"في وضع التتبع ، يرى المبرمج تسلسل تنفيذ الأوامر وقيم المتغيرات في هذه الخطوة من تنفيذ البرنامج ، مما يجعل من السهل اكتشاف الأخطاء" ، كما يخبرنا ويكيبيديا. نظرًا لأن نظام Linux يشجعنا على أنفسنا ، فنحن نتفحص بانتظام مسألة الأدوات المحددة الأفضل لتنفيذها. ونريد أن نشارك في ترجمة مقال للمبرمج هونجلي لاي الذي يوصي بـ bpftrace. بالنظر إلى المستقبل ، أقول إن المقالة تنتهي بإيجاز: "bpftrace هو المستقبل". فلماذا أثار إعجاب زميل لاي؟ إجابة مفصلة تحت الخفض.
هناك نوعان من أدوات التتبع الرئيسية على Linux:
يتيح لك
strace معرفة مكالمات النظام التي يتم إجراؤها ؛
يتيح لك
ltrace معرفة المكتبات الديناميكية التي يتم استدعاؤها.
على الرغم من فائدتها ، إلا أن هذه الأدوات محدودة. وإذا كنت بحاجة لمعرفة ما يحدث داخل نظام أو مكالمة مكتبة؟ وإذا كنت لا تحتاج فقط إلى تجميع قائمة المكالمات ، ولكن أيضًا ، على سبيل المثال ، جمع إحصائيات حول سلوك معين؟ وإذا كنت بحاجة إلى تتبع العديد من العمليات ومقارنة البيانات من عدة مصادر؟
في عام 2019 ، حصلنا في النهاية على إجابة مناسبة لهذه الأسئلة على نظام Linux:
bpftrace على أساس تقنية
eBPF . يسمح لك Bpftrace بكتابة البرامج الصغيرة التي تعمل في كل مرة يحدث فيها حدث.
في هذه المقالة سوف أصف كيفية تثبيت bpftrace وتعليم تطبيقه الأساسي. سأقدم أيضًا نظرة عامة على ما يبدو عليه النظام البيئي للتتبع (على سبيل المثال ، "ما هو eBPF؟") وكيف تطورت إلى ما لدينا اليوم.
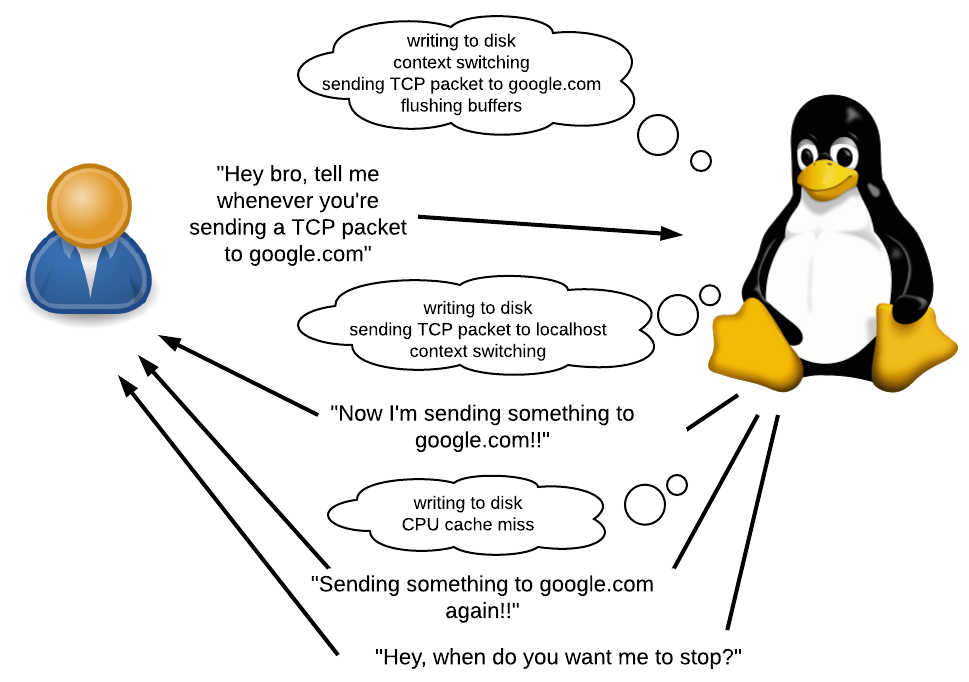
ما هو الأثر؟
كما ذكرنا سابقًا ، يسمح لك bpftrace بكتابة برامج صغيرة يتم تشغيلها في كل مرة يحدث فيها حدث.
