
أود أن أعرض مفهوم
البرمجة الوظيفية للمبتدئين بأبسط الطرق ، مع تسليط الضوء على بعض مزاياها من العديد من الميزات الأخرى التي ستجعل الكود أكثر قابلية للقراءة والتعبير. لقد التقطت بعض العروض التوضيحية المثيرة للاهتمام بالنسبة لك الموجودة في
Playground Github .
البرمجة الوظيفية: التعريف
بادئ ذي بدء ،
البرمجة الوظيفية ليست لغة أو بناء جملة ، ولكن على الأرجح وسيلة لحل المشكلات عن طريق تقسيم العمليات المعقدة إلى عمليات أكثر بساطة وتكوينها اللاحق. كما يوحي الاسم ، "
البرمجة الوظيفية "
، فإن وحدة التكوين لهذا النهج هي
وظيفة ؛ والغرض من هذه
الوظيفة هو تجنب تغيير الحالة أو القيم خارج
scope) .
في
Swift World ، توجد جميع الشروط لذلك ، لأن
الوظائف هنا هي مشاركة كاملة في عملية البرمجة مثل
الكائنات ، ويتم حل مشكلة
mutation على مستوى مفهوم
value TYPES (الهياكل الهيكلية
enum التعداد) التي تساعد في إدارة قابلية التحويل (
mutation والتواصل بوضوح كيف ومتى يمكن أن يحدث هذا.
ومع ذلك ، فإن
Swift ليست بالمعنى الكامل للغة
البرمجة الوظيفية ، فهي لا تجبرك على
البرمجة الوظيفية ، على الرغم من أنها تدرك مزايا النهج
الوظيفية وتجد طرقًا لتضمينها.
في هذه المقالة ، سنركز على استخدام العناصر المدمجة في
البرمجة الوظيفية في
Swift (أي ، "خارج الصندوق") وفهم كيف يمكنك استخدامها بشكل مريح في التطبيق الخاص بك.
النهج الحتمية والوظيفية: المقارنة
لتقييم النهج
الوظيفي ، دعونا نقارن الحلول ببعض المشكلات البسيطة بطريقتين مختلفتين. الحل الأول هو "ضروري"
، حيث يغير الكود الحالة داخل البرنامج.
لاحظ أننا نتعامل مع القيم الموجودة داخل الصفيف القابلة للتغيير القابلة للتغيير ، ثم نطبعها على وحدة التحكم. بالنظر إلى هذا الرمز ، حاول الإجابة على الأسئلة التالية التي سنناقشها في المستقبل القريب:
- ما الذي تحاول تحقيقه باستخدام الكود الخاص بك؟
- ماذا يحدث إذا حاول
thread آخر الوصول إلى مجموعة numbers أثناء تشغيل الرمز الخاص بك؟ - ماذا يحدث إذا كنت تريد الوصول إلى القيم الأصلية في مجموعة
numbers ؟ - كيف يمكن الاعتماد عليها هذا الرمز؟
الآن دعونا نلقي نظرة على نهج "
وظيفي " بديل:
في هذه الشفرة ، نحصل على نفس النتيجة على وحدة التحكم ، ونقترب من حل المشكلة بطريقة مختلفة تمامًا. لاحظ أن مجموعة
numbers هذه المرة غير قابلة للتغيير بفضل الكلمة الرئيسية
let . لقد
timesTen() عملية ضرب الأرقام من صفيف
numbers إلى الأسلوب
timesTen() ، الموجود في ملحق
extension Array . ما زلنا نستخدم حلقة من
for تعديل متغير يسمى
output ، لكن
scope هذا المتغير محدود فقط بهذه الطريقة. وبالمثل ، يتم تمرير
self وسيطة الإدخال الخاصة بنا إلى الأسلوب
timesTen() حسب القيمة (
by value ) ، مع وجود نفس نطاق إخراج الإخراج المتغير. يتم
timesTen() الأسلوب
timesTen() ، ويمكننا الطباعة على كل من صفيف
numbers الأصلية ونتيجة صفيف
result .
دعنا نعود إلى الأسئلة الأربعة.
1. ما الذي تحاول تحقيقه باستخدام الكود؟في مثالنا ، نؤدي مهمة بسيطة للغاية بضرب الأرقام في صفيف
numbers 10 .
مع اتباع نهج
حتمي ، من أجل الحصول على مخرجات ، يجب عليك التفكير كجهاز كمبيوتر ، باتباع الإرشادات الواردة في الحلقة
for . في هذه الحالة ، يُظهر الرمز
تحقيق النتيجة. باستخدام النهج
الوظيفي ، يتم "لف"
يتم "التفاف" في الأسلوب
timesTen() . شريطة أن يتم تنفيذ هذه الطريقة في مكان آخر ، يمكنك فقط رؤية تعبير
numbers.timesTen() . يوضح هذا الرمز بوضوح
تحقيقه من خلال هذا الرمز ، وليس
حل المهمة. وهذا ما يسمى
البرمجة التصريحية ، ومن السهل تخمين سبب كون هذا النهج جذابًا.
إن الطريقة الحتمية تجعل المطور يفهم
الكود من أجل تحديد
يجب عليه فعله.
يعتبر النهج
الوظيفي مقارنة بالنهج
الضروري أكثر تعبيرية ويوفر للمطور فرصة فاخرة للافتراض ببساطة أن الطريقة تفعل ما تدعي القيام به! (من الواضح أن هذا الافتراض ينطبق فقط على الكود الذي تم التحقق منه مسبقًا).
2. ماذا يحدث إذا حاول thread آخر الوصول إلى مجموعة numbers أثناء تشغيل الرمز الخاص بك؟توجد الأمثلة المذكورة أعلاه في مساحة معزولة تمامًا ، على الرغم من أنه في بيئة معقدة متعددة الخيوط ، من الممكن تمامًا أن يحاول
threads متشابهان الوصول إلى نفس الموارد في وقت واحد. في حالة النهج
Imperative ، من السهل أن ترى أنه عندما يكون
thread آخر حق الوصول إلى صفيف
numbers في عملية استخدامه ، سيتم إملاء النتيجة حسب الترتيب الذي تصل به
threads إلى صفيف
numbers . هذا الموقف يسمى
race condition ويمكن أن يؤدي إلى سلوك غير متوقع وحتى عدم استقرار وتعطل التطبيق.
في المقابل ، فإن النهج
الوظيفي ليس له "آثار جانبية". بمعنى آخر ، لا يؤدي
output طريقة
output تغيير أي قيم مخزنة في نظامنا ويتم تحديده فقط من خلال الإدخال. في هذه الحالة ، فإن أي مؤشر ترابط (
threads ) لديه حق الوصول إلى صفيف
numbers سيحصل دائمًا على نفس القيم وسيظل سلوكه ثابتًا ويمكن التنبؤ به.
3. ماذا يحدث إذا كنت ترغب في الوصول إلى القيم الأصلية المخزنة في مجموعة
numbers ؟
هذا هو استمرار لمناقشتنا من "الآثار الجانبية". من الواضح ، لا يتم تعقب تغييرات الحالة. لذلك ، مع النهج "
الإلزامي" ، نفقد الحالة الأولية لمجموعة
numbers لدينا أثناء عملية التحويل. يقوم حلنا ، استنادًا إلى النهج
الوظيفي ، بحفظ مجموعة
numbers الأصلية وإنشاء مجموعة
result جديدة مع الخصائص المطلوبة في الإخراج. إنه يترك مجموعة
numbers الأصلية سليمة ومناسبة للمعالجة المستقبلية.
4. كيف يمكن الاعتماد عليها هذا الرمز؟
نظرًا لأن النهج
الوظيفي يدمر كل "الآثار الجانبية" ، فإن الوظيفة المختبرة موجودة داخل الطريقة تمامًا. لن يواجه إدخال هذه الطريقة أي تغييرات ، لذلك يمكنك اختبار عدة مرات باستخدام الدورة كما تشاء ، وستحصل دائمًا على نفس النتيجة. في هذه الحالة ، الاختبار سهل للغاية. في المقابل ، سيؤدي اختبار الحل
الضروري في حلقة إلى تغيير بداية الإدخال وستحصل على نتائج مختلفة تمامًا بعد كل تكرار.
