كلنا نعرف كيف يبدأ الوطن ، والتعلم العميق يبدأ بالبيانات. بدونها ، من المستحيل تدريب نموذج وتقييمه واستخدامه بالفعل. منخرطون في البحث ، وزيادة مؤشر هيرش بمقالات حول أبنية الشبكات العصبية الجديدة والتجربة ، نعتمد على أبسط مصادر البيانات المحلية ؛ عادة الملفات في أشكال مختلفة. إنه يعمل ، لكن سيكون من الجيد تذكر نظام قتالي يحتوي على تيرابايت من البيانات المتغيرة باستمرار. وهذا يعني أنك تحتاج إلى تبسيط وتسريع نقل البيانات في الإنتاج ، وكذلك تكون قادرًا على العمل مع البيانات الضخمة. هذا هو المكان الذي يأتي فيه اباتشي اشعال.
Apache Ignite هي قاعدة بيانات موزعة متمحورة حول الذاكرة ، بالإضافة إلى منصة للتخزين المؤقت ومعالجة العمليات المتعلقة بالمعاملات والتحليلات وتحميل الدفق. النظام قادر على طحن البيانات ذات البيجابايت بسرعة RAM. ستركز المقالة على التكامل بين Apache Ignite و TensorFlow ، والذي يسمح لك باستخدام Apache Ignite كمصدر للبيانات لتدريب الشبكة العصبية والاستدلال ، بالإضافة إلى مستودع للنماذج المدربة ونظام لإدارة الكتلة للتعلم الموزع.
مصدر بيانات ذاكرة الوصول العشوائي الموزعة
يتيح لك
Apache Ignite تخزين ومعالجة البيانات التي تحتاجها في مجموعة موزعة. للاستفادة من Apache Ignite عند تدريب الشبكات العصبية في TensorFlow ، استخدم
Ignite Dataset .
ملاحظة: لا يعد Apache Ignite أحد الروابط الموجودة في خط أنابيب ETL بين قاعدة بيانات أو مستودع بيانات و TensorFlow. Apache Ignite في حد ذاته هو
HTAP (نظام هجين لمعالجة بيانات المعاملات / التحليلية). عند اختيار Apache Ignite و TensorFlow ، فإنك تحصل على نظام واحد للمعالجة والتحليلات ، وفي الوقت نفسه ، القدرة على استخدام البيانات التشغيلية والتاريخية لتدريب الشبكة العصبية والاستدلال.
توضح المقاييس التالية أن Apache Ignite مناسب تمامًا للسيناريوهات حيث يتم تخزين البيانات على مضيف واحد. يتيح لك هذا النظام تحقيق إنتاجية تزيد عن 850 ميجابايت / ثانية ، إذا كان مستودع البيانات والعميل موجودين على العقدة نفسها. إذا كان التخزين موجودًا على مضيف بعيد ، فإن الإنتاجية تبلغ حوالي 800 ميجابايت / ثانية.
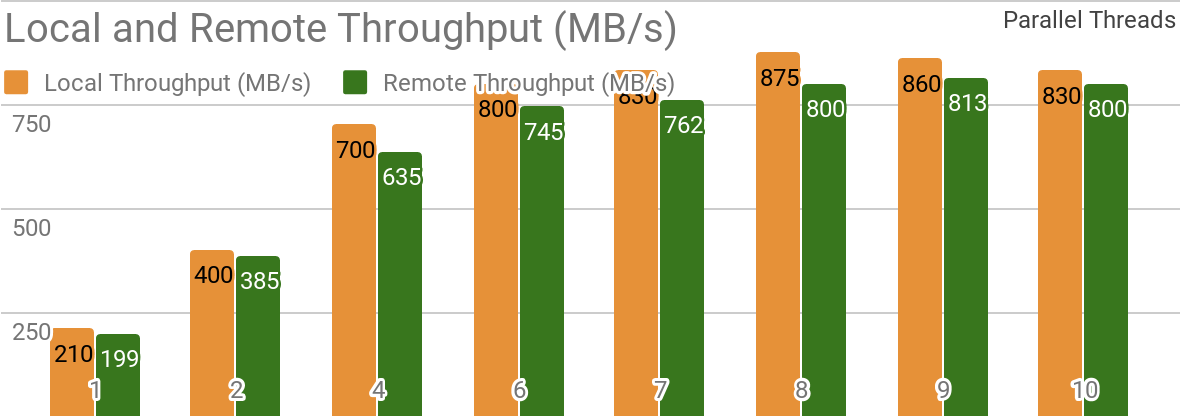
يوضح الرسم البياني النطاق الترددي لـ Ignite Dataset لعقدة Apache Ignite محلية واحدة. تم الحصول على هذه النتائج على معالج 2x Xeon E5-2609 v4 1.7 جيجا هرتز مع 16 جيجابايت من ذاكرة الوصول العشوائي وعلى شبكة ذات نطاق ترددي 10 جيجابايت / ثانية (كل سجل بحجم 1 ميجابايت ، حجم الصفحة - 20 ميجابايت).