ما هو الحدث؟ قد تكون مكالمة نظام أو مكالمة وظيفية أو حتى شيء يحدث داخل مثل هذه الطلبات. يمكن أن يكون أيضًا مؤقتًا أو حدثًا للجهاز ، على سبيل المثال ، "مرت 50 مللي ثانية منذ آخر الأحداث نفسها" أو "حدث فشل في الصفحة" أو "حدث تبديل للسياق" أو "حدث cashe-miss".
ما الذي يمكن القيام به استجابة لحدث ما؟ يمكنك التعهد بشيء ما ، وجمع الإحصاءات وتنفيذ أوامر shell التعسفية. سيكون لديك الوصول إلى مختلف المعلومات السياقية ، مثل PID الحالي ، تتبع المكدس ، الوقت ، وسائط الاتصال ، قيم الإرجاع ، إلخ.
متى تستخدم؟ في كثير. يمكنك معرفة سبب بطء التطبيق من خلال تجميع قائمة من أبطأ المكالمات. يمكنك تحديد ما إذا كان هناك تسرب للذاكرة في التطبيق ، وإذا كان الأمر كذلك ، فأين. أنا استخدامها لفهم لماذا يستخدم روبي الكثير من الذاكرة.
الإضافة الكبيرة من bpftrace هي أنك لست بحاجة إلى إعادة ترجمة التطبيق. ليست هناك حاجة لكتابة مكالمات الطباعة يدويًا أو أي كود تصحيح أخطاء آخر في التعليمات البرمجية المصدر للتطبيق قيد الدراسة. ليست هناك حاجة حتى لإعادة تشغيل التطبيقات. وكل هذا مع انخفاض النفقات العامة للغاية. هذا يجعل bpftrace مفيدًا بشكل خاص لأنظمة تصحيح الأخطاء مباشرة على prod أو في موقف آخر حيث توجد صعوبات في إعادة التحويل.
DTrace: والد التتبع
لفترة طويلة ، كانت أفضل أداة تتبع هي
DTrace ، وهو إطار تتبع ديناميكي كامل تم تطويره في الأصل بواسطة Sun Microsystems (صناع Java). مثل bpftrace ، يسمح لك DTrace بكتابة برامج صغيرة يتم تشغيلها استجابة للأحداث. في الواقع ، تم تطوير العديد من العناصر الرئيسية للنظام الإيكولوجي إلى حد كبير بواسطة
Brendan Gregg ، وهو خبير مشهور في DTrace يعمل حاليًا في Netflix. وهو ما يفسر أوجه التشابه بين DTrace و bpftrace.
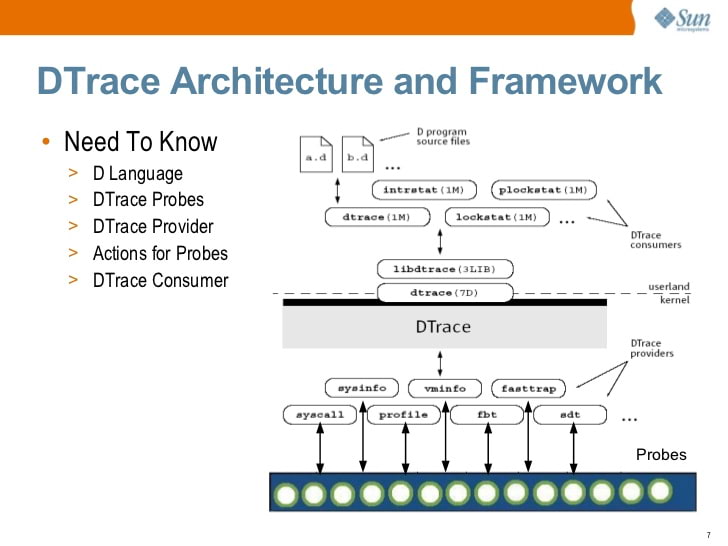 مقدمة مقدمة Solaris DTrace (2009) من تأليف S. Tripathi ، شركة صن مايكروسيستمز
مقدمة مقدمة Solaris DTrace (2009) من تأليف S. Tripathi ، شركة صن مايكروسيستمزفي مرحلة ما ، فتحت صن مصدر DTrace. اليوم ، يتوفر DTrace على Solaris و FreeBSD و macOS (على الرغم من أن إصدار macOS غير قابل للتشغيل بشكل عام لأن حماية تكامل النظام (SIP) قد خرقت العديد من المبادئ التي يعمل عليها DTrace).
