قبل بضعة أشهر ،
عقد زملاؤنا من Google مسابقة في Kaggle لإنشاء مصنف للصور التي تم تلقيها في
اللعبة المشهورة "Quick، Draw!". احتل الفريق ، الذي شارك فيه مطور ياندكس رومان فلاسوف ، المركز الرابع في المسابقة. في جلسة التدريب الآلي التي عقدت في شهر يناير ، تبادل رومان أفكار فريقه ، والتنفيذ النهائي للمصنف ، وممارسات مثيرة للاهتمام للخصمين.
- مرحبا بالجميع! اسمي روما فلاسوف ، اليوم سوف أخبركم عن السحب السريع! تحدي التعرف على رسومات الشعار المبتكرة.

كان هناك خمسة أشخاص في فريقنا. انضممت إليها مباشرة أمام الموعد النهائي للدمج. كنا محظوظين ، لقد اهتزنا قليلاً ، لكننا كنا مظللين بالمال ، وكانوا من موقع الذهب. وقد اتخذنا المركز الرابع الشرفاء.
(خلال المسابقة ، لاحظت الفرق نفسها في التصنيف ، الذي تم تكوينه وفقًا للنتائج الموضحة في جزء واحد من مجموعة البيانات المقترحة. تم تكوين التقييم النهائي ، بدوره ، على الجزء الآخر من مجموعة البيانات. ويتم ذلك حتى لا يقوم المشاركون في المسابقة بضبط خوارزمياتهم على بيانات محددة. لذلك ، في النهائيات ، عند التبديل بين التصنيفات ، فإن المواقف "تهز" قليلاً (من تغيير اللغة الإنجليزية - خلط ورق اللعب): على البيانات الأخرى وقد تكون النتيجة مختلفة. كان فريق رومان هو الأول في المراكز الثلاثة الأولى. AU الترويكا - هو المال، منطقة تصنيفات المال، منذ فقط المواقع الثلاثة الأولى تعتمد الجائزة بعد "فريق هزة APA" كان بالفعل في المركز الرابع بنفس الطريقة خسر الفريق الآخر النصر، والموقف من الذهب -... إد) ..
كانت المسابقة مهمة أيضًا لأن إيفجيني باباخنين استقبل الكثير من السادة ، إيفان سوسين - الماجستير ، وظل رومان سولوفيوف كبيرًا ، واستلم أليكس بارينوف أستاذًا ، وأصبحت خبيرًا ، والآن أنا بالفعل أستاذ.
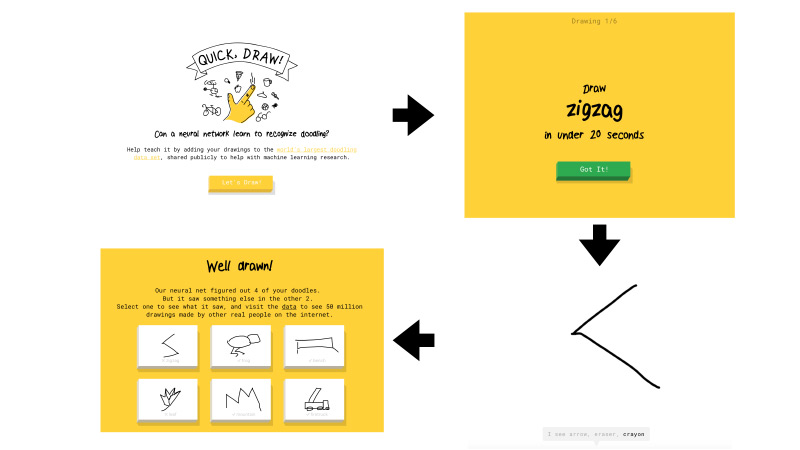
ما هو هذا السحب السريع؟ هذه خدمة من Google. تهدف Google إلى الترويج لمنظمة العفو الدولية ، ومن خلال هذه الخدمة أرادت أن توضح كيف تعمل الشبكات العصبية. تذهب إلى هناك ، انقر فوق "دعونا نرسم" ، وستظهر لك صفحة جديدة توضح مكانك: ارسم خطًا متعرجًا ، أمامك 20 ثانية للقيام بذلك. حاولت رسم متعرج في 20 ثانية ، مثل هنا ، على سبيل المثال. إذا كان كل شيء يناسبك ، تقول الشبكة إنها متعرجة وأنت تمضي قدمًا. لا يوجد سوى ستة من هذه الصور.
