مرحبا بالجميع! أقدم إليكم ترجمة لمقالة Analytics Vidhya مع نظرة عامة على أحداث AI / ML في 2018 و 2019. المواد كبيرة جدًا ، بحيث يتم تقسيمها إلى قسمين. آمل أن لا تهم المقالة المتخصصين المتخصصين فقط ، ولكن أيضًا المهتمين بموضوع الذكاء الاصطناعى. هل لديك قراءة لطيفة!
مقدمة
لقد مرت السنوات القليلة الماضية لعشاق الذكاء الاصطناعى ومحترفي التعلم الآلي سعيا وراء الحلم. لم تعد هذه التقنيات مناسبة ، وأصبحت سائدة وتؤثر بالفعل على حياة ملايين الأشخاص في الوقت الحالي. تم إنشاء وزارات منظمة العفو الدولية في بلدان مختلفة [
مزيد من التفاصيل هنا - تقريبا. لكل.] ويتم تخصيص الميزانيات لمواكبة هذا السباق.
وينطبق الشيء نفسه بالنسبة لمتخصصي علم البيانات. قبل بضع سنوات ، قد تشعر بالراحة لمعرفة بعض الأدوات والحيل ، ولكن هذه المرة قد مرت. عدد الأحداث الأخيرة في علم البيانات ومقدار المعرفة اللازمة لمواكبة العصر في هذا المجال مذهلة.
قررت العودة إلى الوراء والنظر في التطورات في بعض المجالات الرئيسية في مجال الذكاء الاصطناعي من وجهة نظر خبراء علم البيانات. ما اندلعت حدثت؟ ماذا حدث في عام 2018 وما الذي يمكن توقعه في عام 2019؟ قراءة هذا المقال للحصول على إجابات!
ملاحظة: كما هو الحال في أي توقع ، فيما يلي استنتاجاتي الشخصية بناءً على محاولات دمج الأجزاء الفردية في الصورة بأكملها. إذا كانت وجهة نظرك مختلفة عن وجهة نظري ، فسوف يسعدني أن أعرف رأيك حول ما قد يتغير في علم البيانات في عام 2019.
المجالات التي سنغطيها في هذه المقالة هي:
- بروسس اللغة الطبيعية (NLP)
- رؤية الكمبيوتر
- الأدوات والمكتبات
- تعزيز التعلم
- قضايا الأخلاق في الذكاء الاصطناعى
معالجة اللغات الطبيعية (NLP)
كانت إجبار الآلات على تحليل الكلمات والجمل دائمًا تبدو وكأنها حلم بعيد المنال. هناك الكثير من الفروق الدقيقة والميزات في اللغات التي يصعب فهمها في بعض الأحيان حتى بالنسبة للأشخاص ، ولكن عام 2018 كان نقطة تحول حقيقية لـ NLP.
شاهدنا طفرة رائعة واحدة تلو الأخرى: ULMFiT ، ELMO ، OpenAl Transformer ، Google BERT ، وهذه ليست قائمة كاملة. التطبيق الناجح لتعلم النقل (فن تطبيق النماذج المدربة مسبقًا على البيانات) قد فتح الباب أمام البرمجة اللغوية العصبية في مجموعة متنوعة من المهام.
نقل التعلم - يتيح لك تكييف نموذج / نظام مُدرَّب مسبقًا مع مهمتك المحددة باستخدام كمية صغيرة نسبيًا من البيانات.
دعونا نلقي نظرة على بعض هذه التطورات الرئيسية بمزيد من التفصيل.
ألميفت
تم تطوير ULMFiT من قِبل سيباستيان رودر وجيريمي هوارد (fast.ai) ، وكان أول إطار يتلقى التعلم في مجال النقل هذا العام. بالنسبة للمبتدئين ، يشير اختصار ULMFiT إلى "ضبط اللغة بلغة نموذج عالمية". أضاف جيريمي وسيباستيان بحق كلمة "عالمية" إلى ULMFiT - يمكن تطبيق هذا الإطار على أي مهمة في البرمجة اللغوية العصبية تقريبًا!
