مرحباً هبر!
ربما فكر العديد من القراء والمؤلفين العاديين في دورة حياة المقالات المنشورة هنا. وعلى الرغم من حدسي هذا واضح أكثر أو أقل (من الواضح ، على سبيل المثال ، أن المقالة في الصفحة الأولى لديها الحد الأقصى لعدد المشاهدات) ، ولكن كم على وجه التحديد؟
لجمع الإحصاءات ، سوف نستخدم بيثون ، بانداس ، ماتبلوتليب و Raspberry Pi.
أولئك الذين يهتمون بما جاء منه ، من فضلك ، تحت القط.
جمع البيانات
أولاً ، دعونا نقرر المقاييس - ما نريد أن نعرفه. كل شيء بسيط هنا ، يحتوي كل مقالة على 4 معلمات رئيسية معروضة على الصفحة - هذا هو عدد مرات المشاهدة والإعجابات والإشارات المرجعية والتعليقات. سنقوم بتحليلها.
يمكن لأولئك الذين يرغبون في رؤية النتائج على الفور ، الانتقال إلى الجزء الثالث ، ولكن في الوقت الحالي سيكون الأمر يتعلق بالبرمجة.
الخطة العامة: سنقوم بتحليل البيانات اللازمة من صفحة الويب ، وحفظها باستخدام ملف CSV ، ومعرفة ما نحصل عليه لمدة عدة أيام. أولاً ، قم بتحميل نص المقالة (تم حذف الاستثناء من أجل الوضوح):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
نحتاج الآن إلى استخراج البيانات من سطر data_str (بالطبع ، بتنسيق HTML). افتح الكود المصدري في المتصفح (تمت إزالة العناصر غير المبدئية):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
من السهل أن نرى أن النص الذي نحتاجه موجود داخل الكتلة '<ul class = "post-stats post-stats_post js-user_>' ، وأن العناصر الضرورية في كتل تحتوي على أسماء تصويت - wjt__counter ، bookmark__counter ، post-stats__views-count و post- stats__comments-count. بالاسم ، كل شيء واضح تماما.
سنرث الطبقة str ونضيف إليها طريقة استخراج السلسلة الفرعية الموجودة بين العلامتين:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
يمكنك الاستغناء عن الميراث ، لكن هذا سيسمح لك بكتابة كود أكثر إيجازًا. مع ذلك ، يناسب كل استخراج البيانات في 4 خطوط:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
لكن هذا ليس كل شيء. كما ترون ، يمكن تخزين عدد التعليقات أو المشاهدات كسلسلة مثل "12.1k" ، والتي لا تترجم مباشرة إلى int.
أضف وظيفة لتحويل مثل هذه السلسلة إلى رقم:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
يبقى فقط لإضافة الطابع الزمني ، ويمكنك حفظ البيانات في ملف CSV:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
نظرًا لأننا مهتمون بتحليل العديد من المقالات ، فإننا نضيف القدرة على تحديد رابط من خلال سطر الأوامر. سنقوم أيضًا بإنشاء اسم ملف السجل بمعرف المقالة:
link = sys.argv[1]
والخطوة الأخيرة جدا. نحن نخرج الشفرة في الوظيفة ، في الحلقة التي نقوم باستطلاع البيانات بها ، ونكتب النتائج في السجل.
delay_s = 5*60 while True:
كما ترى ، تم تحديث البيانات كل 5 دقائق حتى لا يتم إنشاء حمل على الخادم. قمت بحفظ ملف البرنامج تحت اسم habr_parse.py ، عند بدء تشغيله ، سيتم حفظ البيانات حتى يتم إغلاق البرنامج.
علاوة على ذلك ، يُنصح بحفظ البيانات ، على الأقل لبضعة أيام. بسبب نحن مترددون في إبقاء الكمبيوتر قيد التشغيل لعدة أيام ، فنحن نأخذ Raspberry Pi - سيكون لديه طاقة كافية لمثل هذه المهمة ، وعلى عكس الكمبيوتر الشخصي ، فإن Raspberry Pi لا يصدر ضوضاء ولا يستهلك كهرباءًا تقريبًا. نذهب إلى SSH ونشغل نصنا:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
يترك الأمر nohup البرنامج النصي في الخلفية بعد إغلاق وحدة التحكم.