ملخص الفوائد
كما رأينا من مثال بسيط للغاية ، فإن الأسلوب
الوظيفي هو شيء رائع إذا كنت تتعامل مع نموذج البيانات بسبب:
- إنه إعلاني
- يعمل على إصلاح المشكلات المتعلقة بسلسلة
race condition مثل race condition والجمود - يترك الحالة دون تغيير ، والتي يمكن استخدامها للتحولات اللاحقة.
- إنه سهل الاختبار.
دعنا نذهب أبعد من ذلك قليلا في تعلم البرمجة
الوظيفية في
Swift . يفترض أن "الجهات الفاعلة" الرئيسية هي الوظائف ، ويجب أن تكون في المقام الأول
كائنات من الدرجة الأولى .
وظائف الدرجة الأولى ووظائف الرتب العليا
لكي تكون الوظيفة من الدرجة الأولى ، يجب أن يكون لديها القدرة على التصريح كمتغير. يتيح لك ذلك إدارة الوظيفة كنوع عادي من البيانات وتنفيذها في نفس الوقت. لحسن الحظ ، في
Swift الدوال هي كائنات من الدرجة الأولى ، أي ، يتم دعمها بتمريرها كوسائط إلى وظائف أخرى ، أو إعادتها كنتيجة لوظائف أخرى ، أو تخصيصها للمتغيرات ، أو تخزينها في بنيات البيانات.
لهذا السبب ، لدينا وظائف أخرى في
Swift - وظائف ذات ترتيب أعلى يتم تعريفها على أنها وظائف تأخذ وظيفة أخرى كوسيطة أو تقوم بإرجاع دالة. هناك العديد منها:
map ،
filter ،
reduce ،
forEach ،
flatMap ،
compactMap ،
sorted ، إلخ. الأمثلة الأكثر شيوعًا لوظائف الرتب العليا هي
map filter reduce . فهي ليست عالمية ، كلها "مرتبطة" ببعض أنواعها. إنها تعمل على جميع أنواع
Sequence TYPES ، بما في ذلك
Collection ، والتي تمثلها هياكل البيانات
Swift مثل
Array ،
Dictionary و
Set . في
Swift 5 ، تعمل وظائف الترتيب العالي أيضًا مع نتيجة TYPE جديدة تمامًا.
map(_:)
في
Swift map(_:) تأخذ دالة كمعلمة وتحول قيم
معينة وفقًا لهذه الوظيفة. على سبيل المثال ، بتطبيق
map(_:) على
Array قيم
Array ، فإننا نطبق دالة معلمة على كل عنصر من عناصر المصفوفة الأصلية ونحصل على صفيف
Array ، لكن القيم المحولة ، كذلك.
في التعليمة البرمجية أعلاه ، أنشأنا
timesTen (_:Int) الوظيفية
timesTen (_:Int) ، والتي تأخذ قيمة عدد صحيح
Int وتُرجع قيمة عدد صحيح
Int مضروبة في
10 ، واستخدمناها كمعلمة إدخال في
map(_:) العليا
map(_:) ، وتطبيقها على صفيفنا
numbers . حصلنا على النتيجة التي نحتاجها في مجموعة
result .
اسم دالة المعلمة
timesTen للوظائف ذات الترتيب الأعلى مثل
map(_:) لا يهم ، ونوع المعلمة المدخلة وقيمة الإرجاع مهمان ، أي أن التوقيع
(Int) -> Int معلمة الإدخال الوظيفي. لذلك ، يمكننا استخدام وظائف مجهولة في
map(_:) - عمليات الإغلاق - بأي شكل ، بما في ذلك تلك التي لها أسماء وسيطات مختصرة
$0 ،
$1 ، إلخ.
إذا نظرنا إلى
map(_ :) وظيفة
Array ، فقد يبدو مثل هذا:
func map<T>(_ transform: (Element) -> T) -> [T] { var returnValue = [T]() for item in self { returnValue.append(transform(item)) } return returnValue }
يعد هذا رمزًا إلزاميًا مألوفًا بالنسبة إلينا ، ولكنه لم يعد يمثل مشكلة مطور أو مشكلة
Apple مشكلة
Swift . تم تحسين تطبيق
map(_:) ذات الترتيب العالي
map(_:) بواسطة
Apple من حيث الأداء ، ونحن مطورو البرامج مضمونون
map(_:) وظيفة ، حتى نتمكن من التعبير بشكل صحيح فقط مع وظيفة وسيطة
transform نريد دون القلق بشأن
سيتم تنفيذه. نتيجة لذلك ، نحصل على رمز يمكن قراءته تمامًا في شكل سطر واحد ، والذي سيعمل بشكل أفضل وأسرع.
قد لا يتزامن
المرتجع بواسطة دالة المعلمة مع
للعناصر في المجموعة الأصلية.
في التعليمة البرمجية أعلاه ، لدينا عدد صحيح
possibleNumbers من
failable ،
failable ، ونريد تحويلها إلى أعداد صحيحة من
Int ، باستخدام
failable Int(_ :String) يمثله الإغلاق
{ str in Int(str) } . نفعل ذلك باستخدام
map(_:) ونحصل على مجموعة معيّنة من
Optional كإخراج:

نتمكن من تحويل
عناصر صفيفتنا
possibleNumbers إلى أعداد صحيحة ، ونتيجة لذلك ، تلقى جزء ما قيمة
nil ، مما يشير إلى استحالة تحويل
String إلى عدد صحيح
Int ، والجزء الآخر تحول إلى
Optionals ، والتي لها قيم:
print (mapped)
compactMap(_ :)
إذا كانت وظيفة المعلمة التي تم تمريرها إلى الدالة ذات الترتيب الأعلى لها قيمة
Optional في المخرجات ، فقد يكون من المفيد استخدام وظيفة أخرى ذات ترتيب أعلى ، على نحو مماثل في المعنى -
compactMap(_ :) ، والتي تقوم بنفس الشيء مثل
map(_:) ، ولكن بالإضافة إلى ذلك "يوسع" القيم التي يتم تلقيها في الإخراج
Optional ويزيل قيم
nil من المجموعة.

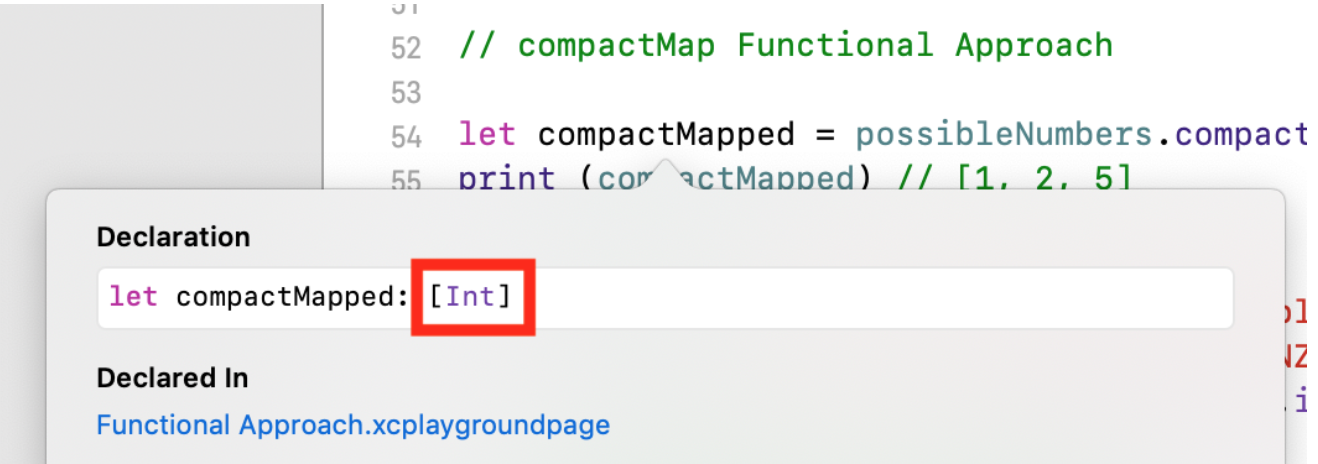
في هذه الحالة ، نحصل على مجموعة من TYPE
compactMapped [Int] ، ولكن ربما أصغر:
let possibleNumbers = ["1", "2", "three", "///4///", "5"] let compactMapped = possibleNumbers.compactMap(Int.init) print (compactMapped)
كلما كنت تستخدم
init?() Initializer كدالة تحويل ، سيتعين عليك استخدام
compactMap(_ :) :
يجب أن أقول أن هناك أكثر من الأسباب الكافية لاستخدام
compactMap(_ :) الدالة ذات الترتيب
compactMap(_ :) .
