المؤلفان هما جون هينيسي وديفيد باترسون ، الحاصلين على جائزة تورينج 2017 "لنهج مبتكر وقابل للقياس لتصميم وفحص هياكل الكمبيوتر التي كان لها تأثير دائم على صناعة المعالجات الدقيقة بأكملها." مقالة نشرت في اتصالات ACM ، فبراير 2019 ، المجلد 62 ، العدد 2 ، الصفحات 48-60 ، doi: 10.1145 / 3282307 "أولئك الذين لا يتذكرون الماضي محكوم عليهم بتكراره"
"أولئك الذين لا يتذكرون الماضي محكوم عليهم بتكراره" - جورج سانتايانا ، 1905
بدأنا
محاضرة تورينج في 4 يونيو 2018 بمراجعة بنية الكمبيوتر التي بدأت في الستينيات. بالإضافة إلى ذلك ، نحن نسلط الضوء على القضايا الحالية ونحاول تحديد الفرص المستقبلية التي تعد بعصر ذهبي جديد في مجال هندسة الكمبيوتر في العقد القادم. مثلما حدث في الثمانينيات ، عندما أجرينا بحثنا حول تحسين التكلفة ، وكفاءة الطاقة ، والأمن ، وأداء المعالجات ، والتي حصلنا عليها من أجل هذه الجائزة المشرفة.
الأفكار الرئيسية
- تقدم البرامج قد يدفع الابتكار المعماري
- زيادة مستوى واجهات البرامج والأجهزة تخلق فرصًا للابتكار المعماري
- يحدد السوق في النهاية الفائز في نزاع الهندسة المعمارية
برنامج "محادثات" إلى المعدات من خلال قاموس يسمى "بنية مجموعة التعليمات" (ISA). بحلول أوائل الستينيات من القرن الماضي ، كان لدى IBM أربعة سلسلة من أجهزة الكمبيوتر غير المتوافقة ، ولكل منها ISA ، ومكدس برمجيات ، ونظام الإدخال / الإخراج ، وموقع السوق - الموجهة للأعمال التجارية الصغيرة ، والأعمال التجارية الكبيرة ، والتطبيقات العلمية وأنظمة الوقت الفعلي ، على التوالي. قرر مهندسو شركة IBM ، بما في ذلك فريدريك بروكس الابن الحائز على جائزة تورينج ، إنشاء ISA واحد يوحد بفعالية الأربعة.
احتاجوا إلى حل تقني حول كيفية توفير ISA بسرعة متساوية لأجهزة الكمبيوتر مع كل من الحافلات 8 بت و 64 بت. بمعنى ما ، فإن الحافلات هي "عضلات" أجهزة الكمبيوتر: إنها تؤدي المهمة ، لكن من السهل نسبيًا "ضغطها" و "توسيعها". آنذاك والآن التحدي الأكبر للمصممين هو "عقل" معدات التحكم في المعالج. مستوحاة من البرمجة ، اقترح الرائد موريس ويلكس الحائز على جائزة علوم الكمبيوتر وخيارات تورينج تبسيط هذا النظام. تم تقديم عنصر التحكم كصفيف ثنائي الأبعاد ، والذي أطلق عليه "مخزن التحكم" (مخزن التحكم).
يتوافق كل عمود من الصفيف مع خط تحكم واحد ، وكان كل صف عبارة عن تعليمات دقيقة ، وكان يسمى سجل التعليمات الدقيقة البرمجة الدقيقة . تحتوي ذاكرة التحكم على مترجم ISA مكتوب بواسطة تعليمات متناهية الصغر ، وبالتالي فإن تنفيذ التعليمات العادية يأخذ عدة تعليمات متناهية الصغر. يتم تطبيق ذاكرة التحكم ، في الواقع ، في الذاكرة ، وهي أرخص بكثير من العناصر المنطقية.
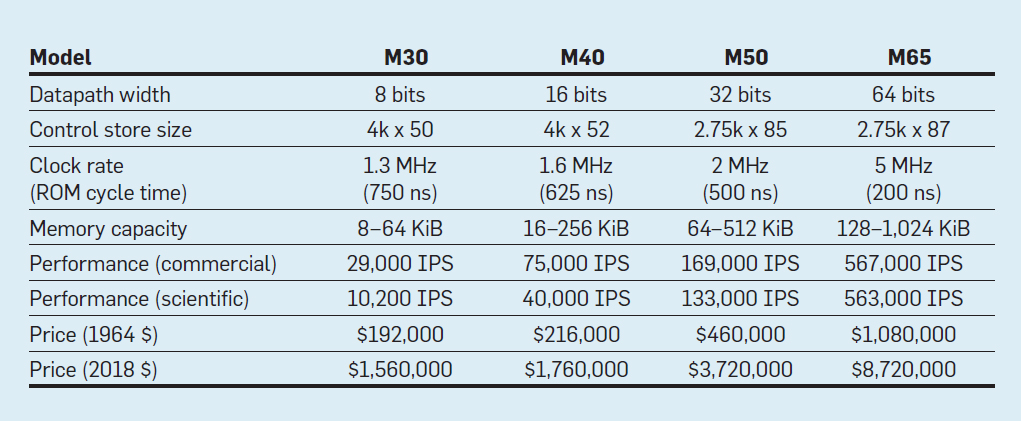 ميزات النماذج الأربعة لعائلة IBM System / 360 ؛ IPS يعني عمليات في الثانية الواحدة
ميزات النماذج الأربعة لعائلة IBM System / 360 ؛ IPS يعني عمليات في الثانية الواحدةيعرض الجدول أربعة نماذج من ISA الجديد في System / 360 من IBM ، تم تقديمه في 7 أبريل 1964. تختلف الحافلات بنسبة 8 مرات ، وتبلغ سعة الذاكرة 16 ، وسرعة الساعة تقارب 4 ، والأداء 50 ، والتكلفة تقريبًا 6. تمتلك أجهزة الكمبيوتر أغلى ذاكرة تحكم واسعة ، لأن حافلات البيانات الأكثر تعقيدًا تستخدم خطوط تحكم أكثر . أرخص أجهزة الكمبيوتر لديها ذاكرة تحكم أقل بسبب أجهزة أبسط ، لكنها تحتاج إلى مزيد من الإرشادات الدقيقة ، لأنها تحتاج إلى مزيد من دورات الساعة لتنفيذ تعليمات System / 360.
بفضل البرمجة المصغرة ، راهنت IBM على أن ISA الجديد سيحدث ثورة في صناعة الحوسبة - وفاز بالرهان. سيطرت شركة IBM على أسواقها ، ولا يزال المتحدرون من الأبنية الرئيسية لشركة IBM البالغة من العمر 55 عامًا يحققون إيرادات بقيمة 10 مليارات دولار سنويًا.
كما لوحظ مرارًا وتكرارًا ، على الرغم من أن السوق يعد حُكمًا ناقصًا كتقنية ، ولكن نظرًا للعلاقات الوثيقة بين الهندسة المعمارية والحواسيب التجارية ، فإنه يحدد في نهاية المطاف نجاح الابتكارات المعمارية ، التي تتطلب غالبًا استثمارات هندسية كبيرة.
الدوائر المتكاملة ، CISC ، 432 ، 8086 ، IBM PC
عندما تحولت أجهزة الكمبيوتر إلى دوائر متكاملة ، كان قانون مور يعني أن ذاكرة التحكم يمكن أن تصبح أكبر بكثير. بدوره ، سمح هذا ISA أكثر تعقيدا بكثير. على سبيل المثال ، ذاكرة التحكم VAX-11/780 من شركة Digital Equipment Corp. في عام 1977 ، كان 5120 كلمة في 96 بت ، في حين أن سابقتها تستخدم فقط 256 كلمة في 56 بت.
مكّنت بعض الشركات المصنعة البرامج الثابتة للعملاء المحددين الذين ربما أضافوا ميزات مخصصة. وهذا ما يسمى مخزن التحكم للكتابة (WCS). كان الكمبيوتر الأكثر شهرة في WCS هو
Alto ، الذي أنشأه الفائزان بجوائز Turing Chuck Tucker و Butler Lampson وزملاؤه في مركز أبحاث Xerox Palo Alto في عام 1973. لقد كان بالفعل أول جهاز كمبيوتر شخصي: هنا هو أول جهاز عرض مع تصوير عنصر لكل عنصر وأول شبكة إيثرنت محلية. كانت وحدات التحكم للشاشة المبتكرة وبطاقة الشبكة عبارة عن برامج microprogram يتم تخزينها في WCS بسعة 4096 كلمة في 32 بت.
في السبعينيات ، بقيت المعالجات 8 بت (على سبيل المثال ، Intel 8080) وتمت برمجتها بشكل أساسي في المجمّع. أضاف المنافسون تعليمات جديدة للتفوق على بعضهم البعض ، مع عرض إنجازاتهم بأمثلة عن المجمّع.
يعتقد غوردون مور أن ISA ISA المقبل ستستمر إلى الأبد بالنسبة للشركة ، لذا فقد استأجر الكثير من الأطباء الأذكياء في علوم الكمبيوتر وأرسلهم إلى منشأة جديدة في بورتلاند لابتكار ISA العظيم التالي. أصبح المعالج 8800 ، كما أطلقت عليه شركة إنتل أصلاً ، مشروعًا طموحًا لهندسة الكمبيوتر لأي عصر ، بالطبع ، كان المشروع الأكثر عدوانية في الثمانينات. تضمنت عنونة تستند إلى الإمكانات 32 بت ، بنية موجهة للكائنات ، تعليمات متغيرة الطول ، ونظام التشغيل الخاص بها بلغة برمجة Ada الجديدة.
لسوء الحظ ، تطلب هذا المشروع الطموح عدة سنوات من التطوير ، مما أجبر شركة Intel على إطلاق مشروع نسخ احتياطي للطوارئ في سانتا كلارا من أجل إطلاق معالج بسرعة 16 بت في عام 1979. أعطت إنتل الفريق الجديد 52 أسبوعًا لتطوير ISA الجديد "8086" ، وتصميم وبناء الشريحة. نظرًا للجدول الزمني الضيق ، استغرق تصميم ISA 10 أسابيع فقط لمدة ثلاثة أسابيع تقويمية منتظمة ، ويرجع ذلك أساسًا إلى توسيع سجلات 8 بت ومجموعة من 8080 تعليمات إلى 16 بت. أنهى الفريق 8086 في الموعد المحدد ، ولكن تم الإعلان عن هذا المعالج المصطنع دون ضجة كبيرة.
كانت شركة Intel محظوظة جدًا لأن شركة IBM كانت تقوم بتطوير جهاز كمبيوتر شخصي للتنافس مع Apple II وتحتاج إلى معالج دقيق 16 بت. كانت آي بي إم تتطلع إلى موتورولا 68000 بمعايير ISA مماثلة لـ آي بي إم 360 ، لكنها كانت وراء جدول آي بي إم العدواني. بدلاً من ذلك ، تحولت IBM إلى الإصدار 8 بت من ناقل 8086. عندما أعلنت IBM عن الكمبيوتر في 12 أغسطس 1981 ، كانت تأمل في بيع 250 ألف جهاز كمبيوتر بحلول عام 1986. وبدلاً من ذلك ، باعت الشركة 100 مليون في جميع أنحاء العالم ، مما يمثل مستقبلاً واعداً للغاية في مجال الطوارئ ISA لشركة إنتل.
تمت إعادة تسمية مشروع Intel 8800 الأصلي إلى iAPX-432. أخيرًا ، تم الإعلان عنه في عام 1981 ، لكنه تطلب عدة شرائح ولديه مشكلات خطيرة في الأداء. تم الانتهاء منه في عام 1986 ، أي بعد عام من قيام Intel بتوسيع ISA 8086 من 16 بت إلى 80386 ، مما زاد من السجلات من 16 بت إلى 32 بت. وهكذا ، فقد تبين أن تنبؤ مور بشأن ISA كان صحيحًا ، لكن السوق اختار 8086 الذي تم تصنيعه في النصف ، بدلاً من iAPX-432 الممسوح. كما أدرك مهندسو معالجات موتورولا 68000 و iAPX-432 ، نادراً ما يكون السوق قادراً على إظهار الصبر.
