ملاحظة perev. : شارك موظفو Tinder مؤخرًا بعض التفاصيل الفنية لترحيل بنيتهم التحتية إلى Kubernetes. استغرقت العملية ما يقرب من عامين وأسفرت عن إطلاق منصة K8 على منصة كبيرة للغاية تتكون من 200 خدمة مستضافة على 48 ألف حاوية. ما الصعوبات المثيرة التي واجهها مهندسو Tinder وما هي النتائج التي توصلوا إليها - اقرأ في هذه الترجمة.
لماذا؟
قبل عامين تقريبًا ، قررت Tinder تبديل برنامجها إلى Kubernetes. سوف تسمح Kubernetes لفريق Tinder بالحاوية والتحول إلى التشغيل بأقل جهد ممكن من خلال
النشر الثابت . في هذه الحالة ، سيتم تحديد تجميع التطبيقات ونشرها والبنية التحتية نفسها بشكل فريد بواسطة الرمز.
بحثنا أيضًا عن حل لمشكلة قابلية التوسع والاستقرار. عندما أصبح التحجيم أمرًا بالغ الأهمية ، كان علينا غالبًا الانتظار عدة دقائق لإطلاق مثيلات EC2 جديدة. لذلك ، أصبحت فكرة إطلاق الحاويات وبدء خدمة المرور في ثوانٍ بدلاً من دقائق جذابة للغاية بالنسبة لنا.
لم تكن العملية سهلة. خلال عملية الترحيل ، في أوائل عام 2019 ، وصلت كتلة Kubernetes إلى كتلة حرجة وبدأنا نواجه العديد من المشكلات بسبب حجم الحركة وحجم المجموعة و DNS. في هذه الرحلة ، قمنا بحل الكثير من المشكلات المثيرة للاهتمام المتعلقة بنقل 200 خدمة وصيانة مجموعة Kubernetes ، التي تتكون من 1000 عقدة و 15000 قرنة و 48000 حاوية عمل.
كيف؟
منذ يناير 2018 ، مررنا بمراحل مختلفة من الهجرة. بدأنا عن طريق حاويات جميع خدماتنا ونشرها في بيئات اختبار Kubernetes. في أكتوبر ، بدأت عملية النقل المنهجي لجميع الخدمات الحالية إلى Kubernetes. بحلول شهر مارس من العام التالي ، تم الانتهاء من "النقل" والآن تعمل منصة Tinder حصريًا على Kubernetes.
بناء الصور ل Kubernetes
لدينا أكثر من 30 مستودعًا للشفرة المصدرية للخدمات الصغيرة التي تعمل في مجموعة Kubernetes. تتم كتابة التعليمات البرمجية الموجودة في هذه المستودعات بلغات مختلفة (على سبيل المثال ، Node.js و Java و Scala و Go) مع العديد من بيئات وقت التشغيل لنفس اللغة.
تم تصميم نظام الإنشاء لتوفير "سياق بناء" قابل للتخصيص بالكامل لكل خدمة microservice. يتكون عادةً من Dockerfile وقائمة أوامر shell. محتوياتها قابلة للتخصيص بالكامل ، وفي الوقت نفسه ، تتم كتابة جميع سياقات البناء وفقًا لتنسيق موحد. يتيح توحيد سياقات الإنشاء لنظام بناء واحد التعامل مع جميع الخدمات المصغرة.
 الشكل 1-1. عملية بناء موحدة من خلال باني الحاويات (Builder)
الشكل 1-1. عملية بناء موحدة من خلال باني الحاويات (Builder)لتحقيق أقصى اتساق بين أوقات التشغيل ، يتم استخدام نفس عملية الإنشاء أثناء التطوير والاختبار. لقد واجهنا مشكلة مثيرة للغاية: كان علينا تطوير طريقة لضمان تناسق بيئة التجميع في جميع أنحاء النظام الأساسي. للقيام بذلك ، يتم تنفيذ جميع عمليات التجميع داخل حاوية
منشئ خاصة.
