
على مدار العام الماضي ، كان هناك العديد من المنشورات حول الخدمات المصغرة بحيث أنه سيكون مضيعة للوقت لمعرفة ما هو ولماذا ، لذلك ستركز بقية المناقشة على مسألة كيفية تنفيذ هذه البنية ولماذا واجهت بالضبط وما هي المشاكل التي واجهتها.
واجهنا مشاكل كبيرة في بنك صغير: 3 صخور متراصة متصلة بكمية هائلة من تفاعلات RPC المتزامنة مع حجم كبير من الإرث. من أجل حل جميع المشكلات التي تنشأ في نفس الوقت جزئيًا على الأقل ، تقرر التبديل إلى بنية الخدمات الصغيرة. ولكن قبل اتخاذ قرار بشأن هذه الخطوة ، يجب عليك الإجابة عن ثلاثة أسئلة رئيسية:
- كيفية تقسيم متراصة إلى الخدمات الصغيرة والمعايير التي ينبغي اتباعها.
- كيف تتفاعل الخدمات الميكروية؟
- كيف تراقب؟
في الواقع سوف تكرس إجابات موجزة على هذه الأسئلة لهذه المادة.
كيفية تقسيم متراصة إلى الخدمات الصغيرة والمعايير التي ينبغي اتباعها.
هذا السؤال الذي يبدو بسيطا في النهاية حدد بنية المستقبل بالكامل.
نحن بنك ، لذلك يدور النظام بأكمله حول العمليات المالية والأشياء المساعدة المختلفة. من الممكن بالتأكيد تحويل معاملات ACID المالية إلى نظام موزع مع sagas ، ولكن في الحالة العامة ، يكون الأمر بالغ الصعوبة. وبالتالي قمنا بتطوير القواعد التالية:
- يتوافق مع S من SOLID للخدمات الدقيقة
- يجب أن تتم المعاملة بالكامل في microservice - لا توجد معاملات موزعة على تلف قاعدة البيانات
- للعمل ، يحتاج microservice إلى معلومات من قاعدة البيانات الخاصة به أو من طلب
- حاول أن تضمن النظافة (بمعنى اللغات الوظيفية) للخدمات الدقيقة
بطبيعة الحال ، في نفس الوقت كان من المستحيل إرضائهم تمامًا ، ولكن حتى التنفيذ الجزئي يبسط عملية التطوير إلى حد كبير.
كيف تتفاعل الخدمات الميكروية؟
هناك العديد من الخيارات ، ولكن في النهاية ، يمكن استخلاصها جميعًا من خلال "رسائل تبادل الخدمات المصغرة" البسيطة ، ولكن إذا قمت بتطبيق بروتوكول متزامن (على سبيل المثال ، RPC عبر REST) ، فستظل معظم مساوئ المتراصة ، ولكن بالكاد ستظهر مزايا الخدمات المجهرية. لذلك كان الحل الواضح هو أخذ أي وسيط للرسائل والبدء. اختيار بين RabbitMQ وكافكا استقر على الأخير ، وهنا لماذا:
- كافكا أبسط وتوفر نموذج مراسلة واحد - نشر - اشتراك
- من السهل نسبيًا الحصول على بيانات من كافكا للمرة الثانية. هذا مناسب للغاية لتصحيح الأخطاء أو إصلاح الخلل أثناء المعالجة غير الصحيحة ، فضلاً عن المراقبة والتسجيل.
- هناك طريقة واضحة وبسيطة لتوسيع نطاق الخدمة: تم إضافة أقسام للموضوع وأطلقت عددًا أكبر من المشتركين - وسيتم تنفيذ الباقي بواسطة kafka.
بالإضافة إلى ذلك ، أود أن ألفت الانتباه إلى مقارنة عالية الجودة ومفصلة .
تسمح لنا قوائم الانتظار في kafka + عدم التزامن بما يلي:
- قم بإيقاف تشغيل أي خدمة microservice للتحديثات لفترة وجيزة دون عواقب ملحوظة على البقية
- قم بإيقاف تشغيل أي خدمة لفترة طويلة ولا تهتم باستعادة البيانات. على سبيل المثال ، سقطت microservice في الآونة الأخيرة. تم إصلاحه بعد ساعتين ، أخذ الحسابات الأولية من كافكا وقام بمعالجة كل شيء. لم يكن ضروريًا ، كما كان من قبل ، لاستعادة ما كان من المفترض أن يحدث هناك وتنفيذ سجلات HTTP يدويًا وجدول منفصل في قاعدة البيانات.
- قم بتشغيل إصدارات اختبار الخدمات على البيانات الحالية من البيع وقارن نتائج معالجتها مع إصدار الخدمة على البيع.