إذا لم تتمكن الشبكة من Google من التعرف على ما رسمته ، فقد تم وضع تقاطع على المهمة. في وقت لاحق ، سوف أخبرك بماذا يعني في المستقبل ما إذا كانت الشبكة يتم التعرف عليها من خلال الشبكة أم لا.
جمعت هذه الخدمة عددًا كبيرًا من المستخدمين ، وتم تسجيل جميع الصور التي رسمها المستخدمون.

كان من الممكن جمع ما يقرب من 50 مليون صورة. من هذا ، تم تشكيل تاريخ القطار والاختبار لمنافستنا. بالمناسبة ، كمية البيانات الموجودة في الاختبار وعدد الفصول لم تذهب سدى. سأتحدث عنها لاحقًا.
كان تنسيق البيانات على النحو التالي. هذه ليست مجرد صور RGB ، ولكن ، تقريبًا ، سجل كل ما فعله المستخدم. Word هو هدفنا ورمز البلد هو المكان الذي يأتي منه الرمز ، والوقت الزمني هو الوقت المناسب. تظهر العلامة المعترف بها فقط ما إذا كانت الشبكة من Google قد تعرفت على الصورة أم لا. والرسم هو تسلسل تقريبي للمنحنى الذي يرسمه المستخدم بالنقاط. والتوقيت. هذا هو الوقت المناسب من بداية رسم الصورة.
تم تقديم البيانات بتنسيقين. هذا هو التنسيق الأول ، والثاني مبسط. لقد استبعدوا توقيتات من هناك وقربوا هذه المجموعة من النقاط بمجموعة أصغر من النقاط. للقيام بذلك ، استخدموا
خوارزمية دوغلاس بيكر . لديك مجموعة كبيرة من النقاط تقريبًا خط مستقيم ، ولكن يمكنك تقريبًا هذا الخط بنقطتين فقط. هذه هي فكرة الخوارزمية.
تم توزيع البيانات على النحو التالي. كل شيء موحد ، ولكن هناك بعض القيم المتطرفة. عندما حلنا المشكلة ، لم ننظر إليها. الشيء الرئيسي هو أنه لم تكن هناك فصول قليلة بالفعل ، لم يكن علينا القيام بأخذ عينات مرجحة وتجاوز البيانات.

كيف تبدو الصور؟ هذا هو فئة الطائرات والأمثلة منه معترف بها وغير معترف بها. كانت نسبتها في مكان ما من 1 إلى 9. كما ترون ، البيانات صاخبة للغاية. أود أن أقترح أن هذه طائرة. إذا نظرت إلى غير معترف بها ، فإنه في معظم الحالات يكون مجرد ضوضاء. حاول شخص ما أن يكتب "طائرة" ، ولكن يبدو أنه باللغة الفرنسية.
أخذ معظم المشاركين ببساطة شبكات ، وقدموا بيانات من سلسلة الخطوط هذه كصور RGB ، وألقوا بها في الشبكة. قمت بالرسم بالطريقة نفسها تقريبًا: لقد أخذت لوحة ألوان ، ورسمت السطر الأول بلون واحد ، والذي كان في بداية هذه اللوحة ، وآخرها ، مع آخر ، والذي كان في نهاية اللوحة ، وبينهم في كل مكان محرف على هذه اللوحة. بالمناسبة ، أعطى هذا نتيجة أفضل مما لو كنت ترسم على الشريحة الأولى - أسود فقط.
