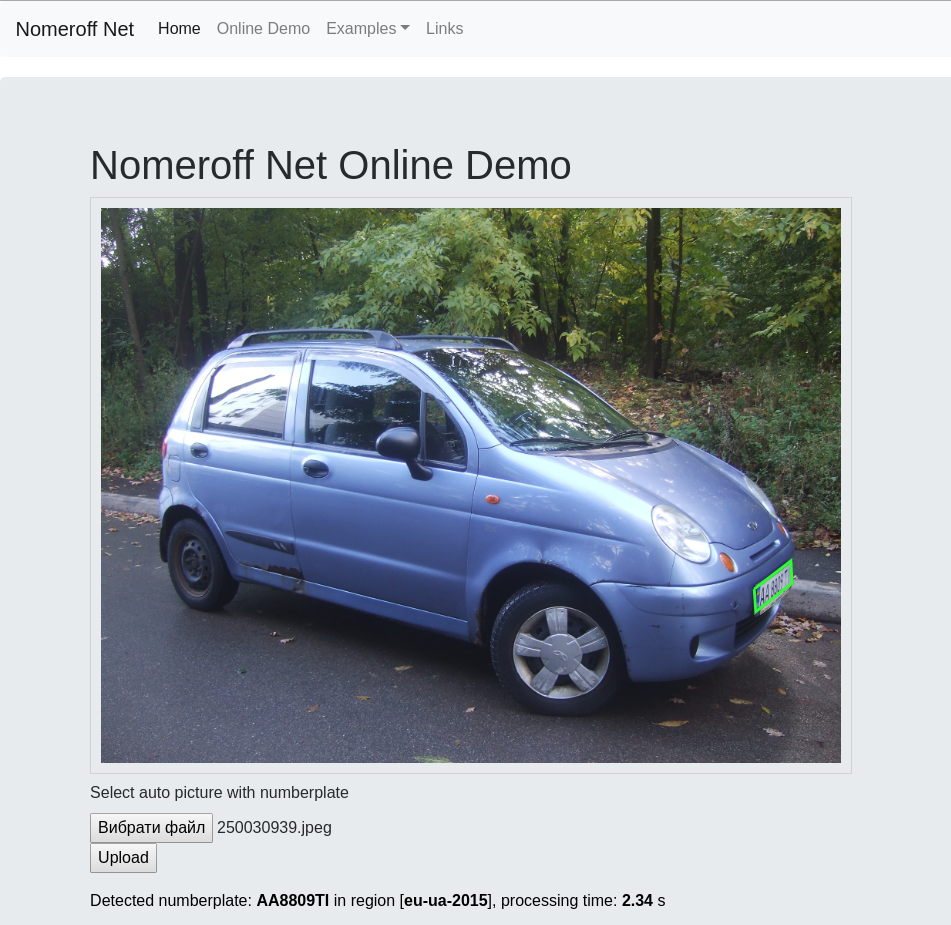
نواصل قصة كيفية التعرف على لوحات ترخيص لأولئك الذين يمكن أن يكتبوا تطبيق hello world في بيثون! في هذا الجزء ، سوف نتعلم كيفية تدريب النماذج التي تبحث عن منطقة كائن معين ، وكذلك نتعلم كيفية كتابة شبكة RNN بسيطة من شأنها أن تتكيف مع أرقام القراءة بشكل أفضل من بعض النظراء التجاريين.
في هذا الجزء ، سأخبرك عن كيفية تدريب Nomeroff Net على بياناتك ، وكيفية الحصول على جودة عالية للتعرف ، وكيفية تكوين دعم وحدة معالجة الرسومات وتسريع كل شيء بترتيب من الحجم ...
نقوم بتدريب Mask RCNN لإيجاد المنطقة التي بها الرقم
بالطبع ، لا يمكنك العثور على رقم فحسب ، بل يمكنك العثور على أي كائن آخر تحتاج إلى العثور عليه. على سبيل المثال ، يمكنك ، عن طريق القياس ، البحث عن بطاقة الائتمان وقراءة التفاصيل الخاصة بها. بشكل عام ، يُعرف العثور على القناع المدرج فيه الكائن في الصورة بمهمة "تقسيم مثيل" (لقد كتبت بالفعل عن ذلك في الجزء الأول).
