مرحبا يا هبر! في هذا المنشور ، سنكتب تطبيقًا على Spring Boot 2 باستخدام Apache Kafka ضمن Linux ، من تثبيت JRE إلى تطبيق microservice فعال.
يشكو زملاء من قسم تطوير الواجهة الأمامية الذين شاهدوا المقال من أنني لا أشرح ماهية أباتشي كافكا و Spring Boot. أعتقد أن أي شخص يحتاج إلى تجميع مشروع مكتمل باستخدام التقنيات المذكورة أعلاه يعرف ما هو عليه ولماذا يحتاجون إليه. إذا لم يكن السؤال في وضع الخمول بالنسبة للقارئ ، فإليك بعض المقالات الممتازة حول هبر وما هي
أباتشي كافكا و
Spring Boot .
يمكننا الاستغناء عن توضيحات مطولة حول ماهية Kafka و Spring Boot و Linux وبدلاً من ذلك ، تشغيل خادم Kafka من نقطة الصفر على جهاز Linux ، وكتابة جهازي microservices وجعل أحدهما يرسل رسائل إلى الآخر - بشكل عام ، قم بتكوين العمارة الدقيقة الكاملة.

سوف تتألف المشاركة من قسمين. في البداية ، نقوم بتكوين وتشغيل Apache Kafka على جهاز Linux ، وفي الثانية نكتب جهازي خدمات مصغّرة في Java.
في بدء التشغيل ، حيث بدأت مسيرتي المهنية كمبرمج ، كانت هناك خدمات microservices على Kafka ، كما عملت واحدة من خدمات microservices الخاصة بي مع آخرين من خلال Kafka ، لكنني لم أعرف كيف يعمل الخادم نفسه ، سواء كان مكتوبًا كتطبيق أم أنه محاصر بالفعل المنتج. ما كان مفاجأة وخيبة الأمل عندما اتضح أن Kafka لا يزال منتجًا محاصرًا ، ولن تكون مهمتي هي كتابة عميل في Java (وهو ما أحب القيام به) ، بالإضافة إلى نشر وإعداد التطبيق النهائي كـ devOps (وهو ما أفترضه) أكره أن تفعل). ومع ذلك ، حتى لو تمكنت من رفعه على خادم كافكا الافتراضي في أقل من يوم ، فمن السهل جدًا القيام بذلك. هكذا
سيكون لدينا تطبيق هيكل التفاعل التالي:
في نهاية المنشور ، كالعادة ، ستكون هناك روابط إلى git مع رمز العمل.
نشر Apache Kafka + Zookeeper على جهاز افتراضي
حاولت أن أرفع كافكا على نظام Linux المحلي ، وعلى الخشخاش وعلى نظام Linux البعيد. في حالتين (Linux) ، نجحت بسرعة كبيرة. مع الخشخاش حتى الآن لم يحدث شيء. لذلك ، سنرفع كافكا على لينكس. اخترت أوبونتو 18.04.
ولكي تعمل كافكا ، فإنها تحتاج إلى حارس للحيوانات. للقيام بذلك ، يجب عليك تنزيله وتشغيله قبل تشغيل Kafka.
هكذا
0. تثبيت JRE
يتم ذلك عن طريق الأوامر التالية:
sudo apt-get update sudo apt-get install default-jre
إذا سارت الأمور على ما يرام ، يمكنك إدخال الأمر
java -version
وتأكد من تثبيت Java.
1. قم بتنزيل Zookeeper
أنا لا أحب الفرق السحرية على نظام Linux ، خاصةً عندما يقدمون بعض الأوامر فقط وليس من الواضح ما الذي يفعلونه. لذلك ، سوف أصف كل إجراء - ماذا يفعل بالضبط. لذلك ، نحن بحاجة إلى تنزيل Zookeeper وفك ضغطه في مجلد مناسب. من المستحسن أن يتم تخزين جميع التطبيقات في مجلد / opt ، وهذا في حالتنا ، سيكون / opt / zookeeper.
