نحن البيانات الكبيرة في MTS وهذا هو أول وظيفة لدينا. سنتحدث اليوم عن التقنيات التي تسمح لنا بتخزين ومعالجة البيانات الضخمة بحيث تتوفر دائمًا موارد كافية للتحليلات ، ولا تذهب تكلفة شراء الحديد إلى ارتفاع السماء.
لقد فكروا في إنشاء مركز البيانات الكبيرة في MTS في عام 2014: كانت هناك حاجة لتوسيع نطاق التخزين التحليلي الكلاسيكي وإعداد تقارير BI عليه. في ذلك الوقت ، كانت معالجة البيانات ومحرك BI هي SAS - لقد حدث ذلك تاريخيًا. وعلى الرغم من أن احتياجات العمل للتخزين قد تم إغلاقها ، إلا أنه مع مرور الوقت ، نمت وظائف BI والتحليلات المخصصة بالإضافة إلى التخزين التحليلي بدرجة كبيرة لدرجة أنه كان من الضروري حل مشكلة زيادة الإنتاجية ، على مدار السنوات الماضية زاد عدد المستخدمين عشر مرات.
نتيجة المسابقة ، ظهر نظام Teradata MPP في النظام التجاري المتعدد الأطراف ، وهو يغطي احتياجات الاتصالات في ذلك الوقت. كان هذا هو الدافع لمحاولة شيء أكثر شعبية ومفتوحة المصدر.
 في الصورة - فريق Big Data MTS في مكتب ديكارت الجديد في موسكو
في الصورة - فريق Big Data MTS في مكتب ديكارت الجديد في موسكو المجموعة الأولى كانت من 7 عقد. كان هذا كافياً لاختبار العديد من الفرضيات التجارية والأشياء الأولى. الجهود لم تذهب سدى: البيانات الكبيرة موجودة في النظام التجاري المتعدد الأطراف لمدة ثلاث سنوات ، والآن تحليل البيانات يشارك في جميع المجالات الوظيفية تقريبا. نما الفريق من ثلاث إلى مائتي.
أردنا أن يكون لدينا عمليات تطوير سهلة ، واختبار الفرضيات بسرعة. للقيام بذلك ، تحتاج إلى ثلاثة أشياء: فريق لديه تفكير في بدء التشغيل ، وعمليات تطوير خفيفة الوزن وبنية تحتية متطورة. هناك الكثير من الأماكن التي يمكنك من خلالها قراءة والاستماع عن الأول والثاني ، ولكن الأمر يستحق أن نبينه حول البنية التحتية المتقدمة بشكل منفصل ، لأن المصادر القديمة ومصادر البيانات الموجودة في الاتصالات مهمة هنا. البنية الأساسية للبيانات المتقدمة لا تقوم فقط ببناء بحيرة بيانات وطبقة بيانات مفصلة وطبقة واجهة المتجر. ويشمل أيضًا أدوات وواجهات وصول إلى البيانات ، وعزل موارد الحوسبة للمنتجات والأوامر ، وآليات لتسليم البيانات للمستهلكين - في الوقت الفعلي وفي وضع الدُفعات. وأكثر من ذلك بكثير.
برز كل هذا العمل في منطقة منفصلة ، تعمل في مجال تطوير المرافق وأدوات البيانات. هذه المنطقة تسمى منصة تكنولوجيا البيانات الكبيرة.
من أين تأتي البيانات الكبيرة في النظام التجاري المتعدد الأطراف
MTS لديه الكثير من مصادر البيانات. واحدة من المحطات الرئيسية هي المحطات الأساسية ؛ نحن نخدم قاعدة المشتركين لأكثر من 78 مليون مشترك في روسيا. لدينا أيضًا العديد من الخدمات التي لا تتعلق بالاتصالات وتسمح لك بتلقي المزيد من البيانات متعددة الاستخدامات (التجارة الإلكترونية ، تكامل النظام ، إنترنت الأشياء ، الخدمات السحابية ، وما إلى ذلك - جميع "غير الاتصالات" تحقق بالفعل حوالي 20٪ من إجمالي الإيرادات).
