء للتدريب.
يمكنك تطبيق هذه الطريقة باستخدام فئة GaussianAugmentation في ART-IBM
from art.defences.gaussian_augmentation import GaussianAugmentation GDA = GaussianAugmentation() new_x = GDA(x_train)
تسمية تجانس
طريقة تجانس الملصقات بسيطة للغاية في التنفيذ ، ولكنها تحمل الكثير من المعاني الاحتمالية. لن ندخل في تفاصيل التفسير الاحتمالي لهذه الطريقة ؛ يمكنك العثور عليها في المقالة الأصلية Rethinking the Inception Architecture لـ Computer Vision . ولكن ، باختصار ، فإن Label Smoothing هو نوع إضافي من تنظيم النموذج في مشكلة التصنيف ، مما يجعله أكثر مقاومة للضوضاء.
في الواقع ، هذه الطريقة تنعم التسميات الصفية. جعلها ، مثلا ، ليس 1 ، ولكن 0.9. وبالتالي ، يتم تغريم نماذج التدريب للحصول على "ثقة" أكبر بكثير في التسمية لكائن معين.
يمكن الاطلاع على تطبيق هذه الطريقة في بايثون أدناه.
from art.defences.label_smoothing import LabelSmoothing LS = LabelSmoothing() new_x, new_y = LS(train_x, train_y)
يحدها relu
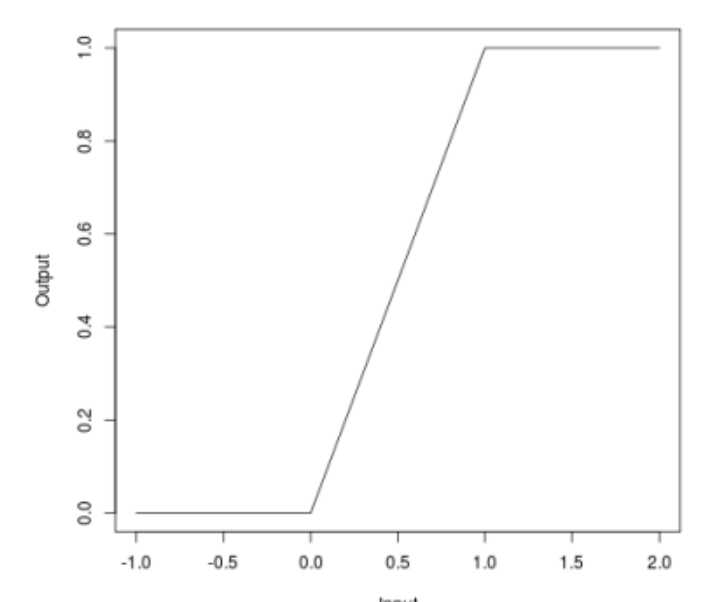
عندما تحدثنا عن الهجمات ، قد يلاحظ الكثيرون أن بعض الهجمات (JSMA ، OnePixel) تعتمد على مدى قوة التدرج اللوني في نقطة أو أخرى في صورة الإدخال. تحاول طريقة Bounded ReLU البسيطة و "الرخيصة" (من حيث التكاليف الحسابية والوقت) التعامل مع هذه المشكلة.
جوهر الأسلوب هو على النحو التالي. دعنا نستبدل وظيفة التنشيط لـ ReLU في شبكة عصبية مع نفس واحدة ، وهي محدودة ليس فقط من الأسفل ، ولكن أيضًا من أعلى ، وبالتالي تجنّب خرائط التدرجات اللونية ، وفي بعض النقاط المحددة ، لن يكون من الممكن الحصول على دفقة ، والتي لن تسمح لك بخداع الخوارزمية عن طريق تغيير بكسل واحد من الصورة.
