بفضل التحليل في الوقت الفعلي ، نحن ، موظفون في Uber ، لدينا فكرة عن الحالة وكفاءة العمل ، واستناداً إلى البيانات التي نقرر كيفية تحسين جودة العمل على منصة Uber. على سبيل المثال ، يراقب فريق المشروع حالة السوق ويحدد المشاكل المحتملة على نظامنا الأساسي ؛ تتنبأ البرامج المستندة إلى نماذج التعلم الآلي بعروض الركاب والطلب على السائقين ؛ يعمل اختصاصيو معالجة البيانات على تحسين نماذج التعلم الآلي - بدوره ، لتحسين جودة التنبؤ.

في الماضي ، من أجل التحليل في الوقت الفعلي ، استخدمنا حلول قواعد البيانات من شركات أخرى ، لكن لم يستوف أي منها جميع معاييرنا المتعلقة بالوظائف والقابلية للتطوير والكفاءة والتكلفة والمتطلبات التشغيلية.
تم إصدار AresDB في نوفمبر 2018 ، وهو أداة تحليل في الوقت الحقيقي مفتوحة المصدر. يستخدم مصدر طاقة غير تقليدي ، معالجات رسومية (GPU) ، مما يسمح لك بزيادة حجم التحليل. تقدمت تقنية GPU ، وهي أداة تحليل واعدة في الوقت الحقيقي ، بشكل ملحوظ في السنوات الأخيرة ، مما يجعلها مثالية للحوسبة المتوازية ومعالجة البيانات في الوقت الحقيقي.
في الأقسام التالية ، وصفنا بنية AresDB وكيف سمح لنا هذا الحل المثير للتحليل في الوقت الفعلي بتوحيد حلول قاعدة بيانات Uber وتبسيطها وتحسينها على نحو أكثر فعالية وعقلانية لتحليلها في الوقت الفعلي. نأمل بعد تجربة قراءة هذا المقال أن تجرب AresDB كجزء من مشاريعك الخاصة وتأكد أيضًا من فائدته!
تطبيقات التحليل اوبر في الوقت الحقيقي
تحليل البيانات أمر حاسم لنجاح اوبر. من بين وظائف أخرى ، يتم استخدام الأدوات التحليلية لحل المهام التالية:
- بناء لوحات المعلومات لرصد مقاييس العمل.
- اتخاذ قرارات تلقائية (على سبيل المثال ، تحديد تكلفة الرحلة وتحديد حالات الاحتيال ) بناءً على مقاييس الملخص المجمّعة.
- قم بإنشاء استعلامات عشوائية لتشخيص العمليات التجارية واستكشافها وإصلاحها.
نقوم بتصنيف هذه الوظائف بمتطلبات مختلفة على النحو التالي:

تستخدم لوحات المعلومات وأنظمة صنع القرار أنظمة التحليل في الوقت الفعلي لإنشاء استفسارات مماثلة على مجموعات فرعية صغيرة نسبياً ولكنها مهمة للغاية (مع أعلى مستوى من ملاءمة البيانات) مع QPS عالية ووقت استجابة منخفض.
تحتاج إلى وحدة تحليلية أخرى
المشكلة الأكثر شيوعًا التي يستخدمها Uber أدوات تحليل في الوقت الفعلي لحلها هي حساب مجموعات السلاسل الزمنية. تعطي هذه الحسابات فكرة عن تفاعلات المستخدم حتى نتمكن من تحسين جودة الخدمات وفقًا لذلك. بناءً عليها ، نطلب مؤشرات لمعلمات معينة (على سبيل المثال ، اليوم والساعة ومعرف المدينة وحالة الرحلة) لفترة معينة من الوقت لبيانات تمت تصفيتها عشوائيًا (أو مجتمعة في بعض الأحيان). على مر السنين ، نشر Uber العديد من الأنظمة المصممة لحل هذه المشكلة بطرق مختلفة.
فيما يلي بعض حلول الجهات الخارجية التي استخدمناها لحل هذا النوع من المشكلات:
- يعد Apache Pinot ، وهي قاعدة بيانات تحليلية مفتوحة المصدر موزعة بلغة Java ، مناسبة لتحليل البيانات على نطاق واسع. يستخدم Pinot بنية lambda داخلية للاستعلام عن بيانات الحزم وبيانات الوقت الفعلي في تخزين الأعمدة ، وفهرس بت مقلوب للتصفية ، وشجرة نجمة لتخزين النتائج الإجمالية. ومع ذلك ، فهو لا يدعم ميزة إلغاء البيانات المكررة على أساس المفتاح أو تحديثها أو إدراجها أو دمجها أو دمجها في ميزات الاستعلام المتقدمة مثل التصفية الجغرافية المكانية. بالإضافة إلى ذلك ، نظرًا لأن Pinot عبارة عن قاعدة بيانات تستند إلى JVM ، فإن الاستعلام مكلف للغاية من حيث استخدام الذاكرة.
- يتم استخدام Elasticsearch بواسطة Uber لحل مختلف مهام تحليل التدفق. إنها مبنية على أساس مكتبة Apache Lucene ، التي تخزن المستندات ، للبحث عن النص الكامل للكلمات الرئيسية وفهرس مقلوب. النظام واسع الانتشار وموسع لدعم البيانات الإجمالية. يوفر الفهرس المقلوب التصفية ولكنه غير مُحسن لتخزين البيانات وتصفيتها استنادًا إلى النطاقات الزمنية. يتم تخزين السجلات في شكل مستندات JSON ، مما يفرض تكاليف إضافية لتوفير الوصول إلى المستودع والطلبات. مثل Pinot ، Elasticsearch هي قاعدة بيانات تعتمد على JVM ، وبالتالي ، لا تدعم وظيفة الصلة ، ويشغل تنفيذ الاستعلام كمية كبيرة من الذاكرة.
على الرغم من أن هذه التقنيات لها نقاط قوتها ، إلا أنها تفتقر إلى بعض الميزات اللازمة لحالة الاستخدام الخاصة بنا. كنا بحاجة إلى حل موحد ومبسط ومُحسّن ، وفي بحثنا ، عملنا في اتجاه غير قياسي (بشكل أكثر دقة ، داخل وحدة معالجة الرسومات).