أفضل ما في ULMFiT هو أنك لست بحاجة إلى تدريب الموديلات من الصفر! لقد قام الباحثون بالفعل بالأكثر صعوبة بالنسبة لك - التقدم والتقديم في مشاريعك. تفوقت ULMFiT على الطرق الأخرى في ستة مهام لتصنيف النصوص.
يمكنك
قراءة البرنامج التعليمي بواسطة Pratek Joshi [Pateek Joshi - تقريبا. عبر.] حول كيفية البدء في استخدام ULMFiT لأي مهمة من تصنيف النص.
إلمو
خمن ماذا يعني اختصار ELMo؟ اختصار لحفلات الزفاف من نماذج اللغة [مرفقات من نماذج اللغة - تقريبا. عبر.]. ولفت ELMo انتباه المجتمع ML مباشرة بعد الإصدار.
يستخدم ELMo نماذج اللغة لتلقي مرفقات لكل كلمة ، ويأخذ أيضًا في الاعتبار السياق الذي تتناسب فيه الكلمة مع جملة أو فقرة. السياق هو جانب هام من البرمجة اللغوية العصبية ، حيث فشل معظم المطورين في السابق. يستخدم ELMo LSTMs ثنائية الاتجاه لإنشاء مرفقات.
الذاكرة طويلة المدى (LSTM) هي نوع من بنية الشبكات العصبية المتكررة التي اقترحها في عام 1997 سيب هوكرتر ويورن شميدهوبر. مثل معظم الشبكات العصبية المتكررة ، تعد شبكة LSTM عالمية بمعنى أنه مع وجود عدد كافٍ من عناصر الشبكة ، يمكنها إجراء أي حساب يمكن للكمبيوتر العادي أن يتطلبه ، وهو ما يتطلب مصفوفة وزن مناسبة يمكن اعتبارها برنامجًا. على عكس الشبكات العصبية المتكررة التقليدية ، فإن شبكة LSTM مناسبة تمامًا للتدريب على مشاكل تصنيف السلاسل الزمنية ومعالجتها والتنبؤ بها في الحالات التي يتم فيها فصل الأحداث المهمة بفارق زمني مع مدة غير محدودة وحدود.
- المصدر. ويكيبيديا
مثل ULMFiT ، يحسن ELMo الإنتاجية بشكل كبير في حل عدد كبير من مهام البرمجة اللغوية العصبية ، مثل تحليل مزاج النص أو الإجابة على الأسئلة.
بيرت من جوجل
يلاحظ الكثير من الخبراء أن إصدار BERT يمثل بداية عهد جديد في البرمجة اللغوية العصبية. بعد ULMFiT و ELMo ، تولى بيرت الصدارة ، مما يدل على الأداء العالي. كما ينص الإعلان الأصلي: "بيرت بسيط من الناحية المفاهيمية وقوي من الناحية التجريبية."
لقد أظهر بيرت نتائج رائعة في 11 مهمة في البرمجة اللغوية العصبية! شاهد النتائج في اختبارات SQuAD:
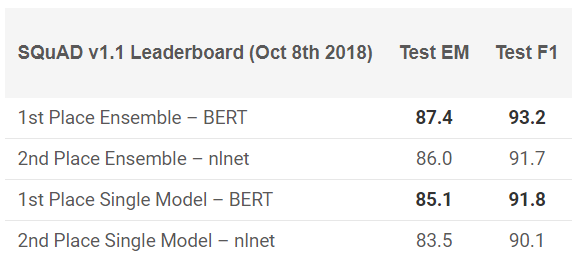
تريد أن تجرب ذلك؟ يمكنك استخدام إعادة التنفيذ على رمز PyTorch أو TensorFlow من Google ومحاولة تكرار النتيجة على جهازك.