على سبيل المكافأة ، يمكنك تشغيل خادم http في الخلفية عن طريق إدخال الأمر "nuhup python -m SimpleHTTPServer 8000 &". سيتيح لك ذلك مشاهدة النتائج مباشرة في المتصفح في أي وقت ، وفتح رابط النموذج
http://192.168.1.101:8000 (قد يكون العنوان مختلفًا بالطبع).
يمكنك الآن تشغيل Raspberry Pi والعودة إلى المشروع في غضون أيام قليلة.
تحليل البيانات
إذا كان كل شيء قد تم بشكل صحيح ، فيجب أن يكون الإخراج مثل هذا السجل:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
دعونا نرى كيف يمكن معالجتها. للبدء ، قم بتحميل csv في dataframe الباندا:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
أضف وظائف للتحويل والتوسيط ، واستخرج البيانات اللازمة:
def to_float(s):
يعد التشغيل ضروريًا لأن عدد مرات المشاهدة على الموقع معروض بزيادات 100 ، مما يؤدي إلى جدول "تمزيقه". من حيث المبدأ ، هذا ليس ضروريًا ، ولكن مع المتوسط يبدو أفضل. تتم إضافة منطقة موسكو الزمنية أيضًا في الكود (الوقت الذي أصبح فيه Raspberry Pi هو GMT).
أخيرًا ، يمكنك عرض الرسوم البيانية ومعرفة ما حدث.
import matplotlib.pyplot as plt
النتائج
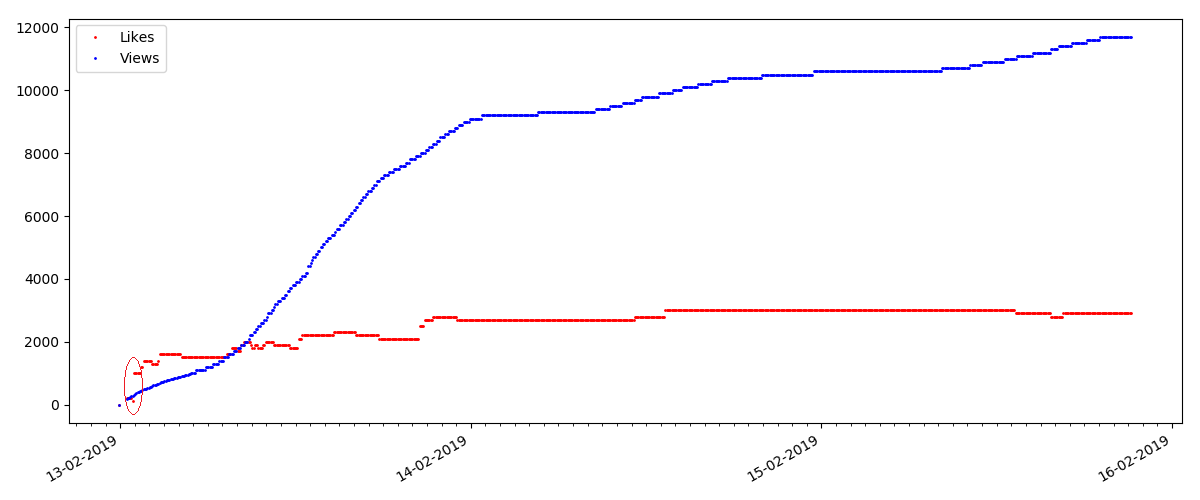
في بداية كل رسم بياني ، توجد مساحة فارغة ، والتي يتم شرحها ببساطة - عندما تم إطلاق البرنامج النصي ، تم نشر المقالات بالفعل ، وبالتالي لم يتم جمع البيانات من نقطة الصفر. تمت إضافة نقطة "الصفر" يدويًا من وصف وقت نشر المقال.