Swift "يحب" القيم
Optional ، يمكن الحصول عليها ليس فقط عن طريق استخدام
init?() "
failable "
init?() ، ولكن أيضًا باستخدام
as? "الصب"
:
let views = [innerView,shadowView,logoView] let imageViews = views.compactMap{$0 as? UIImageView}
...
try? عند معالجة الأخطاء التي ألقيت بها بعض الأساليب. يجب أن أقول أن
Apple تشعر بالقلق من أن استخدام
try? في كثير من الأحيان يؤدي إلى مضاعفة
Optional وفي
Swift 5 يترك الآن مستوى
Optional واحد فقط بعد تطبيق
try? .
هناك وظيفة واحدة أكثر مماثلة في اسم
flatMap(_ :) ذات الترتيب العالي
flatMap(_ :) ، أي أقل قليلاً منها.
في بعض الأحيان ، لاستخدام
map(_:) الوظائف ذات الترتيب الأعلى
map(_:) ، من المفيد استخدام طريقة
zip (_:, _:) لإنشاء سلسلة من الأزواج من تسلسلين مختلفين.
لنفترض أن لدينا
view حول عدة نقاط يتم تمثيلها ، مترابطة معًا وتشكل خطًا معطلًا:
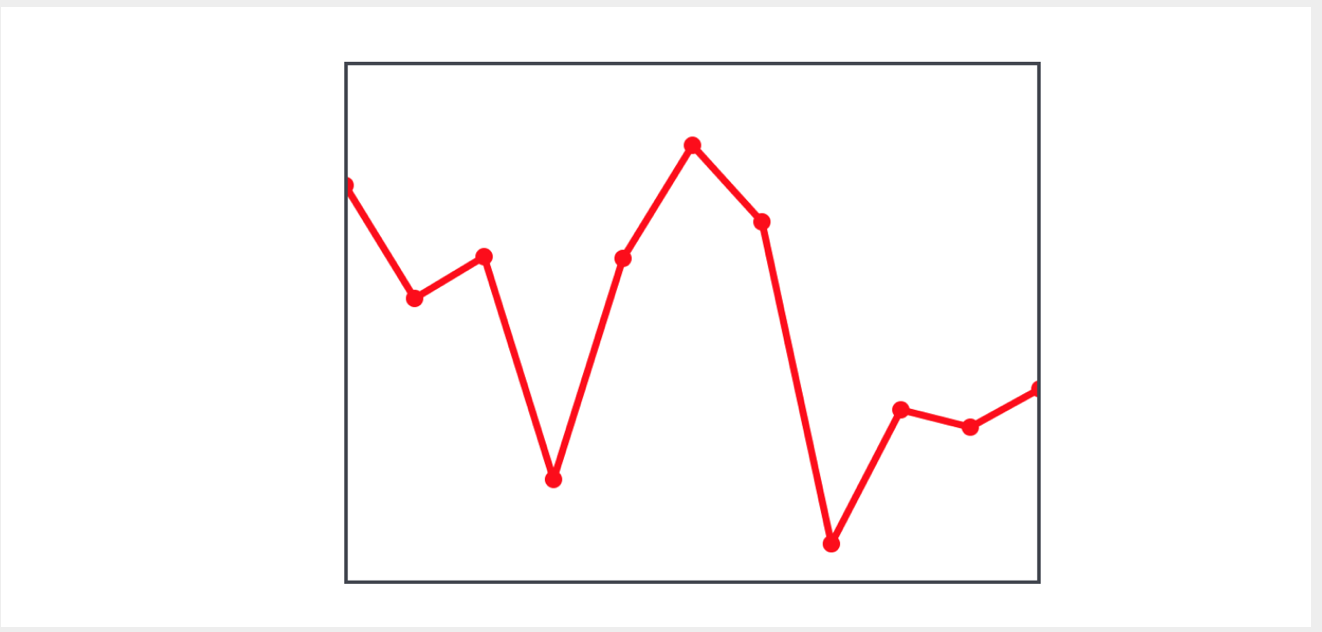
نحتاج إلى بناء خط معطل آخر يربط النقاط الوسطى لشرائح الخط المعطوب الأصلي:

من أجل حساب نقطة المنتصف للقطعة ، يجب أن نحصل على إحداثيات نقطتين: الحالية والأخرى. للقيام بذلك ، يمكننا تشكيل تسلسل يتكون من أزواج من النقاط - الحالية والقادمة - باستخدام
zip (_:, _:) ، حيث سنستخدم مجموعة نقاط نقاط البداية ومجموعة من النقاط التالية.
points.dropFirst() :
let pairs = zip (points,points.dropFirst()) let averagePoints = pairs.map { CGPoint(x: ($0.x + $1.x) / 2, y: ($0.y + $1.y) / 2 )}
لدينا مثل هذا التسلسل ، فنحن نحسب نقاط المنتصف بسهولة شديدة باستخدام
map(_:) الوظائف ذات الترتيب العالي
map(_:) ونعرضها على الرسم البياني.
filter (_:)
في
Swift ، يتوفر
filter (_:) الترتيب العالي
filter (_:) لمعظم الأنواع التي تتوفر بها
map(_:) . يمكنك تصفية أي
Sequence تسلسل مع
filter (_:) ، وهذا واضح! يأخذ
filter (_:) طريقة وظيفة أخرى كمعلمة ، وهو شرط لكل عنصر من عناصر التسلسل ، وإذا تم استيفاء الشرط ، فسيتم تضمين العنصر في النتيجة ، وإذا لم يكن كذلك ، فلا يتم تضمينه. تأخذ هذه "الوظيفة الأخرى" قيمة واحدة - عنصرًا من
Sequence التسلسل - وتقوم بإرجاع
Bool ، وهو ما يسمى المسند.
على سبيل المثال ، بالنسبة لصفائف
Array ، يطبق
filter (_:) الوظيفة ذو الترتيب العالي
filter (_:) الدالة المسند وإرجاع صفيف آخر يتكون فقط من تلك العناصر في المصفوفة الأصلية التي ترجع دالة تقدير المدخلات لها إلى
true .
هنا ، يأخذ
filter (_:) الوظائف ذات الترتيب العالي
filter (_:) كل عنصر من عناصر مجموعة
numbers (يمثلها
$0 ) ويتحقق لمعرفة ما إذا كان هذا العنصر هو رقم زوجي. إذا كان هذا رقمًا
filted ،
filted تسقط عناصر صفيف
numbers في الصفيف
filted الجديد ، وإلا لا. أبلغنا البرنامج في شكل إعلان
الذي نريد أن نحصل عليه بدلاً من الاهتمام
القيام بذلك.