\ تبدأ {المعادلة *} f (x) =
\ تبدأ {الحالات}
0 ، س <0
\\
x ، 0 \ leq x \ leq t
\\
ر ، س> ر
\ end {cases}
\ end {equation *}
وقد تم وصف هذه الطريقة أيضًا في المقالة " الدفاعات الفعالة ضد الهجمات العدوانية"
فرق بناء النموذج
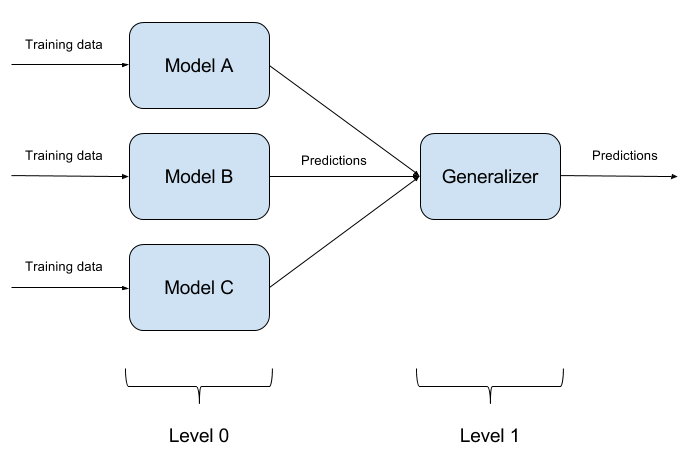
ليس من الصعب خداع نموذج واحد مدرب. إن خداع نموذجين في نفس الوقت بكائن واحد هو أمر أكثر صعوبة. وإذا كان هناك N هذه النماذج؟ بناءً على ذلك ، تعتمد طريقة المجموعات على النماذج. نحن ببساطة بناء نماذج مختلفة ونجمع ناتجها في إجابة واحدة. إذا كانت النماذج ممثلة أيضًا بخوارزميات مختلفة ، فمن الصعب للغاية خداع مثل هذا النظام!
من الطبيعي تمامًا أن يكون تنفيذ مجموعات النماذج نهجًا معماريًا بحتًا ، حيث يطرح الكثير من الأسئلة (ما النماذج الأساسية التي يجب اتخاذها؟ كيفية تجميع مخرجات النماذج الأساسية؟ هل هناك علاقة بين النماذج؟ وما إلى ذلك). لهذا السبب ، لم يتم تطبيق هذا النهج في ART-IBM
ميزة الضغط
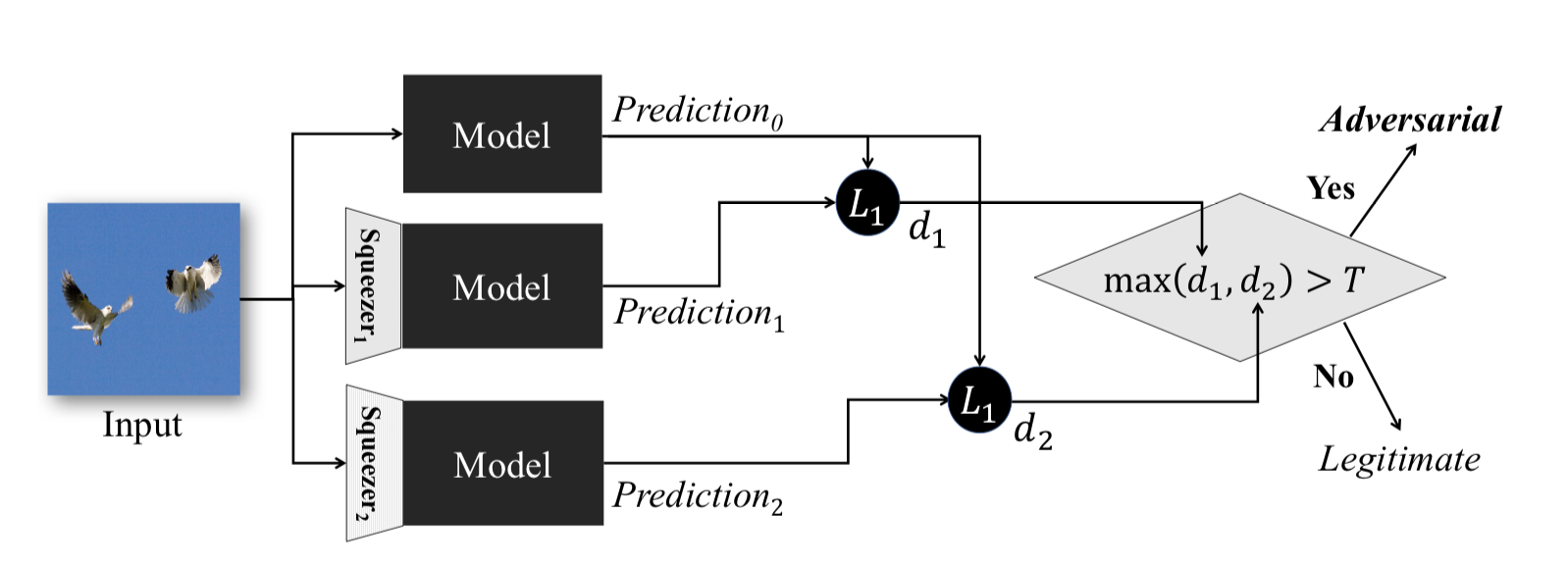
تعمل هذه الطريقة ، الموضحة في " عصر الميزة": الكشف عن أمثلة عدوانية في الشبكات العصبية العميقة ، خلال المرحلة التشغيلية للنموذج. انها تسمح لك للكشف عن أمثلة الخصم.