من مجموعة معقدة إلى مجموعة التعليمات المختصرة
في أوائل الثمانينيات من القرن الماضي ، أجريت العديد من الدراسات لأجهزة الكمبيوتر التي تحتوي على مجموعة من الإرشادات المعقدة (CISC): لديهم برامج ميكروية كبيرة في ذاكرة التحكم الكبيرة. عندما أثبت Unix أنه حتى نظام التشغيل يمكن كتابته بلغة عالية المستوى ، كان السؤال الرئيسي هو: "ما هي الإرشادات التي سيولدها المترجمون؟" بدلا من السابق "ما المجمع سوف تستخدم المبرمجين؟" خلقت زيادة كبيرة في مستوى واجهة الأجهزة والبرامج فرصة للابتكار في الهندسة المعمارية.
طور جون كوك ، الفائز بجائزة تورينج وزملاؤه ، معايير أبسط للمحركات الصغيرة ومترجمين للحواسيب الصغيرة. كتجربة ، قاموا بإعادة توجيه المترجمين البحثيين إلى استخدام IBM 360 ISA لاستخدام العمليات البسيطة فقط بين السجلات والتحميل مع الذاكرة ، وتجنب الإرشادات الأكثر تعقيدًا. لاحظوا أن البرامج تعمل بشكل أسرع ثلاث مرات إذا كانت تستخدم مجموعة فرعية بسيطة.
وجد Emer and Clark أن 20٪ من تعليمات VAX تشغل 60٪ من الرمز الصغير وتستغرق 0.2٪ فقط من وقت التنفيذ. أمضى أحد مؤلفي هذا المقال (باترسون) عطلة إبداعية في DEC ، مما ساعد على تقليل الأخطاء في الرمز الصغير VAX. إذا كانت الشركات المصنعة للمعالجات الدقيقة ستتبع تصميمات ISA مع مجموعة من أوامر CISC المعقدة في أجهزة الكمبيوتر الكبيرة ، فقد توقعوا عددًا كبيرًا من أخطاء الرمز الصغير وأرادوا إيجاد طريقة لإصلاحها. كتب
مثل هذا المقال ، لكن مجلة
الكمبيوتر رفضته. اقترح المراجعون أن الفكرة الرهيبة المتمثلة في بناء المعالجات الدقيقة مع ISA معقدة للغاية بحيث تحتاج إلى إصلاح في هذا المجال. هذا الفشل يلقي ظلالا من الشك على قيمة CISC للمعالجات الدقيقة. ومن المفارقات أن معالجات CISC الحديثة تشمل آليات استرداد الرمز الصغير ، لكن رفض نشر المقال ألهم المؤلف لتطوير ISA أقل تعقيدًا للمعالجات الدقيقة - أجهزة كمبيوتر بها مجموعة تعليمات منخفضة (RISC).
سمحت هذه التعليقات والانتقال إلى اللغات عالية المستوى بالانتقال من CISC إلى RISC. أولاً ، يتم تبسيط تعليمات RISC ، لذلك ليست هناك حاجة لمترجم فوري. عادة ما تكون تعليمات RISC بسيطة كتعليمات دقيقة ويمكن تنفيذها مباشرة بواسطة الأجهزة. ثانياً ، تم إعادة تصميم الذاكرة السريعة التي كانت تُستخدم سابقًا لمترجم الشفرة المصغرة CISC في ذاكرة التخزين المؤقت لتعليمات RISC (ذاكرة التخزين المؤقت هي ذاكرة صغيرة وسريعة تقوم بتخزين الإرشادات التي تم تنفيذها مؤخرًا ، نظرًا لأنه من المحتمل إعادة استخدام هذه الإرشادات في المستقبل القريب). ثالثًا ، قام
مُخصصو التسجيل استنادًا إلى مخطط التلوين في الرسم البياني من قِبل غريغوري شيتين بتسهيل الاستخدام الفعال
للسجلات للمجمعين ، والتي استفادت من
معايير التدقيق الدولية هذه من خلال عمليات تسجيل السجل. أخيرًا ، أدى قانون مور إلى حقيقة أنه في الثمانينيات كان هناك عدد كافٍ من الترانزستورات على رقاقة لاستيعاب حافلة كاملة 32 بت على شريحة واحدة ، إلى جانب مخابئ للإرشادات والبيانات.
على سبيل المثال ، في التين. يوضح الشكل 1 المعالجات الدقيقة
RISC-I و
MIPS المطورة في جامعة كاليفورنيا في بيركلي وجامعة ستانفورد في عامي 1982 و 1983 ، والتي أظهرت فوائد RISC. نتيجة لذلك ، في عام 1984 تم تقديم هذه المعالجات في المؤتمر الرائد حول تصميم الدوائر ، مؤتمر IEEE الدولي للدوائر الصلبة (
1 ،
2 ). لقد كانت لحظة رائعة عندما ابتكر العديد من طلاب الدراسات العليا في بيركلي وستانفورد معالجات دقيقة تجاوزت قدرات الصناعة في تلك الحقبة.
 شكل 1. معالجات RISC-I من جامعة كاليفورنيا في بيركلي و MIPS من جامعة ستانفورد
شكل 1. معالجات RISC-I من جامعة كاليفورنيا في بيركلي و MIPS من جامعة ستانفوردألهمت هذه الرقائق الأكاديمية العديد من الشركات لإنشاء معالجات RISC الدقيقة ، والتي كانت الأسرع على مدار الخمسة عشر عامًا القادمة. يرتبط التفسير بصيغة أداء المعالج التالية:
الوقت / البرنامج = (التعليمات / البرنامج) × (التدابير / التعليمات) × (الوقت / القياس)أظهر مهندسو DEC فيما بعد أنه بالنسبة لبرنامج واحد ، تتطلب CISCs الأكثر تعقيدًا 75٪ من عدد تعليمات RISC (الفصل الأول في الصيغة) ، ولكن في تقنية مماثلة (الفصل الثالث) ، يستغرق كل تعليمي CISC 5-6 دورات أكثر (الفصل الدراسي الثاني) ، يجعل RISC المعالجات الدقيقة حوالي 4 مرات أسرع.
لم تكن هناك مثل هذه الصيغ في أدبيات الكمبيوتر في الثمانينيات ، مما جعلنا نكتب كتاب
هندسة الكمبيوتر: منهج كميتفي عام 1989. يشرح العنوان الفرعي موضوع الكتاب: استخدام القياسات والمعايير لقياس المفاضلات ، بدلاً من الاعتماد على الحدس وتجربة المصمم ، كما كان في الماضي. استلهم نهجنا الكمي أيضًا ما فعله
كتاب تورينغ الحائز على جائزة دونج نوث للخوارزميات.
VLIW ، EPIC ، إيتانيوم
كان من المفترض أن يتجاوز معيار ISA المبتكرة التالي نجاح كل من RISC و CISC. استخدمت
بنية تعليمات الجهاز
VLIW الطويلة جدًا وابن عمها EPIC (الحوسبة بالتوازي الواضح مع تعليمات الماكينة) من Intel و Hewlett-Packard تعليمات طويلة ، كل منها يتكون من عدة عمليات مستقلة مرتبطة ببعضها. كان مؤيدو VLIW و EPIC في ذلك الوقت يعتقدون أنه إذا كانت هناك تعليمات واحدة يمكن أن تشير ، على سبيل المثال ، إلى ست عمليات مستقلة - نقلان للبيانات ، عمليتان صحيحتان وعمليتان في الفاصلة العائمة - وتكنولوجيا المحول البرمجي يمكن أن تعين العمليات بكفاءة إلى ست فتحات للتعليم ، ثم يمكن تبسيط المعدات. على غرار نهج RISC ، قام VLIW و EPIC بنقل العمل من الأجهزة إلى برنامج التحويل البرمجي.
معاً ، طورت Intel و Hewlett-Packard معالجًا يستند إلى EPIC 64 بت لاستبدال بنية x86 32 بت. تم تعليق توقعات كبيرة على أول معالج EPIC يدعى Itanium ، ولكن الواقع لم يتوافق مع البيانات المبكرة للمطورين. على الرغم من أن نهج EPIC يعمل بشكل جيد لبرامج الفاصلة العائمة عالية التنظيم ، إلا أنه لم يتمكن من تحقيق أداء عالٍ للبرامج الصحيحة ذات الأخطاء المتفرعة وأقل من المتوقع في ذاكرة التخزين المؤقت. كما
لاحظ دونالد نوث لاحقًا: "كان من المفترض أن يكون Itanium ... رائعًا - حتى اتضح أن المترجمين المطلوبين كان من المستحيل أن يكتبوا". لاحظ النقاد التأخير في إطلاق Itanium وأطلقوا عليها اسم Itanik تكريما لسفينة الركاب Titanic المشؤومة. فشل السوق مرة أخرى في إظهار الصبر واعتماد الإصدار 64 بت من x86 ، وليس Itanium ، كخليفة.
والخبر السار هو أن VLIW لا يزال مناسبًا للتطبيقات الأكثر تخصصًا التي تدير برامج صغيرة مع فروع أبسط دون تفويت ذاكرة التخزين المؤقت ، بما في ذلك معالجة الإشارة الرقمية.
RISC مقابل CISC في عصر الكمبيوتر الشخصي وما بعد الكمبيوتر
احتاجت AMD و Intel إلى 500 فريق تصميم وتكنولوجيا أشباه الموصلات الفائقة لسد فجوة الأداء بين x86 و RISC. مرة أخرى ، من أجل تحقيق الأداء من خلال خطوط الأنابيب ، تقوم وحدة فك ترميز التعليمات الفورية بترجمة تعليمات x86 المعقدة إلى تعليمات داخلية مثل RISC. AMD و Intel ثم بناء خط أنابيب لتنفيذها. أي أفكار استخدمها مصممو RISC لتحسين الأداء - منفصلة للتعليمات وتخزين البيانات المؤقت ، وذاكرة التخزين المؤقت من المستوى الثاني على الشريحة ، وخط أنابيب عميق ، والاستلام والتنفيذ المتزامن لعدة تعليمات - تم تضمينها في الإصدار x86. في ذروة عصر الكمبيوتر الشخصي في عام 2011 ، شحنت AMD و Intel حوالي 350 مليون x86 من المعالجات الدقيقة سنويًا. يعني الحجم الكبير والهوامش المنخفضة للصناعة أيضًا انخفاض الأسعار عن أجهزة RISC.
مع بيع مئات الملايين من أجهزة الكمبيوتر سنويًا ، أصبح البرنامج سوقًا ضخمًا. في حين كان على بائعي برامج Unix إصدار إصدارات مختلفة من البرامج لمختلف أبنية RISC - Alpha و HP-PA و MIPS و Power و SPARC - كان لدى أجهزة الكمبيوتر الشخصية ISA واحد ، لذلك أصدر المطورون برمجيات "متقلصة" كانت متوافقة مع الهندسة المعمارية فقط إلى x86. نظرًا لقاعدة البرامج الأكبر حجماً والأداء المماثل وانخفاض الأسعار ، سيطرت الهندسة المعمارية x86 بحلول عام 2000 على أسواق أجهزة سطح المكتب والخوادم الصغيرة.
