
عندما أقدم نفسي وأقول ما الذي تفعله شركة بدء التشغيل الخاصة بنا ، يطرح المحاور على الفور السؤال التالي: هل عملت على Facebook من قبل ، أم أن تطويرك تم إنشاؤه تحت تأثير Facebook؟ يدرك الكثيرون الجهود التي يبذلها موقع Facebook للحفاظ على الرسم البياني الاجتماعي ، لأن الشركة نشرت
العديد من المقالات حول البنية التحتية لهذا الرسم البياني ، والتي قامت ببنائها بعناية.
تحدثت Google عن
الرسم البياني المعرفي الخاص بها ، ولكن لم تتحدث عن البنية الأساسية الداخلية. ومع ذلك ، فإن الشركة لديها أيضا النظم الفرعية المتخصصة لذلك. في الواقع ، يتم إيلاء الكثير من الاهتمام إلى الرسم البياني المعرفة. شخصيا ، وضعت على الأقل اثنين من العروض الترويجية الخاصة بي على هذا الحصان - وبدأت العمل على رسم بياني جديد في عام 2010.
احتاجت Google إلى بناء البنية الأساسية ليس فقط لخدمة العلاقات المعقدة في Knowledge Graph ، ولكن أيضًا لدعم جميع الكتل المواضيعية
OneBox في نتائج البحث التي لها حق الوصول إلى البيانات المهيكلة. البنية التحتية ضرورية من أجل 1) التحايل على جودة الحقائق مع 2) عرض النطاق الترددي العالي بما فيه الكفاية و 3) تأخير منخفضة بما يكفي لالتقاط حصة جيدة من استعلامات البحث على شبكة الإنترنت. اتضح أنه لا يوجد نظام أو قاعدة بيانات واحدة متاحة يمكنها تنفيذ جميع الإجراءات الثلاثة.
الآن وقد شرحت سبب الحاجة إلى البنية التحتية ، في بقية المقالة ، سأتحدث عن تجربتي في بناء مثل هذه الأنظمة ، بما في ذلك لـ
Knowledge Graph و
OneBox .
كيف أعرف ذلك؟
سوف أقدم نفسي لفترة وجيزة. عملت في Google من عام 2006 إلى عام 2013. أولاً كمتدرب ، ثم كمهندس برمجيات في البنية التحتية لبحث الويب.
حصلت Google
على Metaweb في عام 2010 ، وفريقي أطلق للتو
Caffeine . أردت أن أفعل شيئًا آخر - وبدأت العمل مع اللاعبين من Metaweb (في سان فرانسيسكو) ، وقضاء الوقت في السفر بين سان فرانسيسكو وماونتن فيو. أردت معرفة كيفية استخدام الرسم البياني للمعرفة لتحسين بحث الويب الخاص بي.
كانت هناك مثل هذه المشاريع على جوجل قبلي. من الجدير بالذكر أن المشروع المسمى
Squared تم إنشاؤه في مكتب في نيويورك ، وكان هناك بعض الحديث عن بطاقات المعرفة. بعد ذلك ، كانت هناك جهود متفرقة قام بها أفراد / فرق صغيرة ، لكن في ذلك الوقت لم تكن هناك سلسلة فريق ثابتة ، مما أجبرني في النهاية على مغادرة Google. ولكن سنعود إلى هذا في وقت لاحق ...
تاريخ Metaweb
كما ذكرنا سابقًا ، حصلت Google على Metaweb في عام 2010. صمم Metaweb رسمًا بيانيًا للمعرفة عالي الجودة باستخدام عدة طرق ، بما في ذلك الزحف والتحليل على ويكيبيديا ، بالإضافة إلى نظام تحرير على غرار ويكي باستخدام التعهيد الجماعي باستخدام
Freebase . كل هذا يعمل على أساس قاعدة بيانات Graphd الخاصة بالرسوم البيانية - شيطان الرسم البياني (تم
نشره الآن على جيثب).
وكان Graphd بعض الخصائص النموذجية إلى حد ما. كخفي ، كان يعمل على خادم واحد ، وتخزين جميع البيانات في الذاكرة ، ويمكن أن تصدر موقع Freebase بأكمله. بعد الشراء ، قامت Google بتعيين إحدى المهام لمواصلة العمل مع Freebase.
بنيت جوجل إمبراطورية على الأجهزة القياسية والبرامج الموزعة. لن يتمكن أحد نظم إدارة قواعد البيانات (DBMS) من جانب الخادم من تقديم نتائج الزحف والفهرسة والبحث. تم إنشاء SSTable أولاً ، ثم Bigtable ، والذي يتم قياسه أفقيًا لمئات أو الآلاف من الأجهزة التي تشترك في عدد كبير من بايتات البيانات. يتم تخصيص الأجهزة بواسطة Borg (تأتي
K8 من هنا) ، وتتواصل عبر Stubby (تأتي gRPC من هنا) بحل عناوين IP من خلال خدمة اسم Borg (BNC داخل K8) وتخزين البيانات في نظام ملفات Google (
GFS ، يمكنك أن تقول Hadoop FS).
قد تموت العمليات ، قد تنكسر الآلات ، لكن النظام ككل غير قابل للتدمير وسيستمر في الإزعاج.حصلت Graphd في مثل هذه البيئة. إن فكرة وجود قاعدة بيانات تخدم موقعًا كاملاً على خادم واحد غريبة على Google (بما في ذلك أنا). على وجه الخصوص ، يحتاج Graphd إلى 64 جيجابايت أو أكثر من الذاكرة لتشغيله. إذا بدا لك أن هذا قليل ، تذكر: هذا هو عام 2010. تم تجهيز معظم خوادم Google بسعة تصل إلى 32 جيجابايت. في الواقع ، كان على Google شراء أجهزة خاصة ذات ذاكرة RAM كافية لخدمة Graphd بشكله الحالي.
استبدال Graphd
بدأت العصف الذهني حول كيفية نقل بيانات Graphd أو إعادة كتابة النظام للعمل بطريقة موزعة. ولكن ، كما ترى ، الرسوم البيانية معقدة. هذه ليست قاعدة بيانات ذات قيمة أساسية بالنسبة لك ، حيث يمكنك ببساطة أخذ جزء من البيانات ، ونقلها إلى خادم آخر وإصدارها عند طلب مفتاح ما. تؤدي الرسوم البيانية عمليات الربط والحلول الفعالة التي تتطلب أن يعمل البرنامج بطريقة محددة.
كانت فكرة واحدة لاستخدام مشروع يسمى MindMeld (IIRC). كان من المفترض أن الذاكرة من خادم آخر ستكون متاحة بشكل أسرع بكثير من خلال معدات الشبكة. كان يجب أن يكون أسرع من RPCs العادية ، بسرعة كافية لتكرار الوصول المباشر إلى الذاكرة المطلوبة من قبل قاعدة البيانات في الذاكرة. لكن الفكرة لم تذهب بعيدا.
فكرة أخرى أصبحت بالفعل مشروعًا هي إنشاء نظام خدمة رسم بياني موزع حقًا. شيء لا يمكن أن يحل محل Graphd for Freebase فقط ، ولكنه يعمل أيضًا بالفعل في الإنتاج.
كانت تسمى Dgraph - رسم بياني موزع ، مقلوب من Graphd (الرسم البياني الخفي).إذا كنت مهتما ، ثم نعم. تتم تسمية شركتي الناشئة Dgraph Labs والشركة والمشروع المفتوح المصدر Dgraph باسم هذا المشروع على Google (ملاحظة: Dgraph هي علامة تجارية لـ Dgraph Labs ؛ على حد علمي ، لا تطلق Google مشاريع بأسماء تطابق الأسماء الداخلية).
في الجزء المتبقي من النص تقريبًا ، عندما أذكر Dgraph ، أعني مشروع Google الداخلي ، وليس المشروع المفتوح المصدر الذي أنشأناه. ولكن أكثر على
ذلك في وقت لاحق.
قصة Cerebro: محرك المعرفة
إنشاء بنية تحتية عن غير قصد للرسوم البيانيةعلى الرغم من أنني عرفت عمومًا بمحاولة Dgraph لاستبدال Graphd ، إلا أن هدفي كان إنشاء شيء لتحسين البحث على الويب. في Metaweb ، قابلت مهندس أبحاث DH الذي أنشأ
Cubed .
كما ذكرت ، قامت مجموعة متنوعة من المهندسين من قسم نيويورك بتطوير Google
Squared . لكن نظام DH كان أفضل
بكثير . بدأت أفكر في كيفية تنفيذه على Google. كان لدى Google قطع ألغاز يمكنني استخدامها بسهولة.
الجزء الأول من اللغز هو محرك البحث. هذه طريقة لتحديد الكلمات ذات الصلة بدقة مع بعضها البعض. على سبيل المثال ، عندما ترى عبارة مثل [tom hanks movies] ، فقد تخبرك بأن [tom] و [hanks] مرتبطتان. وبالمثل ، من [الطقس سان فرانسيسكو] نرى اتصال بين [سان] و [فرانسيسكو]. هذه أشياء واضحة للناس ، ولكنها ليست واضحة للسيارات.
الجزء الثاني من اللغز هو فهم القواعد. عندما تكون في الاستعلام [كتب للمؤلفين الفرنسيين] ، يمكن للآلة تفسير ذلك على أنه [كتب] من [مؤلفين فرنسيين] ، أي كتب لهؤلاء المؤلفين الفرنسيين. لكنها يمكن أن تفسر هذا أيضًا على أنها [كتب فرنسية] من [مؤلفين] ، أي كتب باللغة الفرنسية من قبل أي مؤلف. لقد استخدمت علامة
جزء الكلام (POS) من جامعة ستانفورد لتحليل القواعد بشكل أفضل وبناء الشجرة.
الجزء الثالث من اللغز هو فهم الكيانات. [الفرنسية] يمكن أن يعني الكثير. قد يكون هذا البلد (المنطقة) أو الجنسية (المتعلقة بالشعب الفرنسي) أو المطبخ (المتعلق بالطعام) أو اللغة. ثم طبقت نظامًا آخر للحصول على قائمة بالكيانات التي يمكن أن تتوافق معها كلمة أو عبارة.
كان الجزء الرابع من اللغز هو فهم العلاقة بين الكيانات. عندما يكون من المعروف كيفية توصيل الكلمات بعبارات ، وبأي ترتيب يجب أن يتم تنفيذ الجمل ، أي قواعدها اللغوية ، وأي الكيانات التي يمكن أن تتوافق معها ، تحتاج إلى العثور على العلاقة بين هذه الكيانات لإنشاء تفسيرات آلية. على سبيل المثال ، نقوم بتشغيل الاستعلام [كتب للمؤلفين الفرنسيين] ، ويقول POS إنه [كتب] من [مؤلفين فرنسيين]. لدينا العديد من الكيانات لـ [الفرنسية] والعديد من [المؤلفين]: يجب أن تحدد الخوارزمية كيفية ارتباطها. على سبيل المثال ، قد تكون مرتبطة حسب مكان الميلاد ، أي المؤلفين الذين ولدوا في فرنسا (على الرغم من أنهم يمكنهم الكتابة باللغة الإنجليزية). أو يمكن أن يكون المؤلفون هم مواطنون فرنسيون. إما المؤلفون الذين يمكنهم التحدث أو الكتابة باللغة الفرنسية (ولكن قد لا يكونون مرتبطين بفرنسا كدولة) ، أو المؤلفين الذين يحبون المطبخ الفرنسي ببساطة.
بحث فهرس الرسم البياني النظام
لتحديد ما إذا كان هناك اتصال بين الكائنات وكيفية اتصالها ، فأنت بحاجة إلى نظام رسم بياني. لم يكن Graphd ينتقل أبدًا إلى مستوى Google ، ولكن يمكنك استخدام البحث نفسه. يتم تخزين بيانات الرسم البياني للمعرفة في تنسيق الثلاثية ، أي أن كل حقيقة يتم تمثيلها بثلاثة أجزاء: الموضوع (الكيان) ، المسند (العلاقة) والكائن (الكيان الآخر). تذهب الطلبات مثل
[SP] → [O] أو
[PO] → [S] ، وأحيانًا
[SO] → [P] .
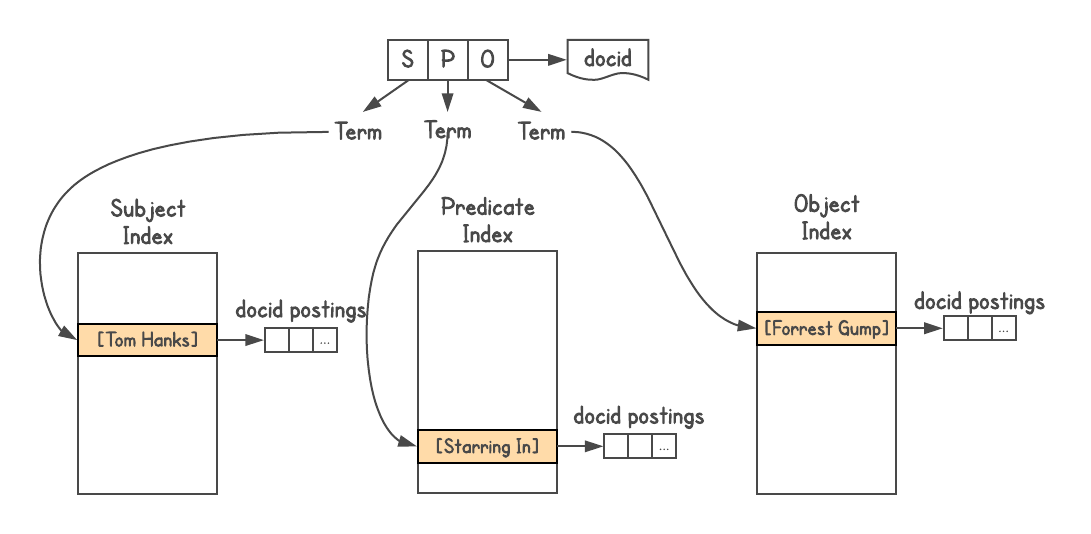 لقد استخدمت فهرس بحث Google
لقد استخدمت فهرس بحث Google ،
وقمت بتعيين مستند لكل ثلاثة أضعاف ، وقمت ببناء ثلاثة فهارس ، أحدها لـ S و P و O. بالإضافة إلى ذلك ، فإن الفهرس قابل للتداخل ، لذلك أضفت معلومات حول نوع كل كيان (مثل الفاعل ، والكتاب ، والشخص ، و الخ).
لقد صنعت مثل هذا النظام ، على الرغم من أنني رأيت مشكلة في عمق الوصلات (وهو موضح أدناه) وهي غير مناسبة للاستعلامات المعقدة. في الواقع ، عندما طلب مني أحد أعضاء فريق Metaweb نشر نظام للزملاء ، رفضت ذلك.لتحديد العلاقة ، يمكنك معرفة عدد النتائج التي يقدمها كل استعلام. على سبيل المثال ، كم عدد النتائج التي تعطيها [الفرنسية] و [المؤلف]؟ نحن نأخذ هذه النتائج ونرى مدى ارتباطها بـ [الكتب] ، إلخ. وهكذا ، ظهر الكثير من التفسيرات الآلية للاستعلام. على سبيل المثال ، يولد الاستعلام [أفلام توم هانكس] مجموعة متنوعة من التفسيرات ، مثل [الأفلام التي أخرجها توم هانكس] ، [الأفلام بطولة توم هانكس] ، [الأفلام التي ينتجها توم هانكس] ، لكنه يرفض تلقائيًا التفسيرات مثل [الأفلام المسماة توم هانكس].
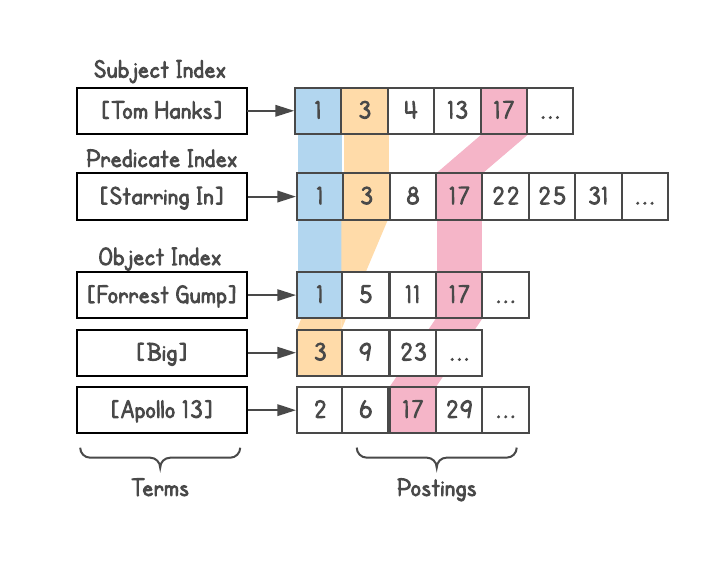
ينشئ كل تفسير قائمة بالنتائج - كيانات صالحة على المخطط - كما يعرض أنواعها (موجودة في المرفقات). ثبت أن هذه وظيفة قوية للغاية لأن فهم نوع النتائج يفتح إمكانيات مثل التصفية أو التصنيف أو التوسع الإضافي. يمكنك فرز الأفلام مع سنة الإصدار ، وطول الفيلم (قصير ، طويل) ، واللغة ، والجوائز المستلمة ، إلخ.
بدا المشروع ذكيًا لدرجة أننا (DH مشاركًا جزئيًا كخبير في الرسم البياني للمعرفة) أطلقنا عليه اسم Cerebro ، تكريماً لجهاز يحمل نفس الاسم من فيلم
"X-Men" .
وكشف Cerebro في كثير من الأحيان حقائق مثيرة للاهتمام التي لم تكن في الأصل في استعلام البحث. على سبيل المثال ، بناءً على طلب [رؤساء الولايات المتحدة] ، سوف يدرك Cerebro أن الرؤساء هم أشخاص ، وأن الناس لديهم نمو. هذا يسمح لنا بترتيب الرؤساء حسب النمو وإظهار أن أبراهام لنكولن هو أعلى رئيس للولايات المتحدة. بالإضافة إلى ذلك ، يمكن تصفية الأشخاص حسب الجنسية. في هذه الحالة ، تظهر أمريكا والمملكة المتحدة في القائمة ، لأن الولايات المتحدة لديها رئيس بريطاني واحد ، ألا وهو جورج واشنطن. (إخلاء المسئولية: تستند النتائج إلى حالة الرسم البياني للمعرفة في وقت التجربة ؛ لا يمكنني أن أؤكد صحة ذلك).
الروابط الزرقاء مقابل المعرفة
كان Cerebro قادراً على فهم طلبات المستخدم حقًا. بعد تلقي بيانات الرسم البياني بأكمله ، يمكننا إنشاء تفسيرات آلية للاستعلام وإنشاء قائمة بالنتائج وفهم الكثير من هذه النتائج لمزيد من الدراسة للرسم البياني. تم شرح ذلك أعلاه: بمجرد أن يفهم النظام أنه يتعامل مع الأفلام أو الأشخاص أو الكتب ، وما إلى ذلك ، يمكن تنشيط بعض الفلاتر وأنواعها. يمكنك حتى الالتفاف حول العقد وإظهار المعلومات ذات الصلة: من [رؤساء الولايات المتحدة] إلى [المدارس التي ذهبوا إليها] أو [الأطفال الذين ولدوا]. فيما يلي بعض الاستعلامات الأخرى التي أنشأها النظام نفسه: [نساء أفريقيات من الأميركيين الأفارقة] ، [ممثلات بوليوود متزوجين من سياسيين] ، [أطفال منا الرؤساء] ، [أفلام بطولة توم هانكس صدرت في التسعينيات]
أظهرت DH هذه الفرصة للانتقال من قائمة إلى أخرى في مشروع آخر يسمى
Parallax .
أظهرت Cerebro نتيجة رائعة للغاية ، ودعمتها إدارة Metaweb. حتى فيما يتعلق بالبنية التحتية ، اتضح أنها فعالة وعملية. دعوتها
محرك المعرفة (مثل محرك البحث). لكن على Google ، لم يتناول أي شخص هذا الموضوع على وجه التحديد. كانت ذات أهمية كبيرة لمديري ، فقد نصحواني بالتحدث مع شخص ما ، ثم مع شخص آخر ، ونتيجة لذلك ، أتيحت لي الفرصة لعرض النظام على مدير بحث عالٍ للغاية.
لم تكن الإجابة هي التي كنت آمل . لإظهار نتائج محرك المعرفة لـ [كتب المؤلفين الفرنسيين] ، أطلق بحثًا على Google وأظهر عشرة أسطر تحتوي على روابط زرقاء وقال إن Google يمكنها أن تفعل الشيء نفسه. بالإضافة إلى ذلك ، لا يريدون نقل حركة المرور من المواقع ، لأنها تغضب.
إذا كنت تعتقد أنه على صواب ، ففكر في هذا: عندما تقوم Google بالبحث على الإنترنت ، فإنها لا تفهم حقًا الطلب. يبحث النظام عن الكلمات الصحيحة في الموضع الصحيح ، مع مراعاة وزن الصفحة وما إلى ذلك. هذا نظام معقد للغاية ، لكنه لا يفهم الاستعلام أو النتائج. يقوم المستخدم بنفسه بكامل العمل: قراءة وتحليل واستخراج المعلومات الضرورية من النتائج وعمليات البحث الإضافية ، إضافة قائمة كاملة بالنتائج ، إلخ.
على سبيل المثال ، بالنسبة لـ [كتب المؤلفين الفرنسيين] ، سيحاول الشخص أولاً العثور على قائمة شاملة ، على الرغم من أنه قد لا يمكن العثور على صفحة واحدة بها هذه القائمة. ثم فرز هذه الكتب حسب سنوات النشر أو التصفية حسب الناشرين وما إلى ذلك - كل هذا يتطلب من الشخص معالجة كمية كبيرة من المعلومات وعمليات البحث المتعددة ومعالجة النتائج. Cerebro قادر على تقليل هذه الجهود وجعل تفاعل المستخدم بسيطًا وخاليًا من العيوب.
ولكن بعد ذلك لم يكن هناك فهم كامل لأهمية الرسم البياني للمعرفة. لم يكن الدليل متأكداً من فائدته أو كيفية ربطه بالبحث.
هذا النهج الجديد للمعرفة ليس سهلاً بالنسبة للمؤسسة التي حققت هذا النجاح الكبير من خلال تزويد المستخدمين بروابط لصفحات الويب.على مدار السنة ، واجهت سوء فهم للمديرين ، وفي النهاية استسلمت. التفت إلي مدير من مكتب شنغهاي ، وسلمته المشروع في يونيو 2011. وضع عليه فريقا من 15 مهندسا. لقد أمضيت أسبوعًا في شنغهاي ، حيث نقلت إلى المهندسين كل ما صنعته وتعلمته. شارك DH أيضًا في هذا العمل ، وقاد الفريق لفترة طويلة.
مشكلة الانضمام إلى العمق
واجه نظام الرسوم البيانية في Cerebro مشكلة في عمق الاتحاد. يتم تنفيذ الانضمام عندما تكون هناك حاجة إلى نتيجة استعلام مبكر لإكمال استعلام لاحق. يتضمن التوحيد النموذجي بعض
SELECT ، أي عامل تصفية في نتائج معينة من مجموعة بيانات عالمية ، ثم يتم استخدام هذه النتائج للتصفية بواسطة جزء آخر من مجموعة البيانات. سأشرح مع مثال.
قل أنك تريد أن تعرف [الأشخاص في SF الذين يتناولون السوشي]. يتم تخصيص بعض البيانات لبعض الأشخاص ، بما في ذلك من يعيش في المدينة ونوع الطعام الذي يتناولونه.
الاستعلام أعلاه هو صلة مستوى واحد. إذا وصل التطبيق إلى قاعدة البيانات ، فسوف يقدم طلبًا واحدًا للخطوة الأولى. ثم استعلامات قليلة (استعلام واحد لكل نتيجة) لمعرفة ما يأكله كل شخص ، واختيار فقط أولئك الذين يتناولون السوشي.
الخطوة الثانية تعاني من مشكلة الخروج. إذا كانت الخطوة الأولى تعطي مليون نتائج (سكان سان فرانسيسكو) ، فيجب إعطاء الخطوة الثانية عند الطلب للجميع ، وطلب عاداتهم الغذائية ، ثم تطبيق مرشح.

عادة ما يحل مهندسو النظام الموزع هذه المشكلة عن طريق
البث ، أي عن طريق التوزيع في كل مكان. يقومون بتجميع النتائج المطابقة ، مما يجعل طلب واحد لكل خادم في المجموعة. يوفر هذا صلة ، ولكنه يسبب مشاكل في زمن استجابة الطلب.
البث لا يعمل بشكل جيد في نظام موزع. أفضل تفسير لهذه المشكلة هو
Jeff Dean من Google في كلمته "تحقيق استجابة سريعة في الخدمات الكبيرة عبر الإنترنت" (
مقاطع الفيديو ،
الشرائح ). التأخير الكلي دائمًا أكبر من تأخير المكون الأبطأ.
يتسبب التوهج الصغير على أجهزة الكمبيوتر الفردية في حدوث تأخير ، كما أن تضمين العديد من أجهزة الكمبيوتر في الاستعلام يزيد بشكل كبير من احتمال حدوث تأخير.النظر في خادم مع تأخير لأكثر من 1 مللي ثانية في 50 ٪ من الحالات ، وأكثر من 1 ثانية في 1 ٪ من الحالات. إذا انتقل الطلب إلى خادم واحد فقط ، فإن 1٪ فقط من الردود تتجاوز الثانية. ولكن إذا كان الطلب يذهب إلى مئات من هذه الخوادم ، فإن 63 ٪ من الردود تتجاوز الثانية.
وبالتالي ، فإن بث طلب واحد يزيد بشكل كبير من التأخير. فكر الآن ، وإذا كنت بحاجة إلى اثنين أو ثلاثة أو أكثر من الجمعيات؟ انها بطيئة جدا في التنفيذ في الوقت الحقيقي.
مشكلة نشر المعجبين عند بث الطلب متأصلة في معظم قواعد البيانات غير الأصلية من الرسوم البيانية ، بما في ذلك
الرسم البياني لـ Janus و
Twitter FlockDB و
Facebook TAO .
الجمعيات الموزعة مشكلة معقدة. تسمح قواعد بيانات الرسم البياني الأصلية بتجنب هذه المشكلة عن طريق تخزين مجموعة بيانات عالمية داخل خادم واحد (قاعدة بيانات مستقلة) وتنفيذ جميع الصلات دون الوصول إلى خوادم أخرى. على سبيل المثال ،
Neo4j يفعل هذا.
Dgraph: النقابات العمق التعسفي
بعد أن أكملت العمل في Cerebro ولديها خبرة في بناء نظام إدارة الرسوم البيانية ، شاركت في مشروع Dgraph ، وأصبحت أحد مديري المشاريع التقنية الثلاثة. طبقنا مفاهيم مبتكرة حل مشكلة عمق الاتحاد.
على وجه الخصوص ، يفصل Dgraph بيانات الرسم البياني بحيث يمكن تنفيذ كل صلة بالكامل بواسطة جهاز واحد. بالرجوع
subject-predicate-object (SPO) ، يحتوي كل مثيل Dgraph على كل الموضوعات والكائنات المقابلة لكل مسند في هذه الحالة. يتم تخزين العديد من المسندات في مثيل ، كل واحد يتم تخزينه بالكامل.
هذا سمح لنا بتلبية الطلبات مع عمق تعسفي من الجمعيات ، والقضاء على مشكلة نشر المعجبين أثناء البث. على سبيل المثال ، سينشئ الاستعلام [الأشخاص في SF الذين يتناولون السوشي]
كحد أقصى مكالمات شبكة اثنين في قاعدة البيانات بغض النظر عن حجم الكتلة. سيجد التحدي الأول جميع الأشخاص الذين يعيشون في سان فرانسيسكو. سوف يرسل الطلب الثاني هذه القائمة للتقاطع مع جميع الأشخاص الذين يتناولون السوشي. بعد ذلك ، يمكنك إضافة قيود أو إضافات إضافية ، لا تزال كل خطوة توفر أكثر من مكالمة شبكة واحدة.

يؤدي ذلك إلى إنشاء مشكلة التنبؤات الكبيرة جدًا على نفس الخادم ، ولكن يمكن حلها عن طريق تقسيم التقديرات بين حالتين أو أكثر مع نمو الحجم. في أسوأ الحالات ، سيتم تقسيم المسند واحد عبر المجموعة بأكملها. ولكن هذا لن يحدث إلا في حالة رائعة ، عندما تتوافق جميع البيانات مع مسند واحد فقط. في حالات أخرى ، يمكن لهذا النهج أن يقلل بشكل كبير من تأخير الطلبات في الأنظمة الحقيقية.
Sharding لم يكن الابتكار الوحيد في Dgraph. تم تعيين معرفات عدد صحيح لكل الكائنات ، وتم فرزها وحفظها في شكل قائمة (قائمة النشر) لعبور هذه القوائم بسرعة في وقت لاحق. يتيح لك هذا التصفية بسرعة أثناء الدمج ، والعثور على روابط شائعة ، وما إلى ذلك. الأفكار من محركات بحث Google مفيدة هنا أيضًا.
الجمع بين جميع كتل OneBox من خلال البلازما
جوجل dgraph لم يكن قاعدة بيانات . كان هذا أحد النظم الفرعية التي استجابت أيضًا للتحديثات. لذلك احتاجت للفهرسة. لقد كانت لدي خبرة واسعة في العمل مع أنظمة الفهرسة الإضافية في الوقت الفعلي التي تعمل تحت
الكافيين .
لقد بدأت مشروعًا لتوحيد كل OneBox ضمن نظام فهرسة الرسم البياني ، بما في ذلك الطقس ومواعيد الرحلات والأحداث وما إلى ذلك. قد لا تعرف مصطلح OneBox ، لكنك بالتأكيد رأيته - هذه نافذة منفصلة تظهر عند تنفيذ أنواع معينة من الاستعلامات ، حيث تقوم Google بإرجاع معلومات أكثر ثراءً. لرؤية OneBox أثناء العمل ، جرّب [
weather in sf ].
في السابق ، كان كل OneBox يعمل على خلفية مستقلة وكان مدعومًا من قبل مجموعات تطوير مختلفة.
كانت هناك مجموعة غنية من البيانات المهيكلة ، لكن وحدات OneBox لم تتبادل البيانات مع بعضها البعض. أولاً ، زيادة تكاليف العمالة المختلفة مرات عديدة. ثانياً ، حد عدم مشاركة المعلومات من نطاق الطلبات التي يمكن أن ترد عليها Google.
على سبيل المثال ، [الأحداث في SF] يمكن أن تظهر الأحداث ، و [الطقس في SF] يمكن أن تظهر الطقس. ولكن إذا أدركت [الأحداث في SF] أنها أصبحت ممطرة الآن ، فيمكنك تصفية الأحداث أو فرزها حسب النوع "في الداخل" أو "في الهواء الطلق" (
ربما يكون من الأفضل الذهاب إلى السينما بدلاً من كرة القدم في أمطار غزيرة) )
بمساعدة فريق Metaweb ، بدأنا في تحويل جميع هذه البيانات إلى تنسيق SPO وفهرستها باستخدام نظام واحد. لقد أطلق عليها اسم
بلازما ، وهو محرك فهرسة الرسم البياني في الوقت الحقيقي لخدمة Dgraph.
إدارة قفزة
مثل Cerebro ، تلقى مشروع البلازما موارد قليلة ، لكنه واصل اكتساب الزخم. في النهاية ، عندما أدركت الإدارة أن كتل OneBox كانت جزءًا حتميًا من مشروعنا ، قررت على الفور تعيين
"الأشخاص المناسبين" لإدارة نظام الرسم البياني. في ذروة اللعبة السياسية ، تم استبدال ثلاثة قادة ، كل منهم لديه خبرة صفر في العمل مع الرسوم البيانية.
خلال قفزة Dgraph هذه ، دعا مديرو مشروع
Spanner Dgraph
إلى نظام
معقد للغاية . كمرجع ، Spanner هي قاعدة بيانات SQL موزعة في جميع أنحاء العالم والتي تحتاج إلى ساعة GPS خاصة بها لضمان الاتساق العالمي.
المفارقة في هذا لا تزال تهب سقف بلدي.تم إلغاء Dgraph ، نجا البلازما. وعلى رأس المشروع ، قاموا بتشكيل فريق جديد مع قائد جديد ، مع تسلسل هرمي واضح وتقديم التقارير إلى المدير التنفيذي. قرر الفريق الجديد - الذي لديه فهم ضعيف للرسوم البيانية والمشاكل ذات الصلة - إنشاء نظام فرعي للبنية التحتية استنادًا إلى فهرس بحث Google الحالي (كما فعلت مع Cerebro). اقترحت استخدام النظام الذي قمت به بالفعل مع Cerebro ، لكن تم رفضه. لقد قمت بتعديل Plasma للزحف إلى كل عقدة معرفة وتوسيعها إلى عدة مستويات حتى يتمكن النظام من عرضها كوثيقة ويب. ودعوا هذا النظام TS (
اختصار ).
هذا يعني أن النظام الفرعي الجديد لن يكون قادرًا على أداء ارتباطات عميقة. مرة أخرى ، هذه لعنة أراها في العديد من الشركات لأن المهندسين يبدأون بالفكرة الخاطئة بأن "الرسوم البيانية تمثل مشكلة بسيطة يمكن حلها ببساطة عن طريق بناء طبقة فوق نظام آخر."
بعد بضعة أشهر ، في مايو 2013 ، غادرت Google بعد العمل على Dgraph / Plasma لمدة عامين تقريبًا.
خاتمة
- بعد بضع سنوات ، تمت إعادة تسمية وحدة "البنية التحتية لبحث الإنترنت" إلى "البنية التحتية للبحث عن الإنترنت ومعرفة الرسم البياني" ، والزعيم الذي عرضت عليه ذات مرة سيريبرو يرأس اتجاه "الرسم البياني للمعرفة" ، ويتحدث عن الطريقة التي يعتزمون استبدالها بالبساطة. روابط المعرفة الزرقاء للإجابة على أسئلة المستخدم بشكل مباشر قدر الإمكان.
- عندما كان فريق شنغهاي الذي يعمل في Cerebro على وشك وضعه قيد الإنتاج ، تم نقل المشروع منه وتم تسليمه إلى قسم نيويورك. في النهاية ، تم إطلاقه كقطاع المعرفة. إذا كنت تبحث عن [ أفلام توم هانكس ] ، فسترى ذلك في الأعلى. لقد تحسنت قليلاً منذ الإطلاق الأول ، لكنها لا تدعم مستوى التصفية والفرز الذي تم وضعه في Cerebro.
- غادر المديرون الفنيون الثلاثة الذين عملوا في Dgraph (بما فيهم أنا) Google في النهاية. حسب علمي ، يعمل الباقون الآن في Microsoft و LinkedIn.
- تمكنت من الحصول على عرضين ترويجيين في Google ، وكان من المفترض أن أحصل على الثلث عندما غادرت الشركة كمهندس برامج أقدم (مهندس برامج أول).
- إنطلاقًا من بعض الشائعات المجزأة ، فإن الإصدار الحالي من TS هو في الواقع قريب جدًا من تصميم نظام الرسم البياني Cerebro ، ولكل موضوع ، مسند ، وموضوع به فهرس. لذلك ، فهي لا تزال تعاني من مشكلة عمق التوحيد.
- تمت إعادة كتابة البلازما وإعادة تسميتها منذ ذلك الحين ، لكنها تواصل العمل كنظام لفهرسة الرسم البياني في الوقت الفعلي لنظام TS. معًا ، يواصلون نشر جميع البيانات المنظمة ومعالجتها على Google ، بما في ذلك الرسم البياني للمعرفة.
- إن عجز Google عن تكوين نقابات عميقة مرئي في العديد من الأماكن. على سبيل المثال ، ما زلنا لا نرى تبادل البيانات بين كتل OneBox: [المدن التي بها معظم الأمطار في آسيا] لا تقدم قائمة بالمدن ، على الرغم من أن جميع البيانات موجودة في عمود المعرفة (بدلاً من ذلك ، يتم ذكر صفحة الويب في نتائج البحث) ؛ لا يمكن تصفية [الأحداث في SF] حسب الطقس ؛ نتائج [رؤساء الولايات المتحدة] لا يتم فرزها أو تصفيتها أو توسيعها حسب حقائق أخرى: أطفالهم أو المدارس التي درسوا فيها. أعتقد أن هذا كان أحد أسباب توقف دعم Freebase .
Dgraph: طائر الفينيق
بعد عامين من مغادرة Google ، قررت
تطوير Dgraph . في الشركات الأخرى ، أرى نفس التردد فيما يتعلق بالرسومات كما هو الحال في Google. كانت هناك العديد من الحلول غير المكتملة في مساحة الرسم البياني ، على وجه الخصوص ، تم تجميع العديد من الحلول المخصصة على عجل على رأس قواعد البيانات العلائقية أو NoSQL ، أو باعتبارها واحدة من العديد من ميزات قواعد البيانات متعددة النماذج. إذا كان هناك حل أصلي ، فإنه يعاني من مشاكل قابلية التوسع.
لم يكن لدى أي شيء رأيته قصة متماسكة ذات تصميم منتج وقابل للتطوير.
يعد إنشاء قاعدة بيانات رسم بيانية قابلة للتطوير أفقياً مع الوصلات المنخفضة والعمق التعسفي مهمة صعبة للغاية ، وأردت التأكد من قيامنا بإنشاء Dgraph بشكل صحيح.
قضى فريق Dgraph السنوات الثلاث الماضية ليس فقط في دراسة تجربتي الخاصة ، ولكن أيضًا بذل الكثير من جهودهم الخاصة في التصميم - إنشاء قاعدة بيانات بيانية لا تحتوي على نظائرها في السوق. وبالتالي ، فإن الشركات لديها الفرصة لاستخدام حل موثوق وقابل للتطوير ومنتج بدلاً من حل آخر غير مكتمل.