في آخر تجمع داخلي لبيروس ، تحدثنا عن التخزين الموزع الحديث ، وشارك ماكسيم نلسكي ، الرئيس التنفيذي ومؤسس Pyrus ، انطباعه الأول عن FoundationDB. في هذه المقالة ، نتحدث عن الفروق الدقيقة التقنية التي تواجهها عند اختيار تقنية لتخزين تخزين البيانات المنظمة.
عندما تكون الخدمة غير متاحة للمستخدمين لبعض الوقت ، فهي غير سارة إلى حد كبير ، ولكنها لا تزال غير قاتلة. لكن فقدان بيانات العميل أمر غير مقبول على الإطلاق. لذلك ، نحن نقيم بدقة أي تقنية لتخزين البيانات من خلال اثنين إلى ثلاثة عشر معلمة.
البعض منهم تملي الحمل الحالي على الخدمة.
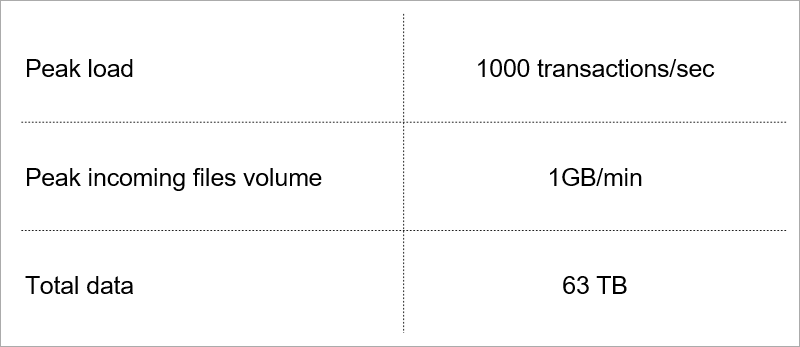 الحمل الحالي. نختار التكنولوجيا مع الأخذ في الاعتبار نمو هذه المؤشرات.
الحمل الحالي. نختار التكنولوجيا مع الأخذ في الاعتبار نمو هذه المؤشرات.بنية خادم العميل
نموذج خادم العميل الكلاسيكي هو أبسط مثال على النظام الموزع. الخادم هو نقطة التزامن ؛ فهو يتيح للعديد من العملاء القيام بشيء معًا بطريقة منسقة.
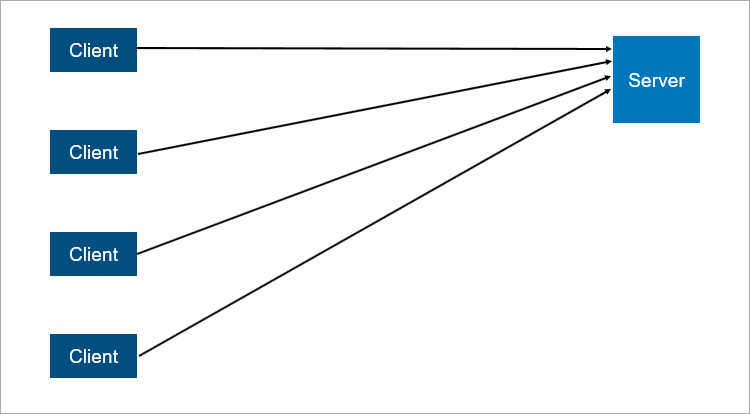 مخطط مبسط للغاية للتفاعل بين العميل والخادم.
مخطط مبسط للغاية للتفاعل بين العميل والخادم.ما هو غير موثوق به في بنية خادم العميل؟ من الواضح ، قد يتعطل الخادم. وعندما يتعطل الخادم ، لا يمكن لجميع العملاء العمل. لتجنب هذا الأمر ، توصل الناس إلى اتصال بين السيد والعبد (والذي أصبح الآن
صحيحًا من الناحية السياسية يسمى زعيم الأتباع ). خلاصة القول هي أن هناك خادمين ، يتواصل جميع العملاء مع الخادم الرئيسي ، وفي الثانية يتم نسخ جميع البيانات ببساطة.
