هذا هو مقال طال انتظاره حول التعلم التعزيز (RL). RL هو موضوع رائع!
قد تعلم أن أجهزة الكمبيوتر يمكن أن
تتعلم الآن
تلقائيًا ممارسة ألعاب ATARI (عن طريق الحصول على بكسلات ألعاب خام عند المدخل!). لقد تغلبوا على أبطال العالم في لعبة
Go ، وتعلموا بأربعة أرجل افتراضي
الجري والقفز ، ويتعلم الإنسان الآلي أداء مهام معالجة معقدة تتحدى البرمجة الواضحة. اتضح أن كل هذه الإنجازات ليست كاملة دون RL. كنت مهتمًا أيضًا بـ RL على مدار العام الماضي: عملت مع كتاب
Richard Sutton (تقريبًا المرجع: استبدال) ، وقراءة دورة
David Silver ،
وحضر محاضرات John Schulman ، وكتب
مكتبة RL على Javascript ، وفي التدريب الصيفي في DeepMind ، كنت أعمل في مجموعة DeepRL ، ومؤخراً ، في تطوير
OpenAI Gym ، هي مجموعة أدوات RL الجديدة. لذلك ، بالطبع ، لقد كنت على هذه الموجة منذ عام على الأقل ، لكنني لم أزعجني حتى الآن بكتابة ملاحظة حول سبب أهمية RL لأهميته الكبيرة ، وعن ماهية الموضوع ، وكيف يتطور كل هذا.
 أمثلة على استخدام Deep Q-Learning. من اليسار إلى اليمين: تقوم الشبكة العصبية بلعب ATARI ، وتلعب الشبكة العصبية لعبة AlphaGo ، حيث يقوم الرجل الآلي بطي Lego ، حيث يعمل الجهاز الافتراضي ذو الأرجل الأربعة على العقبات الافتراضية.
أمثلة على استخدام Deep Q-Learning. من اليسار إلى اليمين: تقوم الشبكة العصبية بلعب ATARI ، وتلعب الشبكة العصبية لعبة AlphaGo ، حيث يقوم الرجل الآلي بطي Lego ، حيث يعمل الجهاز الافتراضي ذو الأرجل الأربعة على العقبات الافتراضية.من المثير للاهتمام التفكير في طبيعة التقدم الذي أحرز مؤخرا في RL. أود أن أشير إلى أربعة عوامل منفصلة تؤثر على تطور الذكاء الاصطناعي:
- سرعة الحوسبة (GPU ، أسيك للأجهزة الخاصة ، قانون مور)
- بيانات كافية في شكل قابل للاستخدام (مثل ImageNet)
- الخوارزميات (البحث والأفكار ، على سبيل المثال backprop ، CNN ، LSTM)
- بنية أساسية (Linux ، TCP / IP ، Git ، ROS ، PR2 ، AWS ، AMT ، TensorFlow ، وما إلى ذلك).
تمامًا كما هو الحال في رؤية الكمبيوتر ، يتقدم التقدم في RL ... ولكن ليس بقدر ما قد يبدو. على سبيل المثال ، في رؤية الكمبيوتر ، تعد الشبكة العصبية لـ AlexNet 2012 إصدارًا متعمقًا وعميقًا لشبكة التسعينيات ConvNets العصبية. وبالمثل ، يعد ATARI Deep Q-Learning 2013 تطبيقًا لخوارزمية Q-Learning القياسية التي يمكنك العثور عليها في كتاب ريتشارد سوتون الكلاسيكي لعام 1998. علاوة على ذلك ، تستخدم AlphaGo تقنية تدرج السياسة والبحث الشجري في مونت كارلو (MCTS) هي أيضًا أفكار قديمة أو مجموعاتها. بالطبع ، يتطلب الأمر الكثير من المهارات والصبر لحملهم على العمل ، وقد تم تطوير العديد من الإعدادات الصعبة بالإضافة إلى الخوارزميات القديمة.
ولكن في التقريب الأول ، ليس الدافع الرئيسي للتقدم الأخير هو الخوارزميات والأفكار الجديدة ، بل تكثيف العمليات الحسابية ، والبيانات الكافية ، والبنية التحتية الناضجة.عاد الآن إلى RL. لا يعتقد الكثير من الناس أنه بإمكاننا تعليم الكمبيوتر كيفية لعب ألعاب ATARI على المستوى الإنساني باستخدام وحدات بكسل خام من نقطة الصفر واستخدام نفس خوارزمية التعلم الذاتي. في الوقت نفسه ، في كل مرة أشعر بوجود فجوة - كيف تبدو سحرية ، وكم هي بسيطة في الداخل.
النهج الأساسي الذي نستخدمه هو في الواقع غبية جدا. وبغض النظر عن ذلك ، أود أن أقدم لكم تقنية النهج التدريجي (PG) ، وهو خيارنا الافتراضي المفضل لحل مشاكل RL في الوقت الحالي. قد تكون فضولياً لماذا ، بدلاً من ذلك ، لا أستطيع أن أتخيل DQN ، وهي خوارزمية RL بديلة ومعروفة وتستخدم أيضًا في
تدريب ATARI . اتضح أنه على الرغم من أن Q-Learning معروف ، إلا أنه ليس مثاليًا. يختار معظم الناس استخدام "تدرج السياسة" ، بما في ذلك مؤلفو
مقالة DQN الأصلية ، الذين أظهروا أنه مع التوليف الجيد ، يعمل تدرج السياسة بشكل أفضل من Q-Learning. PG هو الأفضل لأنه صريح: هناك سياسة واضحة ونهج متماسك يحسن مباشرة المكافآت المتوقعة. على سبيل المثال ، سوف نتعلم كيف نلعب ATARI Pong: من البداية ، من البكسلات الخام من خلال تدرج السياسة مع شبكة عصبية. وسنضع كل هذا في 130 سطرًا من بيثون. (
رابط Gist ) دعونا نرى كيف يتم ذلك.

 أعلاه: بينج بونج. أدناه: عرض بينج بونج كحالة خاصة لعملية صنع القرار في ماركوف (MDP) : يتوافق كل رأس من الرسم البياني مع حالة معينة من اللعبة ، وتحدد الحواف احتمالات الانتقال إلى حالات أخرى. كما يحدد كل ضلع المكافأة. الهدف هو العثور على أفضل مسار من أي ولاية لتعظيم المكافأة
أعلاه: بينج بونج. أدناه: عرض بينج بونج كحالة خاصة لعملية صنع القرار في ماركوف (MDP) : يتوافق كل رأس من الرسم البياني مع حالة معينة من اللعبة ، وتحدد الحواف احتمالات الانتقال إلى حالات أخرى. كما يحدد كل ضلع المكافأة. الهدف هو العثور على أفضل مسار من أي ولاية لتعظيم المكافأةيعد لعب Ping Pong مثالاً رائعًا على تحدي RL. في إصدار ATARI 2600 ، سنلعب مضربًا واحدًا بأنفسنا. يتم التحكم في مضرب آخر بواسطة خوارزمية مدمجة. نحتاج أن نضرب الكرة حتى لا يتوفر للاعب الآخر الوقت لضربها. آمل ألا تكون هناك حاجة لشرح ما هي لعبة Ping Pong. على مستوى منخفض ، تعمل اللعبة على النحو التالي: نحصل على إطار صورة - مجموعة من وحدات البايت 210 × 160 × 3 ، ونقرر ما إذا كنا نريد تحريك المضرب لأعلى أو لأسفل. هذا هو ، لدينا خياران فقط لإدارة اللعبة. بعد كل اختيار ، يؤدي محاكي اللعبة نشاطه ويمنحنا مكافأة: إما مكافأة +1 إذا مرت الكرة على مضرب الخصم ، أو -1 إذا أخطأنا الكرة. 0. وبطبيعة الحال ، فإن هدفنا هو تحريك المضرب بحيث نحصل على أكبر قدر ممكن من المكافأة.
عند التفكير في حل ، تذكر أننا سنحاول وضع عدد قليل من الافتراضات حول كرة الطاولة ، لأنها ليست مهمة بشكل خاص في الممارسة. نأخذ الكثير من الأشياء في الاعتبار في المهام واسعة النطاق ، مثل معالجة الروبوتات والتجميع والتنقل. Pong هي مجرد حالة اختبار للعبة ممتعة نلعب بها أثناء اكتشافنا لكيفية كتابة أنظمة الذكاء الاصطناعى العامة جدًا التي يمكنها القيام بمهام تعسفية ذات يوم.
الشبكة العصبية كسياسة RL . أولاً ، سنحدد السياسة المزعومة التي ينفذها لاعبنا (أو "الوكيل"). ((*) "العامل" و "البيئة" و "سياسة الوكيل" هي مصطلحات قياسية من نظرية RL). وظيفة السياسة في حالتنا هي شبكة عصبية. ستقبل حالة اللعبة عند المدخل وعند الخروج ستقرر ما يجب فعله - التحرك لأعلى أو لأسفل. بصفتنا مجموعة الحسابات البسيطة المفضلة لدينا ، سوف نستخدم شبكة عصبية ثنائية الطبقة تأخذ بيكسلات صورة خام (إجمالي 100800 رقم (210 * 160 * 3)) وتنتج رقمًا واحدًا يشير إلى احتمال تحريك المضرب لأعلى. يرجى ملاحظة أن استخدام سياسة الاستوكاستك هو المعيار ، مما يعني أننا ننتج فقط احتمال الحركة الصعودية. للحصول على التحرك الفعلي ، سوف نستخدم هذا الاحتمال. سوف يصبح سبب ذلك أوضح عندما نتحدث عن التدريب.
