الاهتمام بتحليل الصور لتوليد التوصيات يتزايد كل يوم. قررنا معرفة مدى حقيقة موضوع هذا الاتجاه يجلب. نتحدث عن اختبار استخدام التعلم العميق (التعلم العميق) لتحسين توصيات المنتجات ذات الصلة.

في هذه المقالة ، وصفنا تجربة تطبيق تقنية تحليل الصور لتحسين خوارزمية المنتجات ذات الصلة. يمكنك قراءتها بطريقتين: يمكن لأولئك الذين لا يهتمون بالتفاصيل التقنية لاستخدام الشبكات العصبية تخطي الفصول حول إنشاء مجموعة بيانات وتنفيذ الحلول والانتقال مباشرة إلى اختبارات AB ونتائجها. وبالنسبة لأولئك الذين لديهم فهم أساسي لمفاهيم مثل الزينة ، طبقة من الشبكة العصبية ، إلخ ، فإن المادة بأكملها ستكون مثيرة للاهتمام.
التعلم العميق في سياق تحليل الصور
في حزمة التكنولوجيا الخاصة بنا ، يتم استخدام التعلم العميق بنجاح كبير لحل بعض المشكلات. لبعض الوقت ، لم نجرؤ على تطبيقه في سياق تحليل الصور ، ولكن ظهر عدد من الأماكن التي غيرت رأينا مؤخرًا:
- زيادة اهتمام المجتمع بتحليل الصور باستخدام أساليب التعلم العميق ؛
- تم تحديد دائرة من الأطر "الناضجة" والشبكات العصبية المدربة مسبقًا ، والتي يمكن للمرء أن يبدأ بسرعة وببساطة ؛
- غالبًا ما يتم استخدام تحليل الصور في أنظمة التوصية كميزة تسويقية تضمن تحسينات "غير مسبوقة" ؛
- الاحتياجات الغذائية بدأت تظهر في هذا النوع من البحوث.
في سياق تقاطع أنظمة التوصية وتحليل الصور ، يمكن أن يكون هناك العديد من تطبيقات التعلم العميق ، ومع ذلك ، في المرحلة الأولى ، حددنا لأنفسنا ثلاث طرق رئيسية لتطوير هذا المجال:
- تحسن عام في جودة التوصيات ، على سبيل المثال ، المنتجات ذات الصلة بفستان تتناسب بشكل أفضل مع اللون والأناقة.
- يعد العثور على البضائع في قاعدة منتجات المتجر باستخدام صورة (In Shop Retrieval) آلية تتيح لك العثور على منتجات في قاعدة بيانات المتجر باستخدام صورة محملة.
- تحديد خصائص / سمات المنتج من الصورة (تمييز السمات) ، عندما يتم تحديد سمات مهمة من الصورة ، على سبيل المثال ، نوع المنتج - قميص ، سترة ، سراويل ، إلخ.
الخيار الأول والأول بالنسبة لنا هو الخيار الأول ، وقررنا استكشافه.
لماذا اخترت خوارزمية للمنتجات ذات الصلة
يحتوي أي نظام توصية على خوارزميات أساسية ثابتة للسلع الأساسية: البدائل والمنتجات ذات الصلة. وإذا كان كل شيء واضحًا مع البدائل - فهذه منتجات تشبه النموذج الأصلي (على سبيل المثال ، أنواع مختلفة من القمصان) ، ثم مع كل المنتجات ذات الصلة ، يصبح كل شيء أكثر تعقيدًا. من المهم هنا عدم ارتكاب خطأ في المراسلات بين المنتجات الأساسية والمنتجات الموصى بها ، على سبيل المثال ، يجب أن يكون الشاحن مناسبًا للهاتف ولون الفستان للأحذية وما إلى ذلك ؛ تحتاج إلى التفكير في ردود الفعل ، على سبيل المثال ، لا تنصح الهاتف لشاحن ، على الرغم من حقيقة أن يتم شراؤها معا ؛ والتفكير في مجموعة من الفروق الدقيقة الأخرى التي تنشأ في الممارسة العملية. إلى حد كبير بسبب وجود الفروق الدقيقة المختلفة ، وقع اختيارنا على المنتجات ذات الصلة. بالإضافة إلى ذلك ، فقط في المنتجات ذات الصلة ، يمكن تشكيل مظهر كامل ، إذا تحدثنا عن قسم الأزياء.