ساعدت شركة Apple في دخول مرحلة ما بعد الكمبيوتر الشخصي مع جهاز iPhone في عام 2007. بدلاً من شراء المعالجات الدقيقة ، قامت شركات الهواتف الذكية بتكوين أنظمتها الخاصة على رقاقة (SoC) باستخدام تطورات الأشخاص الآخرين ، بما في ذلك معالجات RISC من ARM. هنا ، المصممون مهمون ليس فقط في الأداء ، ولكن أيضًا في استهلاك الطاقة ومساحة الرقاقة ، مما يضع بنية CISC في غير صالحها. بالإضافة إلى ذلك ، زاد إنترنت الأشياء بشكل كبير من عدد المعالجات والمفاضلات اللازمة في حجم الرقاقة والطاقة والتكلفة والأداء. زاد هذا الاتجاه من أهمية وقت التصميم والتكلفة ، مما زاد من تفاقم موقف معالجات CISC.
في عصر ما بعد الكمبيوتر الشخصي اليوم ، انخفضت شحنات x86 السنوية بنسبة تقارب 10٪ منذ الذروة 2011 ، في حين ارتفعت رقائق RISC إلى 20 مليار. اليوم ، 99 ٪ من المعالجات 32 و 64 بت في العالم هي RISC.في ختام هذا الاستعراض التاريخي ، يمكننا القول أن السوق قد حسم النزاع بين RISC و CISC. على الرغم من فوز CISC بالمراحل اللاحقة من عصر الكمبيوتر الشخصي ، إلا أن RISC يفوز الآن بعد وصول عصر ما بعد الكمبيوتر. لا توجد معايير ISA جديدة في CISC لعقود. لدهشتنا ، لا يزال الإجماع العام حول أفضل مبادئ ISA لمعالجات الأغراض العامة اليوم لصالح RISC ، بعد 35 عامًا من اختراعها.التحديات الحديثة لهندسة المعالج
« , , , , » —
(ISA), ISA, ISA . 70- - (MOS), n- (nMOS), (CMOS). MOS — — , ISA.
1965 ينص على مضاعفة سنوية لكثافة الترانزستورات. في عام 1975 ، قام بتنقيحها ، وتوقع مضاعفة كل عامين. في النهاية ، بدأ يطلق على هذا التوقع قانون مور. نظرًا لأن كثافة الترانزستورات تنمو بشكل رباعي ، وتنمو السرعة بشكل خطي ، فإن استخدام المزيد من الترانزستورات يمكن أن يزيد الإنتاجية.نهاية قانون مور وقانون دينار التدريجي
على الرغم من أن قانون مور ساري المفعول لعدة عقود (انظر الشكل 2) ، في مكان ما حوالي عام 2000 ، فقد بدأ في التباطؤ ، وبحلول عام 2018 ، ازدادت الفجوة بين تنبؤات مور والقدرات الحالية إلى 15 مرة. في عام 2003 ، اقترح مور أن هذا أمر لا مفر منه . من المتوقع حاليًا أن تستمر الفجوة في الاتساع مع اقتراب تقنية CMOS من الحدود الأساسية.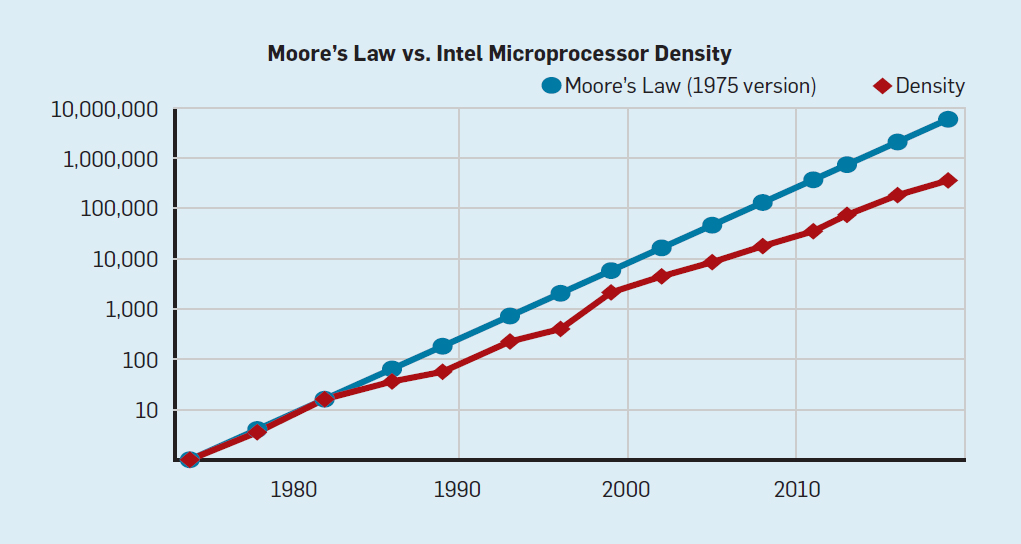 شكل 2. عدد الترانزستورات على شريحة إنتل مقارنةبقانون مور ، وصاحب قانون مور إسقاط قدمه روبرت دينارد بعنوان "دينارد سكالينج"أنه مع زيادة كثافة الترانزستورات ، سينخفض استهلاك الطاقة في الترانزستور ، وبالتالي فإن استهلاك لكل ملم مربع من السيليكون سيكون ثابتًا تقريبًا. نظرًا لنمو الطاقة الحاسوبية لمليمتر السيليكون مع كل جيل جديد من التكنولوجيا ، أصبحت أجهزة الكمبيوتر أكثر كفاءة في استخدام الطاقة. بدأ مقياس Dennard في التباطؤ بشكل كبير في عام 2007 ، وبحلول عام 2012 لم يأتِ من شيء عمليًا (انظر الشكل 3).
شكل 2. عدد الترانزستورات على شريحة إنتل مقارنةبقانون مور ، وصاحب قانون مور إسقاط قدمه روبرت دينارد بعنوان "دينارد سكالينج"أنه مع زيادة كثافة الترانزستورات ، سينخفض استهلاك الطاقة في الترانزستور ، وبالتالي فإن استهلاك لكل ملم مربع من السيليكون سيكون ثابتًا تقريبًا. نظرًا لنمو الطاقة الحاسوبية لمليمتر السيليكون مع كل جيل جديد من التكنولوجيا ، أصبحت أجهزة الكمبيوتر أكثر كفاءة في استخدام الطاقة. بدأ مقياس Dennard في التباطؤ بشكل كبير في عام 2007 ، وبحلول عام 2012 لم يأتِ من شيء عمليًا (انظر الشكل 3).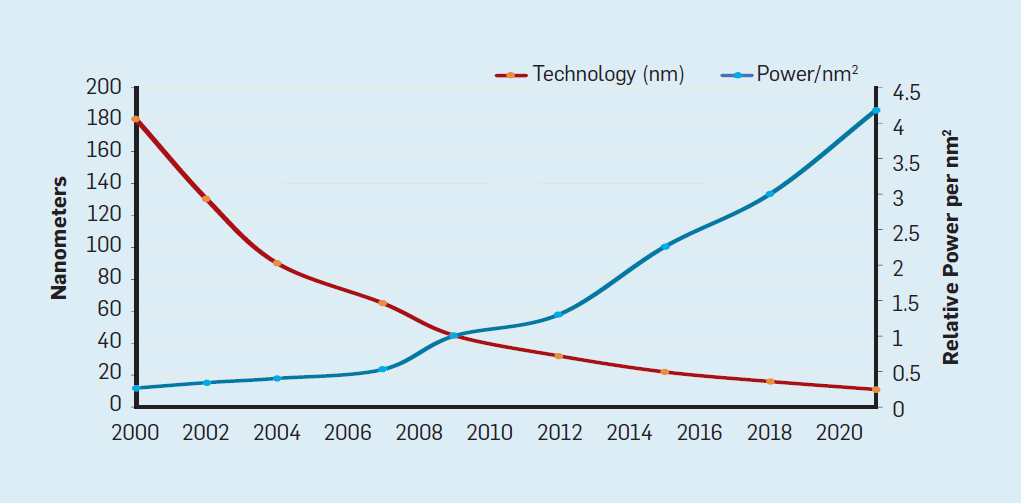 شكل 3. عدد الترانزستورات لكل رقاقة واستهلاك الطاقة لكل ملم مربعمن عام 1986 إلى عام 2002 ، كان التزامن على مستوى التعليم (ILP) هو الطريقة المعمارية الرئيسية لزيادة الإنتاجية. جنبا إلى جنب مع زيادة سرعة الترانزستورات ، وهذا أعطى زيادة سنوية في الإنتاجية بنحو 50 ٪. تعني نهاية قياس Dennard أن على المهندسين المعماريين إيجاد طرق أفضل لاستخدام التزامن.لفهم سبب زيادة الكفاءة في ILP ، فكر في جوهر معالجات ARM و Intel و AMD الحديثة. لنفترض أن لديه خط أنابيب من 15 مرحلة وأربع تعليمات في الساعة. وبالتالي ، يوجد في أي وقت على الناقل ما يصل إلى 60 تعليمات ، بما في ذلك حوالي 15 فرعًا ، لأنها تشكل حوالي 25٪ من التعليمات المنفذة. لملء خط الأنابيب ، يتم توقع الفروع ، ويتم وضع رمز المضاربة في خط الأنابيب للتنفيذ. التنبؤ بالمضاربة هو مصدر كل من أداء ILP وعدم الكفاءة. عندما يكون تنبؤ الفروع مثاليًا ، تعمل المضاربة على تحسين الأداء وتزيد فقط من استهلاك الطاقة بشكل طفيف - وحتى يمكنها توفير الطاقة - ولكن عندما لا يتم التنبؤ بالفروع بشكل صحيح ، يجب على المعالج التخلص من الحسابات الخاطئة.وكل العمل والطاقة يضيعان. يجب أيضًا استعادة الحالة الداخلية للمعالج إلى الحالة التي كانت موجودة قبل الفرع الذي أسيء فهمه ، مع حساب الوقت الإضافي والطاقة.لفهم مدى تعقيد هذا التصميم ، تخيل صعوبة التنبؤ بنتائج 15 فرعًا بشكل صحيح. إذا قام مُنشئ المعالج بتعيين حد 10٪ من الخسائر ، يجب على المعالج أن يتنبأ بشكل صحيح بكل فرع بدقة 99.3٪. لا يوجد العديد من برامج الأغراض العامة التي يمكن التنبؤ بها بدقة.لتقييم ما يتكون هذا العمل الضائع ، اطلع على البيانات في الشكل. 4 ، والتي تبين نسبة الإرشادات التي يتم تنفيذها بكفاءة ولكن تضيع لأن المعالج توقع بشكل غير صحيح المتفرعة. في اختبارات SPEC على Intel Core i7 ، يضيع ما معدله 19٪ من التعليمات. ومع ذلك ، فإن كمية الطاقة المستهلكة أكبر ، حيث يجب على المعالج استخدام طاقة إضافية لاستعادة الحالة عندما يتم التنبؤ بها بشكل غير صحيح.