يتم إنشاء جميع المخططات المنصوص عليها بواسطة matplotlib والرمز أعلاه.
وفقا للنتائج ، قسمت المقالات التي تم التحقيق فيها إلى 3 مجموعات. الانقسام مشروط ، رغم أنه لا يزال لديه بعض المعنى.
المادة الساخنة
يتناول هذا المقال موضوعًا شائعًا وذو صلة بالموضوع ، بعنوان "How MTS يقتطع المال" أو "Roskomnadzor block
porn git hub".
تحتوي هذه المقالات على عدد كبير من المشاهدات والتعليقات ، لكن "الضجيج" يستمر كحد أقصى لعدة أيام. يمكنك أيضًا رؤية اختلاف بسيط في نمو عدد مرات المشاهدة خلال النهار والليل (ولكن ليس بنفس الأهمية كما هو متوقع - على ما يبدو ، تتم قراءة Habr من جميع المناطق الزمنية تقريبًا).
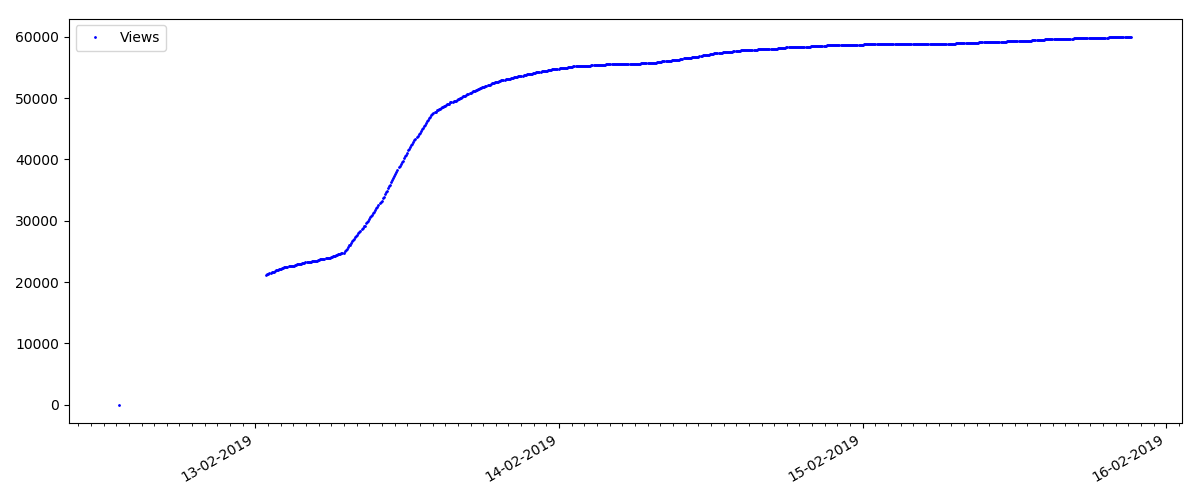
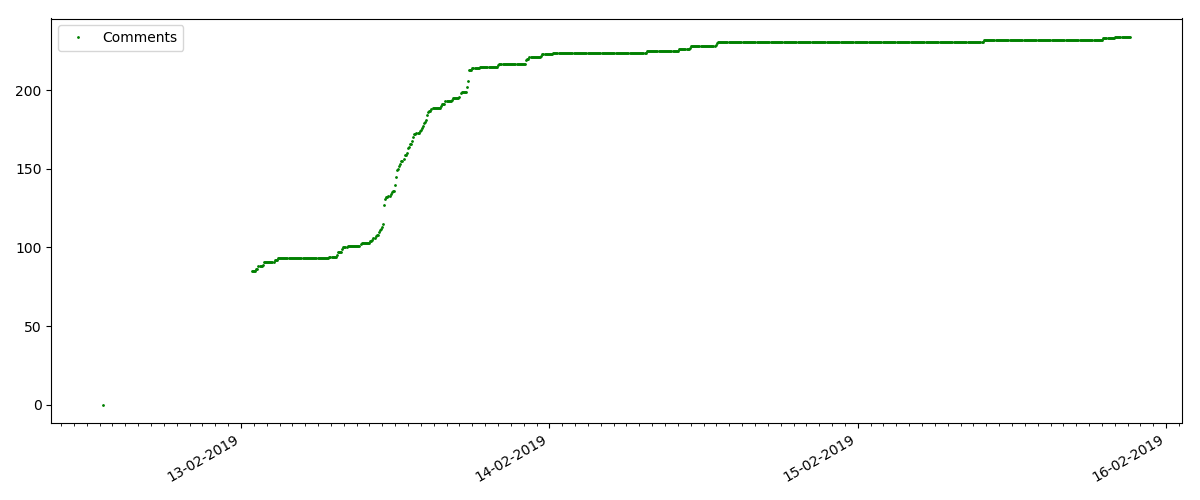
ينمو عدد "الإعجابات" بشكل كبير ، بينما ينمو عدد الإشارات المرجعية بشكل أبطأ. هذا منطقي ، لأنه قد يعجب شخص ما بالمقال ، لكن خصوصية النص لا تحتاج إلى وضع إشارة مرجعية عليه.
