لقد كان اكتشاف الهجمات مهمة مهمة في أمن المعلومات لعدة عقود. تعود أول أمثلة معروفة لتطبيق IDS إلى أوائل الثمانينيات.
بعد عدة عقود ، تم تشكيل صناعة كاملة من أدوات الكشف عن الهجوم. حاليًا ، هناك أنواع مختلفة من المنتجات ، مثل IDS و IPS و WAF وجدران الحماية ، ومعظمها يوفر اكتشاف الهجوم القائم على القواعد. لا تبدو فكرة استخدام تقنيات الكشف عن الحالات الشاذة للكشف عن الهجمات القائمة على إحصاءات الإنتاج واقعية كما كانت في الماضي. أو كل نفس؟
الكشف عن الشذوذ في تطبيقات الويب
بدأت أول جدران الحماية المصممة خصيصًا للكشف عن الهجمات على تطبيقات الويب في الظهور في الأسواق في أوائل التسعينيات. منذ ذلك الحين ، تغيرت أساليب الهجوم وآليات الدفاع بشكل كبير ، ويمكن للمهاجمين أن يتقدموا خطوة واحدة في أي وقت.
حاليًا ، تحاول معظم WAFs اكتشاف الهجمات على النحو التالي: هناك بعض الآليات المستندة إلى القواعد والمضمنة في الخادم الوكيل العكسي. المثال الأكثر وضوحا هو mod_security ، وحدة WAF لخادم الويب Apache ، والذي تم تطويره في عام 2002. تحديد الهجمات باستخدام القواعد له عدة عيوب. على سبيل المثال ، لا يمكن للقواعد اكتشاف هجمات اليوم صفر ، بينما يمكن للخبراء اكتشاف نفس الهجمات بسهولة ، وهذا ليس مفاجئًا ، لأن الدماغ البشري لا يعمل مثل مجموعة من التعبيرات المنتظمة.
من وجهة نظر WAF ، يمكن تقسيم الهجمات إلى تلك التي يمكننا اكتشافها من خلال تسلسل الطلبات ، وتلك التي يكون فيها طلب HTTP واحد (استجابة) كافياً لحلها. يركز بحثنا على اكتشاف الأنواع الأخيرة من الهجمات - SQL Injection و Scripting Site Script و XML External Entities Injection و Path Traversal و OS Commanding و Object Injection ، إلخ.
لكن أولاً ، دعونا نختبر أنفسنا.
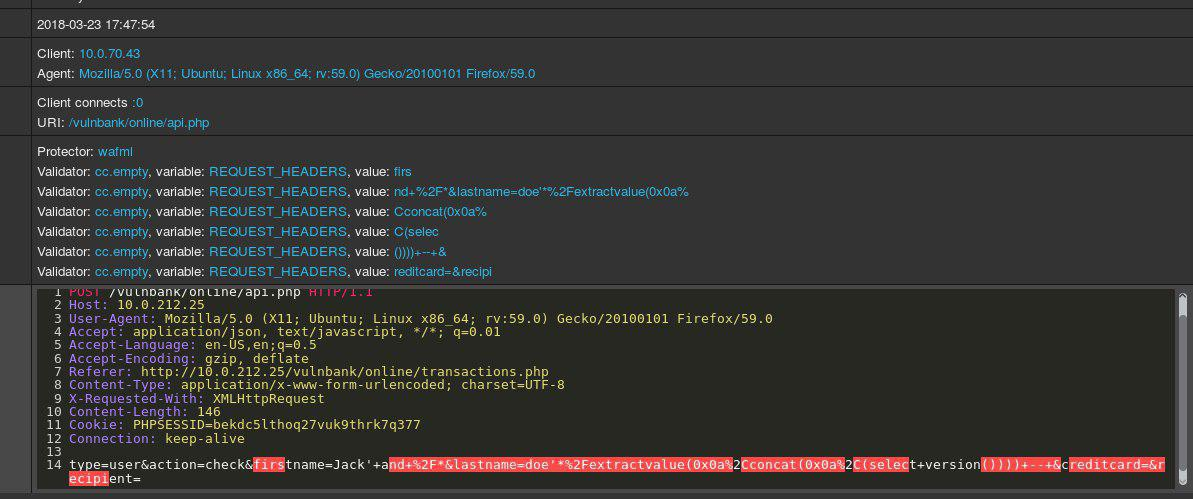
ماذا سيفكر الخبير عندما يرى الاستعلامات التالية؟
ألقِ نظرة على مثال طلب HTTP للتطبيقات:
إذا تم تكليفك بمهمة اكتشاف الطلبات الضارة لأحد التطبيقات ، فمن المرجح أنك ترغب في مراقبة سلوك المستخدم المعتاد لبعض الوقت. من خلال فحص الاستعلامات بحثًا عن نقاط نهاية متعددة للتطبيق ، يمكنك الحصول على فكرة عامة حول بنية ووظائف الاستعلامات غير الخطرة.