يتطلب تنفيذه تقنيات متقدمة للعمل مع Docker. يرث Builder معرف المستخدم المحلي والأسرار (مثل مفتاح SSH وبيانات اعتماد AWS وما إلى ذلك) المطلوبة للوصول إلى مستودعات Tinder الخاصة. يحمّل الدلائل المحلية التي تحتوي على مصدر لتخزين القطع الأثرية التجميع بشكل طبيعي. تعمل هذه الطريقة على تحسين الأداء من خلال التخلص من الحاجة إلى نسخ عناصر التجميع بين حاوية الباني والمضيف. يمكن إعادة استخدام عناصر التجميع المخزنة دون تكوين إضافي.
بالنسبة لبعض الخدمات ، اضطررنا إلى إنشاء حاوية أخرى لمطابقة بيئة الترجمة مع وقت التشغيل (على سبيل المثال ، أثناء عملية التثبيت ، تنشئ مكتبة Node.js bcrypt مصنوعات ثنائية ثنائية خاصة بالنظام الأساسي). أثناء التحويل البرمجي ، قد تختلف المتطلبات للخدمات المختلفة ، ويتم تجميع ملف Dockerfile النهائي سريعًا.
Kubernetes الكتلة العمارة والهجرة
إدارة حجم الكتلة
قررنا استخدام
kube-aws لنشر الكتلة تلقائيًا على مثيلات Amazon EC2. في البداية ، كان كل شيء يعمل في مجموعة مشتركة واحدة من العقد. أدركنا بسرعة الحاجة إلى فصل أعباء العمل حسب الحجم ونوع الحالات لاستخدام أكثر كفاءة للموارد. كان المنطق هو أن إطلاق عدة قرون متعددة الخيوط تم تحميلها كان قابلاً للتنبؤ في الأداء أكثر من تعايشها مع عدد كبير من القرون المفردة الترابط.
نتيجة لذلك ، استقرنا على:
- m5.4xlarge - للمراقبة (بروميثيوس) ؛
- c5.4xlarge - بالنسبة إلى عبء العمل Node.js (حمل العمل المفرد المترابط) ؛
- c5.2xlarge - لـ Java and Go (عبء العمل المتعدد الخيوط) ؛
- c5.4xlarge - للوحة التحكم (3 عقد).
الهجرة
كانت إحدى الخطوات التحضيرية للانتقال من البنية التحتية القديمة إلى Kubernetes إعادة توجيه التفاعل المباشر الحالي بين الخدمات إلى موازين التحميل الجديدة (ELB ، موازن التحميل المرنة). تم إنشاؤها على شبكة فرعية خاصة سحابة خاصة (VPC). تم توصيل هذه الشبكة الفرعية بـ Kubernetes VPC. هذا سمح لنا بترحيل الوحدات بشكل تدريجي ، دون الأخذ في الاعتبار الترتيب المحدد لتبعيات الخدمة.
تم إنشاء نقاط النهاية هذه باستخدام مجموعات مرجحة من سجلات DNS مع الإشارة إلى CNAMEs إلى كل ELB جديد. للتبديل ، أضفنا سجلاً جديدًا يشير إلى خدمة Kubernetes الجديدة ELB بوزن 0. ثم قمنا بتعيين وقت البقاء (TTL) لمجموعة السجلات على 0. بعد ذلك ، تم تعديل الأوزان القديمة والجديدة ببطء ، وفي النهاية ذهب 100٪ من الحمل إلى الخادم الجديد. بعد اكتمال التبديل ، عادت قيمة TTL إلى مستوى أكثر ملاءمة.
عالجت وحدات Java الموجودة لدينا نظام TTL DNS المنخفض ، لكن تطبيقات العقدة لم تفعل ذلك. أعاد أحد المهندسين كتابة جزء من رمز تجمع الاتصالات ، لفه في مدير قام بتحديث المجمعات كل 60 ثانية. عملت الطريقة المختارة بشكل جيد للغاية ودون انخفاض ملحوظ في الأداء.
الدروس
قيود جهاز الشبكة
في ساعات الصباح الباكر من 8 يناير 2019 ، تحطمت منصة Tinder فجأة. استجابة لزيادة غير مرتبطة في زمن الوصول إلى النظام الأساسي في وقت مبكر من الصباح ، زاد عدد القرون والعقد في المجموعة. هذا أدى إلى استنفاد ذاكرة التخزين المؤقت ARP على كافة العقد الخاصة بنا.