باختصار ، يمكن تمثيل الهندسة المعمارية لدينا مثل هذا الرسم البياني:
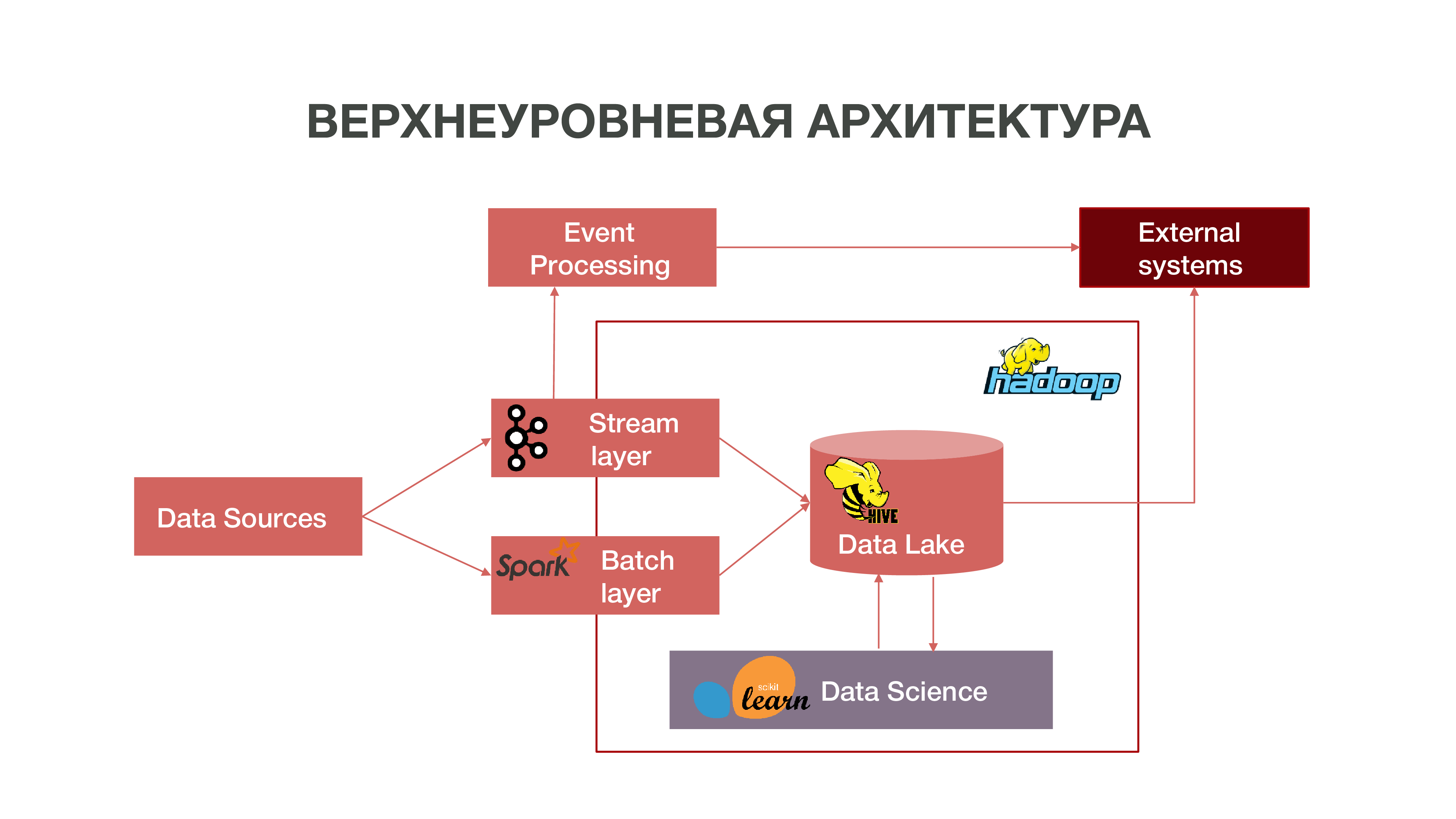
كما ترون على الرسم البياني ، يمكن لـ Datasources تقديم المعلومات في الوقت الحقيقي. نحن نستخدم طبقة البث - يمكننا معالجة المعلومات في الوقت الفعلي ، واستخراج بعض الأحداث التي تهمنا ، وبناء التحليلات على ذلك. من أجل توفير معالجة الأحداث هذه ، قمنا بتطوير تطبيق قياسي إلى حد ما (من وجهة نظر الهندسة المعمارية) باستخدام Apache Kafka و Apache Spark والرمز بلغة Scala. يمكن استهلاك المعلومات التي تم الحصول عليها نتيجة لهذا التحليل داخل النظام التجاري المتعدد الأطراف وفي المستقبل في الخارج: غالبًا ما يهتم النشاط التجاري بحقيقة بعض الإجراءات الخاصة بالمشتركين.
