
مرحبا يا هبر! اسمي Stanislav Semenov ، أعمل على تقنيات لاستخراج البيانات من الوثائق في R&D ABBYY. سأتحدث في هذه المقالة عن الأساليب الأساسية لمعالجة المستندات شبه المهيكلة (الفواتير والإيصالات النقدية وما إلى ذلك) التي استخدمناها مؤخرًا والتي نستخدمها الآن. وسوف نتحدث عن كيفية تطبيق أساليب التعلم الآلي لحل هذه المشكلة.
سننظر في الفواتير باعتبارها وثائق ، لأن في العالم ، فهي منتشرة للغاية وأكثر طلبًا من حيث استخراج البيانات. بالمناسبة ، تعد المعالجة التلقائية للفواتير أحد السيناريوهات الأكثر شيوعًا بين عملائنا الأجانب. على سبيل المثال ، بمساعدة ABBYY FlexiCapture ، قللت American PepsiCo Imaging Technology
من الوقت اللازم لمعالجة الفواتير وعدد الأخطاء الناجمة عن الإدخال اليدوي ،
وبدأت شركة التجزئة الأوروبية Sportina
بإدخال البيانات من الحسابات في أنظمة المحاسبة
بشكل أسرع مرتين .
الفواتير هي المستندات المستخدمة في الممارسات التجارية الدولية والتي لها أهمية كبيرة بالنسبة للأعمال التجارية. شيء مشابه لفاتورة في روسيا ، على سبيل المثال ، بوليصة الشحن. البيانات من هذه الوثائق تقع في أنظمة محاسبة مختلفة ، والأخطاء هناك ، بعبارة ملطفة ، غير مرحب بها.
يمكن اعتبار الفاتورة العادية منظمة تمامًا ؛ فهي تحتوي على فئتين رئيسيتين من الكائنات:
- حقول متنوعة من الرأس (رقم المستند ، التاريخ ، المرسل ، المستلم ، الإجمالي ، إلخ) ،
- البيانات المجدولة هي قائمة بالسلع والخدمات (الكمية والسعر والوصف وما إلى ذلك).
هذا ما يبدو عليه:
يتم إنفاق الملايين من ساعات العمل سنويًا على معالجة الفواتير. وهي مكلفة للغاية. وفقًا لتقديرات مختلفة ، تتكلف معالجة فاتورة ورقية واحدة لشركة ما من 10 دولارات إلى 40 دولارًا ، حيث يكون جزء كبير من هذه التكاليف هو العمل اليدوي لإدخال البيانات وتسويتها.
هناك شركات تعالج ملايين الفواتير شهريًا. للقيام بذلك ، تحتوي على مجموعة كاملة من المئات ، وأحيانًا الآلاف من الأشخاص. من السهل تقدير أن زيادة دقة الاعتراف أو كفاءة استخراج البيانات بنسبة 1٪ فقط يمكن أن تقلل من تكاليف الشركات الكبيرة بمئات الآلاف وحتى ملايين الدولارات سنويًا.
من ناحية أخرى ، هناك كمية كارثية من الوثائق. في عام 2017 ،
قدرت شركة Billentis إجمالي عدد الفواتير / الفواتير المتولدة سنويًا في العالم بنحو 400 مليار. من بين هؤلاء ، كان حوالي 10٪ فقط إلكترونيًا ، والباقي يحتاج إلى إدخال يدوي كامل أو مشاركة بشرية مكثفة. إذا قمت بطباعة 400 مليار مستند على ورق A4 قياسي ، فستكون آلاف شاحنات الورق يوميًا ، أو كومة من الورق حول ارتفاع بشري كل ثانية!
بضع كلمات حول كيفية تطور التكنولوجيا

تقوم العديد من الشركات بتطوير برامج متخصصة يمكنها التعرف على المستندات واستخراج البيانات منها. لكن جودة معالجة الفاتورة لا تزال غير كاملة. "ما هي المشكلة؟" - أنت تسأل.
الأمر كله يتعلق بمجموعة كبيرة من الفواتير. لا توجد معايير للفواتير ، ولكل شركة حرية إنشاء نسختها الخاصة من المستند: نوع وهيكل الحقول وموقعها.
البحث عن الحقول حسب الكلمات الرئيسية
ظهرت المحاولات الأولى لاستخراج البيانات للعثور على كلمات أساسية خاصة بين جميع الكلمات المعترف بها ، مثل ، على سبيل المثال ، رقم الفاتورة أو الإجمالي ، ثم ، في حي صغير من هذه الكلمات ، على سبيل المثال ، إلى اليمين أو الأسفل ، للعثور على المعاني نفسها.