قمنا بصياغة هدف بحثنا الرئيسي على أنه "فهم ما إذا كان يمكن تحسين الخوارزمية الحالية للمنتجات ذات الصلة بشكل كبير باستخدام طرق التعلم العميق لتحليل الصور"
لاحظت قبل ذلك أننا لم نستخدم معلومات الصورة على الإطلاق عند حساب توصيات المنتج ، وهنا السبب:
- أثناء وجود منصة Retail Rocket ، اكتسبنا خبرة كبيرة في مجال توصيات المنتج. والنتيجة الرئيسية التي تلقيناها خلال هذا الوقت هي أن الاستخدام الصحيح لسلوك المستخدم يوفر حوالي 90 ٪ من النتيجة. نعم ، هناك مشكلة البداية الباردة ، عندما تكون محتويات المحتوى ، مثل المعلومات حول الصورة ، هي التي يمكن أن توضح أو تحسن التوصيات ، لكن في الواقع هذا التأثير أقل بكثير مما يقولونه نظريًا. لذلك ، لا نركز كثيرًا على مصادر محتوى المعلومات.
- لإنشاء توصيات المنتج في شكل معلومات المحتوى ، نستخدم عناصر مثل السعر والفئة والوصف وغيرها من الخصائص التي ينقلها المتجر إلينا. هذه الخصائص مستقلة عن المجال ويتم التحقق من صحتها نوعيًا عند دمج خدماتنا. قيمة الصورة ، على العكس من ذلك ، تنشأ في الواقع فقط في قطاع سلع الموضة.
- تعد المحافظة على خدمة العمل مع الصور ، والتحقق من جودتها وتوافقها مع البضائع عملية معقدة إلى حد ما وواجب فني جاد لم أرغب في تحمله دون تأكيد الحاجة.
ومع ذلك ، قررنا إعطاء فرصة للصور ونرى كيف ستؤثر على فعالية بناء التوصيات. نهجنا ليس مثالياً ، فمن المؤكد أن يقوم أحدهم بحل المشكلة بشكل مختلف. الهدف من هذه المقالة هو تقديم مقاربتنا بوصف للحجج في كل خطوة وتقديم النتائج للقارئ.
تشكيل مفهوم
بدأنا من خلال عبور المكونات الثلاثة لأي منتج: التكنولوجيا بأسعار معقولة ، والموارد المتاحة ، واحتياجات العملاء. لقد تطور مفهوم "تحسين التوصيات من خلال المعلومات حول صورة المنتجات ذات الصلة" بمفرده. تم تشكيل التطبيق "المثالي" لهذا المنتج كمشكلة تم تجميعها في صورة المظهر المحدد. علاوة على ذلك ، لا ينبغي أن تبدو هذه التوصيات رائعة فحسب ، بل يجب أن تعمل أيضًا من وجهة نظر مقاييس التجارة الإلكترونية الأساسية (التحويل ، RPV ، AOV) ، وليس أسوأ من الخوارزمية الأساسية لدينا.
Look هي صورة يختارها المصممون ، والتي تتضمن مجموعة من الأشياء المختلفة التي تجمع بين بعضها البعض ، على سبيل المثال ، الفستان ، السترة ، الكيس ، الحزام ، إلخ. على جانب عملائنا ، يتم تنفيذ هذا العمل عادة من قبل أشخاص معينين خصيصًا والذين يكون عملهم آليًا بشكل سيء. بعد كل شيء ، ليس كل شبكة عصبية يمكن أن يكون لها شعور الذوق.
 صورة مثال (انظر).
صورة مثال (انظر).كانت هناك قيود على استخدام معلومات الصورة على الفور - في الواقع ، تم العثور على التطبيق فقط في قطاع الأزياء.
البنية التحتية ومجموعة البيانات
بادئ ذي بدء ، رفعنا مقعد اختبار للتجارب والنماذج الأولية. كل شيء قياسي GPU + Python + Keras هنا ، لذلك لن ندخل في التفاصيل. لقد وجدنا مجموعة بيانات عالية الجودة تم تصميمها لحل العديد من المشكلات في وقت واحد ، بدءًا من التنبؤ بالسمات بدءًا من الصورة وحتى إنتاج مواد جديدة للملابس. ما كان مهمًا بشكل خاص بالنسبة لنا ، فقد تضمن صورًا تكوّن شكلًا واحدًا تقريبًا. أيضًا ، تضمنت مجموعة البيانات صوراً لنماذج الملابس من زوايا مختلفة ، والتي حاولنا استخدامها في المرحلة الأولى.