فيسبوك PyText
كيف يمكن للفيسبوك الابتعاد عن هذا السباق؟ تقدم الشركة إطار عمل البرمجة اللغوية العصبية مفتوح المصدر الخاص به والمسمى PyText. وفقًا لدراسة نشرتها Facebook ، زادت PyText من دقة نماذج المحادثة بنسبة 10٪ وقلصت وقت التدريب.
PyText هو في الواقع وراء العديد من منتجات Facebook الخاصة ، مثل Messenger. لذا فإن العمل معه سيضيف نقطة جيدة إلى محفظتك ومعرفتك القيمة التي ستكسبها بلا شك.
يمكنك تجربتها بنفسك ، قم
بتنزيل الكود من جيثب .
جوجل على الوجهين
من الصعب تصديق أنك لم تسمع عن Google Duplex. فيما يلي عرض توضيحي لفترة طويلة في العناوين الرئيسية:
نظرًا لأن هذا منتج من منتجات Google ، فهناك فرصة ضئيلة لأن يتم نشر الشفرة عاجلاً أم آجلاً للجميع. بالطبع ، هذا العرض التوضيحي يثير العديد من الأسئلة: من القضايا الأخلاقية إلى الخصوصية ، ولكن سنتحدث عن ذلك لاحقًا. الآن ، فقط استمتع بمدى وصولنا إلى ML في السنوات الأخيرة.
2019 اتجاهات البرمجة اللغوية العصبية
من هو أفضل من سيباستيان رودر نفسه يمكنه إعطاء فكرة عن المكان الذي يتجه NLP إليه في عام 2019؟ وهنا النتائج التي توصل إليها:
- سيصبح استخدام نماذج الاستثمار اللغوي المدرَّب مسبقًا واسع الانتشار ؛ سوف النماذج المتقدمة دون دعم تكون نادرة جدا.
- ستظهر المشاهدات المدربة مسبقًا والتي يمكنها تشفير المعلومات المتخصصة التي تكمل مرفقات نموذج اللغة. سنكون قادرين على تجميع أنواع مختلفة من العروض التقديمية المدربة مسبقًا وفقًا لمتطلبات المهمة.
- سوف يظهر المزيد من العمل في مجال التطبيقات متعددة اللغات والنماذج متعددة اللغات. على وجه الخصوص ، بالاعتماد على تضمين الكلمات بين اللغات ، سنرى ظهور تمثيلات لغوية عميقة مُدرَّبة مسبقًا.
رؤية الكمبيوتر

اليوم ، رؤية الكمبيوتر هي المنطقة الأكثر شعبية في مجال التعلم العميق. يبدو أن الثمار الأولى للتكنولوجيا تم الحصول عليها بالفعل ونحن في مرحلة التطوير النشط. بغض النظر عما إذا كانت هذه الصورة أو الفيديو ، نرى ظهور العديد من الأطر والمكتبات التي تحل مشاكل رؤية الكمبيوتر بسهولة.
إليكم قائمة أفضل الحلول التي يمكن رؤيتها هذا العام.
BigGANs خارج
صمم Ian Goodfellow شبكات GAN في عام 2014 ، وأنتج المفهوم مجموعة واسعة من التطبيقات. سنة بعد سنة ، لاحظنا كيف تم الانتهاء من المفهوم الأصلي للاستخدام في الحالات الحقيقية. ولكن بقي شيء واحد دون تغيير حتى هذا العام - الصور التي تم إنشاؤها بواسطة الكمبيوتر كانت سهلة التمييز. ظهر عدم تناسق معين دائمًا في الإطار ، مما جعل الفرق واضحًا جدًا.