موقع رقم الفاتورة في فواتير مختلفة (قابلة للنقر):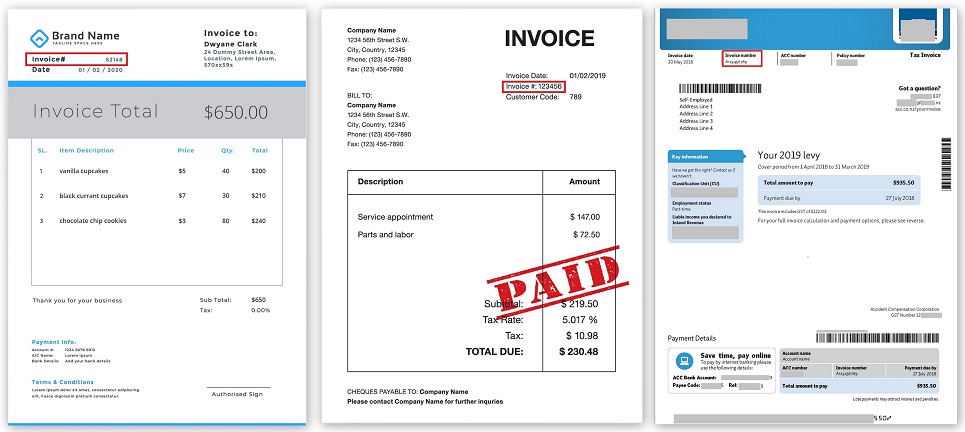
تمت برمجة المنطق برمته ، وأن هناك مثل هذه الحقول وكذا ، فهي موجودة في مكان كذا وكذا من المستند ، حولها هناك حقول أخرى على بعض المسافات. وقد نجح هذا بطريقة ما حتى ظهرت شركة أخرى ، والتي بدأت في إرسال مستنداتها في شكل مختلف تمامًا. أو الشركة السابقة غيرت فجأة التنسيق ، وتوقف كل شيء عن العمل.
أنماط
إن قتال هذا ، في كل مرة يعيد فيها برمجة شيء ما ، كان غير منطقي. لذلك ، جاء نموذج جديد لإنقاذ - استخدام القوالب.
القالب عبارة عن مجموعة من الحقول التي يجب العثور عليها في مستند ومجموعة من القواعد حول كيفية العثور على هذه الحقول. الميزة الرئيسية هنا هي أن يتم إنشاء القوالب بصريا. على سبيل المثال ، نريد البحث عن رقم الفاتورة وإجمالي ، وحدد هذه الحقول وتكوين المعلمات التي تأتي مثل هذا الحقل ومثل هذه الكلمة فورًا ومثل هذه الكلمة الأساسية ، وتقع في الجزء العلوي من المستند وتحتوي على أرقام وعلامات الترقيم.
تم تطوير أدوات متخصصة ، تسمى برامج تحرير النماذج ، حيث يمكن للمستخدمين المتقدمين بالفعل دون مساعدة المبرمجين تعيين نوع من المنطق بسرعة يدويًا. بمجرد وصول مستند من نموذج جديد ، تم إنشاء قالب له وبدأ كل شيء في العمل أكثر أو أقل.