هناك ثلاثة خيارات Linux مرتبطة بذاكرة التخزين المؤقت لـ ARP:

(
المصدر )
gc_thresh3 هو الحد الصعب. يعني المظهر في سجل إدخالات النموذج "تجاوز جدول الجوار" أنه حتى بعد جمع البيانات المهملة المتزامنة (GC) في ذاكرة التخزين المؤقت ARP ، لم تكن هناك مساحة كافية لتخزين السجل المجاور. في هذه الحالة ، قام النواة ببساطة بإسقاط الحزمة.
نحن نستخدم
الفانيلا كنسيج شبكة في Kubernetes. تنتقل الحزم عبر VXLAN. VXLAN هو نفق L2 ، تم رفعه عبر شبكة L3. تستخدم التكنولوجيا تغليف MAC-in-UDP (بروتوكول مخطط بيانات عنوان المستخدم) وتسمح لك بتوسيع شرائح الشبكة من المستوى الثاني. بروتوكول النقل في الشبكة الفعلية لمركز البيانات هو IP plus UDP.
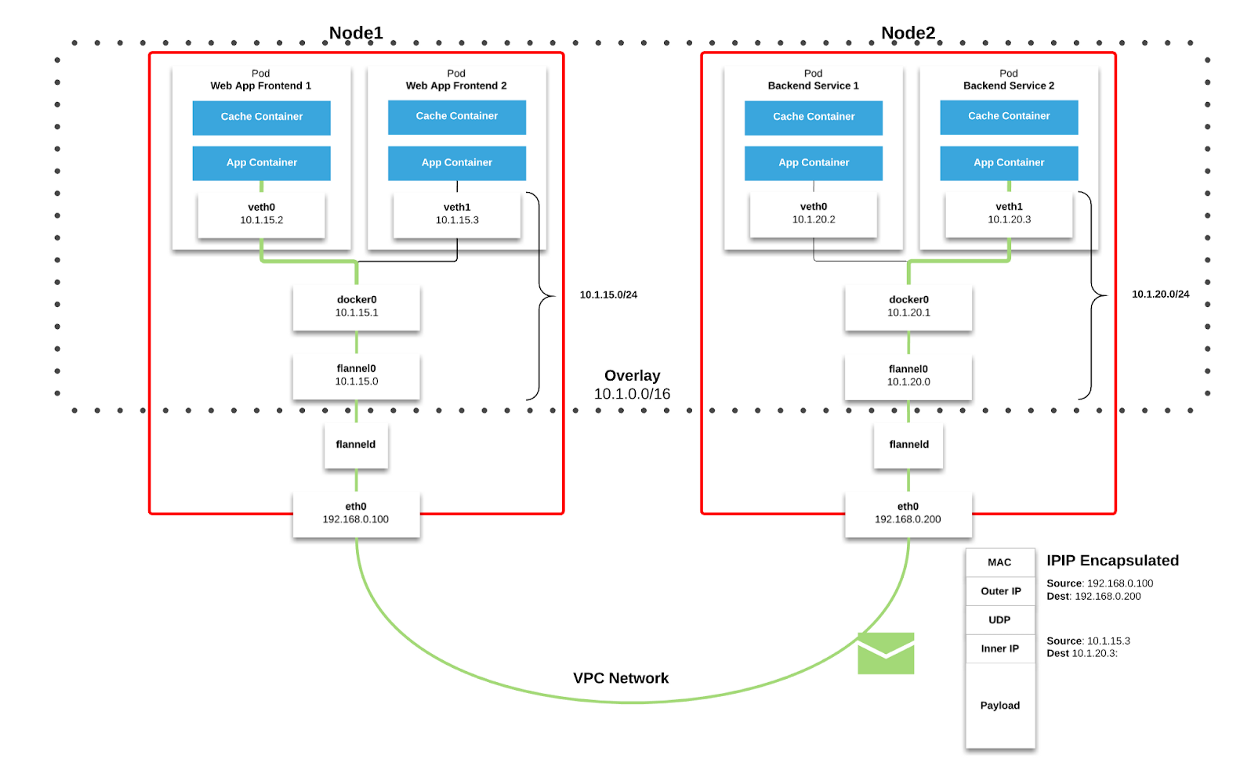 الشكل 2-1. مخطط الفانيلا ( المصدر )
الشكل 2-1. مخطط الفانيلا ( المصدر ) الشكل 2-2. حزمة VXLAN ( المصدر )
الشكل 2-2. حزمة VXLAN ( المصدر )كل عقدة عمل Kubernetes تخصص مساحة عنوان افتراضية مع قناع / 24 من الكتلة الأكبر / 9. لكل عقدة ،
يعني هذا إدخالًا واحدًا في جدول التوجيه ،
وإدخالًا واحدًا في جدول ARP (على الواجهة
flannel.1 )
وإدخالًا واحدًا في جدول التبديل (FDB). تتم إضافتها عند بدء عقدة العمل لأول مرة أو عند اكتشاف كل عقدة جديدة.