الآن يمكنك الحصول على الاستعلام التالي للتحليل:

من الواضح على الفور أن هناك خطأ ما هنا. سوف يستغرق الأمر بعض الوقت لفهم الشكل الحقيقي هنا ، وبمجرد تحديد جزء الطلب الذي يبدو غير طبيعي ، يمكنك البدء في التفكير في نوع الهجوم. في جوهرها ، هدفنا هو جعل "ذكائنا الاصطناعي للكشف عن الهجمات" تعمل بنفس الطريقة - لتشبه التفكير الإنساني.
الشيء الواضح هو أن بعض الزيارات ، والتي تبدو للوهلة الأولى ضارة ، قد تكون طبيعية لموقع معين.
على سبيل المثال ، دعنا نفكر في الاستعلامات التالية:
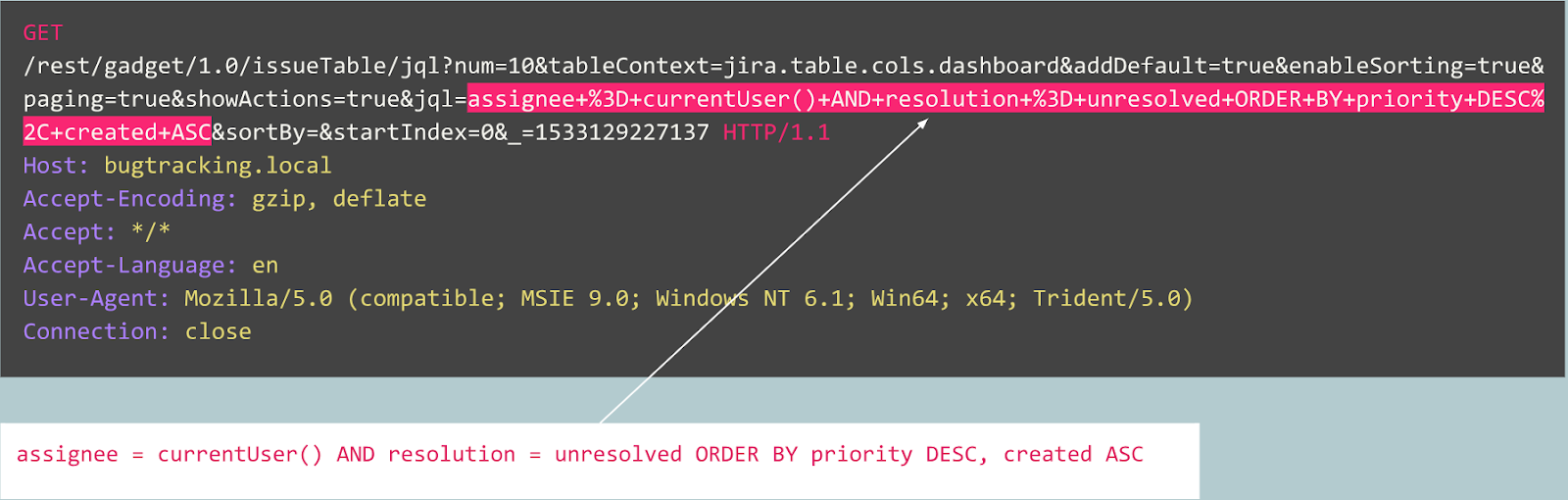
هل هذا الاستعلام غير طبيعي؟
في الواقع ، هذا الطلب هو منشور لخطأ في متتبع Jira وهو نموذجي لهذه الخدمة ، مما يعني أن الطلب متوقع وطبيعي.
