هل حدث لك أنك التزمت بنوع من اللعبة البسيطة ، معتقدة أن الذكاء الاصطناعي يمكن أن يتغلب عليها؟ اعتدت على ذلك ، وقررت أن أحاول إنشاء لاعب بوت. علاوة على ذلك ، هناك الآن العديد من الأدوات لرؤية الكمبيوتر والتعلم الآلي التي تسمح لك بإنشاء نماذج دون فهم عميق لتفاصيل التنفيذ. يمكن للبشر العاديين إنشاء نموذج أولي دون بناء شبكات عصبية لأشهر من الصفر.

ستجد في الجزء السفلي عملية إنشاء روبوت إثبات لمفهوم لعبة Clash Royale ، حيث استخدمت مكتبات Scala و Python و CV. باستخدام رؤية الكمبيوتر والتعلم الآلي ، حاولت إنشاء روبوت للعبة تتفاعل مثل اللاعب المباشر.
اسمي سيرجي Tolmachev ، أنا مطور برنامج Scala في منهاج Waves
وأدرس دورة Scala في Binary District ، وفي وقت فراغي أدرس تقنيات أخرى ، مثل الذكاء الاصطناعي. وأردت تعزيز المهارات المكتسبة مع بعض الخبرة العملية. على عكس مسابقات الذكاء الاصطناعي ، حيث تلعب روبوتك ضد روبوتات المستخدم الآخر ، يمكن أن يلعب Clash Royale ضد أشخاص ، الأمر الذي يبدو مضحكا. الروبوت الخاص بك يمكن أن يتعلم التغلب على لاعبين حقيقيين!
ميكانيكا اللعبة في Clash Royale
آليات اللعبة بسيطة جدا. لديك وخصمك ثلاثة مبانٍ: حصن وبرجان. يقوم اللاعبون قبل اللعبة بجمع الطوابق - 8 وحدات متوفرة ، والتي يتم استخدامها بعد ذلك في المعركة. لديهم مستويات مختلفة ، ويمكن ضخها ، وجمع المزيد من بطاقات هذه الوحدات وشراء التحديثات.
بعد بدء اللعبة ، يمكنك وضع الوحدات المتاحة على مسافة آمنة من أبراج العدو ، بينما تنفق وحدات من مانا ، والتي يتم استعادتها ببطء أثناء اللعبة. يتم إرسال الوحدات إلى مباني العدو وتشتت انتباه الأعداء الذين يواجهونها على طول الطريق. يمكن للاعب التحكم فقط في الوضع الأولي للوحدات - يمكنه التأثير على حركتها وتلفها فقط من خلال تعيين وحدات أخرى.
لا تزال هناك نوبات يمكن لعبها في أي مكان في هذا المجال ، فهي عادة ما تسبب أضرارًا للوحدات بطرق مختلفة. تعاويذ يمكن استنساخ ، تجميد ، أو تسريع الوحدات في المنطقة.
