قرصنة الموسيقى لإضفاء الطابع الديمقراطي على المحتوى المشتقإخلاء المسئولية: يتم الكشف عن جميع حقوق الملكية الفكرية والتصاميم والأساليب الموضحة في هذه المقالة في US10014002B2 و US9842609B2.
أتمنى أن أعود إلى عام 1965 ، وأطرق الباب الأمامي لاستوديو Abby Road بتمريرة ، والذهاب إلى الداخل وسماع الأصوات الحقيقية للينون ومكارتني ... حسنًا ، دعنا نحاول. المدخلات: البيتلز متوسط الجودة MP3
يمكننا العمل بها . المسار العلوي هو مزيج المدخلات ، والمسار السفلي هو غناء معزولة أبرزت شبكتنا العصبية.
من الناحية الرسمية ، تُعرف هذه المشكلة
بفصل مصادر الصوت أو
فصل الإشارة (فصل مصدر الصوت). يتكون من استعادة أو إعادة بناء واحدة أو أكثر من الإشارات الأصلية ، والتي يتم خلطها مع إشارات أخرى نتيجة لعملية
خطية أو تلافيفية . يحتوي هذا المجال من الأبحاث على العديد من التطبيقات العملية ، بما في ذلك تحسين جودة الصوت (الكلام) والتخلص من الضوضاء ، وإعادة خلط الموسيقى ، والتوزيع المكاني للصوت ، وإعادة الصياغة ، إلخ. هناك الكثير من الموارد في هذا الموضوع ، من فصل الإشارة العمياء مع تحليل المكونات المستقلة (ICA) إلى المعالجة شبه الخاضعة للمصفوفات غير السلبية وتنتهي مع النهج اللاحقة القائمة على الشبكات العصبية. يمكنك العثور على معلومات جيدة عن النقطتين الأوليين في
هذه الأدلة المصغرة من CCRMA ، والتي كانت ذات مرة مفيدة جدًا لي.
ولكن قبل الغوص في التنمية ... قدرا كبيرا من فلسفة تعلم الآلة التطبيقية ...لقد انخرطت في معالجة الإشارات والصور حتى قبل أن ينتشر شعار "التعلم العميق يحل كل شيء" ، حتى أتمكن من تقديم حل لك باعتباره رحلة
هندسية مميزة وأظهر
لماذا تعتبر الشبكة العصبية هي أفضل نهج لهذه المشكلة بالذات . لماذا؟ في كثير من الأحيان ، أرى أن الناس يكتبون شيئًا مثل هذا:
"مع التعلم العميق ، لم يعد عليك القلق بشأن اختيار الميزات ؛ سوف تفعل ذلك من أجلك. "أو ما هو أسوأ ...
"الفرق بين التعلم الآلي والتعلم العميق [مهلا ... لا يزال التعلم العميق هو التعلم الآلي!] هل
أنت في ML أنت نفسك تستخلص السمات ، وهذا يحدث في التعلم العميق تلقائيًا داخل الشبكة."ربما تأتي هذه التعميمات من حقيقة أن DNNs يمكن أن تكون فعالة للغاية في استكشاف المساحات المخفية الجيدة. لكن من المستحيل التعميم. إنني منزعج للغاية عندما يستسلم الخريجين والممارسين الجدد للمفاهيم الخاطئة المذكورة أعلاه ويعتمدون منهج "التعلم العميق للجميع". مثل ، يكفي أن ترسم مجموعة من البيانات الخام (حتى بعد معالجة أولية قليلة) - وسيعمل كل شيء كما ينبغي. في العالم الواقعي ، يتعين عليك الاهتمام بأشياء مثل الأداء والتنفيذ في الوقت الفعلي ، وما إلى ذلك. وبسبب هذه المفاهيم الخاطئة ، ستظل عالقًا في وضع التجربة لفترة طويلة جدًا ...
لا تزال هندسة الميزات تخصصًا مهمًا للغاية في تصميم الشبكات العصبية الاصطناعية. كما هو الحال في أي تقنية أخرى لـ ML ، في معظم الحالات ، هو الذي يميز الحلول الفعالة لمستوى الإنتاج عن التجارب غير الناجحة أو غير الفعالة. إن الفهم العميق لبياناتك وطبيعتها لا يزال يعني الكثير ...من الألف إلى الياء
حسنا ، انتهيت من الخطبة. الآن دعونا نرى لماذا نحن هنا! كما هو الحال مع أي مشكلة في معالجة البيانات ، دعونا أولاً نرى ما يبدو. ألقِ نظرة على المقطع الصوتي التالي من تسجيل الاستوديو الأصلي.
استوديو غناء "واحد آخر مرة" ، أريانا غرانديليست مثيرة للاهتمام للغاية ، أليس كذلك؟ حسنًا ، هذا لأننا نتصور الإشارة
في الوقت المناسب . هنا نرى التغييرات السعة فقط مع مرور الوقت. لكن يمكنك استخراج كل أنواع الأشياء الأخرى ، مثل مغلفات الاتساع (المظروف) ، والقيم المربعة لمتوسط الجذر (RMS) ، ومعدل التغيير من القيم الموجبة للسعة إلى السالبة (معدل العبور الصفري) ، إلخ ، لكن هذه
العلامات بدائية للغاية وليست مميزة بشكل كافٍ ، للمساعدة في مشكلتنا. إذا أردنا استخراج غناء من إشارة صوتية ، نحتاج أولاً إلى تحديد بنية الكلام البشري بطريقة أو بأخرى. لحسن الحظ ، فإن نافذة
تحويل فورييه (STFT) يأتي لإنقاذ.
طيف سعة STFT - حجم النافذة = 2048 ، التداخل = 75٪ ، مقياس التردد اللوغاريتمي [Sonic Visualizer]على الرغم من أنني أحب معالجة الكلام وبالتأكيد أحب اللعب
بمحاكاة عوامل تصفية الإدخال و cepstrums و sototami و LPC و MFCC وما إلى ذلك
، إلا أننا سنتخطى كل هذا الهراء ونركز على العناصر الرئيسية ذات الصلة
بمشكلتنا بحيث يمكن فهم المقال من قبل أكبر عدد ممكن من الناس ، ليس فقط المتخصصين في معالجة الإشارات.