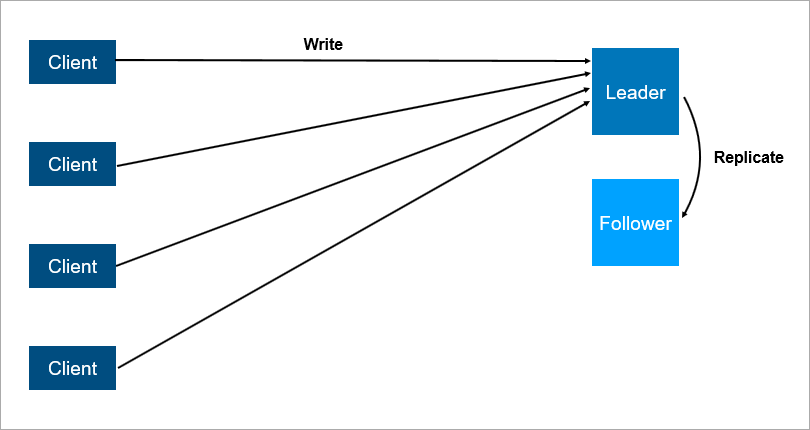 بنية خادم العميل مع تكرار البيانات للمتابعين.
بنية خادم العميل مع تكرار البيانات للمتابعين.من الواضح أن هذا النظام أكثر موثوقية: إذا تعطل الخادم الرئيسي ، فستكون نسخة من جميع البيانات في المتابع ويمكن رفعها بسرعة.
من المهم فهم كيفية عمل النسخ المتماثل. إذا كانت متزامنة ، فيجب أن يتم تخزين المعاملة في وقت واحد على القائد وعلى التابع ، وقد يكون ذلك بطيئًا. إذا كانت النسخ المتماثل غير متزامن ، فيمكنك فقد بعض البيانات بعد الفشل.
وماذا سيحدث إذا سقط القائد ليلا عندما ينام الجميع؟ توجد بيانات على التابع ، لكن لم يخبره أحد أنه الآن قائد ، ولا يتصل به العملاء. حسنًا ، دعنا نمنح التابع بمنطق أنه يبدأ في اعتبار نفسه الشيء الرئيسي عندما يتم فقد الاتصال بالزعيم. ثم يمكننا بسهولة الحصول على دماغ منقسم - صراع عندما ينقطع الاتصال بين القائد والتابع ، ويعتقد كلاهما أنهما الرئيسان. يحدث هذا بالفعل على العديد من الأنظمة ،
مثل RabbitMQ ، تقنية الطوابير الأكثر شعبية اليوم.
لحل هذه المشكلات ، قم بتنظيم تجاوز الفشل التلقائي - أضف خادمًا ثالثًا (شاهد ، شاهد). إنه يضمن أن لدينا قائد واحد فقط. وإذا سقط القائد ، فإن المتابع يعمل تلقائيًا بأقل فترة توقف ، والتي يمكن تخفيضها إلى بضع ثوانٍ. بالطبع ، يجب أن يعرف العملاء في هذا المخطط مقدمًا عناوين القائد والتابعي وأن يقوموا بتنفيذ منطق إعادة الاتصال التلقائي بينهم.