الآن سنكتشف كيفية تدريب الشبكة لحل هذه المشكلة. في الواقع ، هناك القليل من البرمجة هنا ، كل هذا يرجع إلى ترميز بيانات رتيب وموحد وموحد. نعم ، نعم ، بعد وضع علامة على أول مائة لديك ، ستفهم ما أقصده :)
لذلك ، خوارزمية إعداد البيانات هي كما يلي:
- نلتقط صورًا بحجم 300 × 300 على الأقل ، ونفقد كل شيء في مجلد واحد
- نقوم بتحميل أداة تمييز VGG Image Annotator (VIA) ، ويمكنك وضع علامة عليها مباشرة عبر الإنترنت ، وسيكون الإخراج دليلًا يحتوي على صورة وملف json الذي قمت بإنشائه باستخدام الترميز. هناك نوعان من هذه المجلدات ، في المجلد الذي يدعى train وضع الجزء الرئيسي من الأمثلة ، في val الثاني حوالي 20-30 ٪ من عدد الأمثلة من الحزمة الأولى (بالطبع ، لا ينبغي أن يكون لهذه المجلدات نفس الصور). يمكنك مشاهدة مثال على البيانات ذات العلامات لمشروع Nomeroff Net . من حيث الكمية - كلما كان ذلك أفضل. يوصي بعض الخبراء بـ 5000 مثال ، نحن كسولون ، ونكتب أكثر من 1000 بقليل لأن النتيجة كانت جيدة جدًا معنا.

- لبدء التدريب ، تحتاج إلى تنزيل مشروع Nomeroff Net من Github ، وتثبيت Mask RCNN بجميع التبعيات ، ويمكنك تجربة تشغيل البرنامج النصي للتدريب على القطار / mrcnn.ipynb على بياناتنا
- أنا أحذرك على الفور ، هذا لا يعمل بسرعة. إذا لم يكن لديك GPU ، فقد يستغرق ذلك أيامًا. لتسريع عملية التعلم بشكل كبير ، من المستحسن تثبيت tensorflow مع دعم GPU .
- إذا كان التدريب على مجموعة البيانات الخاصة بنا ناجحًا ، يمكنك الآن التبديل بأمان إلى مجموعة البيانات الخاصة بك.
يرجى ملاحظة - نحن لا نقوم بتدريب كل شيء من نقطة الصفر ، نحن ندرب النموذج المدرب على بيانات مجموعة بيانات COCO ، والذي يتم تنزيل Mask RCNN عند التشغيل لأول مرة
- يمكنك تدريب ليس coco ، ولكن لدينا نموذج mask_rcnn_numberplate_0700.h5 ، وتحديد المسار إلى هذا النموذج في معلمة التكوين WEIGHTS (بشكل افتراضي ، "WEIGHTS": "coco")
- من المعلمات التي يمكن تمديدها: EPOCH ، STEPS_PER_EPOCH
- سيتم تفريغ النتيجة بعد كل عصر إلى المجلد. / logs/numberplate<date of launch> /
لاختبار النموذج المدربين في الممارسة ، في
أمثلة المشروع ، استبدل MASK_RCNN_MODEL_PATH بالمسار إلى النموذج الخاص بك.
تحسين المصنف لوحة ترخيص لمتطلباتك
بعد العثور على المناطق التي تحتوي على لوحات ترخيص ، تحتاج إلى محاولة تحديد حالة / نوع العدد الذي نتعرف عليه. هنا التعميم يعمل ضد جودة الاعتراف. لذلك ، من الناحية المثالية ، تحتاج إلى تدريب مصنف لا يحدد البلد الذي هو الرقم فحسب ، بل وأيضًا نوع تصميم هذا الرقم (موقع الأحرف ، خيارات الرمز لمجموعة متنوعة من الأرقام).
