ما مدى تعقيد موضوع التعلم الآلي؟ إذا كنت جيدًا في الرياضيات ، لكن مقدار المعرفة بالتعلم الآلي يميل إلى الصفر ، إلى أي مدى يمكنك الذهاب في منافسة جادة على منصة
Kaggle ؟

عن الموقع والمسابقة
Kaggle هي مجموعة من الأشخاص المهتمين بـ ML (من المبتدئين إلى المحترفين البارعين) ومكانًا للمسابقات (غالبًا مع مجموعة جوائز رائعة).
للانغماس على الفور في كل سحر ML ، قررت اختيار منافسة جدية على الفور. كان هذا متاحًا للتو:
اثنان من سيجما: استخدام الأخبار للتنبؤ بحركات الأسهم . يتمثل جوهر المسابقة باختصار في التنبؤ بسعر أسهم مختلف الشركات بناءً على حالة الأصل والأخبار المتعلقة بهذا الأصل. تبلغ قيمة جائزة المسابقة 100000 دولار ، وسيتم توزيعها على المشاركين الذين فازوا بالمراكز السبعة الأولى.
المسابقة خاصة لسببين:
- هذه مسابقة Kernels فقط: يمكنك تدريب الموديلات فقط في سحابة Kaggle Kernels ؛
- سيُعرف التوزيع النهائي للمقاعد بعد ستة أشهر فقط من الانتهاء من صنع القرار ؛ خلال هذا الوقت ، ستتوقع القرارات الأسعار في التاريخ الحالي.
عن المهمة
بشرط ، يجب أن نتوقع الثقة
في أن العائد على الأصول سوف تزيد. يعتبر العائد على الأصل متعلقًا بعائد السوق ككل. القياس المستهدف مخصص - فهو ليس
RMSE أو
MAE الأكثر دراية ، ولكن
نسبة Sharpe ، والتي تعتبر في هذه الحالة على النحو التالي:
اين
،
- العائد على الأصول بالنسبة إلى السوق لليوم t في أفق 10 أيام ،
- متغير منطقي يشير إلى ما إذا كان قد تم تضمين الأصل ith في التقييم لليوم t ،
- متوسط القيمة
،
- الانحراف المعياري
.
نسبة شارب هي العائد المعدل حسب المخاطر ، وقيم المعامل تظهر فعالية المتداول:
- أقل من 1: ضعف الأداء
- 1-2: متوسطة ، كفاءة طبيعية ،
- 2 - 3: الأداء الممتاز ،
- فوق 3: الكمال.
حركة السوق البيانات- الوقت (datetime64 [ns، UTC]) - الوقت الحالي (في بيانات حركة السوق في جميع الخطوط في الساعة 22:00 بالتوقيت العالمي المنسق)
- مادة العرض (الكائن) - معرف الأصول
- (اسم الفئة) - معرف مجموعة أصول للتواصل مع بيانات الأخبار
- الكون (float64) - قيمة منطقية تشير إلى ما إذا كانت هذه المادة ستؤخذ في الاعتبار عند حساب النتيجة
- حجم التداول (float64) - حجم التداول اليومي
- إغلاق (float64) - سعر الإغلاق لهذا اليوم
- مفتوح (float64) - سعر مفتوح لهذا اليوم
- ReturnClosePrevRaw1 (float64) - العائد من الإغلاق إلى الإغلاق لليوم السابق
- ReturnOpenPrevRaw1 (float64) - الربحية من الافتتاح إلى الافتتاح لليوم السابق
- ReturnClosePrevMktres1 (float64) - الربحية من الإغلاق إلى الإغلاق لليوم السابق ، بعد تعديلها وفقًا لحركة السوق ككل
- ReturnOpenPrevMktres1 (float64) - الربحية من الافتتاح إلى الافتتاح لليوم السابق ، بعد تعديلها وفقًا لحركة السوق ككل
- ReturnClosePrevRaw10 (float64) - العائد من الإغلاق على مدار الأيام العشرة الماضية
- ReturnOpenPrevRaw10 (float64) - الربحية من الافتتاح إلى الافتتاح للأيام العشرة السابقة
- ReturnClosePrevMktres10 (float64) - العائد من الإغلاق على مقربة للأيام العشرة الماضية ، بعد تعديله وفقًا لحركة السوق ككل
- ReturnOpenPrevMktres10 (float64) - العائد من الافتتاح إلى الافتتاح للأيام العشرة السابقة ، بعد تعديله وفقًا لحركة السوق ككل
- ReturnOpenNextMktres10 (float64) - حقق العائد من الفتح لفتح خلال الأيام العشرة التالية ، بعد تعديله لحركة السوق ككل. سوف نتوقع هذه القيمة.