نعم ، لقد لاحظت بشكل صحيح ... Linux ليس في هذه القائمة. هذه ليست مشكلة هندسية ، إنها مشكلة ترخيص. تم فتح DTrace تحت CDDL بدلاً من GPL.
أصبح منفذ Linux DTrace متاحًا منذ عام 2011 ، ولكن لم يتم دعمه من قِبل مطوري Linux الرئيسيين. في أوائل عام 2018 ،
أعادت Oracle فتح DTrace تحت رخصة GPL ، ولكن بحلول ذلك الوقت كان قد فات الأوان.
تتبع نظام لينكس البيئي
لا شك أن التتبع مفيد للغاية ، وقد سعى مجتمع Linux إلى تطوير حلوله الخاصة لهذا الموضوع. ولكن ، على عكس Solaris ، لا يخضع نظام Linux للرقابة بواسطة بائع واحد ، وبالتالي لم يكن هناك جهد متعمد لتطوير بديل وظيفي بالكامل لـ DTrace. تطور نظام التتبع البيئي لنظام Linux ببطء وبطبيعة الحال ، مما أدى إلى حل المشكلات عند نشوئها. ومؤخرا فقط نما هذا النظام البيئي بما يكفي لمنافسة DTrace بجدية.
بسبب النمو الطبيعي ، قد يبدو هذا النظام الإيكولوجي فوضويًا قليلاً ، ويتألف من العديد من المكونات المختلفة. لحسن الحظ ،
كتبت جوليا إيفانز
مراجعة لهذا النظام البيئي (الانتباه ، تاريخ النشر - 2017 ، قبل ظهور bpftrace).
 نظام لينكس تتبع النظام البيئي الذي وصفته جوليا إيفانز
نظام لينكس تتبع النظام البيئي الذي وصفته جوليا إيفانزليست كل العناصر متساوية في الأهمية. اسمحوا لي أن ألخص بإيجاز العناصر التي أعتبرها أهم.
مصادر الحدثيمكن أن تأتي بيانات الأحداث إما من مساحة المستخدم أو النواة (التطبيقات والمكتبات). بعضها متاح تلقائيًا ، دون بذل جهود إضافية للمطور ، بينما يحتاج البعض الآخر إلى الإعلان اليدوي.
 نظرة عامة على أهم مصادر الأحداث المتعقبة في Linux
نظرة عامة على أهم مصادر الأحداث المتعقبة في Linuxعلى جانب kernel ، توجد kprobes (
من "probes kernel" ، "kernel sensor" ، تقريبًا لكل. ) - وهي آلية تسمح لك بتتبع أي مكالمة وظيفة داخل kernel. مع ذلك ، يمكنك تتبع ليس فقط النظام يدعو أنفسهم ، ولكن أيضا ما يحدث داخلها (لأن نقاط دخول مكالمات النظام استدعاء وظائف داخلية أخرى). يمكنك أيضًا استخدام kprobes لتتبع أحداث kernel التي ليست مكالمات النظام ، على سبيل المثال ، "تتم كتابة البيانات المخزنة مؤقتًا على القرص" أو "يتم إرسال حزمة TCP عبر الشبكة" أو "تبديل السياق قيد التقدم".
تسمح نقاط تتبع Kernel بتتبع الأحداث غير القياسية المعرفة من قبل مطوري kernel. هذه الأحداث ليست على مستوى استدعاءات الوظائف. لإنشاء مثل هذه النقاط ، يضع مطورو kernel يدويًا الماكرو TRACE_EVENT في رمز kernel.