هناك أيضًا طريقة لتحميل البيانات في طبقة الدُفعات - الدُفعات. عادةً ما يتم التنزيل مرة واحدة في الساعة وفقًا لجدول زمني ، نستخدم Apache Airflow كجدول زمني ، ويتم تنفيذ عمليات تنزيل الدُفعات نفسها في بيثون. في هذه الحالة ، يتم تحميل كمية أكبر بكثير من البيانات في Data Lake ، وهو أمر ضروري لتعبئة البيانات الكبيرة بالبيانات التاريخية ، والتي يجب تدريب نماذج علم البيانات الخاصة بنا عليها. نتيجة لذلك ، يتم تشكيل ملف تعريف المشترك في السياق التاريخي استنادًا إلى بيانات نشاط الشبكة الخاص به. هذا يسمح لنا بالحصول على إحصائيات تنبؤية وبناء نماذج من السلوك البشري ، وحتى إنشاء صورة نفسية له - لدينا مثل هذا المنتج المنفصل. هذه المعلومات مفيدة للغاية ، على سبيل المثال ، لشركات التسويق.
لدينا أيضًا كمية كبيرة من البيانات التي تشكل المستودع الكلاسيكي. أي أننا نجمع المعلومات حول الأحداث المختلفة - المستخدم والشبكة. تساعد كل هذه البيانات مجهولة المصدر أيضًا على التنبؤ بمزيد من الدقة في اهتمامات المستخدم والأحداث المهمة للشركة - على سبيل المثال ، للتنبؤ بعطل المعدات المحتمل واستكشاف الأخطاء وإصلاحها في الوقت المناسب.
Hadoop
إذا نظرت إلى الماضي وتذكرت مدى ظهور البيانات الضخمة بشكل عام ، تجدر الإشارة إلى أنه تم تنفيذ تراكم البيانات بشكل أساسي لأغراض التسويق. لا يوجد تعريف واضح لمثل هذه البيانات الضخمة - إنها غيغابايت ، تيرابايت ، بيتابايت. من المستحيل رسم خط. بالنسبة للبعض ، البيانات الكبيرة هي عشرات الجيجابايت ، والبعض الآخر ، البيجابايت.
لقد حدث أنه مع مرور الوقت تراكمت الكثير من البيانات في جميع أنحاء العالم. ومن أجل إجراء نوع من التحليل الأكثر أهمية إلى حد ما لهذه البيانات ، لم تعد المستودعات المعتادة التي تطورت منذ سبعينيات القرن الماضي كافية. عندما بدأت مجموعة المعلومات في العقد الأول من القرن العشرين ، وفي العشرينيات من القرن الماضي ، وعندما كان هناك الكثير من الأجهزة التي كان لديها وصول إلى الإنترنت ، وعندما ظهر إنترنت الأشياء ، لم تتمكن هذه المستودعات من التعامل مع المفاهيم. كان أساس هذه المستودعات النظرية العلائقية. بمعنى ، كانت هناك علاقات بأشكال مختلفة تتفاعل مع بعضها البعض. كان هناك نظام لوصف كيفية بناء وتصميم المستودعات.
عندما تفشل التقنيات القديمة ، تظهر تقنيات جديدة. في العالم الحديث ، يتم حل مشكلة تحليلات البيانات الكبيرة بطريقتين:
إنشاء إطار العمل الخاص بك الذي يسمح لك بمعالجة كميات كبيرة من المعلومات. عادةً ما يكون هذا تطبيقًا موزعًا على مئات الآلاف من الخوادم - مثل Google ، Yandex ، التي أنشأت قواعد البيانات الموزعة الخاصة بها والتي تسمح لك بالعمل مع هذا الحجم من المعلومات.