بيانات الأخبار- الوقت (datetime64 [ns، UTC]) - الوقت في توفر بيانات UTC
- sourceTimestamp (datetime64 [ns، UTC]) - الوقت في نشر أخبار UTC
- firstCreated (datetime64 [ns، UTC]) - الوقت بالتوقيت العالمي المنسق (UTC) للإصدار الأول من البيانات
- sourceId (كائن) - معرف السجل
- العنوان (الكائن) - العنوان
- إلحاح (int8) - أنواع الأخبار (1: تنبيه ، 3: مقال)
- takeSequence (int16) - معلمة غير واضحة تمامًا ، الرقم في بعض التسلسل
- المزود (الفئة) - معرف مزود الأخبار
- الموضوعات (الفئة) - قائمة برموز موضوع الأخبار (قد تكون علامة جغرافية أو حدثًا أو قطاعًا صناعيًا ، إلخ.)
- شرائح الجمهور (الفئة) - قائمة أخبار رموز الجمهور
- bodySize ( int32 ) - عدد الشخصيات في نص الأخبار
- companyCount (int8) - عدد الشركات المذكورة صراحة في الأخبار
- headlineTag (كائن) - علامة عنوان معينة من طومسون رويترز
- marketCommentary (منطقي) - إشارة إلى أن الأخبار تتعلق بظروف السوق العامة
- الجملةالعدد (int16) - عدد العروض في الأخبار
- wordCount ( int32 ) - عدد الكلمات وعلامات الترقيم في الأخبار
- رمز الأصول (فئة) - قائمة الأصول المذكورة في الأخبار
- اسم الأصول (الفئة) - رمز مجموعة الأصول
- firstMentionSentence (int16) - جملة تذكر أولاً أحد الأصول:
- الصلة (float32) - رقم من 0 إلى 1 ، يُظهر أهمية الأخبار المتعلقة بالأصل
- sentimentClass (int8) - فئة الدرجة اللونية للأخبار
- sentimentNegative (float32) - احتمال أن تكون الدرجة اللونية سلبية
- sentimentNeutral (float32) - احتمال أن تكون النغمة محايدة
- sentimentPositive (float32) - احتمال أن يكون المفتاح إيجابيًا
- sentimentWordCount (int32) - عدد الكلمات في النص المتعلقة بالأصل
- noveltyCount12H (int16) - أخبار "الجدة" في 12 ساعة ، محسوبة بالنسبة إلى الأخبار السابقة حول هذا الأصل
- newtycount24h (int16) - نفسه ، في غضون 24 ساعة
- noveltyCount3D (int16) - نفسه ، في 3 أيام
- noveltyCount5D (int16) - نفسه ، في 5 أيام
- noveltyCount7D (int16) - نفسه ، في 7 أيام
- volumeCounts12H (int16) - مقدار الأخبار حول هذا الأصل في 12 ساعة
- volumeCounts24H (int16) - نفسه ، في 24 ساعة
- volumeCounts3D (int16) - نفسه ، في 3 أيام
- volumeCounts5D (int16) - نفسه ، لمدة 5 أيام
- volumeCounts7D (int16) - نفسه ، في 7 أيام
المهمة هي في الأساس مهمة التصنيف الثنائي ، أي أننا نتوقع علامة ثنائية ، ستؤدي إلى زيادة (فئة واحدة) أو نقصان (فئة 0).
حول الأدوات
Kaggle Kernels هي عبارة عن منصة الحوسبة السحابية التي تدعم التعاون. الأنواع التالية من النوى مدعومة:
- بيثون النصي
- النصي R
- دفتر Jupyter
- RMarkdown
كل نواة تعمل في حاوية الإرساء. يتم تثبيت عدد كبير من الحزم في الحاوية ، ويمكن الاطلاع على قائمة بيثون
هنا . المواصفات الفنية هي كما يلي:
- وحدة المعالجة المركزية: 4 النوى ،
- ذاكرة الوصول العشوائي: 17 جيجابايت ،
- محرك الأقراص: 5 جيجابايت دائم و 16 جيجابايت مؤقت ،
- الحد الأقصى لوقت تشغيل البرنامج النصي: 9 ساعات (في وقت بدء المسابقة كان 6 ساعات).