في مشروعنا ، قمنا بتنفيذ الدعم للاعتراف بأعداد أوكرانيا والاتحاد الروسي والأرقام الأوروبية بشكل عام. تعد جودة التعرف على الأرقام الأوروبية أسوأ قليلاً ، نظرًا لوجود أرقام ذات تصميمات مختلفة وعدد أكبر من الأحرف الموجودة. ربما ، بمرور الوقت ، ستكون هناك وحدات تمييز منفصلة لـ "eu-ee" ، "eu-pl" ، "eu-nl" ، ...
قبل تصنيف لوحة الترخيص ، تحتاج إلى "إخراجها" من الصورة وتطبيعها ، بمعنى آخر ، إزالة جميع التشوهات إلى الحد الأقصى والحصول على مستطيل أنيق سيخضع لمزيد من التحليل. تحولت هذه المهمة إلى أنها غير تافهة تمامًا ، حتى أنني اضطررت إلى تذكر الرياضيات المدرسية وكتابة تطبيق متخصص لخوارزمية تجميع الكتل :). الوحدة النمطية التي تعالج هذا تسمى RectDetector ، هكذا تبدو الأرقام الطبيعية ، والتي سنقوم بتصنيفها والتعرف عليها بشكل أكبر.

من أجل أتمتة عملية إنشاء مجموعة بيانات لتصنيف الأرقام بطريقة ما ، قمنا بتطوير
لوحة إدارة صغيرة على nodejs . باستخدام لوحة الإدارة هذه ، يمكنك وضع علامة على النقش على لوحة الترخيص والفئة التي تنتمي إليها.
يمكن أن يكون هناك العديد من المصنفات. في حالتنا ، حسب نوع العدد وما إذا كان يتم رسمه / رسمه في الصورة.
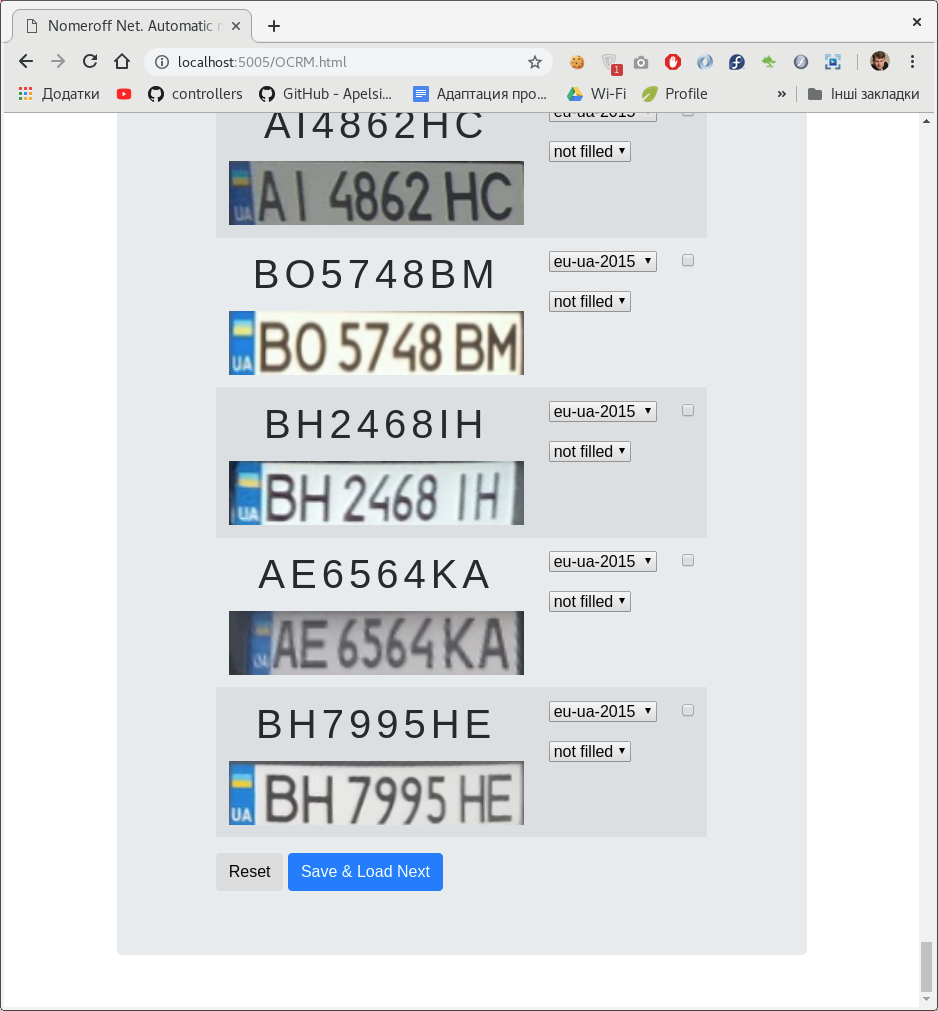
بعد أن وضعنا علامة على مجموعة البيانات ، قمنا بتقسيمها إلى عينات تدريب وإثبات وصحة. على سبيل المثال ، قم بتنزيل
مجموعة بيانات autoriaNumberplateOptions3Dataset-2019-05-20.zip لمعرفة كيف
يعمل كل شيء هناك.