كلا المصادر لها إيجابيات وسلبيات. Kprobes يعمل "تلقائيا" ل لا يتطلب من مطوري kernel رمز الكود يدويًا. ولكن يمكن أن تتغير أحداث kprobe بشكل تعسفي من إصدار واحد من النواة إلى أخرى ، لأن الوظائف تتغير باستمرار - يتم إضافتها أو حذفها أو إعادة تسميتها.
تكون نقاط تتبع Kernel عمومًا أكثر ثباتًا بمرور الوقت وقد توفر معلومات مفيدة للسياق قد لا تكون متاحة في حالة استخدام kprobes. باستخدام kprobes ، يمكنك الوصول إلى وسيطات استدعاء الوظيفة. ولكن بمساعدة نقاط التتبع ، يمكنك الحصول على أي معلومات يقرر المطور kernel وصفها يدويًا.
في مساحة المستخدم ، يوجد تناظر بين kprobes و urobes. وهي مصممة لتتبع المكالمات وظيفة في مساحة المستخدم.
أجهزة استشعار USDT ("آثار مساحة المستخدم المحددة بشكل ثابت") هي تمثيلية لنقاط التتبع kernel في مساحة المستخدم. يحتاج مطورو التطبيقات إلى إضافة مستشعرات USDT يدويًا إلى الكود الخاص بهم.
حقيقة مثيرة للاهتمام: لقد وفرت DTrace منذ فترة طويلة واجهة برمجة التطبيقات (API) لتحديد التماثل الخاص بها لمستشعرات USDT (باستخدام الماكرو DTRACE_PROBE). قرر مطورو نظام التتبع على نظام Linux ترك الكود المصدري متوافقًا مع واجهة برمجة التطبيقات هذه ، وبالتالي يتم تحويل أي وحدات ماكرو DTRACE_PROBE تلقائيًا إلى مستشعرات USDT!
لذلك ، من الناحية النظرية ، يمكن تنفيذ الشرائط باستخدام kprobes ، ويمكن تنفيذ ltrace باستخدام uprobes. لست متأكدًا مما إذا كانت هذه تمارس بالفعل أم لا.
واجهاتواجهات هي التطبيقات التي تسمح للمستخدمين بسهولة استخدام مصادر الحدث.
دعونا ننظر في كيفية عمل مصادر الحدث. سير العمل على النحو التالي:
- يمثل kernel آلية - عادةً ملف / proc أو / sys مفتوحًا للكتابة - يسجل كل من نية تتبع الحدث وما يجب أن يتبع الحدث.
- بعد التسجيل ، يقوم kernel بترجمة kernel / function في الذاكرة / نقاط التتبع / مجسات USDT وتغيير الكود الخاص بهم حتى يحدث شيء آخر.
- يمكن جمع نتيجة "شيء آخر" لاحقًا باستخدام بعض الآليات.
لا أريد أن أفعل كل هذا يدويًا! لذلك ، تأتي السطوح البينية: فهي تفعل كل ذلك من أجلك.
هناك واجهات لكل ذوق ولون. في مجال
الواجهات المستندة إلى eBPF ، هناك
واجهات منخفضة المستوى تتطلب فهمًا عميقًا لكيفية التفاعل مع مصادر الأحداث وكيفية عمل كود eBPF bytecode. وهناك مستوى عالٍ وسهل التشغيل ، على الرغم من أنها لم تُظهر مرونة كبيرة أثناء وجودها.
لهذا السبب فإن bpftrace - أحدث واجهة - هي المفضلة لدي. انها سهلة الاستخدام ومرنة مثل DTrace. لكنه جديد تمامًا ويتطلب تلميعًا.
eBPF
eBPF هو
نجم تتبع Linux الجديد الذي تقوم عليه bpftrace. عندما تتعقب حدثًا ، فأنت تريد حدوث شيء ما في النواة. كيف طريقة مرنة لتحديد ما هو هذا "شيء"؟ بالطبع ، باستخدام لغة البرمجة (أو باستخدام رمز الجهاز).
eBPF (نسخة محسنة من مرشح حزم Berkeley). هذا جهاز ظاهري عالي الأداء يعمل في kernel ويحتوي على الخصائص / القيود التالية:
- تحدث جميع تفاعلات مساحة المستخدم من خلال "بطاقات" eBPF ، وهي عبارة عن تخزين بيانات ذي قيمة مفتاح.