إن تطوير تقنية Hadoop هو إطار عمل للحوسبة الموزعة ، وهو نظام ملفات موزع يمكنه تخزين ومعالجة كمية كبيرة جدًا من المعلومات. أدوات علم البيانات متوافقة بشكل أساسي مع Hadoop وهذا التوافق يفتح العديد من الاحتمالات لتحليل البيانات المتقدمة. العديد من الشركات ، بما في ذلك ، تتجه نحو النظام Hadoop مفتوح المصدر.
تقع مجموعة Hadoop المركزية في نيجني نوفغورود. أنه يجمع المعلومات من جميع مناطق البلاد تقريبا. من حيث الحجم ، يمكن الآن تنزيل حوالي 8.5 بيتابايت من البيانات. أيضا في موسكو ، لدينا مجموعات RND منفصلة حيث نجري تجارب.
نظرًا لأن لدينا حوالي ألف خادم في مناطق مختلفة ، حيث نجري التحليلات ، كما يتم التخطيط للتوسع ، فإن السؤال الذي يطرح نفسه هو الاختيار الصحيح للمعدات للأنظمة التحليلية الموزعة. يمكنك شراء معدات تكفي لتخزين البيانات ، ولكن تبين أنها غير مناسبة للتحليلات - ببساطة لأنه لن يكون هناك ما يكفي من الموارد ، وعدد مراكز وحدة المعالجة المركزية وذاكرة الوصول العشوائي المجانية على العقد. من المهم إيجاد توازن من أجل الحصول على فرص تحليل جيدة وليس تكاليف معدات مرتفعة للغاية.
قدمت لنا Intel خيارات مختلفة حول كيفية تحسين العمل باستخدام نظام موزع حتى يمكن الحصول على التحليلات في حجم بياناتنا مقابل أموال معقولة. تقنية Intel Advances NAND SSD لمحركات الأقراص الصلبة إنه أسرع بمئات المرات من الأقراص الصلبة العادية. مما هو جيد بالنسبة لنا: يوفر SSD ، خاصة مع واجهة NVMe ، وصولاً سريعًا بدرجة كافية إلى البيانات.
بالإضافة إلى ذلك ، أصدرت Intel محركات أقراص SSD لخادم Intel Optane SSD استنادًا إلى النوع الجديد من الذاكرة غير المتطايرة Intel 3D XPoint. إنهم يتعاملون مع الأحمال المختلطة المركزة على نظام التخزين ، ولديهم مورد أطول من محركات أقراص الحالة الصلبة العادية NAND. لماذا هو جيد بالنسبة لنا: يتيح لك Intel Optane SSD العمل بثبات تحت أحمال ثقيلة مع زمن انتقال منخفض. نظرنا مبدئيًا إلى NAND SSD كبديل لمحركات الأقراص الصلبة التقليدية ، لأن لدينا كمية كبيرة جدًا من البيانات تتحرك بين القرص الصلب وذاكرة الوصول العشوائي - ونحن بحاجة إلى تحسين هذه العمليات.
الاختبار الأول
أول اختبار أجريناه في عام 2016. لقد اتخذنا للتو وحاولنا استبدال HDD بسرعة SSD NAND. للقيام بذلك ، طلبنا عينات من محرك Intel الجديد - في ذلك الوقت كان DC P3700. وقد أجروا الاختبار القياسي لـ Hadoop - نظام بيئي يسمح لك بتقييم كيفية تغير الأداء في ظروف مختلفة. هذه هي اختبارات موحدة TeraGen ، TeraSort ، TeraValidate.

يسمح لك TeraGen "بإنشاء" بيانات اصطناعية من حجم معين. على سبيل المثال ، أخذنا 1 غيغابايت و 1 تيرابايت. مع TeraSort ، قمنا بتصنيف هذا الكم من البيانات في Hadoop. هذه عملية كثيفة الاستخدام للموارد. ويتيح لك الاختبار الأخير - TeraValidate - التأكد من فرز البيانات بالترتيب الصحيح. وهذا هو ، نذهب من خلالهم مرة ثانية.

كتجربة ، أخذنا السيارات فقط باستخدام محركات أقراص الحالة الثابتة - أي تثبيت Hadoop فقط على محركات أقراص الحالة الصلبة دون استخدام محركات الأقراص الصلبة. في الإصدار الثاني ، استخدمنا SSD لتخزين الملفات المؤقتة ، HDD - لتخزين البيانات الأساسية. وفي الإصدار الثالث ، تم استخدام محركات الأقراص الصلبة لكليهما.