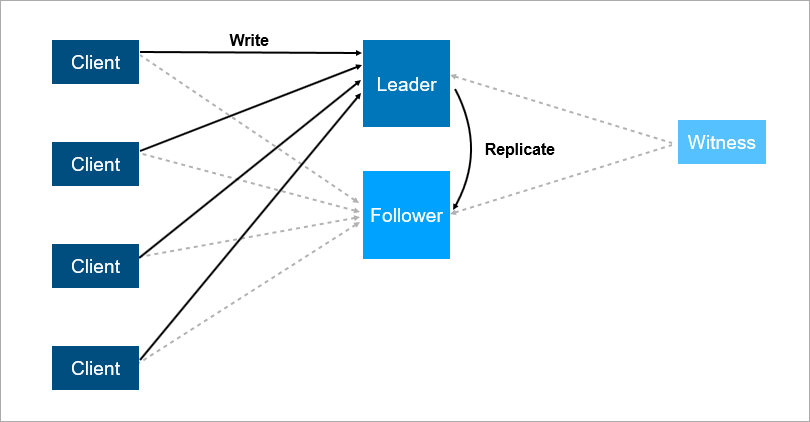 يضمن الشاهد وجود قائد واحد فقط. إذا سقط الزعيم ، فسيتم تشغيل التابع تلقائيًا.
يضمن الشاهد وجود قائد واحد فقط. إذا سقط الزعيم ، فسيتم تشغيل التابع تلقائيًا.مثل هذا النظام يعمل الآن معنا. هناك قاعدة بيانات رئيسية ، وقاعدة بيانات احتياطية ، وهناك شاهد ونعم - في بعض الأحيان نأتي في الصباح ونرى أن التبديل حدث في الليل.
ولكن هذا المخطط له أيضا عيوب. تخيل أنك تقوم بتثبيت حزم الخدمات أو تحديث نظام التشغيل على خادم رائد. قبل ذلك ، قمت بتبديل الحمل يدويًا على المتابعين ثم ... إنه يقع! كارثة ، خدمتك غير متوفرة. ما يجب القيام به لحماية نفسك من هذا؟ إضافة خادم النسخ الاحتياطي الثالث - متابع آخر. ثلاثة هو نوع من الرقم السحري. إذا كنت ترغب في أن يعمل النظام بشكل موثوق ، فإن خادمين لا يكفيان ، فأنت تحتاج إلى ثلاثة. واحد للصيانة ، والثاني يقع ، يبقى الثالث.
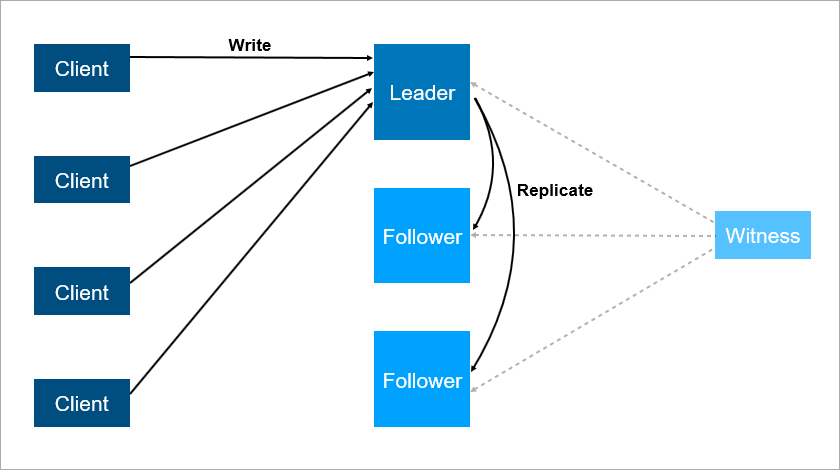 يوفر الخادم الثالث عملية موثوقة في حالة عدم توفر الأولين.
يوفر الخادم الثالث عملية موثوقة في حالة عدم توفر الأولين.لتلخيص ، يجب أن يكون التكرار مساويا لاثنين. وفرة واحدة ليست كافية. لهذا السبب ، في صفائف القرص ، بدأ الناس في استخدام نظام RAID6 بدلاً من RAID5 ، حيث نجوا من سقوط قرصين في وقت واحد.
المعاملات
هناك أربعة متطلبات أساسية للمعاملات معروفة جيدًا: الذرية ، والاتساق ، والعزلة ، والمتانة (الذرية ، الاتساق ، العزلة ، المتانة - حمض المعدة).