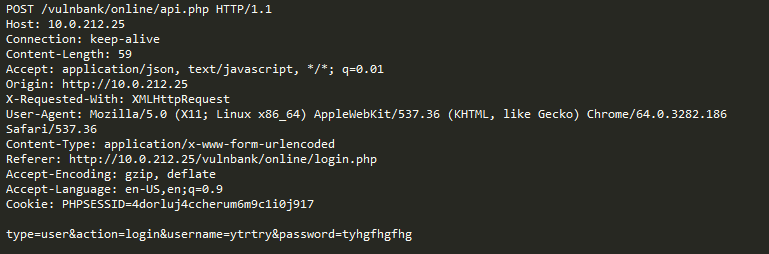
الآن خذ بعين الاعتبار المثال التالي:

للوهلة الأولى ، يبدو الطلب وكأنه تسجيل مستخدم عادي على موقع ويب يستند إلى جملة CMS. ومع ذلك ، فإن العملية المطلوبة هي user.register بدلاً من التسجيل المعتاد. الخيار الأول قديم ، ويحتوي على ثغرة أمنية تسمح لأي شخص بالتسجيل كمسؤول. يُعرف استغلال مشكلة عدم الحصانة هذه باسم جملة <3.6.4 إنشاء حساب / امتياز تصعيد (CVE-2016-8869 ، CVE-2016-8870).

من أين بدأنا؟
بالطبع ، درسنا أولاً الحلول الحالية للمشكلة. بذلت محاولات عديدة لإنشاء خوارزميات الكشف عن الهجوم على أساس الإحصاءات أو التعلم الآلي لعدة عقود. تتمثل إحدى الطرق الأكثر شيوعًا في حل مشكلة التصنيف ، عندما تكون الفصول مثل "الاستعلامات المتوقعة" ، و "حقن SQL" ، و XSS ، و CSRF ، إلخ. وبهذه الطريقة ، يمكنك تحقيق بعض الدقة الجيدة لمجموعة البيانات باستخدام المصنف. ومع ذلك ، فإن هذا النهج لا يحل المشاكل الهامة للغاية من وجهة نظرنا:
- اختيار الفصل محدود ومحدّد مسبقًا . ماذا لو كان نموذجك في عملية التعلم ممثلاً بثلاثة فصول ، مثل "الاستعلامات العادية" و SQLi و XSS ، وخلال عملية النظام واجهت CSRF أو هجومًا في اليوم صفر؟
- معنى هذه الفئات . افترض أنك بحاجة إلى حماية عشرة عملاء ، كل منهم يدير تطبيقات ويب مختلفة تمامًا. بالنسبة لمعظمهم ، ليس لديك فكرة عما يبدو عليه حقن SQL في تطبيقهم. هذا يعني أنه يجب عليك إنشاء مجموعات بيانات التدريب بطريقة مصطنعة. هذا النهج ليس الأمثل ، لأنه في النهاية سوف تتعلم من البيانات التي تختلف في التوزيع عن البيانات الحقيقية.
- تفسير نتائج النموذج . حسنا ، أنتجت النموذج نتيجة حقن SQL ، والآن ماذا؟ والأهم من ذلك ، يجب أن تخمن أنت وعميلك ، وهو أول من يرى تحذيراً وليس خبيرًا في هجمات الويب ، أي جزء من الطلب يعتبره النموذج خبيثًا.