يوضح معيار آخر كيف يعمل Ignite Dataset مع مجموعة Apache Ignite الموزعة. هذا هو التكوين الذي يتم تحديده افتراضيًا عند استخدام Apache Ignite كنظام HTAP ويسمح لك بتحقيق الإنتاجية لعميل واحد يزيد عن 1 غيغابايت / ثانية على مجموعة ذات نطاق ترددي 10 جيجابت / ثانية.
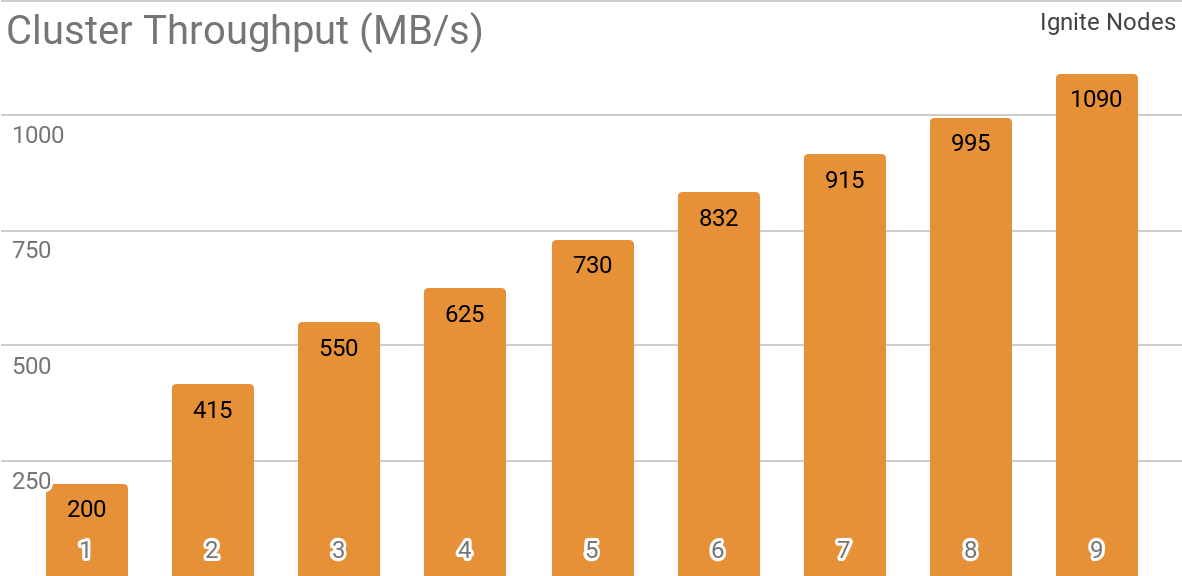
يوضح الرسم البياني صبيب Ignite Dataset لمجموعة Apache Ignite الموزعة مع عدد مختلف من العقد (من 1 إلى 9). تم الحصول على هذه النتائج على معالج 2x Xeon E5-2609 v4 1.7 جيجا هرتز مع 16 جيجابايت من ذاكرة الوصول العشوائي وعلى شبكة ذات نطاق ترددي 10 جيجابايت / ثانية (كل سجل بحجم 1 ميجابايت ، حجم الصفحة - 20 ميجابايت).
تم اختبار السيناريو التالي: يتم تعبئة ذاكرة التخزين المؤقت لـ Apache Ignite (مع عدد متغير من الأقسام في المجموعة الأولى من الاختبارات ومع 2048 قسمًا في الثانية) بسطر 10K بسعة 1 ميغابايت لكل منهما ، وبعد ذلك يقوم عميل TensorFlow بقراءة البيانات باستخدام Ignite Dataset. تم بناء المجموعة من أجهزة مزودة بذاكرة Xeon E5-2609 v4 سعة 1.7 جيجا هرتز وذاكرة 16 جيجا بايت ومتصلة عبر شبكة تعمل بسرعة 10 جيجابايت / ثانية. على كل عقدة ، عملت Apache Ignite في
التكوين القياسي .