تتوفر وحدات معالجة الرسومات أيضًا في Kernels ، ومع ذلك ، تم حظر GPU في هذه المسابقة.
Keras هو إطار شبكي عصبي عالي المستوى يعمل أعلى
TensorFlow أو
CNTK أو
Theano . إنها واجهة برمجة تطبيقات مريحة للغاية ويمكن فهمها ، ومن الممكن إضافة طبولوجيا الشبكة ووظائف الخسارة والمزيد باستخدام واجهة برمجة تطبيقات الواجهة الخلفية.
Scikit-learn هي مكتبة كبيرة من خوارزميات التعلم الآلي. مصدر مفيد لخوارزميات معالجة البيانات وتحليل البيانات لاستخدامها مع أطر عمل أكثر تخصصًا.
التحقق من صحة النموذج
قبل إرسال النموذج للتقييم ، تحتاج إلى التحقق بطريقة أو بأخرى محليًا من حسن سيره - أي التوصل إلى طريقة للتحقق المحلي. جربت الطرق التالية:
- التحقق من الصحة مقابل التقسيم النسبي البسيط إلى مجموعات تدريب / اختبار ؛
- الحساب المحلي لنسبة شارب مقابل ROC AUC .
نتيجةً لذلك ، أظهرت النتائج الأقرب إلى التقييم التنافسي ، بشكل غريب بما فيه الكفاية ، مزيجًا من القسم التناسبي (تم تحديد القسم تجريبيًا 0.85 / 0.15) و AUC. ربما لا يكون التحقق من الصحة مناسبًا جدًا ، لأن سلوك السوق مختلف تمامًا في المراحل الأولى من بيانات التدريب وفي فترة التقييم. لماذا عملت AUC أفضل من نسبة شارب - لا أستطيع أن أقول على الإطلاق.
المحاولات الأولى
نظرًا لأن المهمة تتمثل في التنبؤ بالسلاسل الزمنية ، فقد تم اختبار الحل الأول - وهو عبارة عن شبكة عصبية متكررة (
RNN ) أو بالأحرى متغيراتها
LSTM و
GRU .
المبدأ الرئيسي للشبكات المتكررة هو أنه بالنسبة لكل قيمة إخراج ، ليست هناك عينة واحدة هي المدخلات ، ولكن تسلسل كامل. ويترتب على ذلك ما يلي:
- نحن بحاجة إلى بعض المعالجة المسبقة للبيانات الأولية - إنشاء هذه التسلسلات ذاتها من الطول ر أيام لكل الأصول ؛
- لا يمكن للنموذج القائم على شبكة متكررة أن يتنبأ بقيمة المخرجات إذا لم تكن هناك بيانات لأيام t السابقة.
لقد قمت بإنشاء تسلسلات كل يوم ، بدءًا من t ، لذلك لم تعد المجموعة الكاملة لعينات التدريب مناسبة للذاكرة في حالة t الكبيرة إلى حد ما (من 20). تم حل المشكلة باستخدام المولدات ، حيث يمكن لـ Keras استخدام المولدات كمجموعات بيانات المدخلات والمخرجات لكل من التدريب والتنبؤ.
كان الإعداد الأولي للبيانات ساذجًا قدر الإمكان: نحن نأخذ بيانات السوق بأكملها بالإضافة إلى إضافة اثنين من الميزات (يوم الأسبوع والشهر ورقم الأسبوع من السنة) ، ونحن لا نلمس بيانات الأخبار على الإطلاق.
استخدم النموذج الأول t = 10 وبدا كما يلي:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
لم يتم ضغط أي شيء مناسب من هذا النموذج ، وكانت النتيجة قريبة من الصفر (حتى ناقصًا قليلًا).
الشبكات التلافيفية الزمنية
حل الشبكة العصبية الأكثر حداثة للتنبؤ بالسلسلة الزمنية هو TCN. جوهر هذه الطوبولوجيا بسيط للغاية: نأخذ شبكة تلافيفية أحادية البعد ونطبقها على تسلسل الطول t. تستخدم خيارات أكثر تقدمًا العديد من الطبقات التلافيفية ذات الامتداد المختلف. تم نسخ تطبيق TCN جزئيًا (أحيانًا على مستوى الفكرة)
من هنا (تصوّر مكدس TCN مأخوذ من
مقالة Wavenet ).