إذن ماذا يخبرنا هيكل الكلام البشري؟
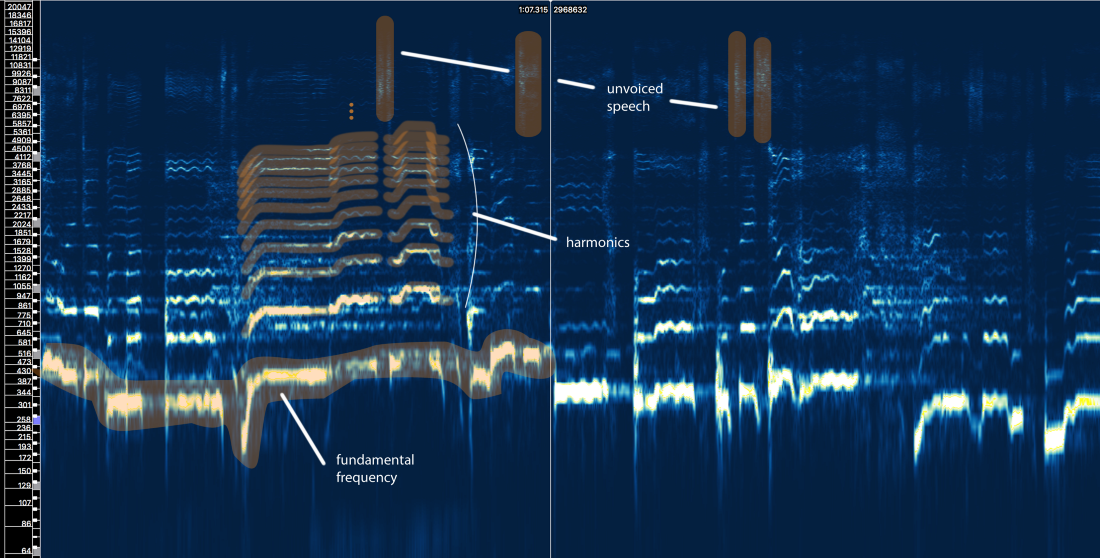
حسنًا ، يمكننا تحديد ثلاثة عناصر رئيسية هنا:
- التردد الأساسي (f0) ، والذي يتم تحديده بواسطة تردد اهتزاز الحبال الصوتية. في هذه الحالة ، تغني أريانا في حدود 300-500 هرتز.
- سلسلة من التوافقيات أعلى f0 تتبع شكلًا أو نموذجًا مشابهًا. تظهر هذه التوافقيات على ترددات مضاعفات f0.
- كلام غير صوتي ، يتضمن أحرف العلة مثل 't' و 'p' و 'k' و 's (والذي لا ينتج عن اهتزاز الحبال الصوتية) ، والتنفس ، إلخ. كل هذا يظهر في شكل رشقات قصيرة في المنطقة عالية التردد.
المحاولة الأولى مع القواعد
دعنا ننسى للمرة الثانية ما يسمى التعلم الآلي. هل يمكن تطوير طريقة استخراج صوتي بناءً على معرفتنا بالإشارة؟ دعني أحاول ...
السذاجة الصوتية العزلة V1.0:- تحديد المناطق مع غناء. هناك الكثير من الأشياء في الإشارة الأصلية. نريد التركيز على تلك المناطق التي تحتوي بالفعل على محتوى صوتي ، ونتجاهل كل شيء آخر.
- يميز بين الكلام الصريح والخطاب. كما رأينا ، فهي مختلفة جدا. ربما يحتاجون إلى التعامل معها بشكل مختلف.
- تقييم التغير في التردد الأساسي مع مرور الوقت.
- استنادًا إلى الدبوس 3 ، استخدم نوعًا من القناع لالتقاط التوافقيات.
- افعل شيئًا ما باستخدام أجزاء من الكلام غير المفاجئ ...

إذا عملنا بشكل جيد ، يجب أن تكون النتيجة قناعًا ناعمًا أو قناعًا للبتات ، حيث يعطي تطبيقه على سعة STFT (الضرب الأولي) إعادة بناء تقريبية لسعة غناء STFT. ثم نجمع هذا STFT الصوتي مع معلومات حول مرحلة الإشارة الأصلية ، وحساب STFT معكوس ، والحصول على إشارة الوقت من صوت إعادة بنائها.
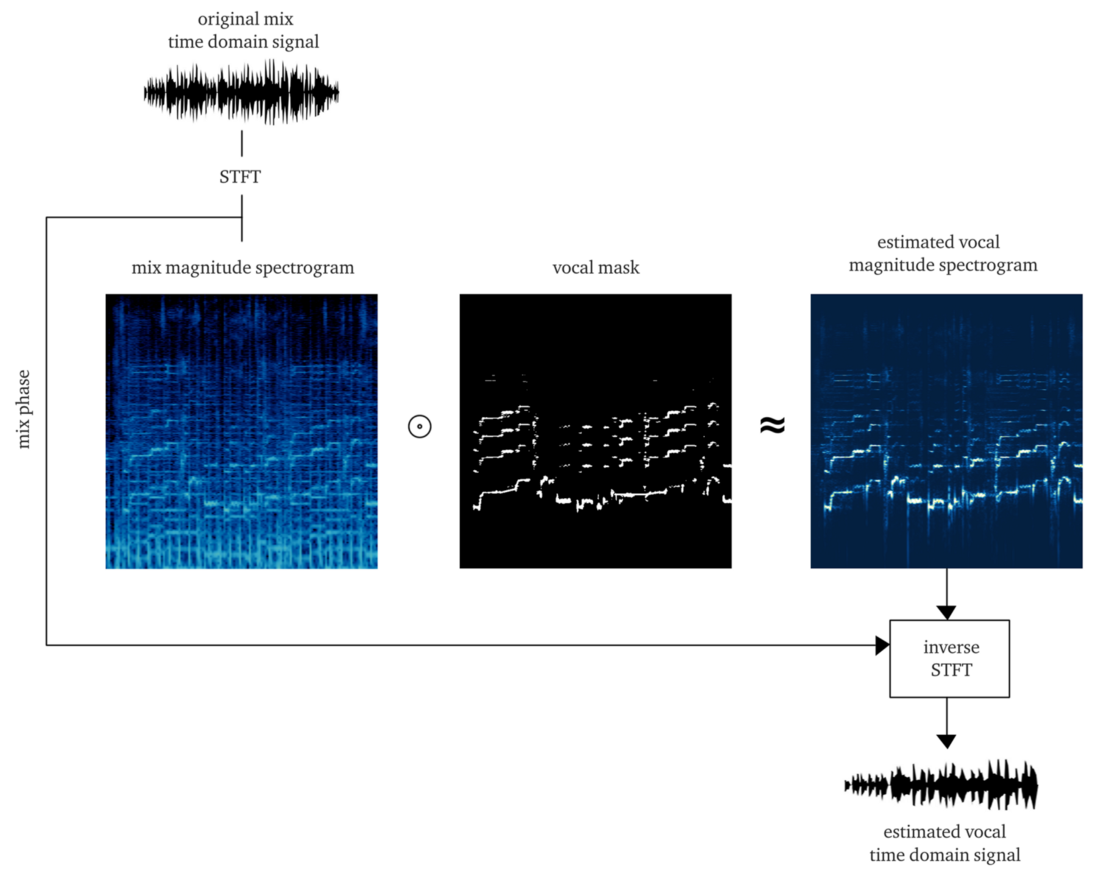
فعل ذلك من الصفر هو بالفعل وظيفة كبيرة. ولكن من أجل التوضيح ، فإن تطبيق
خوارزمية pYIN قابل للتطبيق . على الرغم من أنه يهدف إلى حل الخطوة 3 ، ولكن بالإعدادات الصحيحة ، فإنه ينفذ الخطوتين 1 و 2 بشكل لائق ، ويتتبع الأساس الصوتي حتى في وجود الموسيقى. المثال أدناه يحتوي على الإخراج بعد معالجة هذه الخوارزمية ، دون معالجة خطاب unvoiced.
وماذا ...؟ يبدو أنه قام بكل العمل ، لكن لا توجد نوعية جيدة وقريبة. ربما من خلال إنفاق المزيد من الوقت والطاقة والمال ، سنحسن هذه الطريقة ...
لكن دعني أسألك ...
ماذا يحدث إذا ظهر
عدد قليل من الأصوات على المسار ، ولكن غالبًا ما توجد في 50٪ على الأقل من المقاطع الاحترافية الحديثة؟
ماذا يحدث إذا تمت معالجة غناء بواسطة
تردد ، والتأخير وغيرها من الآثار؟ دعنا نلقي نظرة على آخر جوقة لأريانا غراندي من هذه الأغنية.
هل تشعر بالفعل بألم ...؟ أنا كذلك.
مثل هذه الأساليب على قواعد صارمة تتحول بسرعة كبيرة إلى مجموعة من البطاقات. المشكلة معقدة للغاية. الكثير من القواعد ، والاستثناءات كثيرة للغاية ، والعديد من الشروط المختلفة (الآثار وإعدادات المزج). يتضمن النهج متعدد الخطوات أيضًا أن الأخطاء في خطوة واحدة تمتد المشكلات إلى الخطوة التالية. سيصبح تحسين كل خطوة مكلفًا للغاية: سوف يستغرق الأمر عددًا كبيرًا من التكرارات لتصحيحها. وأخيراً وليس آخراً ، من المحتمل أن نحصل في النهاية على ناقل كثيف الاستخدام للموارد ، والذي في حد ذاته يمكن أن ينفي كل الجهود.
في مثل هذه الحالة ، حان الوقت للبدء في التفكير في نهج أكثر شمولية والسماح لـ ML باكتشاف جزء من العمليات والعمليات الأساسية اللازمة لحل المشكلة. ولكن لا يزال يتعين علينا إظهار مهاراتنا والمشاركة في هندسة الميزات ، وسوف ترى السبب.الفرضية: استخدم الشبكة العصبية كدالة نقل تترجم الخلطات إلى غناء
بالنظر إلى إنجازات الشبكات العصبية التلافيفية في معالجة الصور ، لماذا لا يتم تطبيق نفس النهج هنا؟
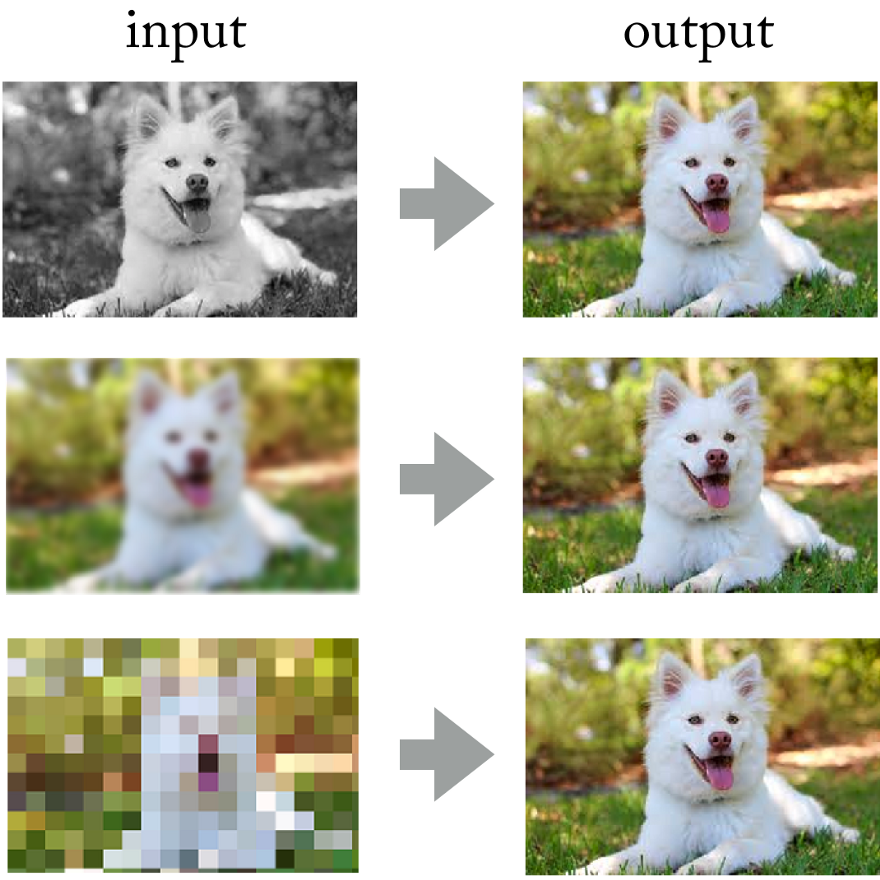 الشبكات العصبية تحل بنجاح مشاكل مثل تلوين الصور ، الوضوح والدقة.
الشبكات العصبية تحل بنجاح مشاكل مثل تلوين الصور ، الوضوح والدقة.في النهاية ، يمكنك تخيل الإشارة الصوتية "كصورة" باستخدام تحويل فورييه قصير الأجل ، أليس كذلك؟ على الرغم من أن هذه
الصور الصوتية لا تتوافق مع التوزيع الإحصائي للصور الطبيعية ، إلا أنها لا تزال تحتوي على أنماط مكانية (في الوقت والتردد في الفضاء) لتدريب الشبكة عليها.
 يسار: إيقاع الأسطوانة والخط القاعدي أدناه ، أصوات الأصوات المتعددة في الوسط ، جميعها مختلطة مع غناء. الحق: فقط غناء
يسار: إيقاع الأسطوانة والخط القاعدي أدناه ، أصوات الأصوات المتعددة في الوسط ، جميعها مختلطة مع غناء. الحق: فقط غناءسيكون إجراء مثل هذه التجربة عملية مكلفة نظرًا لأنه يصعب الحصول على أو إنشاء بيانات التدريب اللازمة. لكن في البحوث التطبيقية ، أحاول دائمًا استخدام هذا النهج: أولاً ،
لتحديد مشكلة أبسط تؤكد نفس المبادئ ، ولكنها لا تتطلب الكثير من العمل. يسمح لك ذلك بتقييم الفرضية وتكرار النموذج وتصحيحه بشكل أسرع بأقل خسائر إذا لم ينجح كما ينبغي.
الشرط الضمني هو أن
الشبكة العصبية يجب أن تفهم بنية خطاب الإنسان . قد تكون هذه مشكلة أبسط:
يمكن للشبكة العصبية تحديد وجود الكلام على جزء تعسفي من التسجيل الصوتي . نحن نتحدث عن
كاشف نشاط صوت موثوق
(VAD) ، يتم تنفيذه في شكل مصنف ثنائي.
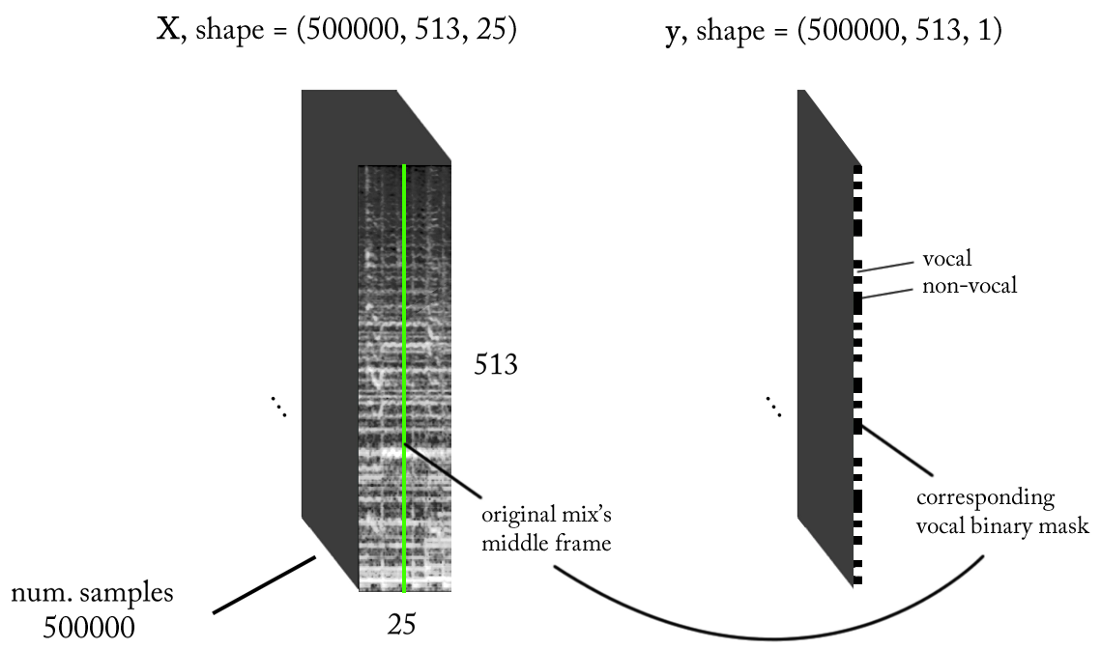
نحن تصميم مساحة علامات
نحن نعلم أن الإشارات الصوتية ، مثل الموسيقى والكلام البشري ، تعتمد على التبعيات الزمنية. ببساطة ، لا يحدث شيء في عزلة في وقت معين. إذا أردت أن أعرف ما إذا كان هناك صوت على قطعة معينة من التسجيل الصوتي ، فأنا بحاجة إلى النظر إلى المناطق المجاورة. يوفر هذا
السياق الزمني معلومات جيدة حول ما يحدث في مجال الاهتمام. في الوقت نفسه ، من المستحسن إجراء تصنيف بزيادات زمنية صغيرة جدًا من أجل التعرف على الصوت البشري بأعلى دقة زمنية ممكنة.

دعونا نعول قليلا ...
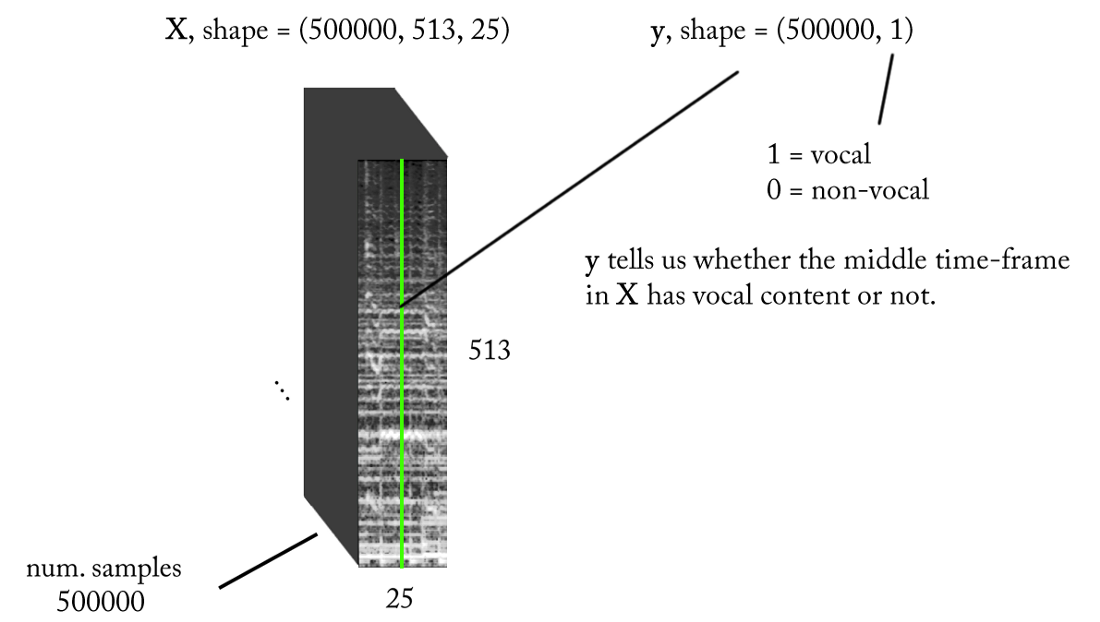
- تردد أخذ العينات (fs): 22050 هرتز (نقوم بتخفيض العينة من 44100 إلى 22050)
- تصميم STFT: حجم النافذة = 1024 ، حجم القفزة = 256 ، طباشير خط الطباشير لمرشح الترجيح ، مع مراعاة التصور. نظرًا لأن مدخلاتنا حقيقية ، يمكنك العمل مع نصف STFT (هناك تفسير خارج نطاق هذه المقالة ...) مع الحفاظ على مكون DC (اختياري) ، والذي يعطينا 513 صندوق تردد.
- دقة التصنيف المستهدفة: إطار STFT واحد (حوالي 11.6 مللي ثانية = 256/22050)
- السياق الزمني المستهدف: ~ 300 مللي ثانية = 25 إطارًا من إطارات STFT.
- العدد المستهدف من أمثلة التدريب: 500 ألف.
- على افتراض أننا نستخدم نافذة انزلاقية مع خطوة من 1 إطار زمني STFT لإنشاء بيانات التدريب ، نحتاج إلى حوالي 1.6 ساعة من الصوت المسمى لتوليد 500 ألف عينة بيانات
مع المتطلبات المذكورة أعلاه ، فإن مدخلات ومخرجات المصنف الثنائي لدينا هي كما يلي:
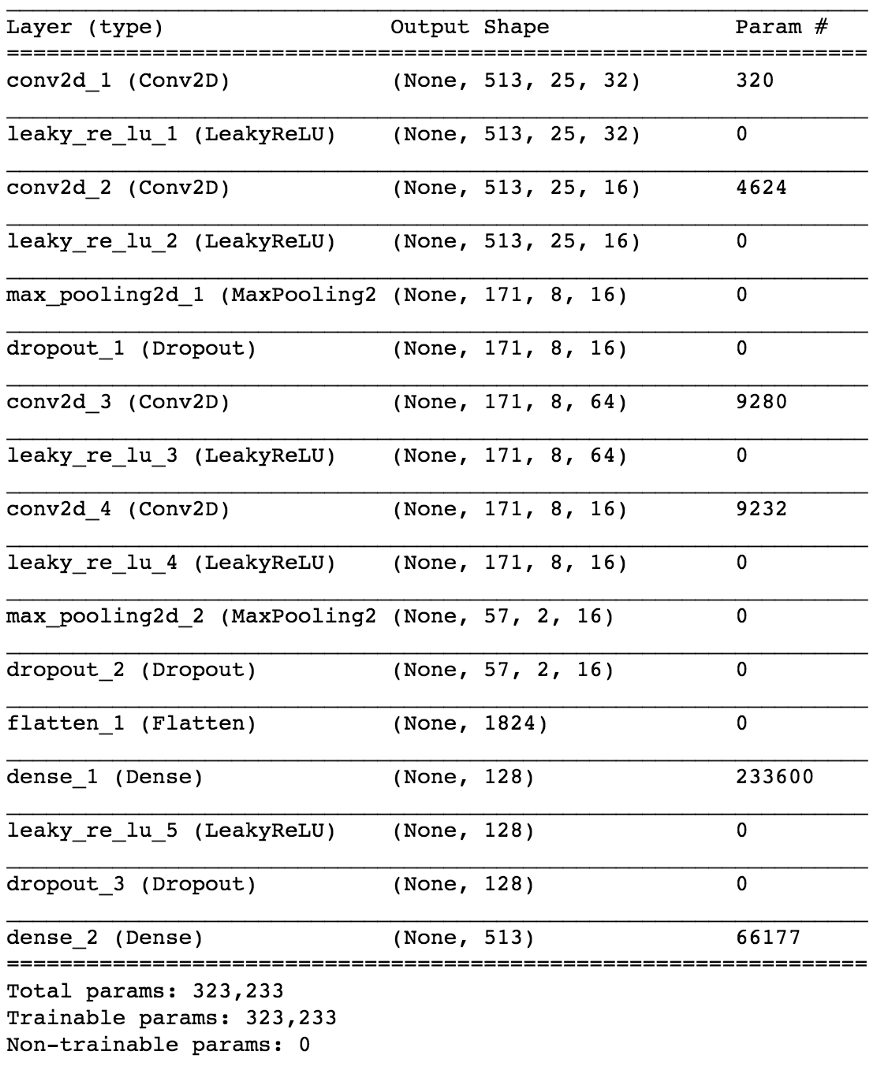
نموذج
باستخدام Keras ، سنقوم ببناء نموذج صغير لشبكة عصبية لاختبار فرضيتنا.
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
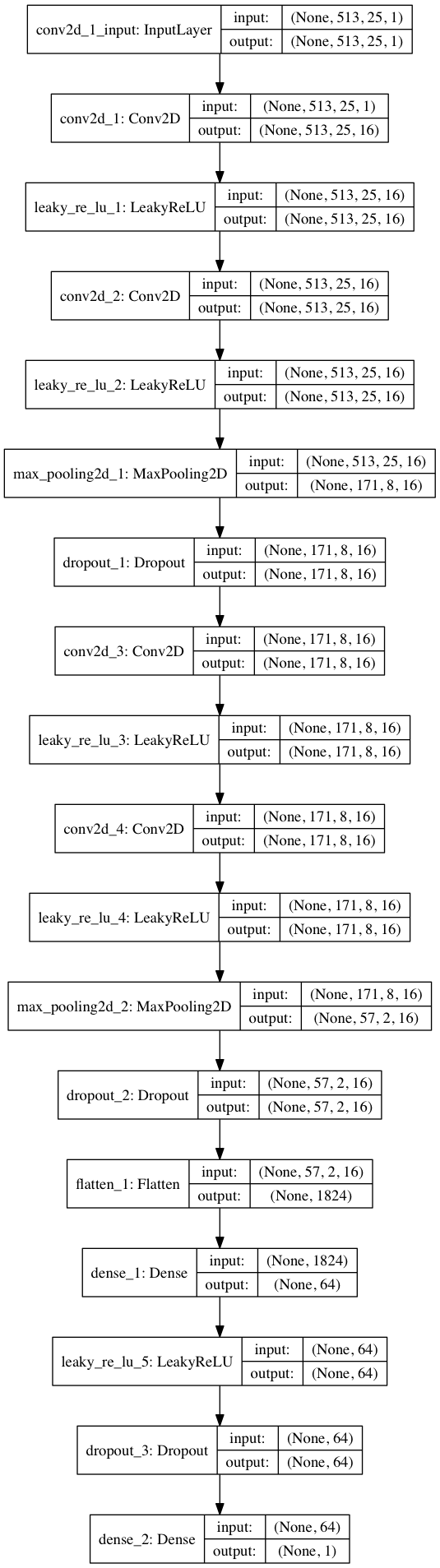
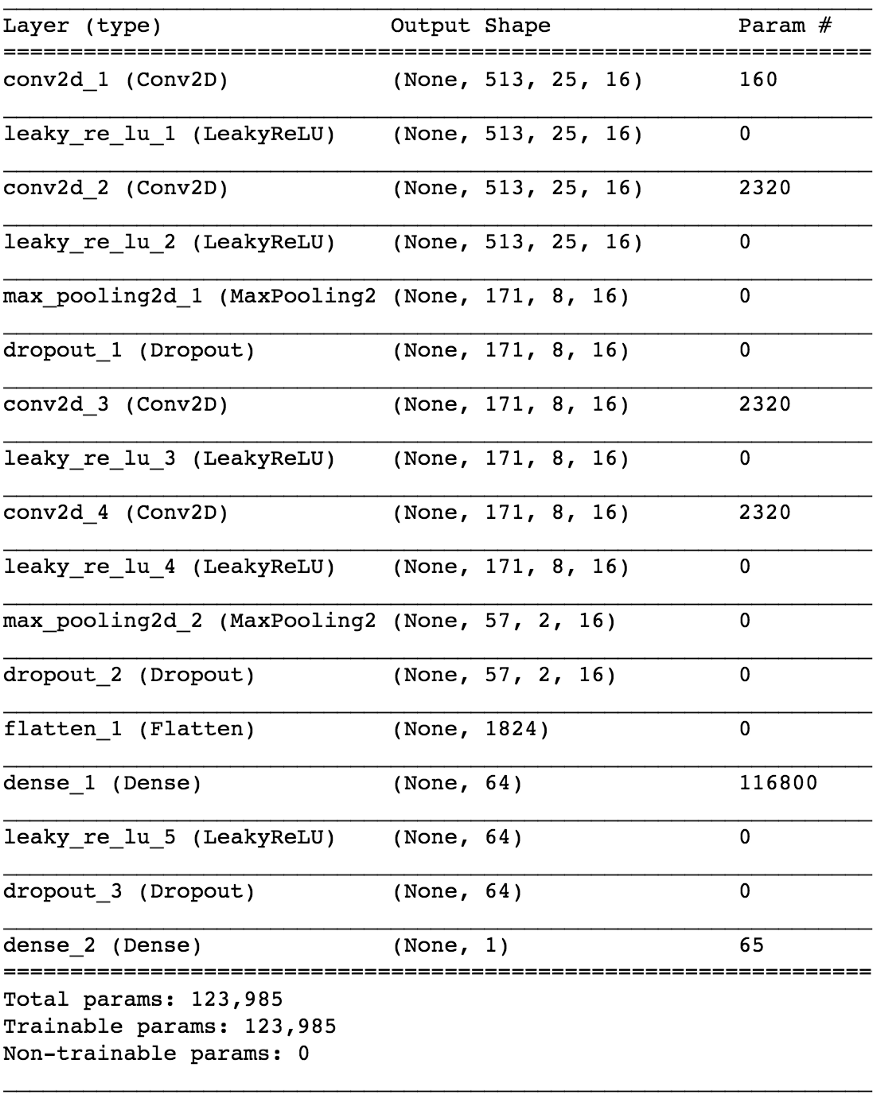
بتقسيم 80/20 من البيانات إلى التدريب والاختبار بعد حوالي 50 عصرًا ، نحصل على
الدقة عند اختبار ~ 97٪ . هذا دليل كاف على أن نموذجنا قادر على التمييز بين الغناء في أجزاء الصوت الموسيقية (والشظايا بدون غناء). إذا تحققنا من بعض خرائط الميزات من الطبقة التلافيفية الرابعة ، فيمكننا أن نستنتج أن الشبكة العصبية يبدو أنها قامت بتحسين حباتها لأداء مهمتين: تصفية الموسيقى وغناء الترشيح ...
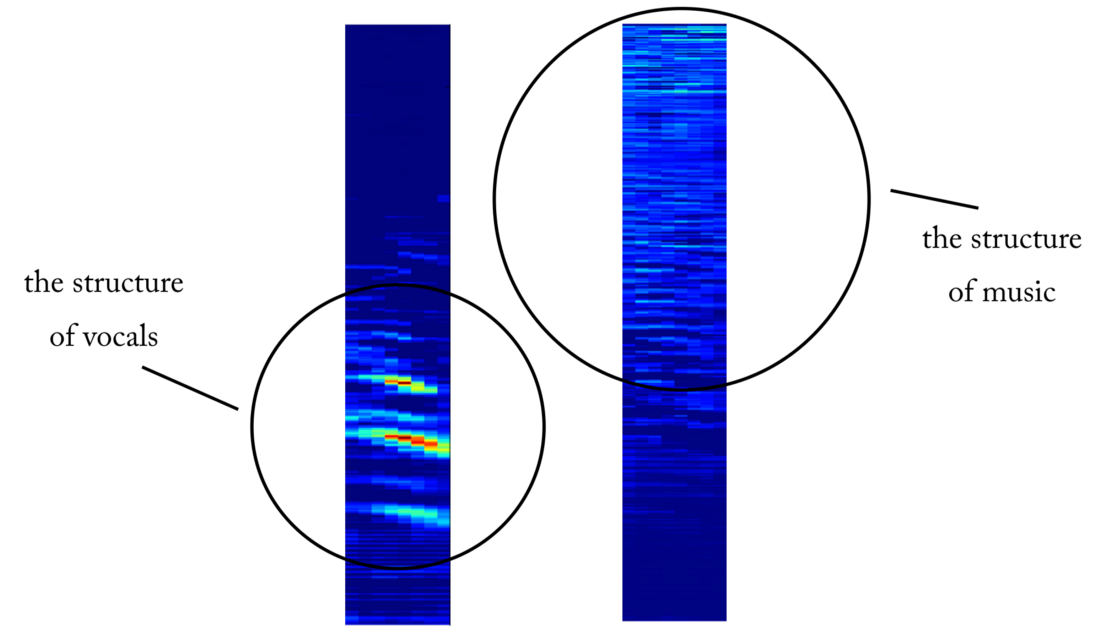 مثال على خريطة للكائنات عند خروج الطبقة التلافيفية الرابعة. يبدو أن الإخراج على اليسار هو نتيجة عمليات kernel في محاولة للحفاظ على المحتوى الصوتي أثناء تجاهل الموسيقى. القيم العالية تشبه التركيب المتناغم للكلام البشري. خريطة الكائن على اليمين ويبدو أن نتيجة عكس ذلك
مثال على خريطة للكائنات عند خروج الطبقة التلافيفية الرابعة. يبدو أن الإخراج على اليسار هو نتيجة عمليات kernel في محاولة للحفاظ على المحتوى الصوتي أثناء تجاهل الموسيقى. القيم العالية تشبه التركيب المتناغم للكلام البشري. خريطة الكائن على اليمين ويبدو أن نتيجة عكس ذلكمن كاشف الصوت إلى إشارة قطع الاتصال
بعد حل مشكلة التصنيف البسيطة ، كيف يمكننا الانتقال إلى الفصل الحقيقي للغناء عن الموسيقى؟ حسنًا ، بالنظر إلى الطريقة الأولى
الساذجة ، ما زلنا نريد الحصول على مطياف السعة للغناء بطريقة أو بأخرى. الآن أصبحت هذه مهمة الانحدار. ما نريد القيام به هو حساب طيف الاتساع المقابل للغناء في هذا الإطار الزمني من STFT للإشارة الأصلية ، أي من المزيج (مع سياق زمني كاف).
ماذا عن مجموعة بيانات التدريب؟ (يمكنك أن تسألني في هذه اللحظة)اللعنة ... لماذا كذلك. كنت سأفكر في هذا الأمر في نهاية المقال حتى لا أتعرض للانتباه عن الموضوع!
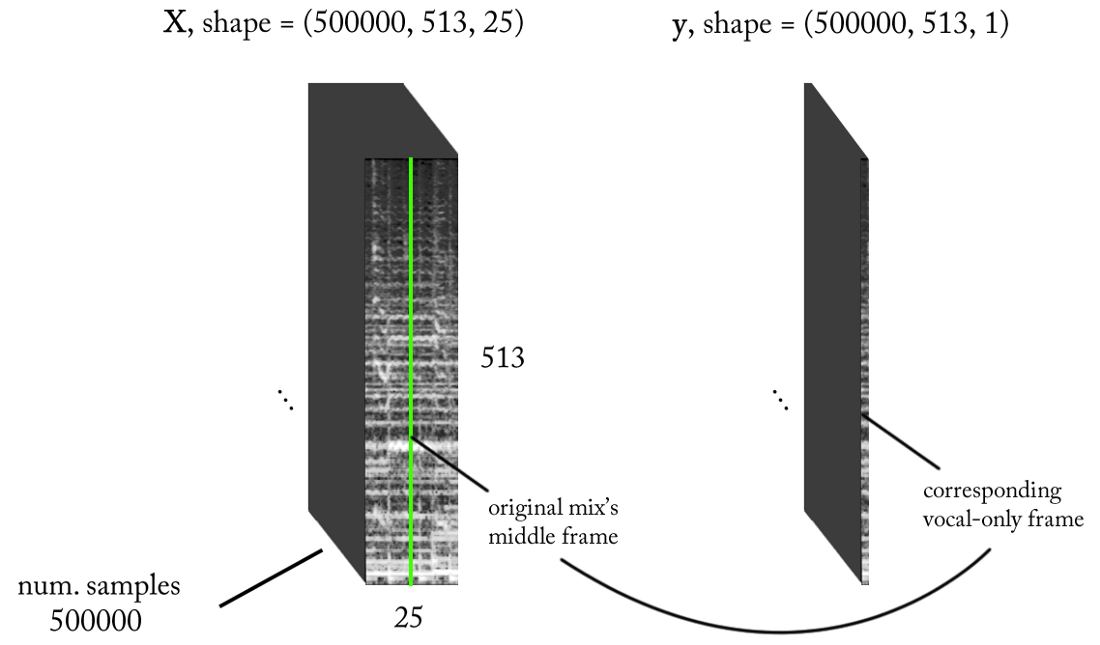
إذا كان نموذجنا مدربين تدريباً جيداً ، فلكي تحصل على نتيجة منطقية ، ستحتاج فقط إلى تنفيذ نافذة انزلاقية بسيطة إلى مزيج STFT. بعد كل توقع ، انقل النافذة إلى اليمين بمقدار إطار زمني واحد ، وتوقع الإطار التالي مع غناء وربطه بالتنبؤ السابق. أما بالنسبة للنموذج ، فلنأخذ نفس النموذج الذي تم استخدامه للكشف عن الصوت وإجراء تغييرات بسيطة: أصبح الشكل الموجي للإخراج الآن (513.1) ، التنشيط الخطي في الإخراج ، MSE كدالة للخسائر. الآن نبدأ التدريب.