 تتألف وظيفة سياستنا من شبكة عصبية متصلة بالكامل بطبقتين
تتألف وظيفة سياستنا من شبكة عصبية متصلة بالكامل بطبقتينبشكل أكثر تحديدًا ، لنفترض أنه عند الإدخال نحصل على ناقل X ، والذي يحتوي على مجموعة من وحدات البكسل التي تمت معالجتها مسبقًا. ثم يجب علينا حساب باستخدام python \ numpy:
h = np.dot(W1, x)
في هذه الشريحة ، W1 و W2 هما مصفوفان نبدأ التهيئة بشكل عشوائي. نحن لا نستخدم التحيز ، لأننا أردنا. لاحظ أننا في النهاية نستخدم اللامخطية من السيني ، مما يقلل من احتمال الإخراج إلى المدى [0،1]. بشكل حدسي ، يمكن للخلايا العصبية الموجودة في طبقة مخفية (التي تقع أوزانها في W1) اكتشاف سيناريوهات اللعبة المختلفة (على سبيل المثال ، الكرة في الأعلى ومضربنا في المنتصف) ، ويمكن للأوزان في W2 بعد ذلك تحديد ما إذا كان يجب علينا الصعود في كل حالة أو لأسفل. وبطبيعة الحال ، فإن العشوائي الأولي W1 و W2 ، في البداية ، سوف يتسبب في حدوث تشنجات وتشنجات في لاعبنا العصبي ، مما يساويه شخص مصاب بالتوحد عند التحكم في الطائرة. المهمة الوحيدة الآن هي العثور على W1 و W2 ، والتي تؤدي إلى لعبة جيدة!
هناك ملاحظة حول المعالجة المسبقة للبكسل - من الناحية المثالية ، تحتاج إلى نقل إطارين على الأقل إلى الشبكة العصبية حتى تتمكن من اكتشاف الحركة. ولكن لتبسيط الموقف ، سوف نطبق الفرق بين إطارين. أي أننا سنطرح الإطارات الحالية والسابقة وبعد ذلك فقط نطبق الفرق على مدخلات الشبكة العصبية.
يبدو وكأنه شيء مستحيل. في هذه المرحلة ، أود منك أن تقدر مدى تعقيد مشكلة RL. نحصل على 100 800 رقم (210 × 160 × 3) ونرسل إلى شبكتنا العصبية التي تنفذ سياسة اللاعب (والتي ، بالمناسبة ، تتضمن بسهولة حوالي مليون معلمة في المصفوفات W1 و W2). لنفترض أننا في مرحلة ما قررنا الصعود. يستطيع محاكي اللعبة الإجابة على أننا سنحصل هذه المرة على 0 جائزة ومنحنا 100 800 رقم آخر للإطار التالي. يمكننا تكرار هذه العملية مئات المرات قبل أن نحصل على مكافأة غير صفرية! على سبيل المثال ، افترض أننا حصلنا في النهاية على مكافأة +1. هذا رائع ، لكن كيف يمكننا إذن أن نقول ما الذي أدى إلى هذا؟ هل كان هذا الإجراء الذي قمنا به للتو؟ أو ربما 76 لقطة الظهر؟ أو ربما تم ربط هذا أولاً بالإطار 10 ، ثم فعلنا شيئًا صحيحًا في الإطار 90؟ وكيف نكتشف - أي من "أقلام" المليون التي يجب تحريفها لتحقيق نجاح أكبر في المستقبل؟ نسمي هذا مهمة تحديد معامل الثقة في بعض الإجراءات. في الحالة المحددة مع كرة الطاولة ، نعلم أننا نحصل على +1 إذا مرت الكرة على الخصم. السبب الحقيقي هو أننا ركلنا الكرة بطريق الخطأ على طول مسار جيد بإطارات قليلة ، ولم يؤثر كل إجراء تالٍ قمنا به على الإطلاق. بمعنى آخر ، نواجه مشكلة حسابية معقدة للغاية ، ويبدو كل شيء كئيبًا إلى حد ما.
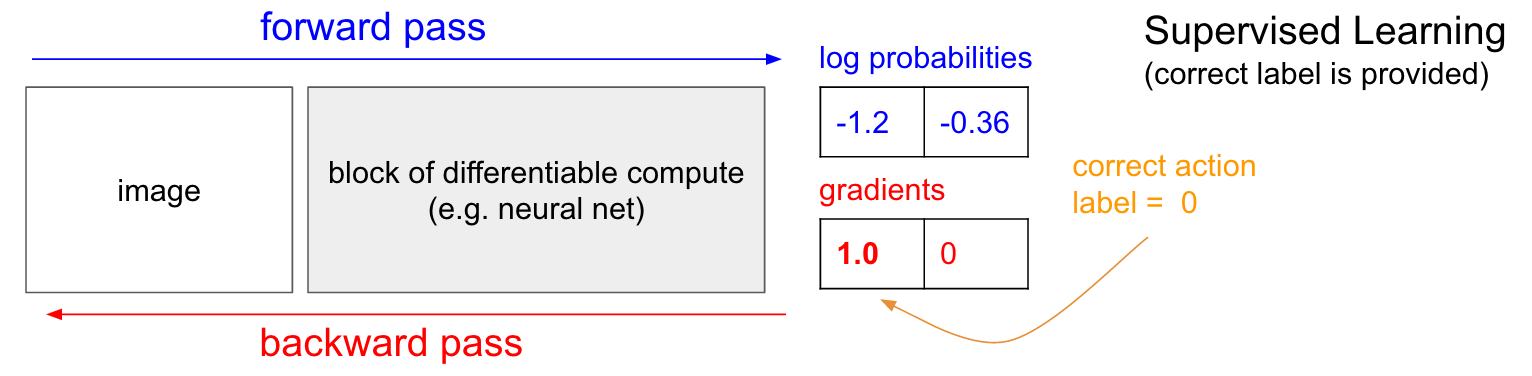
التدريب مع المعلم. قبل الخوض في تدرج السياسة (PG) ، أود أن أتذكر بإيجاز التدريس مع المعلم ، لأنه ، كما سنرى ، RL متشابهة جدًا. الرجوع إلى الرسم البياني أدناه. في التدريس العادي مع أحد المعلمين ، سننقل الصورة إلى الشبكة وسنتلقى في المخرجات بعض الاحتمالات العددية للفصول. على سبيل المثال ، في حالتنا لدينا فئتان: UP و DOWN. أستخدم الاحتمالات اللوغاريتمية (-1،2 ، -0،36) بدلاً من الاحتمالات بتنسيق 30٪ و 70٪ ، لأننا نقوم بتحسين الاحتمالية اللوغاريتمية للفئة الصحيحة (أو التصنيف). هذا يجعل العمليات الحسابية أكثر أناقة وتعادل تحسين الاحتمال العادل ، لأن اللوغاريتم رتيب.
في التدريب مع المعلم ، سيكون لدينا إمكانية الوصول الفوري إلى الفصل الصحيح (التسمية). في مرحلة التدريب ، سوف يخبروننا بالضبط بالخطوة الصحيحة المطلوبة الآن (دعنا نقول أنها UP ، التسمية 0) ، على الرغم من أن الشبكة العصبية قد تفكر بشكل مختلف. لذلك ، نحسب التدرج
n a b l a W l o g p ( y = U P m i d x ) للقرص إعدادات الشبكة. يخبرنا هذا التدرج اللوني فقط كيف ينبغي لنا أن نغير كل معلمة من ملايين معلماتنا بحيث من المحتمل أن تتنبأ الشبكة قليلاً في نفس الموقف. على سبيل المثال ، يمكن أن تحتوي إحدى معلمات المليون في الشبكة على تدرج -2.1 ، مما يعني أنه إذا قمنا بزيادة هذه المعلمة بقيمة موجبة صغيرة (على سبيل المثال ، 0.001) ، فإن الاحتمال اللوغاريتمي لـ UP سينخفض بمقدار 2.1 * 0.001. (انخفاض بسبب علامة سلبية). إذا قمنا بتطبيق التدرج الليلي ثم قمنا بتحديث المعلمة باستخدام خوارزمية backpropagation ، إذن ، نعم ، ستوفر شبكتنا احتمالًا كبيرًا لـ UP عندما ترى الصورة نفسها أو صورة مشابهة جدًا في المستقبل.