نموذج القالب (قابل للنقر):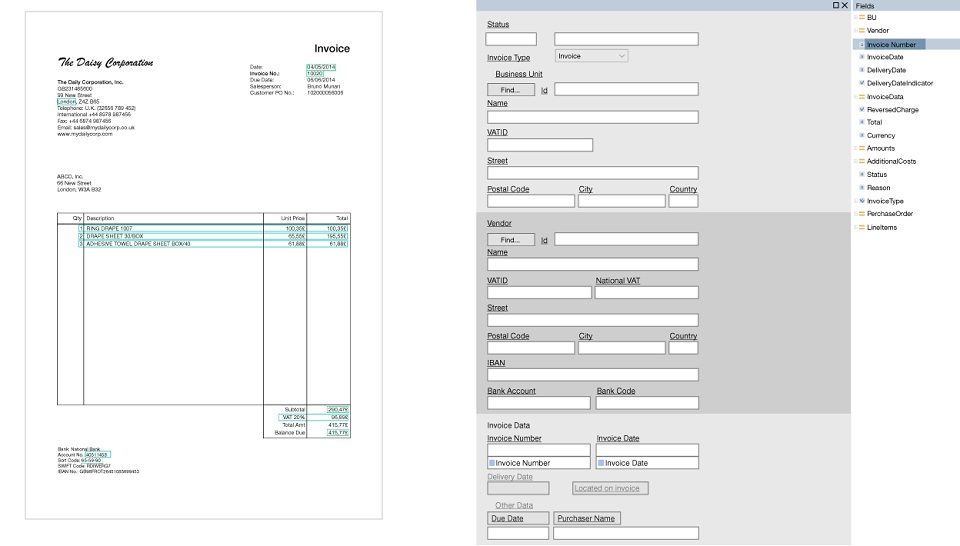
ولكن لجعل قالب واحد لا يكفي ، فإنها تحتاج إلى المئات وحتى الآلاف. وبالتالي ، قد يستغرق إعداد منتج لكل عميل أحيانًا الكثير من الوقت. من المستحيل إنشاء قوالب "عالمية" مسبقًا ، والتي سوف تغطي مجموعة متنوعة كاملة من الفواتير.
باستخدام القوالب ، يمكنك تحسين جودة استرداد الجدول بشكل ملحوظ. ولكن غالبًا ما يتم العثور على هياكل الجداول المعقدة ، مع تمثيل غير قياسي للبيانات ، ومستويات تداخل متعددة ، والقوالب في هذه الحالات لا تعمل دائمًا بشكل جيد. لذا ، مرة أخرى ، يجب عليك كتابة بعض البرامج النصية التي تحتوي على العديد من المعلمات والشروط والاستثناءات المحددة يدويًا ، إلخ.
باستخدام التعلم الآلي
التكنولوجيا اليوم لا تزال قائمة ، ومع تطور التعلم الآلي ، أصبح من الممكن نقل مهمة استخراج البيانات من الوثائق إلى الشبكات العصبية.
اليوم ، هناك العديد من الأساليب الأساسية المستخدمة في الممارسة:
- الطريقة الأولى هي العمل مباشرة مع صورة إدخال المستند. أي ، يتم تغذية صورة (صورة) أو جزء إلى إدخال الشبكة ، وتتعلم الشبكة العثور على مساحات صغيرة حيث توجد الحقول اللازمة ، ومن ثم يتم التعرف على النص في هذه المناطق باستخدام تقنيات التعرف الضوئي على الحروف (OCR) الكلاسيكية. هذا هو الحل الشامل الذي يمكن تنفيذه بسرعة. يمكنك أن تأخذ شبكة جاهزة للبحث عن كائنات في الصور ، على سبيل المثال ، YOLO أو Faster R-CNN وتدريبها على صور محددة للوثائق.
عيب هذا النهج ليس أفضل جودة للبيانات المستخرجة وصعوبة استخراج الجداول. في الواقع ، هذا النهج يشبه إلى حد ما مهمة العثور على الكلمات الصحيحة في الصورة (اكتشاف الكلمات) ، وهي مشكلة أساسية من مجال رؤية الكمبيوتر ، لكننا هنا لا نبحث عن الكلمات ، ولكن عن الحقول الضرورية. - الطريقة الثانية هي معالجة النص المستخرج من المستند. يمكن أن يكون هذا إما نصًا من PDF أو مستند OCR كامل الصفحة. يستخدم تقنية معالجة اللغة الطبيعية (NLP) . يتم تجميع الخطوط من كلمات فردية ، ويتم تشكيل أجزاء مختلفة من النص أو الفقرات أو الأعمدة من خطوط ، وفيها تتعلم الشبكة بالفعل التمييز بين مختلف الكيانات المسماة NER (Named-Entity Recognition).
طرق مختلفة لتشكيل شظايا النص ممكنة. يمكنك الجمع بين الأسلوبين الأول والثاني ، وتدريب شبكة واحدة للعثور على كتل كبيرة بمعلومات معينة في الصور ، على سبيل المثال ، بيانات حول المرسل أو بيانات حول المستلم ، والتي تحتوي على الاسم والعنوان والتفاصيل وما إلى ذلك على الفور ، ثم نقل نص كل كتلة من هذه المجموعات. إلى الشبكة NER الثانية.