 مثال نظرة من مجموعة البيانات.
مثال نظرة من مجموعة البيانات. أمثلة لصور نموذج الملابس نفسه من زوايا مختلفة.
أمثلة لصور نموذج الملابس نفسه من زوايا مختلفة.الخطوات الأولى
كانت الفكرة الأولى لتنفيذ المنتج النهائي باستخدام مجموعة البيانات بسيطة للغاية: "فلنقل المشكلة إلى مهمة التعرف على الملابس حسب الصورة. وبالتالي ، عند صياغة التوصيات ، "سنرفع" تلك التوصيات المشابهة للمنتج الأساسي. " وفقًا لذلك ، كان من المفترض أن تجد وظيفة "القرب" من البضائع ، وعلى طول الطريق ، حل مشكلة إزالة البدائل في القضية.
يجب أن أقول على الفور أنه يمكن حل هذا النوع من المشاكل باستخدام شبكة عصبية تقليدية مدربة مسبقًا ، مثل ResNet-50. في الواقع: نحن نزيل الطبقة الأخيرة ، ونحصل على حفلات الزفاف ، ثم ، ثم جيب التمام ، كمقياس لـ "القرب". ومع ذلك ، بعد أن جربنا هذا النهج قليلاً ، قررنا تركه بشكل أساسي لثلاثة أسباب.
- ليس من الواضح جدًا كيفية تفسير القرب الناتج بشكل صحيح. ما يقصده جيب تمام = 0.7 في مجال القمصان ، حيث كقاعدة عامة ، كل شيء يشبه إلى حد كبير بعضهم البعض وما هو جيب التمام = 0.5 في مجال السترات ، حيث تكون الاختلافات أكثر أهمية. كنا بحاجة إلى هذا النوع من التفسير من أجل إزالة المنتجات القريبة جدًا - البدائل في وقت واحد.
- حصرنا هذا النهج قليلاً من وجهة نظر التعليم الإضافي لمهامنا المحددة. على سبيل المثال ، الميزات الهامة التي تشكل صورة شاملة ليست دائمًا هي نفسها من مجال لآخر. في مكان ما ، يكون اللون والشكل أكثر أهمية ، ولكن في مكان ما المادة وملمسها. بالإضافة إلى ذلك ، أردنا تدريب الشبكة لارتكاب أخطاء أقل بين الجنسين عندما ينصح النساء بملابس الرجال. مثل هذا الخطأ واضح على الفور وينبغي مواجهته نادراً قدر الإمكان. مع الاستخدام البسيط للشبكات العصبية المدربة مسبقًا ، بدا أننا كنا محدودين بعض الشيء بسبب عدم القدرة على تقديم أمثلة "متشابهة" جيدًا من حيث الصورة.
- يبدو أن استخدام شبكات سيامي ، والتي هي أكثر ملاءمة لهذه المهام ، هو خيار أكثر طبيعية ودراسة جيدة.
قليلا عن الشبكة العصبية سيامي
تستخدم الشبكات العصبية السيامية على نطاق واسع في حل المهام المتعلقة بالتعرف على الوجوه. عند الإدخال ، يتم توفير صورة للشخص ، عند الإخراج ، اسم الشخص من قاعدة البيانات التي ينتمي إليها. يمكن حل هذه المشكلة مباشرة ، إذا كنت تستخدم برنامج softmax وعدد الطبقات مساويًا لعدد الأشخاص المعروفين في الطبقة الأخيرة من الشبكة العصبية. ومع ذلك ، يحتوي هذا النهج على العديد من القيود:
- يجب أن يكون لديك عدد كبير بما فيه الكفاية من الصور لكل فصل ، وهذا مستحيل عملياً.
- يجب إعادة تدريب هذه الشبكة العصبية في كل مرة يتم فيها إضافة شخص جديد إلى قاعدة البيانات ، وهو أمر غير مريح للغاية.
يتمثل الحل المنطقي في مثل هذا الموقف في الحصول على وظيفة "التشابه" الخاصة بالصورتين من أجل الإجابة في أي وقت عما إذا كانت الصورتان - التي تغذيها مدخلات الشبكة العصبية والمرجع من قاعدة البيانات - تنتمي إلى نفس الشخص ، وبالتالي ، حل مشكلة التعرف على الوجوه. هذا أكثر اتساقًا مع سلوك الشخص. على سبيل المثال ، ينظر الحارس إلى وجه شخص وصورة على شارة ويجيب على السؤال عما إذا كان هذا الشخص واحدًا أم لا. تطبق الشبكة العصبية السيامية مفهومًا مشابهًا.