الفكرة من وراء هذه الطريقة هي ما يلي: إذا قمت بتدريب نماذج n على نفس البيانات ، ولكن مع نسب ضغط مختلفة ، ستظل نتائج عملها متشابهة. في الوقت نفسه ، من المرجح أن يفشل مثال الخصوم ، الذي يعمل على شبكة المصدر ، على شبكات إضافية. وبالتالي ، بالنظر إلى الفرق بين زوجي مخرجات الشبكة العصبية الأولية وتلك الإضافية ، واختيار الحد الأقصى منها ومقارنتها بعتبة تم تحديدها مسبقًا ، يمكننا أن نذكر أن كائن الإدخال هو إما خصم أو صالح تمامًا.
فيما يلي طريقة للحصول على كائنات مضغوطة باستخدام ART-IBM
from art.defences.feature_squeezing import FeatureSqueezing FS = FeatureSqueezing() new_x = FS(train_x)
سننتهي بطرق الحماية. ولكن سيكون من الخطأ عدم فهم نقطة واحدة مهمة. إذا لم يتمكن المهاجم من الوصول إلى نموذج المدخلات والمخرجات ، فلن يفهم كيف تتم معالجة البيانات الخام داخل النظام الخاص بك قبل إدخال النموذج. عندئذٍ فقط ، سيتم تقليل جميع هجماته إلى فرز قيم الإدخال بشكل عشوائي ، وهو أمر غير مرجح بطبيعة الحال أن يؤدي إلى النتيجة المرجوة.
اختبار
الآن دعنا نتحدث عن اختبار الخوارزميات لمواجهة الأمثلة العدائية. هنا ، أولاً وقبل كل شيء ، من الضروري أن نفهم كيف سنختبر نموذجنا. إذا افترضنا أن أي مهاجم يمكنه بأي حال من الأحوال الوصول الكامل إلى النموذج بأكمله ، فمن الضروري اختبار طرازنا باستخدام أساليب الهجوم في WhiteBox.
في حالة أخرى ، نفترض أن المهاجم لن يتمكن أبدًا من الوصول إلى "الدواخل" في نموذجنا ، ومع ذلك ، سيكون قادرًا ، وإن كان بشكل غير مباشر ، على التأثير على بيانات الإدخال ومشاهدة نتيجة النموذج. ثم يجب عليك تطبيق أساليب هجمات BlackBox.