- لا توجد دورات بحيث ينتهي كل برنامج eBPF في وقت محدد.
- انتظر ، قلنا Batch Filter؟ أنت على حق: لقد تم تصميمها في الأصل لتصفية حزم الشبكة. هذه مهمة مشابهة: عند إعادة توجيه الحزم (حدوث حدث) ، يلزمك تنفيذ بعض الإجراءات الإدارية (قبول أو تجاهل أو تعليق أو إعادة توجيه حزمة ، وما إلى ذلك). تم اختراع جهاز افتراضي لتسريع هذه الإجراءات (مع إمكانية JIT) تجميع). تعتبر النسخة "الموسعة" نظرًا لحقيقة أنه ، مقارنةً بالإصدار الأصلي من مرشح حزم Berkeley ، يمكن استخدام eBPF خارج سياق الشبكة.
ها أنت ذا. باستخدام bpftrace ، يمكنك تحديد الأحداث التي يجب تتبعها وما الذي يجب أن يحدث في الاستجابة. يقوم Bpftrace بتجميع برنامج bpftrace عالي المستوى الخاص بك إلى eBPF bytecode ، ويتتبع الأحداث ، ويقوم بتحميل الكود الثاني في kernel.
الأيام المظلمة قبل eBPF
قبل eBPF ، كانت خيارات الحل ، بعبارة ملطفة ، محرجة. يعد
SystemTap جزءًا من السلف "الأكثر خطورة" لـ bpftrace في عائلة Linux. يتم ترجمة البرامج النصية SystemTap إلى اللغة C وتحميلها في kernel كوحدات نمطية. ثم يتم تحميل وحدة النواة الناتجة.
كان هذا النهج هشًا للغاية وسوء الدعم خارج ريد هات إنتربرايز لينوكس. بالنسبة لي ، لم يعمل بشكل جيد على Ubuntu ، والذي كان يميل إلى كسر SystemTap على كل تحديث kernel بسبب تغيير في بنية بيانات kernel. يُقال أيضًا أنه في الأيام الأولى من وجوده ،
أدى SystemTap
بسهولة إلى نوبة
الذعر .
تركيب Bpftrace
حان الوقت لنشمر عن سواعدك! في هذا الدليل ، سننظر في تثبيت bpftrace على Ubuntu 18.04. الإصدارات الأحدث من التوزيع غير مرغوب فيها ، لأن أثناء التثبيت ، سنحتاج إلى حزم لم يتم تجميعها بعد.
تركيب التبعيةأولاً ، قم بتثبيت Clang 5.0 و lbclang 5.0 و LLVM 5.0 ، بما في ذلك جميع ملفات الرأس. سنستخدم الحزم التي توفرها llvm.org ، لأن الحزم الموجودة في مستودعات Ubuntu هي
مشكلة .
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
التالي:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
وأخيرًا ، قم بتثبيت libbfcc-dev من المنبع ، وليس من مستودع Ubuntu. لا
توجد ملفات رأس في الحزمة الموجودة في أوبونتو. وهذه المشكلة لم تحل حتى الساعة 18.10.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Bpftrace التثبيت الرئيسيحان الوقت لتثبيت bpftrace نفسه من المصدر! دعونا استنساخها وتجميعها وتثبيتها في / usr / local:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
وانتهيت! سيتم تثبيت الملف التنفيذي في / usr / local / bin / bpftrace. يمكنك تغيير الوجهة باستخدام وسيطة cmake ، والتي تبدو كهذا افتراضيًا:
DCMAKE_INSTALL_PREFIX=/usr/local.
أمثلة سطر واحددعنا ندير بعض bpftrace أحادية السطح لفهم قدراتنا. أخذت هذه من
دليل بريندان جريج ، الذي يحتوي على وصف مفصل لكل منهم.
# 1.عرض قائمة من أجهزة الاستشعار
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
# 2.التهاني
bpftrace -e 'BEGIN { printf("hello world\n"); }'
# 3.فتح ملف
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# 4.عدد مكالمات النظام لكل عملية
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 5.توزيع مكالمات القراءة () حسب عدد البايتات
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
# 6.تتبع ديناميكي للقراءة () المحتوى
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
# 7.الوقت الذي يقضيه في قراءة () المكالمات
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
# 8.عد الأحداث مستوى العملية
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
# 9.نحات التنميط مداخن العمل
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
# 10. مخطط التتبع
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
# 11.تتبع عرقلة I / O
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
تحقق من موقع Brendan Gregg لمعرفة
نوع المخرجات التي يمكن أن تنتجها الفرق المذكورة أعلاه .