لم تكن نتائج هذه التجارب مرضية للغاية بالنسبة لنا ، لأن الفرق في مؤشرات الأداء لم يتجاوز 10-20 ٪. أي أننا أدركنا أن Hadoop ليست صديقة للغاية لمحركات الأقراص الصلبة من حيث التخزين ، لأنه في البداية تم إنشاء النظام لتخزين البيانات الكبيرة على الأقراص الصلبة ، ولم يقم أحد بتحسينها خاصةً لمحركات أقراص الحالة الصلبة السريعة والمكلفة. وبما أن تكلفة SSD كانت مرتفعة جدًا في ذلك الوقت ، فقد قررنا حتى الآن عدم الخوض في هذه القصة والتخلص من محركات الأقراص الصلبة.
الاختبار الثاني
بعد ذلك ، قدمت إنتل سواقات جديدة من Intel Optane SSDs تعتمد على الذاكرة ثلاثية الأبعاد. تم إصدارها في نهاية عام 2017 ، ولكن العينات كانت متاحة لنا في وقت سابق. تتيح ميزات ذاكرة 3D XPoint استخدام Intel Optane SSD امتداداً لذاكرة الوصول العشوائي في الخوادم. نظرًا لأننا أدركنا بالفعل أنه لن يكون من السهل حل مشكلة أداء IO Hadoop على مستوى أجهزة تخزين البلوك ، فقد قررنا تجربة خيار جديد - توسيع ذاكرة الوصول العشوائي (RAM) باستخدام تقنية Intel Memory Drive Technology (IMDT). وفي بداية هذا العام ، كنا واحدة من أوائل الدول في العالم التي اختبرت ذلك.
وهذا مفيد لنا: إنه أرخص من ذاكرة الوصول العشوائي ، والذي يسمح لك بجمع الخوادم التي تحتوي على تيرابايت من ذاكرة الوصول العشوائي. وبما أن ذاكرة الوصول العشوائي سريعة بما يكفي ، يمكنك تحميل مجموعات البيانات الكبيرة فيه وتحليلها. اسمحوا لي أن أذكركم بأن خصوصية العملية التحليلية لدينا هي أننا نصل إلى البيانات عدة مرات. من أجل القيام بنوع من التحليل ، نحتاج إلى تحميل أكبر قدر ممكن من البيانات في الذاكرة و "التمرير" نوعًا ما من التحليلات لهذه البيانات عدة مرات.