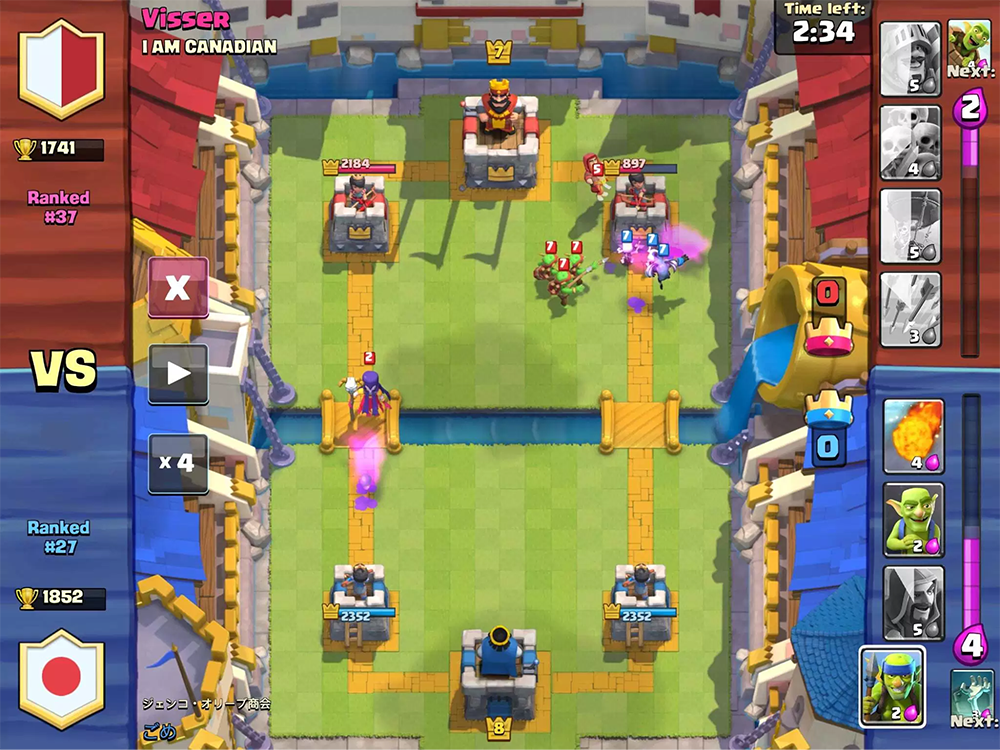
الهدف من اللعبة هو تدمير مباني العدو. لتحقيق النصر الكامل ، يجب عليك تدمير القلعة أو بعد دقيقتين من اللعبة تدمير المزيد من المباني (تعتمد القواعد على أوضاع اللعبة ، ولكن بشكل عام يبدو أنها مثل هذا).
أثناء اللعبة ، تحتاج إلى أن تأخذ في الاعتبار حركة الوحدات ، والعدد المحتمل من مانا وبطاقات العدو الحالية. تحتاج أيضًا إلى التفكير في كيفية تأثير تركيب الوحدة على الملعب.
بناء الحل
Clash Royale هي لعبة محمولة ، لذلك قررت تشغيلها على Android والتفاعل معها من خلال ADB. هذا من شأنه أن يدعم العمل مع جهاز محاكاة أو مع جهاز حقيقي.
قررت أن الروبوت ، مثل العديد من الذكاء الاصطناعى للعبة ، يجب أن يعمل على خوارزمية التصور - التحليل - العمل. يتم عرض البيئة بأكملها في اللعبة على الشاشة ، ويحدث التفاعل معها من خلال النقر على الشاشة. لذلك ، يجب أن يكون الروبوت عبارة عن برنامج ، يصف مدخلاته الحالة الحالية للعبة: موقع وخصائص الوحدات والمباني ، والبطاقات الممكنة الحالية ومقدار مانا. عند الخرج ، ينبغي أن يعطي الروبوت مجموعة من الإحداثيات حيث يجب تسجيل الوحدة.
ولكن قبل إنشاء الروبوت نفسه ، كان من الضروري حل مشكلة استخراج المعلومات حول الوضع الحالي للعبة من لقطة الشاشة. بشكل عام ، يتم تخصيص المحتوى الإضافي لهذه المقالة لهذه المهمة.
لحل هذه المشكلة ، قررت استخدام Computer Vision. ربما ليس هذا هو الحل الأفضل: من الواضح أن السيرة الذاتية التي لا تتمتع بالكثير من الخبرة والموارد لها حدود ولا يمكنها التعرف على كل شيء على المستوى الإنساني.
سيكون من الأكثر دقة أخذ البيانات من الذاكرة ، لكن لم يكن لدي مثل هذه التجربة. مطلوب الجذر وعموما هذا الحل يبدو أكثر تعقيدا. ومن غير الواضح أيضًا ما إذا كان يمكن تحقيق السرعة في الوقت الفعلي هنا إذا كنت تبحث عن كائنات بها كومة JVM داخل الجهاز. بالإضافة إلى ذلك ، أردت حل مشكلة السيرة الذاتية أكثر من هذا.
من الناحية النظرية ، يمكن للمرء إنشاء خادم وكيل وأخذ المعلومات من هناك. لكن بروتوكول الشبكة الخاص باللعبة يتغير غالبًا ، يظهر الوكلاء على الإنترنت ، لكن سرعان ما يصبح قديمًا وغير معتمد.