سأقدم مثالًا آخر على استخدام
filter (_:) الوظائف ذات الترتيب العالي
filter (_:) للحصول على أول
20 رقم فيبوناتشي فقط بقيمة
< 4000 :
let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
نحصل على سلسلة من tuples تتكون من عنصرين من تسلسل Fibonacci: n-th و (n + 1) - th:
(0, 1), (1, 1), (1, 2), (2, 3), (3, 5) …
لمزيد من المعالجة ، نقتصر عدد العناصر على العناصر الحادية والعشرين باستخدام
prefix (20) ونأخذ العنصر
0 من المجموعة التي تم إنشاؤها باستخدام
map {$0.0 } ، والتي تتوافق مع تسلسل فيبوناتشي الذي يبدأ بـ
0 :
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
يمكن أن نأخذ العنصر
1 من الصفوف المشكلة باستخدام
map {$0.1 } ، والتي تتوافق مع تسلسل فيبوناتشي بدءًا من
1 :
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,...
نحصل على العناصر التي نحتاج إليها بمساعدة
filter {$0 % 2 == 0 && $0 < 4000} الوظائف ذات الترتيب العالي
filter {$0 % 2 == 0 && $0 < 4000} ، والتي تُرجع مجموعة من عناصر التسلسل التي تفي بالتنبؤ المحدد. في حالتنا ، ستكون مجموعة من الأعداد الصحيحة
[Int] :
[0, 2, 8, 34, 144, 610, 2584]
يوجد مثال آخر مفيد لاستخدام
filter (_:) for
Collection .
واجهت
مشكلة حقيقية واحدة ، عندما يكون لديك مجموعة من
images التي يتم عرضها باستخدام
CollectionView ، وباستخدام تقنية
Drag & Drop يمكنك جمع مجموعة كاملة من الصور ونقلها في كل مكان ، بما في ذلك إسقاطها على " علبة القمامة ".

في هذه الحالة ، يتم إصلاح مجموعة الفهارس التي
removedIndexes مؤشرات
removedIndexes تفريغها في "علبة المهملات" ، وستحتاج إلى إنشاء مجموعة جديدة من الصور ، باستثناء تلك الفهارس الموجودة في المصفوفة
removedIndexes . لنفترض أن لدينا مجموعة من الأعداد الصحيحة
images التي تحاكي الصور ، ومجموعة من الفهارس لهذه الأعداد الصحيحة التي تمت إزالتها والتي تحتاج إلى إزالتها. سنستخدم
filter (_:) لحل مشكلتنا:
var images = [6, 22, 8, 14, 16, 0, 7, 9] var removedIndexes = [2,5,0,6] var images1 = images .enumerated() .filter { !removedIndexes.contains($0.offset) } .map { $0.element } print (images1)
الأسلوب
enumerated() بإرجاع سلسلة من tuples يتكون من مؤشرات
offset وقيم
element الصفيف.
بعد ذلك ، نقوم بتطبيق مرشح filterعلى التسلسل الناتج من tuples ، مع ترك فقط أولئك الذين $0.offsetلا يوجد فهرس في الصفيف removedIndexes. في الخطوة التالية ، نختار القيمة من المجموعة $0.elementونحصل على المجموعة التي نحتاجها images1.reduce (_:, _:)
طريقة reduce (_:, _:)متاح أيضا أكثر من map(_:)و filter (_:). طريقة reduce (_:, _:)"انهيار" التسلسل Sequenceإلى قيمة المتراكمة واحدة ولها اثنين من المعلمات. المعلمة الأولى هي قيمة البدء التراكمية ، والمعلمة الثانية هي وظيفة تجمع بين القيمة التراكمية وعنصر التسلسل Sequenceللحصول على قيمة تجميع جديدة.يتم تطبيق وظيفة معلمة الإدخال على كل عنصر من عناصر التسلسل Sequence، واحدة تلو الأخرى ، حتى تصل إلى النهاية وتخلق القيمة التراكمية النهائية. let sum = Array (1...100).reduce(0, +)
هذا مثال تافه كلاسيكي لاستخدام دالة ترتيب أعلى reduce (_:, _:)- حساب مجموع عناصر الصفيف Array. 1 0 1 0 +1 = 1 2 1 2 2 + 1 = 3 3 3 3 3 + 3 = 6 4 6 4 4 + 6 = 10 . . . . . . . . . . . . . . . . . . . 100 4950 100 4950 + 100 = 5050
باستخدام الوظيفة ، reduce (_:, _:)يمكننا ببساطة حساب مجموع أرقام فيبوناتشي التي تفي بشرط معين: let fibonacci = sequence(first: (0, 1), next: { ($1, $0 + $1) }) .prefix(20).map{$0.0} .filter {$0 % 2 == 0 && $0 < 4000} print (fibonacci)
ولكن هناك تطبيقات أكثر إثارة للدالة العليا reduce (_:, _:).على سبيل المثال ، يمكننا تحديد معلمة مهمة جدًا وبسيطة جدًا UIScrollView- لحجم المنطقة "القابلة للتمرير" contentSize- استنادًا إلى حجمها subviews: let scrollView = UIScrollView() scrollView.addSubview(UIView(frame: CGRect(x: 300.0, y: 0.0, width: 200, height: 300))) scrollView.addSubview(UIView(frame: CGRect(x: 100.0, y: 0.0, width: 300, height: 600))) scrollView.contentSize = scrollView.subviews .reduce(CGRect.zero,{$0.union($1.frame)}) .size
في هذا العرض التوضيحي ، تكون القيمة التراكمية GCRect، والعملية التراكمية هي عملية الجمع بين unionالمستطيلات التي frameلدينا subviews.على الرغم من حقيقة أن وظيفة الترتيب الأعلى reduce (_:, _:)تفترض طابعًا تراكميًا ، يمكن استخدامها في منظور مختلف تمامًا. على سبيل المثال ، لتقسيم tuple إلى أجزاء في مجموعة من tuples:
4.2قدم سويفت نوعًا جديدًا من وظائف الترتيب العالي reduce (into:, _:). تعتبر الطريقة reduce (into:, _:)مفضلة في الكفاءة مقارنة بالطريقة reduce (:, :)إذا COW (copy-on-write) Arrayأو تم استخدامها كهيكل ناتج Dictionary.يمكن استخدامه بفعالية لإزالة القيم المطابقة في مجموعة من الأعداد الصحيحة:
... أو عند حساب عدد العناصر المختلفة في صفيف:
flatMap (_:)
قبل الانتقال إلى هذه الوظيفة ذات الترتيب العالي ، دعونا ننظر إلى عرض بسيط للغاية. let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
إذا قمنا بتشغيل هذه التعليمة البرمجية للتنفيذ Playground، فسيبدو كل شيء جيدًا ، ولنا firstNumberمتساوون 42: لكن إذا كنت لا تعرف ،
لكن إذا كنت لا تعرف ، Playgroundفغالبًا ما يخفي الكود الحقيقي firstNumber. في الواقع، فإن الثابت firstNumberهو Optional: يحدث هذا بسبب
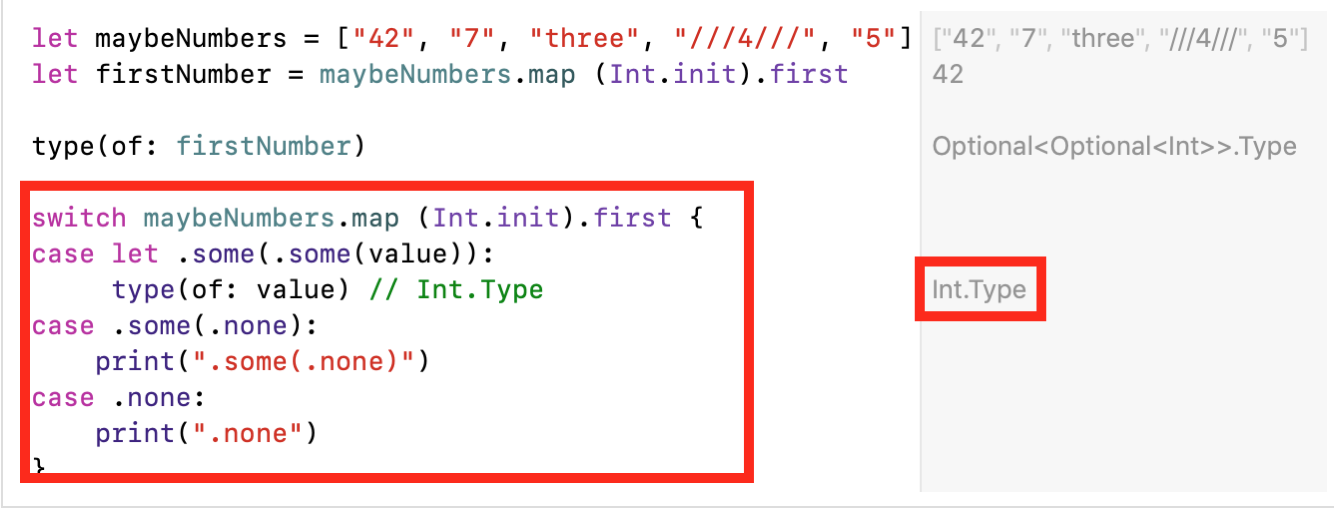
يحدث هذا بسبب map (Int.init)صفيف الإخراج يولد Optionalالقيم نوع [Int?]حيث أن كل خط ليست Stringقادرة على تحويل Intومهيئ Int.intهو "السقوط" ( failable). ثم نأخذ العنصر الأول للصفيف المشكل باستخدام دالة firstالمصفوفة Array، والتي تشكل أيضًا الإخراجOptional، نظرًا لأن الصفيف قد يكون فارغًا ولن نتمكن من الحصول على العنصر الأول من الصفيف. نتيجة لذلك ، لدينا Optionalنوعان مزدوجان ، أيInt?? .