نظرًا لأن الاختيار تم تحديده بالفعل (خاضع للإشراف) ، فأنت بحاجة إلى تغيير "isModerated": 1 إلى "isModerated": 0 في ملفات json عشوائية ثم قم بتشغيل لوحة المسؤول .
نحن ندرب المصنف:
سوف يساعدك برنامج التدريب النصي
/ options.ipynb في الحصول على نسختك من النموذج. يوضح مثالنا أنه بالنسبة لتصنيف المناطق / أنواع لوحات الترخيص ، حصلنا على دقة بلغت
98.8 ٪ ، لتصنيف "هل تم رسم الرقم؟"
99.4 ٪ على مجموعة البيانات الخاصة بنا. توافق ، اتضح بشكل جيد.
تدريب التعرف الضوئي على الحروف (التعرف على النص)
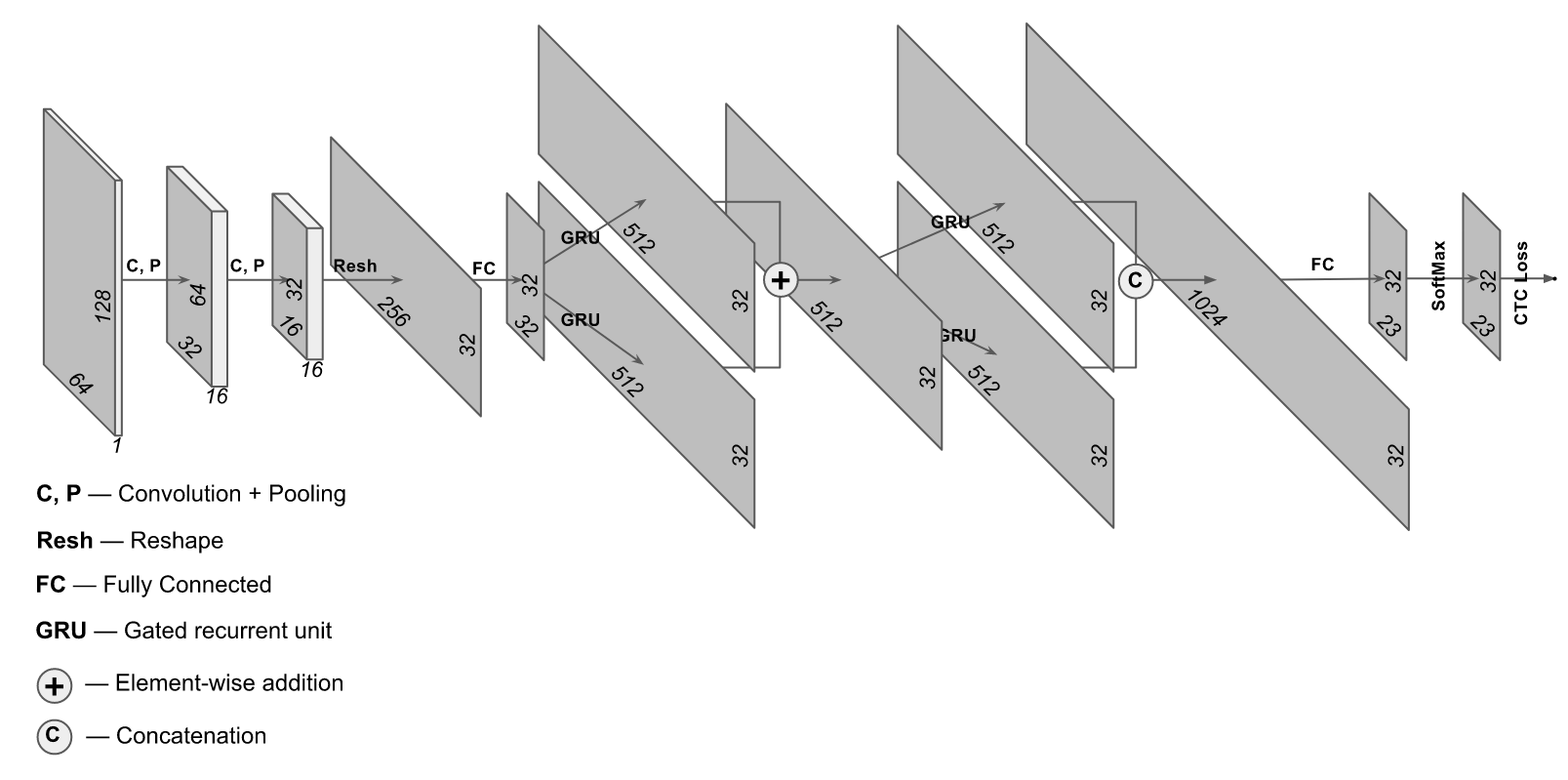
حسنًا ، وجدنا المنطقة ذات الرقم وقمنا بتطبيعها في مستطيل يحتوي على النقش الذي يحتوي على الرقم. كيف نقرأ النص؟ أسهل طريقة لتشغيلها من خلال FineReader أو Tesseract. ستكون الجودة "ليست غاية" ، لكن بدقة المنطقة ، حيث يمكنك الحصول على دقة تصل إلى 80٪. في الواقع ، هذه ليست دقة سيئة ، ولكن إذا قلت لك أنه يمكنك الحصول على
97 ٪ وفي الوقت نفسه تنفق موارد الكمبيوتر أقل بكثير؟ تبدو جيدة - دعنا نحاول. بنية غير عادية قليلاً مناسبة لهذه الأغراض ، حيث يتم استخدام كل من الطبقات التلافيفية والمتكررة. تبدو بنية هذه الشبكة مثل هذا:
تم تنفيذ التطبيق من الموقع
https://supervise.ly/ ، وقمنا بتعديله قليلاً للتدريب على الصور الحقيقية (على الموقع الإشرافي ، تم اختيار خيار لأخذ العينات الاصطناعية)
يبدأ الجزء الممتع الآن ، وضع علامة على 5000 رقم على الأقل :). وضعنا علامة على حوالي
100000 أوكراني ،
~ 50000 أوكراني مع التصميم "القديم" ،
~ 6500 أوروبي ،
~ 10000 RF . كان هذا الجزء الأكثر صعوبة في التطوير. لا يمكنك حتى أن تتخيل عدد المرات التي كنت فيها نائماً على كرسي الكمبيوتر الذي يدير عدة ساعات في اليوم للجزء التالي من الأرقام. لكن البطل الحقيقي
للعلامة هو
dimabendera - لقد حدد 2/3 من كل المحتوى ، (أعطه علامة زائد إذا كنت تفهم كم كان مملًا أن تفعل كل هذا العمل :))
يمكنك محاولة أتمتة هذه العملية بطريقة أو بأخرى ، على سبيل المثال ، بعد التعرف على كل صورة باستخدام Tesseract ، ثم تصحيح الأخطاء باستخدام
لوحة المشرف الخاصة بنا .
يرجى ملاحظة: يتم استخدام نفس لوحة المسؤول لتمييز المصنف و OCR على الرقم. يمكنك تحميل نفس البيانات هناك وهناك ، باستثناء الأرقام المخططة ، بالطبع.