شكل 3. عدد الترانزستورات لكل رقاقة واستهلاك الطاقة لكل ملم مربعمن عام 1986 إلى عام 2002 ، كان التزامن على مستوى التعليم (ILP) هو الطريقة المعمارية الرئيسية لزيادة الإنتاجية. جنبا إلى جنب مع زيادة سرعة الترانزستورات ، وهذا أعطى زيادة سنوية في الإنتاجية بنحو 50 ٪. تعني نهاية قياس Dennard أن على المهندسين المعماريين إيجاد طرق أفضل لاستخدام التزامن.لفهم سبب زيادة الكفاءة في ILP ، فكر في جوهر معالجات ARM و Intel و AMD الحديثة. لنفترض أن لديه خط أنابيب من 15 مرحلة وأربع تعليمات في الساعة. وبالتالي ، يوجد في أي وقت على الناقل ما يصل إلى 60 تعليمات ، بما في ذلك حوالي 15 فرعًا ، لأنها تشكل حوالي 25٪ من التعليمات المنفذة. لملء خط الأنابيب ، يتم توقع الفروع ، ويتم وضع رمز المضاربة في خط الأنابيب للتنفيذ. التنبؤ بالمضاربة هو مصدر كل من أداء ILP وعدم الكفاءة. عندما يكون تنبؤ الفروع مثاليًا ، تعمل المضاربة على تحسين الأداء وتزيد فقط من استهلاك الطاقة بشكل طفيف - وحتى يمكنها توفير الطاقة - ولكن عندما لا يتم التنبؤ بالفروع بشكل صحيح ، يجب على المعالج التخلص من الحسابات الخاطئة.وكل العمل والطاقة يضيعان. يجب أيضًا استعادة الحالة الداخلية للمعالج إلى الحالة التي كانت موجودة قبل الفرع الذي أسيء فهمه ، مع حساب الوقت الإضافي والطاقة.لفهم مدى تعقيد هذا التصميم ، تخيل صعوبة التنبؤ بنتائج 15 فرعًا بشكل صحيح. إذا قام مُنشئ المعالج بتعيين حد 10٪ من الخسائر ، يجب على المعالج أن يتنبأ بشكل صحيح بكل فرع بدقة 99.3٪. لا يوجد العديد من برامج الأغراض العامة التي يمكن التنبؤ بها بدقة.لتقييم ما يتكون هذا العمل الضائع ، اطلع على البيانات في الشكل. 4 ، والتي تبين نسبة الإرشادات التي يتم تنفيذها بكفاءة ولكن تضيع لأن المعالج توقع بشكل غير صحيح المتفرعة. في اختبارات SPEC على Intel Core i7 ، يضيع ما معدله 19٪ من التعليمات. ومع ذلك ، فإن كمية الطاقة المستهلكة أكبر ، حيث يجب على المعالج استخدام طاقة إضافية لاستعادة الحالة عندما يتم التنبؤ بها بشكل غير صحيح.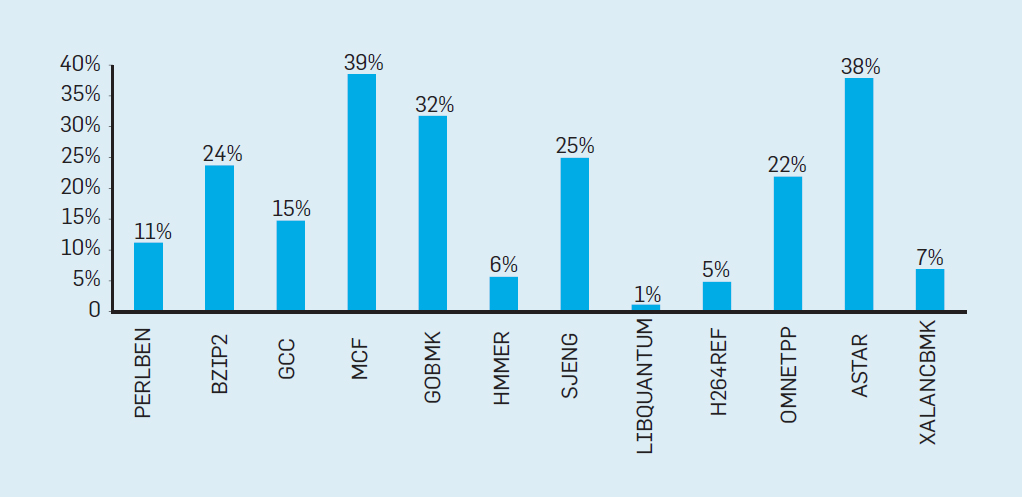 الشكل 4. التعليمات المهدرة كنسبة مئوية من جميع التعليمات التي تم تنفيذها على Intel Core i7 لمختلف اختبارات SPEC الصحيحة ،أدت هذه القياسات إلى استنتاج مفاده أنه ينبغي السعي إلى اتباع نهج مختلف لتحقيق أداء أفضل. لذلك ولدت عصر multicore.في هذا المفهوم ، يتم نقل مسؤولية تحديد التزامن وتحديد كيفية استخدامه إلى المبرمج ونظام اللغة. Multicore لا يحل مشكلة الحوسبة الموفرة للطاقة ، والتي تفاقمت بحلول نهاية عملية القياس التي قام بها Dennard. يستهلك كل قلب نشط الطاقة ، بغض النظر عما إذا كان متورطًا في العمليات الحسابية الفعالة. العقبة الرئيسية هي ملاحظة قديمة تسمى قانون أمدال. تقول أن فوائد الحوسبة المتوازية محدودة بجزء الحوسبة المتسلسلة. لتقييم أهمية هذه الملاحظة ، خذ بعين الاعتبار الشكل 5. فهو يوضح مدى سرعة عمل التطبيق مع 64 مركزًا مقارنةً بنواة واحدة ، بافتراض نسبة مختلفة من العمليات الحسابية المتسلسلة عندما يكون معالج واحد نشطًا فقط. على سبيل المثالإذا كان 1٪ من الوقت يتم إجراء الحساب بشكل متسلسل ، فستكون ميزة تكوين المعالج 64٪ هي 35٪ فقط. لسوء الحظ ، يتناسب استهلاك الطاقة مع 64 معالجات ، لذلك يتم إهدار حوالي 45٪ من الطاقة.
الشكل 4. التعليمات المهدرة كنسبة مئوية من جميع التعليمات التي تم تنفيذها على Intel Core i7 لمختلف اختبارات SPEC الصحيحة ،أدت هذه القياسات إلى استنتاج مفاده أنه ينبغي السعي إلى اتباع نهج مختلف لتحقيق أداء أفضل. لذلك ولدت عصر multicore.في هذا المفهوم ، يتم نقل مسؤولية تحديد التزامن وتحديد كيفية استخدامه إلى المبرمج ونظام اللغة. Multicore لا يحل مشكلة الحوسبة الموفرة للطاقة ، والتي تفاقمت بحلول نهاية عملية القياس التي قام بها Dennard. يستهلك كل قلب نشط الطاقة ، بغض النظر عما إذا كان متورطًا في العمليات الحسابية الفعالة. العقبة الرئيسية هي ملاحظة قديمة تسمى قانون أمدال. تقول أن فوائد الحوسبة المتوازية محدودة بجزء الحوسبة المتسلسلة. لتقييم أهمية هذه الملاحظة ، خذ بعين الاعتبار الشكل 5. فهو يوضح مدى سرعة عمل التطبيق مع 64 مركزًا مقارنةً بنواة واحدة ، بافتراض نسبة مختلفة من العمليات الحسابية المتسلسلة عندما يكون معالج واحد نشطًا فقط. على سبيل المثالإذا كان 1٪ من الوقت يتم إجراء الحساب بشكل متسلسل ، فستكون ميزة تكوين المعالج 64٪ هي 35٪ فقط. لسوء الحظ ، يتناسب استهلاك الطاقة مع 64 معالجات ، لذلك يتم إهدار حوالي 45٪ من الطاقة.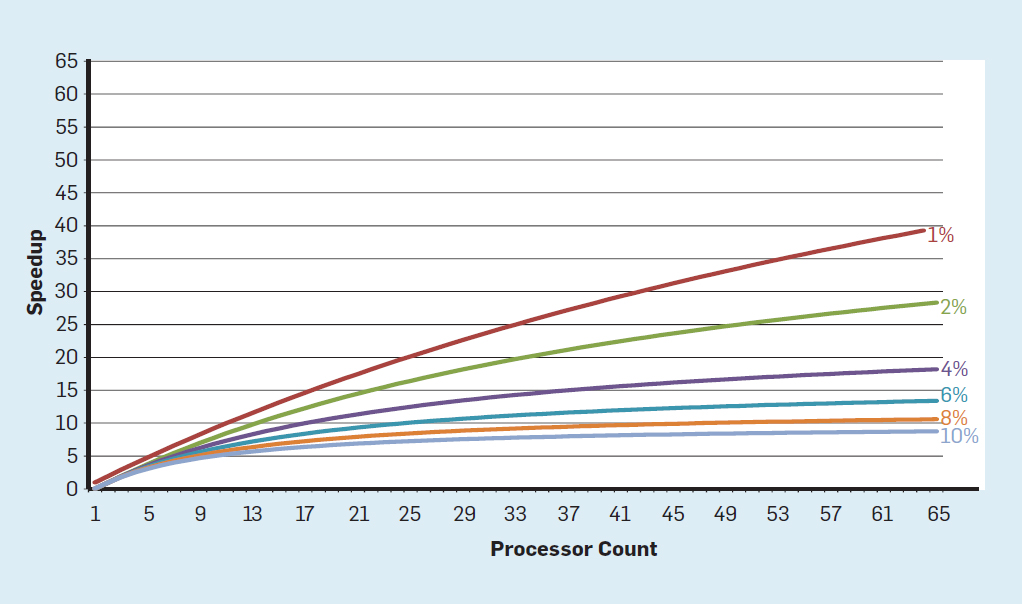 شكل 5. تأثير قانون أمدال على زيادة السرعة ، مع مراعاة نسبة التدابير في وضع تسلسلي ،وبطبيعة الحال ، للبرامج الحقيقية هيكل أكثر تعقيدًا. هناك أجزاء تسمح لك باستخدام عدد مختلف من المعالجات في أي وقت معين. ومع ذلك ، فإن الحاجة إلى التفاعل والمزامنة بشكل دوري تعني أن معظم التطبيقات تحتوي على بعض الأجزاء التي لا يمكنها استخدام جزء من المعالجات إلا بكفاءة. على الرغم من أن قانون أمدال قد تجاوز 50 عامًا ، إلا أنه لا يزال يمثل عقبة صعبة.مع نهاية تحجيم دينارد ، فإن زيادة عدد النوى على الرقاقة تعني أن الطاقة زادت أيضًا بنفس المعدل تقريبًا. لسوء الحظ ، يجب بعد ذلك إزالة الجهد الكهربائي الذي تم تزويد المعالج به كحرارة. وبالتالي ، فإن المعالجات متعددة النواة محدودة بقدرة الخرج الحراري (TDP) أو متوسط مقدار الطاقة الذي يمكن للهيكل ونظام التبريد إزالته. على الرغم من أن بعض مراكز البيانات المتقدمة تستخدم تقنيات تبريد أكثر تطوراً ، لن يرغب أي مستخدم في وضع مبادل حراري صغير على الطاولة أو حمل المبرد على ظهره لتبريد الهاتف المحمول. أدى حد TDP إلى عصر السيليكون الغامق ، عندما تبطئ المعالجات سرعة الساعة وتوقف تشغيل النوى الخاملة لمنع ارتفاع درجة الحرارة. طريقة أخرى للنظر في هذا النهج هوأن بعض الدوائر الصغيرة يمكنها إعادة توزيع قوتها الثمينة من النوى غير النشطة إلى تلك النشطة.إن الحقبة التي لم يتم فيها توسيع نطاق دينارد ، إلى جانب الحد من قانون مور وقانون أمدال ، تعني أن عدم الكفاءة يحد من تحسين الإنتاجية إلى نسبة مئوية قليلة فقط في السنة (انظر الشكل 6).