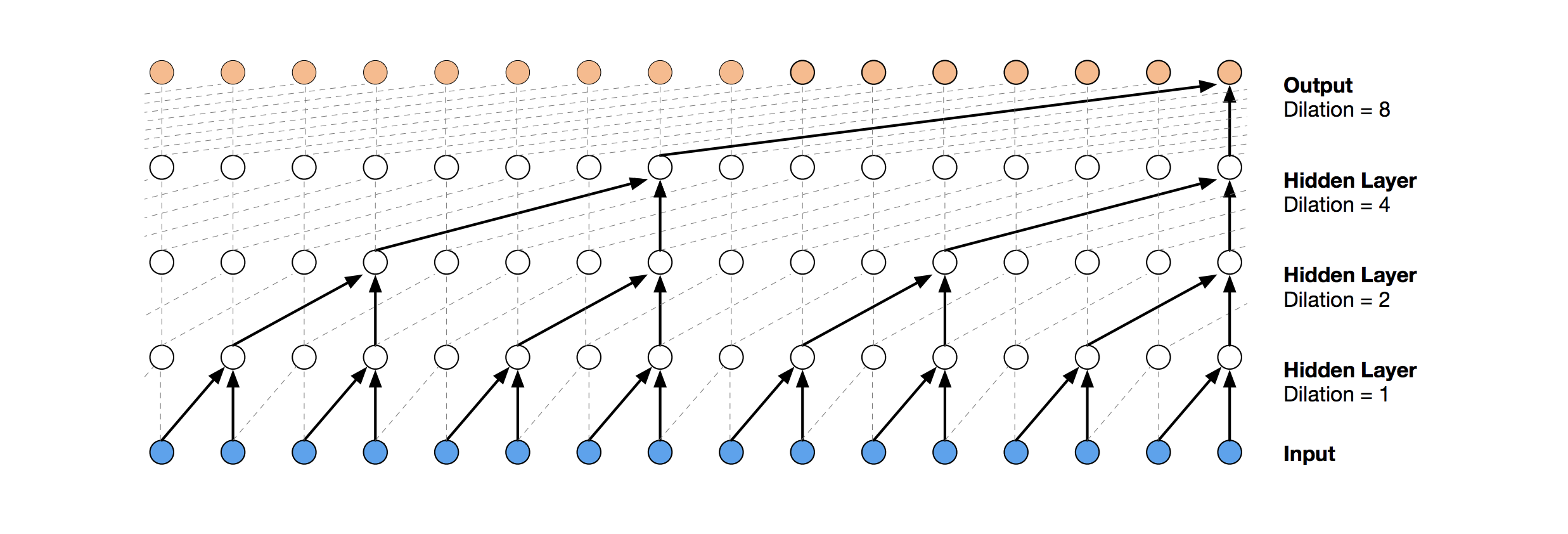
كان الحل الأول الناجح نسبيًا هو هذا النموذج ، والذي يتضمن طبقة GRU أعلى TCN:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
ينتج هذا النموذج الدرجات = 0.27668. مع القليل من الضبط (عدد فلاتر TCN ، حجم الدُفعة) وزيادة في t إلى 100 ، حصلنا على 0.41092 بالفعل:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
بعد ذلك نضيف التطبيع والتسرب:
كود batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
بتطبيق هذا النموذج ، بما في ذلك في الخطوات المبكرة (مع t = 1) ، نحصل على النتيجة = 0.53578.
آلات تعزيز التدرج
في هذه المرحلة ، انتهت الأفكار ، وقررت أن أفعل ما يجب القيام به في البداية: رؤية القرارات العامة للمشاركين الآخرين. معظم الحلول الجيدة لم تستخدم الشبكات العصبية على الإطلاق ، مفضلة GBM.
Gradient Boosting هي طريقة ML ، حيث يتم الحصول على مجموعة من النماذج البسيطة (غالبًا أشجار القرار). نظرًا للعدد الكبير من هذه النماذج البسيطة ، تم تحسين وظيفة الخسارة. يمكنك قراءة المزيد حول Gradient Boosting ، على سبيل المثال ،
هنا .
كما استخدم تطبيق GBM
lightgbm - إطار عمل مشهور إلى حد ما من Microsoft.