موارد اللعبة المتاحة
بادئ ذي بدء ، قررت التعرف على المواد المتاحة من اللعبة. لقد وجدت
ناديًا من الحرفيين يسحبون موارد اللعبة المعبأة
[1] [2] . بادئ ذي بدء ، كنت مهتمًا بصور الوحدات ، لكن في حزمة الألعاب غير المعبأة ، يتم تقديمها في شكل خريطة تجانب (تتكون الأجزاء منها من وحدة).
لقد عثرت أيضًا على نصوص لاصقة (وإن لم تكن مثالية) لإطارات الرسوم المتحركة للوحدة - كانت مفيدة في تدريب نموذج التعرف.

بالإضافة إلى ذلك ، في الموارد ، يمكنك العثور على ملف csv مع بيانات اللعبة المختلفة - مقدار HP ، والأضرار التي لحقت بوحدات من مستويات مختلفة ، وما إلى ذلك. هذا مفيد عند إنشاء منطق البوت. على سبيل المثال ، اتضح من البيانات أن الحقل تم تقسيمه إلى 18 × 29 خلية ، ولا يمكن وضع الوحدات عليها إلا. كانت هناك أيضًا جميع صور خرائط الوحدات ، والتي ستكون مفيدة لنا لاحقًا.
رؤية الكمبيوتر للكسول
بعد البحث عن حلول السيرة الذاتية المتاحة ، أصبح من الواضح أنه في أي حال ، سيتعين تدريبهم على مجموعة بيانات تحمل علامات. لقد التقطت لقطات شاشة وكنت جاهزًا بالفعل لتحديد عدد معين من لقطات الشاشة بيدي. هذا تبين أن مهمة شاقة.
استغرق العثور على برامج التعرف المتاحة بعض الوقت. أنا استقر على
labelImg . كانت جميع تطبيقات التعليقات التوضيحية التي وجدتها بدائية إلى حد ما: لم يدعم الكثير منها اختصارات لوحة المفاتيح ، وأصبح اختيار الكائنات وأنواعها أقل ملاءمة بكثير من التسمية.
أثناء الترميز ، تبين أنه من المفيد الحصول على الكود المصدري للتطبيق. أخذت لقطات كل بضع ثوان من المباراة. هناك العديد من الكائنات في لقطات الشاشة (على سبيل المثال ، جيش من الهياكل العظمية) ، وقمت بإجراء تعديل في labelImg - افتراضيًا ، عند وضع علامة على الصورة التالية ، تم التقاط الملصقات من السابقة. في كثير من الأحيان ، كان يتعين عليهم ببساطة نقلهم إلى موضع جديد للوحدات ، وإزالة الوحدات الميتة وإضافة عدد قليل ظهر ، وليس علامة من الصفر.

اتضح أن العملية كانت كثيفة الاستخدام للموارد - في غضون يومين في الوضع الهادئ ، نشرت حوالي 200 لقطة شاشة. تبدو العينة صغيرة جدًا ، لكنني قررت البدء بالتجربة. يمكنك دائمًا إضافة المزيد من الأمثلة وتحسين جودة النموذج.
في وقت الترميز ، لم أكن أعرف أي أداة تدريب سأستخدمها ، لذلك قررت حفظ نتائج الترميز بتنسيق VOC - أحد التنسيقات المحافظة والتي تبدو عالمية.
قد يطرح السؤال التالي: لماذا لا تبحث فقط عن صور وحدات البكسل بوحدات بكسل عن طريق الصدفة الكاملة؟ تكمن المشكلة في أنه يجب على المرء أن يبحث عن عدد كبير من الإطارات المختلفة للرسوم المتحركة لوحدات مختلفة. سيكون بالكاد العمل. أردت أن أقوم بحل عالمي يدعم أذونات مختلفة. بالإضافة إلى ذلك ، يمكن أن يكون للوحدات لون مختلف حسب التأثير المطبق عليها - التجميد والتسارع.