Apache Ignite سهل الاستخدام كقاعدة بيانات كلاسيكية مع واجهة SQL وفي نفس الوقت كمصدر بيانات لـ TensorFlow.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
كائنات مهيكلة
يتيح لك Apache Ignite تخزين الأشياء من أي نوع والتي يمكن إنشاؤها في أي تسلسل هرمي. يمكنك العمل معها من خلال Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
يتطلب التدريب على الشبكة العصبية والحسابات الأخرى معالجة مسبقة ، والتي يمكن إجراؤها كجزء من خط أنابيب
tf.data إذا كنت تستخدم Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
التدريب الموزع
TensorFlow هو إطار تعلم آلي
يدعم تعلم الشبكة العصبية الموزعة والاستدلال والحوسبة الأخرى. كما تعلم ، يعتمد تدريب الشبكة العصبية على حساب تدرجات دالة الخسارة. في حالة التدريب الموزع ، يمكننا حساب هذه التدرجات على كل قسم ، ثم تجميعها. هذه هي الطريقة التي تسمح لك بحساب التدرجات للعقد الفردية التي يتم تخزين البيانات عليها وتلخيصها ، وأخيرا تحديث معلمات النموذج. وبما أننا تخلصنا من نقل بيانات نموذج التدريب بين العقد ، فإن الشبكة لا تصبح "عنق الزجاجة" للنظام.
يستخدم Apache Ignite التقسيم الأفقي (المشاركة) لتخزين البيانات في كتلة موزعة. من خلال إنشاء ذاكرة التخزين المؤقت لـ Apache Ignite (أو جدول ، من حيث SQL) ، يمكنك تحديد عدد الأقسام التي سيتم توزيع البيانات بينها. على سبيل المثال ، إذا كانت مجموعة Apache Ignite تتكون من 100 جهاز ، وقمنا بإنشاء ذاكرة تخزين مؤقت تحتوي على 1000 قسم ، فسيكون كل جهاز مسؤولاً عن حوالي 10 أقسام مع البيانات.
يتيح لك Ignite Dataset استخدام هذين الجانبين لتدريب موزع على الشبكات العصبية. Ignite Dataset هي عقدة
الرسم البياني الحسابي التي تشكل أساس بنية TensorFlow. ومثل أي عقدة في الرسم البياني ، يمكن تشغيله على عقدة بعيدة في الكتلة. تستطيع العقدة البعيدة هذه تجاوز معلمات Ignite Dataset (على سبيل المثال ،
host أو
port أو
part ) ، وتعيين متغيرات البيئة المناسبة لسير العمل (على سبيل المثال ،
IGNITE_DATASET_PORT أو
IGNITE_DATASET_PART أو
IGNITE_DATASET_PART ). باستخدام مثل هذا التجاوز ، يمكنك تعيين قسم محدد لكل عقدة نظام المجموعة. ثم تكون العقدة الواحدة مسؤولة عن قسم واحد وفي نفس الوقت يتلقى المستخدم واجهة واحدة من العمل مع مجموعة البيانات.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
يتيح Apache Ignite أيضًا التعلم الموزع باستخدام مكتبة
API مقدرة عالية المستوى في TensorFlow. تستند هذه الوظيفة إلى ما يسمى
وضع العميل المستقل للتعلم الموزع في TensorFlow ، حيث يعمل Apache Ignite كمصدر بيانات ونظام لإدارة نظام المجموعة. سيتم تخصيص المقال التالي بالكامل لهذا الموضوع.
تعلم نقطة التحكم التخزين
بالإضافة إلى إمكانيات قاعدة البيانات ، يحتوي Apache Ignite أيضًا على نظام ملفات
IGFS موزع. من الناحية الوظيفية ، يشبه نظام الملفات Hadoop HDFS ، ولكن فقط في ذاكرة الوصول العشوائي. إلى جانب واجهات برمجة التطبيقات الخاصة به ، يطبق نظام ملفات IGFS واجهة برمجة تطبيقات Hadoop FileSystem ويمكنه الاتصال بشفافية بـ Hadoop أو Spark. توفر مكتبة TensorFlow على Apache Ignite التكامل بين IGFS و TensorFlow. يعتمد التكامل على TensorFlow المساعد
لنظام الملفات و Apache Ignite
IGFS API الأصلي . هناك سيناريوهات مختلفة لاستخدامها ، على سبيل المثال:
- يتم تخزين نقاط تفتيش الحالة في IGFS من أجل الموثوقية والتسامح مع الخطأ.
- تتفاعل عمليات التعلم مع TensorBoard عن طريق كتابة ملفات الأحداث إلى دليل تراقبه TensorBoard. يضمن IGFS تشغيل مثل هذه الاتصالات حتى عند تشغيل TensorBoard في عملية أخرى أو على جهاز آخر.