مع وضع كل هذه المشكلات في الاعتبار ، قررنا محاولة تدريب نموذج المصنف على أي حال.
نظرًا لأن بروتوكول HTTP هو بروتوكول نصي ، فقد كان من الواضح أننا نحتاج إلى إلقاء نظرة على مصنفات النص الحديثة. أحد الأمثلة المعروفة هو تحليل المشاعر في مجموعة بيانات مراجعة فيلم IMDB. تستخدم بعض الحلول RNN لتصنيف المراجعات. قررنا تجربة نموذج مشابه لهندسة RNN مع بعض الاختلافات الطفيفة. على سبيل المثال ، تستخدم هندسة RNN للغة الطبيعية تمثيلًا متجهًا للكلمات ، لكن من غير الواضح أي الكلمات تحدث في لغة غير طبيعية مثل HTTP. لذلك ، قررنا استخدام التمثيل المتجه للرموز لمهمتنا.
لا تحل عروض التمثيل الجاهزة مشكلتنا ، لذلك استخدمنا تعيينات بسيطة من الأحرف في رموز رقمية مع العديد من العلامات الداخلية ، مثل
GO و
EOS .
بعد الانتهاء من تطوير واختبار النموذج ، أصبحت جميع المشكلات التي سبق التنبؤ بها واضحة ، ولكن على الأقل انتقل فريقنا من الافتراضات غير المجدية إلى نتيجة ما.
ما التالي؟
بعد ذلك ، قررنا اتخاذ بعض الخطوات نحو تفسير نتائج النموذج. في مرحلة ما ، صادفنا آلية الاهتمام "الاهتمام" وبدأنا تنفيذها في نموذجنا. وأعطى نتائج واعدة. الآن بدأ نموذجنا في عرض ليس فقط تسميات الفصل ، ولكن أيضًا عوامل الاهتمام لكل حرف انتقلنا إلى النموذج.
الآن يمكننا أن نتصور ونظهر في واجهة الويب المكان بالضبط الذي تم فيه اكتشاف هجوم حقن SQL. كانت هذه نتيجة جيدة ، لكن المشاكل الأخرى من القائمة كانت لا تزال دون حل.
كان من الواضح أننا يجب أن نستمر في التحرك نحو الاستفادة من آلية الاهتمام والابتعاد عن مهمة التصنيف. بعد قراءة عدد كبير من الدراسات ذات الصلة على نماذج التسلسل (حول آليات الانتباه [2] ، [3] ، [4] ، حول تمثيل المتجهات ، على معماريات أجهزة الترميز التلقائي) والتجارب مع بياناتنا ، تمكنا من إنشاء نموذج اكتشاف شاذ في النهاية ستعمل أكثر أو أقل بالطريقة التي يعمل بها الخبير.