عندما نتحدث عن قواعد البيانات الموزعة ، فإننا نعني أنه يجب تغيير حجم البيانات. قراءة المقاييس جيدًا - يمكن لآلاف المعاملات قراءة البيانات بشكل متوازٍ دون أي مشاكل. ولكن عندما تكتب المعاملات الأخرى البيانات في نفس الوقت الذي تتم فيه القراءة ، تكون الآثار غير المرغوب فيها متنوعة ممكنة. من السهل جدًا الحصول على موقف حيث تقوم إحدى المعاملات بقراءة قيم مختلفة لنفس السجلات. وهنا بعض الأمثلة.
يقرأ القذرة. في المعاملة الأولى ، نرسل الطلب نفسه مرتين: خذ جميع المستخدمين المعرف = 1. إذا غيرت المعاملة الثانية هذا السطر ثم تراجعت ، فلن ترى قاعدة البيانات أي تغييرات من ناحية ، ولكن من ناحية أخرى ستقوم المعاملة الأولى بقراءة قيم عمرية مختلفة لـ Joe.
 قراءة غير قابلة للتكرار.
قراءة غير قابلة للتكرار. حالة أخرى هي إذا تم إكمال معاملة الكتابة بنجاح ، وتلقى معاملة القراءة بيانات مختلفة أثناء تنفيذ الطلب نفسه.

في الحالة الأولى ، يقرأ العميل البيانات التي كانت غائبة عمومًا في قاعدة البيانات. في الحالة الثانية ، يقوم العميل في كل مرة بقراءة البيانات من قاعدة البيانات ، لكنهما مختلفان ، على الرغم من أن القراءة تحدث في نفس المعاملة.
تقرأ Phantom عندما نعيد قراءة نطاق في نفس المعاملة ونحصل على مجموعة مختلفة من الخطوط. في مكان ما في الوسط ، تم إدخال معاملة أخرى وإدخالها أو حذفها.

لتجنب هذه الآثار غير المرغوب فيها ، تقوم أنظمة إدارة قواعد البيانات (DBMS) الحديثة بتطبيق آليات القفل (المعاملة تقيد الوصول إلى البيانات التي تعمل معها حاليًا لمعاملات أخرى) أو التحكم في إصدار التحويل المتعدد ،
MVCC (المعاملة لا تغير أبدًا البيانات المسجلة سابقًا وتقوم دائمًا بإنشاء إصدار جديد).
يحدد معيار ANSI / ISO SQL 4 مستويات للعزل للمعاملات التي تؤثر على درجة الحجب المتبادل. كلما ارتفع مستوى العزل ، كانت التأثيرات غير المرغوب فيها أقل. ثمن ذلك هو إبطاء التطبيق (نظرًا لأن المعاملات تنتظر في أغلب الأحيان لإلغاء تأمين البيانات التي تحتاجها) وزيادة احتمال حدوث حالة توقف تام.
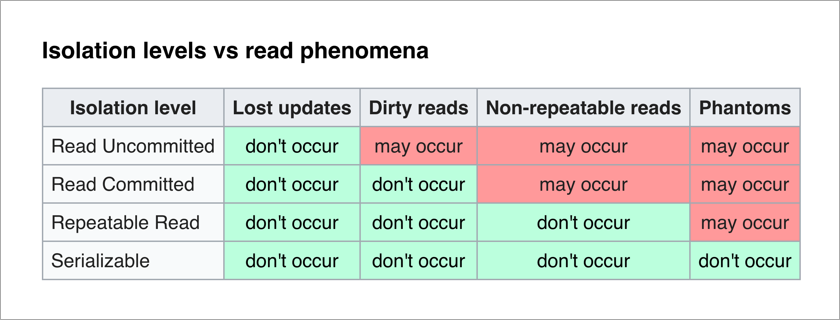
الأكثر متعة لمبرمج التطبيق هو المستوى المتسلسل - لا توجد أي آثار غير مرغوب فيها ويتم نقل التعقيد الكامل لضمان سلامة البيانات إلى قواعد البيانات.