كنظام تسلسل البيانات ، اخترنا AVRO ، لماذا - الموصوفة في مقال منفصل .
ولكن بغض النظر عن طريقة التسلسل التي تم اختيارها ، من المهم أن نفهم كيف سيتم تحديث البروتوكول. على الرغم من أن AVRO تدعم دقة المخطط ، إلا أننا لا نستخدم هذا ونقرر إدارياً بحتة:
- تتم كتابة البيانات في الموضوعات وقراءتها فقط من خلال AVRO ، اسم الموضوع يتوافق مع اسم المخطط (و Confluent لديه نهج مختلف - يكتبون مخططات ID AVRO من التسجيل في بايتات عالية من الرسالة ، بحيث يمكن أن يكون لديهم أنواع مختلفة من الرسائل في موضوع واحد
- إذا كنت بحاجة إلى إضافة أو تغيير البيانات ، يتم إنشاء مخطط جديد بموضوع جديد في kafka ، وبعد ذلك ينتقل جميع المنتجين إلى موضوع جديد ، ويتبعهم المشتركون
نقوم بتخزين دوائر AVRO نفسها في وحدات فرعية git والاتصال بجميع مشاريع kafka. قرروا عدم تنفيذ سجل مركزي للمخططات حتى الآن.
ملاحظة: قام الزملاء بعمل خيار مفتوح المصدر ولكن فقط باستخدام مخطط JSON بدلاً من AVRO .
بعض الخفايا
يتلقى كل مشترك جميع الرسائل من الموضوع
هذا هو خصوصية نشر - نموذج تفاعل الاشتراك - عند الاشتراك في موضوع ما ، سيتلقى المشترك كل منهم. نتيجة لذلك ، إذا كانت الخدمة تحتاج فقط إلى بعض الرسائل ، فسيتعين عليها تصفية هذه الرسائل. إذا أصبحت هذه مشكلة ، فسيكون من الممكن إنشاء جهاز توجيه خدمة منفصل يعرض الرسائل في العديد من الموضوعات المختلفة ، وبالتالي تنفيذ جزء من وظيفة RabbitMQ غير الموجودة في kafka. الآن لدينا مشترك واحد على python في عمليات ترابط واحد حوالي 7-5 آلاف رسالة في الثانية الواحدة ، ولكن إذا قمت بتشغيل من خلال PyPy ، فإن السرعة تنمو إلى 11-15000 / ثانية.
حدد عمر المؤشر في الموضوع
في إعدادات kafka ، هناك معلمة تحد من الوقت الذي "يتذكر" kafka حيث توقف القارئ - الافتراضي هو يومين. سيكون من الجيد رفعه إلى أسبوع ، بحيث إذا نشأت المشكلة في أيام العطلات ولم يتم حلها لمدة يومين ، فلن يؤدي ذلك إلى فقدان المركز في الموضوع.
قراءة تأكيد الحد الزمني
إذا لم يؤكد قارئ كافكا القراءة في 30 ثانية (معلمة قابلة للتكوين) ، فإن الوسيط يعتقد أن هناك خطأ ما ويحدث خطأ عند محاولة تأكيد القراءة. لتجنب ذلك ، عند معالجة رسالة لفترة طويلة ، نرسل تأكيدات للقراءة دون تحريك المؤشر.
الرسم البياني للاتصالات من الصعب فهم.
إذا قمت برسم كل العلاقات بصدق في graphviz ، فهناك قنفذ من نهاية العالم التقليدية للخدمات الميكروية مع عشرات الاتصالات في عقدة واحدة. لجعله (الرسم البياني للاتصالات) على الأقل قابلاً للقراءة ، اتفقنا على الملاحظة التالية: الخدمات الميكروية - البيضاوية ، موضوعات الكافكا - المستطيلات. وبالتالي ، على الرسم البياني واحد ، من الممكن عرض كل من حقيقة التفاعل ونوعه. لكن ، للأسف ، لم يتحسن الوضع كثيرًا. لذلك هذا السؤال لا يزال مفتوحا.