لماذا اخترت YOLO
بدأت في استكشاف الحلول الممكنة للتعرف على الصور. نظرت إلى تطبيق الخوارزميات المختلفة: OpenCV ، TensorFlow ، Torch. أردت أن أقدم اعترافًا بأسرع وقت ممكن ، حتى أضحي بالدقة ، وأحصل على نقطة POC في أسرع وقت ممكن.
بعد قراءة
المقالات ، أدركت أن مهمتي لا تتناسب مع المصنفات HOG / LBP / SVM / HAAR / .... على الرغم من أنها سريعة ، إلا أنه يجب تطبيقها عدة مرات - وفقًا لمصنف كل وحدة - ثم واحدة تلو الأخرى لتطبيقها على الصورة للبحث. بالإضافة إلى ذلك ، فإن مبدأ عملها من الناحية النظرية سيعطي نتائج سيئة: يمكن أن يكون للوحدات شكل مختلف ، على سبيل المثال ، عند التحرك من اليسار إلى الأعلى.
من الناحية النظرية ، باستخدام شبكة العصبية ، يمكنك تطبيقها مرة واحدة على صورة والحصول على جميع الوحدات من أنواع مختلفة مع موضعها ، لذلك بدأت في البحث عن الشبكات العصبية. وجد TensorFlow دعمًا للشبكات العصبية التلافيفية (CNN). اتضح أنه ليس من الضروري تدريب الشبكات العصبية من نقطة الصفر - يمكنك
إعادة تدريب الشبكة القوية الحالية .
ثم وجدت خوارزمية YOLO أكثر عملية تعد بدرجة أقل من التعقيد ، وبالتالي اضطررت إلى توفير خوارزمية بحث عالية السرعة دون التضحية بكثير من الدقة (وفي بعض الحالات ، تجاوز النماذج الأخرى).
يعد
موقع YOLO الإلكتروني بفارق كبير في السرعة باستخدام النموذج الصغير والشبكة الأصغر والأفضل. يتيح لك YOLO أيضًا إعادة تدريب الشبكة العصبية
المكتملة لمهمتك ، و
darknet - إطار عمل
مفتوح المصدر لاستخدام خلايا عصبية مختلفة قام مطوروها بتطوير YOLO - هو تطبيق C أصلي بسيط ، وكل العمل معها يتم من خلال مكالمات المعلمات الخاصة به.
TensorFlow ، المكتوب بلغة Python ، هو في الواقع مكتبة Python ويستخدم باستخدام البرامج النصية المكتوبة ذاتيا التي تحتاجها لمعرفة أو صقلها لتناسب احتياجاتك. ربما ، بالنسبة للبعض ، تعتبر مرونة TensorFlow ميزة إضافية ، لكن دون الخوض في التفاصيل ، يصعب أخذها واستخدامها بسرعة. لذلك ، في مشروعي ، وقع الاختيار على YOLO.
بناء نموذج
للعمل على التدريب النموذجي ، قمت بتثبيت Ubuntu 18.10 ، وسلمت حزم التجميع ، وحزمة OpenCL من NVIDIA وغيرها من التبعيات ، وقمت بتصميم darknet.
يحتوي Github على
قسم به خطوات بسيطة لإعادة تدريب نموذج YOLO : تحتاج إلى تنزيل النموذج والتكوينات وتغييرها وبدء إعادة التدريب.
أردت أولاً محاولة إعادة تدريب نموذج YOLO بسيط ، ثم Tiny ومقارنتها. ومع ذلك ، اتضح أنه لتدريب الطرز البسيطة ، أنت بحاجة إلى ذاكرة بطاقة فيديو بسعة 4 جيجابايت ، ولم يكن لدي سوى بطاقة رسومات NVIDIA GeForce GTX 1060 بسعة 3 جيجابايت تم شراؤها للألعاب. لذلك ، كنت قادراً على تدريب نموذج Tiny فقط على الفور.
تم ترميز الوحدات على الصور التي
أمتلكها بتنسيق VOC ، وعملت YOLO بتنسيقها الخاص ، لذلك استخدمت أداة
convert2Yolo لتحويل ملفات التعليقات التوضيحية.