أنا استخدم الأمر أدناه. إذا كنت تعرف أوامر Linux الأخرى التي ، برأيك ، ستتيح لك القيام بذلك بطريقة أكثر عنصرية بشكل صحيح ، استخدمها. أنا مطور ، وليست مطورًا ، وأنا أتواصل مع الخوادم على مستوى "الماعز نفسه". لذلك ، قم بتنزيل التطبيق:
wget -P /home/xpendence/downloads/ "http://apache-mirror.rbc.ru/pub/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz"
تم تنزيل التطبيق على المجلد الذي تحدده ، لقد قمت بإنشاء المجلد / home / xpendence / download لتنزيل جميع التطبيقات التي أحتاجها.
2. فك الحارس
استخدمت الأمر:
tar -xvzf /home/xpendence/downloads/zookeeper-3.4.12.tar.gz
يقوم هذا الأمر بفك ضغط الأرشيف في المجلد الذي توجد به. قد تحتاج بعد ذلك إلى نقل التطبيق إلى / opt / zookeeper. ويمكنك الدخول إليه على الفور ومن هناك فك الأرشيف بالفعل.
3. تحرير الإعدادات
في المجلد / zookeeper / conf / يوجد ملف zoo-sample.cfg ، أقترح إعادة تسميته إلى zoo.conf ، هذا هو الملف الذي سيبحث عنه JVM عند بدء التشغيل. يجب إضافة ما يلي إلى هذا الملف في النهاية:
tickTime=2000 dataDir=/var/zookeeper clientPort=2181
أيضًا ، قم بإنشاء الدليل / var / zookeeper.
4. إطلاق Zookeeper
انتقل إلى المجلد / opt / zookeeper وابدأ تشغيل الخادم باستخدام الأمر:
bin/zkServer.sh start
يجب أن تظهر كلمة "STARTED".
بعد ذلك ، أقترح التحقق من أن الخادم يعمل. نكتب:
telnet localhost 2181
يجب أن تظهر رسالة أن الاتصال كان ناجحًا. إذا كان لديك خادم ضعيف ولم تظهر الرسالة ، فحاول مرة أخرى - حتى عند ظهور STARTED ، يبدأ التطبيق في الاستماع إلى المنفذ في وقت لاحق. عندما حاولت كل هذا على خادم ضعيف ، حدث لي كل مرة. إذا كان كل شيء متصلاً ، فأدخل الأمر
ruok
ماذا يعني ذلك: "هل أنت بخير؟" يجب أن يستجيب الخادم:
imok ( !)
وانقطع الاتصال. لذلك ، كل شيء وفقا للخطة. نشرع في إطلاق Apache Kafka.
5. إنشاء مستخدم تحت Kafka
للعمل مع كافكا نحتاج إلى مستخدم منفصل.
sudo adduser --system --no-create-home --disabled-password --disabled-login kafka
6. تحميل اباتشي كافكا
هناك نوعان من التوزيعات - ثنائي ومصادر. نحن بحاجة إلى ثنائي. في المظهر ، الأرشيف مع ثنائي يختلف في الحجم. يزن الثنائي 59 ميغابايت ، ويزن 6.5 ميغابايت.
قم بتنزيل الملف الثنائي إلى الدليل هناك ، باستخدام الرابط أدناه:
wget -P /home/xpendence/downloads/ "http://mirror.linux-ia64.org/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz"
7. فك أباتشي كافكا
لا يختلف إجراء التفريغ عن نفس الشيء بالنسبة لـ Zookeeper. نقوم أيضًا بفك ضغط الأرشيف في دليل / opt وإعادة تسميته إلى kafka بحيث يكون المسار إلى مجلد / bin هو / opt / kafka / bin
tar -xvzf /home/xpendence/downloads/kafka_2.11-2.1.0.tgz
8. تحرير الإعدادات
الإعدادات في /opt/kafka/config/server.properties. أضف سطر واحد:
delete.topic.enable = true
يبدو أن هذا الإعداد اختياري ، ويعمل بدونه. يسمح لك هذا الإعداد بحذف الموضوعات. خلاف ذلك ، لا يمكنك ببساطة حذف المواضيع من خلال سطر الأوامر.