شكل 5. تأثير قانون أمدال على زيادة السرعة ، مع مراعاة نسبة التدابير في وضع تسلسلي ،وبطبيعة الحال ، للبرامج الحقيقية هيكل أكثر تعقيدًا. هناك أجزاء تسمح لك باستخدام عدد مختلف من المعالجات في أي وقت معين. ومع ذلك ، فإن الحاجة إلى التفاعل والمزامنة بشكل دوري تعني أن معظم التطبيقات تحتوي على بعض الأجزاء التي لا يمكنها استخدام جزء من المعالجات إلا بكفاءة. على الرغم من أن قانون أمدال قد تجاوز 50 عامًا ، إلا أنه لا يزال يمثل عقبة صعبة.مع نهاية تحجيم دينارد ، فإن زيادة عدد النوى على الرقاقة تعني أن الطاقة زادت أيضًا بنفس المعدل تقريبًا. لسوء الحظ ، يجب بعد ذلك إزالة الجهد الكهربائي الذي تم تزويد المعالج به كحرارة. وبالتالي ، فإن المعالجات متعددة النواة محدودة بقدرة الخرج الحراري (TDP) أو متوسط مقدار الطاقة الذي يمكن للهيكل ونظام التبريد إزالته. على الرغم من أن بعض مراكز البيانات المتقدمة تستخدم تقنيات تبريد أكثر تطوراً ، لن يرغب أي مستخدم في وضع مبادل حراري صغير على الطاولة أو حمل المبرد على ظهره لتبريد الهاتف المحمول. أدى حد TDP إلى عصر السيليكون الغامق ، عندما تبطئ المعالجات سرعة الساعة وتوقف تشغيل النوى الخاملة لمنع ارتفاع درجة الحرارة. طريقة أخرى للنظر في هذا النهج هوأن بعض الدوائر الصغيرة يمكنها إعادة توزيع قوتها الثمينة من النوى غير النشطة إلى تلك النشطة.إن الحقبة التي لم يتم فيها توسيع نطاق دينارد ، إلى جانب الحد من قانون مور وقانون أمدال ، تعني أن عدم الكفاءة يحد من تحسين الإنتاجية إلى نسبة مئوية قليلة فقط في السنة (انظر الشكل 6).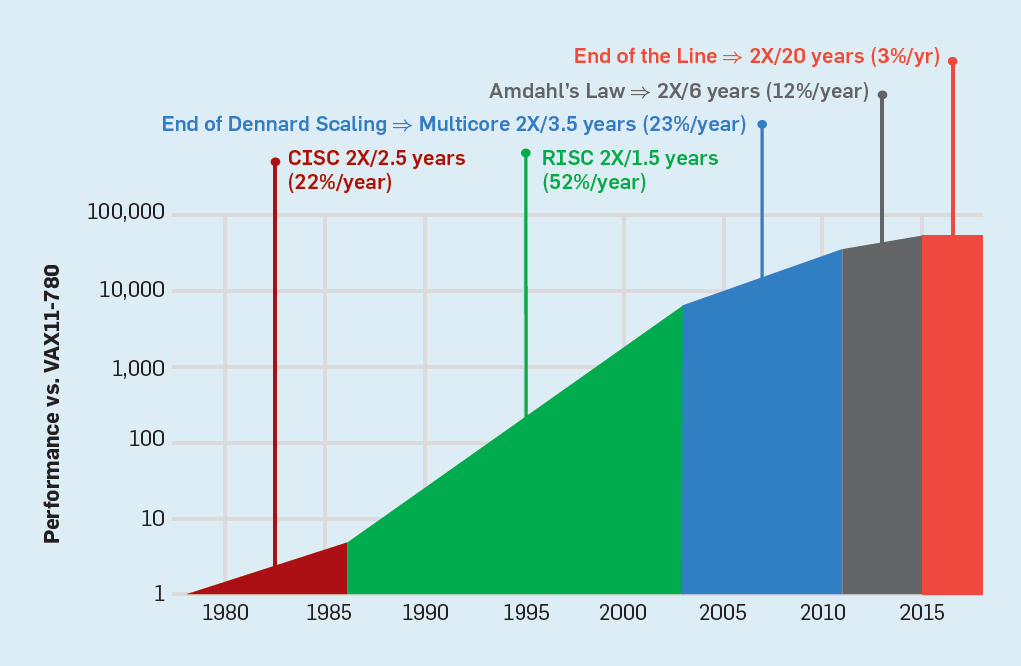 شكل 6. نمو أداء الكمبيوتر عن طريق الاختبارات الصحيحة (SPECintCPU) يتطلبتحقيق معدلات أعلى من تحسين الأداء - كما لوحظ في الثمانينيات والتسعينيات - مناهجًا معمارية جديدة تستفيد من الدوائر المتكاملة بكفاءة أكبر. سنعود إلى مناقشة الأساليب الفعالة المحتملة ، مع الإشارة إلى عيب خطير آخر في أجهزة الكمبيوتر الحديثة - الأمن.
شكل 6. نمو أداء الكمبيوتر عن طريق الاختبارات الصحيحة (SPECintCPU) يتطلبتحقيق معدلات أعلى من تحسين الأداء - كما لوحظ في الثمانينيات والتسعينيات - مناهجًا معمارية جديدة تستفيد من الدوائر المتكاملة بكفاءة أكبر. سنعود إلى مناقشة الأساليب الفعالة المحتملة ، مع الإشارة إلى عيب خطير آخر في أجهزة الكمبيوتر الحديثة - الأمن.الأمن المنسي
في سبعينيات القرن الماضي ، قام مطورو المعالج بضمان أمان الكمبيوتر بجد بمساعدة مفاهيم متنوعة ، بدءًا من حلقات الحماية إلى الوظائف الخاصة. لقد فهموا جيدًا أن معظم الأخطاء ستكون في البرنامج ، لكنهم يعتقدون أن الدعم المعماري يمكن أن يساعد. معظم هذه الميزات لم تستخدم من قبل أنظمة التشغيل التي عملت في بيئات آمنة يفترض (مثل أجهزة الكمبيوتر الشخصية). لذلك ، تم القضاء على الوظائف المرتبطة حمولة كبيرة. في مجتمع البرمجيات ، اعتقد الكثيرون أن الاختبارات والطرق الرسمية مثل استخدام microkernel ستوفر آليات فعالة لإنشاء برامج آمنة للغاية. لسوء الحظ ، فإن نطاق أنظمة البرامج المشتركة لدينا والسعي لتحقيق الأداء يعني أن مثل هذه الأساليب لا يمكن مواكبة الأداء. ونتيجة لذلك ، لا تزال أنظمة البرامج الكبيرة بها الكثير من العيوب الأمنية ، ويتم تضخيم التأثير بسبب الكم الهائل والمتزايد من المعلومات الشخصية على الإنترنت واستخدام الحوسبة السحابية ، حيث يتقاسم المستخدمون نفس المعدات المادية مع مهاجم محتمل.
على الرغم من أن مصممي المعالج وغيرهم لم يدركوا الأهمية المتزايدة للأمان على الفور ، إلا أنهم بدأوا في تضمين دعم الأجهزة للأجهزة الافتراضية والتشفير. لسوء الحظ ، قدم التنبؤ بالفروع ثغرة أمنية غير معروفة ولكنها مهمة في العديد من المعالجات. على وجه الخصوص ،
تستغل نقاط الضعف في Meltdown و Specter ميزات البنية الدقيقة ، مما يسمح بتسريب المعلومات المحمية . يستخدم كلاهما ما يسمى بالهجمات على قنوات الجهات الخارجية عندما تتسرب المعلومات وفقًا للاختلاف في الوقت المستغرق في المهمة. في عام 2018 ، أظهر الباحثون
كيفية استخدام أحد خيارات Specter لاستخراج المعلومات عبر الشبكة دون تنزيل الكود إلى المعالج الهدف . على الرغم من أن هذا الهجوم ، المسمى NetSpectre ، ينقل المعلومات ببطء ، فإن حقيقة أنه يسمح لك بمهاجمة أي جهاز على نفس الشبكة المحلية (أو في نفس المجموعة في السحابة) يخلق العديد من متجهات الهجوم الجديدة. في وقت لاحق ، تم الإبلاغ عن اثنين من نقاط الضعف في بنية الأجهزة الافتراضية (
1 ،
2 ). يسمح لك أحدهما ، يسمى Foreshadow ، باختراق آليات أمان Intel SGX المصممة لحماية البيانات الأكثر قيمة (مثل مفاتيح التشفير). تم العثور على نقاط ضعف جديدة شهريا.
ليست الهجمات على قنوات الجهات الخارجية جديدة ، ولكن في معظم الحالات ، كانت أخطاء البرامج هي السبب في وقت سابق. في Meltdown و Specter وهجمات أخرى ، يعد هذا خطأ في تطبيق الأجهزة. هناك صعوبة أساسية في كيفية تحديد مهندسي المعالج ما هو التنفيذ الصحيح لـ ISA لأن التعريف القياسي لا يقول شيئًا عن تأثيرات أداء تنفيذ سلسلة من التعليمات ، فقط حالة تنفيذ ISA المرئية. يجب على المهندسين المعماريين إعادة التفكير في تعريفهم للتطبيق الصحيح لـ ISA لمنع مثل هذه العيوب الأمنية. في الوقت نفسه ، يجب أن يعيدوا النظر في الاهتمام الذي يولونه لأمن الكمبيوتر ، وكيف يمكن للمهندسين المعماريين العمل مع مطوري البرمجيات لتنفيذ أنظمة أكثر أمانًا. لا ينبغي للمهندسين المعماريين (وأي شخص آخر) أن يأخذوا الأمن بأي طريقة أخرى غير الحاجة الأساسية.
الفرص المستقبلية في هندسة الكمبيوتر
"لدينا فرص مذهلة متنكرة في زي مشاكل غير قابلة للحل." - جون جاردنر ، 1965
إن أوجه القصور الكامنة في معالجات الأغراض العامة ، سواء أكانت تقنية ILP أو معالجات متعددة النواة ، بالإضافة إلى الانتهاء من عملية القياس التي وضعها دينارد وقانون مور ، تجعل من غير المحتمل أن يكون المهندسون المعماريون ومطورو المعالجون قادرين على الحفاظ على وتيرة كبيرة في تحسين الأداء للمعالجات للأغراض العامة. بالنظر إلى أهمية تحسين الإنتاجية للبرمجيات ، يجب أن نطرح السؤال التالي: ما هي الأساليب الواعدة الأخرى؟
هناك احتمالان واضحان ، بالإضافة إلى ثالث تم إنشاؤه من خلال الجمع بين الاثنين. أولاً ، تستخدم أساليب تطوير البرامج الحالية بشكل مكثف اللغات عالية المستوى من خلال الكتابة الديناميكية. لسوء الحظ ، عادة ما يتم تفسير هذه اللغات وتنفيذها بشكل غير فعال للغاية. لتوضيح عدم الكفاءة هذا ، قدم ليسرسون وزملاؤه
مثالاً بسيطًا: ضرب المصفوفة .
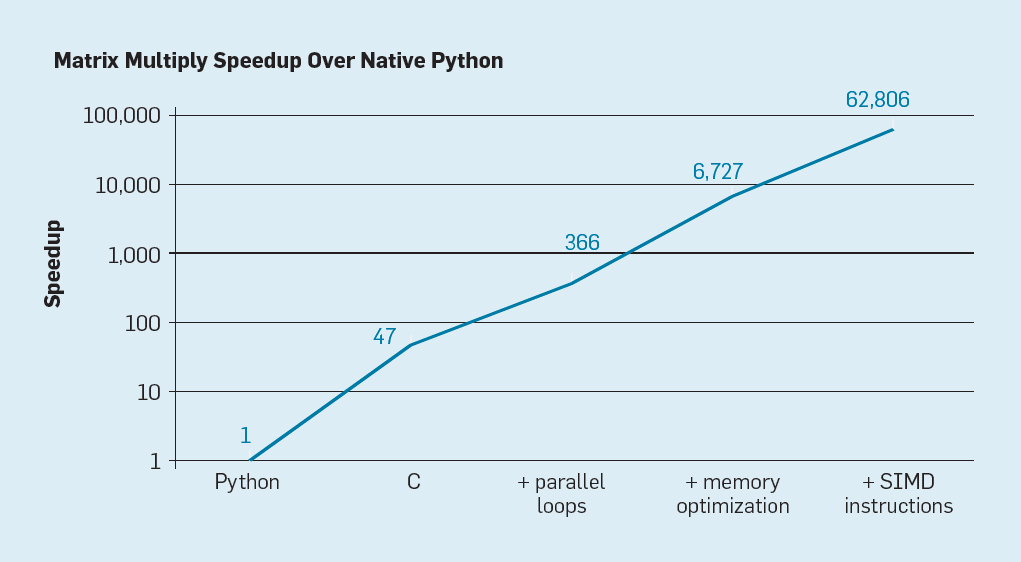 شكل 7. تسارع محتمل لتكاثر مصفوفات بايثون بعد أربعة تحسينات
شكل 7. تسارع محتمل لتكاثر مصفوفات بايثون بعد أربعة تحسيناتكما هو مبين في التين. 7 ، ببساطة إعادة كتابة التعليمات البرمجية من Python إلى C يحسن الأداء بنسبة 47 مرة. يعطي استخدام حلقات متوازية على العديد من النوى عاملًا إضافيًا بحوالي 7. ويعطي تحسين بنية الذاكرة لاستخدام ذاكرات التخزين المؤقت عامل 20 ، ويأتي العامل الأخير وهو 9 من استخدام ملحقات الأجهزة لتنفيذ عمليات SIMD الموازية ، والتي تكون قادرة على تنفيذ 16 إرشادات 32 بت. بعد ذلك ، تعمل النسخة النهائية المحسّنة بدرجة كبيرة على معالج Intel متعدد النواة أسرع بمعدل 62،806 مرة من إصدار Python الأصلي. هذا ، بالطبع ، مثال صغير. يمكن افتراض أن المبرمجين سوف يستخدمون مكتبة محسنة. على الرغم من أن الفجوة في الأداء مبالغ فيها ، إلا أن هناك العديد من البرامج التي يمكن تحسينها من 100 إلى 1000 مرة.