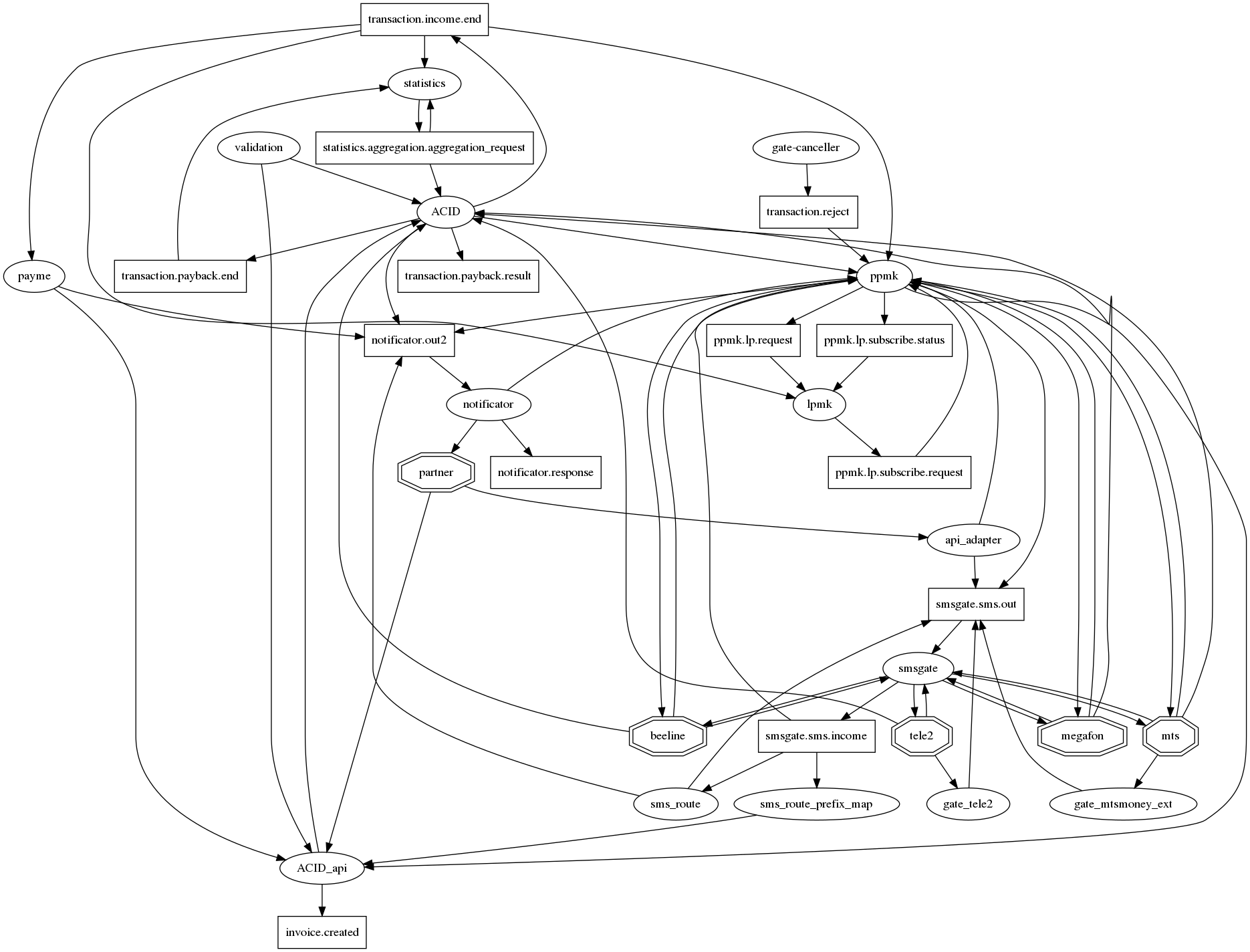
كيف تراقب؟
حتى كجزء من المتراصة ، كان لدينا سجلات في الملفات و Sentry ، لكن عندما تحولنا إلى التفاعل من خلال Kafka ونشرنا في k8s ، انتقلت السجلات إلى ElasticSearch وبالتالي قمنا بمراقبة قراءة سجلات المشترك أولاً في Elastic. لا سجلات - لا يوجد عمل.