بعد ليلة من التدريب في 200 لقطة شاشة ، حصلت على النتائج الأولى ، وفاجأوني - كان النموذج حقًا قادرًا على التعرف على شيء صحيح! أدركت أنني كنت أسير في الاتجاه الصحيح ، وقررت أن أفعل المزيد من الأمثلة التعليمية.

لم أكن أرغب في الاستمرار في عرض لقطات الشاشة ، وتذكرت الإطارات من الرسوم المتحركة للوحدة. قمت بتمييز جميع الصور الصغيرة مع فصولهم وحاولت تدريب الشبكة على هذه المجموعة. كانت النتيجة سيئة للغاية. أفترض أن النموذج لم يتمكن من تحديد الأنماط الصحيحة من الصور الصغيرة لاستخدامها في الصور الكبيرة.
بعد ذلك ، قررت أن أضعها على خلفيات جاهزة لساحات المعارك وأنشئ ملف ترميز VOC برمجياً. اتضح مثل هذه لقطة الاصطناعية مع تخطيط دقيق بنسبة 100 ٪ التلقائي.
كتبت نصًا في Scala يقسم لقطة الشاشة إلى 16 مربعًا 4 × 4 ويضع الوحدات في وسطها بحيث لا تتقاطع مع بعضها البعض. سمح لي البرنامج النصي أيضًا بتخصيص إنشاء نماذج تدريبية - عند حدوث الضرر ، يتم رسم الوحدات باللون الخاص بفريقها (أحمر / أزرق) ، وخلال التصنيف ، أتعرف بشكل منفصل على وحدات بألوان مختلفة. بالإضافة إلى تلطيخ ، وحدات من الفرق المختلفة التي تلقت الضرر لديها اختلافات طفيفة في الملابس. أيضًا ، قمت بزيادة الوحدات ونقصتها بشكل عشوائي ، بحيث تعلم النموذج عدم الاعتماد على حجم الوحدة كثيرًا. نتيجة لذلك ، تعلمت كيفية إنشاء عشرات الآلاف من الأمثلة التدريبية التي تشبه تقريبًا لقطات الشاشة الحقيقية.
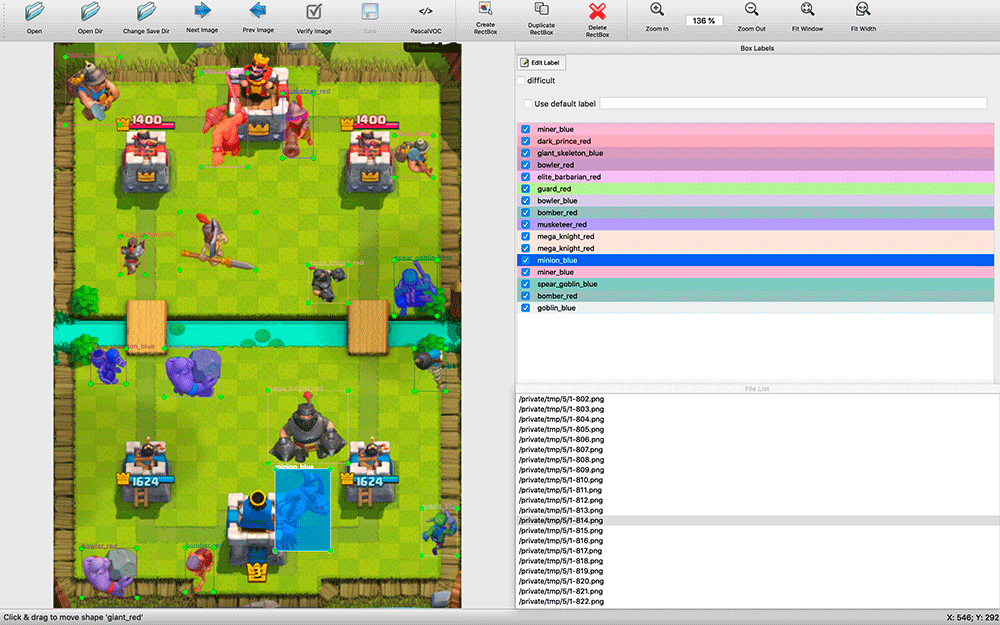
الجيل لم يكن مثاليا. غالبًا ما كانت الوحدات موضوعة فوق المباني ، على الرغم من أنها كانت وراءها ؛ لم تكن هناك أمثلة للأجزاء المتداخلة من الوحدة ، رغم أن هذا ليس موقفًا نادرًا في اللعبة. لكن حتى الآن قررت إهمالها.