حصلنا على بنية متداخلة Optionalفي Optional، الذي هو في الحقيقة من الصعب العمل، والتي نحن بطبيعة الحال لا تريد أن يكون. من أجل الحصول على القيمة من هذا الهيكل المتداخل ، يتعين علينا "الغوص" في مستويين. بالإضافة إلى ذلك ، يمكن لأي تحويلات إضافية تعميق المستوى Optionalأقل.الحصول على القيمة من المتداخلة المزدوجة Optionalمرهق للغاية.لدينا 3 خيارات وكلها تتطلب معرفة متعمقة للغة Swift.if let , ; «» «» Optional , — «» Optional :

if case let ( pattern match ) :

?? :

- ,
switch :
والأسوأ من ذلك ، genericحاويات معممة ( ) يتم تعريف العملية لها map. على سبيل المثال ، للصفائف Array.النظر في مثال آخر رمز. افترض أن لدينا نصًا متعدد الأسطر multilineStringنريد تقسيمه إلى كلمات مكتوبة بأحرف صغيرة (صغيرة): let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .map{$0.split(separator: " ")}
من أجل الحصول على مجموعة من الكلمات words، نجعل أولاً الأحرف الكبيرة (الصغيرة) صغيرة (صغيرة) باستخدام الطريقة lowercased()، ثم نقسم النص إلى split(separatot: "\n")أسطر باستخدام الطريقة ونحصل على مجموعة من السلاسل ، ثم نستخدمها map {$0.split(separator: " ")}لفصل كل سطر في كلمات منفصلة.نتيجة لذلك ، حصلنا على صفائف متداخلة: [["", ",", "", ","], ["", "", ";", "", "", "", "", ",", "—"], ["", ",", "", "", ":"], ["", "—", "", "", ",", "", "", "."], ["", "", ",", "", "", ","], ["", "", ".", "", ""], ["", ".", "", ",", ""], ["", "", "", ""], ["", "", ",", "", "«", "»"], ["", ".", "", ","], ["", ",", "", "", "!"]]
... wordsوله Array: حصلنا مرة أخرى على بنية بيانات "متداخلة" ، لكن هذه المرة لم نكن
حصلنا مرة أخرى على بنية بيانات "متداخلة" ، لكن هذه المرة لم نكن Optional، لكن Array. إذا أردنا متابعة معالجة الكلمات المستلمة words، على سبيل المثال ، للعثور على طيف الحروف في هذا النص متعدد الأسطر ، فسوف يتعين علينا أولاً "ضبط" الصفيف المزدوج Arrayوتحويله إلى صفيف مفرد Array. هذا مشابه لما فعلناه مع ضعف Optionalالعرض التوضيحي في بداية هذا القسم حول flatMap: let maybeNumbers = ["42", "7", "three", "///4///", "5"] let firstNumber = maybeNumbers.map (Int.init).first
لحسن الحظ ، Swiftلا يتعين علينا اللجوء إلى الإنشاءات النحوية المعقدة. Swiftيزودنا بحل جاهز للصفائف Arrayو Optional. هذه هي وظيفة ترتيب أعلى flatMap! يشبه إلى حد كبير map، ولكن لديه وظائف إضافية المرتبطة "استقامة" لاحقة من "المرفقات" التي تظهر أثناء التنفيذ map. وهذا هو السبب في أن يطلق flatMapعليه ، "تصويب" ( flattens) النتيجة map.دعنا نحاول التقديم flatMapعلى firstNumber: لقد حصلنا بالفعل على مستوى بمستوى واحد
لقد حصلنا بالفعل على مستوى بمستوى واحد Optional. يعملأكثر إثارة للاهتمام flatMapلمجموعة Array. في تعبيرنا عن ، wordsنحن ببساطة استبدال mapمعflatMap: ... ونحصل فقط على مجموعة من الكلمات
... ونحصل فقط على مجموعة من الكلمات wordsدون أي "تداخل": ["", ",", "", ",", "", "", ";", "", "", "", "", ",", "—", "", ",", "", "", ":", "", "—", "", "", ",", "", "", ".", "", "", ",", "", "", ",", "", "", ".", "", "", "", ".", "", ",", "", "", "", "", "", "", "", ",", "", "«", "»", "", ".", "", ",", "", ",", "", "", "!"]
الآن يمكننا متابعة المعالجة التي نحتاجها لمجموعة الكلمات الناتجة words، لكن كن حذرًا. إذا قمنا بتطبيقه مرة أخرى flatMapعلى كل عنصر من عناصر الصفيف words، فسنحصل على نتيجة غير متوقعة ولكنها مفهومة تمامًا. نحصل على مجموعة واحدة ، وليس "متداخلة" من الحروف والرموز
نحصل على مجموعة واحدة ، وليس "متداخلة" من الحروف والرموز [Character]الموجودة في عبارة متعددة الأسطر لدينا: ["", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ",", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ";", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ...]