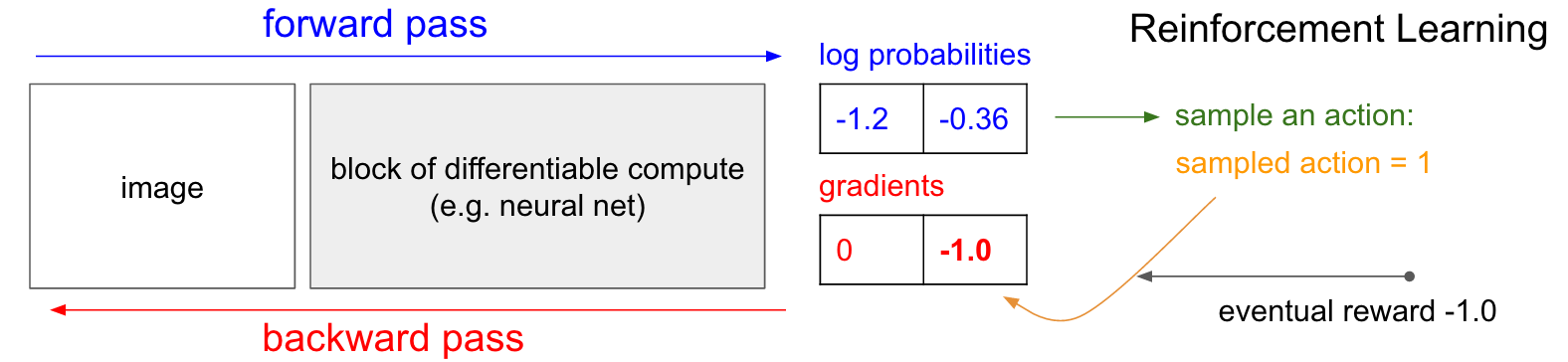
 التدرجات السياسية (PG)
التدرجات السياسية (PG) . حسنًا ، لكن ماذا نفعل إذا لم يكن لدينا بطاقة تدريب التعزيز الصحيحة؟ إليك حل PG (راجع المخطط أدناه مرة أخرى). حسبت شبكتنا العصبية احتمال ارتفاع بنسبة 30 ٪ (logprob -1.2) و DOWN بنسبة 70 ٪ (logprob -0.36). الآن نقوم باختيار من هذا التوزيع ونحدد الإجراء الذي سنفعله. على سبيل المثال ، اختاروا DOWN وأرسلوا هذا الإجراء إلى محاكي اللعبة. في هذه المرحلة ، انتبه إلى حقيقة واحدة مثيرة للاهتمام: يمكننا على الفور حساب وتطبيق التدرج اللوني لتصرف DOWN ، كما فعلنا في التدريس مع المعلم ، وبالتالي جعل الشبكة أكثر عرضة لأداء إجراء DOWN في المستقبل. وبالتالي ، يمكننا أن نقدر على الفور ونتذكر هذا التدرج. لكن المشكلة هي أنه في الوقت الحالي لا نعرف حتى الآن - هل من الجيد أن تنزل؟
ولكن الشيء الأكثر إثارة للاهتمام هو أنه يمكننا فقط الانتظار قليلاً وتطبيق التدرج اللاحق! في Pong ، يمكننا الانتظار حتى نهاية اللعبة ، ثم نأخذ المكافأة التي تلقيناها (إما +1 إذا فزنا ، أو -1 إذا فقدنا) ، وأدخلها كعامل للتدرج. لذلك ، إذا قدمنا -1 لاحتمال DOWN وقمنا بالانتشار الخلفي ، فسنقوم بإعادة إنشاء معلمات الشبكة بحيث يكون من غير المحتمل إجراء إجراء DOWN في المستقبل عندما تواجه نفس الصورة ، لأن اعتماد هذا الإجراء دفعنا إلى خسارة اللعبة. وهذا يعني أننا سنحتاج إلى تذكر جميع الإجراءات (مدخلات ومخرجات الشبكة العصبية) في إحدى حلقات اللعبة ، واستناداً إلى هذا المصفوفة ، قم بتحريف الشبكة العصبية بنفس طريقة التدريس في المدرس تقريبًا.
وهذا كل ما هو مطلوب: لدينا سياسة عشوائية تختار الإجراءات ، ثم في المستقبل ، يتم تشجيع الإجراءات التي تؤدي في النهاية إلى نتائج جيدة ، والإجراءات التي تؤدي إلى نتائج سيئة لا يتم تشجيعها. بالإضافة إلى ذلك ، يجب ألا تكون المكافأة +1 أو -1 إذا فزنا في النهاية باللعبة. يمكن أن تكون قيمة تعسفية لنفس المعنى. على سبيل المثال ، إذا كان كل شيء يعمل بشكل جيد بالفعل ، فقد تكون المكافأة 10.0 ، والتي نستخدمها بعد ذلك كتدرج لبدء backpropagation. هذا هو جمال الشبكات العصبية. قد يبدو استخدامها بمثابة خدعة: يُسمح لك بوجود مليون معلمة مضمّنة في 1 ترافلوب من العمليات الحسابية ، ويمكنك جعل البرنامج يتعلم كيفية القيام بأشياء تعسفية من خلال النسب التدريجي العشوائي (SGD). لا ينبغي أن تعمل ، ولكن من المضحك أن نعيش في عالم يعمل فيه.
إذا لعبنا ألعاب لوحية بسيطة ، مثل لعبة الداما ، فسيكون الترتيب هو نفسه تقريبًا. هناك اختلاف ملحوظ من خوارزميات لقطة minimax أو alpha-beta. في هذه الخوارزميات ، يتطلع البرنامج إلى الأمام بخطوات قليلة ، ومعرفة قواعد اللعبة ، ويحلل ملايين المواضع. في نهج RL ، يتم تحليل التحركات التي تم إجراؤها بالفعل فقط. في الوقت نفسه ، لا تتطلع الشبكة العصبية إلى الأمام ، لأنها لا تعرف أي شيء عن قواعد اللعبة.
ترتيب تجريب في التفاصيل. نقوم بإنشاء وتهيئة شبكة عصبية باستخدام بعض W1 و W2 ولعب 100 لعبة كرة الطاولة (نسميها "الركض" للسياسة وتداول السياسات). لنفترض أن كل لعبة تتكون من 200 إطار ، لذلك في المجموع اتخذنا 100 * 200 = 20،000 قرار صعودا أو هبوطا. ولكل من الحلول ، فإننا نعرف تدرجًا يخبرنا كيف يجب تغيير المعلمات إذا أردنا تشجيع أو حظر هذا الحل في هذه الحالة في المستقبل. كل ما تبقى الآن هو تسمية كل قرار نتخذه بأنه جيد أو سيء. على سبيل المثال ، افترض أننا فزنا بـ 12 مباراة وخسرنا 88. سنتخذ جميع القرارات 200 * 12 = 2400 التي اتخذناها في الألعاب الفائزة ونجري تحديثًا إيجابيًا (ملء تدرج +1.0 لكل إجراء ، وإجراء backprop ، وتحديث المعلمات تشجيع الإجراءات التي اخترناها في كل هذه الظروف). وسنتخذ القرارات 200 * 88 = 17،600 الأخرى التي اتخذناها في خسارة الألعاب وإجراء تحديث سلبي (لا نوافق على ما فعلناه). وهذا كل ما يتطلبه الأمر. ستكون الشبكة الآن أكثر عرضة لتكرار الإجراءات التي نجحت ، وأقل احتمالًا تكرار الإجراءات التي لم تنجح. الآن نلعب 100 لعبة أخرى من خلال سياستنا الجديدة المحسّنة قليلاً ، ثم نكرر تطبيق التدرجات.
 مخطط الكرتون من 4 مباريات. كل دائرة سوداء هي نوع من حالة اللعبة (تظهر ثلاثة أمثلة للحالات أدناه) ، وكل سهم عبارة عن انتقال يتم تمييزه بالإجراء الذي تم تحديده. في هذه الحالة ، فزنا بمباراتين وخسرنا مباراتين. لقد اتخذنا المباراتين اللتين فزناهما وشجعنا كل إجراء قمنا به في هذه الحلقة. بالمقابل ، سوف نأخذ أيضًا المباراتين المفقودتين ونثبط بعض الإجراءات الفردية التي قمنا بها في هذه الحلقة.
مخطط الكرتون من 4 مباريات. كل دائرة سوداء هي نوع من حالة اللعبة (تظهر ثلاثة أمثلة للحالات أدناه) ، وكل سهم عبارة عن انتقال يتم تمييزه بالإجراء الذي تم تحديده. في هذه الحالة ، فزنا بمباراتين وخسرنا مباراتين. لقد اتخذنا المباراتين اللتين فزناهما وشجعنا كل إجراء قمنا به في هذه الحلقة. بالمقابل ، سوف نأخذ أيضًا المباراتين المفقودتين ونثبط بعض الإجراءات الفردية التي قمنا بها في هذه الحلقة.إذا كنت تفكر في هذا ، فسوف تبدأ في العثور على بعض الخصائص الممتعة. على سبيل المثال ، ماذا لو فعلنا إجراءً جيدًا في الإطار 50 ، حيث ركلنا الكرة بشكل صحيح ، ولكن بعد ذلك أخطأنا الكرة في الإطار 150؟ نظرًا لأننا خسرنا اللعبة ، فإن كل إجراء فردي أصبح الآن سيئًا ، ألا يمنع هذا الضربة الصحيحة على الإطار 50؟ أنت على حق - سيكون الأمر كذلك بالنسبة لهذا الحزب. ومع ذلك ، عندما تفكر في العملية في آلاف / ملايين الألعاب ، فإن التنفيذ الصحيح للارتداد يزيد من احتمالية الفوز في المستقبل. في المتوسط ، سترى تحديثات أكثر إيجابية من السلبية لإضراب مضرب مناسب. وستنتج سياسة تنفيذ الشبكة العصبية في نهاية المطاف ردود الفعل الصحيحة.