النموذج الذي تم الحصول عليه بعد عدة ليال من التدريب على مزيج من 200 لقطة حقيقية و 5000 صورة تم إنشاؤها أثناء عملية التدريب مرة واحدة يوميًا ، عندما تم اختباره على هذه اللقطات ، أعطى نتائج سيئة. ليس من المستغرب ، لأن الصور التي تم إنشاؤها لها الكثير من الاختلافات عن الصور الحقيقية.
لذلك ، وضعت النموذج الناتج لإعادة تدريب على عينة متوسطة ، حيث لم يكن هناك سوى 200 من لقطات الشاشة الخاصة بي. بعد ذلك ، بدأت العمل بشكل أفضل.
اللعنة العارأعتذر عن التعامل مع مثل هذه الإجراءات غير العلمية بأنها "أفضل بكثير" ، لكنني لا أعرف كيفية التحقق من صحة الصور بسرعة ، لذلك جربت لقطات شاشة متعددة من مجموعة غير تدريبية ونظرت لمعرفة ما إذا كانت النتائج ترضي. هذا هو الشيء الأكثر أهمية. نحن كسول ونقوم بعمل نموذج أولي ، أليس كذلك؟
كانت الخطوات التالية لتحسين النموذج مفهومة - قم بترميز لقطات أكثر واقعية وتدريبهم على النموذج ، وتم تدريبهم مسبقًا على لقطات الشاشة التي تم إنشاؤها.
دعنا ننكب على الروبوت
قررت أن أكتب روبوتًا في Python - به العديد من الأدوات المتاحة لـ ML. قررت استخدام طرازي مع OpenCV ، والذي
تعلم من
3.5 استخدام نماذج الشبكة العصبية ، وحتى أنني وجدت
مثالًا بسيطًا . بعد أن جربت العديد من المكتبات للعمل مع ADB ، اخترت
python-adb النقي - كل ما أحتاجه يتم تنفيذه ببساطة هناك: وظيفة التقاط الشاشة والعملية على جهاز shell ؛ أنا اضغط باستخدام "اضغط المدخلات".
لذلك ، بعد تلقي لقطة شاشة للعبة ، والتعرف على الوحدات عليها والتلصص عليها على الشاشة ، واصلت العمل على التعرف على حالة اللعبة. بالإضافة إلى الوحدات ، كنت بحاجة إلى التعرف على مستوى مانا الحالي والبطاقات المتاحة للاعب.
يتم عرض مستوى مانا في اللعبة كشريط التقدم والأرقام. وبدون تفكير مرتين ، بدأت في خفض العدد
والانعكاس والاعتراف باستخدام
pytesseract .
لتحديد البطاقات المتاحة
وموضعها ، استخدمت
كاشف keypoint KAZE من OpenCV . حتى الآن لم أكن أرغب في العودة إلى تعلم الشبكة العصبية مرة أخرى ، واخترت طريقة كانت أسرع وأسهل ، رغم أنه تبين في النهاية أنها تتمتع بالحد الأدنى من الدقة الكافية في الحالة عندما تحتاج إلى البحث عن العديد من الكائنات.
عند بدء الروبوت ، قمت بحساب نقاط المفاتيح لجميع صور الخريطة (هناك عدة عشرات في المجموع) ، وخلال اللعبة بحثت عن مطابقات لجميع البطاقات مع منطقة بطاقة اللاعب لتقليل عدد الأخطاء وزيادة السرعة. تم فرزها حسب الدقة والتنسيق
x للحصول على ترتيب الخرائط - معلومات حول كيفية وجودها على الشاشة.