مجال البحث المثير للاهتمام هو مسألة ما إذا كان من الممكن سد بعض الثغرات في الأداء مع تقنية المترجم الجديدة ، وربما مع التحسينات المعمارية. على الرغم من صعوبة ترجمة وتجميع لغات البرمجة النصية عالية المستوى مثل Python بكفاءة ، فإن المردود المحتمل كبير. حتى التحسين البسيط يمكن أن يؤدي إلى حقيقة أن برامج بيثون سوف تعمل أسرع بعشرات المرات. يوضح هذا المثال البسيط مدى الفجوة بين اللغات الحديثة التي تركز على أداء المبرمجين والأساليب التقليدية التي تؤكد على الأداء.
البنى المتخصصة
تتمثل الطريقة الأكثر توجهاً للأجهزة في تصميم بنيات تتكيف مع مجال موضوع معين ، حيث تظهر كفاءة كبيرة. هذه هي بنيات متخصصة خاصة بالمجال (بنيات خاصة بالمجال ، DSAs). عادة ما تكون هذه معالجات قابلة للبرمجة وكاملة ، ولكن مع الأخذ في الاعتبار فئة معينة من المهام. وبهذا المعنى ، فإنها تختلف عن الدوائر المتكاملة الخاصة بالتطبيقات (ASICs) ، والتي تُستخدم غالبًا لنفس الوظيفة مثل الكود الذي نادرًا ما يتغير. غالبًا ما يطلق على DSAs اسم المسرعات لأنها تسرع بعض التطبيقات مقارنة بتشغيل التطبيق بأكمله على وحدة المعالجة المركزية للأغراض العامة. بالإضافة إلى ذلك ، يمكن ل DSAs توفير أداء أفضل لأنها مصممة بشكل أكثر دقة لاحتياجات التطبيق. تتضمن أمثلة DSAs المعالجات الرسومية (GPUs) ، ومعالجات الشبكات العصبية المستخدمة للتعلم العميق ، ومعالجات الشبكات المعرفة بالبرمجيات (SDN). تحقق DSAs أداءً أعلى وكفاءة طاقة أكبر لأربعة أسباب رئيسية.
أولاً ، تستخدم DSAs شكلاً أكثر فعالية من التزامن لمجال موضوع معين. على سبيل المثال ، يعد SIMD (دفق التعليمات الفردي ، دفق البيانات المتعددة)
أكثر فعالية من MIMD (دفق التعليمات المتعدد ، دفق البيانات المتعدد). على الرغم من أن بطاقة SIMD أقل مرونة ، إلا أنها مناسبة تمامًا للعديد من DSAs. يمكن للمعالجات المتخصصة أيضًا استخدام نُهج ILP الخاصة بـ VLIW بدلاً من آليات المضاربة الضعيفة. كما ذكرنا سابقًا ، فإن
معالجات VLIW غير مناسبة لرمز الأغراض العامة ، لكن بالنسبة للمناطق الضيقة ، تكون أكثر فعالية بكثير لأن آليات التحكم أبسط. على وجه الخصوص ، فإن معظم معالجات الأغراض العامة المتطورة متعددة الأنابيب بشكل مفرط ، الأمر الذي يتطلب منطق تحكم معقد لبدء واستكمال التعليمات. في المقابل ، تقوم VLIW بالتحليل والتخطيط الضروريين في وقت التحويل البرمجي ، مما قد يعمل بشكل جيد لبرنامج متوازي بوضوح.
ثانياً ، تستفيد خدمات DSA بشكل أفضل من التسلسل الهرمي للذاكرة. أصبح الوصول إلى الذاكرة أغلى بكثير من العمليات الحسابية ،
كما أشار هورويتز . على سبيل المثال ، يتطلب الوصول إلى كتلة في ذاكرة التخزين المؤقت 32 كيلو بايت طاقة أكثر بنحو 200 مرة من إضافة أعداد صحيحة 32 بت. مثل هذا الفارق الكبير يجعل الوصول إلى الذاكرة أمرًا بالغ الأهمية لتحقيق كفاءة طاقة عالية. تقوم المعالجات ذات الأغراض العامة بتنفيذ تعليمات برمجية تظهر فيها عمليات الوصول إلى الذاكرة عادةً مكانًا مكانيًا وزمانًا ، لكن لا يمكن التنبؤ بها في وقت الترجمة. لذلك ، لزيادة الإنتاجية ، تستخدم وحدات المعالجة المركزية ذاكرة التخزين المؤقت متعددة المستويات وإخفاء التأخير في وحدات DRAM بطيئة نسبيًا خارج الشريحة. غالبًا ما تستهلك ذاكرات التخزين المؤقت متعددة المستويات حوالي نصف طاقة المعالج ، ولكنها تمنع جميع المكالمات تقريبًا إلى DRAM ، والتي تستهلك حوالي 10 أضعاف الطاقة من الوصول إلى ذاكرة التخزين المؤقت للمستوى الأخير.
مخابئ واثنين من العيوب البارزة.
عندما تكون مجموعات البيانات كبيرة جدًا . ببساطة لا تعمل ذاكرات التخزين المؤقت جيدًا عندما تكون مجموعات البيانات كبيرة جدًا ، أو يكون موقعها مؤقتًا أو مكانيًا منخفضًا.
عندما مخابئ تعمل بشكل جيد . عندما تعمل ذاكرة التخزين المؤقت بشكل جيد ، تكون المنطقة عالية جدًا ، بمعنى أن معظم ذاكرة التخزين المؤقت تكون خامدة في معظم الأوقات.
في التطبيقات التي تكون فيها أنماط الوصول إلى الذاكرة محددة ومفهومة جيدًا في وقت الترجمة ، وهذا صحيح بالنسبة للغات النموذجية الخاصة بمجال (DSL) ، يمكن للمبرمجين والمترجمين تحسين استخدام الذاكرة بشكل أفضل من ذاكرات التخزين المؤقت المخصصة ديناميكيًا. وبالتالي ، تستخدم DSAs عادة تسلسل هرمي للذاكرة يتحكم فيه البرنامج بشكل صريح ، على غرار طريقة عمل معالجات المتجهات. في التطبيقات المقابلة ، يتيح لك التحكم اليدوي في ذاكرة المستخدم إنفاق طاقة أقل بكثير من ذاكرة التخزين المؤقت القياسية.
ثالثًا ، يمكن لـ DSA تقليل دقة العمليات الحسابية إذا لم تكن هناك حاجة إلى دقة عالية. تدعم وحدات المعالجة المركزية للأغراض العامة عادةً حسابات عدد صحيح 32 بت و 64 بت ، وكذلك بيانات النقطة العائمة (FP). بالنسبة للعديد من تطبيقات التعلم الآلي والرسومات ، هذه دقة زائدة. على سبيل المثال ، في الشبكات العصبية العميقة ، غالبًا ما يستخدم الحساب أرقامًا من 4 إلى 8 أو 16 بت ، مما يحسن كلاً من إنتاجية البيانات وقدرة المعالجة. وبالمثل ، فإن حسابات الفاصلة العائمة مفيدة لتدريب الشبكات العصبية ، ولكن 32 بت ، وغالبًا 16 بت ، كافية.
أخيرًا ، تستفيد DSAs من البرامج المكتوبة بلغات خاصة بالمجال والتي تتيح مزيدًا من التوافق ، وتحسين البنية ، والوصول إلى الذاكرة ، وتبسيط تراكب التطبيقات الفعال على معالج متخصص.
اللغات الموجهة للموضوع
تتطلب DSAs تكييف العمليات ذات المستوى الأعلى وفقًا لبنية المعالج ، ولكن من الصعب جدًا القيام بها بلغة عامة الغرض مثل Python أو Java أو C أو Fortran. تساعد لغات (DSL) الخاصة بالمجال في ذلك وتتيح لك برمجة DSAs بفعالية. على سبيل المثال ، يمكن لـ DSLs جعل عمليات المتجهات الصريحة والمصفوفة الكثيفة والمصفوفة المتناثرة واضحة ، مما يسمح لبرنامج التحويل البرمجي لـ DSL بتحديد العمليات بفعالية إلى المعالج. من بين اللغات الخاصة بالمجال Matlab ، وهي لغة للعمل مع المصفوفات ، TensorFlow لبرمجة الشبكات العصبية ، P4 للبرمجة للشبكات المعرفة بالبرمجيات ، وهالايد لمعالجة الصور ذات التحولات عالية المستوى.
تتمثل مشكلة DSL في كيفية الحفاظ على الاستقلال المعماري الكافي بحيث يمكن نقل البرنامج الموجود به إلى العديد من البنيات ، مع تحقيق الكفاءة العالية عند مقارنة البرنامج مع DSA الأساسي. على سبيل المثال ،
يقوم نظام XLA بترجمة رمز
Tensorflow إلى أنظمة غير متجانسة باستخدام وحدات معالجة الرسومات Nvidia أو معالجات التنسور (TPUs). تعد موازنة قابلية نقل DSAs مع الحفاظ على الكفاءة مهمة بحثية مهمة لمطوري اللغات ومجمعيها و DSAs أنفسهم.
مثال DSA: TPU v1
وكمثال على DSA ، ضع في اعتبارك Google TPU v1 ، المصمم لتسريع تشغيل الشبكة العصبية (
1 ،
2 ). تم إنتاج TPU هذا منذ عام 2015 ، وقد تم تشغيل العديد من التطبيقات عليه: من استعلامات البحث إلى ترجمة النصوص والتعرف على الصور في برامج AlphaGo و AlphaZero و DeepMind للعب go and chess. كان الهدف هو زيادة الإنتاجية وكفاءة الطاقة في الشبكات العصبية العميقة بمقدار 10 مرات.