الترميز التلقائي
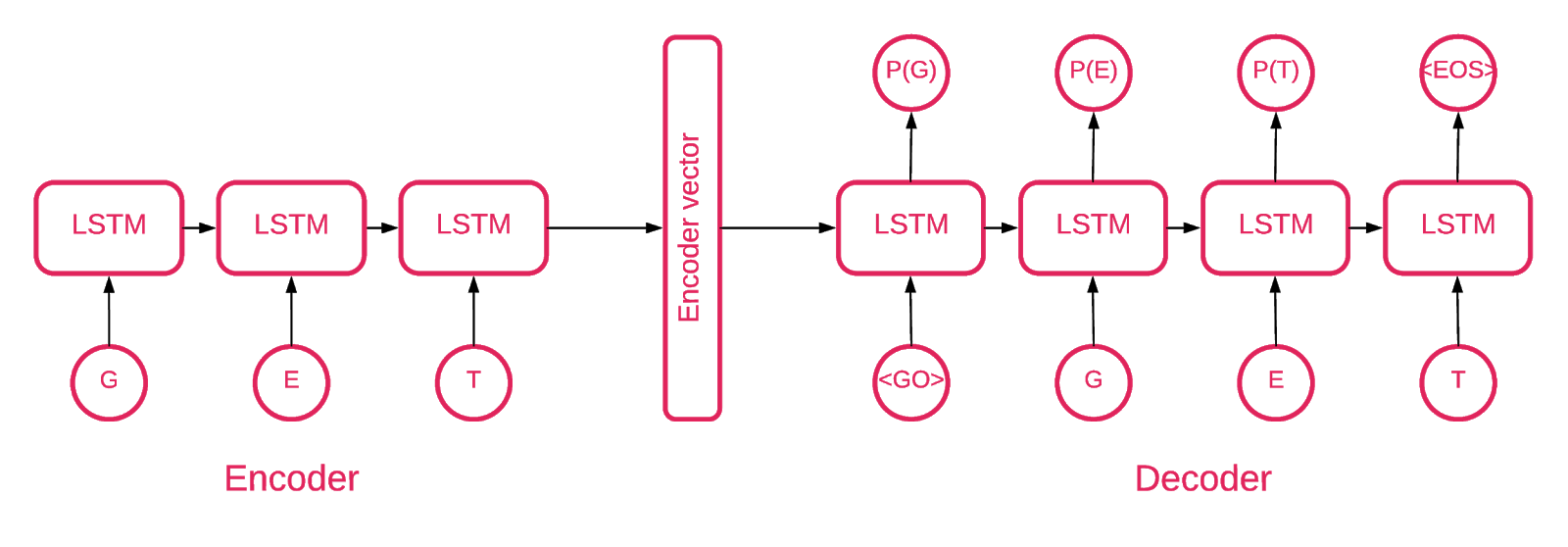
في مرحلة ما ، أصبح من الواضح أن بنية Seq2Seq [5] هي الأنسب لمهمتنا.
يتكون نموذج Seq2Seq [7] من LSTMs متعدد الطبقات - تشفير وفك تشفير. يعين المشفر تسلسل الإدخال إلى متجه بطول ثابت. وحدة فك الترميز لفك تشفير المتجه الهدف باستخدام إخراج التشفير. في التدريب ، يعتبر التشفير التلقائي نموذجًا تُضبط فيه القيم المستهدفة على نفس قيم الإدخال.
والفكرة هي تعليم الشبكة لفك تشفير الأشياء التي تراها ، أو بعبارة أخرى ، تقريب الهوية. إذا تم إعطاء وحدة التشفير التلقائي المدربة نمطًا غير طبيعي ، فمن المحتمل أن يعيد تكوينه بدرجة عالية من الخطأ ، لمجرد أنه لم يتم رؤيته مطلقًا.
الحل
يتكون حلنا من عدة أجزاء: تهيئة النموذج والتدريب والتنبؤ والتحقق. معظم التعليمات البرمجية الموجودة في المستودع ، كما نأمل ، لا تتطلب أي تفسير ، لذلك سنركز فقط على الأجزاء المهمة.