يعطي النموذج والمعالجة المسبقة للبيانات المأخوذة
من هنا على الفور درجة 0.64:
كود def prepare_data(marketdf, newsdf):
تشتمل المعالجة المسبقة هنا بالفعل على بيانات الأخبار ، والجمع بينها وبين بيانات السوق (ومع ذلك ، فإنه من السذاجة إلى حد ما ، يتم أخذ شفرة أصول واحدة فقط من كل ما ذكر في الأخبار في الاعتبار). أخذت هذا الخيار قبل المعالجة كأساس لجميع القرارات اللاحقة.
بإضافة ميزة صغيرة (firstMentionSentence و marketCommentary و sentimentClass) ، وكذلك استبدال المقياس بـ
ROC AUC ، نحصل على 0.65389.
فرقة
كان القرار الناجح التالي هو استخدام مجموعة تتكون من نموذج شبكة عصبية و GBM (على الرغم من أن "الفرقة" اسم كبير لنموذجين). يتم الحصول على التنبؤ الناتج عن طريق حساب متوسط تنبؤات النموذجين ، وبالتالي تطبيق آلية التصويت اللين. سمح هذا القرار للحصول على درجة 0.66879.
تحليل البيانات الاستكشافية وهندسة المعالم
شيء آخر لتبدأ كان EDA. بعد أن قرأت أنه من المهم فهم العلاقة بين الميزات ، فإننا نبني مثل هذه الصورة (الصور في هذا القسم قابلة للنقر):
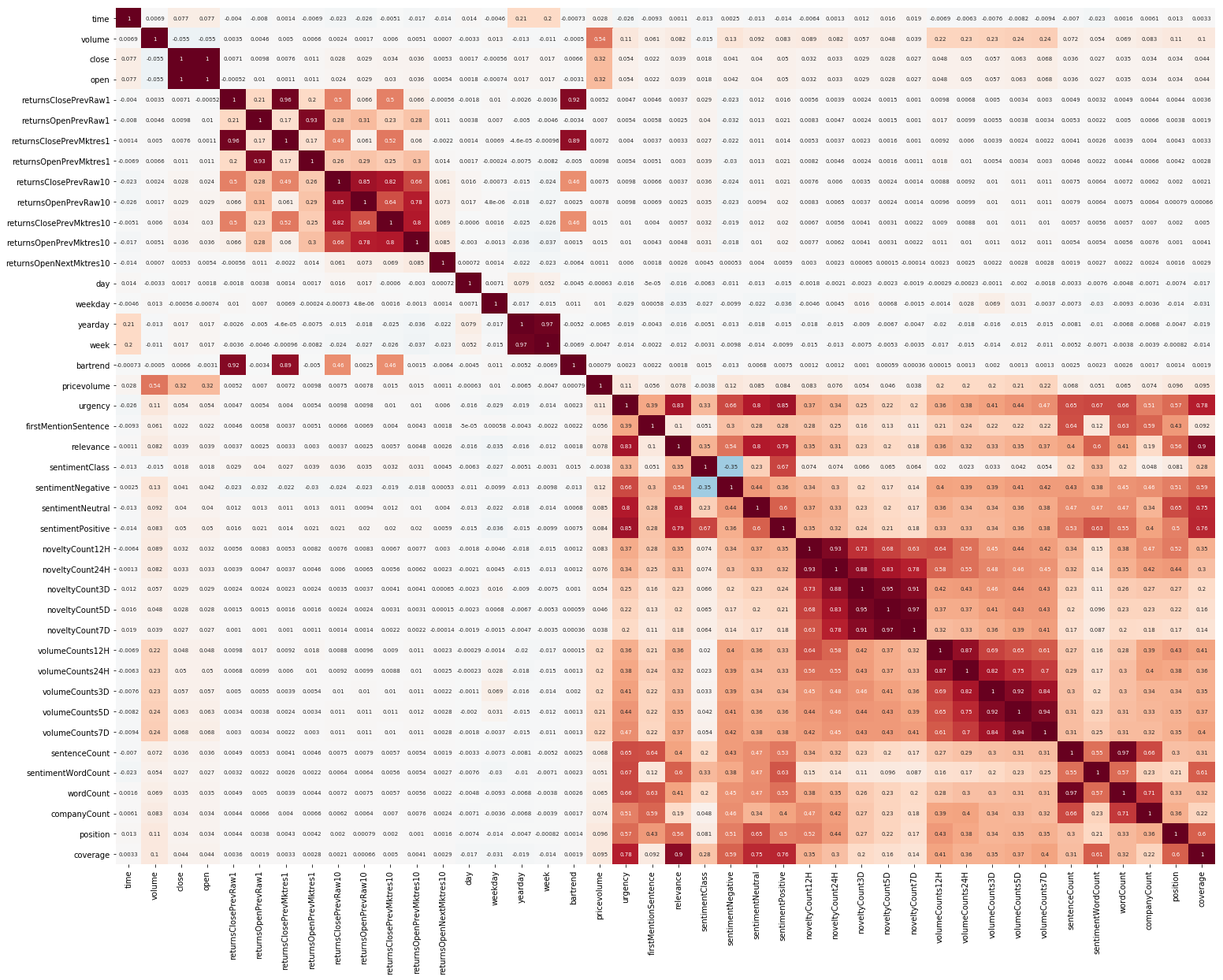
من الواضح هنا أن الارتباط بشكل منفصل داخل السوق وبيانات الأخبار مرتفع جدًا ، ومع ذلك ، فإن قيم العائدات فقط ترتبط بالقيمة المستهدفة بطريقة أو بأخرى على الأقل. نظرًا لأن البيانات تمثل سلسلة زمنية ، فمن المنطقي أيضًا أن ننظر إلى الارتباط التلقائي للقيمة الهدف:
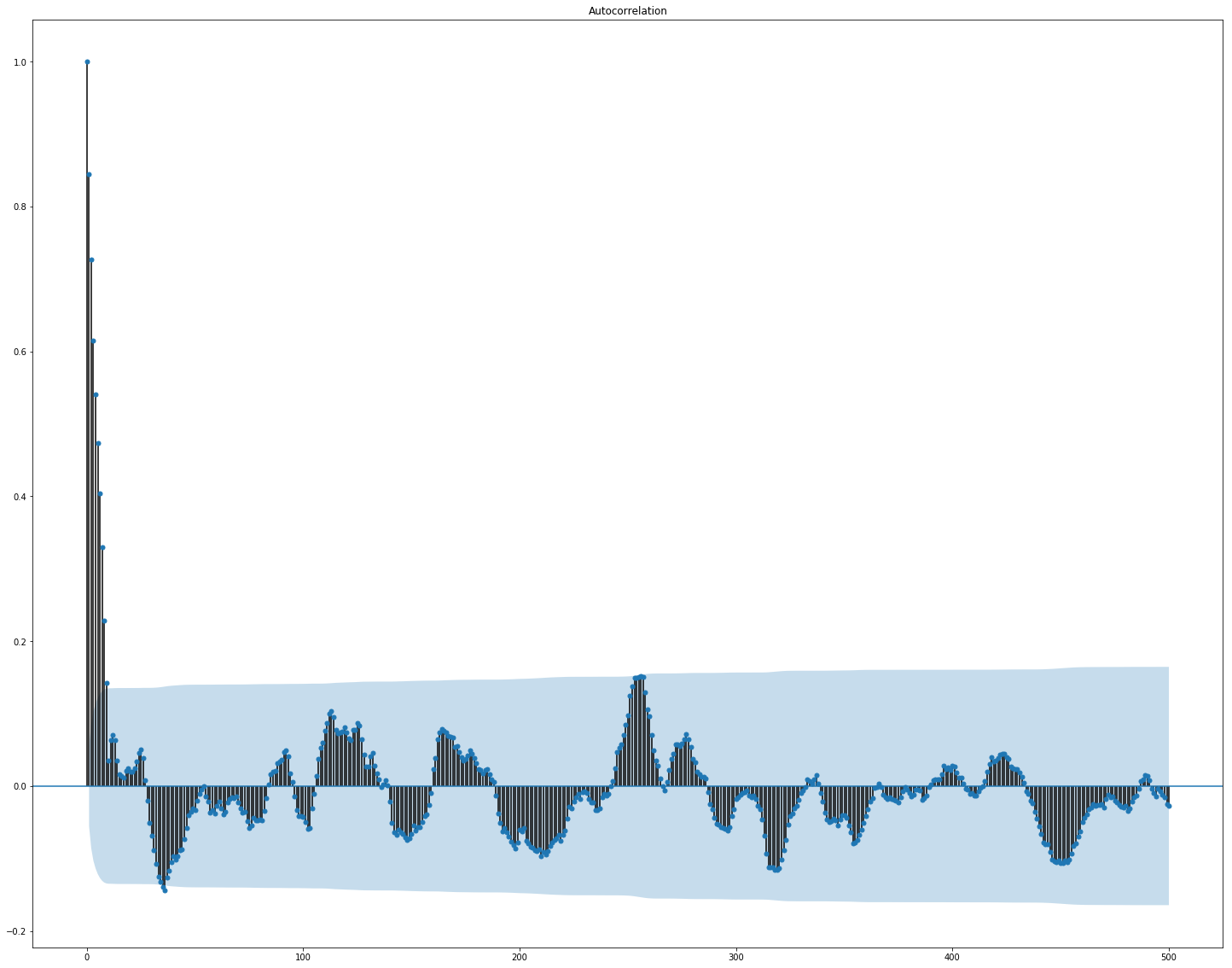
يمكن ملاحظة أنه بعد فترة 10 أيام ، ينخفض الاعتماد بشكل كبير. ربما هذا هو السبب الذي يجعل GBM يعمل بشكل جيد ، مع مراعاة الميزات فقط مع تأخير لمدة 10 أيام (الموجودة بالفعل في مجموعة البيانات الأصلية).