بالإضافة إلى ذلك ، ينتهي اتصال العقدة (أو pod-pod) في النهاية من خلال واجهة
eth0 (كما هو موضح في مخطط Flannel أعلاه). ينتج عن هذا إدخال إضافي في جدول ARP لكل مصدر ووجهة مطابقة للعقدة.
في بيئتنا ، هذا النوع من الاتصالات شائع للغاية. بالنسبة لكائنات نوع الخدمة في Kubernetes ، يتم إنشاء ELB ويقوم Kubernetes بتسجيل كل عقدة في ELB. ELB لا يعرف شيئًا عن القرون وقد لا تكون العقدة المحددة هي الوجهة النهائية للحزمة. والحقيقة هي أنه عندما تتلقى العقدة حزمة من ELB ، فإنها تراعي ذلك مع مراعاة قواعد
iptables لخدمة معينة وتختار عشوائيًا pod على عقدة أخرى.
في وقت الفشل ، كان لدى المجموعة 605 عقد. للأسباب المذكورة أعلاه ، كان هذا كافياً للتغلب على قيمة
gc_thresh3 الافتراضية . عندما يحدث هذا ، لا يتم التخلص من الحزم فقط ، ولكن تختفي مساحة العنوان الافتراضية لـ Flannel بالكامل مع قناع / 24 من جدول ARP. تمت مقاطعة اتصالات العقدة واستعلامات DNS (تتم استضافة DNS في كتلة ؛ راجع بقية هذه المقالة للحصول على التفاصيل).
لحل هذه المشكلة ، قم بزيادة قيم
gc_thresh1 و
gc_thresh2 و
gc_thresh3 وأعد تشغيل Flannel لإعادة تسجيل الشبكات المفقودة.
تحجيم DNS غير متوقع
أثناء عملية الترحيل ، استخدمنا DNS بنشاط لإدارة حركة المرور ونقل الخدمات تدريجياً من البنية التحتية القديمة إلى Kubernetes. وضعنا قيم TTL منخفضة نسبيًا لمجموعات السجلات ذات الصلة في Route53. عندما كانت البنية الأساسية القديمة تعمل على مثيلات EC2 ، أشار تكوين محلل البيانات الخاص بنا إلى Amazon DNS. لقد اعتبرنا ذلك أمرًا مفروغًا منه ، كما أن تأثير انخفاض TTL على خدمات Amazon لدينا (مثل DynamoDB) لم يلاحظه أحد تقريبًا.
عندما تم نقل الخدمات إلى Kubernetes ، وجدنا أن DNS يتعامل مع 250،000 استفسار في الثانية. نتيجة لذلك ، بدأت التطبيقات في اختبار مهلات ثابتة وخطيرة لاستعلامات DNS. حدث هذا على الرغم من الجهود المذهلة لتحسين وتبديل مزود DNS إلى CoreDNS (التي وصلت إلى 1000 قرنة تعمل على 120 مركز في ذروة الحمل).
استكشاف الأسباب والحلول المحتملة الأخرى ، وجدنا
مقالة تصف ظروف السباق التي تؤثر على إطار تصفية حزم
netfilter على Linux. تتوافق المهلات التي لاحظناها مع العداد
insert_failed المتزايد في واجهة Flannel مع استنتاجات المقالة.
تنشأ المشكلة في مرحلة ترجمة عنوان المصدر والوجهة الشبكة (SNAT و DNAT)
والإدخال اللاحق إلى جدول
conntrack . أحد الحلول التي نوقشت داخل الشركة والتي اقترحها المجتمع هو نقل DNS إلى عقدة العمل نفسها. في هذه الحالة:
- لا يلزم SNAT لأن حركة المرور تبقى داخل العقدة. لا يحتاج إلى توجيه من خلال واجهة eth0 .