في الأشهر الأخيرة ، ظهرت تحولات في هذا الاتجاه ، ومع
إنشاء BigGAN ، يمكن حل هذه المشكلات مرة واحدة وإلى الأبد. انظر إلى الصور الناتجة عن هذه الطريقة:

بدون مجهر ، من الصعب أن نقول ما هو الخطأ في هذه الصور. بطبيعة الحال ، سيقرر الجميع لنفسه ، ولكن لا شك في أن GAN يغير الطريقة التي نتصور بها الصور الرقمية (والفيديو).
كمرجع: تم تدريب هذه النماذج لأول مرة على مجموعة بيانات ImageNet ، ثم على JFT-300M لإثبات أن هذه النماذج يتم نقلها جيدًا من مجموعة بيانات إلى أخرى. فيما يلي
رابط لصفحة من قائمة GAN البريدية تشرح كيفية تصور GAN وفهمه.
نموذج Fast.ai تدرب على ImageNet في 18 دقيقة
هذا هو تطبيق رائع حقا. هناك اعتقاد واسع النطاق بأنه ، لأداء مهام التعلم العميق ، ستحتاج إلى تيرابايت من البيانات وموارد الحوسبة الكبيرة. وينطبق الشيء نفسه على تدريب النموذج من نقطة الصفر على بيانات ImageNet. فكر معظمنا بنفس الطريقة قبل قليل من الناس في الصوم. لم يتمكنوا من إثبات عكس الجميع.
أعطى نموذجهم دقة 93 ٪ مع 18 دقيقة مثيرة للإعجاب. تتألف الأجهزة التي استخدموها ،
الموضحة بالتفصيل
على مدونتهم ، من 16 حالة سحابة AWS عامة ، كل منها يحتوي على 8 وحدات معالجة الرسومات NVIDIA V100. بنوا خوارزمية باستخدام مكتبات fast.ai و PyTorch.
التكلفة الإجمالية للتجميع 40 دولار فقط! وصف جيريمي أساليبهم
وطرقهم بمزيد من التفصيل
هنا . هذا نصر مشترك!
vid2vid من NVIDIA
على مدار السنوات الخمس الماضية ، قطعت معالجة الصور خطوات كبيرة ، ولكن ماذا عن الفيديو؟ تبين أن طرق التحويل من إطار ثابت إلى إطار ديناميكي أكثر تعقيدًا قليلاً مما كان متوقعًا. هل يمكنك التقاط تسلسل الإطارات من الفيديو والتنبؤ بما سيحدث في الإطار التالي؟ وقد أجريت هذه الدراسات من قبل ، ولكن المنشورات كانت غامضة في أحسن الأحوال.

قررت NVIDIA إتاحة قرارها للجمهور في وقت سابق من هذا العام [2018 - تقريبًا. في.] ، والتي تم تقييمها بشكل إيجابي من قبل المجتمع. الغرض من vid2vid هو استخلاص وظيفة عرض من فيديو إدخال معين من أجل إنشاء فيديو إخراج ينقل محتويات الفيديو المدخلات بدقة لا تصدق.
يمكنك تجربة تنفيذها على PyTorch ، خذها
إلى جيثب هنا .
اتجاهات رؤية الماكينة لعام 2019
كما ذكرت سابقًا ، في عام 2019 ، من المرجح أن نشهد تطور اتجاهات 2018 ، بدلاً من اختراقات جديدة: السيارات ذاتية القيادة ، خوارزميات التعرف على الوجوه ، والواقع الافتراضي والمزيد. هل يمكن أن تتعارض معي إذا كان لديك وجهة نظر أو إضافات مختلفة ، وشاركها معنا ، ماذا يمكننا أن نتوقع في عام 2019؟
قضية الطائرات بدون طيار ، في انتظار موافقة السياسيين والحكومة ، قد تحصل في النهاية على ضوء أخضر في الولايات المتحدة (الهند متأخرة في هذا الأمر). شخصيا ، أود إجراء مزيد من البحوث في سيناريوهات العالم الحقيقي. تقدم مؤتمرات مثل
CVPR و
ICML تغطية جيدة لأحدث الإنجازات في هذا المجال ، ولكن مدى قرب المشاريع من الواقع ليس واضحًا للغاية.