قد تكون جودة هذا النهج أعلى مما كانت عليه في النهج الأول فقط ، ولكن يصعب بناء نموذج فعال. اليوم ، هناك نماذج متقدمة جدًا ، على سبيل المثال ، LSTM-CRF لـ NER ، والتي يمكنها تمييز الكلمات في النص وتحديد الكيانات. - الطريقة الثالثة هي بناء تمثيل دلالي للوثيقة دون الرجوع إلى نوع المستند ، أي عندما لا نعرف ما هو المستند أمامنا ، لكننا نحاول فهمه أثناء المعالجة. مجموعة من كلمات الوثيقة ذات سماتها المختلفة (على سبيل المثال ، هل تحتوي الكلمة على أحرف فقط أم أنها رقم) ، ويتم ترتيب الترتيب الهندسي للكلمات (الإحداثيات ، والمسافات البادئة) ومع المحددات المختلفة والاتصالات التي تم تحديدها أثناء تحليل الصور ، في إدخال الشبكة ويتم الحصول على الإخراج من أجل كل كلمة لها مجموعة محددة من الخصائص. بناءً على الخصائص التي تم الحصول عليها ، يتم تشكيل مجموعات مختلفة من فرضيات الحقول أو الجداول المحتملة ، والتي يتم فرزها وتقييمها بواسطة مصنف إضافي. ثم يتم تحديد الفرضية الأكثر موثوقية للهيكل ومحتوى المستند.
هذا بالفعل أصعب الحلول ، ولكن يمكنك حل مشكلة استخراج البيانات من المستندات بطريقة عامة.
كيف نستخدم الشبكات العصبية
نحن في ABBYY لا نراقب عن كثب إنجازات العلم والتكنولوجيا فحسب ، بل نبتكر أيضًا تقنياتنا المتقدمة ونطبقها في مختلف المنتجات.
يوضح الشكل أدناه البنية العامة لحلنا باستخدام الشبكات العصبية.
صورة قابلة للنقر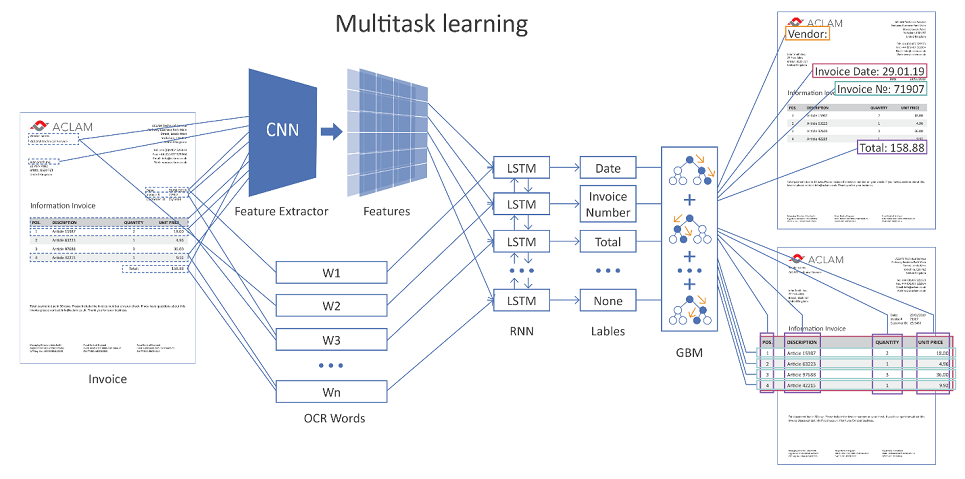
يتم تغذية صفحة المستند بأكملها بإدخال الشبكة. باستخدام الطبقات التلافيفية (CNN) ، يتم تشكيل العديد من الميزات الهندسية ، على سبيل المثال ، الموضع النسبي للكلمات بالنسبة لبعضها البعض. علاوة على ذلك ، يتم الجمع بين هذه العلامات مع التمثيل المتجه للكلمات المعترف بها (زخارف الكلمات) ويتم تقديمها على طبقات متكررة (LSTM) وطبقة متصلة بالكامل. هناك العديد من طبقات الإخراج المختلفة (التعلم متعدد المهام) ، كل حل يحل مشكلته الخاصة:
- تحديد نوع المجال الذي يمكن للكلمة أن تتوافق معه ،
- فرضيات حدود الجدول ،
- فرضيات صفوف الجدول ، حدود الأعمدة ، إلخ.
إذا كان المستند متعدد الصفحات ، فستقوم الشبكة بتوقع كل صفحة على حدة ، ثم يتم دمج النتائج.