المكون الرئيسي للشبكة العصبية السيامية هو الشبكة العصبية الأساسية ، والتي تنتج صورة تضمين. يمكن استخدام هذا التضمين لتحديد درجة التشابه بين الصورتين. في بنية الشبكة العصبية السيامية ، يتم استخدام المكون الأساسي مرتين ، في كل مرة لتلقي دمج الصورة. يحتاج الباحث إلى إظهار قيم المخرجات 0 أو 1 ، اعتمادًا على ما إذا كان شخص أو شخص آخر يمتلك الصور ، وضبط الشبكة العصبية الأساسية.
 مثال على الشبكة العصبية السيامية. يتم الحصول على زخرفة الصور العلوية والسفلية من العمود الفقري للشبكة العصبية. الصورة مأخوذة من دورة "الشبكات العصبية الملتوية" لأندري نغ.
مثال على الشبكة العصبية السيامية. يتم الحصول على زخرفة الصور العلوية والسفلية من العمود الفقري للشبكة العصبية. الصورة مأخوذة من دورة "الشبكات العصبية الملتوية" لأندري نغ.الحل الأساسي
وهكذا ، بعد إجراء بعض التجارب ، كانت النسخة الأولى من الخوارزمية كما يلي:
- نحن نأخذ أي شبكة عصبية مدربة مسبقا باعتبارها العمود الفقري. قمنا بتجربة ResNet-50 و InceptionV3. تم اختيارها على أساس توازن حجم الشبكة ودقة التنبؤات. ركزنا على البيانات المقدمة في الوثائق الرسمية لقسم Keras "توثيق النماذج الفردية".
- نخلق شبكة سيامي على أساسها ونستخدم Triple Triple Loss للتدريب.
- كأمثلة إيجابية ، نحن نخدم نفس الصورة ، ولكن من زاوية مختلفة. كمثال سلبي ، نحن نخدم منتجًا آخر.
- بوجود نموذج مدرب ، نحصل على مقياس القرب لأي زوج من المنتجات بنفس طريقة اعتبار Triplet Loss.
ثلاثة أضعاف رمز حساب الخسارة.كانت الصفقة مع Triplet Loss في مشروع حقيقي هي المرة الأولى التي خلقت عددًا من الصعوبات. في البداية ، ناضلوا لفترة طويلة مع حقيقة أن جميع حفلات الزفاف المستلمة وصلت إلى نقطة واحدة. كان هناك عدد من الأسباب: لم نقم بتطبيع الأعراس قبل حساب الخسارة ؛ الهامش كانت المعلمة alpha صغيرة جدًا والأمثلة صعبة للغاية. بدأ التطبيع المضافة وحفلات الزفاف تختلف. المشكلة الثانية أصبحت بشكل غير متوقع انفجار التدرج. لحسن الحظ ، جعل Keras من الممكن حل هذه المشكلة بكل بساطة - لقد أضفنا clipnorm = 1.0 إلى المُحسِّن ، والذي لم يسمح للمتدربين بالنمو أثناء التدريب.
كان العمل تكراريًا: قمنا بتدريب النموذج وخفضنا الخسارة ونظرنا إلى النتيجة النهائية وقررنا بخبرة الاتجاه الذي كنا نسير فيه. في مرحلة ما ، أصبح من الواضح أننا قمنا على الفور بإعداد أمثلة معقدة إلى حد ما وأن التعقيد لا يتغير في عملية التعلم ، مما يؤثر سلبًا على النتيجة النهائية. لحسن الحظ ، كان لمجموعة البيانات التي عملنا بها بنية شجرة جيدة ، مما يعكس المنتج نفسه ، على سبيل المثال الرجال -> السراويل ، الرجال -> البلوزات ، إلخ. هذا سمح لنا بإعادة تشكيل المولد وبدأنا في تقديم أمثلة "سهلة" للعصور القليلة الأولى ، ثم تلك الأكثر تعقيدًا وما إلى ذلك. الأمثلة الأكثر صعوبة هي منتجات من نفس فئة المنتج ، على سبيل المثال سراويل ، سلبية.