حاول أعضاء الفريق الآخرون ، مثل إيفان سوسين ، اتباع أساليب مختلفة قليلاً في الرسم. من خلال قناة واحدة ، قام ببساطة برسم صورة رمادية ، وقناة أخرى ، ووجه كل ضربة بضربة تدرج من البداية إلى النهاية ، من 32 إلى 255 ، ورسمت القناة الثالثة تدرجًا في جميع الخطوط من 32 إلى 255.
شيء آخر مثير للاهتمام هو أن أليكس بارينوف ألقى المعلومات في الشبكة عبر رمز البلد.
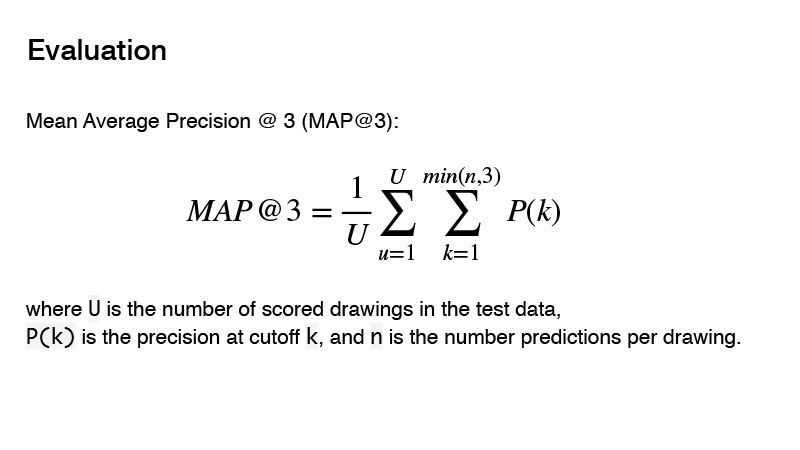
المقياس المستخدم في المسابقة هو متوسط الدقة المتوسط. ما هو جوهر هذا المقياس للمنافسة؟ يمكنك إعطاء ثلاثة متنبئين ، وإذا لم تكن هذه المتنبئات الثلاثة صحيحة ، فستحصل على 0. إذا كان هناك تنبؤ صحيح ، فسيتم أخذ ترتيبها في الاعتبار. وستعتبر نتيجة الهدف 1 ، مقسومة على ترتيب تنبؤك. على سبيل المثال ، لقد قدمت ثلاثة تنبؤات ، وأول واحد هو الصحيح ، ثم تقسم 1 على 1 وتحصل على 1. إذا كان المتنبئ صحيحًا وكان ترتيبه 2 ، ثم 1 يقسم على 2 ، تحصل على 0.5. حسنا ، الخ

مع تجهيز البيانات - كيفية رسم الصور وهلم جرا - قررنا قليلا. ما هي البنى التي استخدمناها؟ لقد حاولنا استخدام تصميمات جريئة مثل PNASNet و SENet ومعماريات كلاسيكية بالفعل مثل SE-Res-NeXt ، فهي تدخل بشكل متزايد في مسابقات جديدة. كان هناك أيضا ResNet و DenseNet.



كيف علمنا هذا؟ جميع النماذج التي أخذناها ، أخذنا أنفسنا قبل التدريب على imagenet. على الرغم من أن هناك الكثير من البيانات ، 50 مليون صورة ، ولكن لا يزال ، إذا كنت تأخذ شبكة مدربة مسبقًا على imagenet ، فقد أظهرت نتيجة أفضل مما لو كنت مجرد تدريب عليه من نقطة الصفر.
ما هي تقنيات التدريب التي استخدمناها؟ هذا هو Cosing الصلب مع دافئ إعادة التشغيل ، سأتحدث عن ذلك في وقت لاحق قليلا. هذه تقنية أستخدمها في جميع مسابقاتي الأخيرة تقريبًا ، ومعها اتضح أن تدريب الشباك جيدًا لتحقيق الحد الأدنى.