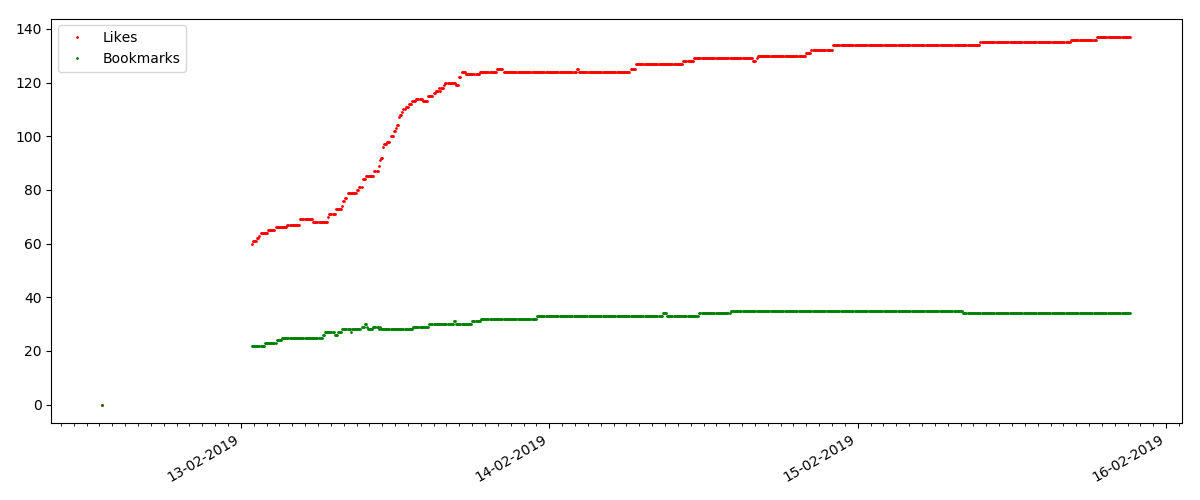
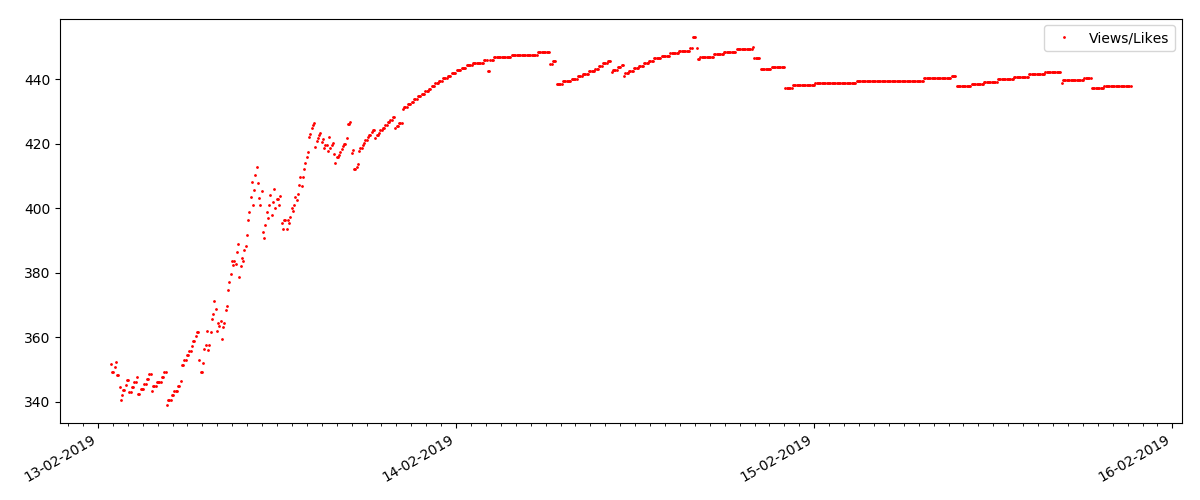
تظل نسبة مرات المشاهدة والإعجابات كما هي تقريبًا وهي 400: 1:
مقالة "فنية"
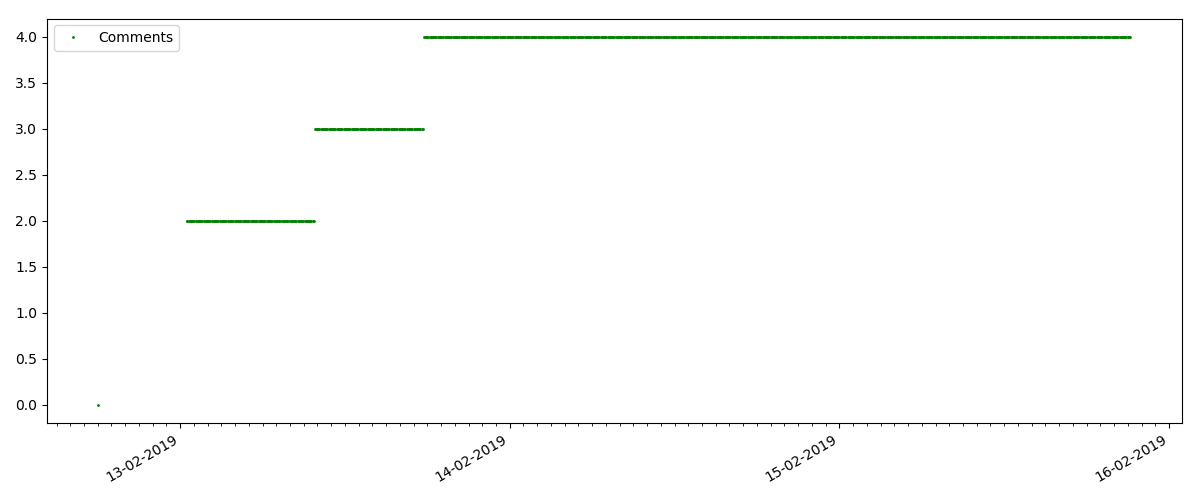
هذه مقالة أكثر تخصصًا ، مثل "إعداد البرامج النصية للعقدة JS". مثل هذه المقالة ، بالطبع ، تكتسب مرات أقل عددًا من الآراء "الساخنة" ، وعدد التعليقات أيضًا أصغر بشكل ملحوظ (في هذه الحالة كان هناك 4 فقط).