يتم إنشاء النموذج كمثيل لفئة Seq2Seq ، والذي يحتوي على وسيطات المُنشئ التالية:
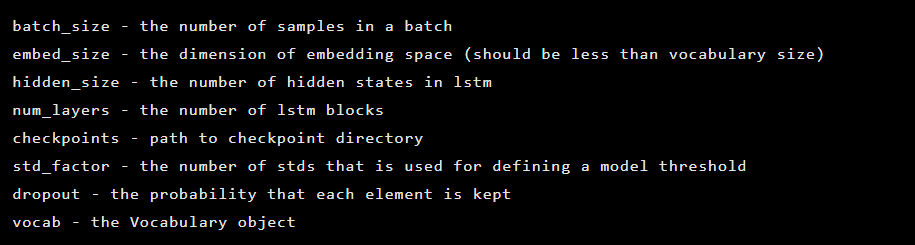
بعد ذلك ، تتم تهيئة طبقات التشفير التلقائي. التشفير الأول:
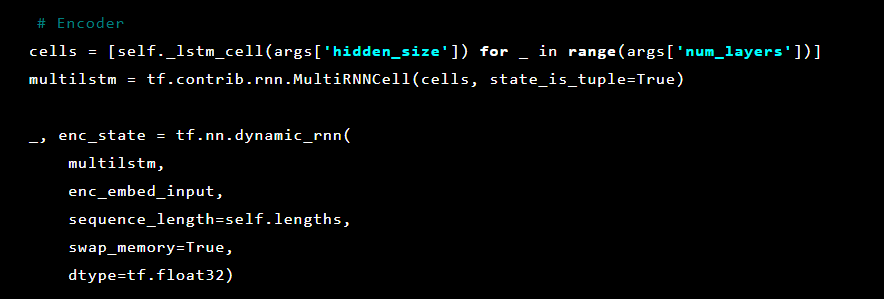
ثم فك التشفير:
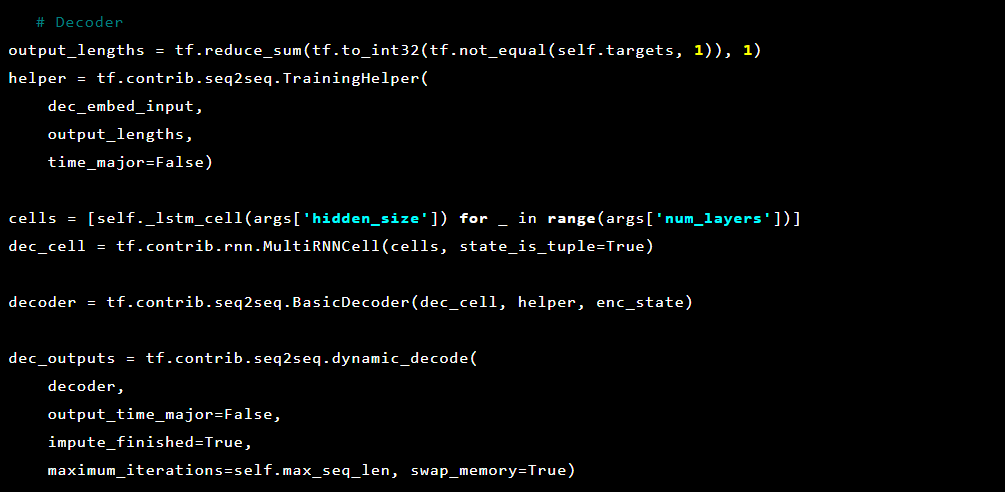
نظرًا لأن المشكلة التي نحلها هي اكتشاف الحالات الشاذة ، فإن القيم المستهدفة والمدخلات هي نفسها. لذلك يبدو feed_dict لدينا مثل هذا:
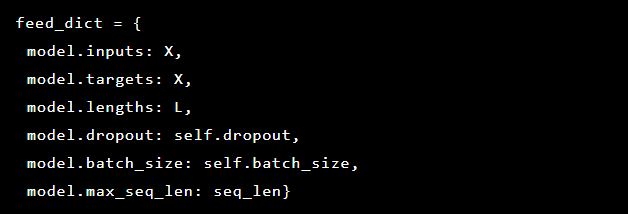
بعد كل عصر ، يتم حفظ أفضل طراز كنقطة مرجعية ، والتي يمكن بعد ذلك تنزيلها. لأغراض الاختبار ، تم إنشاء تطبيق ويب دافعنا عنه باستخدام نموذج للتحقق من نجاح الهجمات الحقيقية.
من وحي آلية الانتباه ، حاولنا تطبيقه على نموذج التشفير التلقائي لتمييز الأجزاء غير الطبيعية من هذا الاستعلام ، لكن لاحظنا أن الاحتمالات المستمدة من الطبقة الأخيرة تعمل بشكل أفضل.