التالي خفض معدل التعلم على الهضبة. تبدأ في تدريب الشبكة ، وتعيين بعض معدل التعلم ، ثم تعلمه ، ثم تتحول خسارتك تدريجياً إلى قيمة معينة. يمكنك التحقق من ذلك ، على سبيل المثال ، خلال عشرة عصور ، لم يتغير الفقد. يمكنك تقليل معدل التعلم الخاص بك عن طريق بعض القيمة والاستمرار في التعلم. تنخفض مرة أخرى قليلاً ، وتتقارب عند حد أدنى معين ، وتخفض مرة أخرى معدل التعلم ، وهكذا ، حتى تتلاقى شبكتك أخيرًا.
تقنية أخرى مثيرة للاهتمام: لا تتحلل معدل التعلم ، وزيادة حجم الدفعة. هناك مقال بنفس الاسم. عندما تقوم بتدريب الشبكة ، لن تضطر إلى خفض معدل التعلم ، يمكنك فقط زيادة حجم الدفعة.
هذه التقنية ، بالمناسبة ، تم استخدامها من قبل أليكس بارينوف. لقد بدأ بدفعة تساوي 408 ، وعندما وصلت الشبكة إلى بعض الهضاب ، قام ببساطة بمضاعفة حجم الدُفعة ، إلخ.
في الحقيقة ، لا أتذكر القيمة التي وصل إليها حجم الدُفعة ، لكن المثير للاهتمام ، أن هناك فرقًا على Kaggle استخدمت نفس الأسلوب ، وكان حجم الدُفعة الخاصة بها حوالي 10000. وبالمناسبة ، فإن الأطر الحديثة للتعلم العميق ، مثل PyTorch ، على سبيل المثال ، يتيح لك القيام بذلك بكل بساطة. تقوم بإنشاء مجموعتك وإرسالها إلى الشبكة ليس كما هي ، في مجملها ، ولكن تقسيمها إلى قطع بحيث تناسبها في بطاقة الفيديو الخاصة بك ، عد التدرجات ، وبعد حساب التدرج للدفعة بأكملها ، يمكنك تحديث المقاييس.
بالمناسبة ، لا تزال أحجام الدُفعات الكبيرة تأتي في هذه المسابقة ، لأن البيانات كانت صاخبة للغاية ، وساعدك حجم الدُفعة الكبيرة في تقريب التدرج بدقة أكثر.
تم استخدام زائفة dabbing أيضا ، بالنسبة للجزء الأكبر ، تم استخدامه من قبل الروماني Soloviev. أخذ عينات من مكان ما في نصف البيانات من الاختبار ، وعلى مثل هذه الدفعات قام بتدريب الشبكة.
لعب حجم الصور دورًا ، ولكن الحقيقة هي أن لديك الكثير من البيانات ، تحتاج إلى التدريب لفترة طويلة ، وإذا كان حجم الصورة كبيرًا جدًا ، فسوف تدرب لفترة طويلة جدًا. ولكن هذا لم يجلب الكثير من الجودة في المصنف النهائي ، لذلك كان من المفيد استخدام بعض المقايضات. وحاولوا الصور فقط ليست كبيرة الحجم.
كيف تعلم كل شيء؟ في البداية ، تم التقاط صور ذات حجم صغير ، وتم تشغيل عدة عصور عليها ، واستغرق الأمر وقتًا طويلاً. ثم تم إعطاء صور كبيرة ، تعلمت الشبكة ، ثم أكثر ، حتى لا تدربها من نقطة الصفر ولا تقضي الكثير من الوقت.