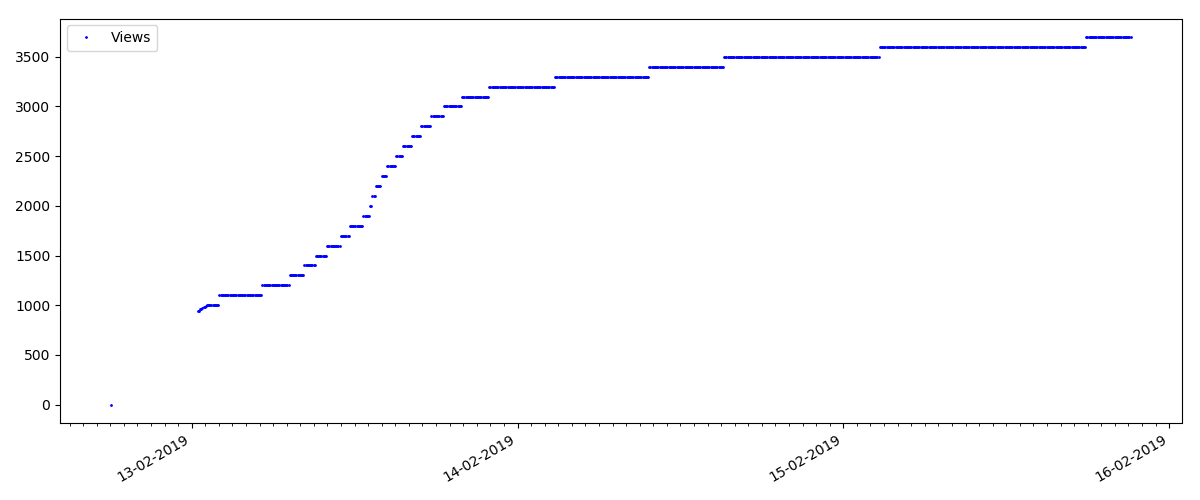
لكن النقطة التالية أكثر إثارة للاهتمام: عدد "الإعجابات" لمثل هذه المقالات يزداد بشكل أبطأ بشكل ملحوظ من عدد "الإشارات المرجعية". في ما يلي الاتجاه الآخر مقارنة بالإصدار السابق - يجد الكثيرون أن هذه المقالة مفيدة لحفظها في المستقبل ، لكن لا يتعين على القارئ النقر على "أعجبني" على الإطلاق.
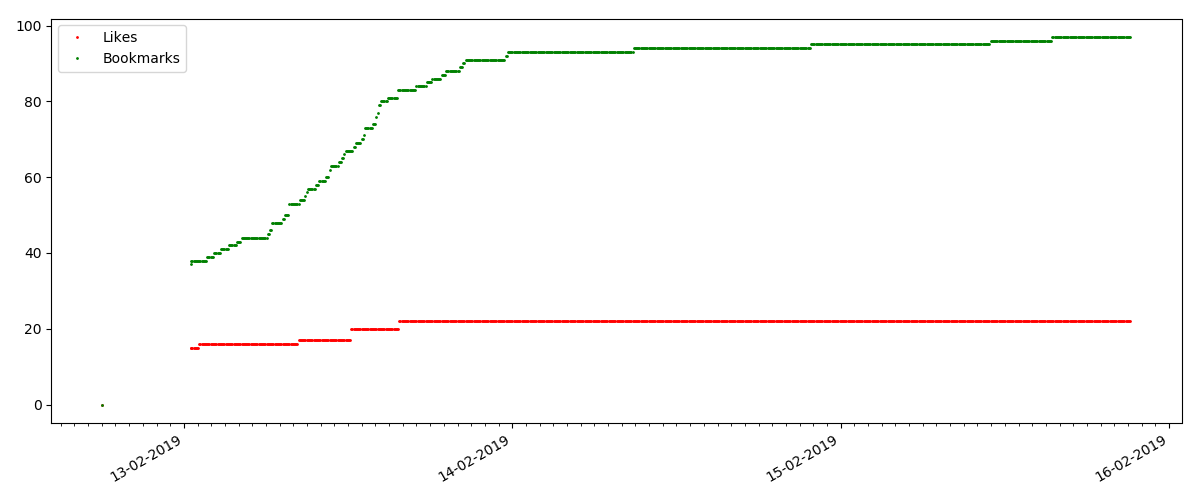
بالمناسبة ، في هذه المرحلة أود أن ألفت انتباه مسؤولي الموقع - عند حساب تصنيفات المقالات ، يجب أن تحسب الإشارات المرجعية بالتوازي مع الإعجابات (على سبيل المثال ، دمج المجموعات حسب OR). بخلاف ذلك ، يؤدي هذا إلى تحيز في التصنيف ، عندما يكون لمقال مشهور العديد من الإشارات المرجعية (أي أن القراء أعجبهم بالتأكيد) ، لكن هؤلاء الناس نسوا أو كانوا كسالى للغاية للنقر فوق "أعجبني".