بعد أن لعبت قليلاً مع المعلمات ، حصلت في الواقع على الكثير من الأخطاء ، على الرغم من أن بعض الصور المعقدة للبطاقات ، والتي كانت مخطئة أحيانًا للآخرين من قبل الخوارزمية ، تم التعرف عليها بدقة عالية. اضطررت إلى إضافة مخزن مؤقت مكون من ثلاثة عناصر: إذا حصلنا على ثلاث قيم متتالية في نفس القيم ، فإننا نعتقد أنه يمكننا الوثوق بها.

بعد تلقي جميع المعلومات اللازمة (الوحدات والموقع التقريبي لها ، مانا والبطاقات المتاحة) ، يمكنك اتخاذ بعض القرارات.
بادئ ذي بدء ، قررت أن تأخذ شيئًا بسيطًا: على سبيل المثال ، إذا كان هناك مانا كافٍ على بطاقة يمكن الوصول إليها ، فقم بتشغيلها في الحقل. ولكن لا يزال الروبوت لا يعرف كيفية "تشغيل" البطاقات - فهو يعرف البطاقات التي لدينا ، وأين يوجد الحقل ، تحتاج إلى النقر على البطاقة المطلوبة ، ثم على الخلية المطلوبة في الحقل.
معرفة دقة لقطة الشاشة ، يمكنك فهم إحداثيات الخريطة وخلية الحقل المطلوبة. لقد ربطت الآن دقة الشاشة بدقة ، لكن إذا لزم الأمر ، يمكنني تجاهل ذلك. تقوم وظيفة القرار بإرجاع مجموعة من الصنابير التي يجب القيام بها في المستقبل القريب. بشكل عام ، سيكون روبوتنا حلقة لا نهائية (مبسطة):
: = : ( ) : = () = () = () += (, , , )
حتى الآن ، يمكن للبوت أن يضع الوحدات عند نقطة واحدة فقط ، ولكن لديه بالفعل معلومات كافية لبناء إستراتيجية أكثر تعقيدًا.
المشاكل الأولى
في الواقع ، واجهت مشكلة غير متوقعة وغير سارة للغاية. يستغرق إنشاء لقطة من خلال ADB حوالي 100 مللي ثانية ، مما يوفر تأخيرًا كبيرًا - لقد اعتمدت على مثل هذا التأخير الأقصى ، مع مراعاة جميع العمليات الحسابية واختيار الإجراء ، ولكن ليس في خطوة واحدة لإنشاء لقطة. لا يمكن العثور على حل بسيط وسريع. من الناحية النظرية ، باستخدام محاكي Android ، يمكنك التقاط لقطات شاشة مباشرة من نافذة التطبيق ، أو يمكنك إنشاء أداة لبث الصور من هاتف مع ضغط عبر UDP وتوصيل الروبوت به ، لكنني أيضًا لم أجد حلولاً سريعة هنا.
اذن
بعد أن قمت بتقييم حالة مشروعي بوعي ، قررت أن أتناول هذا النموذج في الوقت الحالي. قضيت عدة أسابيع من وقت فراغي في القيام بذلك ، والتعرّف على الوحدة هو جزء فقط من طريقة اللعب.
قررت تطوير أجزاء البوت بالتدريج - لجعل منطق الإدراك الأساسي ، ثم المنطق البسيط للعبة والتفاعل مع اللعبة ، وبعد ذلك سيكون من الممكن تحسين الأجزاء الفرعية المنبثقة من البوت. عندما يصبح مستوى نموذج التعرف على الوحدة كافيًا ، يمكن أن تؤدي إضافة معلومات حول HP ومستوى الوحدات إلى تطوير تطوير اللعبة إلى مرحلة جديدة تمامًا. ربما يكون هذا هو الهدف التالي ، ولكن بالتأكيد لا يستحق الأمر التركيز على هذه المهمة.
مستودع مشروع جيثبلقد قضيت الكثير من الوقت في المشروع ، وبصراحة ، لقد سئمت من ذلك ، لكنني لست نادما على ذلك - حصلت على تجربة جديدة في ML / CV.
ربما سأعود إليه لاحقًا - سأكون سعيدًا إذا انضم لي أحدهم. إذا كنت مهتمًا ، فقم بالانضمام إلى المجموعة على
Telegram ،
وتوجه أيضًا إلى
دورة Scala الخاصة بي.