يمكن وصف خوارزمية الاختبار العامة بالمثال التالي:
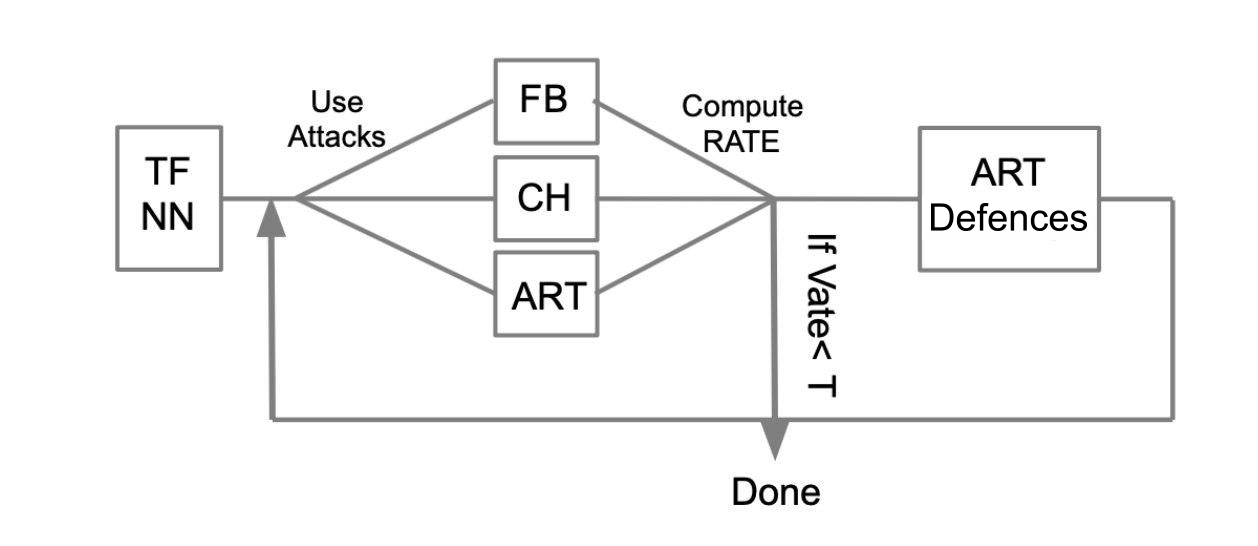
فليكن هناك شبكة عصبية مدربة مكتوبة بلغة TensorFlow (TF NN). ندعي بخبرة أن شبكتنا يمكن أن تقع في أيدي مهاجم من خلال اختراق النظام الذي يوجد به النموذج. في هذه الحالة ، نحتاج إلى تنفيذ هجمات WhiteBox. للقيام بذلك ، نحدد مجموعة الهجوم والأطر (FoolBox - FB ، CleverHans - CH ، صندوق أدوات مقاومة الخصوم - ART) التي تسمح بتنفيذ هذه الهجمات. ثم ، بعد حساب عدد الهجمات التي نجحت ، نحسب معدل النجاح (SR). إذا كانت SR مناسبة لنا ، فإننا ننتهي من الاختبار ، وإلا فإننا نستخدم إحدى طرق الحماية ، على سبيل المثال ، يتم تنفيذها في ART-IBM. ثم مرة أخرى نقوم بتنفيذ هجمات ونفكر في SR. نقوم بهذه العملية بشكل دوري ، حتى يناسبنا SR.
الاستنتاجات
أود أن أنهي هنا بمعلومات عامة حول الهجمات والدفاعات واختبار نماذج التعلم الآلي. تلخيص المادتين ، يمكننا أن نستنتج ما يلي:
- لا تؤمن بالتعلم الآلي كنوع من المعجزات التي يمكنها حل جميع مشاكلك.
- عند تطبيق خوارزميات التعلم الآلي في مهامك ، فكر في مدى مقاومة هذه الخوارزمية لمثل هذا التهديد مثل أمثلة الخصومة.
- يمكنك حماية الخوارزمية من جانب التعلم الآلي ، ومن جانب النظام الذي يتم فيه تشغيل هذا النموذج.
- اختبر نماذجك ، خاصةً في الحالات التي تؤثر فيها نتيجة النموذج بشكل مباشر على القرار
- توفر المكتبات مثل FoolBox و CleverHans و ART-IBM واجهة مريحة لمهاجمة نماذج التعلم الآلي والدفاع عنها.
أيضًا في هذه المقالة ، أود تلخيص العمل مع مكتبات FoolBox و CleverHans و ART-IBM:
FoolBox هي مكتبة بسيطة ومفهومة لمهاجمة الشبكات العصبية ، ودعم العديد من الأطر المختلفة.
CleverHans هي مكتبة تسمح لك بتنفيذ هجمات عن طريق تغيير العديد من معلمات الهجوم ، وهو أكثر تعقيدًا بقليل من FoolBox ، ويدعم عددًا أقل من الأطر.
ART-IBM هي المكتبة الوحيدة أعلاه التي تسمح لك بالعمل مع طرق الأمان ، حتى الآن تدعم TensorFlow و Keras فقط ، ولكنها تتطور بشكل أسرع من غيرها.
هنا تجدر الإشارة إلى أن هناك مكتبة أخرى للعمل مع أمثلة معادية من بايدو ، لكنها ، للأسف ، مناسبة فقط للأشخاص الذين يتحدثون الصينية.
في المقالة التالية حول هذا الموضوع ، سنقوم بتحليل جزء من المهمة التي تم حلها خلال ZeroNights HackQuest 2018 من خلال خداع شبكة عصبية نموذجية باستخدام مكتبة FoolBox.