- ليست هناك حاجة إلى DNAT ، لأن عنوان IP المقصود محلي للمضيف ، وليس جرابًا تم اختياره عشوائيًا وفقًا لقواعد iptables .
قررنا التمسك بهذا النهج. تم نشر CoreDNS كـ DaemonSet في Kubernetes وقمنا بتطبيق خادم DNS مضيف محلي في
حلال كل
من قرنة عن طريق تكوين علامة
--cluster-dns للأمر
kubelet . لقد أثبت هذا الحل فعاليته في مهل DNS.
ومع ذلك ، ما زلنا لاحظنا فقدان الحزمة وزيادة العداد
insert_failed في واجهة Flannel. استمر هذا الموقف بعد إدخال الحل ، حيث تمكنا من استبعاد SNAT و / أو DNAT فقط لحركة مرور DNS. استمرت ظروف السباق لأنواع أخرى من حركة المرور. لحسن الحظ ، فإن معظم حزمنا هي TCP ، وعندما تحدث مشكلة ، يتم إعادة إرسالها ببساطة. ما زلنا نحاول إيجاد حل مناسب لجميع أنواع حركة المرور.
باستخدام المبعوث لتحسين توازن الحمل
أثناء ترحيل خدمات الخلفية إلى Kubernetes ، بدأنا نعاني من حمولة غير متوازنة بين القرون. لقد وجدنا أنه بسبب HTTP Keepalive ، علقت اتصالات ELB على السنفات الجاهزة الأولى لكل عملية نشر تمهيدية. وهكذا ، ذهب الجزء الأكبر من حركة المرور من خلال نسبة صغيرة من القرون المتاحة. كان الحل الأول الذي قمنا باختباره هو تعيين المعلمة MaxSurge إلى 100٪ على عمليات النشر الجديدة لأسوأ الحالات. كان التأثير ضئيلاً وغير واعد من حيث عمليات النشر الكبيرة.
الحل الآخر الذي استخدمناه هو زيادة طلبات الموارد بشكل مصطنع للخدمات المهمة. في هذه الحالة ، سيكون للقرون المجاورة مساحة أكبر للمناورة مقارنة بالقرون الثقيلة الأخرى. على المدى الطويل ، لن ينجح أيضًا بسبب إهدار الموارد. بالإضافة إلى ذلك ، كانت تطبيقات Node الخاصة بنا مفردة الترابط ، وبالتالي ، يمكن فقط استخدام نواة واحدة. كان الحل الحقيقي الوحيد هو استخدام موازنة تحميل أفضل.
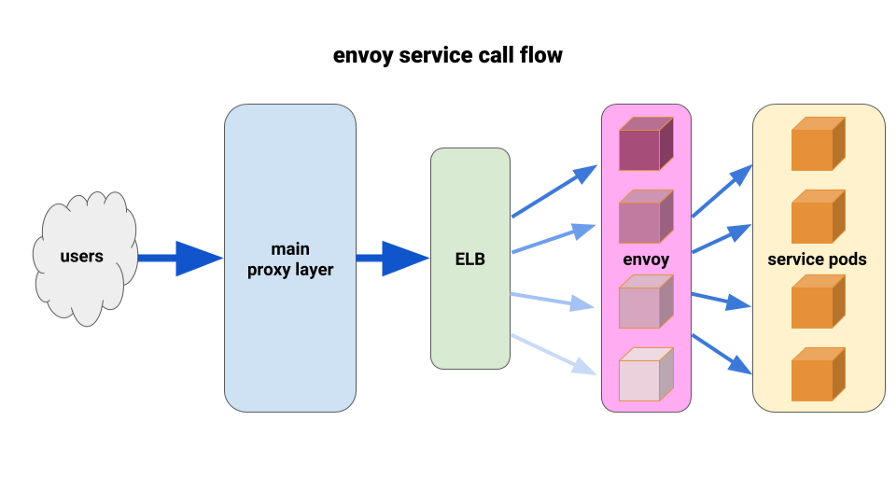
لقد أردنا منذ فترة طويلة أن نقدر
المبعوث بالكامل. الوضع الحالي سمح لنا بنشرها بطريقة محدودة للغاية والحصول على نتائج فورية. يعد Envoy وكيلًا مفتوح المصدر وعالي الأداء من المستوى السابع مصمم لتطبيقات الخدمية الكبيرة. إنه قادر على تطبيق تقنيات موازنة التحميل المتقدمة ، بما في ذلك المحاولات التلقائية وقواطع الدوائر الكهربائية وحدود السرعة العالمية.