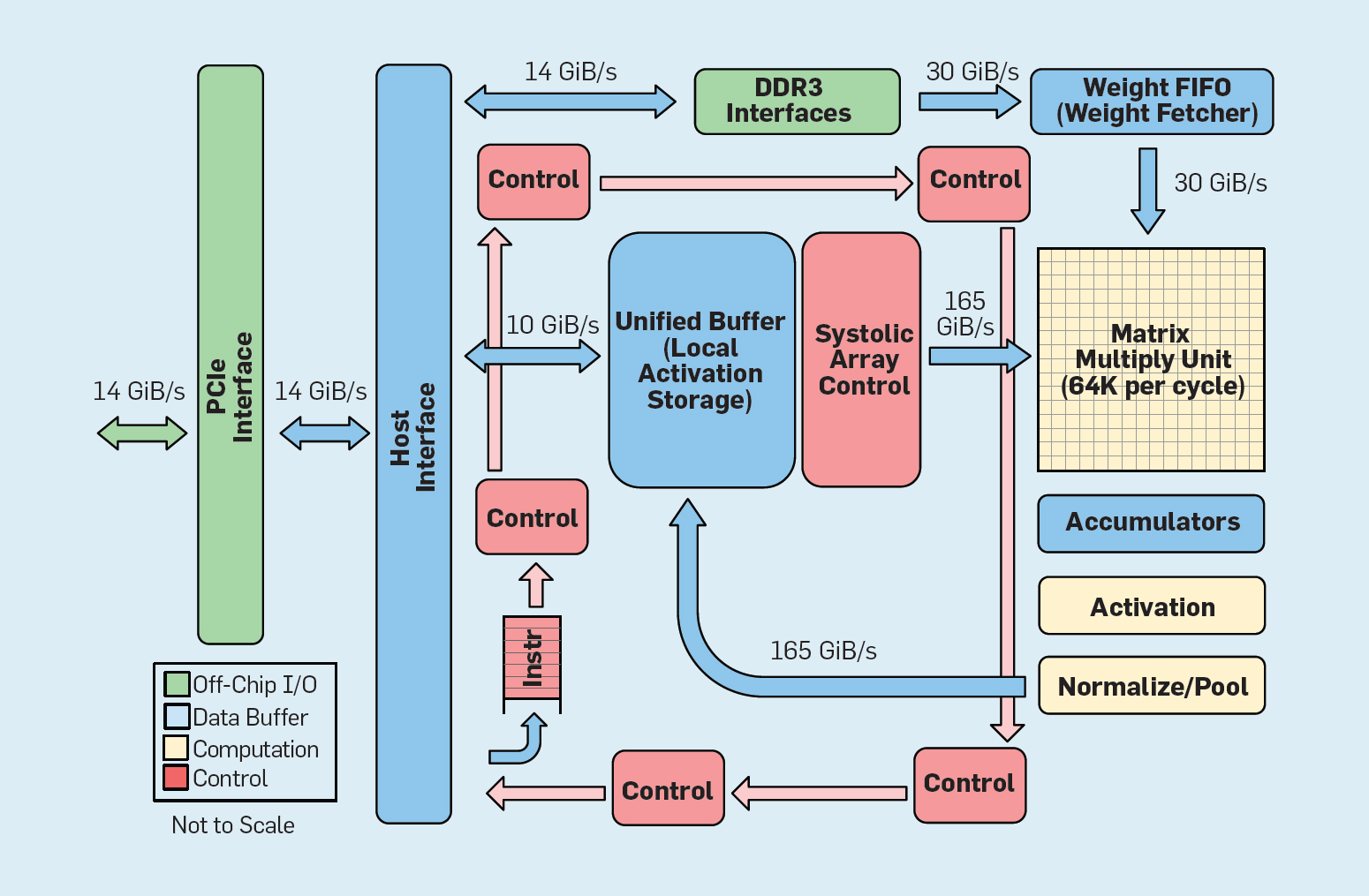 شكل 8. المنظمة الوظيفية Google Tensor Processing Unit (TPU v1)
شكل 8. المنظمة الوظيفية Google Tensor Processing Unit (TPU v1)كما هو مبين في الشكل 8 ، يختلف تنظيم TPU اختلافًا جذريًا عن معالج للأغراض العامة. وحدة الحوسبة الرئيسية هي وحدة المصفوفة ، وهي
بنية المصفوفات الانقباضية ، والتي تنتج كل دورة 256 × 256 تتضاعف تتراكم. إن الجمع بين دقة 8 بت ، وهيكل انقباضي عالي الكفاءة ، والتحكم في SIMD ، وتخصيص جزء كبير من الشريحة لهذه الوظيفة ، يساعد على تنفيذ عمليات مضاعفة تراكمية بمعدل 100 مرة تقريبًا لكل دورة مقارنة بنواة وحدة المعالجة المركزية متعددة الأغراض. بدلاً من التخزين المؤقت ، يستخدم TPU ذاكرة محلية تبلغ 24 ميغابايت ، وهو ضعف حجم ذاكرة التخزين المؤقت لوحدة المعالجة المركزية للأغراض العامة لعام 2015 بنفس TDP. أخيرًا ، ترتبط كل من ذاكرة تنشيط الخلايا العصبية وذاكرة توازن الشبكة العصبية (بما في ذلك بنية FIFO التي تخزن الأوزان) من خلال قنوات عالية السرعة يتحكم فيها المستخدم. إن متوسط الأداء المرجح لـ TPU لستة مشاكل نموذجية للإخراج المنطقي للشبكات العصبية في مراكز بيانات Google أعلى 29 مرة من أداء المعالجات للأغراض العامة. نظرًا لأن الـ TPU تتطلب أقل من نصف الطاقة ، فإن كفاءتها في استخدام الطاقة لأعباء العمل هذه تزيد على 80 ضعف كفاءة المعالجات للأغراض العامة.
ملخص
درسنا طريقتين مختلفتين لتحسين أداء البرنامج من خلال زيادة كفاءة استخدام تقنيات الأجهزة. أولاً ، عن طريق زيادة إنتاجية اللغات الحديثة عالية المستوى التي يتم تفسيرها عادةً. ثانياً ، من خلال إنشاء تصميمات لمجالات مواضيع محددة ، مما يحسن الأداء والكفاءة بشكل ملحوظ مقارنة بمعالجات الأغراض العامة. تعد اللغات الخاصة بالمجال مثالًا آخر على كيفية تحسين واجهة برنامج الأجهزة التي تتيح الابتكارات المعمارية مثل DSA. لتحقيق نجاح كبير باستخدام مثل هذه الأساليب ، ستكون هناك حاجة إلى فريق مشروع متكامل رأسياً على دراية بالتطبيقات واللغات الموجهة نحو الموضوع وتقنيات التجميع ذات الصلة وهندسة الكمبيوتر ، فضلاً عن تقنية التنفيذ الأساسية. كانت الحاجة إلى التكامل الرأسي واتخاذ قرارات التصميم على مستويات مختلفة من التجريد نموذجية لمعظم الأعمال المبكرة في مجال تكنولوجيا الكمبيوتر قبل أن تصبح الصناعة أفقية. في هذا العصر الجديد ، أصبح التكامل الرأسي أكثر أهمية. سيتم منح المزايا للفرق التي يمكنها أن تجد وتقبل الحلول الوسط المعقدة والتحسينات.
لقد أدت هذه الفرصة بالفعل إلى طفرة في الابتكار المعماري ، وجذب العديد من الفلسفات المعمارية المتنافسة:
GPU تستخدم وحدات معالجة الرسومات (Nvidia) وحدات متعددة ، ولكل منها ملفات تسجيل كبيرة وتدفقات أجهزة متعددة وذاكرة تخزين مؤقت.
TPU تعتمد TPUs من Google على صفائف انقباضية كبيرة ثنائية الأبعاد وذاكرة قابلة للبرمجة على الرقاقة.
FPGA تطبق Microsoft Corporation في مراكز البيانات الخاصة بها صفيفات بوابة قابلة للبرمجة بواسطة المستخدم (FPGAs) ، والتي تُستخدم في تطبيقات الشبكات العصبية.
وحدة المعالجة المركزية تقدم Intel معالجات متعددة النوى وذاكرة تخزين مؤقت كبيرة متعددة المستويات وتعليمات SIMD أحادية البعد ، بطريقة مثل FPGA من Microsoft ،
والمعالج العصبي الجديد أقرب إلى TPU من وحدة المعالجة المركزية .
بالإضافة إلى هؤلاء اللاعبين الرئيسيين ، يقوم
العشرات من الشركات الناشئة بتنفيذ أفكارهم الخاصة . لتلبية الطلب المتزايد ، يجمع المصممون المئات والآلاف من الرقائق لإنشاء أجهزة كمبيوتر عملاقة للشبكات العصبية.
يشير هذا الانهيار الجليدي لمباني الشبكات العصبية إلى أن وقتًا مثيرًا للاهتمام قد حان في تاريخ هندسة الكمبيوتر. في عام 2019 ، من الصعب التكهن بأي من هذه المجالات العديدة سيفوز (إذا فاز أي شخص على الإطلاق) ، ولكن السوق ستحدد النتيجة بالتأكيد ، تمامًا كما حلت المناقشة المعمارية في الماضي.
فتح العمارة
باتباع مثال برنامج مفتوح المصدر ناجح ، يمثل فتح ISA فرصة بديلة في هندسة الكمبيوتر. هناك حاجة لإنشاء نوع من "Linux للمعالجات" ، بحيث يمكن للمجتمع إنشاء نواة مفتوحة المصدر بالإضافة إلى الشركات الفردية التي تمتلك نواة الملكية. إذا قامت العديد من المؤسسات بتصميم معالجات تستخدم نفس ISA ، فإن المزيد من المنافسة يمكن أن يؤدي إلى ابتكار أسرع. الهدف هو توفير بنية للمعالجات التي تكلف من بضعة سنتات إلى 100 دولار.
المثال الأول هو RISC-V (RISC Five) ،
هيكل RISC الخامس الذي تم تطويره في جامعة كاليفورنيا في بيركلي . وهي مدعومة من قبل مجتمع تقوده
مؤسسة RISC-V .
يسمح الهيكل المفتوح بتطور المعيار الدولي ISA في نظر الجمهور ، بمشاركة الخبراء حتى يتم اتخاذ قرار نهائي. ميزة إضافية لصندوق مفتوح هي أنه من غير المرجح أن تتوسع ISA لأسباب التسويق بشكل أساسي ، لأن هذا هو التفسير الوحيد في بعض الأحيان لتوسيع مجموعات التعليمات الخاصة بها.RISC-V هي مجموعة تعليمات معيارية. تطلق قاعدة تعليمات صغيرة رزمة برمجيات مفتوحة المصدر كاملة ، تليها امتدادات قياسية إضافية يمكن للمصممين تمكينها أو تعطيلها حسب احتياجاتهم. تحتوي قاعدة البيانات هذه على إصدارات 32 بت و 64 بت من العناوين. يمكن أن تنمو RISC-V فقط من خلال ملحقات اختيارية ؛ ستظل حزمة البرامج تعمل بشكل جيد ، حتى لو لم يقبل المهندسون المعماريون امتدادات جديدة. عادةً ما تتطلب معماريات الملكية توافقًا تصاعديًا على المستوى الثنائي: وهذا يعني أنه إذا أضافت شركة المعالج ميزة جديدة ، فيجب أن تشملها أيضًا جميع المعالجات المستقبلية. RISC-V لا ، هنا جميع التحسينات اختيارية ويمكن إزالتها إذا كان التطبيق لا يحتاج إليها.فيما يلي الملحقات القياسية في الوقت الحالي ، مع الأحرف الأولى من الاسم الكامل:- M. الضرب / تقسيم عدد صحيح.
- أ. عمليات الذاكرة الذرية.
- F / د. واحدة / مزدوجة الدقة عمليات النقطة العائمة.
- تعليمات مضغوطة.
السمة المميزة الثالثة لـ RISC-V هي بساطة ISA. على الرغم من أن هذا المؤشر غير قابل للقياس الكمي ، فإليك مقارنتان بالهيكل ARMv8 ، تم تطويرهما بالتوازي بواسطة ARM:- تعليمات أقل . يحتوي RISC-V على تعليمات أقل بكثير. هناك 50 في قاعدة البيانات ، وهي متشابهة بشكل مدهش من حيث العدد والحرف إلى RISC-I الأصلي . تضيف بقية الإضافات القياسية (M ، A ، F ، و D) 53 تعليمات ، بالإضافة إلى إضافة C 34 أخرى ، وبالتالي فإن العدد الإجمالي هو 137. للمقارنة ، يحتوي ARMv8 على أكثر من 500 تعليمات.
- . RISC-V : , ARMv8 14.
, . RISC-V : - IoT, .
-, RISC-V — 25 , . RISC , , ( ) ( ), .