"الإجابة على الأسئلة المرئية" و "أنظمة الحوار المرئية" قد تظهر أخيرًا مع ظهور طال انتظاره. تفتقر هذه الأنظمة إلى القدرة على التعميم ، لكن من المتوقع أن نرى قريبًا نهجًا متعدد الوسائط متكاملًا.
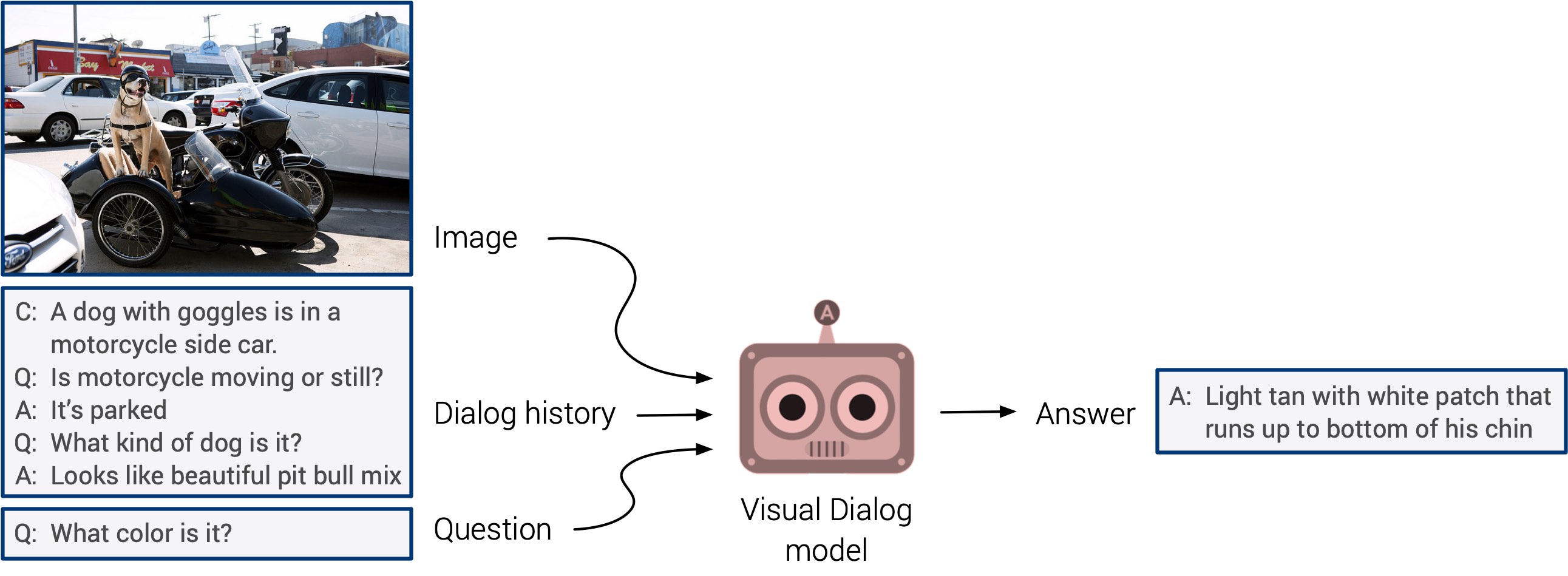
جاء التدريب الذاتي في المقدمة هذا العام. أراهن أنه في العام المقبل سيجد التطبيق في عدد أكبر بكثير من الدراسات. هذا اتجاه رائع حقًا: يتم تحديد العلامات مباشرةً من بيانات الإدخال ، بدلاً من إضاعة الوقت في تحديد الصور يدويًا. دعونا نبقي أصابعنا متقاطعة!