دعونا نفكر في التطبيق الساذج لمستوى Serializable - مع كل معاملة ، نحن فقط نمنع أي شخص آخر. من الناحية النظرية ، يمكن إجراء كل معاملة للكتابة في 50 µs (وقت عملية الكتابة الواحدة على أقراص SSD الحديثة). ونحن نريد حفظ البيانات إلى ثلاث آلات ، تذكر؟ إذا كانوا في مركز البيانات نفسه ، فسيستغرق التسجيل من 1-3 دقائق. وإذا كانت ، من أجل الموثوقية ، موجودة في مدن مختلفة ، فيمكن أن يستغرق التسجيل من 10 إلى 12 مللي ثانية (وقت السفر لحزمة شبكة من موسكو إلى سان بطرسبرج والعكس). وهذا هو ، مع تطبيق ساذج للمستوى التسلسلي بالتسجيل المتسلسل ، لا يمكننا إجراء أكثر من 100 معاملة في الثانية. بينما يسمح لك SSD منفصل بإجراء حوالي 20،000 عملية كتابة في الثانية الواحدة!
الخلاصة: يجب تنفيذ معاملات الكتابة بالتوازي ، ولتوسيع نطاقها ، فأنت بحاجة إلى آلية جيدة لحل النزاعات.
تقاسم
ماذا تفعل عندما تتوقف البيانات عن الحصول على خادم واحد؟ هناك نوعان من آليات التكبير القياسية:
- تستقيم عندما نضيف فقط الذاكرة والأقراص إلى هذا الخادم. هذا له حدوده - من حيث عدد النوى لكل معالج ، وعدد المعالجات ، ومقدار الذاكرة.
- أفقي ، عندما نستخدم العديد من الأجهزة وتوزيع البيانات بينها. مجموعات من هذه الآلات تسمى مجموعات. لوضع البيانات في كتلة ، يجب أن تكون مشتركة - أي لكل سجل ، تحديد الخادم الذي سيكون عليه.
مفتاح المشاركة هو معلمة يتم من خلالها توزيع البيانات بين الخوادم ، على سبيل المثال ، معرف العميل أو المؤسسة.
تخيل أنك تحتاج إلى تسجيل بيانات حول جميع سكان الأرض في كتلة. كمفتاح للشر ، يمكنك أن تأخذ ، على سبيل المثال ، سنة ميلاد الشخص. بعد ذلك سيكون عدد الخوادم 116 كافيًا (وكل عام سيكون من الضروري إضافة خادم جديد). أو يمكنك أن تأخذ مفتاح البلد الذي يعيش فيه الشخص ، فستحتاج إلى حوالي 250 خادم. ومع ذلك ، فإن الخيار الأول هو الأفضل ، لأن تاريخ ميلاد الشخص لا يتغير ، ولن تحتاج أبدًا إلى نقل البيانات عنه بين الخوادم.