( ملاحظة الترجمة : لمزيد من التفاصيل ، راجع المقالة الأخيرة حول Istio - شبكة الخدمة ، والتي تستند إلى Envoy.)لقد توصلنا إلى التكوين التالي: لدينا Envis sidecar لكل جراب وطريق واحد ، والكتلة - قم بتوصيل الحاوية محليًا بواسطة منفذ. لتقليل المتتالية المحتملة والمحافظة على دائرة نصف قطرها صغير من "التلف" ، استخدمنا منصة pod أمام الوكيل Envoy ، واحدة لكل منطقة توفر (AZ) لكل خدمة. لقد تحولوا إلى آلية اكتشاف خدمة بسيطة كتبها أحد مهندسينا ، والتي أعادت ببساطة قائمة بالقرون في كل من الألف إلى الياء لخدمة معينة.
بعد ذلك ، استخدم مبعوثو الخدمة آلية اكتشاف الخدمة هذه مع مجموعة واحدة من المسار الرئيسي والطريق. لقد حددنا مهلات كافية ، وزدنا كل إعدادات قاطع الدائرة ، وأضفنا الحد الأدنى من إعدادات إعادة المحاولة للمساعدة في حالات الفشل الفردية وضمان نشر سلس. قبل كل من مبعوثي الخدمة هؤلاء ، وضعنا TCP ELB. حتى إذا كانت مادة keepalive من طبقة البروكسي الرئيسية الخاصة بنا معلقة على بعض السنفات من Envoy ، فبإمكانها التعامل مع الحمل بشكل أفضل بكثير وتم ضبطها لتحقيق التوازن من خلال طلب على الأقل في الخلفية.
للنشر ، استخدمنا الخطاف preStop على كل من قرون التطبيق والقرون الجانبية. بدأ الخطاف في التحقق من حالة نقطة نهاية المسؤول الموجودة على الحاوية الجانبية ، و "النوم" لفترة من الوقت للسماح بإكمال الاتصالات النشطة.
أحد الأسباب وراء تمكننا من التقدم بسرعة كبيرة في حل المشكلات يتعلق بالمقاييس التفصيلية التي تمكنا من دمجها بسهولة في تثبيت بروميثيوس القياسي. معهم ، أصبح من الممكن رؤية ما حدث بالضبط أثناء تحديد معلمات التكوين وإعادة توزيع حركة المرور.
كانت النتائج فورية وواضحة. لقد بدأنا بأكثر الخدمات غير المتوازنة ، وفي الوقت الحالي ، فإنه يعمل بالفعل قبل أهم 12 خدمة في المجموعة. نخطط هذا العام للانتقال إلى شبكة خدمة كاملة مع اكتشاف أكثر تقدمًا للخدمة ، وكسر الدارات ، والكشف عن الخارج ، والحد من السرعة والتتبع.