باستخدام GPU لتحليل في الوقت الحقيقي
من أجل تقديم صور واقعية بمعدل إطارات مرتفع ، تقوم وحدات معالجة الرسومات في وقت واحد بمعالجة عدد كبير من الأشكال والبكسل بسرعة عالية. على الرغم من أن الميل إلى زيادة وتيرة الساعة لوحدات معالجة البيانات على مدى السنوات القليلة الماضية قد بدأ في الانخفاض ، إلا أن عدد الترانزستورات في الشريحة زاد فقط وفقًا لقانون مور . كنتيجة لذلك ، تزداد بسرعة سرعة حوسبة GPU ، المقاسة بالجيigافلوبات في الثانية (Gflops / s). يوضح الشكل 1 أدناه مقارنة لاتجاه السرعة النظرية (Gflops / s) لوحدة معالجة الرسومات NVIDIA GPU و Intel CPU على مر السنين:
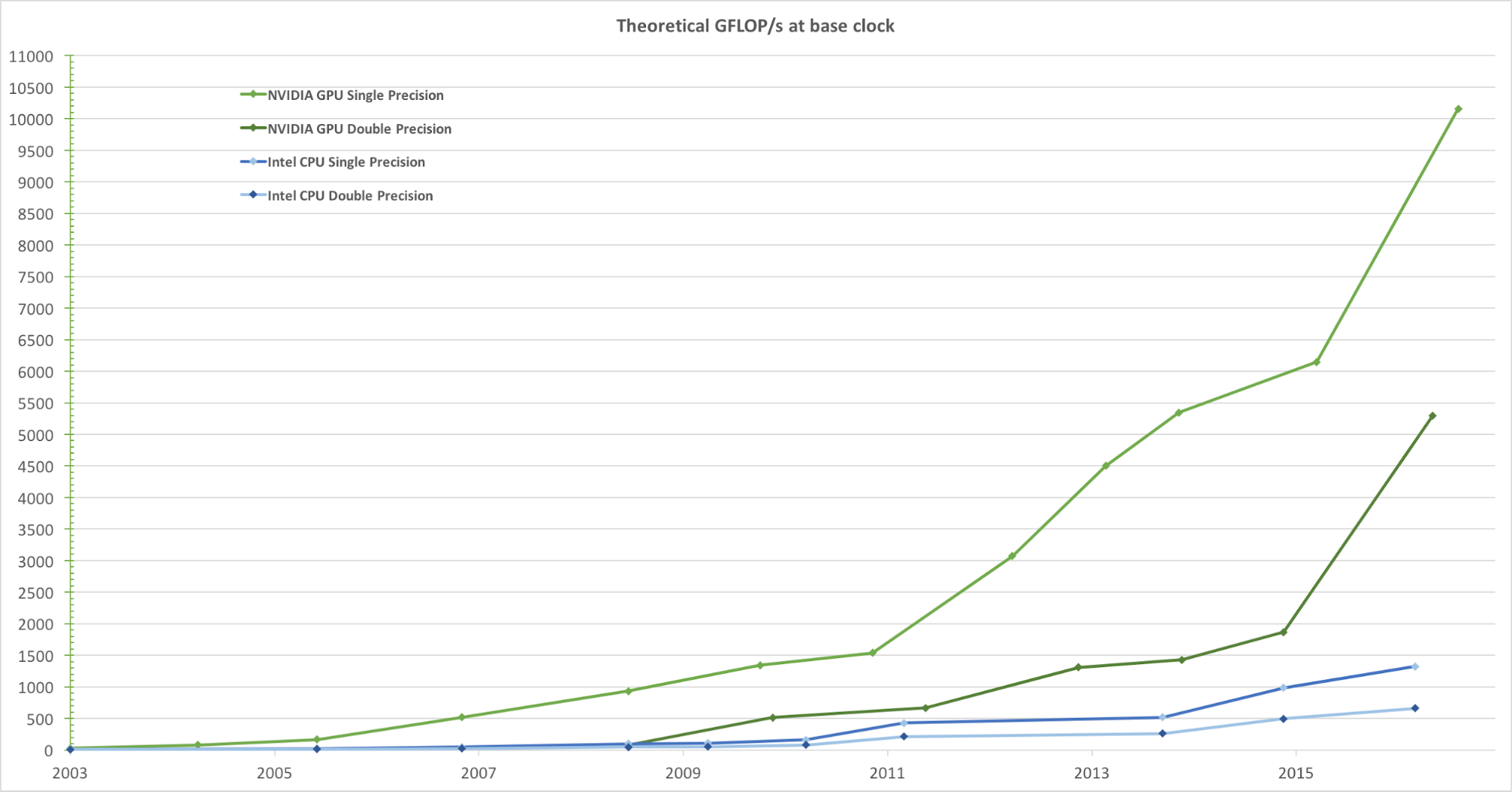
الشكل 1. مقارنة أحادية النقطة العائمة وحدة المعالجة المركزية وأداء GPU على مدى عدة سنوات. الصورة مأخوذة من دليل البرمجة CUDA C من Nvidia.
في تطوير آلية طلب التحليل في الوقت الفعلي ، كان قرار دمج GPU أمرًا طبيعيًا. في Uber ، يتطلب طلب التحليل في الوقت الحقيقي النموذجي معالجة البيانات في غضون أيام قليلة مع الملايين أو حتى مليارات السجلات ، ثم تصفيتها وتلخيصها في فترة زمنية قصيرة. تتناسب هذه المهمة الحسابية تمامًا مع نموذج المعالجة المتوازية GPU للأغراض العامة ، لأنها:
- يعالجون البيانات بالتوازي مع سرعة عالية جدا.
- أنها توفر سرعة حسابية أعلى (Gflops / s) ، مما يجعلها ممتازة لأداء المهام الحسابية المعقدة (في كتل البيانات) التي يمكن موازتها.
- أنها توفر أداء أعلى (دون تأخير) في تبادل البيانات بين وحدة الحوسبة والتخزين (ALU والذاكرة GPU) مقارنة بوحدات المعالجة المركزية (CPU) ، مما يجعلها مثالية لمعالجة مهام I / O الذاكرة المتوازية ، والتي يتطلب كمية كبيرة من البيانات.
من خلال التركيز على استخدام قاعدة بيانات تحليلية قائمة على GPU ، قمنا - من وجهة نظر احتياجاتنا - بتقييم العديد من الحلول التحليلية الحالية التي تستخدم وحدات معالجة الرسومات:
- ضربت Kinetica ، وهي أداة تحليلية قائمة على GPU ، السوق في عام 2009 ، للاستخدام في البداية في الجيش الأمريكي ووكالات الاستخبارات. على الرغم من أنه يوضح الإمكانات العالية لتكنولوجيا GPU في التحليلات ، فقد وجدنا أنه بالنسبة لظروف الاستخدام لدينا ، هناك العديد من الوظائف الرئيسية مفقودة ، بما في ذلك تغيير المخطط والإدراج الجزئي أو التحديث وضغط البيانات وتكوين القرص والذاكرة على مستوى العمود والاتصال بواسطة العلاقات الجغرافية المكانية.
- بدت OmniSci ، وهي وحدة استعلام SQL مفتوحة المصدر ، كخيار واعد ، ولكن عند تقييم المنتج ، أدركنا أنه يفتقر إلى بعض الميزات المهمة للاستخدام في Uber ، مثل إلغاء البيانات المكررة. على الرغم من أن OminiSci قدمت شفرة المصدر المفتوح لمشروعها في عام 2017 ، بعد تحليل حلها على أساس C ++ ، توصلنا إلى استنتاج مفاده أنه لا يمكن تغيير قاعدة الشفرة الخاصة بهم أو تشعبها عمليًا.
- غالبًا ما تستخدم أدوات التحليل في الوقت الفعلي القائمة على GPU ، بما في ذلك GPUQP و CoGaDB و GPUDB و Ocelot و OmniDB و Virginian ، في المؤسسات البحثية والتعليمية. ومع ذلك ، نظرًا لأهدافهم الأكاديمية ، تركز هذه القرارات على تطوير الخوارزميات واختبار المفاهيم ، بدلاً من حل مشاكل العالم الحقيقي. لهذا السبب ، لم نأخذها في الاعتبار - في ظروف حجمنا وحجمنا.
بشكل عام ، تُظهر هذه الأنظمة الميزة والإمكانات الهائلة لمعالجة البيانات باستخدام تقنية GPU ، وقد ألهمتنا لإنشاء حل التحليل في الوقت الحقيقي الخاص بنا استنادًا إلى GPU ، المتكيفة مع احتياجات Uber. بناءً على هذه المفاهيم ، قمنا بتطوير وفتح الكود المصدري لـ AresDB.
AresDB العمارة نظرة عامة
على مستوى عالٍ ، يخزن AresDB معظم البيانات الموجودة في الذاكرة المضيفة (RAM ، المتصلة بوحدة المعالجة المركزية) ، ويستخدم وحدة المعالجة المركزية لمعالجة البيانات المستلمة والأقراص لاستعادة البيانات. أثناء فترة الطلب ، ينقل AresDB البيانات من الذاكرة المضيفة إلى ذاكرة GPU للمعالجة المتوازية في GPU. كما هو مبين في الشكل 2 أدناه ، يتضمن AresDB تخزين الذاكرة وتخزين البيانات الوصفية والقرص:

الشكل 2. تتضمن البنية الفريدة لـ AresDB تخزين الذاكرة والقرص وتخزين البيانات الوصفية.