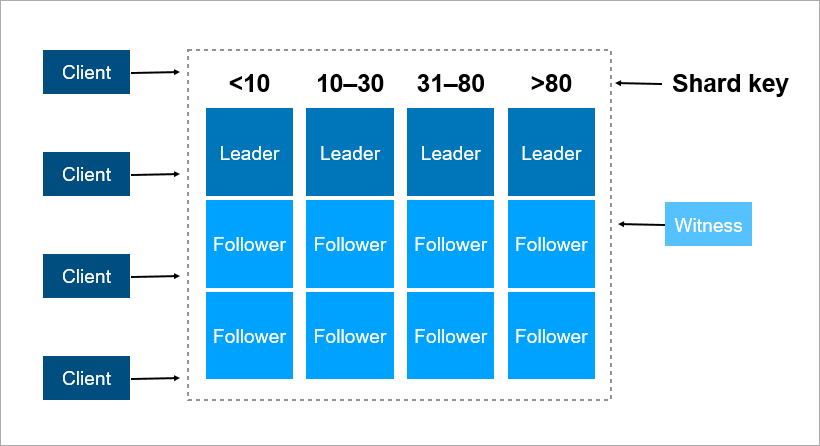
في Pyrus ، يمكنك أن تأخذ مؤسسة كمفتاح مشاركة. لكنهم مختلفون في الحجم: يوجد بنك سوفكوم ضخم (أكثر من 15 ألف مستخدم) وآلاف الشركات الصغيرة. عندما تقوم بتعيين مؤسسة لخادم معين ، لا تعرف مقدمًا كيف ستنمو. إذا كانت المؤسسة كبيرة وتستخدم الخدمة بنشاط ، فسوف تتوقف بياناتها عاجلاً أو آجلاً على خادم واحد ، وسيتعين عليك إعادة المشاركة. وهذا ليس سهلا إذا كانت البيانات تيرابايت. تخيل: نظام محمّل ، تستمر المعاملات كل ثانية ، وفي هذه الظروف تحتاج إلى نقل البيانات من مكان إلى آخر. لا يمكنك إيقاف النظام ، حيث يمكن ضخ هذا الحجم لعدة ساعات ، ولن ينجو عملاء الأعمال من هذا التوقف الطويل.
كمفتاح مشاركة ، من الأفضل اختيار البيانات التي نادراً ما تتغير. ومع ذلك ، فإن المهمة المطبقة تجعل المهمة سهلة للغاية.
توافق في الكتلة
عندما يكون هناك الكثير من الأجهزة في المجموعة ويفقد بعضها الاتصال مع الآخرين ، فكيف تقرر من يخزن أحدث إصدار من البيانات؟ لا يكفي مجرد تعيين خادم شاهد لأنه قد يفقد الاتصال مع المجموعة بالكامل. بالإضافة إلى ذلك ، في حالة انقسام المخ ، يمكن للعديد من الأجهزة تسجيل إصدارات مختلفة من نفس البيانات - وتحتاج إلى تحديد ما هو الأكثر صلة. لحل هذه المشكلة ، توصل الناس إلى خوارزميات الإجماع. أنها تسمح عدة آلات متطابقة للتوصل إلى نتيجة واحدة في أي قضية عن طريق التصويت. في عام 1989 ، تم نشر أول خوارزمية من هذا النوع ،
Paxos ، وفي عام 2014 ، توصل فريق Stanford
men إلى مجموعة من
الطوافة أسهل في التنفيذ. بالمعنى الدقيق للكلمة ، حتى تتمكن مجموعة من الخوادم (2N + 1) من الوصول إلى توافق ، يكفي أن لا تزيد في الوقت نفسه عن فشل N. للبقاء على قيد الحياة 2 فشل ، يجب أن يكون الكتلة 5 خوادم على الأقل.
التحجيم DBMS العلائقية
معظم قواعد البيانات التي تستخدم للمطورين للعمل مع دعم الجبر العلائقية. يتم تخزين البيانات في الجداول وفي بعض الأحيان تحتاج إلى ربط البيانات من جداول مختلفة باستخدام عملية JOIN. النظر في قاعدة بيانات المثال واستعلام بسيط على ذلك.