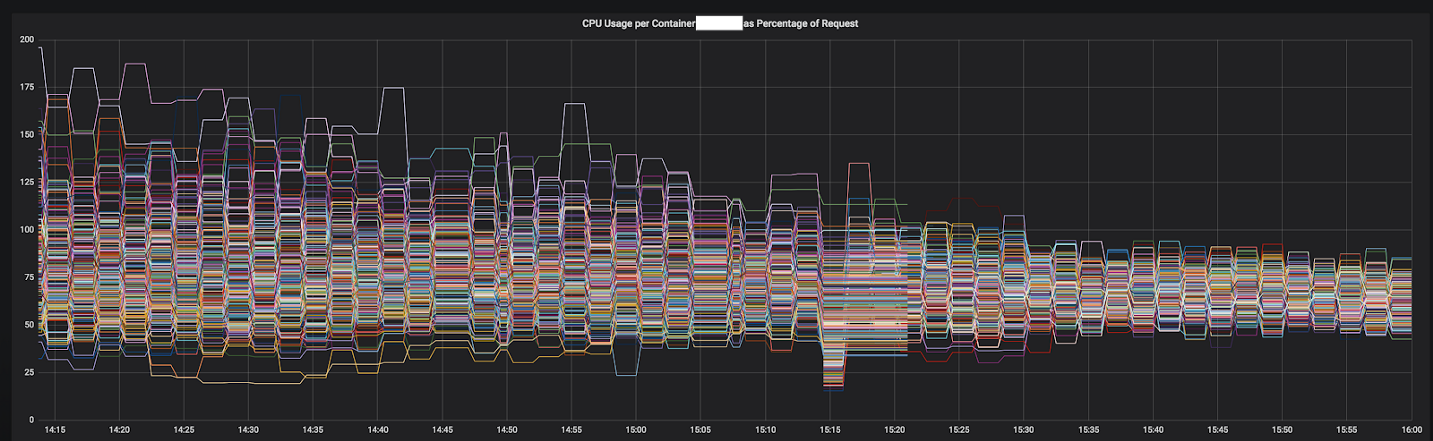 الشكل 3-1. تقارب وحدة المعالجة المركزية من خدمة واحدة أثناء الانتقال إلى المبعوث
الشكل 3-1. تقارب وحدة المعالجة المركزية من خدمة واحدة أثناء الانتقال إلى المبعوث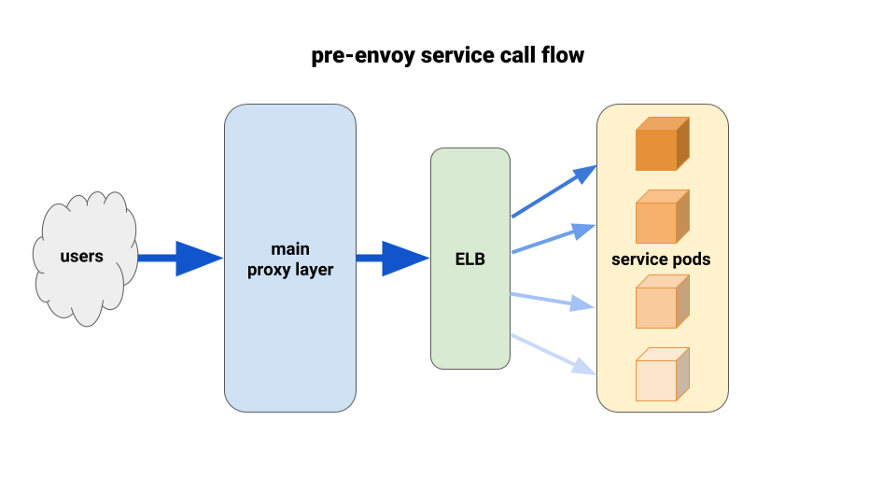
النتيجة النهائية
بفضل خبرتنا وأبحاثنا الإضافية ، قمنا ببناء فريق قوي للبنية التحتية يتمتع بمهارات جيدة في تصميم ونشر وتشغيل مجموعات Kubernetes الكبيرة. الآن جميع مهندسي Tinder لديهم المعرفة والخبرة في كيفية تعبئة الحاويات ونشر التطبيقات في Kubernetes.
عندما نشأت الحاجة إلى قدرات إضافية على البنية التحتية القديمة ، كان علينا الانتظار عدة دقائق لإطلاق مثيلات EC2 جديدة. تبدأ الحاويات الآن في البدء والبدء في معالجة حركة المرور لعدة ثوانٍ بدلاً من دقائق. توفر جدولة حاويات متعددة في مثيل واحد من EC2 أيضًا تحسين التركيز الأفقي. نتيجة لذلك ، في عام 2019 ، نتوقع حدوث انخفاض كبير في تكاليف EC2 مقارنة بالعام الماضي.
استغرق الأمر ما يقرب من عامين للهجرة ، لكننا أكملناها في مارس 2019. حاليًا ، تعمل منصة Tinder حصريًا على مجموعة Kubernetes ، التي تتكون من 200 خدمة و 1000 عقدة و 15000 جراب و 48000 حاوية جارية. البنية التحتية لم تعد المسؤولية الوحيدة لفرق التشغيل. يشارك جميع مهندسينا هذه المسؤولية ويتحكمون في عملية بناء ونشر تطبيقاتهم باستخدام الكود فقط.
PS من المترجم
اقرأ أيضًا سلسلة مقالاتنا على مدونتنا: