كان اكتشاف الهجوم جزءًا من أمن المعلومات على مدار عقود. يرجع تاريخ أول أنظمة اكتشاف التسلل (IDS) إلى أوائل الثمانينيات.
في الوقت الحاضر ، توجد صناعة لكشف الهجمات بالكامل. هناك عدد من أنواع المنتجات - مثل حلول IDS و IPS و WAF وجدار الحماية - معظمها يوفر اكتشاف الهجوم القائم على القواعد. لا تبدو فكرة استخدام نوع من الشذوذ الإحصائي لتحديد الهجمات في الإنتاج واقعية كما كانت عليه في السابق. لكن هل هذا الافتراض مبرر؟
الكشف عن الحالات الشاذة في تطبيقات الويب
ظهرت أول جدران حماية مصممة للكشف عن هجمات تطبيقات الويب في السوق في أوائل التسعينيات. تطورت كل من تقنيات الهجوم وآليات الحماية بشكل كبير منذ ذلك الحين ، مع سباق المهاجمين للتقدم خطوة واحدة إلى الأمام.
تحاول معظم جدران الحماية الحالية لتطبيقات الويب (WAFs) اكتشاف الهجمات بطريقة مماثلة ، مع تضمين محرك يستند إلى قواعد في وكيل عكسي من نوع ما. وأبرز مثال على ذلك هو mod_security ، وهي وحدة WAF لخادم الويب Apache ، والتي تم إنشاؤها في عام 2002. للاكتشاف القائم على القواعد بعض العيوب: على سبيل المثال ، فشل في اكتشاف الهجمات الجديدة (الأيام صفر) ، على الرغم من أن هذه الهجمات نفسها قد يتم اكتشافها بسهولة بواسطة خبير بشري. هذه الحقيقة ليست مفاجئة ، لأن الدماغ البشري يعمل بشكل مختلف تمامًا عن مجموعة من التعبيرات العادية.
من وجهة نظر WAF ، يمكن تقسيم الهجمات إلى هجمات متسلسلة (سلسلة زمنية) وتلك التي تتكون من طلب HTTP واحد أو استجابة. ركز بحثنا على اكتشاف النوع الأخير من الهجمات ، والتي تشمل:
- حقن SQL
- البرمجة عبر المواقع
- حقن الوحدة الخارجية XML
- اجتياز المسار
- قائد نظام التشغيل
- حقن الكائن
لكن أولاً ، دعنا نسأل أنفسنا: كيف يفعل الإنسان ذلك؟
ماذا سيفعل الإنسان عند رؤية طلب واحد؟
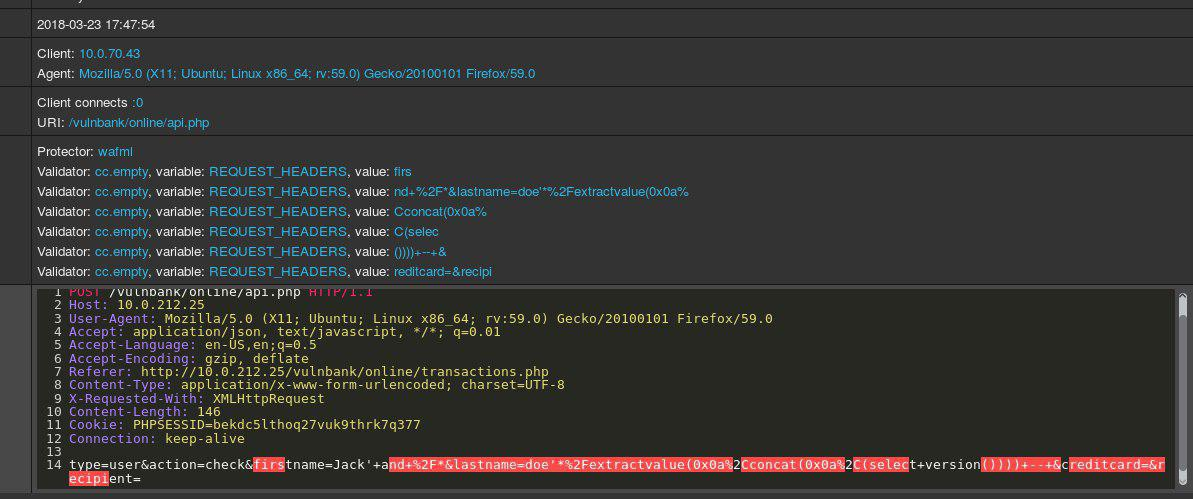
ألق نظرة على نموذج طلب HTTP منتظم لبعض التطبيقات:
إذا كان عليك اكتشاف الطلبات الضارة التي تم إرسالها إلى التطبيق ، فمن المرجح أنك تريد مراقبة الطلبات الحميدة لفترة من الوقت. بعد النظر في طلبات عدد من نقاط نهاية تنفيذ التطبيق ، سيكون لديك فكرة عامة عن كيفية تنظيم الطلبات الآمنة وما تحتويه.
الآن يتم تقديمك مع الطلب التالي:

أنت على الفور يستنتج أن هناك شيئا خطأ. يستغرق الأمر بعض الوقت لفهم ما هو بالضبط ، وبمجرد تحديد موقع قطعة الطلب الشاذ بالضبط ، يمكنك البدء في التفكير في نوع الهجوم. في الأساس ، هدفنا هو جعل اكتشاف هجوم الذكاء الاصطناعي لدينا يعالج المشكلة بطريقة تشبه هذا المنطق الإنساني.
تعقيد مهمتنا هو أن بعض الزيارات ، على الرغم من أنها قد تبدو ضارة من النظرة الأولى ، قد تكون في الواقع طبيعية لموقع ويب معين.
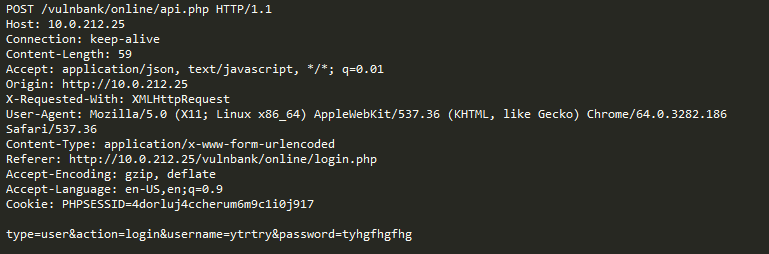
على سبيل المثال ، دعنا ننظر إلى الطلب التالي:
هل هو شذوذ؟ في الواقع ، هذا الطلب حميد: إنه طلب نموذجي يتعلق بنشر الأخطاء على متتبع أخطاء Jira.
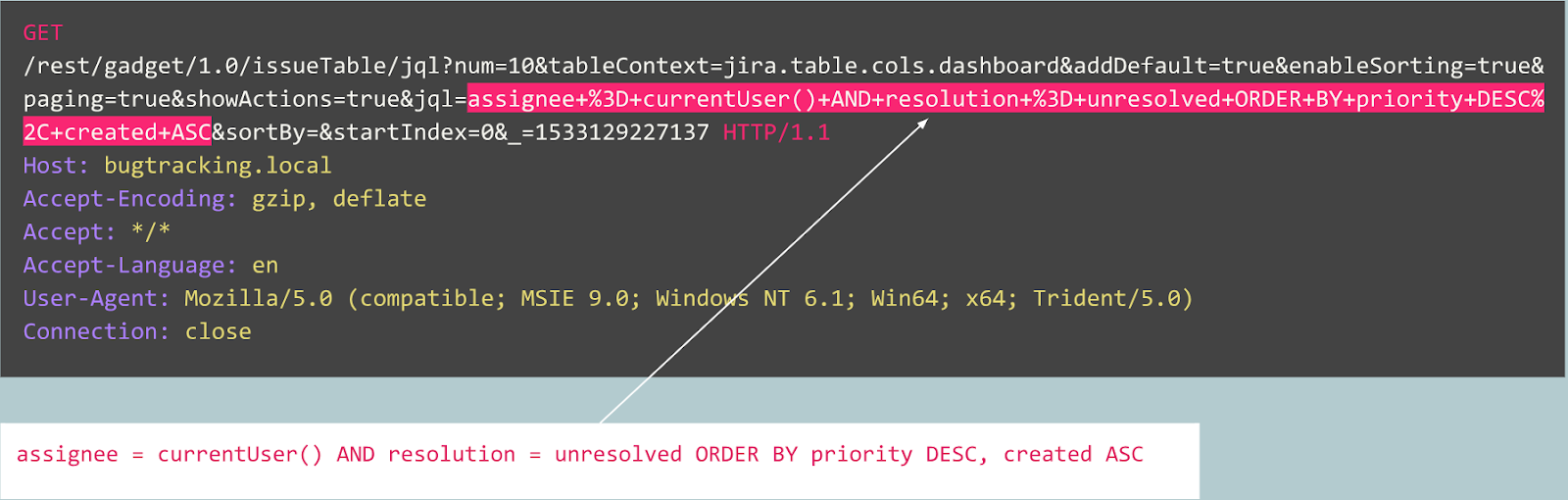
الآن دعونا نلقي نظرة على حالة أخرى:

في البداية ، يبدو الطلب بمثابة تسجيل مستخدم نموذجي على موقع ويب مدعوم من Joomla CMS. ومع ذلك ، فإن العملية المطلوبة هي "user.register" بدلاً من "Registration.register" العادي. تم إهمال الخيار السابق ويحتوي على ثغرة أمنية تسمح لأي شخص بالتسجيل كمسؤول.
يُعرف هذا الاستغلال باسم "جملة <3.6.4 إنشاء الحساب / تصعيد الامتياز" (CVE-2016-8869 ، CVE-2016-8870).

كيف بدأنا
لقد ألقينا أولاً نظرة على الأبحاث السابقة ، حيث تم إجراء العديد من المحاولات لإنشاء خوارزميات مختلفة للتعلم الإحصائي أو الآلي للكشف عن الهجمات على مدار العقود الماضية. أحد الأساليب الأكثر شيوعًا هو حل مهمة التعيين لفئة ("طلب حميد" و "حقن SQL" و "XSS" و "CSRF" وما إلى ذلك). في حين أن الفرد قد يحقق دقة لائقة مع تصنيف لمجموعة بيانات معينة ، إلا أن هذا النهج فشل في حل بعض المشكلات المهمة للغاية:
- اختيار مجموعة الصف . ماذا لو تم عرض النموذج الخاص بك أثناء التعلم على ثلاثة فصول ("حميدة" و "SQLi" و "XSS") ولكن في الإنتاج واجهت هجوم CSRF أو حتى تقنية هجوم جديدة تمامًا؟
- معنى هذه الفئات . افترض أنك بحاجة إلى حماية 10 عملاء ، كل منهم يشغل تطبيقات ويب مختلفة تمامًا. بالنسبة لمعظمهم ، لن يكون لديك أي فكرة عن شكل هجوم "حقن SQL" المفروض على تطبيقاتهم. هذا يعني أنه سيتعين عليك إنشاء مجموعات بيانات التعلم بطريقة مصطنعة بطريقة ما - وهي فكرة سيئة ، لأنك ستنتهي في النهاية بالتعلم من البيانات بتوزيع مختلف تمامًا عن بياناتك الحقيقية.
- تفسير نتائج النموذج الخاص بك . عظيم ، لذلك جاء النموذج مع علامة "حقن SQL" - الآن ماذا؟ أنت والأهم من ذلك عميلك ، وهو أول من يرى التنبيه ، وهو عادةً ليس خبيراً في هجمات الويب ، عليك تخمين أي جزء من الطلب يعتبره النموذج ضارًا.
مع وضع ذلك في الاعتبار ، قررنا إعطاء التصنيف تجربة على أي حال.
نظرًا لأن بروتوكول HTTP يستند إلى النص ، فقد كان من الواضح أنه كان علينا إلقاء نظرة على مصنفات النص الحديثة. أحد الأمثلة المعروفة هو تحليل المشاعر لمجموعة بيانات مراجعة فيلم IMDB. تستخدم بعض الحلول الشبكات العصبية المتكررة (RNN) لتصنيف هذه المراجعات. قررنا استخدام نموذج تصنيف RNN مشابه مع بعض الاختلافات الطفيفة. على سبيل المثال ، يستخدم RNNs لتصنيف اللغة الطبيعية زخارف الكلمات ، ولكن ليس من الواضح ما هي الكلمات الموجودة بلغة غير طبيعية مثل HTTP. لهذا السبب قررنا استخدام زخارف الشخصيات في نموذجنا.
لا تعد الحفلات الجاهزة جاهزة للتغلب على المشكلة ، وهذا هو السبب في أننا استخدمنا تعيينات بسيطة من الأحرف لرموز رقمية مع العديد من العلامات الداخلية مثل
GO و
EOS .
بعد أن انتهينا من تطوير واختبار النموذج ، جاءت جميع المشكلات التي تم التنبؤ بها سابقًا ، ولكن على الأقل انتقل فريقنا من التفكير العاطل إلى شيء منتج.
كيف تابعنا
من هناك ، قررنا محاولة جعل نتائج نموذجنا أكثر قابلية للتفسير. في مرحلة ما ، صادفنا آلية "الاهتمام" وبدأنا في دمجها في نموذجنا. وقد أسفر ذلك عن بعض النتائج الواعدة: أخيرًا ، كل شيء تضافرت وحصلنا على بعض النتائج القابلة للتفسير من قبل الإنسان. بدأ نموذجنا الآن في إخراج ليس فقط الملصقات ولكن أيضًا معاملات الانتباه لكل حرف من المدخلات.
إذا كان من الممكن تصور ذلك ، على سبيل المثال ، في واجهة الويب ، يمكننا تلوين المكان المحدد حيث تم العثور على هجوم "حقن SQL". كانت هذه نتيجة واعدة ، لكن المشكلات الأخرى ما زالت دون حل.
بدأنا نرى أنه يمكننا الاستفادة من المضي في اتجاه آلية الاهتمام ، وبعيدًا عن التصنيف. بعد قراءة الكثير من البحوث ذات الصلة (على سبيل المثال ، "الاهتمام هو كل ما تحتاج إليه" ، Word2Vec ، وأبنية التشفير - وحدة فك الترميز) على نماذج التسلسل ومن خلال تجربة بياناتنا ، تمكنا من إنشاء نموذج اكتشاف شاذ من شأنه أن يعمل في أكثر أو أقل بنفس الطريقة كخبير بشري.
مشعلات السيارات
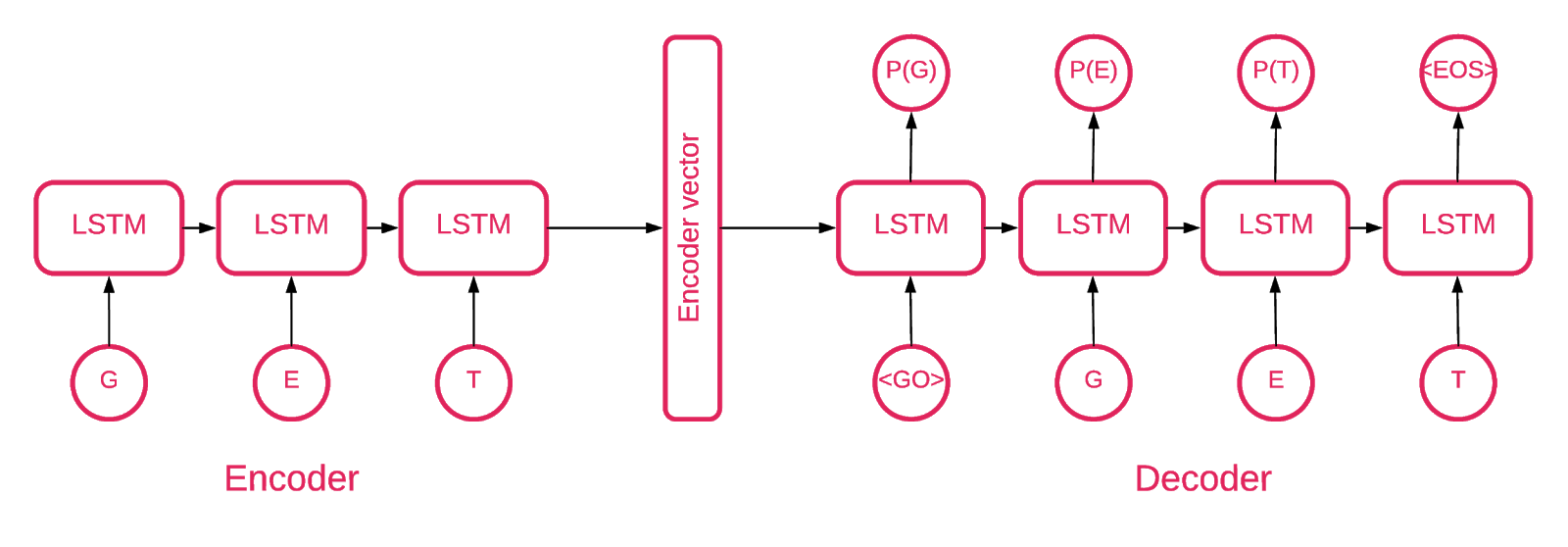
في مرحلة ما ، أصبح من الواضح أن جهاز التشفير التلقائي المتسلسل إلى التسلسل يناسب هدفنا بشكل أفضل.
يتكون نموذج التسلسل إلى التسلسل من نموذجين للذاكرة طويلة المدى متعدد الطبقات (LSTM): مشفر وفك تشفير. يعين المشفر تسلسل الإدخال إلى متجه ذي أبعاد ثابتة. تقوم وحدة فك الترميز بفك تشفير المتجه المستهدف باستخدام خرج المشفر.
لذا فإن وحدة التشفير التلقائي هي نموذج للتسلسل الذي يحدد قيمه المستهدفة مساوية لقيم الإدخال الخاصة به. والفكرة هي تعليم الشبكة لإعادة إنشاء الأشياء التي شاهدتها ، أو بعبارة أخرى ، تقريب وظيفة الهوية. إذا تم إعطاء وحدة التشفير التلقائي المدربة عينة شاذة ، فمن المحتمل أن تقوم بإعادة إنشائها بدرجة عالية من الخطأ بسبب عدم رؤية مثل هذه العينة من قبل.
الكود
يتكون حلنا من عدة أجزاء: تهيئة النموذج ، والتدريب ، والتنبؤ ، والتحقق من الصحة.
معظم الشفرة الموجودة في المستودع غير واضحة ، وسنركز على الأجزاء المهمة فقط.
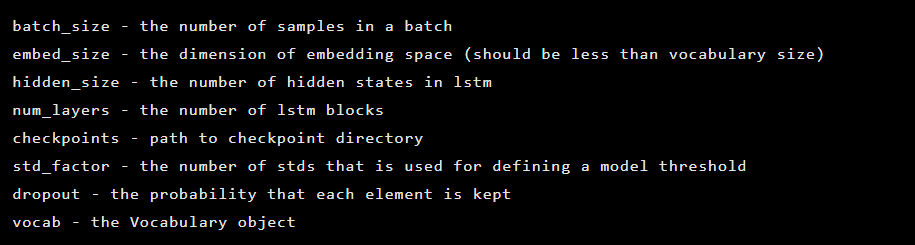
تتم تهيئة النموذج كمثيل لفئة Seq2Seq ، التي تحتوي على وسيطات المُنشئ التالية:
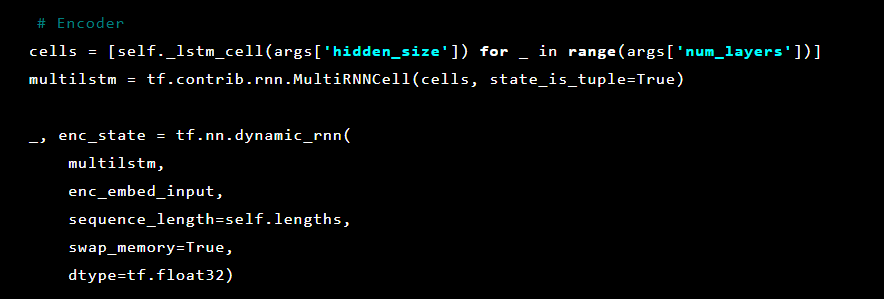
بعد ذلك ، تتم تهيئة طبقات وحدة التشفير التلقائي. أولاً ، التشفير:
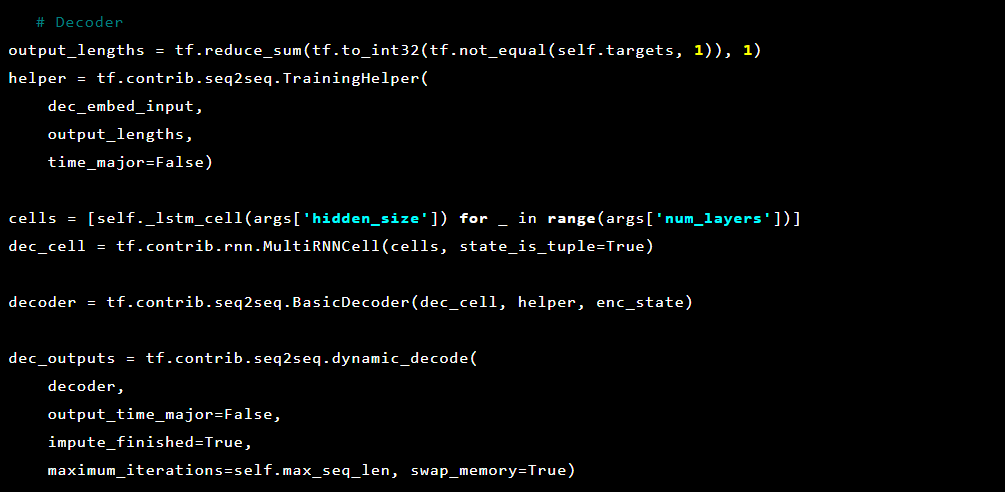
ثم فك التشفير:
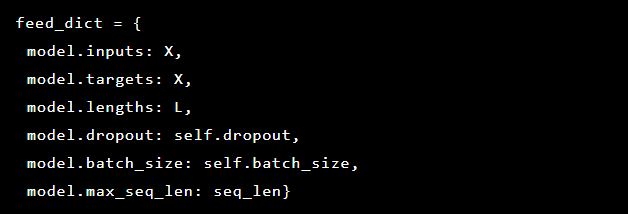
نظرًا لأننا نحاول حل اكتشاف الشذوذ ، فإن الأهداف والمدخلات هي نفسها. وهكذا يبدو لنا feed_dict كما يلي:
بعد كل فترة يتم حفظ أفضل نموذج كنقطة تفتيش ، والتي يمكن تحميلها في وقت لاحق للقيام بالتنبؤات. لأغراض الاختبار ، تم إعداد تطبيق ويب مباشر وحمايته بواسطة النموذج بحيث كان من الممكن اختبار ما إذا كانت الهجمات الحقيقية ناجحة أم لا.
نظرًا لاستلهامنا من آلية الانتباه ، حاولنا تطبيقه على وحدة التشفير التلقائي ولكن لاحظنا أن مخرجات الاحتمالات من الطبقة الأخيرة تعمل بشكل أفضل في تمييز الأجزاء الشاذة من الطلب.

في مرحلة الاختبار من خلال عيناتنا ، حصلنا على نتائج جيدة للغاية: كانت الدقة والتذكر قريبة من 0.99. وكان منحنى ROC حوالي 1. بالتأكيد مشهد جميل!
النتائج
أثبت نموذج وحدة التشفير التلقائي Seq2Seq الموصوفة لدينا أنه قادر على اكتشاف الحالات الشاذة في طلبات HTTP بدقة عالية.
يتصرف هذا النموذج كما يفعل الإنسان: إنه يتعلم فقط طلبات المستخدم "العادية" المرسلة إلى تطبيق ويب. يكتشف الشذوذ في الطلبات ويسلط الضوء على المكان المحدد في الطلب يعتبر الشاذة. قمنا بتقييم هذا النموذج ضد الهجمات على تطبيق الاختبار والنتائج تبدو واعدة. على سبيل المثال ، توضح لقطة الشاشة السابقة كيفية اكتشاف نموذج تقسيم الحقن SQL عبر معلمتين نموذج ويب. يتم حقن أجزاء SQL هذه ، حيث يتم تسليم حمولة الهجوم في العديد من معلمات HTTP. تعمل WAFs الكلاسيكية المستندة إلى القواعد بشكل سيئ في اكتشاف محاولات حقن SQL المجزأة لأنها تفحص عادة كل معلمة من تلقاء نفسها.
لقد تم إصدار رمز النموذج وبيانات القطار / الاختبار كدفتر Jupyter حتى يتمكن أي شخص من إعادة إنتاج نتائجنا واقتراح تحسينات.
الخاتمة
نعتقد أن مهمتنا كانت غير تافهة: التوصل إلى طريقة لاكتشاف الهجمات بأقل جهد ممكن. من ناحية ، سعينا إلى تجنب الإفراط في تعقيد الحل وخلق وسيلة لاكتشاف الهجمات التي ، كما لو كان السحر ، تتعلم أن تقرر بنفسها ما هو جيد وما هو سيء. في نفس الوقت ، أردنا تجنب المشكلات المتعلقة بالعامل البشري عندما يقرر خبير (غير معصوم) ما يشير إلى وقوع هجوم وما لا يحدث. وبشكل عام ، يبدو أن وحدة التشفير التلقائي ذات بنية Seq2Seq تحل مشكلتنا المتمثلة في اكتشاف الحالات الشاذة بشكل جيد.
أردنا أيضًا حل مشكلة تفسير البيانات. عند استخدام تصميمات الشبكات العصبية المعقدة ، من الصعب للغاية توضيح نتيجة معينة. عند تطبيق سلسلة كاملة من التحويلات ، يصبح تحديد أهم البيانات وراء القرار شبه مستحيل. ومع ذلك ، بعد إعادة التفكير في النهج المتبع في تفسير البيانات من خلال النموذج ، تمكنا من الحصول على احتمالات لكل حرف من الطبقة الأخيرة.
من المهم ملاحظة أن هذا النهج ليس نسخة جاهزة للإنتاج. لا يمكننا الكشف عن تفاصيل كيفية تطبيق هذا النهج في منتج حقيقي. لكننا سنحذرك من أنه من غير الممكن القيام بهذا العمل ببساطة و "توصيله". نجعل هذا التحذير لأنه بعد النشر على GitHub ، بدأنا نرى بعض المستخدمين الذين حاولوا ببساطة تنفيذ حلولنا الحالية بالجملة في مشاريعهم الخاصة ، مع نتائج غير ناجحة (وغير مفاجئة).
دليل المفهوم متاح
هنا (github.com).
المؤلفون: ألكسندرا مورزينا (
مورزينا )
وإرينا ستيبانيوك (
جيثب ) وفيدور ساخاروف (
جيثب )
وأرسيني روتوف (
Raz0r )
مزيد من القراءة
- فهم شبكات LSTM
- الاهتمام والشبكات العصبية المتكررة المعززة
- الاهتمام هو كل ما تحتاجه
- الاهتمام هو كل ما تحتاجه (مشروح)
- الترجمة الآلية العصبية (seq2seq)
- مشعلات السيارات
- التسلسل إلى التعلم التسلسلي مع الشبكات العصبية
- بناء مشفر السيارات في كراس