نتيجة لذلك ، حصلنا على نموذج يختلف في إنتاجه عن المنهجية "الساذجة" لاستخدام ResNet-50. ومع ذلك ، فإن جودة التوصيات النهائية لا تناسبنا تمامًا. أولاً ، كانت هناك مشكلة في أخطاء النوع الاجتماعي ، ولكن كان هناك فهم لكيفية حلها. نظرًا لأن مجموعة البيانات قسمت الملابس إلى ذكور وإناث ، فقد كان من السهل جمع أمثلة سلبية للتدريب. ثانياً ، عند التدريب على مجموعة البيانات والنتيجة النهائية ، فحصنا عملاءنا بشكل مرئي - أصبح من الواضح على الفور أنه من الضروري إعادة ضبط أمثلةهم ، لأن بعض الخوارزمية عملت بشكل سيء للغاية إذا لم تتداخل البضاعة جيدًا مع ما تم عرضه أثناء التدريب . أخيرًا ، كانت الجودة في كثير من الأحيان رديئة ، لأن صورة التدريب كانت غالبًا مزعجة ومضمونة ، على سبيل المثال ، ليس فقط الجينز ، ولكن أيضًا قميص.
 صورة الجينز التي في الواقع يظهر أيضا قميصا وأحذية.
صورة الجينز التي في الواقع يظهر أيضا قميصا وأحذية.كانت التجربة الأولى بمثابة أساس للحل اللاحق ، على الرغم من أننا لم نبدأ على الفور في تنفيذ نموذج محسّن.
 مثال على توصيات تستند إلى حل أساسي. هناك أخطاء بين الجنسين ، والبدائل تأتي أيضا.
مثال على توصيات تستند إلى حل أساسي. هناك أخطاء بين الجنسين ، والبدائل تأتي أيضا.نموذج محسّن
بدأنا بتدريب ResNet-50 على البيانات من مجموعة البيانات الخاصة بنا. تحتوي مجموعة البيانات على معلومات حول ما يظهر في الصورة. يتم استخراجها من هيكل مجموعة البيانات الرجال -> السراويل ، النساء -> بالأزرار وأكثر من ذلك. تم تنفيذ هذا الإجراء لسببين: أولاً ، أرادوا "توجيه" العمود الفقري - شبكة عصبية إلى مجال الملابس ؛ ثانياً ، نظرًا لأن الملابس مقسمة حسب الجنس ، فقد كانوا يأملون في التخلص من مشكلة أخطاء النوع التي تمت مواجهتها في الإصدار الأول.
في المرحلة الثانية ، حاولنا إزالة الضوضاء في وقت واحد من الصور المدخلة والحصول على أزواج إيجابية من المنتجات ذات الصلة لمزيد من التدريب. تم تصميم مجموعة البيانات المستخدمة من قبلنا أيضًا لحل مشكلة اكتشاف الكائنات في الصورة. بمعنى آخر ، لكل صورة: إحداثيات المستطيل الذي يصف الكائن وفئته. لحل هذا النوع من المشكلات ، استخدمنا مشروعًا
جاهزًا . يستخدم هذا المشروع هندسة الشبكة العصبية RetinaNet باستخدام فقد بؤري خاص. يكمن جوهر هذه الخسارة في التركيز بشكل أكبر ليس على خلفية الصورة ، الموجودة في كل صورة تقريبًا ، ولكن على الكائن الذي يجب اكتشافه. كعمود أساسي لشبكة عصبية للتدريب ، استخدمنا شبكتنا المدربة مسبقًا ResNet-50.
ونتيجة لذلك ، يتم اكتشاف ثلاث فئات من الكائنات على كل صورة من مجموعة البيانات: "أعلى" و "أسفل" و "منظر عام". بعد تحديد الفئتين "العلوية" و "السفلية" ، قمنا ببساطة بتقطيع الصورة إلى صورتين منفصلتين ، والتي سيتم استخدامها لاحقًا كزوج من الأمثلة الإيجابية لحساب Triplet Loss. تبين أن جودة اكتشاف الأشياء عالية جدًا ، وكانت الشكوى الوحيدة هي أنه لم يكن من الممكن دائمًا العثور على فئة في الصورة. لم تكن هذه مشكلة بالنسبة لنا ، حيث يمكننا بسهولة زيادة عدد الصور للتنبؤات.
 مثال على اكتشاف الفئات "أعلى" و "أسفل" وقطع الصورة.