خصصنا مختبر إنتل للغة الإنجليزية في سويندون مجموعة من ثلاثة خوادم ، قمنا خلال الاختبارات بمقارنتها بمجموعة الاختبارات الموجودة في النظام التجاري المتعدد الأطراف.

كما يتضح من الرسم البياني ، وفقًا لنتائج الاختبار ، حصلنا على نتائج جيدة للغاية.
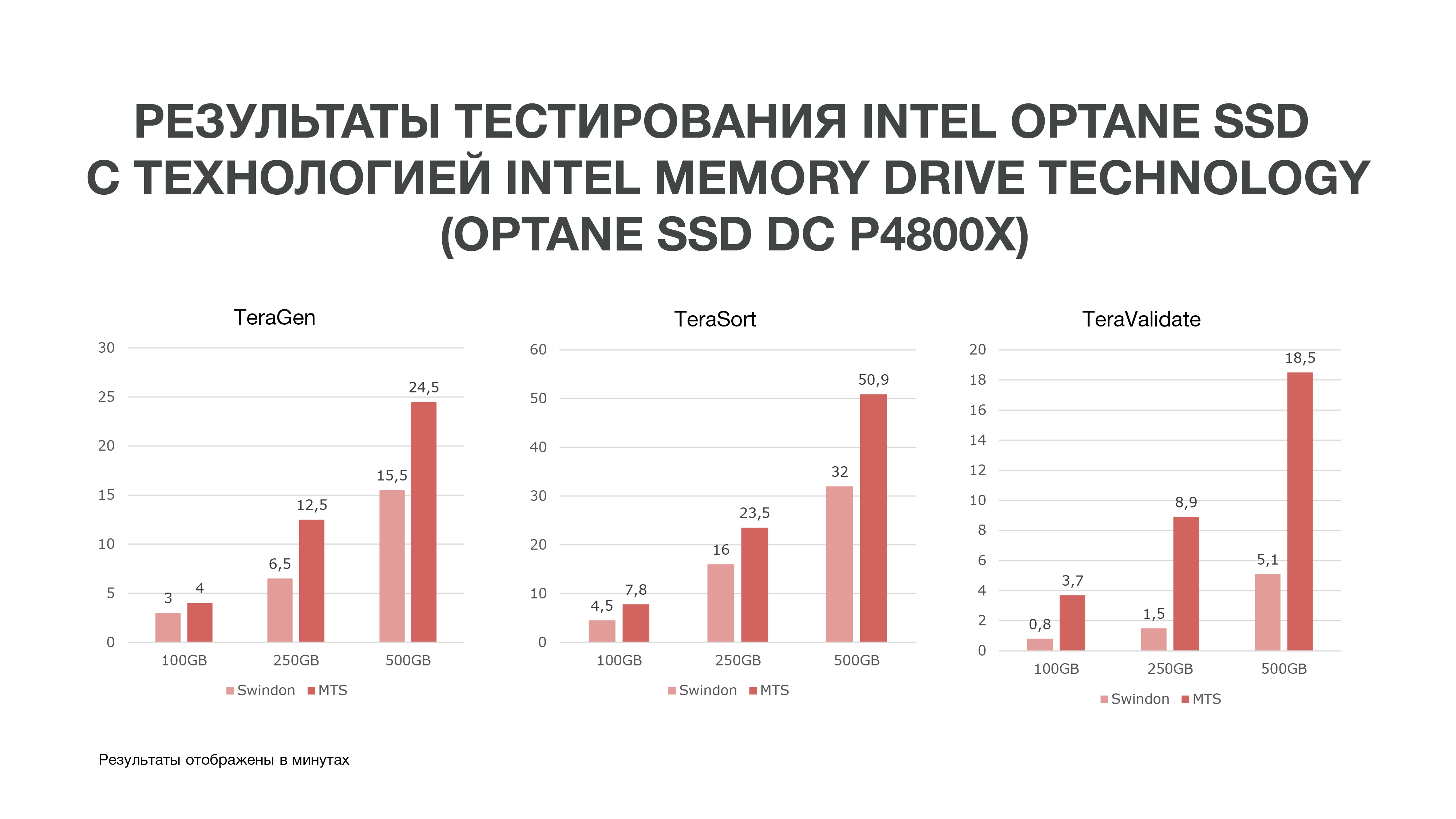
وأظهرت نفس TeraGen زيادة مضاعفة تقريبًا في الإنتاجية ، TeraValidate - بنسبة 75٪. هذا جيد جدًا بالنسبة لنا ، لأننا ، كما قلت ، نصل إلى البيانات الموجودة في ذاكرتنا عدة مرات. وفقًا لذلك ، إذا حصلنا على مثل هذا الأداء ، فسوف يساعدنا هذا بشكل خاص في تحليل البيانات ، خاصة في الوقت الفعلي.
أجرينا ثلاثة اختبارات في ظل ظروف مختلفة. 100 جيجابايت و 250 جيجابايت و 500 جيجابايت. وكلما استخدمنا الذاكرة ، كان أداء Intel Optane SSD المزود بتقنية Intel Memory Drive أفضل. وهذا يعني أنه كلما زاد عدد البيانات التي نحللها ، كلما زادت الكفاءة. يمكن أن تحدث التحليلات التي حدثت على المزيد من العقد على عدد أقل منها. كما نحصل على قدر كبير من الذاكرة على أجهزتنا ، وهو أمر جيد جدًا لمهام "علوم البيانات". بناءً على نتائج الاختبار ، قررنا شراء هذه الأقراص للعمل في MTS.
إذا كان عليك أيضًا اختيار واختبار الأجهزة لتخزين كمية كبيرة من البيانات ومعالجتها ، فسيكون من المثير للاهتمام أن نقرأ الصعوبات التي واجهتها والنتائج التي انتهى بها الأمر: الكتابة في التعليقات.
المؤلفون:
غريغوري كوفال ، رئيس مركز الكفاءة في الهندسة التطبيقية بإدارة البيانات الضخمة في النظام التجاري المتعدد الأطراف ، grigory_koval
رئيس قبيلة إدارة البيانات في قسم البيانات الكبيرة MTS Dmitry Shostko zloi_diman