الحقيقة هي أن السلسلة Stringعبارة عن مجموعة من Collectionالأحرف [Character]، ونطبق flatMapمرة أخرى على كل كلمة على حدة ، ونخفض مرة أخرى مستوى "التداخل" ونصل إلى مجموعة من الأحرف flattenCharacters.ربما هذا هو بالضبط ما تريد ، أو ربما لا. انتبه لهذا.وضع كل ذلك معًا: حل بعض المشكلات
المهمة 1
يمكننا متابعة المعالجة التي نحتاجها لمجموعة الكلمات التي تم الحصول عليها في القسم السابق words، وحساب تكرار حدوث الحروف في عبارة متعددة الأسطر. أولاً ، دعونا "نلصق" كل الكلمات من الصفيف wordsفي سطر واحد كبير ونستبعد كل علامات الترقيم منه ، أي ، اترك الحروف فقط: let wordsString = words.reduce ("",+).filter { "" .contains($0)}
لذلك ، حصلنا على كل الحروف التي نحتاجها. الآن لنجعل قاموسًا لهم ، حيث يكون المفتاح keyهو الحرف ، والقيمة valueهي تواتر حدوثه في النص.يمكننا القيام بذلك بطريقتين.ترتبط الطريقة الأولى باستخدام Swift 4.2مجموعة متنوعة جديدة من وظائف الترتيب العالي التي ظهرت فيها reduce (into:, _:). هذه الطريقة مناسبة تمامًا لنا لتنظيم قاموس letterCountبتكرار حدوث الحروف في عبارة متعددة الأسطر: let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} print (letterCount)
نتيجة لذلك ، سوف نحصل على قاموس letterCount [Character : Int]فيه المفاتيح keyهي الأحرف الموجودة في العبارة قيد الدراسة ، وبما أن القيمة valueهي عدد هذه الأحرف. تتضمنالطريقة الثانية تهيئة القاموس باستخدام التجميع ، مما يعطي نفس النتيجة: let letterCountDictionary = Dictionary(grouping: wordsString ){ $0}.mapValues {$0.count} letterCount == letterCountDictionary
نود فرز القاموس letterCountأبجديًا: let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
لكن لا يمكننا فرز القاموس مباشرة Dictionary، لأنه في الأساس ليس بنية بيانات مرتبة. إذا طبقنا الوظيفة sorted (by:)على القاموس Dictionary، فسترجع إلينا عناصر التسلسل المصنفة مع المسند المعطى في شكل مجموعة من الصفوف المسماة ، والتي mapنتحول إلى مجموعة من السلاسل التي [":17", ":5", ":18", ...]تعكس تكرار حدوث الحرف المقابل.نرى أنه في هذه المرة sorted (by:)يتم تمرير العامل <" " فقط كمسند لوظيفة ذات ترتيب أعلى . وظيفة sorted (by:)ينتظر عند مدخل "مقارنة وظيفة"، كما الحجة الوحيدة. يتم استخدامه لمقارنة قيمتين متجاورتين وتحديد ما إذا كان قد تم ترتيبهما بشكل صحيح (في هذه الحالة ، يتم إرجاعtrue) أم لا (العودة false). يمكننا إعطاء وظائف "وظيفة المقارنة" هذه sorted (by:)في شكل إغلاق مجهول: sorted(by: {$0.key < $1.key}
ويمكننا فقط أن نعطيه المشغل " <" ، الذي يحمل التوقيع الذي نحتاجه ، كما تم أعلاه. هذه أيضًا وظيفة ، والفرز حسب المفتاح قيد التنفيذ key.إذا أردنا تصنيف القاموس حسب القيم valueومعرفة الحروف التي توجد في أغلب الأحيان في هذه العبارة ، فسوف يتعين علينا استخدام الإغلاق للدالة sorted (by:): let countsStat = letterCountDictionary .sorted(by: {$0.value > $1.value}) .map{"\($0.0):\($0.1)"} print (countsStat )
إذا ألقينا نظرة على حل مشكلة تحديد طيف الحروف لعبارة متعددة الأسطر ككل ... let multilineString = """ , , ; , — , : — , . , , . . , , « » . , , ! """ let words = multilineString.lowercased() .split(separator: "\n") .flatMap{$0.split(separator: " ")} let wordsString = words.reduce ("",+).filter { "" .contains($0)} let letterCount = wordsString.reduce(into: [:]) { counts, letter in counts[letter, default: 0] += 1} let lettersStat = letterCountDictionary .sorted(by: <) .map{"\($0.0):\($0.1)"} print (lettersStat)
... ثم سنلاحظ أنه في جزء التعليمات البرمجية هذا لا يوجد أي متغيرات (لا var، فقط let)جميع أسماء الوظائف المستخدمة تعكس ACTIONS (وظائف) على معلومات معينة ، وليس على الإطلاق القلق بشأن كيفية تنفيذ هذه الإجراءات:split- split ،map- convertflatMap- convert with محاذاة (عن طريق إزالة مستوى واحد من تداخل)،filter- مرشح،sorted- والفرز، وreduce- لتحويل البيانات إلى بنية معينة عن طريق عملية محددةفي هذا جزء من كل سطر من التعليمات البرمجية يوضح اسم الدالة التي نستخدمها إذا كنا في. يملأ يستخدم "النقي" التحول mapلو لعبنا يستخدم تحويل مستوى التداخلflatMap، إذا أردنا تحديد بيانات معينة فقط ، فإننا نستخدمها filter، إلخ. كل هذه الوظائف من "أعلى ترتيب" تم تصميمها واختبارها Appleمع مراعاة تحسين الأداء. إذاً هذا الجزء من الشفرة موثوق وموجز للغاية - لم نكن بحاجة إلى أكثر من 5 جمل لحل مشكلتنا. هذا مثال على البرمجة الوظيفية.العيب الوحيد لتطبيق النهج الوظيفي في هذا العرض التوضيحي هو أنه ، من أجل الثبات والقابلية للاختبار وقابلية القراءة ، نطارد نصنا مرارًا وتكرارًا من خلال وظائف متعددة ذات ترتيب أعلى. في حالة وجود عدد كبير من عناصر المجموعة ، Collectionيمكن أن ينخفض الأداء. على سبيل المثال ، إذا استخدمنا أولاً filter(_:)و ، ثم - first.فيSwift 4 تمت إضافة بعض خيارات الميزات الجديدة لتحسين الأداء ، وإليك بعض النصائح لكتابة رمز أسرع.1. استخدام contains، لاfirst( where: ) != nil
يمكن إجراء التحقق من وجود كائن في مجموعة Collectionبعدة طرق. يتم توفير أفضل أداء من خلال الوظيفة contains.الكود الصحيح let numbers = [0, 1, 2, 3] numbers.contains(1)
الكود غير الصحيح let numbers = [0, 1, 2, 3] numbers.filter { number in number == 1 }.isEmpty == false numbers.first(where: { number in number == 1 }) != nil
2. استخدام التحقق من الصحة isEmpty، وليس مقارنة countمع الصفر
منذ بالنسبة لبعض المجموعات ، يتم الوصول إلى العقار countعن طريق التكرار على جميع عناصر المجموعة.الكود الصحيح let numbers = [] numbers.isEmpty
الكود غير الصحيح let numbers = [] numbers.count == 0
3. تحقق من سلسلة فارغة StringمعisEmpty
سلسلة Stringفي Swiftمجموعة من الشخصيات [Character]. هذا يعني أنه من Stringالأفضل أيضًا استخدام السلاسل isEmpty.الكود الصحيح myString.isEmpty
الكود غير الصحيح myString == "" myString.count == 0
4. الحصول على العنصر الأول الذي يفي بشروط معينة
يمكن إجراء التكرار على المجموعة بأكملها من أجل الحصول على الكائن الأول الذي يستوفي شروطًا معينة باستخدام الطريقة filterالتي تتبعها الطريقة first، ولكن الطريقة هي الأفضل من حيث السرعة first (where:). توقف هذه الطريقة عن التكرار على المجموعة بمجرد تلبيتها للشرط اللازم. filterستستمر الطريقة في التكرار على المجموعة بأكملها ، بغض النظر عما إذا كانت تحقق العناصر اللازمة أم لا.من الواضح ، نفس الشيء صحيح بالنسبة لهذه الطريقة last (where:).الكود الصحيح let numbers = [3, 7, 4, -2, 9, -6, 10, 1] let firstNegative = numbers.first(where: { $0 < 0 })