مثال على اكتشاف الفئات "أعلى" و "أسفل" وقطع الصورة.بوجود هذا النوع من الصور المقسمة ، سنحت لنا الفرصة لأخذ أي نظرة من الإنترنت وتقسيمها إلى مكونات للاستخدام في التدريب. لزيادة عينة التدريب والتغلب على المشكلة من خلال عدم كفاية تغطية الأمثلة التي نشأت أثناء تطوير الحل الأساسي ، قمنا بتوسيع مجموعة البيانات بسبب الصور "المقطوعة" لأحد عملائنا. المشكلة الوحيدة هي أننا لم نميز أشياء مثل "الملحقات" ، "غطاء الرأس" ، "الأحذية" ، وهلم جرا. خلق هذا بعض القيود ، لكنه كان مناسبًا تمامًا لاختبار المفهوم. بعد تلقي نتائج إيجابية ، خططنا لتوسيع النموذج ليشمل الفئات الموضحة أعلاه.
بعد تلقي مجموعة بيانات ممتدة ، استخدمنا المنهجية التي تم إثباتها بالفعل لبناء شبكة Siamese من حل أساسي ، على الرغم من وجود العديد من الاختلافات. أولاً ، بصفتنا العمود الفقري للشبكة العصبية ، استخدمنا شبكة ResNet-50 المدربة الآن والموضحة أعلاه. ثانياً ، الآن ، كأمثلة إيجابية ، قدمنا من أعلى إلى أسفل أزواج والعكس بالعكس ، مما يتيح لنا التعلم من الشبكة العصبية بالضبط "مراسلات" الصورة. حسنًا ، في الواقع اثنتي عشرة حقبة في وقت لاحق ، ظهرت آلية منحتنا الفرصة لتقييم "تطابق" البضائع مع صورة واحدة.
 مثال على التوصيات بناءً على استخدام الشبكة العصبية. ينصح السراويل القصيرة للمنتج الأساسي ؛ ينصح القمصان.
مثال على التوصيات بناءً على استخدام الشبكة العصبية. ينصح السراويل القصيرة للمنتج الأساسي ؛ ينصح القمصان.لقد أسعدتنا النتيجة النهائية: اتضح أن التوصيات كانت ذات نوعية جيدة ، وما هو جيد بشكل خاص ، لم يتطلب بنائها أي تاريخ من تفاعلات المستخدم. ومع ذلك ، ظلت المشاكل قائمة ، وكانت المشكلة الرئيسية هي توافر بدائل في عملية التسليم. وهكذا ظهرت عمليات التسليم التي أوصى فيها "القاع" بـ "القاع" ، ونفس الشيء حدث مع الفئة "أعلى". هذا جعلنا نفكر ونحسن الحل لإزالة البدائل.
إزالة البدائل
لحل مشكلة توفر البدائل ، كان الإصدار سريعًا للغاية. ساعدت التجارب الأولية مع ResNet-50 "الفانيليا". أعطت مثل هذه الشبكة العصبية كسلع "مماثلة" تلك التي تزامنت في الصورة - في الواقع ، بدائل. وهذا هو ، يمكن استخدامه لتحديد البدائل.
 مثال على التوصيات المستندة إلى ResNet-50 "الفانيليا". البضائع بدائل.
مثال على التوصيات المستندة إلى ResNet-50 "الفانيليا". البضائع بدائل.باستخدام هذه الخاصية المفيدة لـ ResNet-50 ، بدأنا في تصفية أقرب المنتجات الممكنة من الإصدار ، وبالتالي إزالة البدائل. كانت هناك عيوب أيضًا في هذا النهج - وهو نفس الموقف غير المفهوم الذي اخترت به عتبة التصفية. في بعض الأحيان يتم ترشيح الكثير من المنتجات ، على الرغم من أنها خارجياً لم تكن بدائل. ومع ذلك ، لم نركز على هذه المشكلة واستمرنا في العمل أكثر.
تحضير اختبارات AB
للتحقق النهائي من أي تغيير في الخوارزميات تقريبًا ، نستخدم أداة الاختبار AB على نطاق واسع. علاوة على ذلك ، لدينا قاعدة واحدة فقط: "بغض النظر عن مدى ضياع الخسارة ، وبغض النظر عن مدى تعقيد ومتعددة الطبقات للشبكة العصبية ، كم هي جميلة التوصيات - كل هذا لا يتم النظر فيه إذا لم تكن هناك نتيجة لاختبار AB". المنطق بسيط للغاية: اختبار AB هو الأكثر صدقًا ومفهومًا لجميع الأطراف (وخاصة العملاء والشركات) وطريقة دقيقة لقياس النتيجة. Retail Rocket - ( «
A/- 99% - ? »). - .