إذا قمت بترميز 5000 رقم على الأقل ويمكنك تدريب OCR الخاص بك - لا تتردد في ترتيب جائزة لنفسك مع رؤسائك ، أنا متأكد من أن هذا الاختبار ليس مخصصًا للعيون!
الشروع في التدريب
يقوم
البرنامج النصي train / ocr-ru.ipynb بتدريب نموذج الأرقام الروسية ، وهناك أمثلة
لأوكرانيا وأوروبا .
يرجى ملاحظة أنه في إعدادات التدريب هناك حقبة واحدة فقط (تمريرة واحدة).
ستكون إحدى ميزات التدريب مثل مجموعة البيانات هذه نتيجة مختلفة تمامًا لكل محاولة ، قبل كل جلسة تدريب ، يتم خلط البيانات بترتيب عشوائي ، وأحيانًا تكون "غير جيدة" للتدريب. أنصحك بتجربة 5 مرات على الأقل ، مع التحكم في دقة بيانات الاختبار. من خلال محاولات إطلاق مختلفة ، قد تنقلب دقتنا من
87٪ إلى 97٪ .
بعض التوصيات :
- لا حاجة لتهيئة كل شيء بطريقة جديدة ، فقط أعد تشغيل نموذج الخط = ocrTextDetector.train (mode = MODE) حتى نحصل على النتيجة المتوقعة
- أحد أسباب ضعف الدقة هو عدم كفاية البيانات. إذا لم يعجبك ذلك ، فسنقوم بتمييزها مرارًا وتكرارًا ، وفي وقت ما تتوقف الجودة عن النمو ، ولكل مجموعة بيانات مختلفة ، يمكنك التركيز على عدد 10000 مثال مصنّف
- سيكون التدريب أسرع إذا كان لديك برنامج تشغيل NVIDIA CuDNN مثبتًا ، وقم بتغيير قيمة MODE = "gpu" في البرنامج النصي للتدريب وسيتم توصيل CuDNNGRU بدلاً من طبقة GRU ، مما سيؤدي إلى تسريع ثلاثة أضعاف.
قليلاً حول إعداد tensorflow لوحدات معالجة الرسومات NVIDIA
إذا كنت مالكًا سعيدًا لوحدة معالجة الرسومات من NVIDIA ، فيمكنك تسريع الأمور في بعض الأحيان: كلا من التدريب النموذجي وأرقام الاستدلال (وضع التعرف). المشكلة هي تثبيت وتجميع كل شيء بشكل صحيح.
نستخدم Fedora Linux على خوادم ML الخاصة بنا (حدث هذا تاريخياً).
التسلسل التقريبي للإجراءات لأولئك الذين يستخدمون نظام التشغيل هذا على النحو التالي:
إذا لم تتمكن من بناء tensorflow مع دعم gpu ، يمكنك تشغيل كل شيء من خلال عامل ميناء ، بالإضافة إلى عامل ميناء ، تحتاج إلى تثبيت حزمة nvidia-docker2. داخل حاوية عامل الميناء ، يمكنك تشغيل دفتر jupyter ، ثم تشغيل كل شيء هناك.
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
روابط مفيدة
أود أيضًا أن أشكر مراسلي 2expres ،
glassofkvass على تزويد الصور بالأرقام و
dimabendera لكتابة معظم الكود وترميز معظم البيانات من مشروع Nomeroff Net.
UPD1: منذ أن تم إرسال I و Dmitri إلى الأسئلة القياسية PM بشأن التعرف على الأرقام ، مزيج من tensorflow مع gpu ، إلخ. وديمتري وأعطي نفس الإجابات ، أريد تحسين هذه العملية بطريقة أو بأخرى.
نقترح جعل المراسلات في التعليقات أكثر تنظيماً ، مقسومةً على الموضوع. هناك وظائف مريحة على جيثب لهذا الغرض. في المستقبل ، يرجى طرح الأسئلة ليس في التعليقات ، ولكن في
القضية المواضيعية على جيثب Nomeroff NetUPD2: بمرور الوقت ، ظهرت مجموعات البيانات أيضًا:
أرقام الكازاخستانية والأرقام الجورجية