لا تفرح بعد ...على الرغم من أن تمثيل I / O هذا منطقي ، إلا أنه بعد تدريب نموذجنا عدة مرات ، مع العديد من المعلمات وتطبيع البيانات ، لا توجد نتائج. يبدو أننا نطلب الكثير ...
لقد انتقلنا من مصنف ثنائي إلى
الانحدار على ناقل 513 الأبعاد. على الرغم من أن الشبكة تدرس المشكلة إلى حد ما ، فإن الأغنيات المستعادة لا تزال تحتوي على قطع أثرية واضحة وتداخل من مصادر أخرى. حتى بعد إضافة طبقات إضافية وزيادة عدد معلمات النموذج ، فإن النتائج لا تتغير كثيرًا. ثم يطرح السؤال:
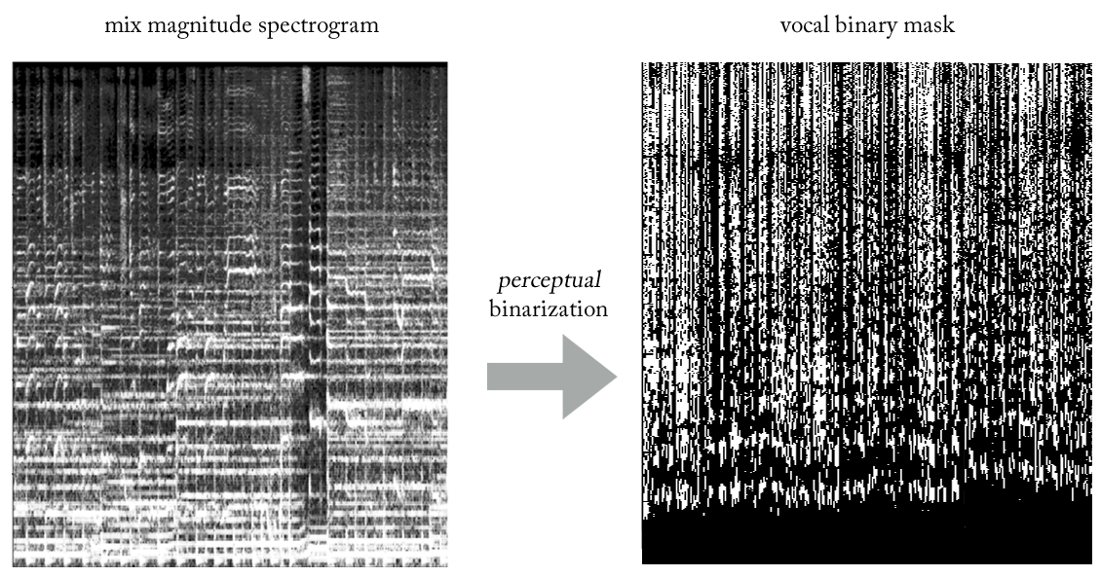
كيفية "تبسيط" مهمة الشبكة عن طريق الخداع ، وفي الوقت نفسه تحقيق النتائج المرجوة؟ماذا لو بدلًا من تقدير سعة غناء STFT ، قمنا بتدريب الشبكة للحصول على قناع ثنائي ، والذي عند تطبيقه على مزيج STFT يعطينا مخططًا طيفيًا مبسّطًا
ومقبولًا للإدراك؟
بتجربة الاستدلالات المختلفة ، توصلنا إلى طريقة بسيطة للغاية (وبالطبع غير تقليدية فيما يتعلق بمعالجة الإشارات ...) لاستخراج غناء من خلطات باستخدام أقنعة ثنائية. دون الخوض في التفاصيل ، جوهر هو على النحو التالي. تخيل الإخراج كصورة ثنائية ، حيث تشير القيمة "1" إلى
التواجد السائد للمحتوى الصوتي في تردد وإطار زمني معين ، والقيمة "0" تشير إلى التواجد السائد للموسيقى في مكان معين. يمكننا أن نسميها
ثنائيات التصور ، فقط للتوصل إلى اسم. بصريا ، يبدو الأمر قبيحًا للغاية ، أن أكون أمينًا ، لكن النتائج جيدة بشكل مدهش.
الآن أصبحت مشكلتنا نوعًا من تصنيف الانحدار الهجين (تقريبًا ...). نطلب من النموذج "تصنيف وحدات البكسل" في المخرجات على أنها صوتية أو غير صوتية ، على الرغم من أنه من الناحية النظرية (وكذلك من وجهة نظر وظيفة فقد MSE المستخدمة) ، تظل المهمة متراجعة.
على الرغم من أن هذا التمييز قد يبدو غير مناسب للبعض ، إلا أنه في الواقع له أهمية كبيرة في قدرة النموذج على دراسة المهمة ، والثاني أكثر بساطة وأكثر محدودية. في الوقت نفسه ، يتيح لنا ذلك الحفاظ على نموذجنا صغيرًا نسبيًا من حيث عدد المعلمات ، نظرًا لتعقيد المهمة ، وهو أمر مرغوب فيه جدًا للعمل في الوقت الفعلي ، والذي كان في هذه الحالة متطلبًا للتصميم. بعد بعض التعديلات الطفيفة ، يشبه النموذج النهائي هذا.
كيفية استرداد إشارة المجال الزمني؟
في الواقع ، كما هو الحال في
الطريقة الساذجة . في هذه الحالة ، لكل تمريرة ، نتوقع إطارًا زمنيًا واحدًا لقناع الغناء الثنائي. مرة أخرى ، مع تحقيق نافذة انزلاقية بسيطة مع خطوة من إطار زمني واحد ، نواصل تقييم الأطر الزمنية المتعاقبة ودمجها ، والتي تشكل في نهاية المطاف القناع الثنائي الصوتي بأكمله.

إنشاء مجموعة التدريب
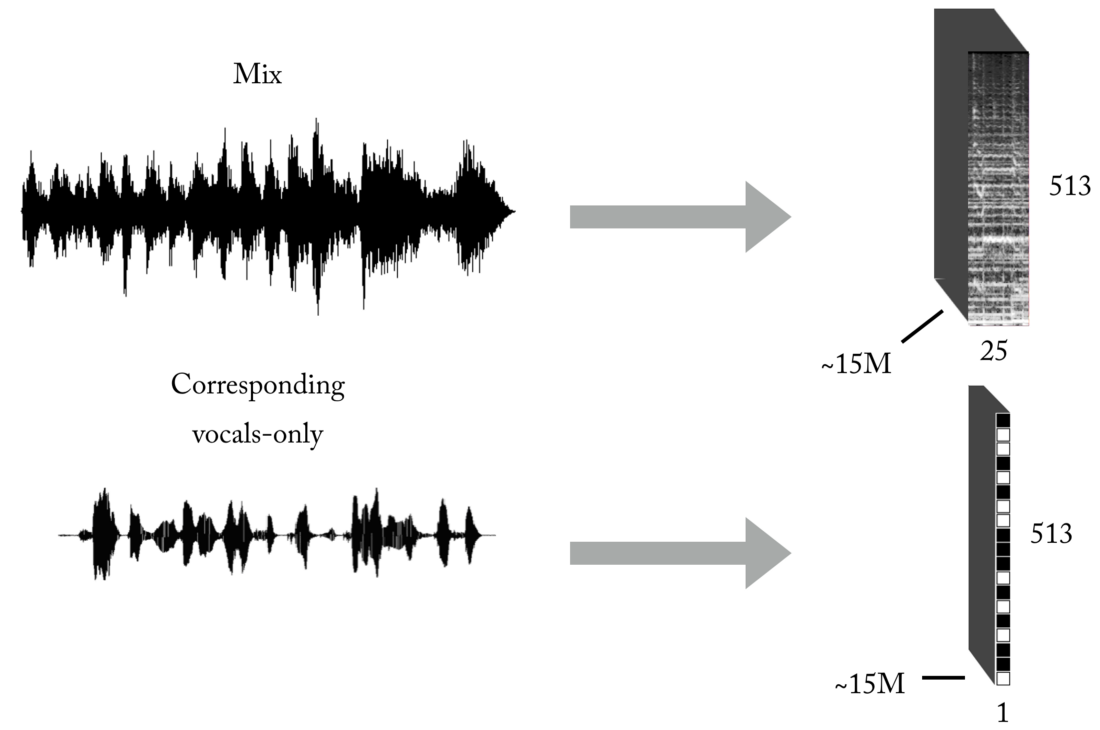
كما تعلمون ، فإن إحدى المشكلات الرئيسية عند التدريس مع مدرس (اترك أمثلة الألعاب هذه مع مجموعات بيانات جاهزة) هي البيانات الصحيحة (من حيث الكم والجودة) للمشكلة المحددة التي تحاول حلها. استنادًا إلى تمثيلات المدخلات والمخرجات الموضحة ، لتدريب نموذجنا ، ستحتاج أولاً إلى عدد كبير من المزيج والمسارات الصوتية المطابقة والمحاذاة والمطابقة تمامًا. يمكن إنشاء هذه المجموعة بعدة طرق ، واستخدمنا مجموعة من الاستراتيجيات ، بدءًا من إنشاء أزواج يدويًا [مزيج <-> غناء] استنادًا إلى العديد من الكبلات الموجودة على الإنترنت ، إلى البحث عن المواد الموسيقية لموسيقى الروك و Youtube scrapbooking. فقط لإعطائك فكرة عن مدى هذه العملية الشاقة والمؤلمة ، كان جزء من المشروع هو تطوير مثل هذه الأداة لإنشاء أزواج تلقائيًا [mix <-> غناء]:

هناك حاجة إلى كمية كبيرة من البيانات للشبكة العصبية لتتعلم وظيفة النقل لبث الإختلاط إلى غناء. تتكون مجموعتنا النهائية من حوالي 15 مليون عينة من مزيج 300 مللي والأقنعة الصوتية الصوتية المقابلة لها.
هندسة خطوط الأنابيب
كما تعلمون ، فإن إنشاء نموذج ML لمهمة محددة هو نصف المعركة فقط. في العالم الواقعي ، تحتاج إلى التفكير في بنية البرنامج ، خاصةً إذا كنت بحاجة إلى عمل في الوقت الفعلي أو بالقرب منه.
في هذا التطبيق بالذات ، يمكن أن تحدث إعادة البناء في المجال الزمني فور توقع قناع الغناء الثنائي الكامل (الوضع المستقل) أو ، بشكل أكثر إثارة للاهتمام ، في الوضع متعدد مؤشرات الترابط ، حيث نتلقى البيانات ونعالجها ، ونستعيد غناءنا ونعيد إنتاج الصوت - كل ذلك في مقاطع صغيرة ، على مقربة من يتدفقون وحتى في الوقت الفعلي تقريبًا ، قم بمعالجة الموسيقى التي يتم تسجيلها أثناء الطيران بأقل تأخير في الواقع ، هذا موضوع منفصل ، وسأتركه لمقال آخر
حول خطوط أنابيب ML في الوقت الفعلي ...
أعتقد أنني قلت ما يكفي ، فلماذا لا تستمع إلى بضعة أمثلة!؟
سخيف الشرير - الحصول على الحظ (تسجيل استوديو)
هنا يمكنك سماع بعض التداخل البسيط من الطبول ...أديل - أشعل النار في المطر (تسجيل حي!)
لاحظ كيف يستخلص نموذجنا في البداية صرخات الحشد كمحتوى صوتي :). في هذه الحالة ، هناك بعض التدخل من مصادر أخرى. نظرًا لأن هذا تسجيل مباشر ، فيبدو من المقبول أن تكون الأغنيات المستخرجة أقل جودة من سابقاتها.نعم ، و "شيء آخر" ...
إذا كان النظام يعمل للغناء ، فلماذا لا يتم تطبيقه على الصكوك الأخرى ...؟
المقالة كبيرة جدًا بالفعل ، ولكن بالنظر إلى العمل المنجز ، فأنت تستحق سماع أحدث إصدار تجريبي. باستخدام نفس المنطق تمامًا عند استخراج الغناء ، يمكننا محاولة تقسيم موسيقى الاستريو إلى مكونات (الطبول ، والباس ، والغناء ، وغيرها) ، وإجراء بعض التغييرات في نموذجنا ، وبالطبع الحصول على مجموعة التدريب المناسبة :).
شكرا للقراءة. كملاحظة أخيرة: كما ترون ، فإن النموذج الفعلي لشبكتنا العصبية التلافيفية ليس مميزًا للغاية. تم تحديد نجاح هذا العمل من خلال شركة
Feature Engineering وعملية اختبار الفرضية الأنيقة ، والتي سأكتب عنها في المقالات المستقبلية!