تحديث: 9 ديسمبر 2016 هو وجهة نظر بديلة. في شرحي أعلاه ، أستخدم مصطلحات مثل "تحديد انتشار التدرج الخلفي والخلفي" ، وهو أسلوب ماهر. إذا كنت معتادًا على كتابة رمز backprop الخاص بك أو باستخدام Torch ، يمكنك التحكم في التدرجات بشكل كامل. ومع ذلك ، إذا كنت معتادًا على Theano أو TensorFlow ، فستكون في حيرة بعض الشيء لأن شفرة backprop مؤتمتة بالكامل ويصعب تخصيصها. في هذه الحالة ، قد يكون العرض البديل التالي أكثر إنتاجية. في التدريس مع المعلم ، فإن الهدف المعتاد هو تحقيق الحد الأقصى
الصورة ش م ط ل س ز ص ( ص ط م ط د س ط ) اين
س أنا ، ذ أنا - أمثلة التدريب (مثل الصور والتسميات الخاصة بهم). إن تطبيق التدرج اللاحق على وظيفة السياسة يتزامن تمامًا مع التدريب مع المعلم ، ولكن مع اختلافين بسيطين: 1) ليس لدينا التصنيفات الصحيحة
ذ أنا لذلك ، "كتسمية مزيفة" ، نستخدم الإجراء الذي تلقيناه للاختيار من السياسة عند رؤيته
س أنا و 2) نقدم معاملًا آخر للنفعية (ميزة) لكل إجراء. وهكذا ، في النهاية ، تبدو خسارتنا الآن
الصورة ش م ط أ ط ل س ز ص ( ص ط م ط د س ط ) اين
ذ أنا - هذا هو الإجراء الذي قمنا به مع العينة ، و
Ai هو الرقم الذي نسميه معامل النفعية. على سبيل المثال ، في حالة بونغ ، القيمة
Ai قد يكون 1.0 إذا انتهى بنا الأمر بالفوز في الحلقة ، و -1.0 إذا خسرنا. هذا يضمن أننا نزيد من احتمال تسجيل الإجراءات التي أدت إلى نتيجة جيدة ، وتقليل احتمال تسجيل الإجراءات التي لم تفعل ذلك. ولن تؤثر الإجراءات المحايدة نتيجة لدعوات كثيرة بشكل خاص على وظيفة السياسة. وهكذا ، فإن التعلم المعزز هو نفسه تمامًا مثل التعلم مع المعلم ، ولكن في مجموعة بيانات دائمة التغير (الحلقات) ، مع عامل إضافي.
ميزات جدوى أكثر تقدما. وعدت أيضا معلومات أكثر قليلا. حتى الآن ، قمنا بتقييم صحة كل إجراء فردي بناءً على ما إذا كنا نفوز أم لا. في إعداد RL أكثر عمومية ، سوف نتلقى "مكافأة مشروطة"
rt لكل خطوة ، اعتمادا على رقم الخطوة أو الوقت. أحد الخيارات الشائعة هو استخدام معامل مخصوم ، لذلك ستكون "المكافأة المحتملة" في المخطط أعلاه
Rt= sum inftyk=0 gammakrt+k اين
gamma هو رقم من 0 إلى 1 ، يسمى معامل الخصم (على سبيل المثال ، 0.99). يشير التعبير إلى أن القوة التي نشجعها على اتخاذ إجراء هي المبلغ المرجح لجميع المكافآت ، ولكن المكافآت اللاحقة أقل أهمية بشكل كبير. وهذا يعني أن السلاسل القصيرة من الإجراءات يتم تشجيعها بشكل أفضل ، ويصبح ذيل السلاسل الطويلة من الإجراءات أقل أهمية. في الممارسة العملية ، تحتاج أيضًا إلى تطبيعها. على سبيل المثال ، لنفترض أننا نحسب
Rt لجميع الإجراءات 20،000 في سلسلة من 100 حلقة من اللعبة. من الأفكار الجيدة جدًا تطبيع هذه القيم (طرح المتوسط ، القسمة على الانحراف المعياري) قبل توصيلها بخوارزمية backprop. وبالتالي ، نشجع دائمًا ونشجع حوالي نصف الإجراءات التي تم تنفيذها. هذا يقلل من التقلبات ويجعل السياسة أكثر تقاربا. يمكن الاطلاع على دراسة أعمق على [
link ].
مشتقة من وظيفة السياسة. أردت أيضًا أن أصف بإيجاز كيف يتم أخذ التدرجات الرياضية. تدرجات وظيفة السياسة هي حالة خاصة لنظرية أكثر عمومية. الحالة العامة هي أنه عندما يكون لدينا تعبير عن النموذج
Ex simp(x mid theta)[f(x)] ، أي توقع بعض الوظائف العددية
f(x) مع بعض توزيع المعلمة لها
p(x؛ theta) معلمات من قبل بعض ناقلات
theta . ثم
f(x) سوف تصبح وظيفة المكافأة لدينا (أو وظيفة النفعية بمعنى أكثر عمومية) ، والتوزيع المنفصل
p(x) ستكون سياستنا ، التي لديها بالفعل النموذج
p(a midI) إعطاء احتمالات اتخاذ إجراء للصورة
I . ثم نحن مهتمون بكيفية تحويل توزيع p من خلال معالمه
theta للتكبير
و (أي كيف يمكننا تغيير إعدادات الشبكة حتى تحصل الإجراءات على مكافأة أعلى). لدينا هذا:
\ start {align} \ nabla _ {\ theta} E_x [f (x)] & = \ nabla _ {\ theta} \ sum_x p (x) f (x) & \ text {تعريف التوقع} \\ & = \ sum_x \ nabla _ {\ theta} p (x) f (x) & \ text {مبادلة الجمع والتدرج} \\ & = \ sum_x p (x) \ frac {\ nabla _ {\ theta} p (x)} {p (x)} f (x) & \ text {الضرب والقسمة}} p (x) \\ & = \ sum_x p (x) \ nabla _ {\ theta} \ log p (x) f (x) & \ text {استخدم حقيقة أن \ \ nabla _ {\ theta} \ log (z) = \ frac {1} {z} \ nabla _ {\ theta} z \\ & = E_x [f (x) \ nabla _ {\ theta} \ log p (x)] & \ text {تعريف التوقع} \ end {align}سأحاول شرح هذا. لدينا بعض التوزيع
p(x؛ theta) (استخدمت الاختصار
p(x) من خلالها يمكننا اختيار قيم محددة. على سبيل المثال ، قد يكون توزيعًا غوسيًا منه عينات مولد رقم عشوائي. لكل مثال ، يمكننا أيضًا حساب دالة التقدير
و ، والتي وفقا للمثال الحالي يعطينا بعض التقدير العددية. تخبرنا المعادلة الناتجة كيف ينبغي لنا أن نحول التوزيع من خلال معاييرها
theta إذا كنا نريد المزيد من الأمثلة على الإجراءات القائمة على ذلك للحصول على معدلات أعلى
و . نأخذ بعض الأمثلة على الإجراءات
x وتقييمهم
f(x) ، وأيضًا بالنسبة لكل x ، نقوم أيضًا بتقييم المصطلح الثاني
nabla theta logp(x؛ theta) . ما هو هذا المضاعف؟ هذا هو بالضبط المتجه - التدرج ، الذي يعطينا الاتجاه في مساحة المعلمة ، الأمر الذي سيؤدي إلى زيادة في احتمال إجراء معين
x . بمعنى آخر ، إذا دفعنا θ في الاتجاه
nabla theta logp(x؛ theta) ، سنرى أن الاحتمال الجديد لهذا الإجراء سيزداد قليلاً. إذا نظرت إلى الوراء في الصيغة ، فإنها تخبرنا أنه ينبغي لنا أن نأخذ هذا الاتجاه ونضرب القيمة العددية به
f(x) . سيضمن هذا أن "الإجراءات" ذات التصنيف الأعلى (في حالتنا ، المكافأة) سوف "تجتذب" بقوة أكبر من الأمثلة ذات المؤشر الأقل ، وبالتالي ، إذا أردنا التحديث استنادًا إلى عدة عينات من
ع ، ستتحول الكثافة الاحتمالية إلى نقاط لعبة أعلى نتيجة ، مما يزيد من احتمال وجود أمثلة أكشن عالية المكافأة. من المهم أن التدرج لا يؤخذ من الوظيفة
و ، لأنه يمكن أن يكون عموما غير متمايزة وغير متوقعة. أ
ع يمكن تمييزها بواسطة
theta . هذا هو
ع هو توزيع منفصل قابل للتعديل بشكل مستمر ، حيث يمكنك ضبط احتمالات الإجراءات الفردية. نحن نفترض ذلك أيضا
ع تطبيع.