9. نمنح حق الوصول إلى دليل المستخدم كافكا كافكا
chown -R kafka:nogroup /opt/kafka chown -R kafka:nogroup /var/lib/kafka
10. الإطلاق الذي طال انتظاره لإباتشي كافكا
ندخل الأمر ، وبعد ذلك يبدأ كافكا:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
إذا لم تنتشر الإجراءات المعتادة (يتم كتابة كافكا بلغة جافا وسكالا) في السجل ، فكل شيء يعمل ويمكنك اختبار خدمتنا.
10.1. مشاكل الخادم ضعيفة
لإجراء تجارب على Apache Kafka ، أخذت خادمًا ضعيفًا يحتوي على لب واحد و 512 ميجابايت من ذاكرة الوصول العشوائي (مقابل 99 روبل فقط) ، والتي تبين أنها عدة مشكلات بالنسبة لي.
نفاد الذاكرة. بالطبع ، لا يمكنك رفع تردد التشغيل بسعة 512 ميجابايت ، ولم يتمكن الخادم من نشر تطبيق كافكا بسبب نقص الذاكرة. الحقيقة هي أن كافكا يستهلك بشكل افتراضي 1 غيغابايت من الذاكرة. لا عجب أنه كان في عداد المفقودين :)
نذهب إلى kafka-server-start.sh ، zookeeper-server-start.sh. يوجد بالفعل خط ينظم الذاكرة:
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
تغييره إلى:
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
هذا سوف يقلل من شهية كافكا ويسمح لك ببدء تشغيل الخادم.
المشكلة الثانية مع الكمبيوتر الضعيف هي ضيق الوقت للاتصال بـ Zookeeper. بشكل افتراضي ، يتم إعطاء هذا 6 ثوانٍ. إذا كان الحديد ضعيفًا ، فهذا بالطبع لا يكفي. في server.properties نزيد وقت الاتصال بـ zukipper:
zookeeper.connection.timeout.ms=30000
أنا وضعت نصف دقيقة.
11. اختبار خادم كافكا
للقيام بذلك ، سوف نفتح محطتين ، على واحدة سنطلق المنتج ، والآخر - المستهلك.
في وحدة التحكم الأولى ، أدخل سطر واحد:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
يجب أن يظهر هذا الرمز ، للإشارة إلى أن المنتج جاهز لإرسال رسائل غير مرغوب فيها:
>
في وحدة التحكم الثانية ، أدخل الأمر:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