الجداول
بخلاف معظم أنظمة إدارة قواعد البيانات العلائقية (RDBMS) ، لا يحتوي AresDB على قاعدة بيانات أو نطاق مخطط. تنتمي جميع الجداول إلى نفس النطاق في مجموعة / مثيل واحد من AresDB ، مما يسمح للمستخدمين بالوصول إليها مباشرة. يقوم المستخدمون بتخزين بياناتهم في شكل جداول حقائق وجداول بُعد.
جدول الحقائق
جدول الحقائق بتخزين دفق لانهائي من أحداث السلاسل الزمنية. يستخدم المستخدمون جدول حقائق لتخزين الأحداث / الوقائع التي تحدث في الوقت الحقيقي ، ويرتبط كل حدث بوقت الحدث ، وغالبًا ما يتم الاستعلام عن الجدول بحلول وقت الحدث. كمثال لنوع المعلومات المخزنة في جدول الحقائق ، يمكننا تسمية الرحلات ، حيث تكون كل رحلة حدثًا ، وغالبًا ما يشار إلى وقت طلب الرحلة على أنه وقت الحدث. إذا كانت هناك عدة طوابع زمنية مرتبطة بحدث ما ، فسيتم الإشارة إلى طابع زمني واحد فقط كوقت للحدث ويتم عرضه في جدول الحقائق.
جدول القياس
يخزن جدول القياس الخصائص الحالية للمنشآت (بما في ذلك المدن والعملاء والسائقين). على سبيل المثال ، يمكن للمستخدمين تخزين معلومات حول المدينة ، ولا سيما اسم المدينة والمنطقة الزمنية والبلد ، في جدول القياس. على عكس جداول الحقائق ، التي تنمو باستمرار ، فإن جداول الأبعاد محدودة دائمًا في الحجم (على سبيل المثال ، بالنسبة لـ Uber ، فإن جدول المدينة محدد بالعدد الفعلي للمدن في العالم). لا تتطلب جداول القياس عمود وقت خاص.
أنواع البيانات
يوضح الجدول أدناه أنواع البيانات الحالية التي يدعمها AresDB:
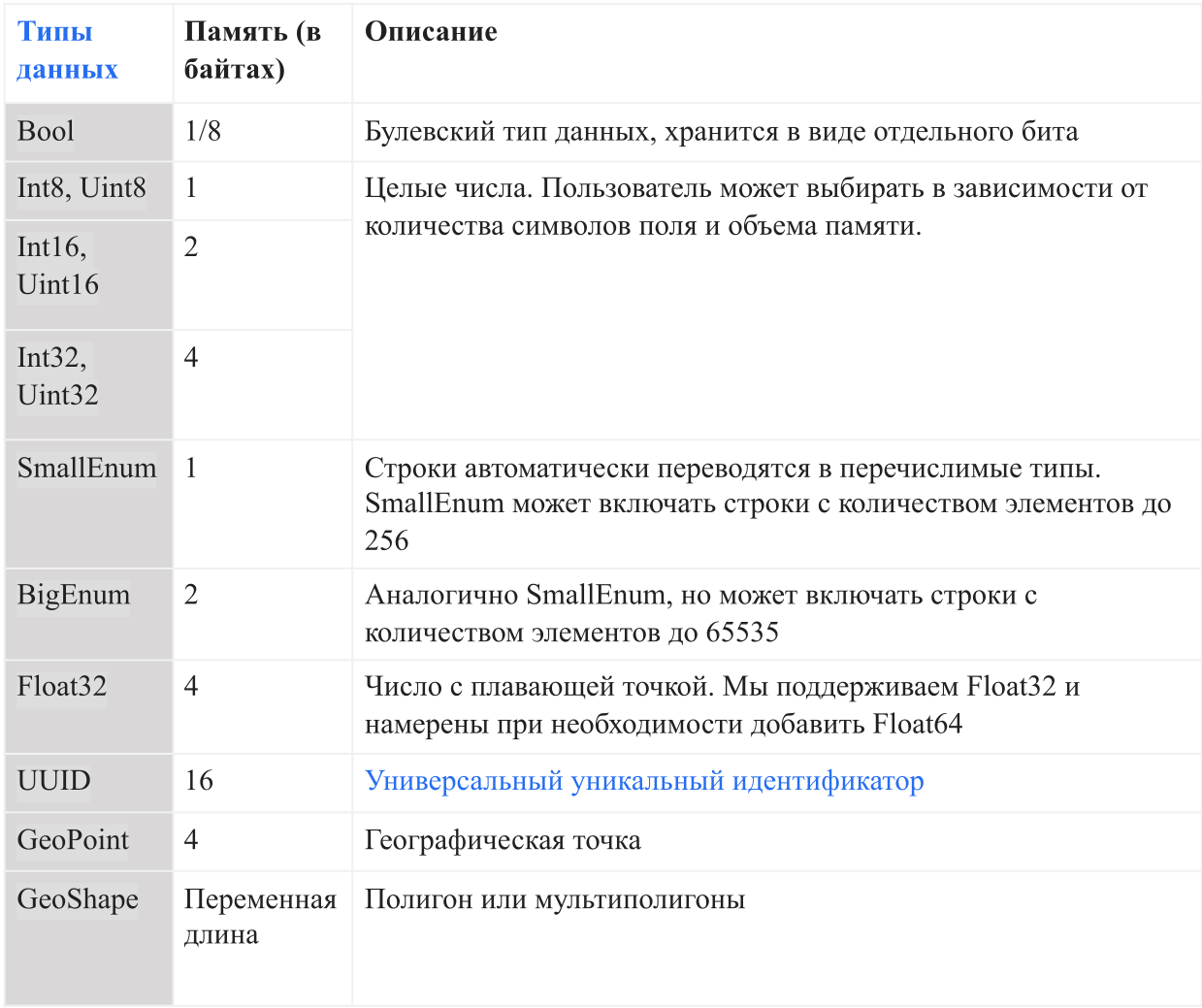
في AresDB ، يتم تحويل السلاسل إلى التعدادات تلقائيًا قبل إدخال قاعدة البيانات لزيادة راحة التخزين وكفاءة الاستعلام. يسمح هذا بالتحقق من المساواة الحساسة لحالة الأحرف ، ولكنه لا يدعم العمليات المتقدمة مثل التسلسل ، و substrings ، والأقنعة ، ومطابقة التعبير العادية. في المستقبل ، نعتزم إضافة خيار الدعم الكامل.
وظائف رئيسية
تدعم بنية AresDB الميزات التالية:
- تخزين قائم على الأعمدة مع ضغط لزيادة كفاءة التخزين (ذاكرة أقل بالبايت لتخزين البيانات) وكفاءة الاستعلام (تقليل تبادل البيانات بين ذاكرة وحدة المعالجة المركزية وذاكرة وحدة معالجة الرسومات عند معالجة الطلب)
- تحديث في الوقت الحقيقي أو إدراج مع إلغاء البيانات المكررة الأساسية لتحسين دقة البيانات وتحديث البيانات في الوقت الحقيقي في بضع ثوان
- معالجة طلب GPU لمعالجة بيانات GPU المتوازية للغاية مع زمن استجابة منخفض (من كسور من ثانية إلى عدة ثوان)
تخزين العمود
المتجهات
AresDB يخزن جميع البيانات في تنسيق العمود. يتم تخزين قيم كل عمود كمتجه قيمة العمود. يتم تخزين علامة الثقة / عدم اليقين الخاصة بالقيم في كل عمود في متجه صفري منفصل ، بينما يتم تقديم علامة الثقة لكل قيمة على هيئة بت واحد.
تخزين نشط
يخزن AresDB بيانات العمود غير المضغوطة وغير المصنفة (الموجهات النشطة) في التخزين النشط. يتم تقسيم سجلات البيانات في التخزين النشط إلى حزم (نشطة) من وحدة تخزين معينة. يتم إنشاء حزم جديدة عند تلقي البيانات ، بينما يتم حذف الحزم القديمة بعد أرشفة السجلات. يتم استخدام فهرس المفتاح الأساسي لتحديد موقع إلغاء البيانات المكررة وتحديث السجلات. يوضح الشكل 3 أدناه كيفية تنظيم السجلات النشطة واستخدام قيمة المفتاح الأساسي لتحديد موقعها:
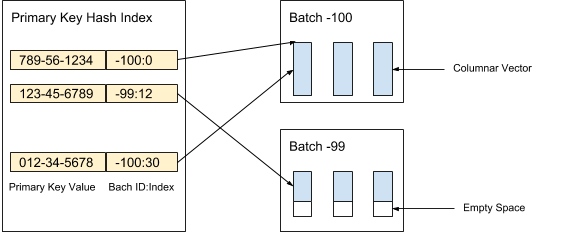
الشكل 3. نستخدم قيمة المفتاح الأساسي لتحديد موقع الحزمة وموضع كل سجل داخل الحزمة.
يتم تخزين قيم كل عمود في الحزمة كمتجه عمود. يتم تخزين علامة الموثوقية / عدم اليقين للقيم في كل متجه للقيمة كمتجه صفري منفصل ، ويتم تقديم علامة الموثوقية لكل قيمة بت واحد. في الشكل 4 أدناه ، نقدم مثالًا يحتوي على خمس قيم لعمود city_id :
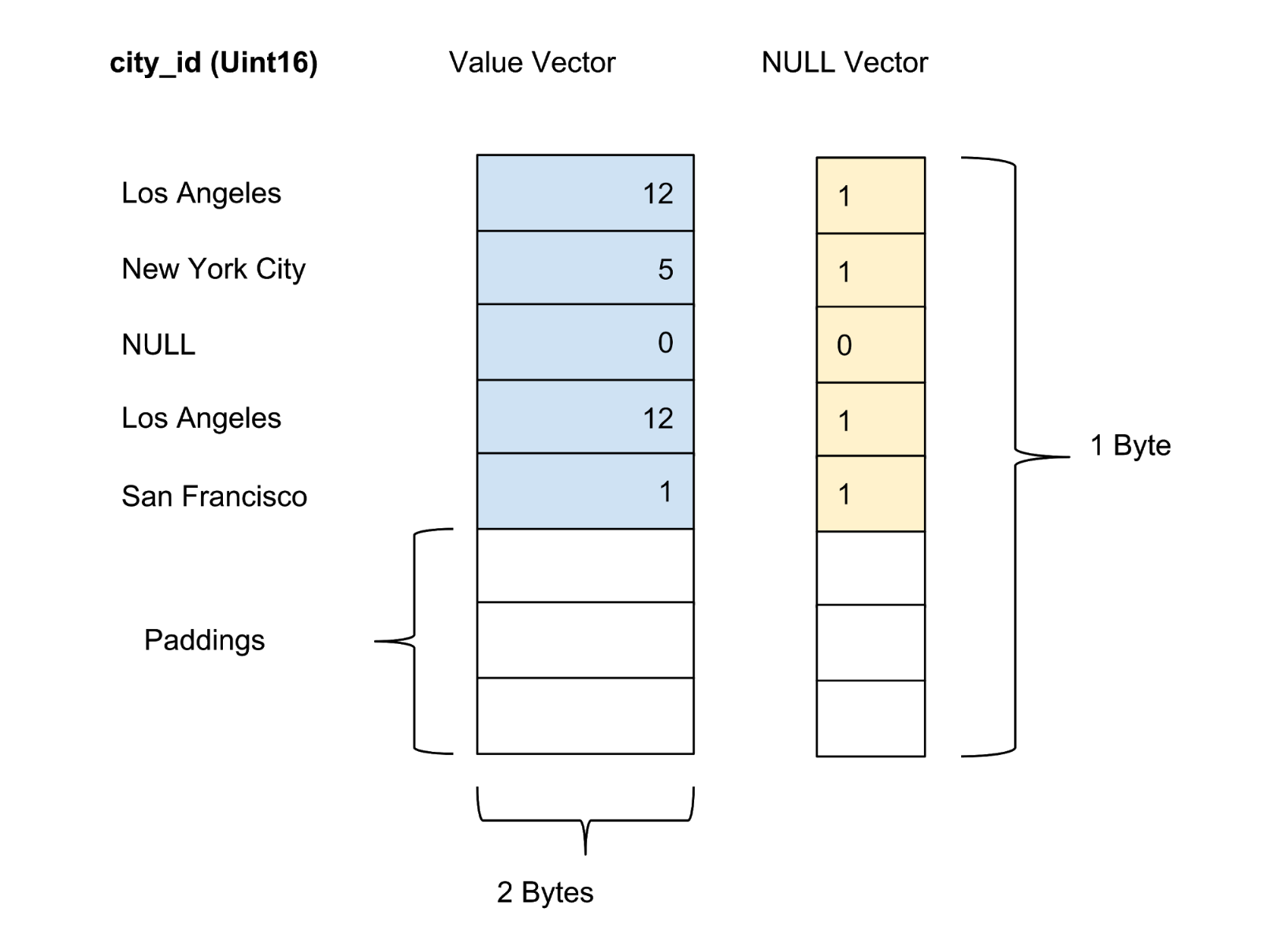
الشكل 4. نقوم بتخزين القيم (القيمة الفعلية) وناقلات الصفر (علامة الثقة) للأعمدة غير المضغوطة في جدول البيانات.
تخزين الأرشيف
يقوم AresDB أيضًا بتخزين بيانات الأعمدة المكتملة والفرز والمضغوطة (متجهات الأرشيف) في تخزين الأرشيف من خلال جداول الحقائق. يتم توزيع السجلات في تخزين الأرشيف أيضًا على دفعات. بخلاف الحزم النشطة ، تخزن حزمة الأرشيف السجلات يوميًا وفقًا للتوقيت العالمي المتفق عليه (UTC). تستخدم حزمة الأرشيف عدد الأيام كمعرّف الحزمة منذ Unix Epoch.