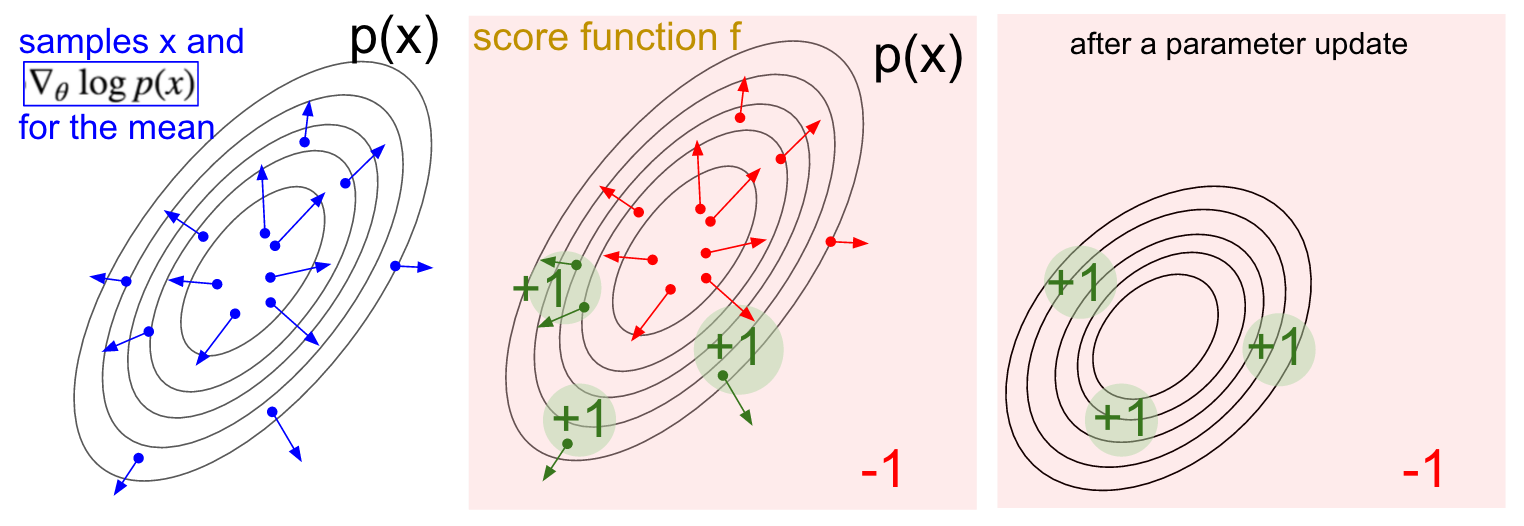 التصور التدرج. يسار: توزيع غاوسي وعدة أمثلة منه (النقاط الزرقاء). في كل نقطة زرقاء ، نقوم أيضًا برسم تدرج الاحتمال اللوغاريتمي فيما يتعلق بالمعلمة المتوسطة. يشير السهم إلى الاتجاه الذي ينبغي فيه تحويل متوسط قيمة التوزيع لزيادة احتمالية هذا الإجراء المثال. في المنتصف: أضيفت بعض وظائف التقييم التي تعطي -1 في كل مكان باستثناء +1 في بعض المناطق الصغيرة (لاحظ أن هذا يمكن أن يكون دالة عددية تعسفية وليس بالضرورة قابلة للتمييز). أصبحت الأسهم الآن مشفرة بالألوان ، نظرًا للضرب ، سنقوم بتقييم كل الأسهم الخضراء بتصنيف إيجابي والسهام الحمراء السلبية. إلى اليمين: بعد تحديث المعلمات ، تدفعنا الأسهم الخضراء والسهام الحمراء المقلوبة إلى اليسار وإلى الأسفل. ستحصل الآن عينات من هذا التوزيع على تصنيف متوقع أعلى ، إذا رغبت في ذلك.
التصور التدرج. يسار: توزيع غاوسي وعدة أمثلة منه (النقاط الزرقاء). في كل نقطة زرقاء ، نقوم أيضًا برسم تدرج الاحتمال اللوغاريتمي فيما يتعلق بالمعلمة المتوسطة. يشير السهم إلى الاتجاه الذي ينبغي فيه تحويل متوسط قيمة التوزيع لزيادة احتمالية هذا الإجراء المثال. في المنتصف: أضيفت بعض وظائف التقييم التي تعطي -1 في كل مكان باستثناء +1 في بعض المناطق الصغيرة (لاحظ أن هذا يمكن أن يكون دالة عددية تعسفية وليس بالضرورة قابلة للتمييز). أصبحت الأسهم الآن مشفرة بالألوان ، نظرًا للضرب ، سنقوم بتقييم كل الأسهم الخضراء بتصنيف إيجابي والسهام الحمراء السلبية. إلى اليمين: بعد تحديث المعلمات ، تدفعنا الأسهم الخضراء والسهام الحمراء المقلوبة إلى اليسار وإلى الأسفل. ستحصل الآن عينات من هذا التوزيع على تصنيف متوقع أعلى ، إذا رغبت في ذلك.آمل أن يكون الاتصال بـ RL واضحًا.
تعطينا سياستنا أمثلة على الإجراءات ، وبعضها يعمل بشكل أفضل من الآخرين (وفقًا لمهمة النفعية). تتمثل طريقة تغيير إعدادات السياسة في التشغيل ، واتخاذ تدرج الإجراءات المحددة ، واضربها في التصنيف وأضف كل ما فعلناه أعلاه. لاستنتاج أكثر شمولاً ، أوصي بمحاضرة لجون شولمان.
التدريب. حسنًا ، قمنا بتطوير مبادئ التدرجات لوظيفة السياسة. لقد طبقت المنهج بالكامل في نص بيثون مكون من 130 سطرًا يستخدم محاكي ATAI 2600 Pong الجاهزة من OpenAI Gym. قمت بتدريب شبكة عصبية مكونة من طبقتين مع 200 خلية عصبية مخفية باستخدام خوارزمية RMSProp لسلسلة من 10 حلقات (كل حلقة ، وفقًا للقواعد ، تتكون من عدة كرات تعادل وتستمر الحلقة في تسجيل 21). لم أقم بإعداد المعلمات المفرطة بشكل مفرط وقمت بتجربة تطبيق Macbook البطيء ، لكن بعد تمرين استمر ثلاثة أيام ، حصلت على سياسة أفضل قليلاً من المشغل المدمج. كان العدد الإجمالي للحلقات حوالي 8000 ، لذلك لعبت الخوارزمية ما يقرب من 200000 لعبة بونغ ، وهو عدد كبير جدًا ، وأنتجت ما مجموعه 800 تحديثًا تقريبًا للأوزان. إذا كنت قد تدربت على GPU باستخدام ConvNets ، فعندئذٍ في غضون بضعة أيام ، سأحقق نتائج رائعة ، وإذا قمت بتحسين المعلمات الفائقة ، فستتمكن دائمًا من الفوز. ومع ذلك ، لم أقضي الكثير من الوقت في الحوسبة أو الإعداد ،بدلاً من ذلك ، حصلنا على Pong AI ، والتي توضح الأفكار الرئيسية وتعمل بشكل جيد: ..يمكننا أيضًا إلقاء نظرة على الأوزان التي تم الحصول عليها من الشبكة العصبية. بفضل المعالجة المسبقة ، كل صورة من مدخلاتنا هي صورة فرق 80 × 80 (الإطار الحالي ناقص الإطار السابق). يتم توصيل كل خلية عصبية من الطبقة W1 بطبقة مخفية W2 تتكون من 200 خلية عصبية. عدد السندات 80 * 80 * 200. دعنا نحاول تحليل هذه الروابط. سنقوم بفرز جميع الخلايا العصبية لطبقة W2 وتصور الأوزان التي تؤدي إليها. من المقاييس التي تؤدي إلى خلية واحدة من الخلايا العصبية W2 من الخلايا العصبية W1 ، سنقوم بتصوير 80 × 80 صورة. فيما يلي 40 صورة من هذه الصور لـ W2 (أي ما مجموعه 200). البيكسلات البيضاء هي أوزان موجبة ، والأسود سالبة. لاحظ أن العديد من الخلايا العصبية W2 يتم ضبطها على الكرة الطائرة المشفرة في خطوط متقطعة. في اللعبة ، يمكن أن تكون الكرة في مكان واحد فقط ،لذلك ، هذه الخلايا العصبية متعددة الأغراض وسوف "تطلق النار" إذا كانت الكرة في مكان ما داخل هذه الخطوط. يعد التناوب بين الأسود والأبيض أمرًا مثيرًا للاهتمام ، لأنه عندما تتحرك الكرة على طول المسار ، يتقلب نشاط الخلايا العصبية مثل موجة جيبية. وبسبب ReLU ، وقال انه "اطلاق النار" فقط في بعض المواقف. هناك الكثير من الضوضاء في الصور ، والتي ستكون أقل إذا كنت تستخدم L2 التنظيم.