اختيار الميزة والمعالجة المسبقة أمر بالغ الأهمية لجميع خوارزميات ML. دعونا نحاول استخدام طرق تلقائية لاستخراج الميزات ، وهي
تحليل المكون الرئيسي (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
دعونا نرى ما هي الميزات التي يولدها PCA:

نرى أن الطريقة لا تعمل جيدًا على بياناتنا ، لأن الارتباط النهائي للميزات الجديدة بالقيمة المستهدفة صغير.
ضبط دقيق وما إذا كانت هناك حاجة لذلك
تحتوي العديد من طرز ML على عدد كبير جدًا من البارامترات ، أي "إعدادات" الخوارزمية نفسها. يمكن اختيارها يدويًا ، ولكن هناك أيضًا آليات اختيار تلقائية. بالنسبة إلى الأخير ، توجد مكتبة
hyperopt تقوم بتنفيذ خوارزميتين
متطابقتين - البحث العشوائي و
Parzen Estimator (TPE) منظم الشجرة . حاولت تحسين:
- معلمات lightgbm (نوع الخوارزمية ، عدد الأوراق ، معدل التعلم وغيرها) ،
- معلمات نماذج الشبكة العصبية (عدد فلاتر TCN ، عدد كتل الذاكرة GRU ، معدل التسرب ، معدل التعلم ، نوع حلال).
نتيجة لذلك ، أعطت جميع الحلول التي تم العثور عليها باستخدام هذا التحسين درجة أقل ، على الرغم من أنها عملت بشكل أفضل على بيانات الاختبار. على الأرجح ، يكمن السبب في حقيقة أن البيانات التي يتم اعتبار النتيجة لا تشبه إلى حد كبير بيانات التحقق من الصحة التي تم اختيارها من التدريب. وبالتالي ، لهذه المهمة ، فإن الضبط الدقيق غير مناسب للغاية ، لأنه يؤدي إلى إعادة تدريب النموذج.
القرار النهائي
وفقًا لقواعد المسابقة ، يمكن للمشاركين اختيار حلين للمرحلة النهائية. قراراتي النهائية هي نفسها تقريبا وتحتوي على مجموعة من نموذجين -
GBM و
GRU متعدد الطبقات. الفرق الوحيد هو أن أحد الحلول لا يستخدم بيانات الأخبار على الإطلاق ، والآخر يستخدمه ، ولكن فقط لنموذج الشبكة العصبية.