بناء جملة البرنامج النصي ومثال توقيت الإدخال / الإخراجالسلسلة التي يتم تمريرها عبر رمز التبديل '-e' هي محتويات البرنامج النصي bpftrace. بناء الجملة في هذه الحالة هو ، بشكل مشروط ، مجموعة من الإنشاءات:
<event source> /<optional filter>/ { <program body> }
دعونا نلقي نظرة على المثال السابع ، حول توقيت عمليات قراءة نظام الملفات:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
نحن نتتبع الحدث من آلية
kprobe ، على سبيل المثال ، نحن نتتبع بداية وظيفة kernel.
إن وظيفة kernel للتتبع هي
vfs_read ،
وتسمى هذه الوظيفة عندما تقوم kernel بإجراء عملية قراءة من نظام الملفات (VFS من "Virtual FileSystem" ، التجريد من نظام الملفات داخل kernel).
عندما يبدأ
تنفيذ vfs_read (أي قبل أن تقوم الوظيفة بأي عمل مفيد) ، يبدأ برنامج bpftrace. إنه يحفظ الطابع الزمني الحالي (بالنانوثانية) لمجموعة مصفوفة عالمية تسمى
st art . المفتاح هو
tid ، في إشارة إلى معرف مؤشر الترابط الحالي.
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1. نقوم بتتبع الحدث من آلية
kretprobe ، التي تشبه
kprobe ، فيما عدا ما يطلق عليه عندما ترجع الدالة نتيجة تنفيذه.
2. وظيفة kernel للتتبع هي
vfs_read .
3. هذا هو مرشح اختياري. يتحقق ما إذا كان قد تم تسجيل وقت البدء مسبقاً. بدون هذا المرشح ، يمكن تشغيل البرنامج أثناء القراءة
والتقاط النهاية فقط ، مما يؤدي إلى وقت
nsecs مقدّر - 0 ، بدلاً من
nsecs - يبدأ .
4. نص البرنامج.
تحسب nsecs - st art [tid] مقدار الوقت الذي انقضى منذ بدء وظيفة vfs_read.
يضيفns [comm] = hist (...) البيانات المحددة إلى الرسم البياني ثنائي الأبعاد المخزن في
ns . يشير المفتاح
comm إلى اسم التطبيق الحالي. لذلك سيكون لدينا أمر المدرج الإحصائي عن طريق الأمر.
حذف (...) يحذف وقت البدء من المصفوفة الترابطية ، لأننا لم نعد بحاجة إليها.
هذا هو الاستنتاج النهائي. يرجى ملاحظة أن جميع الرسوم البيانية يتم عرضها تلقائيا. الاستخدام الواضح لأمر طباعة الرسم البياني غير مطلوب.
ns ليس متغيرًا خاصًا ، لذلك لا يتم عرض الرسم البياني بسببه.
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
مثال استشعار USDTلنأخذ هذا الرمز C وحفظه في ملف
tracetest.c :
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
يعمل هذا البرنامج إلى ما لا نهاية عن طريق استدعاء
myclock () مرة واحدة في الثانية.
يستعلم myclock () الوقت الحالي ويعيد عدد الثواني منذ بداية العصر.
تحدد الدعوة إلى
DTRACE_PROBE1 هنا نقطة تتبع
USDT ثابتة.
- يتم أخذ الماكرو DTRACE_PROBE1 من sys / sdt.h. يُطلق على ماكرو USDT الرسمي ، الذي يفعل الشيء نفسه ، STAP_PROBE1 (STAP من SystemTap ، والذي كان أول آلية Linux مدعومة في USDT). ولكن نظرًا لأن USDT متوافق مع أجهزة استشعار مساحة مستخدم DTrace ، فإن DTRACE_PROBE1 هو مجرد إشارة إلى STAP_PROBE1 .