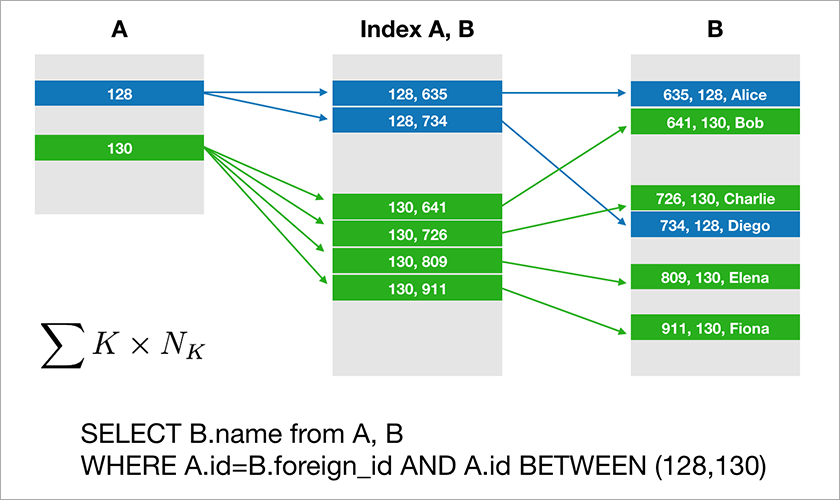
تفترض A.id هو مفتاح أساسي مع فهرس متفاوت المسافات. ثم يقوم المُحسِّن ببناء خطة ستحدد أولاً على الأرجح السجلات اللازمة من الجدول "أ" ثم تأخذ الروابط المناسبة إلى السجلات في الجدول "ب" من فهرس مناسب (أ ، ب) .زمن تنفيذ هذا الاستعلام لوغاريتمياً من عدد السجلات في الجداول.
تخيل الآن أن البيانات موزعة عبر أربعة خوادم في المجموعة وتحتاج إلى تنفيذ نفس الاستعلام:
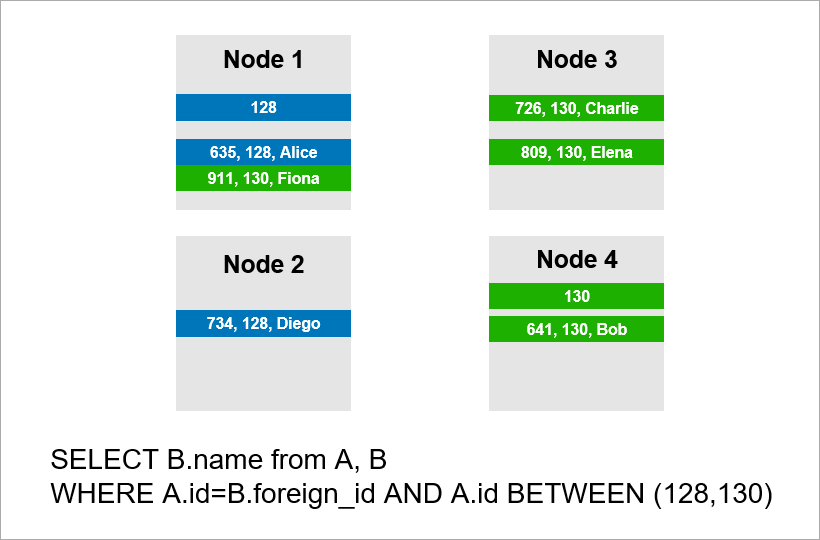
إذا كان DBMS لا يريد عرض جميع سجلات المجموعة بالكامل ، فمن المحتمل أن يحاول البحث عن سجلات ذات قيمة A.id تساوي 128 أو 129 أو 130 والعثور على السجلات المناسبة لها من الجدول ب. لا يمكن معرفة أي خادم يتم تشغيل بيانات الجدول A ، وسيتعين علي الاتصال بجميع الخوادم على أي حال لمعرفة ما إذا كانت هناك سجلات A.id مناسبة لحالتنا. ثم يمكن لكل خادم إنشاء JOIN داخل نفسه ، لكن هذا لا يكفي. ترى ، نحن بحاجة إلى السجل على العقدة 2 في العينة ، ولكن لا يوجد سجل مع A.id = 128؟ إذا كانت العقدتان 1 و 2 ستعملان JOIN بشكل مستقل ، فستكون نتيجة الاستعلام غير مكتملة - لن نتلقى جزءًا من البيانات.