الآن ، بالكتابة في وحدة التحكم الخاصة بالمنتج ، عند الضغط على Enter ، ستظهر في وحدة التحكم الخاصة بالمستهلك.
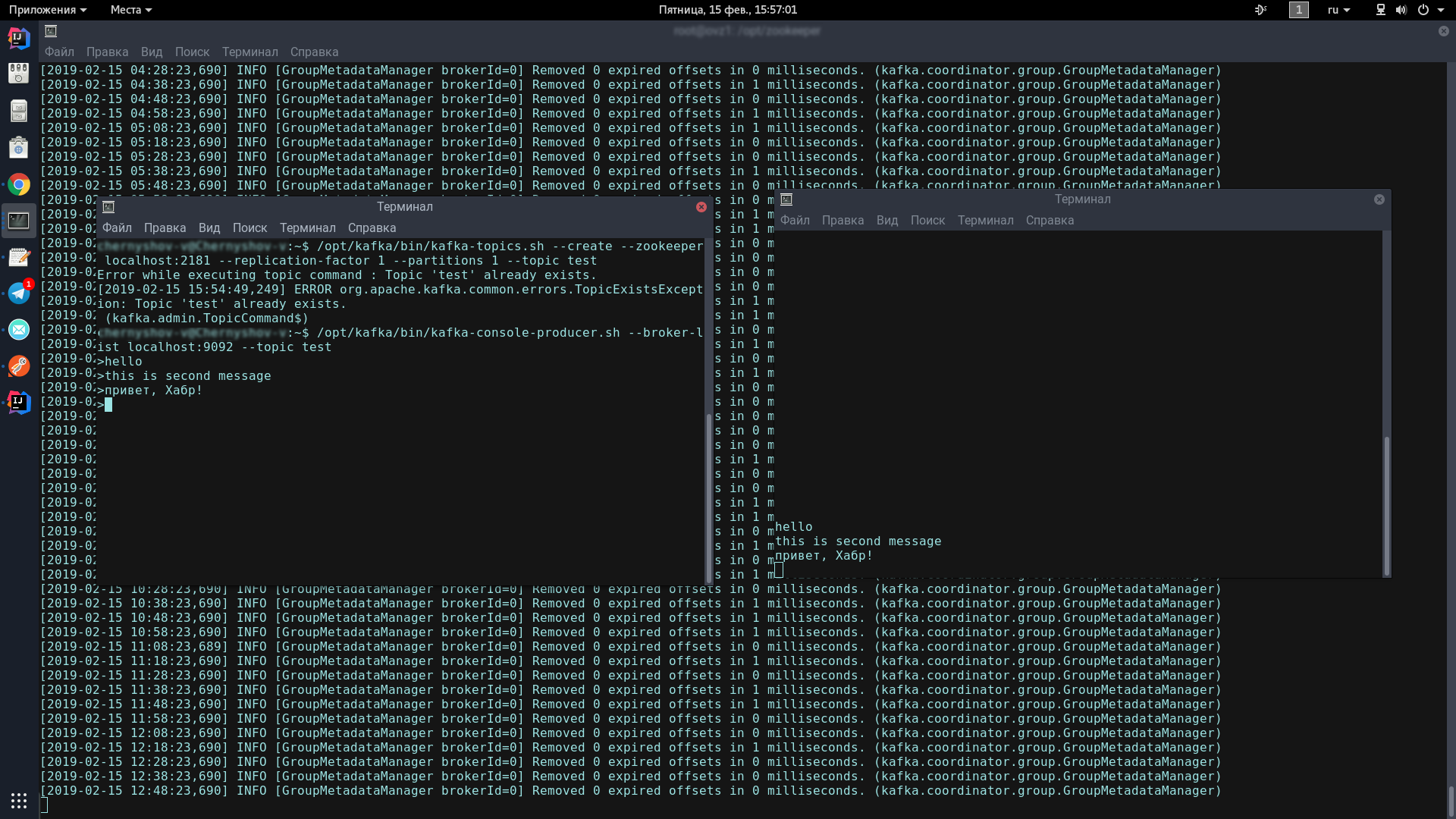
إذا رأيت على الشاشة نفس مثلي - تهانينا ، فالأسوأ قد انتهى!
الآن علينا فقط أن نكتب اثنين من العملاء على Spring Boot سيتواصلون مع بعضهم البعض من خلال Apache Kafka.
كتابة تطبيق على Spring Boot
سنكتب تطبيقين لتبادل الرسائل من خلال Apache Kafka. سوف تسمى الرسالة الأولى kafka-server وسوف تحتوي على كل من المنتج والمستهلك. سيطلق على الثاني اختبار kafka ، وهو مصمم بحيث يكون لدينا بنية microservice.
خادم kafka
لمشاريعنا التي تم إنشاؤها من خلال Spring Initializr ، نحن بحاجة إلى وحدة كافكا. أضفت لومبوك وويب ، لكن هذه مسألة ذوق.
يتكون عميل كافكا من مكونين - المنتج (يرسل رسائل إلى خادم كافكا) والمستهلك (يستمع إلى خادم كافكا ويأخذ رسائل جديدة من هناك حول الموضوعات التي اشترك فيها). مهمتنا هي كتابة كلا المكونين وجعلها تعمل.
المستهلك:
@Configuration public class KafkaConsumerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.group.id}") private String kafkaGroupId; @Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; } @Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); } }
نحتاج إلى تهيئة حقلين ببيانات ثابتة من kafka.properties.
kafka.server=localhost:9092 kafka.group.id=server.broadcast
kafka.server هو العنوان الذي يتوقف عليه خادمنا ، في هذه الحالة ، محلي. بشكل افتراضي ، يستمع Kafka على المنفذ 9092.
kafka.group.id هي مجموعة من العملاء ، يتم خلالها تسليم مثيل واحد من الرسالة. على سبيل المثال ، لديك ثلاثة ناقلات في مجموعة واحدة ، وكلهم يستمعون إلى نفس الموضوع. بمجرد ظهور رسالة جديدة على الخادم مع هذا الموضوع ، يتم تسليمها إلى شخص ما في المجموعة. لا يتلقى المستهلكان المتبقيان الرسالة.