- المعلمة الأولى هي اسم الموفر. أعتقد أن هذا بقايا أثرية من DTrace ، لأن bpftrace لا يبدو أنه يفعل أي شيء مفيد معها. ومع ذلك ، هناك فارق بسيط ( اكتشفته عند تصحيح المشكلة عند الطلب 328 ): يجب أن يكون اسم الموفر مطابقًا لاسم الملف الثنائي للتطبيق ، وإلا فلن يتمكن bpftrace من العثور على نقطة التتبع.
- المعلمة الثانية هي اسم نقطة التتبع.
- أي معلمات إضافية هي السياق المقدم من قبل المطورين. الرقم 1 في DTRACE_PROBE1 يعني أننا نريد تمرير معلمة إضافية واحدة.
دعنا نتأكد من توفر sys / sdt.h لنا ، ووضع البرنامج:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
نطلب bpftrace لإخراج PID و "الوقت هو [العدد]" كلما
تم الوصول إلى
testprobe :
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
تواصل Bpftrace العمل بينما نضغط على Ctrl-C. لذلك ، افتح محطة جديدة وقم بتشغيل
tracetest هناك:
# في المحطة الجديدة
. / اختبار
العودة إلى المحطة الأولى مع bpftrace ، هناك يجب أن ترى شيء مثل:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
مثال تخصيص الذاكرة باستخدام glibc ptmallocيمكنني استخدام bpftrace لفهم لماذا يستخدم روبي الكثير من الذاكرة. وكجزء من بحثي ، أحتاج إلى فهم كيفية استخدام أداة تخصيص الذاكرة الخاصة بـ glibc
لمناطق الذاكرة .
من أجل تحسين الأداء متعدد النواة ، يخصص مخصص ذاكرة glibc عدة "مناطق" من نظام التشغيل. عندما يسأل التطبيق عن تخصيص الذاكرة ، يقوم المُخصص بتحديد منطقة غير مستخدمة ويميز جزءًا من هذه المنطقة كـ "مستخدم". نظرًا لأن الخيوط تستخدم مساحات مختلفة ، يتم تقليل عدد الأقفال ، مما يؤدي إلى تحسين الأداء متعدد الخيوط.
ولكن هذا النهج يولد الكثير من القمامة ، ويبدو أن هذا الاستهلاك الكبير للذاكرة في روبي هو بالضبط بسبب ذلك. من أجل فهم طبيعة هذه القمامة بشكل أفضل ، تساءلت: ما معنى "اختيار منطقة غير مستخدمة"؟ هذا قد يعني واحدة من:
- في كل مرة يتم استدعاء malloc () ، يتكرّر الموزع في جميع المناطق ويجد المنطقة غير المؤمّنة حاليًا. وفقط إذا تم حظرهم جميعًا ، فسيحاول إنشاء حساب جديد.
- في المرة الأولى التي يتم فيها استدعاء malloc () على مؤشر ترابط محدد (أو عند بدء تشغيل مؤشر الترابط) ، سيختار المُخصص الخيط غير المحظور حاليًا. وإذا تم حظرها جميعًا ، فسيحاول إنشاء واحدة جديدة.
- في المرة الأولى التي يتم فيها استدعاء malloc () على مؤشر ترابط محدد (أو عند بدء تشغيل مؤشر الترابط) ، سيحاول المُخصص إنشاء منطقة جديدة ، بغض النظر عما إذا كانت هناك مناطق غير مؤمنة. فقط إذا تعذر إنشاء منطقة جديدة (على سبيل المثال ، عند استنفاد الحد) ، فسيتم إعادة استخدام المنطقة الحالية.
- ربما هناك المزيد من الخيارات التي لم أفكر فيها.
لا توجد إجابة محددة في الوثائق ، أي من هذه الميزات تسمح لك بتحديد منطقة غير مستخدمة. لقد درست الكود المصدري لـ glibc ، والذي اقترح أن الخيار 3 يمكنه القيام به. لكنني أردت التحقق بشكل تجريبي من أنني قمت بتفسير الكود المصدري بشكل صحيح ، دون الحاجة إلى تصحيح الكود في glibc.
هذه هي وظيفة تخصيص ذاكرة glibc التي تنشئ مساحة جديدة. ولكن يمكنك أن تسميها فقط بعد التحقق من الحد.