-. ,
RecSys 2016 . . , , , , . , - , .
, . , . , . - . , , , , - . : .
- , . -, , , , . -, — , , , , . , . , , , “», .
:
- “” “”, , , , . , , , .
- , . proof-of-concept , .
, , . , , .
AB-
, , - . — fashion. . , , . , , .
. 3 . , 95%.
 . Related-9 — “” , Related — .
. Related-9 — “” , Related — . . Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.
. Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.: . , , , “” CTR. , , CTR , . - , - - , -. , .
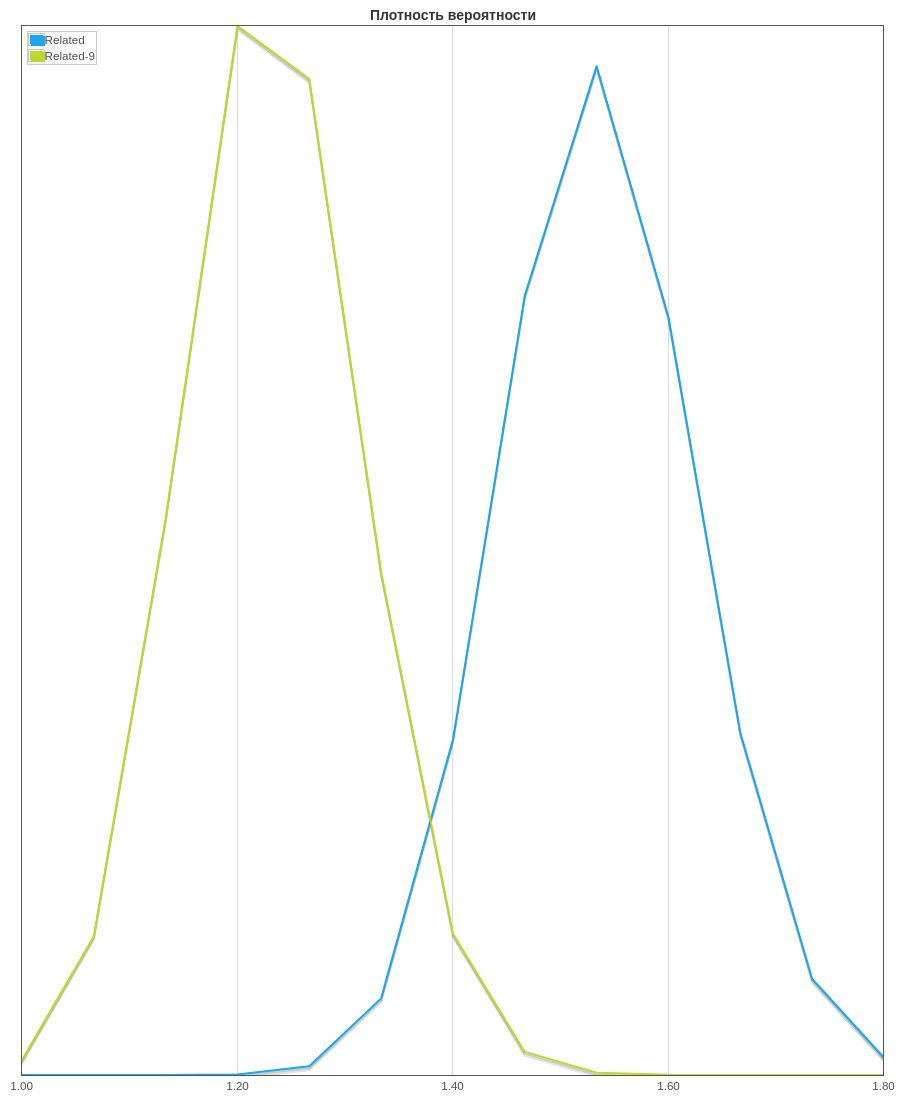 CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%.
CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%., , , , . , , . , , . .
الاستنتاجات
, , . , , . - . , — — , . , . , , , Retail Rocket.
, , , , « ». , . , .
, Retail Rocket