حل بيانات الأخبار:
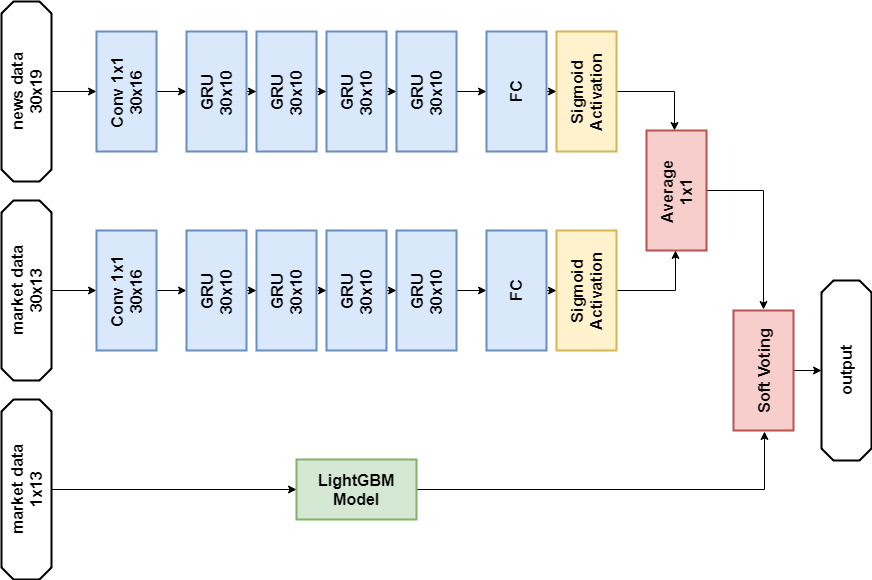
الواردات import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
نموذج الشبكة العصبية def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
نموذج GBM def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
التدريب n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
التنبؤ def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
الحل بدون بيانات الأخبار:

الكود (طريقة مختلفة فقط) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
أعطى كلا القرارين نتيجة مماثلة (حوالي 0.69) في المرحلة الأولى من المسابقة ، والتي تتوافق مع 566 من 2927 مكانًا ، وبعد الشهر الأول من البيانات الجديدة ، اختلطت المواقف في قائمة المشاركين بقوة ، والحل مع بيانات الأخبار كان في المرتبة 65 من بين 697 فريقًا المتبقية بنتيجة 3.19251 وما الذي سيحدث خلال الأشهر الخمسة المقبلة ، لا أحد يعلم.
ماذا حاولت
مقاييس مخصصة
نظرًا لأن القرارات يتم تقييمها باستخدام نسبة Sharpe ، فمن المنطقي محاولة استخدامها كمقياس لإنهاء التدريب مبكرًا.
متري ل lightgbm:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
أثبت التحقق أن مثل هذا المقياس يعمل بشكل أسوأ في هذه المشكلة من AUC.
آلية الاهتمام
تسمح
آلية الاهتمام للشبكة العصبية بالتركيز على الميزات "الأكثر أهمية" في البيانات المصدر. من الناحية الفنية ، يتم تمثيل الانتباه بواسطة ناقل للأوزان (يتم الحصول عليه غالبًا باستخدام طبقة متصلة بالكامل مع تنشيط
softmax ) ، والتي يتم ضربها بواسطة إخراج طبقة أخرى. لقد استخدمت تطبيقًا يتم فيه التركيز على محور الوقت:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
يبدو هذا النموذج جميلًا ، لكن هذا النهج لم يعطِ زيادة في النتيجة ، فقد أصبح حوالي 0.67.
ما لم يكن لديك الوقت للقيام به
العديد من المجالات التي تبدو واعدة:
الاستنتاجات
لقد انتهت مغامرتنا ، يمكنك محاولة تلخيصها. تبين أن المنافسة كانت صعبة ، لكننا لم نتمكن من مواجهة الأوساخ. يشير هذا إلى أن الحد الأدنى للدخول إلى ML ليس عاليًا جدًا ، ولكن كما هو الحال في أي عمل تجاري ، فإن السحر الحقيقي (وهناك الكثير منه في التعلم الآلي) متاح بالفعل للمحترفين.
النتائج بالأرقام:
- الدرجة القصوى في المرحلة الأولى: ~ 0.69 مقابل ~ 1.5 في المقام الأول. كان هناك ما يعادل المتوسط بالنسبة للمستشفى ، وتم التغلب على قيمة 0.7 من قبل عدد قليل ، وكانت النتيجة القصوى للقرار العام أيضا ~ 0.69 ، أكثر بقليل من نظيري.
- مكان في المرحلة الأولى: 566 من 2927.
- النتيجة في المرحلة الثانية: 3.19251 بعد الشهر الأول.
- مكان في المرحلة الثانية: 65 من 697 بعد الشهر الأول.
أود أن ألفت انتباهكم إلى حقيقة أن الأرقام في المرحلة الثانية لا تتحدث بشكل خاص عن أي شيء ، حيث لا تزال هناك بيانات قليلة جدًا لإجراء تقييم نوعي للقرارات.
المراجع
الحل النهائي باستخدام الأخبارسيغما: استخدام الأخبار للتنبؤ بحركات الأسهم - صفحة المسابقة
Keras -
إطار الشبكة العصبية
LightGBM - إطار GBM
Scikit - تعلم - مكتبة خوارزمية التعلم الآلي
Hyperopt - مكتبة لتحسين
المعايير الفوقيةمقال عن WaveNet