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
هل يمكنني استخدام
uprobes لتتبع وظيفة
_int_new_arena ؟ لسوء الحظ ، لا. لسبب ما ، لا يتوفر هذا الرمز في glibc Ubuntu 18.04. حتى بعد تثبيت رموز التصحيح.
لحسن الحظ ، هناك جهاز استشعار USDT في هذه الوظيفة.
LIBC_PROBE هو اسم مستعار لماكرو لـ
STAP_PROBE .
اسم المزود هو libc.
اسم المستشعر هو memory_arena_new.
الرقم 2 يعني أن هناك وسيطين إضافيين تم تحديدهما بواسطة المطور.
الساحة هي عنوان المنطقة التي تم استخراجها من نظام التشغيل ، والحجم هو حجمها.
قبل أن نتمكن من استخدام هذا المستشعر ، نحتاج
إلى حل المشكلة 328 . نحتاج إلى إنشاء ارتباط مع glibc في مكان ما باسم
libc ، لأن bpftrace تتوقع أن يكون اسم المكتبة (والذي سيكون على خلاف ذلك
libc-2.27.so ) مطابقًا لاسم الموفر
(libc) .
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
نحن نطلب الآن من bpftrace ربط جهاز استشعار USDT memory_arena_new ، واسم البائع هو
libc :
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
في محطة أخرى ، سنقوم بتشغيل روبي ، والذي سيخلق ثلاثة خيوط لا تفعل شيئًا وتنتهي في الثانية. نظرًا للحظر الشامل للمترجم
الفوري ، يجب ألا يتم استدعاء Ruby
malloc () في نفس الوقت بواسطة مؤشرات ترابط مختلفة.
ruby -e '3.times { Thread.new { } }; sleep 1'
بالعودة إلى المحطة مع bpftrace ، سنرى:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
هنا هو الجواب على سؤالنا! في كل مرة تقوم بإنشاء سلسلة جديدة في روبي ، يسلط glibc الضوء على منطقة جديدة بغض النظر عن القدرة التنافسية.
ما هي نقاط التتبع المتاحة؟ ما الذي يجب علي تتبعه؟يمكنك سرد جميع نقاط تتبع الأجهزة ، أجهزة ضبط الوقت ، kprobe ، وتتبع kernel الثابت عن طريق تشغيل الأمر:
sudo bpftrace -l
يمكنك سرد جميع نقاط التتبع uprobe (الأحرف الوظيفية) للتطبيق أو المكتبة عن طريق القيام بما يلي:
nm /path-to-binary
يمكنك سرد جميع نقاط التتبع لتطبيق أو مكتبة USDT عن طريق تشغيل الأمر التالي:
/usr/share/bcc/tools/tplist -l /path-to/binary
فيما يتعلق بنقاط التتبع التي يجب استخدامها: لن يضر بفهم شفرة المصدر لما ستقوم بتتبعه. أنصحك بدراسة الكود المصدري.
نصيحة: تنسيق هيكلي لنقاط التتبع في النواةإليك نصيحة مفيدة حول نقاط تتبع kernel. يمكنك التحقق من حقول الوسيطة المتوفرة من خلال قراءة الملف / sys / kernel / debug / tracing / events!
على سبيل المثال ، افترض أنك تريد تتبع المكالمات إلى
madvise (... ، MADV_DONTNEED) :
sudo bpftrace -l | grep madvise
- سوف يخبرنا أنه يمكننا استخدام tracepoint: syscalls: sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
- سوف تقدم لنا المعلومات التالية:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
Madvise التوقيع وفقا لدليل:
(باطل * addr ، size_t طول ، نصيحة كثافة العمليات) . الحقول الثلاثة الأخيرة من هذا الهيكل تتوافق مع هذه المعايير!
ما معنى MADV_DONTNEED؟ اذا حكمنا من خلال grep MADV_DONTNEED / usr / include ، يساوي 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
لذلك يصبح فريق bpftrace لدينا:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
الخاتمة
Bpftrace رائع! Bpftrace هو المستقبل!
إذا كنت ترغب في معرفة المزيد عنه ، فإنني أوصيك بأن تتعرف
على قيادته ، بالإضافة إلى
المشاركة الأولى لعام 2019 على مدونة بريندان جريج.
تصحيح جيد!