الكود غير الصحيح let numbers = [0, 2, 4, 6] let allEven = numbers.filter { $0 % 2 != 0 }.isEmpty
في بعض الأحيان ، عندما تكون المجموعة Collectionكبيرة جدًا وكان الأداء حاسمًا بالنسبة لك ، فإن الأمر يستحق العودة إلى مقارنة النهج الحتمية والوظيفية واختيار المنهج الذي يناسبك.المهمة 2
هناك مثال آخر رائع على الاستخدام المختصر للغاية لوظيفة ذات ترتيب عالي reduce (_:, _:)صادفتها. هذه هي لعبة SET .وهنا قواعدها الأساسية. يأتي اسم اللعبة SETمن الكلمة الإنجليزية "set" - "set". SETتشارك 81 ورقة في اللعبة ، ولكل منها صورة فريدة: تحتوي كل بطاقة على 4 سمات ، مدرجة أدناه:الكمية : تحتوي كل بطاقة على رمز أو رمزين أو ثلاثة.نوع الشخصيات : الأشكال البيضاوية ، المعينية أو الأمواج.اللون : يمكن أن تكون الرموز حمراء أو خضراء أو أرجوانية.التعبئة : يمكن أن تكون الأحرف فارغة أو مظللة أو مظللة.الغرض من اللعبة
ورقة في اللعبة ، ولكل منها صورة فريدة: تحتوي كل بطاقة على 4 سمات ، مدرجة أدناه:الكمية : تحتوي كل بطاقة على رمز أو رمزين أو ثلاثة.نوع الشخصيات : الأشكال البيضاوية ، المعينية أو الأمواج.اللون : يمكن أن تكون الرموز حمراء أو خضراء أو أرجوانية.التعبئة : يمكن أن تكون الأحرف فارغة أو مظللة أو مظللة.الغرض من اللعبةSET: من بين البطاقات الاثنتي عشرة الموضوعة على الطاولة ، تحتاج إلى العثور على SET(مجموعة) مكونة من 3 بطاقات ، تتزامن فيها كل علامة من العلامات تمامًا أو تختلف تمامًا على جميع البطاقات الثلاثة. يجب أن تمتثل جميع العلامات تمامًا لهذه القاعدة.على سبيل المثال ، يجب أن يكون عدد الأحرف على جميع البطاقات الثلاثة هو نفسه أو مختلفًا ، ويجب أن يكون اللون على جميع البطاقات الثلاثة هو نفسه أو مختلفًا ، وهكذا ...في هذا المثال ، سنهتم فقط بخريطة الخريطة SET struct SetCardوالخوارزمية لتحديدها SETبواسطة الخرائط الثالثة isSet( cards:[SetCard]): struct SetCard: Equatable { let number: Variant
نماذج لكل ميزة - عدد number ، نوع رمز shape ، لون color و التعبئة fill - قدم سرد Variantوجود ثلاثة القيم الممكنة var1، var2و var3الذي يتوافق مع الأعداد الصحيحة 3 rawValue- 1,2,3. في هذا النموذج ، rawValueفإنه سهل التشغيل. إذا أخذنا بعض الإشارات ، على سبيل المثال ، colorثم قمنا بإضافة كل شيء rawValueمقابل colors3 بطاقات ، فسنجد أنه إذا كانت colorsجميع البطاقات الثلاث متساوية ، فسيكون المجموع متساويًا 3، 6أو 9إذا كانت جميعها مختلفة ، فسيكون المجموع على قدم المساواة 6. في أي من هذه الحالات ، لدينا تعدد المبلغ الثالث rawValueلـcolorsكل 3 بطاقات. نحن نعلم أن هذا شرط مسبق لما تشكله 3 بطاقات SET. من أجل أن تصبح 3 بطاقات SETضرورية حقًا ، لجميع العلامات SetCard- الكمية numberونوع الرمز shapeواللون colorوالتعبئة fill- يجب أن rawValueيكون مجموعها مضاعفًا في البطاقة الثالثة.لذلك، في staticالأسلوب، isSet( cards:[SetCard])علينا أولا حساب مجموعة sumsمن مبالغ rawValueلجميع الخرائط 3 لجميع خريطة 4 الأداء باستخدام أعلى وظيفة ترتيب reduceمع قيمة أولية يساوي 0، وتراكم المهام {$0 + $1.number.rawValue}، {$0 + $1.color.rawValue}، {$0 + $1.shape.rawValue}، { {$0 + $1.fill.rawValue}. sumsيجب أن يكون كل عنصر من عناصر الصفيف مضاعفًا للثالث ، ونستخدم الدالة مرة أخرىreduce، لكن هذه المرة بقيمة أولية مساوية trueللوظيفة المنطقية " AND" {$0 && ($1 % 3) == 0}. في Swift 5 ، لاختبار تعدد رقم لآخر ، يتم تقديم وظيفة isMultiply(of:)بدلاً من المشغل %الباقي. أيضا فإنه سيتم تحسين سهولة قراءة التعليمات البرمجية: { $0 && ($1.isMultiply(of:3) }.هذا الرمز القصير خيالي لتحديد ما إذا كان 3 SetCardبطاقات SETعشر، التي تم الحصول عليها بفضل " ظيفية النهج"، ويمكننا التأكد من أنها تعمل على Playground: وهذا نموذج من اللعبة
وهذا نموذج من اللعبة SETلبناء واجهة المستخدم ( UI) ويمكن الاطلاع هنا ، هنا و هنا .ميزات نقية والآثار الجانبية
وظيفة نقية تستوفي شرطين. تقوم دائمًا بإرجاع نفس النتيجة مع نفس معلمات الإدخال. ولا يؤدي حساب النتيجة إلى آثار جانبية مرتبطة بإخراج البيانات من الخارج (على سبيل المثال ، إلى القرص) أو مع اقتراض بيانات المصدر من الخارج (على سبيل المثال ، الوقت). هذا يسمح لك بتحسين الكود بشكل ملحوظ.تم Swiftتعيين هذا الموضوع تمامًا على point.free في الحلقات الأولى جدًا من " وظائف " و " تأثيرات جانبية " ، والتي تُترجم إلى الروسية ويتم تقديمها كـ " وظائف " و "تأثيرات جانبية" .تكوين وظيفة
بمعنى رياضي ، هذا يعني تطبيق وظيفة واحدة على نتيجة وظيفة أخرى. في إحدى Swiftالوظائف ، يمكنهم إرجاع قيمة يمكنك استخدامها كمدخلات لوظيفة أخرى. هذه ممارسة برمجة شائعة.تخيل أن لدينا مجموعة من الأعداد الصحيحة ونريد الحصول على مجموعة من المربعات ذات الأرقام الزوجية الفريدة في المخرجات. عادةً ما نعيد تنفيذ هذا كما يلي: var integerArray = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] func unique(_ array: [Int]) -> [Int] { return array.reduce(into: [], { (results, element) in if !results.contains(element) { results.append(element) } }) } func even(_ array: [Int]) -> [Int] { return array.filter{ $0%2 == 0} } func square(_ array: [Int]) -> [Int] { return array.map{ $0*$0 } } var array = square(even(unique(integerArray)))
يمنحنا هذا الرمز النتيجة الصحيحة ، لكنك ترى أن سهولة قراءة السطر الأخير من التعليمات البرمجية ليست بهذه السهولة. تسلسل الوظائف (من اليمين إلى اليسار) هو عكس ذلك الذي اعتدنا عليه (من اليسار إلى اليمين) ونود أن نرى هنا. نحتاج إلى توجيه منطقنا أولاً إلى الجزء الأعمق من الزخارف المتعددة - إلى صفيف inegerArray، ثم إلى دالة خارجية لهذه الصفيف unique، ثم نرتقي بمستوى آخر - دالة even، وأخيراً ، دالة في الختام square.وهنا نأتي إلى مساعدة المشغلين وظائف "تكوين" >>>و |>التي تسمح لنا لكتابة رمز بطريقة مريحة جدا، هو العلاج من مجموعة الأصلي integerArrayفي شكل وظيفة "ناقل": var array1 = integerArray |> unique >>> even >>> square
تقريبا كل لغات مثل البرمجة الوظيفية المتخصصة F#، Elixirو Elmاستخدام هذه الشركات لوظائف "تكوين".كما Swiftأنه لا يوجد المدمج في وظائف المشغلين تكوين " >>>و |>، ولكن يمكننا الحصول عليها بسهولة جدا مع مساعدة Generics، الدائرة ( closure) و infixالمشغل: precedencegroup ForwardComposition{ associativity: left higherThan: ForwardApplication } infix operator >>> : ForwardComposition func >>> <A, B, C>(left: @escaping (A) -> B, right: @escaping (B) -> C) -> (A) -> C { return { right(left($0)) } } precedencegroup ForwardApplication { associativity: left } infix operator |> : ForwardApplication func |> <A, B>(a: A, f: (A) -> B) -> B { return f(a) }