بعد ذلك ، نقوم بإنشاء مصنع للمستهلكين - ConsumerFactory.
@Bean public ConsumerFactory<Long, AbstractDto> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); }
تم التهيئة مع الخصائص التي نحتاجها ، وسيكون بمثابة مصنع قياسي للمستهلكين في المستقبل.
@Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); return props; }
ConsumerConfigs هي مجرد خريطة التكوين. نحن نقدم عنوان الخادم والمجموعة و deserializers.
علاوة على ذلك ، واحدة من أهم النقاط للمستهلك. يمكن للمستهلك استلام كل من الكائنات والمجموعات - على سبيل المثال ، كل من StarshipDto و List. وإذا حصلنا على StarshipDto كـ JSON ، فسنحصل على قائمة كـ ، بصفتها صفيف JSON تقريبًا. لذلك ، لدينا مصنعان للرسالة على الأقل - للرسائل الفردية وللصفائف.
@Bean public KafkaListenerContainerFactory<?> singleFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(false); factory.setMessageConverter(new StringJsonMessageConverter()); return factory; }
نحن إنشاء مثيل ConcurrentKafkaListenerContainerFactory ، كتابة طويلة (مفتاح الرسالة) و AbstractDto (قيمة الرسالة المجردة) ، وتهيئة حقولها بخصائص. نحن ، بطبيعة الحال ، نهيئ المصنع من خلال المصنع القياسي (الذي يحتوي بالفعل على تهيئة الخريطة) ، ثم نحتفل على أننا لا نستمع إلى الحزم (نفس المصفوفات) ونحدد محول JSON البسيط كمحول.
عندما ننشئ مصنعًا للحزم / المصفوفات (الدُفعة) ، يكون الاختلاف الرئيسي (بصرف النظر عن أننا نحتفل بالاستماع إلى الحزم) هو أننا نحدد كمحول محول حزمة خاص يحول الحزم التي تتكون من من سلاسل JSON.
@Bean public KafkaListenerContainerFactory<?> batchFactory() { ConcurrentKafkaListenerContainerFactory<Long, AbstractDto> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true); factory.setMessageConverter(new BatchMessagingMessageConverter(converter())); return factory; } @Bean public StringJsonMessageConverter converter() { return new StringJsonMessageConverter(); }
وأكثر شيء واحد. عند تهيئة حبوب الربيع ، قد لا يتم حساب الصندوق تحت اسم kafkaListenerContainerFactory وسيتم إتلاف التطبيق. من المؤكد أن هناك خيارات أكثر أناقة لحل المشكلة ، والكتابة عنها في التعليقات ، في الوقت الحالي ، قمت فقط بإنشاء صندوق تم إلغاء تحميله بوظائف بنفس الاسم:
@Bean public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() { return new ConcurrentKafkaListenerContainerFactory<>(); }
تم إعداد المستهلك. نمر إلى المنتج.
@Configuration public class KafkaProducerConfig { @Value("${kafka.server}") private String kafkaServer; @Value("${kafka.producer.id}") private String kafkaProducerId; @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, LongSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class); props.put(ProducerConfig.CLIENT_ID_CONFIG, kafkaProducerId); return props; } @Bean public ProducerFactory<Long, StarshipDto> producerStarshipFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<Long, StarshipDto> kafkaTemplate() { KafkaTemplate<Long, StarshipDto> template = new KafkaTemplate<>(producerStarshipFactory()); template.setMessageConverter(new StringJsonMessageConverter()); return template; } }
من المتغيرات الثابتة ، نحتاج إلى عنوان خادم kafka ومعرف المنتج. يمكن أن يكون أي شيء.
في التكوينات ، كما نرى ، لا يوجد شيء خاص. تقريبا نفس الشيء. لكن فيما يتعلق بالمصانع هناك فرق كبير. يجب أن نسجل قالبًا لكل فئة نرسل كائناتها إلى الخادم ، وكذلك مصنعًا لها. لدينا زوج واحد من هذا القبيل ، ولكن يمكن أن يكون هناك العشرات منهم.