..يمكننا أيضًا إلقاء نظرة على الأوزان التي تم الحصول عليها من الشبكة العصبية. بفضل المعالجة المسبقة ، كل صورة من مدخلاتنا هي صورة فرق 80 × 80 (الإطار الحالي ناقص الإطار السابق). يتم توصيل كل خلية عصبية من الطبقة W1 بطبقة مخفية W2 تتكون من 200 خلية عصبية. عدد السندات 80 * 80 * 200. دعنا نحاول تحليل هذه الروابط. سنقوم بفرز جميع الخلايا العصبية لطبقة W2 وتصور الأوزان التي تؤدي إليها. من المقاييس التي تؤدي إلى خلية واحدة من الخلايا العصبية W2 من الخلايا العصبية W1 ، سنقوم بتصوير 80 × 80 صورة. فيما يلي 40 صورة من هذه الصور لـ W2 (أي ما مجموعه 200). البيكسلات البيضاء هي أوزان موجبة ، والأسود سالبة. لاحظ أن العديد من الخلايا العصبية W2 يتم ضبطها على الكرة الطائرة المشفرة في خطوط متقطعة. في اللعبة ، يمكن أن تكون الكرة في مكان واحد فقط ،لذلك ، هذه الخلايا العصبية متعددة الأغراض وسوف "تطلق النار" إذا كانت الكرة في مكان ما داخل هذه الخطوط. يعد التناوب بين الأسود والأبيض أمرًا مثيرًا للاهتمام ، لأنه عندما تتحرك الكرة على طول المسار ، يتقلب نشاط الخلايا العصبية مثل موجة جيبية. وبسبب ReLU ، وقال انه "اطلاق النار" فقط في بعض المواقف. هناك الكثير من الضوضاء في الصور ، والتي ستكون أقل إذا كنت تستخدم L2 التنظيم. ما لا يحدث. لذلك ، تعلمنا كيفية لعب كرة الطاولة على الصور باستخدام تدرج وظيفة السياسة ، وهذا يعمل بشكل جيد. هذا النهج عبارة عن نموذج "اقتراح وتحقق" غريب ، حيث يشير مصطلح "تخمين" إلى تشغيل سياستنا على عدة حلقات من اللعبة ، ويشجع "التحقق" الإجراءات التي تؤدي إلى نتائج جيدة. بشكل عام ، يمثل هذا المستوى الحالي لكيفية تعاملنا حاليًا مع مشاكل التعلم المعزز. إذا كنت تفهم الخوارزمية بشكل حدسي وتعرف كيف تعمل ، فيجب أن تشعر بخيبة أمل على الأقل. على وجه الخصوص ، متى لا يعمل؟قارن هذا بالطريقة التي يمكن أن يتعلم بها الشخص لعب كرة الطاولة. أنت نفسك تبين لهم اللعبة ويقولون شيئًا مثل: "يمكنك التحكم في المضرب ، ويمكنك تحريكه للأعلى وللأسفل ، ومهمتك هي رمي الكرة خلف لاعب آخر يتحكم فيه البرنامج المدمج" ، وتكون جاهزًا للذهاب. يرجى ملاحظة بعض الاختلافات:
ما لا يحدث. لذلك ، تعلمنا كيفية لعب كرة الطاولة على الصور باستخدام تدرج وظيفة السياسة ، وهذا يعمل بشكل جيد. هذا النهج عبارة عن نموذج "اقتراح وتحقق" غريب ، حيث يشير مصطلح "تخمين" إلى تشغيل سياستنا على عدة حلقات من اللعبة ، ويشجع "التحقق" الإجراءات التي تؤدي إلى نتائج جيدة. بشكل عام ، يمثل هذا المستوى الحالي لكيفية تعاملنا حاليًا مع مشاكل التعلم المعزز. إذا كنت تفهم الخوارزمية بشكل حدسي وتعرف كيف تعمل ، فيجب أن تشعر بخيبة أمل على الأقل. على وجه الخصوص ، متى لا يعمل؟قارن هذا بالطريقة التي يمكن أن يتعلم بها الشخص لعب كرة الطاولة. أنت نفسك تبين لهم اللعبة ويقولون شيئًا مثل: "يمكنك التحكم في المضرب ، ويمكنك تحريكه للأعلى وللأسفل ، ومهمتك هي رمي الكرة خلف لاعب آخر يتحكم فيه البرنامج المدمج" ، وتكون جاهزًا للذهاب. يرجى ملاحظة بعض الاختلافات:- - , , , . RL , . , ( ), , . . , , , , , , , , .
- , ( , , , ..), ( «» « , , , - - . .). «» / . , , ( ) ( , ).
- — (brute force), , . . , , , . , «» , . , , .
- , , . , , . .
 : : RL. , , . , . , 99% . , «» . : «», , - , - , - , , . « , ».أود أيضًا أن أؤكد على حقيقة أن تدرج السياسة في العديد من الألعاب سيهزم شخصًا بسهولة. على وجه الخصوص ، ينطبق هذا على الألعاب ذات المكافآت المتكررة ، والتي تتطلب رد فعل دقيق وسريع وبدون تخطيط طويل الأجل. يمكن بسهولة رؤية الارتباطات قصيرة المدى بين المكافآت والإجراءات من خلال نهج PG. يمكنك أن ترى مماثلة في وكيلنا بونغ. يطور إستراتيجية عندما ينتظر ببساطة الكرة ، ثم يتحرك بسرعة للقبض عليه فقط عند الحافة ذاتها ، بسبب ارتداد الكرة بسرعة عمودية عالية. يربح الوكيل عدة انتصارات متتالية ، مكرراً هذه الإستراتيجية البسيطة. هناك العديد من الألعاب (Pinball ، Breakout) التي تجذب فيها لعبة Deep Q-Learning وتدوس شخصًا في الوحل بإجراءاتها البسيطة والدقيقة.بمجرد فهم "الخدعة" التي تعمل بها هذه الخوارزميات ، يمكنك فهم نقاط القوة والضعف فيها. على وجه الخصوص ، هذه الخوارزميات متخلفة عن الأشخاص في بناء أفكار مجردة عن الألعاب التي يمكن للناس استخدامها للتعلم السريع. بمجرد أن ينظر الكمبيوتر إلى صفيف البيكسلات ويلاحظ المفتاح ، فإن الباب يفكر في نفسه أنه من المحتمل أن يكون من الجيد أخذ المفتاح والوصول إلى الباب. لا يوجد شيء قريب من هذا في الوقت الحالي ، ومحاولة الوصول إلى هناك مجال نشط للبحث.حسابات غير قابلة للتمييز في الشبكات العصبية.أود أن أذكر تطبيقًا آخر مثيرًا للاهتمام لمتدرجات سياسة عدم اللعب: فهو يسمح لنا بتصميم وتدريب الشبكات العصبية باستخدام مكونات تؤدي (أو تتفاعل) مع الحوسبة غير القابلة للتمييز. قدمت هذه الفكرة لأول مرة في عام 1992 من قبل ويليامز . وقد تم نشره مؤخرًا في نماذج الاهتمام البصري المتكررة.يُسمى "عن كثب" في سياق نموذج يقوم بمعالجة صورة بتسلسل من الأشكال الضيقة المنخفضة الدقة النقية ، على غرار طريقة فحص عيننا للكائنات ذات الرؤية المركزية الجارية. في كل تكرار ، ستتلقى RNN جزءًا صغيرًا من الصورة وتحديد الموقع الذي يحتاج إلى مزيد من البحث. على سبيل المثال ، يمكن أن ينظر RNN إلى الموضع (5.30) ، ويحصل على جزء صغير من الصورة ، ثم يقرر النظر إلى (24 ، 50) ، وما إلى ذلك. هناك قسم من الشبكة العصبية يختار أن ينظر فيها إلى أبعد من ذلك ، ثم يفحصها. لسوء الحظ ، هذه العملية ليست مختلفة ، لأننا لا نعرف ماذا سيحدث إذا أخذنا عينة في مكان آخر. في حالة أكثر عمومية ، فكر في شبكة عصبية لها عدة مدخلات ومخرجات:
: : RL. , , . , . , 99% . , «» . : «», , - , - , - , , . « , ».أود أيضًا أن أؤكد على حقيقة أن تدرج السياسة في العديد من الألعاب سيهزم شخصًا بسهولة. على وجه الخصوص ، ينطبق هذا على الألعاب ذات المكافآت المتكررة ، والتي تتطلب رد فعل دقيق وسريع وبدون تخطيط طويل الأجل. يمكن بسهولة رؤية الارتباطات قصيرة المدى بين المكافآت والإجراءات من خلال نهج PG. يمكنك أن ترى مماثلة في وكيلنا بونغ. يطور إستراتيجية عندما ينتظر ببساطة الكرة ، ثم يتحرك بسرعة للقبض عليه فقط عند الحافة ذاتها ، بسبب ارتداد الكرة بسرعة عمودية عالية. يربح الوكيل عدة انتصارات متتالية ، مكرراً هذه الإستراتيجية البسيطة. هناك العديد من الألعاب (Pinball ، Breakout) التي تجذب فيها لعبة Deep Q-Learning وتدوس شخصًا في الوحل بإجراءاتها البسيطة والدقيقة.بمجرد فهم "الخدعة" التي تعمل بها هذه الخوارزميات ، يمكنك فهم نقاط القوة والضعف فيها. على وجه الخصوص ، هذه الخوارزميات متخلفة عن الأشخاص في بناء أفكار مجردة عن الألعاب التي يمكن للناس استخدامها للتعلم السريع. بمجرد أن ينظر الكمبيوتر إلى صفيف البيكسلات ويلاحظ المفتاح ، فإن الباب يفكر في نفسه أنه من المحتمل أن يكون من الجيد أخذ المفتاح والوصول إلى الباب. لا يوجد شيء قريب من هذا في الوقت الحالي ، ومحاولة الوصول إلى هناك مجال نشط للبحث.حسابات غير قابلة للتمييز في الشبكات العصبية.أود أن أذكر تطبيقًا آخر مثيرًا للاهتمام لمتدرجات سياسة عدم اللعب: فهو يسمح لنا بتصميم وتدريب الشبكات العصبية باستخدام مكونات تؤدي (أو تتفاعل) مع الحوسبة غير القابلة للتمييز. قدمت هذه الفكرة لأول مرة في عام 1992 من قبل ويليامز . وقد تم نشره مؤخرًا في نماذج الاهتمام البصري المتكررة.يُسمى "عن كثب" في سياق نموذج يقوم بمعالجة صورة بتسلسل من الأشكال الضيقة المنخفضة الدقة النقية ، على غرار طريقة فحص عيننا للكائنات ذات الرؤية المركزية الجارية. في كل تكرار ، ستتلقى RNN جزءًا صغيرًا من الصورة وتحديد الموقع الذي يحتاج إلى مزيد من البحث. على سبيل المثال ، يمكن أن ينظر RNN إلى الموضع (5.30) ، ويحصل على جزء صغير من الصورة ، ثم يقرر النظر إلى (24 ، 50) ، وما إلى ذلك. هناك قسم من الشبكة العصبية يختار أن ينظر فيها إلى أبعد من ذلك ، ثم يفحصها. لسوء الحظ ، هذه العملية ليست مختلفة ، لأننا لا نعرف ماذا سيحدث إذا أخذنا عينة في مكان آخر. في حالة أكثر عمومية ، فكر في شبكة عصبية لها عدة مدخلات ومخرجات: لاحظ أن معظم الأسهم الزرقاء مختلفة كالمعتاد ، ولكن قد تتضمن بعض تحويلات العرض أيضًا عملية تحديد غير متمايزة ، والتي يتم تمييزها باللون الأحمر. يمكننا فقط المرور عبر الأسهم الزرقاء في الاتجاه المعاكس ، لكن السهم الأحمر هو تبعية لا يمكننا من خلالها عكس اتجاه backprop.سياسة التدرج لانقاذ! دعونا نفكر في جزء الشبكة الذي يقوم بأخذ العينات التي يمكن تمثيلها كدالة للسياسة العشوائية المضمنة في شبكة عصبية كبيرة. لذلك ، أثناء التدريب ، سنقدم العديد من الأمثلة (المشار إليها بواسطة الفروع أدناه) ، ثم سنشجع العينات التي تؤدي في النهاية إلى نتائج جيدة (في هذه الحالة ، على سبيل المثال ، تقاس بالخسائر في النهاية). بمعنى آخر ، سنقوم بتدريب المعلمات المضمّنة في الأسهم الزرقاء باستخدام backprop ، كالمعتاد ، ولكن سيتم الآن تحديث المعلمات المضمّنة في السهم الأحمر بغض النظر عن المسار العكسي باستخدام تدرجات السياسة ، مما يشجع العينات التي تؤدي إلى خسائر منخفضة. كانت هذه الفكرة مؤطرة بشكل جيد مؤخرًا.تقدير التدرج باستخدام الرسوم البيانية لحساب الاستوكاستك.
لاحظ أن معظم الأسهم الزرقاء مختلفة كالمعتاد ، ولكن قد تتضمن بعض تحويلات العرض أيضًا عملية تحديد غير متمايزة ، والتي يتم تمييزها باللون الأحمر. يمكننا فقط المرور عبر الأسهم الزرقاء في الاتجاه المعاكس ، لكن السهم الأحمر هو تبعية لا يمكننا من خلالها عكس اتجاه backprop.سياسة التدرج لانقاذ! دعونا نفكر في جزء الشبكة الذي يقوم بأخذ العينات التي يمكن تمثيلها كدالة للسياسة العشوائية المضمنة في شبكة عصبية كبيرة. لذلك ، أثناء التدريب ، سنقدم العديد من الأمثلة (المشار إليها بواسطة الفروع أدناه) ، ثم سنشجع العينات التي تؤدي في النهاية إلى نتائج جيدة (في هذه الحالة ، على سبيل المثال ، تقاس بالخسائر في النهاية). بمعنى آخر ، سنقوم بتدريب المعلمات المضمّنة في الأسهم الزرقاء باستخدام backprop ، كالمعتاد ، ولكن سيتم الآن تحديث المعلمات المضمّنة في السهم الأحمر بغض النظر عن المسار العكسي باستخدام تدرجات السياسة ، مما يشجع العينات التي تؤدي إلى خسائر منخفضة. كانت هذه الفكرة مؤطرة بشكل جيد مؤخرًا.تقدير التدرج باستخدام الرسوم البيانية لحساب الاستوكاستك.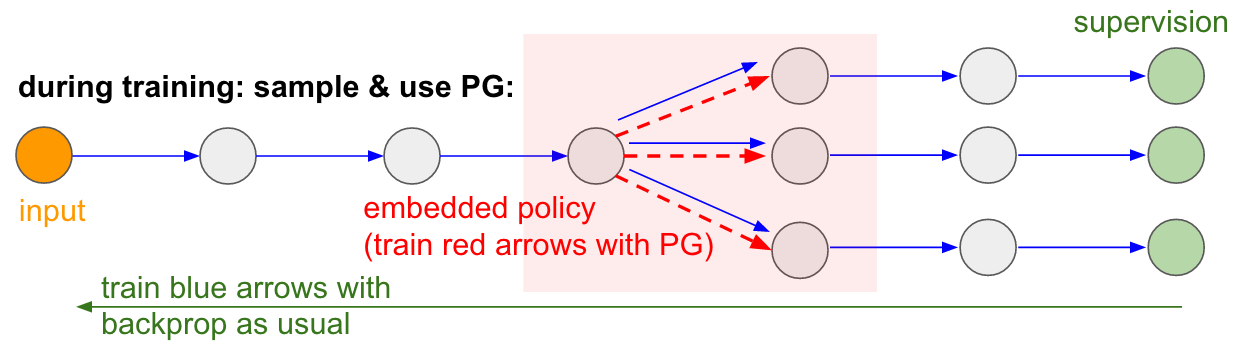 مدخلات الإدخال / الإخراج في ذاكرة الوصول العشوائي. سوف تجد هذه الفكرة أيضًا في العديد من المقالات الأخرى. على سبيل المثال ، تحتوي آلة Neural Turing على شريط ذاكرة يقرأون ويكتبون به. لتنفيذ عملية الكتابة ، تحتاج إلى القيام بشيء مثل m [i] = x ، حيث يتم التنبؤ i و x بواسطة الشبكة العصبية RNN. ومع ذلك ، لا توجد إشارة تخبرنا بما يمكن أن يحدث لوظيفة الخسارة إذا كتبنا j! = I. لذلك ، يمكن لـ NTM إجراء عمليات قراءة وكتابة ناعمة. يتنبأ بوظيفة توزيع الانتباه a ، ثم ينفذ لجميع i: m [i] = a [i] * x. أصبح الأمر مختلفًا الآن ، لكن علينا أن ندفع ثمنًا حسابيًا مرتفعًا ، حيث يتم فرز جميع الخلايا.ومع ذلك ، يمكننا استخدام تدرجات السياسة للتعامل مع هذه المشكلة من الناحية النظرية ، كما هو الحال في RL-NTM. ما زلنا نتوقع توزيع الانتباه (أ) ، ولكن بدلاً من البحث الشامل ، نختار أماكن للكتابة عشوائيًا: i = sample (a)؛ م [i] = س. أثناء التدريب ، يمكننا القيام بذلك لمجموعة صغيرة من i ، وفي النهاية ، سوف نجد مجموعة من شأنها أن تعمل بشكل أفضل من غيرها. ميزة حسابية كبيرة هي أنه أثناء الاختبار يمكنك القراءة / الكتابة من خلية واحدة. ومع ذلك ، كما هو موضح في المستند ، من الصعب جدًا الوصول إلى هذه الاستراتيجية ، لأنك بحاجة إلى استعراض العديد من الخيارات والذهاب إلى خوارزميات العمل تقريبًا عن طريق الخطأ. يوافق الباحثون حاليًا على أن PG يعمل جيدًا فقط عندما يكون هناك العديد من الخيارات المنفصلة ، عندما لا تحتاج إلى التمشيط عبر مساحات بحث ضخمة.ومع ذلك ، بمساعدة تدرجات السياسة ، وفي الحالات التي يتوفر فيها قدر كبير من البيانات وقوة الحوسبة ، يمكننا أن نحلم كثيرًا. على سبيل المثال ، يمكننا تصميم الشبكات العصبية التي تتعلم التفاعل مع الكائنات الكبيرة غير القابلة للتمييز ، مثل المجمعين اللاتكس. على سبيل المثال ، لكي يقوم char-rnn بإنشاء كود Latex جاهز ، أو نظام SLAM ، أو حل LQR ، أو أي شيء آخر. أو ، على سبيل المثال ، قد ترغب الذكاء الخارق في معرفة كيفية التفاعل مع الإنترنت عبر TCP / IP (وهو أيضًا غير قابل للتمييز) للوصول إلى المعلومات الضرورية لالتقاط العالم. هذا مثال رائع.