يتم تخزين السجلات في شكل مفروزة وفقًا لترتيب فرز الأعمدة المعرفة من قبل المستخدم. كما هو مبين في الشكل 5 أدناه ، نقوم بالفرز أولاً حسب عمود city_id ، ثم حسب عمود الحالة:
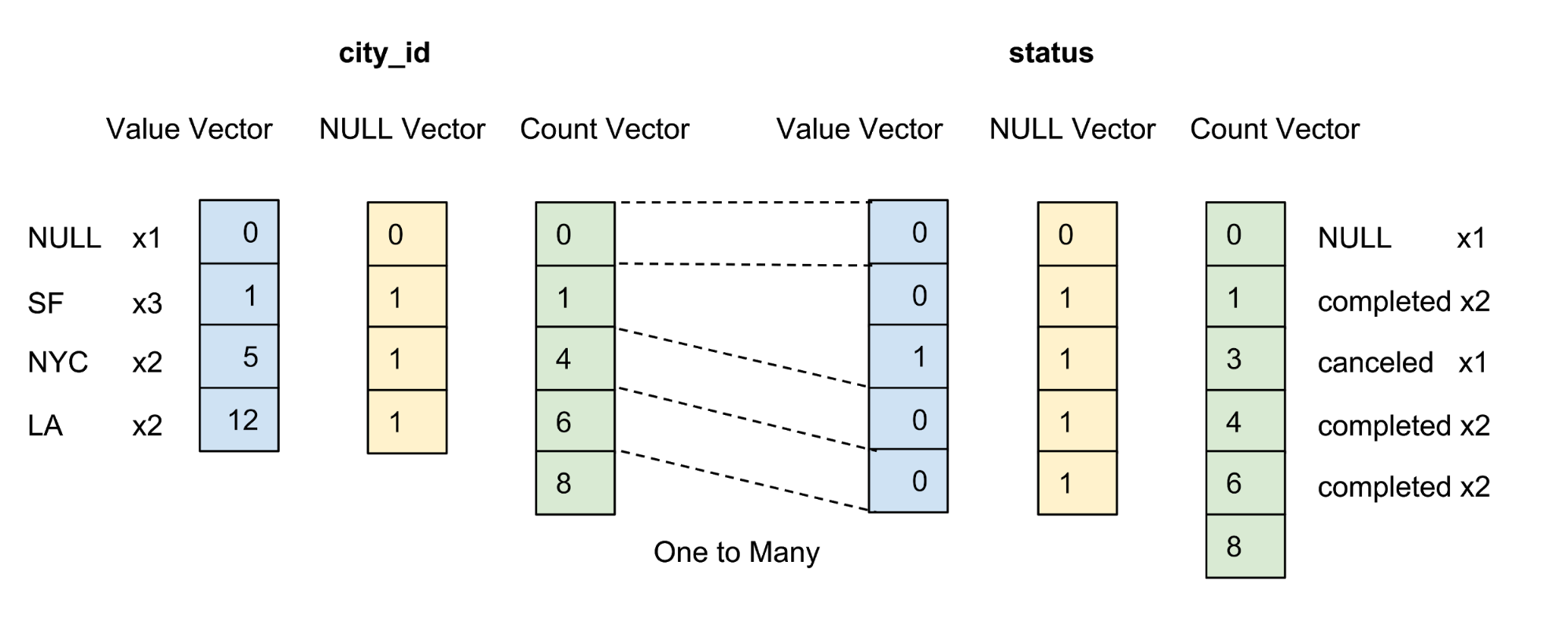
الشكل 5. نقوم بتصنيف جميع الصفوف حسب city_id ، ثم حسب الولاية ، ثم نضغط كل عمود حسب ترميز المجموعة. بعد الفرز والضغط ، سيتلقى كل عمود متجه محاسبة.
هدف تعيين ترتيب الفرز المستخدم للأعمدة كالتالي:
- تعظيم تأثير الضغط عن طريق فرز الأعمدة مع عدد صغير من العناصر في المقام الأول. يعمل الحد الأقصى للضغط على تحسين كفاءة التخزين (يلزم أقل بايت لتخزين البيانات) وكفاءة الاستعلام (يتم نقل عدد أقل من البايتات بين ذاكرة وحدة المعالجة المركزية وذاكرة وحدة معالجة الرسومات).
- توفير تصفية مناسبة قائمة على النطاق لعوامل الترشيح المكافئة الشائعة ، على سبيل المثال city_id = 12. يقلل التصفية المسبقة من عدد البايتات اللازمة لنقل البيانات بين ذاكرة وحدة المعالجة المركزية وذاكرة GPU ، مما يزيد من كفاءة الاستعلام.
يتم ضغط العمود فقط في حالة وجوده بترتيب الفرز المحدد بواسطة المستخدم. نحن لا نحاول ضغط الأعمدة بعدد كبير من العناصر ، لأن هذا يوفر القليل من الذاكرة.
بعد الفرز ، يتم ضغط بيانات كل عمود مؤهل باستخدام خيار ترميز مجموعة محدد. بالإضافة إلى متجه القيمة والناقل صفر ، فإننا نقدم متجه محاسبة لإعادة تمثيل نفس القيمة.
استقبال البيانات في الوقت الحقيقي مع دعم للتحديث وإدراج وظائف
يتلقى العملاء البيانات عبر HTTP API عن طريق نشر حزمة خدمة. حزمة الخدمة عبارة عن تنسيق ثنائي مرتب خاص يقلل من استخدام المساحة مع الحفاظ على الوصول العشوائي إلى البيانات.
عندما يتلقى AresDB حزمة الخدمة ، يقوم أولاً بكتابة حزمة الخدمة في سجل عمليات الاسترداد. عند إضافة حزمة خدمة إلى نهاية سجل الأحداث ، يقوم AresDB بتحديد الإدخالات المتأخرة وتخطيها في جداول الحقائق للاستخدام في التخزين النشط. يعتبر السجل "متأخرًا" إذا كان وقت الحدث أقدم من وقت الأرشفة لحدث قطع الاتصال. بالنسبة للسجلات التي لا تعتبر "متأخرة" ، يستخدم AresDB فهرس المفتاح الأساسي لتحديد موقع الحزمة داخل المتجر النشط الذي تريد إدراجه فيها. كما هو مبين في الشكل 6 أدناه ، يتم إدراج سجلات جديدة (لم تتم مصادفتها مسبقًا بناءً على قيمة المفتاح الأساسي) في مساحة فارغة ، ويتم تحديث السجلات الحالية مباشرةً:
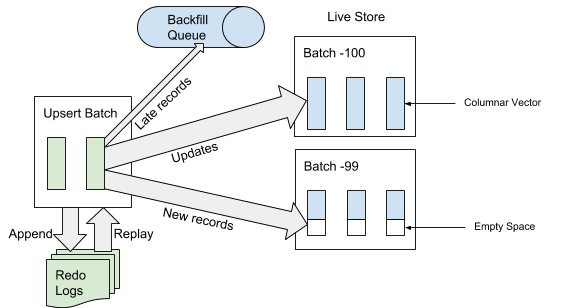
الشكل 6. عند تلقي البيانات ، وبعد إضافة حزمة الخدمة إلى سجل الأحداث ، تتم إضافة الإدخالات "المتأخرة" إلى قائمة الانتظار العكسي والإدخالات الأخرى إلى التخزين النشط.
الأرشفة
عند تلقي البيانات ، تتم إضافة / تحديث السجلات في التخزين النشط ، أو إضافتها إلى قائمة الانتظار العكسية ، في انتظار وضعها في تخزين الأرشيف.
نبدأ بشكل دوري في عملية مجدولة ، يشار إليها باسم الأرشفة ، فيما يتعلق بسجلات التخزين النشط لإرفاق سجلات جديدة (السجلات التي لم تتم أرشفتها من قبل) في تخزين الأرشيف. تعالج عملية الأرشفة السجلات في التخزين النشط فقط مع وقت الحدث في النطاق بين وقت إيقاف التشغيل القديم (وقت إيقاف التشغيل من آخر عملية أرشفة) وزمن إيقاف التشغيل الجديد (وقت إيقاف التشغيل الجديد استنادًا إلى معلمة تأخير الأرشفة في مخطط الجدول).
يتم استخدام وقت حدث السجل لتحديد أي سجلات حزمة الأرشيف يجب دمجها عند حزم بيانات الأرشيف في حزم يومية. لا تتطلب الأرشفة إلغاء البيانات المكررة لفهرس قيمة المفتاح الأساسي أثناء الدمج ، حيث يتم أرشفة السجلات فقط في النطاق بين وقت الإغلاق القديم والجديد.
يوضح الشكل 7 أدناه رسمًا بيانيًا وفقًا لوقت وقوع سجل معين.