ظهرت هذه الوظيفة في إصدار TensorFlow 1.13.0.rc0 ، وستكون أيضًا جزءًا من
tensorflow / io في إصدار TensorFlow 2.0.
اتصال SSL
يتيح لك Apache Ignite تأمين قنوات البيانات باستخدام
SSL والمصادقة. يدعم Ignite Dataset اتصالات SSL مع وبدون مصادقة. راجع وثائق
Apache Ignite SSL / TLS لمزيد من التفاصيل.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
دعم ويندوز
Ignite Dataset متوافق تمامًا مع Windows. يمكن استخدامه كجزء من TensorFlow على محطة عمل Windows ، وكذلك على أنظمة Linux / MacOS.
جربه بنفسك
ستساعدك الأمثلة أدناه على البدء في استخدام الوحدة.
إشعال مجموعة البيانات
أسهل طريقة للبدء في Ignite Dataset هي بدء تشغيل حاوية
Docker باستخدام Apache Ignite وتنزيل بيانات
MNIST ، ثم العمل معها باستخدام Ignite Dataset. تتوفر مثل هذه الحاوية في Docker Hub:
dmitrievanthony / ignet-with-mnist . تحتاج إلى تشغيل الحاوية على جهازك:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
بعد ذلك ، يمكنك العمل معها على النحو التالي:
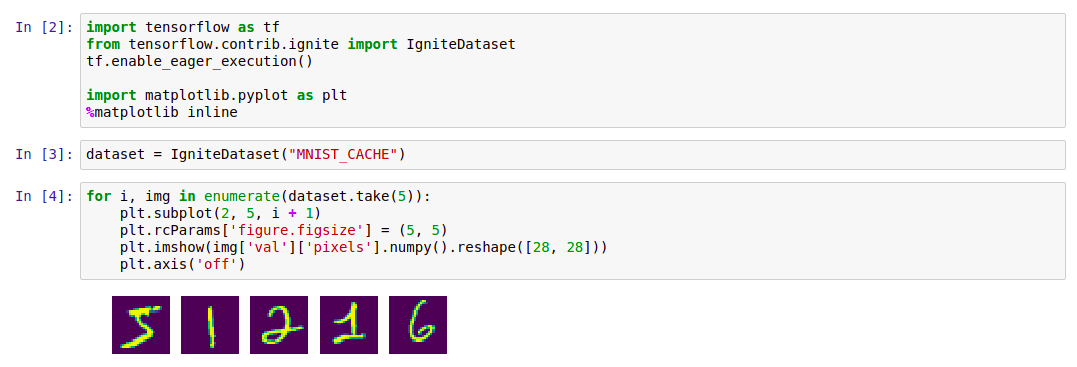
كود import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
ظهر دعم TensorFlow IGFS في إصدار TensorFlow 1.13.0rc0 وسيكون أيضًا جزءًا من إصدار
tensorflow / io في TensorFlow 2.0. لتجربة IGFS مع TensorFlow ، أسهل طريقة لبدء تشغيل حاوية
Docker هي Apache Ignite + IGFS ، ثم العمل معها باستخدام TensorFlow
tf.gfile . تتوفر هذه الحاوية في Docker Hub:
dmitrievanthony / ignit-with-igfs . يمكن تشغيل هذه الحاوية على جهازك:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
ثم يمكنك العمل معها مثل هذا:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
القيود
حاليًا ، عند العمل مع Ignite Dataset ، من المفترض أن جميع الكائنات الموجودة في ذاكرة التخزين المؤقت لها نفس البنية (كائنات متجانسة) ، وأن ذاكرة التخزين المؤقت تحتوي على كائن واحد على الأقل مطلوب لاسترداد المخطط. يتعلق القيد الآخر بالكائنات المهيكلة: Ignite Dataset لا يدعم UUIDs ، والخرائط ، ومصفوفات الكائن ، والتي يمكن أن تكون جزءًا من كائن. تعد إزالة هذه القيود ، وكذلك تثبيت وتزامن إصدارات TensorFlow و Apache Ignite ، واحدة من مهام التطوير المستمر.
من المتوقع TensorFlow 2.0 الإصدار
سوف تبرز التغييرات القادمة في TensorFlow 2.0 هذه الميزات في وحدة
tensorflow / io . بعد ذلك ، يمكن بناء العمل معهم بشكل أكثر مرونة. سوف تتغير الأمثلة قليلاً ، وسوف ينعكس هذا في gihab وفي الوثائق.