في مرحلة الاختبار في العينة المتأخرة ، حصلنا على نتائج جيدة للغاية: الدقة والتذكر قريبة من 0.99. ويميل منحنى ROC إلى 1. يبدو مذهلاً ، أليس كذلك؟
النتائج
تمكن الطراز المقترح من التشفير التلقائي Seq2Seq من اكتشاف الحالات الشاذة في طلبات HTTP بدقة عالية للغاية.
يعمل هذا النموذج كأنه شخص: فهو يدرس فقط طلبات المستخدم "العادية" لتطبيق الويب. وعندما يكتشف الحالات الشاذة في الطلبات ، فإنه يحدد الموقع الدقيق للطلب ، والذي يعتبره غير طبيعي.
لقد اختبرنا هذا النموذج على بعض الهجمات على تطبيق اختبار وكانت النتائج واعدة. على سبيل المثال ، توضح الصورة أعلاه كيف اكتشف نموذجنا حقنة SQL مقسمة إلى معلمتين في نموذج ويب. تسمى حقن SQL هذه بأنها مجزأة: يتم تسليم أجزاء من الحمولة الهجومية في عدة معلمات HTTP ، مما يجعل من الصعب اكتشافها بحثًا عن WAFs المستندة إلى القواعد ، لأنها عادةً ما تختبر كل معلمة على حدة.
يتم نشر رمز النموذج وبيانات التدريب والاختبار كجهاز كمبيوتر محمول Jupyter حتى يتمكن الجميع من إعادة إنتاج نتائجنا واقتراح تحسينات.
في الختام
نعتقد أن مهمتنا كانت غير بديهية إلى حد ما. نود ، مع بذل الحد الأدنى من الجهد (أولاً وقبل كل شيء ، لتجنب الأخطاء بسبب تعقيد الحل) ، التوصل إلى طريقة للكشف عن الهجمات التي ، كما لو كان السحر ، قد تعلمت أن تقرر ما هو جيد وما هو سيء. ثانياً ، أردت أن أتجنب المشاكل المتعلقة بالعامل البشري ، عندما يقرر الخبير بالضبط ما هو علامة على الهجوم وما هو غير ذلك. بإيجاز ، أود أن أشير إلى أن برنامج التشفير التلقائي مع بنية Seq2Seq لمشكلة البحث عن الحالات الشاذة ، في رأينا ومشكلتنا ، قام بعمل ممتاز.
أردنا أيضًا حل المشكلة المتعلقة بتفسير البيانات. عادةً ما يكون من الصعب للغاية استخدام تصميمات الشبكات العصبية المعقدة. في سلسلة من التحولات ، من الصعب بالفعل أن نقول في النهاية ما هو بالضبط جزء البيانات التي أثرت في القرار أكثر. ومع ذلك ، بعد إعادة التفكير في النهج المتبع في تفسير البيانات من خلال النموذج ، اتضح أنه كافٍ للحصول على احتمالات كل رمز من الطبقة الأخيرة.
تجدر الإشارة إلى أن هذه ليست نسخة الإنتاج. لا يمكننا الكشف عن تفاصيل تنفيذ هذا النهج في منتج حقيقي ، ونريد أن نحذر من أن أخذ هذا الحل وإدراجه ببساطة في بعض المنتجات لن ينجح.
مستودع جيثب:
goo.gl/aNwq9Uالمؤلفون : ألكسندرا مورزينا (
مورزينا )
وإرينا ستيبانيوك (
جيثب ) وفيدور ساخاروف (
جيثب )
وأرسيني روتوف (
Raz0r )
المراجع
- فهم شبكات LSTM
- الاهتمام والشبكات العصبية المتكررة المعززة
- الاهتمام هو كل ما تحتاجه
- الاهتمام هو كل ما تحتاجه (مشروح)
- الترجمة الآلية العصبية (seq2seq)
- مشعلات السيارات
- التسلسل إلى التعلم التسلسلي مع الشبكات العصبية
- بناء مشفر السيارات في كراس