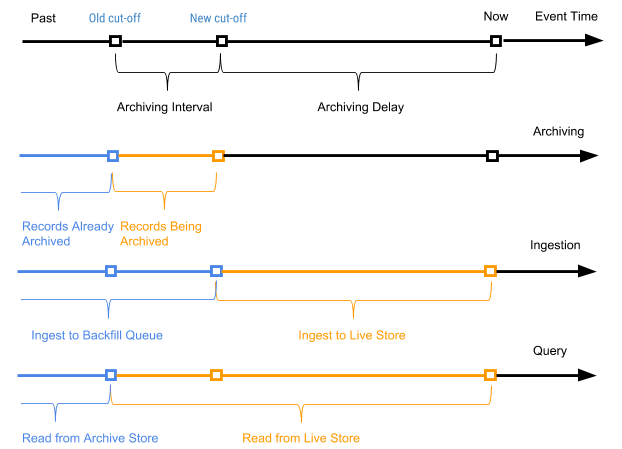
الشكل 7. نستخدم وقت الحدث ووقت الرحلة لتعريف السجلات بأنها جديدة (نشطة) وقديمة (وقت الحدث أقدم من وقت الأرشفة لحدث الرحلة).
في هذه الحالة ، يكون الفاصل الزمني للأرشفة هو الفاصل الزمني بين عمليتي الأرشفة ، وتأخير الأرشفة هو الفترة بعد وقت الحدث ، ولكن حتى يتم أرشفة الحدث. يتم تعريف كلا المعلمتين في إعدادات مخطط جدول AresDB.
ردم
كما هو موضح في الشكل 7 أعلاه ، تتم إضافة السجلات القديمة (التي يكون وقت الحدث الخاص بها أقدم من وقت الأرشفة الخاص بحدث إيقاف التشغيل) لجداول الوقائع إلى قائمة الانتظار العكسية وتتم معالجتها في النهاية كجزء من عملية الردم. مشغلات هذه العملية هي أيضًا وقت أو حجم قائمة الانتظار العكسي ، إذا وصلت إلى مستوى عتبة. مقارنة بعملية إضافة البيانات إلى التخزين النشط ، فإن إعادة الملء غير متزامنة وأكثر تكلفة نسبيًا من حيث وحدة المعالجة المركزية وموارد الذاكرة. يستخدم Backfill في السيناريوهات التالية:
- معالجة بيانات عشوائية متأخرة للغاية
- دليل التقاط البيانات التاريخية من دفق البيانات المنبع
- إدخال البيانات التاريخية في الأعمدة المضافة حديثًا
على عكس الأرشفة ، فإن عملية الردم غير صالحة وتتطلب إلغاء البيانات المكررة بناءً على قيمة المفتاح الأساسي. سوف تكون البيانات القابلة للتعبئة في النهاية مرئية للاستعلامات.
يتم الاحتفاظ بقائمة الانتظار العكسي في الذاكرة بحجم محدد مسبقًا ، ومع وجود حمولة كبيرة من الردم ، سيتم حظر العملية للعميل حتى يتم مسح قائمة الانتظار عن طريق بدء عملية الردم.
طلب المعالجة
في التطبيق الحالي ، يحتاج المستخدم إلى استخدام لغة استعلام آريس (AQL) التي أنشأها أوبر لتنفيذ الاستعلامات في AresDB. AQL هي لغة فعالة للاستعلامات التحليلية للسلاسل الزمنية ولا تتبع بناء جملة SQL القياسي مثل "SELECT From WHERE GROUP BY" مثل اللغات الأخرى المشابهة لـ SQL. بدلاً من ذلك ، يتم استخدام AQL في الحقول المهيكلة ويمكن تضمينه في كائنات JSON و YAML و Go. على سبيل المثال ، بدلاً من /SELECT (*) /FROM /GROUP BY city_id, /WHERE = «» /AND request_at >= 1512000000 ، يتم كتابة متغير AQL المكافئ في JSON كما يلي:
{ “table”: “trips”, “dimensions”: [ {“sqlExpression”: “city_id”} ], “measures”: [ {“sqlExpression”: “count(*)”} ], ;”> “rowFilters”: [ “status = 'completed'” ], “timeFilter”: { “column”: “request_at”, “from”: “2 days ago” } }
في تنسيق JSON ، تقدم AQL لمطوري لوحة القيادة ونظام صنع القرار خوارزمية استعلام برنامج أكثر ملاءمة من SQL ، مما يسمح لهم بسهولة تكوين الاستعلامات ومعالجتها باستخدام التعليمات البرمجية دون القلق بشأن أشياء مثل حقن SQL. إنه بمثابة تنسيق استعلام عالمي للبنيات النموذجية لمتصفحات الويب والخوادم الخارجية والداخلية حتى قاعدة البيانات (AresDB). بالإضافة إلى ذلك ، يوفر AQL بناء جملة مناسبًا للتصفية حسب الوقت والدفع مع دعم لمنطقته الزمنية. بالإضافة إلى ذلك ، تدعم اللغة عددًا من الوظائف ، مثل الاستعلامات الفرعية الضمنية ، لمنع الأخطاء الشائعة في الاستعلامات وتسهيل عملية تحليل الاستعلامات وإعادة كتابتها لمطوري الواجهة الداخلية.
على الرغم من المزايا العديدة التي تقدمها AQL ، فإننا ندرك جيدًا أن معظم المهندسين أكثر دراية بـ SQL. يعد توفير واجهة SQL لتنفيذ الاستعلامات أحد الخطوات التالية التي سننظر إليها كجزء من جهودنا لتحسين التفاعل مع مستخدمي AresDB.
يظهر مخطط تنفيذ استعلام AQL في الشكل 8 أدناه:
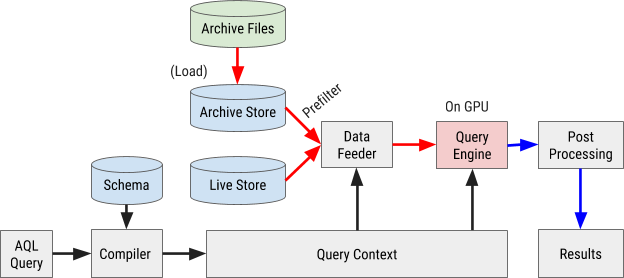
الشكل 8. يستخدم مخطط انسيابي للاستعلام AresDB لغة استعلام AQL الخاصة بنا لمعالجة البيانات واسترجاعها بسرعة وكفاءة.
تجميع الاستعلام
يتم تصنيف استعلام AQL في سياق الاستعلام الداخلي. يتم تحليل التعبيرات في المرشحات والقياسات والمعلمات في أشجار بناء الجملة المجردة (AST) لمزيد من المعالجة من خلال معالج الرسومات (GPU).
تحميل البيانات
يستخدم AresDB المرشحات المسبقة لتصفية بيانات الأرشفة بثمن بخس قبل إرسالها إلى وحدة معالجة الرسومات لمعالجة متوازية. نظرًا لتصنيف البيانات المؤرشفة وفقًا لترتيب العمود المكوّن ، يمكن لبعض المرشحات استخدام ترتيب الفرز هذا وطريقة البحث الثنائية لتحديد النطاق المناسب للمطابقة. على وجه الخصوص ، يمكن استخدام المرشحات المكافئة لجميع أعمدة X التي تم فرزها في البداية ومرشح النطاق الاختياري للأعمدة التي تم فرزها X + 1 كمرشحات أولية ، كما هو موضح في الشكل 9 أدناه.

الشكل 9. يقوم AresDB بتصفية بيانات العمود مسبقًا قبل إرسالها إلى وحدة معالجة الرسومات للمعالجة.