في القالب ، نحتفل بأننا سنسلسل الكائنات في JSON ، وربما هذا يكفي.
لدينا مستهلك ومنتج ، يبقى كتابة خدمة من شأنها إرسال الرسائل واستقبالها.
@Service @Slf4j public class StarshipServiceImpl implements StarshipService { private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate; private final ObjectMapper objectMapper; @Autowired public StarshipServiceImpl(KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate, ObjectMapper objectMapper) { this.kafkaStarshipTemplate = kafkaStarshipTemplate; this.objectMapper = objectMapper; } @Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); } @Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); } private String writeValueAsString(StarshipDto dto) { try { return objectMapper.writeValueAsString(dto); } catch (JsonProcessingException e) { e.printStackTrace(); throw new RuntimeException("Writing value to JSON failed: " + dto.toString()); } } }
هناك طريقتان فقط في خدمتنا ، وهما كافيتان لشرح عمل العميل. نحن autowire الأنماط التي نحتاجها:
private final KafkaTemplate<Long, StarshipDto> kafkaStarshipTemplate;
طريقة المنتج:
@Override public void send(StarshipDto dto) { kafkaStarshipTemplate.send("server.starship", dto); }
كل ما هو مطلوب لإرسال رسالة إلى الخادم هو استدعاء طريقة الإرسال على القالب ونقل الموضوع (الموضوع) وكائننا هناك. سيتم إجراء تسلسل للكائن في JSON وسيتم نقله إلى الخادم تحت الموضوع المحدد.
تبدو طريقة الاستماع هكذا:
@Override @KafkaListener(id = "Starship", topics = {"server.starship"}, containerFactory = "singleFactory") public void consume(StarshipDto dto) { log.info("=> consumed {}", writeValueAsString(dto)); }
نحتفل بهذه الطريقة باستخدام التعليق التوضيحيKafkaListener ، حيث نشير إلى أي معرّف نرغب فيه ، وموضوعات مستمع إليها ومصنع يقوم بتحويل الرسالة المستلمة إلى ما نحتاج إليه. في هذه الحالة ، بما أننا نقبل كائنًا واحدًا ، فإننا نحتاج إلى مصنع فردي. للحصول على قائمة <؟> ، حدد batchFactory. نتيجة لذلك ، نرسل الكائن إلى خادم kafka باستخدام طريقة الإرسال ونحصل عليه باستخدام طريقة الاستهلاك.
يمكنك كتابة اختبار خلال 5 دقائق لإظهار القوة الكاملة لكافكا ، لكننا سنذهب أبعد من ذلك - نمضي 10 دقائق ونكتب تطبيقًا آخر يرسل رسائل إلى الخادم الذي سيستمع إليه أول تطبيق لدينا.
اختبار الكافا
بعد تجربة كتابة التطبيق الأول ، يمكننا بسهولة كتابة الثاني ، خاصةً إذا قمنا بنسخ اللصق وحزمة dto ، تسجيل المنتج فقط (سنرسل الرسائل فقط) وأضف طريقة الإرسال الوحيدة إلى الخدمة. باستخدام الرابط أدناه ، يمكنك بسهولة تنزيل رمز المشروع والتأكد من عدم وجود شيء معقد هناك.
@Scheduled(initialDelay = 10000, fixedDelay = 5000) @Override public void produce() { StarshipDto dto = createDto(); log.info("<= sending {}", writeValueAsString(dto)); kafkaStarshipTemplate.send("server.starship", dto); } private StarshipDto createDto() { return new StarshipDto("Starship " + (LocalTime.now().toNanoOfDay() / 1000000)); }
بعد أول 10 ثوانٍ ، يبدأ kafka-tester في إرسال رسائل بأسماء النجوم إلى خادم كافكا كل 5 ثوانٍ (الصورة قابلة للنقر).