مدخلات الإدخال / الإخراج في ذاكرة الوصول العشوائي. سوف تجد هذه الفكرة أيضًا في العديد من المقالات الأخرى. على سبيل المثال ، تحتوي آلة Neural Turing على شريط ذاكرة يقرأون ويكتبون به. لتنفيذ عملية الكتابة ، تحتاج إلى القيام بشيء مثل m [i] = x ، حيث يتم التنبؤ i و x بواسطة الشبكة العصبية RNN. ومع ذلك ، لا توجد إشارة تخبرنا بما يمكن أن يحدث لوظيفة الخسارة إذا كتبنا j! = I. لذلك ، يمكن لـ NTM إجراء عمليات قراءة وكتابة ناعمة. يتنبأ بوظيفة توزيع الانتباه a ، ثم ينفذ لجميع i: m [i] = a [i] * x. أصبح الأمر مختلفًا الآن ، لكن علينا أن ندفع ثمنًا حسابيًا مرتفعًا ، حيث يتم فرز جميع الخلايا.ومع ذلك ، يمكننا استخدام تدرجات السياسة للتعامل مع هذه المشكلة من الناحية النظرية ، كما هو الحال في RL-NTM. ما زلنا نتوقع توزيع الانتباه (أ) ، ولكن بدلاً من البحث الشامل ، نختار أماكن للكتابة عشوائيًا: i = sample (a)؛ م [i] = س. أثناء التدريب ، يمكننا القيام بذلك لمجموعة صغيرة من i ، وفي النهاية ، سوف نجد مجموعة من شأنها أن تعمل بشكل أفضل من غيرها. ميزة حسابية كبيرة هي أنه أثناء الاختبار يمكنك القراءة / الكتابة من خلية واحدة. ومع ذلك ، كما هو موضح في المستند ، من الصعب جدًا الوصول إلى هذه الاستراتيجية ، لأنك بحاجة إلى استعراض العديد من الخيارات والذهاب إلى خوارزميات العمل تقريبًا عن طريق الخطأ. يوافق الباحثون حاليًا على أن PG يعمل جيدًا فقط عندما يكون هناك العديد من الخيارات المنفصلة ، عندما لا تحتاج إلى التمشيط عبر مساحات بحث ضخمة.ومع ذلك ، بمساعدة تدرجات السياسة ، وفي الحالات التي يتوفر فيها قدر كبير من البيانات وقوة الحوسبة ، يمكننا أن نحلم كثيرًا. على سبيل المثال ، يمكننا تصميم الشبكات العصبية التي تتعلم التفاعل مع الكائنات الكبيرة غير القابلة للتمييز ، مثل المجمعين اللاتكس. على سبيل المثال ، لكي يقوم char-rnn بإنشاء كود Latex جاهز ، أو نظام SLAM ، أو حل LQR ، أو أي شيء آخر. أو ، على سبيل المثال ، قد ترغب الذكاء الخارق في معرفة كيفية التفاعل مع الإنترنت عبر TCP / IP (وهو أيضًا غير قابل للتمييز) للوصول إلى المعلومات الضرورية لالتقاط العالم. هذا مثال رائع.الاستنتاجات
لقد رأينا أن تدرجات السياسة عبارة عن خوارزمية عامة قوية ، وكمثال على ذلك ، قمنا بتدريب وكيل ATARI Pong من وحدات البكسل الخام من نقطة الصفر في 130 سطر Python . بشكل عام ، يمكن استخدام نفس الخوارزمية لتدريب الوكلاء على الألعاب التعسفية ، ونأمل ، في يوم ما ، أن نستخدمها لحل مشكلات التحكم في العالم الحقيقي. في الختام ، أود أن أضيف بعض التعليقات الإضافية:حول تطوير الذكاء الاصطناعى. لقد رأينا أن الخوارزمية تعمل عن طريق البحث عن القوة الغاشمة ، والتي تتفاعل فيها بشكل عشوائي أولاً ويتعين عليك التعثر في المواقف المفيدة مرة واحدة على الأقل ، وغالبًا ما يتم ذلك ، قبل أن تغير وظيفة السياسة معالمها. ورأينا أيضًا أن الشخص يتعامل مع هذه الحلول لهذه المشكلات بطريقة مختلفة تمامًا ، والتي تشبه الإنشاء السريع لنموذج تجريدي. نظرًا لأن هذه النماذج التجريدية صعبة للغاية (إن لم يكن من المستحيل) تخيلها بشكل صريح ، فإن هذا هو السبب أيضًا في وجود اهتمام كبير في الآونة الأخيرة بالنماذج التوليفية وتحريض البرامج.حول استخدامها في الروبوتات.لا تنطبق الخوارزمية حيث يكون من الصعب الحصول على قدر كبير من الأبحاث. على سبيل المثال ، يمكن أن يكون لديك روبوت واحد (أو عدة) يتفاعل مع العالم في الوقت الفعلي. هذا لا يكفي لتطبيق ساذج من الخوارزمية. يتمثل أحد مجالات العمل المصممة للتخفيف من هذه المشكلة في التدرجات السياسية الحتمية . بدلاً من القيام بمحاولات حقيقية ، يحصل هذا النهج على معلومات متدرجة من شبكة عصبية ثانية (تسمى الناقد) تقوم بنمذجة وظيفة التقييم. يمكن لهذا النهج ، من حيث المبدأ ، أن يكون فعالًا مع الإجراءات عالية الأبعاد ، حيث توفر العينة العشوائية تغطية ضعيفة. هناك طريقة أخرى ذات صلة وهي زيادة الروبوتات التي بدأنا نراها في Google Robot Farmأو ربما حتى على تسلا S + مع الطيار الآلي.هناك أيضًا خط عمل يحاول جعل عملية البحث أقل ميؤوس منها بإضافة تحكم إضافي. على سبيل المثال ، في العديد من الحالات العملية ، يمكنك الحصول على الاتجاه الأولي للتنمية مباشرة من الشخص. على سبيل المثال، AlphaGo تشرف عليها الاستخدامات الأولى تعلم فقط استباق الإجراءات الشخص (مثل التحكم عن بعد من الروبوتات ، التلمذة ، تحسين المسار المنحنى ، سياسة بحث شاملة ). ثم تم تكوين السياسة الناتجة باستخدام PG لتحقيق الهدف الحقيقي - الفوز باللعبة.في بعض الحالات ، قد يكون هناك عدد أقل من الإعدادات المسبقة (على سبيل المثال ، للتحكم عن بعد في الروبوتات ) ، وتوجد طرق لاستخدام هذه البيانات قبل التدريب . أخيرًا ، إذا لم يقدم الأشخاص بيانات أو إعدادات محددة ، فيمكن الحصول عليها في بعض الحالات عن طريق الحساب باستخدام طرق تحسين باهظة الثمن إلى حد ما ، على سبيل المثال ، عن طريق تحسين المسار في نموذج ديناميكي معروف (مثل F = ma في محاكي مادي) أو في حالات عند إنشاء نموذج محلي تقريبي (كما هو موضح في بنية واعدة جدًا للبحث في السياسة المدارة).حول استخدام PG في الممارسة العملية.أود التحدث أكثر حول RNN. أعتقد أنه قد يبدو أن RNNs سحرية وتقوم تلقائيًا بحل المشكلات المتعلقة بالتسلسل التعسفي. والحقيقة هي أن الحصول على هذه النماذج للعمل يمكن أن يكون خادعا. مطلوب العناية والخبرة ، وكذلك معرفة متى يمكن أن تساعدك الأساليب الأكثر بساطة بنسبة 90٪. الشيء نفسه ينطبق على التدرجات السياسة. إنها لا تعمل تلقائيًا تمامًا مثل ذلك: تحتاج إلى العديد من الأمثلة ، ويمكن أن تتدرب إلى الأبد ، ومن الصعب تصحيحها عندما لا تعمل. يجب أن تحاول دائمًا إطلاق النار من مسدس صغير قبل الوصول إلى بازوكا. على سبيل المثال ، في حالة التدريب على التعزيز ، يجب دائمًا التحقق من طريقة الإنتروبيا (CEM) أولاً.، أسلوب "تخمين وتحقق" العشوائي البسيط المستوحى من التطور. وإذا كنت تصر على تجربة التدرجات السياسية لمهمتك ، فتأكد من معرفة الحيل المحددة. ابدأ بالبساطة واستخدم خيار PG يسمى TRPO ، والذي يعمل دائمًا بشكل أفضل وأكثر تناسقًا من PG الكلاسيكي . الفكرة الأساسية هي تجنب تحديث الإعدادات التي تغير سياستك أكثر من اللازم ، بسبب استخدام مسافة Kulbak-Leibler بين السياسة القديمة والسياسة الجديدة.هذا كل شئ!
آمل أن أكون قد قدمت لك فكرة عن مكاننا مع Reinforcement Learning ، ما هي المشاكل ، وإذا كنت ترغب في المساعدة في الترويج لـ RL ، أدعوك للقيام بذلك في OpenAI Gym :) أراك في المرة القادمة!
أندريه كارباثي ،باحث ومطور ومدير قسم الذكاء الاصطناعي والطيار الآلي تسلا.معلومات إضافية: دورة
التعلم العميق على الأصابع 2018
https://habr.com/ar/post/414165/
دورة التعلم العميق على الأصابع المفتوحة 2019
https: // habr.com/ru/company/ods/blog/438940/
كلية الفيزياء في NSU
http://www.phys.nsu.ru/