وأخيرًا ، نسبة المشاهدات وما يعجبه: يمكنك أن ترى أنها أعلى بشكل ملحوظ مما كانت عليه في التجسيد الأول وهي تقريبًا 150: 1 ، أي يمكن أيضًا اعتبار جودة المحتوى بشكل غير مباشر أعلى.
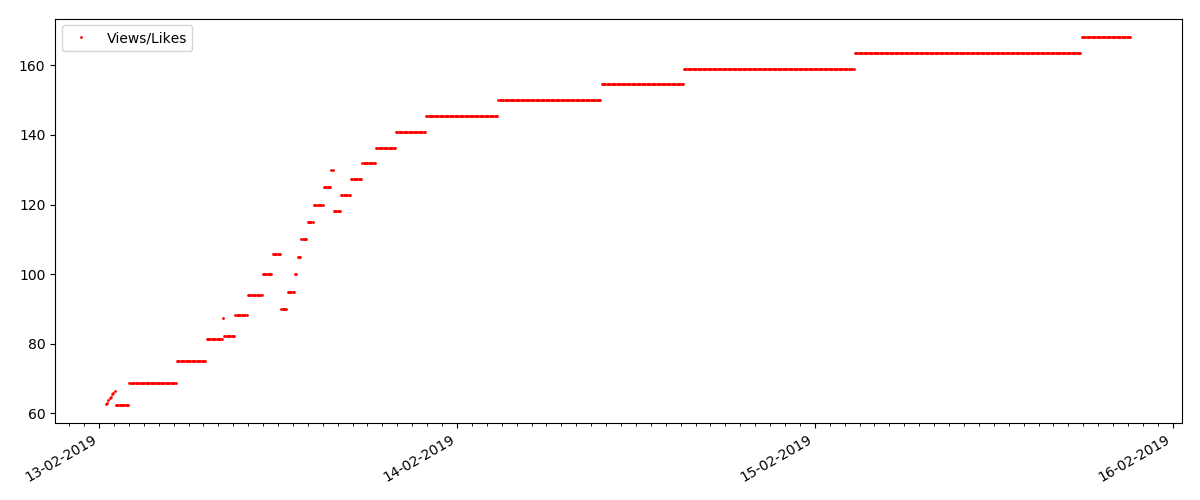
مقالة "مشبوهة" (لكن هذا غير دقيق)
بالنسبة للمقال التالي الذي تم فحصه ، زاد عدد "الإعجابات" بمقدار الثلث في فاصل زمني مدته 5 دقائق (على الفور بواقع 10 مع ما مجموعه 30 سجلًا لعدة أيام).
يمكن للمرء أن يشك في الغش ، ولكن "نظرية الطابور" من حيث المبدأ تسمح لمثل هذه الزيادات. أو ربما أرسل المؤلف الرابط إلى جميع أصدقائه العشرة ، وهو أمر لا تحظره بالطبع.
الاستنتاجات
الاستنتاج الرئيسي هو أن كل شيء تسوس ومايا. حتى المواد الأكثر شعبية ، التي اكتسبت آلاف المشاهدات ، ستذهب "في الماضي" خلال 3-4 أيام فقط. هذا ، للأسف ، خصوصيات الإنترنت الحديثة ، وربما صناعة الإعلام الحديثة بأكملها ككل. وأنا متأكد من أن الأرقام الموضحة محددة ليس فقط لـ Habr ، ولكن أيضًا لأي مورد إنترنت مماثل.
خلاف ذلك ، من المرجح أن يكون هذا التحليل "الجمعة" بطبيعته ، وبطبيعة الحال ، لا يتظاهر بأنه دراسة جادة. آمل أيضًا أن يجد شخص ما شيئًا جديدًا في استخدام Pandas و Matplotlib.
شكرا لاهتمامكم