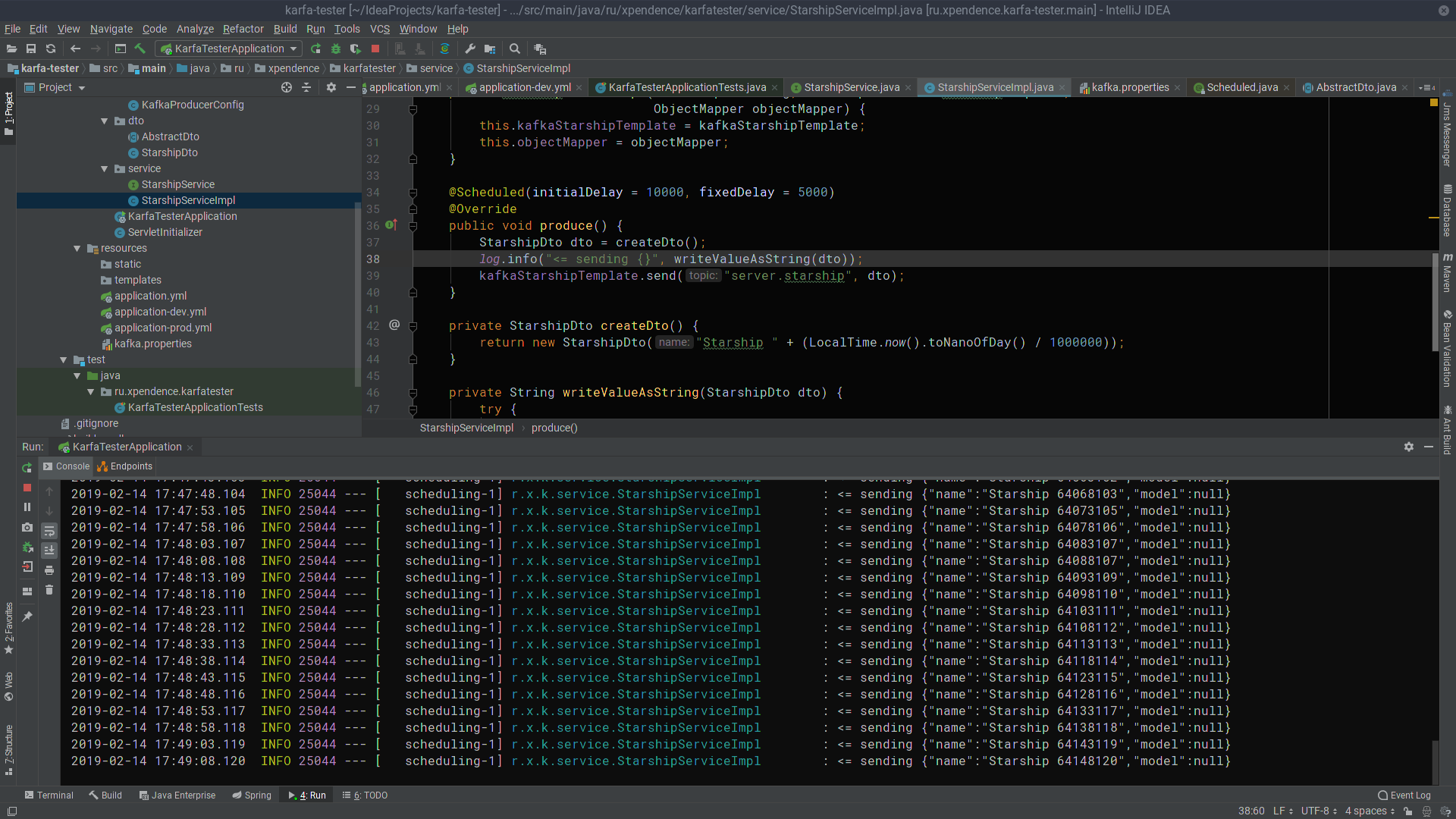
هناك ، يتم الاستماع إليها وتلقيها من قبل خادم kafka (الصورة هي أيضا قابلة للنقر).

آمل أن ينجح أولئك الذين يحلمون بالبدء في كتابة خدمات ميكروية في كافكا بنفس السهولة التي نجحت بها. وهنا هي الروابط إلى المشاريع:
→
خادم كافكا→
اختبار الكافا