بعد التصفية المسبقة ، يجب إرسال القيم الخضراء فقط (تلبية شرط التصفية) إلى وحدة معالجة الرسومات لمعالجة متوازية. يتم تحميل بيانات الإدخال في وحدة معالجة الرسومات ومعالجتها حزمة واحدة في وقت واحد. ويشمل ذلك الحزم النشطة وحزم الأرشيف.
يستخدم AresDB تدفقات CUDA لخطوط الأنابيب ومعالجة البيانات. لكل طلب ، يتم تطبيق دفقين بالتناوب للمعالجة في مرحلتين متداخلتين. في الشكل 10 أدناه ، نقدم رسمًا بيانيًا يوضح هذه العملية.
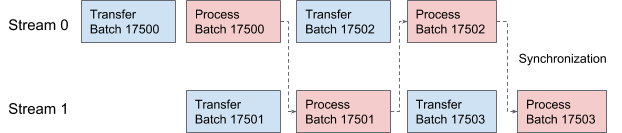
الشكل 10. في AresDB ، يقوم اثنان من مؤشرات الترابط CUDA بنقل ومعالجة البيانات بالتناوب.
تنفيذ الاستعلام
للبساطة ، يستخدم AresDB مكتبة Thrust لتنفيذ إجراءات تنفيذ الاستعلام ، والتي توفر كتل من خوارزمية متوازية ضبطها بدقة من أجل التنفيذ السريع للاستعلامات في الأداة الحالية.
في الدفع ، يتم تقييم بيانات متجه المدخلات والمخرجات باستخدام وحدات تكرار الوصول العشوائي. يبحث كل مؤشر ترابط GPU عن تكرارات الإدخال في موضع العمل الخاص به ، ويقرأ القيم ويقوم بإجراء العمليات الحسابية ، ثم يكتب النتيجة إلى الموضع المقابل في تكرار المخرجات.
لتقييم تعبيرات AresDB ، يتبع نموذج "عامل واحد لكل نواة" (OOPK).
في الشكل 11 أدناه ، يتم توضيح هذا الإجراء باستخدام مثال AST الذي تم إنشاؤه من تعبير البعد request_at – request_at % 86400 في مرحلة تجميع الطلبات:
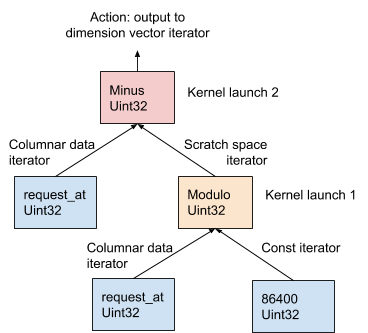
الشكل 11. يستخدم AresDB نموذج OOPK لتقييم التعبيرات.
في نموذج OOPK ، يتخطى مشغل استعلام AresDB كل عقدة ورقة لشجرة AST ويعيد تكرارا للعقدة المصدر. إذا كانت عقدة الجذر محدودة أيضًا ، فسيتم تنفيذ إجراء الجذر مباشرة على مكرر الإدخال.
لكل عقدة غير نهائية غير جذرية ( تشغيل modulo في هذا المثال) ، يتم تخصيص متجه مساحة عمل مؤقت لتخزين النتيجة المتوسطة التي تم الحصول عليها من تعبير request_at% 86400 . باستخدام Thrust ، يتم تشغيل وظيفة kernel لحساب نتيجة هذا البيان في وحدة معالجة الرسومات. يتم تخزين النتائج في مكرر مساحة العمل.
بالنسبة لعقدة الجذر ، تعمل وظيفة kernel بنفس طريقة تشغيل عقدة غير جذر غير محدودة. يتم تنفيذ إجراءات الإخراج المختلفة بناءً على نوع التعبير ، الموضح بالتفصيل أدناه:
- تصفية لتقليل عدد عناصر متجه الإدخال
- تسجيل بيانات مخرجات القياس في متجه القياس لدمج البيانات اللاحقة
- تسجيل إخراج المعلمات في متجه المعلمة لدمج البيانات اللاحقة
بعد تقييم التعبير ، يتم إجراء الفرز والتحول لدمج البيانات أخيرًا. في عمليات الفرز والتحول ، نستخدم قيم متجه البعد كقيم أساسية للفرز والتحول ، وقيم متجه المعلمة كقيم لدمج البيانات. وبالتالي ، يتم تجميع الصفوف ذات قيم البعد المتشابهة ودمجها. يوضح الشكل 12 أدناه عملية الفرز والتحويل هذه.
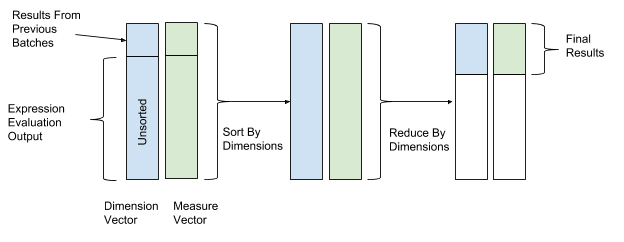
الشكل 12. بعد تقييم التعبير ، يقوم AresDB بفرز وتحويل البيانات وفقًا للقيم الأساسية لمتجهات القياس (القيمة الرئيسية) والمعلمات (القيمة).
يدعم AresDB أيضًا وظائف الاستعلام المتقدمة التالية:
- انضمام : يدعم AresDB حاليًا خيار ربط التجزئة بين جدول الحقائق وجدول البعد
- تقدير عدد عناصر Hyperloglog: يستخدم AresDB خوارزمية Hyperloglog
- تقاطع Geo : يدعم AresDB حاليًا العمليات المترابطة فقط بين GeoPoint و GeoShape
إدارة الموارد
كقاعدة بيانات تعتمد على الذاكرة الداخلية ، يجب على AresDB إدارة الأنواع التالية من استخدام الذاكرة:
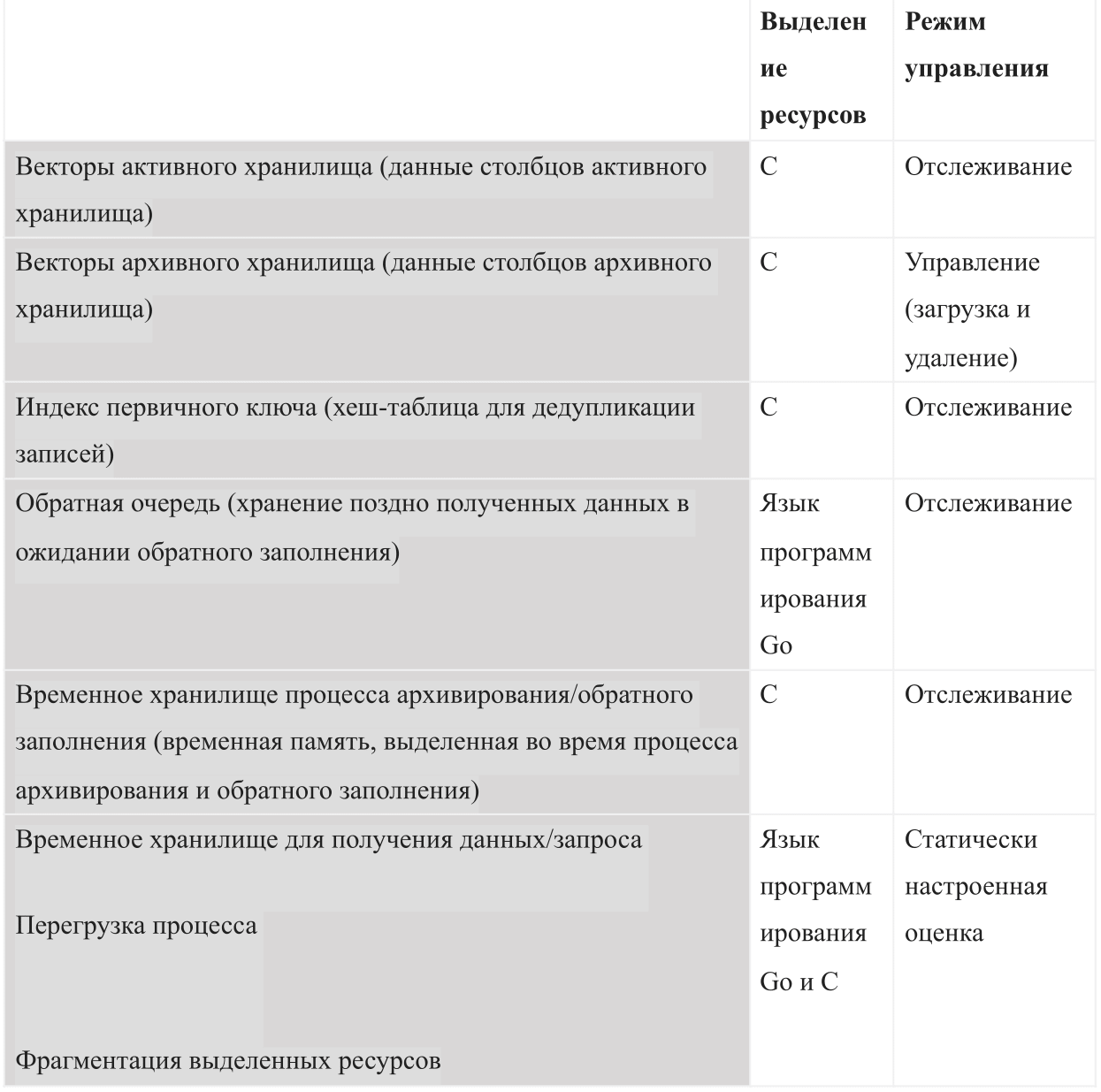