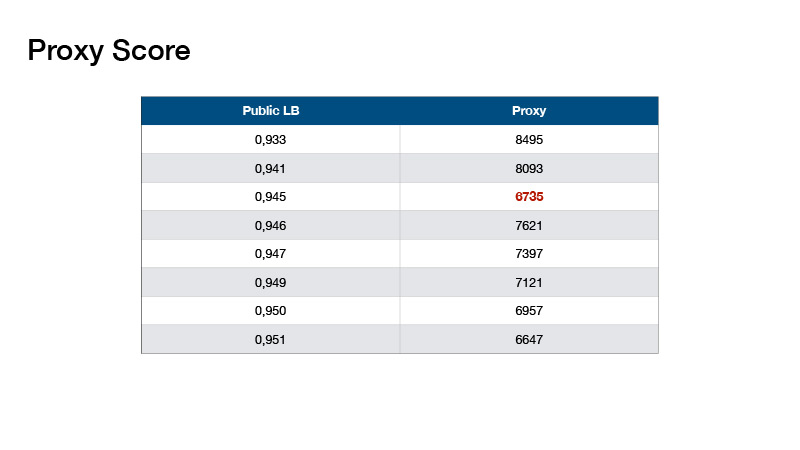
عن المحسنون. استخدمنا SGD وآدم. بهذه الطريقة ، كان من الممكن الحصول على نموذج واحد ، أعطى سرعة 0.941-0.946 على المتصدرين العامة ، وهو أمر جيد للغاية.
إذا قمت بتجميع الموديلات بطريقة ما ، فستحصل على 0.951 في مكان ما. إذا قمت بتطبيق تقنية أخرى ، فستحصل على السرعة النهائية على اللوحة العامة 0.954 ، كما تلقينا. ولكن أكثر على ذلك في وقت لاحق. بعد ذلك ، سوف أخبرك كيف قمنا بتجميع النماذج وكيف تحقق هذه السرعة النهائية.
بعد ذلك ، أود أن أتحدث عن Cosing التلدين مع إعادة التشغيل الدافئة أو هبوط مؤشر ستوكاستيك مع إعادة التشغيل الدافئة. من الناحية التقريبية ، من حيث المبدأ ، يمكنك التمسك بأي مُحسِّن ، ولكن خلاصة القول هي أنه: إذا كنت تدرب شبكة واحدة وتلتقي تدريجيًا إلى الحد الأدنى ، فكل شيء على ما يرام ، ستحصل على شبكة واحدة ، وتحدث أخطاء معينة ، ولكن يمكنك تعليمها بشكل مختلف قليلاً. ستقوم بتعيين معدل تعلّم أولي ، وتخفيضه تدريجيًا وفقًا لهذه الصيغة. أنت تقلل من شأن ذلك ، فإن شبكتك تصل إلى حد معين ، ثم تقوم بحفظ الأوزان ، وتعيين معدل التعلم مرة أخرى ، والذي كان في بداية التدريب ، وبالتالي من هذا الحد الأدنى ، انتقل إلى مكان ما ، ثم قللت مرة أخرى معدل التعلم الخاص بك.
وبالتالي ، يمكنك زيارة العديد من المستويات المنخفضة في وقت واحد ، والتي ستتكبد فيها خسارة زائد أو ناقص. ولكن الحقيقة هي أن الشبكات ذات هذه الأوزان ستقدم أخطاء مختلفة في تاريخك. من خلال حساب متوسطها ، ستحصل على تقريب معين ، وستكون سرعتك أعلى.
حول كيف جمعنا نماذجنا. في بداية العرض التقديمي ، قلت للإهتمام بكمية البيانات في الاختبار وعدد الفصول. إذا أضفت 1 إلى عدد الأهداف في مجموعة الاختبار وقسمت على عدد الفصول ، فستحصل على الرقم 330 ، وقد كتب عن ذلك في المنتدى - أن الفصول في الاختبار متوازنة. هذا يمكن استخدامها.
بناءً على ذلك ، اخترع رومان سولوفيوف المقياس ، الذي أطلقنا عليه اسم Proxy Score ، والذي يرتبط جيدًا بلوحة المتصدرين. خلاصة القول هي: أن تقوم بعمل تنبؤ ، وتأخذ أعلى 1 من توقعاتك وتحسب عدد الكائنات لكل فئة. اطرح 330 من كل قيمة وأضف القيم المطلقة الناتجة.