على الرغم من التكاليف الإضافية ، في بعض الحالات ، قد يؤدي هذا إلى زيادة كبيرة في أداء التعليمات البرمجية الخاصة بك وقابلية قراءتها وقابليتها للاختبار. على سبيل المثال ، عندما mapتقوم بداخلك بوضع سلسلة كاملة من الوظائف باستخدام عامل التشغيل "التكوين" >>>بدلاً من تعقب مجموعة من خلال العديد من map: var integerArray1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 5] let b = integerArray1.map( { $0 + 1 } >>> { $0 * 3 } >>> String.init) print (b)
ولكن ليس دائمًا أن النهج الوظيفي يعطي تأثيرًا إيجابيًا.في البداية ، عندما ظهر Swiftفي عام 2014 ، سارع الجميع إلى كتابة مكتبات مع المشغلين من أجل "تكوين" الوظائف وحل مهمة صعبة في ذلك الوقت مثل التحليل JSONباستخدام عوامل تشغيل البرمجة الوظيفية بدلاً من استخدام الإنشاءات المتداخلة بشكل غير محدود if let. قمت أنا نفسي بترجمة مقالة حول تحليل وظيفي لـ JSON والتي أسعدتني بحلها الأنيق وكانت من محبي مكتبة Argo .لكن المطورين Swiftذهبوا بطريقة مختلفة تمامًا واقترحوا ، على أساس التكنولوجيا الموجهة للبروتوكول ، طريقة أكثر إيجازًا لكتابة التعليمات البرمجية. من أجل "تسليم" JSONالبيانات مباشرة إلىCodable، الذي ينفذ تلقائيا هذا البروتوكول، إذا يتكون النموذج الخاص بك من المعروف Swiftهياكل البيانات: String، Int، URL، Array، Dictionary، الخ struct Blog: Codable { let id: Int let name: String let url: URL }
الحصول على JSONبيانات من هذا المقال الشهير ... [ { "id" : 73, "name" : "Bloxus test", "url" : "http://remote.bloxus.com/" }, { "id" : 74, "name" : "Manila Test", "url" : "http://flickrtest1.userland.com/" } ]
... في الوقت الحالي ، ما عليك سوى سطر واحد من التعليمات البرمجية للحصول على مجموعة من المدونات blogs: let blogs = Bundle.main.path(forResource: "blogs", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Blog].self, from: $0) } print ("\(blogs!)")
لقد نسي الجميع بأمان استخدام مشغلي "تكوين" الوظائف للتحليل JSON، إذا كان هناك طريقة أخرى أكثر قابلية للفهم وسهلة للقيام بذلك باستخدام البروتوكولات.إذا كان كل شيء سهلاً ، فيمكننا "تحميل" JSONالبيانات إلى نماذج أكثر تعقيدًا. افترض أن لدينا ملف JSONبيانات له اسم user.jsonوموجود في دليلنا Resources.، ويحتوي على بيانات عن مستخدم معين: { "email": "blob@pointfree.co", "id": 42, "name": "Blob" }
ولدينا Codable Userلديه مُهيئ من البيانات json: struct User: Codable { let email: String let id: Int let name: String init?(json: Data) { if let newValue = try? JSONDecoder().decode(User.self, from: json) { self = newValue } else { return nil } } }
يمكننا بسهولة الحصول على مستخدم جديد newUserبرمز وظيفي أبسط: let newUser = Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }
من الواضح ، newUserسيكون هناك TYPE Optional، أي User?: لنفترض أنه في الدليل الخاص بنا
لنفترض أنه في الدليل الخاص بنا Resourcesيوجد ملف آخر يحمل اسمًا invoices.jsonويحتوي على بيانات عن فواتير هذا المستخدم. [ { "amountPaid": 1000, "amountDue": 0, "closed": true, "id": 1 }, { "amountPaid": 500, "amountDue": 500, "closed": false, "id": 2 } ]
يمكننا تحميل هذه البيانات كما فعلنا تمامًا User. دعونا نحدد الهيكل كنموذج الفاتورة struct Invoice... struct Invoice: Codable { let amountDue: Int let amountPaid: Int let closed: Bool let id: Int }
... وفك تشفير JSONمجموعة الفواتير المقدمة أعلاه invoices، وتغيير مسار الملف وفك التشفير فقط decode: let invoices = Bundle.main.path(forResource: "invoices", ofType: "json") .map( URL.init(fileURLWithPath:) ) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) }
invoicesسيكون [Invoice]?: الآن نود توصيل المستخدم
الآن نود توصيل المستخدم userبفواتيره invoices، إذا لم تكن متساوية nil، وحفظها ، على سبيل المثال ، في بنية المغلف UserEnvelopeالذي يتم إرساله إلى المستخدم مع فواتيره: struct UserEnvelope { let user: User let invoices: [Invoice] }
بدلا من أداء مرتين if let... if let newUser = newUser, let invoices = invoices { }
... دعونا إرسال بريد التناظرية وظيفي مزدوج if letباعتبارها المساعدة Genericوظيفة zip، وتحويل اثنين Optionalالقيم في Optionalأحد الصفوف (tuple): func zip<A, B>(_ a: A?, _ b: B?) -> (A, B)? { if let a = a, let b = b { return (a, b) } return nil }
الآن، لدينا أي سبب لشيء المتغيرات تعيين newUserو invoicesنحن تضمين فقط كل لدينا ميزة جديدة zip، استخدم مهيئ UserEnvelope.init، وأنها ستعمل! let userEnv = zip( Bundle.main.path(forResource: "user", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { User.init(json: $0) }, Bundle.main.path(forResource: "invoices", ofType: "json") .map(URL.init(fileURLWithPath:)) .flatMap { try? Data.init(contentsOf: $0) } .flatMap { try? JSONDecoder().decode([Invoice].self, from: $0) } ).flatMap (UserEnvelope.init) print ("\(userEnv!)")
في تعبير واحد ، يتم تعبئة خوارزمية كاملة لتقديم JSONالبيانات إلى واحدة معقدة struct UserEnvelope.zip , , . user , JSON , invoices , JSON . .map , , «» .flatMap , , , .
العملية zip، mapو flatMapهي svoebrazny لغة المجال تحديدا (لغة المجال تحديدا، DSL) لتحويل البيانات.يمكننا تطوير هذا العرض التوضيحي لتمثيل قراءة محتويات ملف بشكل غير متزامن كوظيفة خاصة يمكنك رؤيتها على pointfree.co .أنا لست من المعجبين المتعصبين للبرمجة الوظيفية في كل مكان وفي كل شيء ، لكن الاستخدام المعتدل لذلك يبدو لي أمرًا مستحسنًا.الخاتمة
أعطى أمثلة على البرمجة الوظيفية المختلفة ميزات Swfر «من خارج منطقة الجزاء"، استنادا إلى استخدام وظائف النظام العالي map، flatMap، reduce، filterوالآخر للتسلسل Sequence، Optionalو Result. ويمكن أن تكون "حقوله المنتجة" إنشاء تعليمات برمجية في ,وخاصة إذا كان يشارك هناك من قيمة structوالتعدادات enum. iOSيجب أن يمتلك مطور التطبيقات هذه الأداة. يمكن العثور علىجميع العروض التجريبية Playgroundعلى جيثب . إذا كنت تواجه مشكلات في الإطلاق Playground، يمكنك مشاهدة هذه المقالة:كيفية التخلص من أخطاء "تجميد" Xcode Playground مع رسائل "Launch Simulator" و "Running Playground".المراجع
Functional Programming in Swift: An Introduction.An Introduction to Functional Programming in Swift.The Many Faces of Flat-Map: Part 3Inside the Standard Library: Sequence.map()Practical functional programming in Swift