عندما يبدأ AresDB ، فإنه يستخدم ميزانية الذاكرة المشتركة المكونة. يتم تقسيم الميزانية إلى جميع أنواع الذاكرة الستة ويجب أن تترك أيضًا مساحة كافية لنظام التشغيل والعمليات الأخرى. تتضمن هذه الميزانية أيضًا تقدير ازدحام تم تكوينه بشكل ثابت ، ومخزن بيانات نشط يراقبه الخادم ، وبيانات مؤرشفة قد يقرر الخادم تنزيلها وحذفها اعتمادًا على ميزانية الذاكرة المتبقية.
يوضح الشكل 13 أدناه نموذج ذاكرة المضيف AresDB.
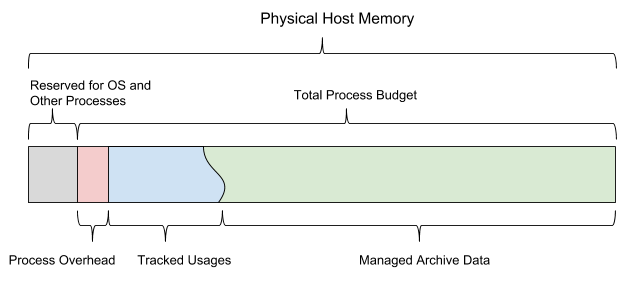
الشكل 13. AresDB يدير استخدام الذاكرة الخاصة به بحيث لا يتجاوز ميزانية العملية الإجمالية التي تم تكوينها.
يتيح AresDB للمستخدمين تعيين أيام التحميل المسبق وأولويات مستوى العمود لجداول الحقائق وعمليات تحميل البيانات المحفوظة مسبقًا في أيام التحميل المسبق فقط. يتم تحميل البيانات التي لم يتم تنزيلها مسبقًا في الذاكرة من القرص عند الطلب. عند التعبئة ، يقوم AresDB أيضًا بحذف البيانات المؤرشفة من ذاكرة المضيف. تستند مبادئ إزالة AresDB إلى المعلمات التالية: عدد أيام التحميل المسبق ، وأولويات الأعمدة ، ويوم تجميع الحزمة ، وحجم العمود.
يدير AresDB أيضًا العديد من أجهزة GPU ويحاكي موارد الجهاز مثل سلاسل عمليات GPU وذاكرة الجهاز ، ويتتبع استخدام ذاكرة GPU لمعالجة الطلبات. يقوم AresDB بإدارة أجهزة GPU من خلال إدارة الأجهزة التي تقوم بتصوير موارد جهاز GPU في بعدين (مؤشرات ترابط GPU وذاكرة الجهاز) وتتبع استخدام الذاكرة عند معالجة الطلبات. بعد ترجمة الطلب ، يتيح AresDB للمستخدمين تقدير مقدار الموارد اللازمة لإكمال الطلب. يجب تلبية متطلبات ذاكرة الجهاز قبل حل الطلب ؛ إذا كانت هناك ذاكرة غير كافية حاليًا على أي جهاز ، فيجب أن ينتظر الطلب. حاليًا ، يمكن لـ AresDB تنفيذ طلب واحد أو أكثر على جهاز GPU نفسه في نفس الوقت إذا كان الجهاز يلبي جميع متطلبات الموارد.
في التطبيق الحالي ، لا يقوم AresDB بتخزين ذاكرة التخزين المؤقت في ذاكرة الجهاز لإعادة استخدامها في طلبات متعددة. يهدف AresDB إلى دعم الاستعلامات مقابل مجموعات البيانات التي يتم تحديثها باستمرار في الوقت الفعلي وتخزينها بشكل سيء بشكل صحيح. في الإصدارات المستقبلية من AresDB ، نعتزم تنفيذ وظائف للتخزين المؤقت للبيانات في ذاكرة GPU ، مما سيساعد على تحسين أداء الاستعلام.
في Uber ، نستخدم AresDB لإنشاء لوحات معلومات للحصول على معلومات العمل في الوقت الفعلي. AresDB مسؤول عن تخزين الأحداث الأساسية مع التحديثات المستمرة وحساب المقاييس المهمة بالنسبة لهم في ثانية مقسمة بفضل موارد GPU بتكلفة منخفضة ، بحيث يمكن للمستخدمين استخدام لوحات المعلومات بشكل تفاعلي. على سبيل المثال ، يتم تحديث بيانات الرحلة مجهولة الهوية التي لها فترة صلاحية طويلة في مستودع البيانات من خلال العديد من الخدمات ، بما في ذلك نظام الإرسال ونظام الدفع والتسعير الخاص بنا. لتحقيق الاستخدام الفعال لبيانات السفر ، يقوم المستخدمون بتقسيم البيانات وتقسيمها إلى أبعاد مختلفة لاكتساب نظرة ثاقبة على الحلول في الوقت الفعلي.
عند استخدام AresDB ، فإن لوحة معلومات Uber هي لوحة معلومات للتحليل واسعة النطاق تستخدمها فرق داخل الشركة لإنتاج مقاييس ذات صلة واستجابات في الوقت الفعلي لتحسين تجربة المستخدم.
14. Uber AresDB .
, , :
( )

( )

AresDB
, , AresDB :

, , , , , .
AresDB , Apache Kafka , , Apache Flink Apache Spark .
AresDB
, « » « ». , -. 24 AQL:

:
, , .

, AresDB , , . AresDB , , .
AresDB Uber , . , , AresDB .
:
- : AresDB, , , .
- : AresDB 2018 , , AresDB .
- : , , , .
- : , (LLVM) GPU.
AresDB Apache. AresDB .
, .
شكر وتقدير
(Kate Zhang), (Jennifer Anderson), (Nikhil Joshi), (Abhi Khune), (Shengyue Ji), (Chinmay Soman), (Xiang Fu), (David Chen) (Li Ning) , !