, RISC-V DSA, .
RISC-V, Nvidia ( 2017 )
إنها بنية حرة ومفتوحة ، تسميها Nvidia Deep Learning Accelerator (NVDLA). إنه DSA قابل للتطوير وقابل للتخصيص للاستدلال في التعلم الآلي. تتضمن معلمات التكوين نوع البيانات (int8 أو int16 أو fp16) وحجم مصفوفة الضرب ثنائية الأبعاد. يتراوح حجم ركيزة السليكون من 0.5 مم ² إلى 3 مم ² ، واستهلاك الطاقة يتراوح من 20 ميغاواط إلى 300 ميغاواط. ISA ، مكدس البرامج والتنفيذ مفتوحة.أبنية مفتوحة بسيطة تسير على ما يرام مع الأمن. أولاً ، لا يؤمن خبراء الأمن بالأمان من خلال الغموض ، لذا فإن تطبيقات المصادر المفتوحة جذابة ، والتطبيقات مفتوحة المصدر تتطلب بنية مفتوحة. بنفس القدر من الأهمية ، هناك زيادة في عدد الأفراد والمؤسسات التي يمكنها الابتكار في مجال البنى الآمنة. تُحد هياكل المباني الخاصة من مشاركة الموظفين ، لكن الهياكل المفتوحة تسمح لأفضل العقول في الأوساط الأكاديمية والصناعة بالمساعدة في مجال الأمن. أخيرًا ، تعمل بساطة RISC-V على تبسيط عملية التحقق من تنفيذها. بالإضافة إلى ذلك ، فإن الهياكل المفتوحة والتطبيقات ومجموعات البرمجيات ، فضلاً عن مرونة FPGAs ، تعني أنه يمكن للمهندسين المعماريين نشر وتقييم حلول جديدة عبر الإنترنت بدورات إصدار أسبوعية بدلاً من دورات سنوية. على الرغم من أن FPGAs أبطأ 10 مرات من الرقائق المخصصة ،لكن أدائها كافٍ للعمل عبر الإنترنت وإظهار الابتكارات الأمنية أمام المهاجمين الحقيقيين للتحقق. نتوقع أن تكون البنايات المفتوحة أمثلة على تصميم الأجهزة والبرامج التعاونية من قبل المهندسين المعماريين وخبراء الأمن.تطوير الأجهزة المرنة
أحدث بيان تطوير البرامج المرنة (2001) Beck et al. ثورة في تطوير البرامج من خلال القضاء على مشاكل نظام الشلال التقليدي القائم على التخطيط والتوثيق. تقوم فرق صغيرة من المبرمجين بسرعة بإنشاء نماذج أولية للعمل ، ولكنها غير مكتملة ، وتتلقى تعليقات العملاء قبل البدء في التكرار التالي. تجمع نسخة سكروم من أجيل فرق من خمسة إلى عشرة من المبرمجين الذين يقومون بالسباق لمدة أسبوعين إلى أربعة أسابيع لكل تكرار.بعد استعارة الفكرة من تطوير البرامج مرة أخرى ، من الممكن تنظيم تطوير أجهزة مرنة. والخبر السار هو أن أدوات التصميم الإلكترونية الحديثة بمساعدة الكمبيوتر (ECAD) قد زادت من مستوى التجريد ، مما أتاح تطويرًا مرنًا. هذا المستوى العالي من التجريد يزيد أيضًا من مستوى إعادة استخدام العمل بين التصميمات المختلفة.تبدو سرعات أربعة أسابيع غير معقولة بالنسبة للمعالجات ، بالنظر إلى الأشهر التي تفصل بين إنشاء التصميم وإنتاج الرقائق. في التين. يوضح الشكل 9 كيف يمكن لطريقة مرنة أن تعمل عن طريق تعديل النموذج الأولي على مستوى مناسب .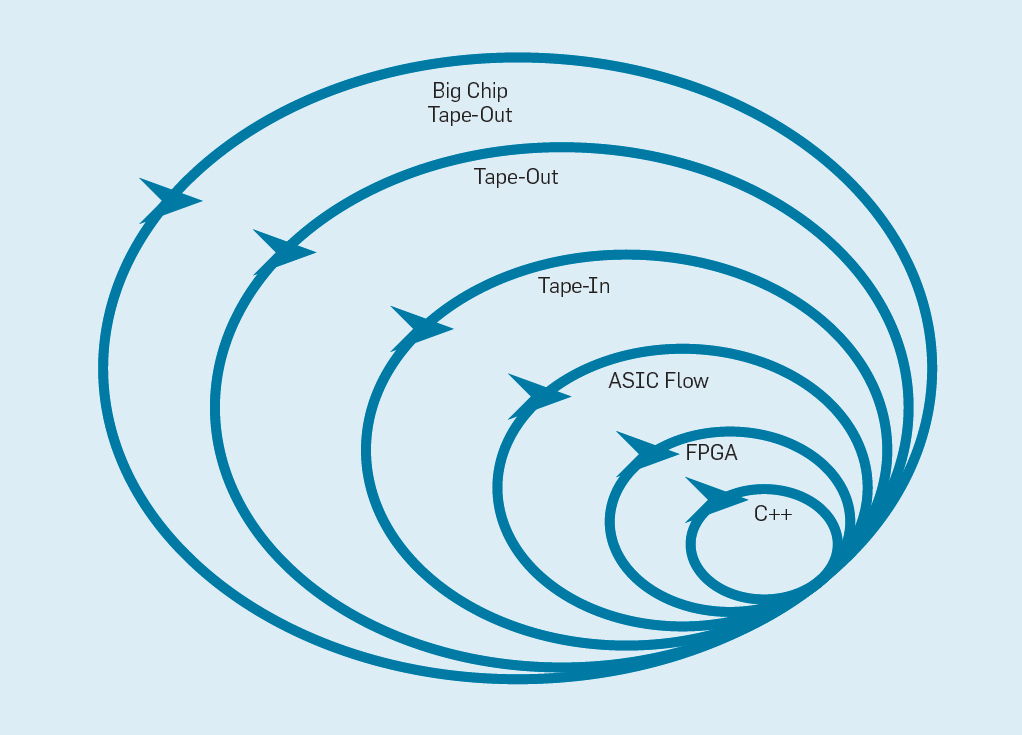 شكل 9. منهجية تطوير المعدات المرنةالمستوى الأعمق هو محاكاة البرامج ، أسهل وأسرع مكان لإجراء التغييرات. المستوى التالي هو رقائق FPGA ، والتي يمكن أن تعمل بمئات المرات أسرع من محاكاة برامج مفصلة. يمكن أن تعمل FPGAs مع أنظمة التشغيل والمعايير الكاملة ، مثل تقييم الأداء القياسي (SPEC) ، والذي يسمح بإجراء تقييم أكثر دقة للنماذج الأولية. تقدم Amazon Web Services FPGAs في السحابة ، بحيث يمكن للمهندسين المعماريين استخدام FPGAs دون الحاجة إلى شراء المعدات أولاً وإنشاء مختبر. يستخدم المستوى التالي أدوات ECAD لإنشاء دائرة شرائح لتوثيق الحجم واستهلاك الطاقة. حتى بعد عمل الأدوات ، من الضروري اتباع بعض الخطوات اليدوية لتحسين النتائج قبل إرسال المعالج الجديد إلى الإنتاج.المطورين المعالج استدعاء هذا المستوى التالي.الشريط في . هذه المستويات الأربعة الأولى تدعم سباق لمدة أربعة أسابيع.لأغراض البحث ، يمكننا التوقف عند المستوى الرابع ، نظرًا لأن تقديرات المساحة والطاقة والأداء دقيقة للغاية. لكن الأمر يشبه العداء الذي أقام سباق الماراثون وتوقف قبل 5 أمتار من النهاية ، لأن وقت الانتهاء قد انتهى بالفعل. على الرغم من صعوبة الاستعداد لسباق الماراثون ، إلا أنه سيفتقد التشويق والسرور بعبور خط النهاية. واحدة من مزايا مهندسي الأجهزة على مهندسي البرمجيات هي أنهم يخلقون أشياء مادية. إن الحصول على رقائق من المصنع: يعد قياس البرامج الحقيقية وتشغيلها وإظهارها للأصدقاء والعائلة فرحة كبيرة للمصمم.يعتقد العديد من الباحثين أنهم يجب أن يتوقفوا لأن صناعة الرقاقات ميسورة التكلفة. ولكن إذا كان التصميم صغيرًا ، فهو غير مكلف بشكل مدهش. يمكن للمهندسين طلب 100 رقاقة من 1 مم مربع مقابل 14000 دولار فقط ، وفي 28 نانومتر ، تحتوي شريحة بحجم 1 مم على ملايين الترانزستورات: هذا يكفي لمعالج RISC-V ومسرع NVLDA. يعد المستوى الخارجي مكلفًا للغاية إذا كان المصمم يعتزم إنشاء شريحة كبيرة ، ولكن يمكن إظهار العديد من الأفكار الجديدة على شرائح صغيرة.
شكل 9. منهجية تطوير المعدات المرنةالمستوى الأعمق هو محاكاة البرامج ، أسهل وأسرع مكان لإجراء التغييرات. المستوى التالي هو رقائق FPGA ، والتي يمكن أن تعمل بمئات المرات أسرع من محاكاة برامج مفصلة. يمكن أن تعمل FPGAs مع أنظمة التشغيل والمعايير الكاملة ، مثل تقييم الأداء القياسي (SPEC) ، والذي يسمح بإجراء تقييم أكثر دقة للنماذج الأولية. تقدم Amazon Web Services FPGAs في السحابة ، بحيث يمكن للمهندسين المعماريين استخدام FPGAs دون الحاجة إلى شراء المعدات أولاً وإنشاء مختبر. يستخدم المستوى التالي أدوات ECAD لإنشاء دائرة شرائح لتوثيق الحجم واستهلاك الطاقة. حتى بعد عمل الأدوات ، من الضروري اتباع بعض الخطوات اليدوية لتحسين النتائج قبل إرسال المعالج الجديد إلى الإنتاج.المطورين المعالج استدعاء هذا المستوى التالي.الشريط في . هذه المستويات الأربعة الأولى تدعم سباق لمدة أربعة أسابيع.لأغراض البحث ، يمكننا التوقف عند المستوى الرابع ، نظرًا لأن تقديرات المساحة والطاقة والأداء دقيقة للغاية. لكن الأمر يشبه العداء الذي أقام سباق الماراثون وتوقف قبل 5 أمتار من النهاية ، لأن وقت الانتهاء قد انتهى بالفعل. على الرغم من صعوبة الاستعداد لسباق الماراثون ، إلا أنه سيفتقد التشويق والسرور بعبور خط النهاية. واحدة من مزايا مهندسي الأجهزة على مهندسي البرمجيات هي أنهم يخلقون أشياء مادية. إن الحصول على رقائق من المصنع: يعد قياس البرامج الحقيقية وتشغيلها وإظهارها للأصدقاء والعائلة فرحة كبيرة للمصمم.يعتقد العديد من الباحثين أنهم يجب أن يتوقفوا لأن صناعة الرقاقات ميسورة التكلفة. ولكن إذا كان التصميم صغيرًا ، فهو غير مكلف بشكل مدهش. يمكن للمهندسين طلب 100 رقاقة من 1 مم مربع مقابل 14000 دولار فقط ، وفي 28 نانومتر ، تحتوي شريحة بحجم 1 مم على ملايين الترانزستورات: هذا يكفي لمعالج RISC-V ومسرع NVLDA. يعد المستوى الخارجي مكلفًا للغاية إذا كان المصمم يعتزم إنشاء شريحة كبيرة ، ولكن يمكن إظهار العديد من الأفكار الجديدة على شرائح صغيرة.الخاتمة
« — » — , 1650
, , , / . iAPX-432 Itanium , , S/360, 8086 ARM , .
, — , , , , , . - , , , . . , , RISC, . , , , , .
, .