لذلك ، لتلبية هذا الطلب ، يجب أن ينتقل كل خادم إلى أي شخص آخر. وقت التشغيل ينمو من الدرجة الثانية مع عدد الخوادم. (أنت محظوظ إذا تمكنت من مشاركة جميع الجداول باستخدام نفس المفتاح ، فلن تحتاج إلى التنقل بين جميع الخوادم. ومع ذلك ، من الناحية العملية هذا غير واقعي - سيكون هناك دائمًا استعلامات حيث لا يكون الجلب قائمًا على مفتاح shard.)
وبالتالي ، فإن عمليات JOIN تنقسم بشكل سيئ بشكل أساسي وهذه مشكلة أساسية في النهج العلائقي.
نهج NoSQL
أدت صعوبات توسيع نطاق نظم إدارة قواعد البيانات الكلاسيكية (DBMS) الكلاسيكية للناس إلى الخروج بقواعد بيانات NoSQL التي لا تحتوي على عمليات JOIN. لا ينضم - لا مشكلة. ولكن لا توجد خصائص ACID ، لكنهم لم يذكروا ذلك في المواد التسويقية.
العثور على الحرفيين بسرعة الذين يختبرون قوة النظم الموزعة المختلفة ونشر
النتائج علنا . اتضح أن هناك سيناريوهات عندما
تفقد كتلة Redis 45 ٪ من البيانات المخزنة ، كتلة RabbitMQ - 35 ٪ من الرسائل ،
MongoDB - 9 ٪ من السجلات ،
كاساندرا - ما يصل إلى 5 ٪ . ونحن نتحدث
عن الخسارة بعد أن أبلغت المجموعة العميل عن الحفظ الناجح. عادة ما تتوقع مستوى أعلى من الموثوقية من التكنولوجيا المختارة.
طورت Google قاعدة بيانات
Spanner ، التي تعمل على مستوى العالم. Spanner يضمن خصائص ACID ، التسلسل وأكثر من ذلك. لديهم ساعات ذرية في مراكز البيانات التي توفر وقتًا دقيقًا ، ويتيح لك ذلك إنشاء ترتيب عالمي للمعاملات دون الحاجة إلى إعادة توجيه حزم الشبكة بين القارات. فكرة Spanner هي أنه من الأفضل للمبرمجين التعامل مع مشاكل الأداء التي تنشأ مع عدد كبير من المعاملات من العكازات حول نقص المعاملات. ومع ذلك ، فإن Spanner هي تقنية مغلقة ، ولا تناسبك إذا كنت لا ترغب في الاعتماد على مورد واحد لسبب ما.
طوّر مواطنو Google تناظرية مفتوحة المصدر لـ Spanner وسموها CockroachDB ("cockroach" باللغة الإنجليزية "cockroach" ، والتي يجب أن ترمز إلى بقاء قاعدة البيانات). على هابري
كتب بالفعل عن عدم توفر المنتج للإنتاج ، لأن الكتلة كانت تفقد البيانات. قررنا التحقق من الإصدار الأحدث 2.0 ، وتوصلنا إلى نتيجة مماثلة. لم نفقد البيانات ، لكن بعضًا من أبسط الاستعلامات تم تنفيذها لفترة غير معقولة.
نتيجة لذلك ، توجد اليوم قواعد بيانات علائقية تتوسع بشكل عمودي فقط ، وهي مكلفة. وهناك حلول NoSQL بدون معاملات وبدون ضمانات ACID (إذا كنت تريد ACID ، فاكتب العكازات).
كيفية إنشاء تطبيقات مهمة للمهام لا تتناسب فيها البيانات مع خادم واحد؟ تظهر حلول جديدة في السوق ، وعن أحدها -
FoundationDB - سنخبرك أكثر في المقالة التالية.