بعد ذلك ، بدأوا في استخدام Prometheus و kafka- source قاموا بتعديل لوحة القيادة الخاصة به قليلاً: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
نتيجة لذلك ، حصلنا على هذه الصور:
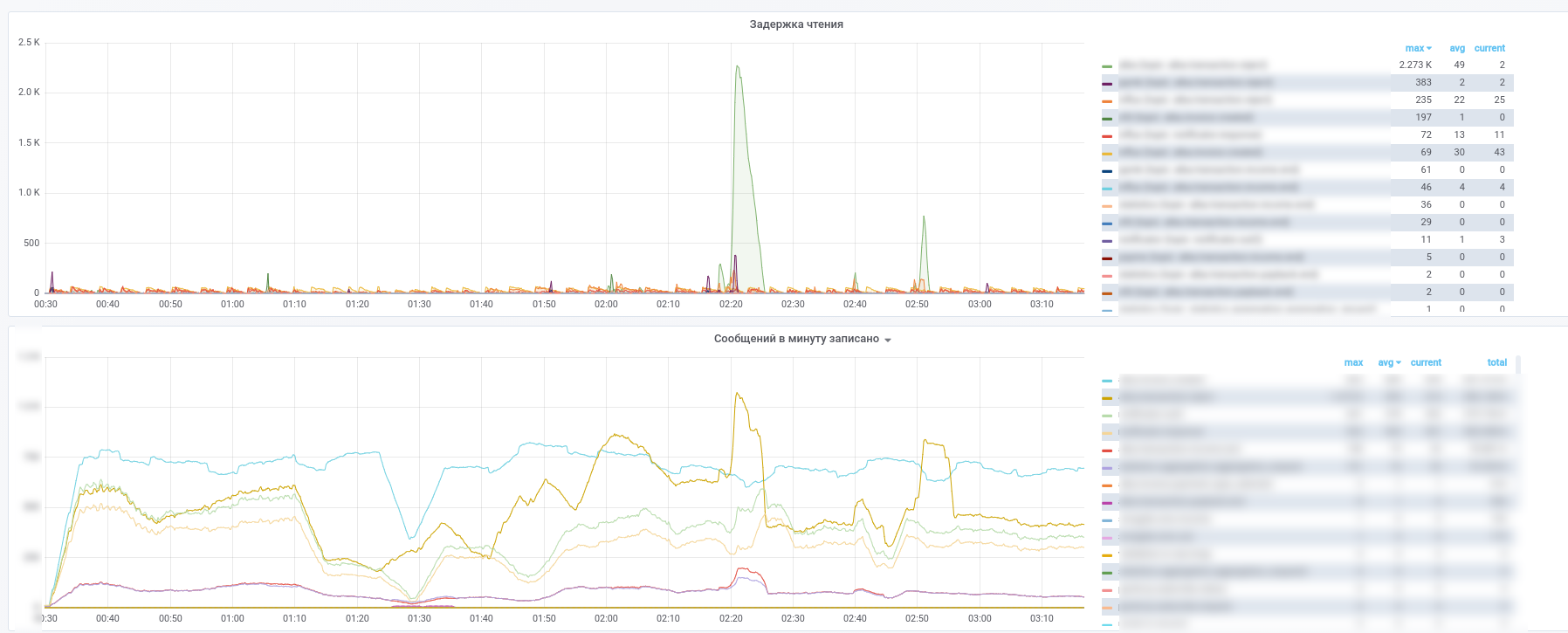
يمكنك معرفة الخدمة التي توقفت عن معالجة الرسائل.
بالإضافة إلى ذلك ، يتم نسخ جميع الرسائل من مواضيع رئيسية (معاملات الدفع وإشعارات من الشركاء ، وما إلى ذلك) إلى InfluxDB ، الذي تم إعداده في نفس grafana. لذلك ، لا يمكننا تسجيل حقيقة مرور الرسائل فقط ، ولكن أيضًا تقديم عينات مختلفة وفقًا للمحتوى. لذا ، فإن الإجابات على أسئلة مثل "ما هو متوسط وقت التأخير للاستجابة من إحدى الخدمات" أو "هل يختلف تدفق المعاملات اليوم كثيرًا عن البارحة في هذا المتجر" دائمًا؟
أيضًا ، لتبسيط تحليل الحوادث ، نستخدم الطريقة التالية: عند قيام كل خدمة ، عند معالجة رسالة ، باستكمالها بمعلومات التعريف التي تحتوي على UUID الصادرة عندما يعرض النظام مجموعة من سجلات النوع:
- اسم الخدمة
- UUID لعملية المعالجة في هذا microservice
- عملية البدء الطابع الزمني
- وقت العملية
- مجموعة العلامات
نتيجة لذلك ، مع مرور الرسالة عبر الرسم البياني الحسابي ، يتم إثراء الرسالة بمعلومات حول المسار الذي تم نقله على الرسم البياني. اتضح وجود تناظر zipkin / opentracing لـ MQ ، والذي يسمح بتلقي رسالة لاستعادة مسارها بسهولة على الرسم البياني. هذا يكتسب قيمة خاصة في تلك الحالات عندما تظهر الدورات على الرسم البياني. تذكر مثال خدمة صغيرة ، المشاركة في مدفوعاتها هي 0.0001٪ فقط ، ومن خلال تحليل المعلومات الوصفية في الرسالة ، يمكنه تحديد ما إذا كانوا بادئ الدفع دون الاتصال بقاعدة البيانات للتحقق منها.