تحولت هذه القيم بها. وقد ساعدنا ذلك في عدم القيام بلوحة اختبار ، ولكن للتحقق من الصحة محليًا وتحديد المعاملات لمجموعاتنا.
مع الفرقة يمكنك الحصول على مثل هذه السرعة. ماذا تفعل؟ افترض أنك استخدمت المعلومات التي تتوازن بها الفصول الموجودة في الاختبار.
كان التوازن مختلفا.
مثال واحد منهم هو تحقيق التوازن بين اللاعبين الذين فازوا بالمركز الأول.
ماذا فعلنا؟ كان توازننا بسيطًا جدًا ، وقد اقترحه إيفجيني باباخنين. قمنا أولاً بفرز توقعاتنا حسب أعلى 1 ومرشحين مختارين منهم - بحيث لا يتجاوز عدد الفصول 330. ولكن بالنسبة لبعض الفصول ، يتضح أن هناك توقعات أقل من 330. حسنًا ، دعنا نفرز حسب أفضل 2 وأعلى 3 ، وكذلك اختيار المرشحين.
كيف يختلف توازننا عن موازنة المركز الأول؟ لقد استخدموا منهجًا تكراريًا ، واستولوا على الفصل الأكثر شيوعًا وقللوا من احتمالات هذه الفئة بعدد قليل - حتى أصبحت هذه الفئة ليست الأكثر شعبية. أخذوا الطبقة الأكثر شعبية القادمة. أبعد من ذلك وخفض حتى أصبح عدد جميع الفئات متساوية.
استخدم الجميع منهجًا زائد أو ناقصًا لشبكات التدريب ، ولكن لم يستخدم الجميع الموازنة. باستخدام التوازن ، يمكن أن تذهب إلى الذهب ، وإذا كنت محظوظًا ، فأنت في حالة ماني.
كيفية تجهيز موعد؟ قام الجميع بمعالجة تاريخ علامة زائد بالطريقة نفسها بنفس الطريقة - فعلوا الميزات اليدوية ، وحاولوا ترميز التوقيت باستخدام حدود لون مختلفة ، إلخ. هذا هو بالضبط ما قاله Alexey Nozdrin-Plotnitsky ، الذي احتل المرتبة الثامنة.

لقد فعل بطريقة مختلفة. قال إن كل هذه الميزات اليدوية الخاصة بك لا تعمل ، فلست بحاجة إلى القيام بذلك ، يجب أن تتعلم شبكتك كل هذا بنفسك. وبدلاً من ذلك ، توصل إلى وحدات تعليمية قامت بمعالجة مسبقة لبياناتك. ألقى فيها البيانات المصدر دون معالجة مسبقة - إحداثيات النقاط والتوقيتات.
علاوة على ذلك ، أخذ الفرق في الإحداثيات ، وبلغ متوسطه خلال التوقيت. وحصل على مصفوفة طويلة إلى حد ما. لقد استخدم الإلتفاف 1D عدة مرات للحصول على مصفوفة 64xn ، حيث n هو العدد الإجمالي للنقاط ، و 64 من أجل إطعام المصفوفة الناتجة إلى طبقة من بعض الشبكات التلافيفية التي تقبل 64 قناة. لقد تحولت إلى مصفوفة 64xn ، ومن هنا كان من الضروري تكوين موتر من حجم ما بحيث يكون عدد القنوات 64. لقد قام بتطبيع جميع النقاط X و Y في النطاق من 0 إلى 32 لجعل موتر بحجم 32x32. لا أعرف لماذا أراد 32 × 32 ، لقد حدث ذلك. وفي هذا الإحداث ، وضع جزءًا من هذه المصفوفة بحجم 64xn. وهكذا ، حصل ببساطة على الموتر 32 × 32 × 64 ، والذي يمكن إضافته إلى شبكتك العصبية التلافيفية. لدي كل شيء.