بعد ذلك ، تتشكل الفرضيات من الترتيب المحتمل للحقول والجداول ، بمساعدة وظيفة انحدار مدربة بشكل منفصل ، ويتم تقييمها ، وتفوز الفرضية الأكثر ثقة.
من أجل زيادة دقة استخراج البيانات ، بالإضافة إلى فصل المستندات حسب النوع (الاختيار ، الفاتورة ، العقد ، وما إلى ذلك) ، يحدث تجميع إضافي داخل نوعه وفقًا لخصائص إضافية.
على سبيل المثال ، بالنسبة للفواتير ، يمكن أن يكون بائعًا أو مجرد مظهر (وفقًا لدرجة التشابه في موقع الحقول). وبعد ذلك ، وفقًا لمجموعة معينة (نظام مجموعة) ، يتم تطبيق إعدادات خوارزمية محددة. من الناحية الفنية ، مع وجود أمثلة على الفواتير التي تم وضع علامة عليها بشكل صحيح لمجموعات مختلفة ، من الممكن من جانب المستخدم إعادة تدريب آليات تقييم الفرضيات الصحيحة واختيارها.
لتكوين جميع أنواع المعلمات من خوارزمياتنا والشبكات العصبية ، نستخدم طريقة التطور التفاضلي ، والتي أثبتت نفسها بشكل جيد للغاية في الممارسة العملية.
لدينا نتائج التعلم آلة

- تُظهر الطريقة المتقدمة لاستخراج البيانات من المستندات المنظمة باستخدام التعلم الآلي في كثير من الحالات نتائج أفضل من الحلول المبرمجة القائمة على الاستدلال. يتراوح اكتساب الجودة في المقاييس المختلفة من عدة وحدات إلى عشرات في المئة على مختلف الكيانات القابلة للاستخراج.
- هناك ميزة لا يمكن إنكارها على النهج الكلاسيكي - القدرة على إعادة تدريب الشبكة على بيانات جديدة. في حالة وجود مجموعة متنوعة من أشكال المستندات ، هذه ليست مشكلة الآن ، ولكنها حاجة. أكثر منهم ، كلما كان ذلك أفضل ؛ كلما زادت قدرة الشبكة على التعميم وتحسين الجودة.
- كانت هناك فرصة لإطلاق ما يسمى الحل "خارج الصندوق" ، عندما يقوم المستخدم ببساطة بتثبيت المنتج (في الواقع ، شبكة مدربة) ، ويبدأ كل شيء على الفور العمل بنتيجة مقبولة. ليست هناك حاجة لبرمجة أي شيء ، وتخصيص قوالب طويلة ومؤلمة ، حدد جميع أنواع المعلمات.
التفاصيل المهمة التي أود ذكرها هي البيانات. لا يمكن أن يحدث التعلم الآلي بدون بيانات عالية الجودة. التعلم الآلي يعطي نتائج أفضل من هندسة المعرفة ، فقط إذا كان هناك كمية كافية من البيانات الموسومة. في حالة الفواتير ، فهذه هي عشرات الآلاف من المستندات المصنفة يدويًا ، وهذا الرقم في تزايد مستمر.
بالإضافة إلى ذلك ، نستخدم آليات زيادة البيانات المتقدمة ، ونغير أسماء المؤسسات والعناوين وقوائم السلع وأنواع الخدمات في الجداول والتواريخ والخصائص الكمية المختلفة ، مثل السعر والكمية والتكلفة ، إلخ. نقوم أيضًا بتغيير تسلسل الكيانات المختلفة في المستندات ، مما يسمح لنا في النهاية بإنشاء ملايين الوثائق المختلفة تمامًا للتدريب.
بدلا من الاستنتاج
في الختام ، يمكننا أن نقول إن البرمجة لم تختف بالطبع ، ولكنها تغير دورها تدريجياً. مع كل يوم جديد ، يبدأ التعلم الآلي في التعامل مع المهام المسندة إليه بشكل أفضل وأفضل في مجموعة متنوعة من الصناعات ، مزاحمة الأساليب التقليدية. الميزة التي لا يمكن إنكارها للتعلم الآلي في الكفاءة: إن عشرات من سنوات العمل الفكري تكلف الآن عشرات الساعات الآلية من التعلم. لذلك ، في المستقبل القريب ، نرى تطورًا أكبر وقابلية للتطبيق للشبكات في جميع تطوراتنا. وإذا كنت مهتمًا ، فنحن دائمًا منفتحون على الاقتراحات
والتعاون .