على مدار السنوات السبع الماضية ، مع الفريق ، كنت أؤيد ونطور جوهر منتج Miro (سابقًا RealtimeBoard): التفاعل بين الخادم والخادم العنقودي ، والعمل مع قاعدة البيانات.
لدينا جافا مع مكتبات مختلفة على متن الطائرة. يتم إطلاق كل شيء خارج الحاوية ، من خلال البرنامج المساعد Maven. يعتمد ذلك على النظام الأساسي لشركائنا ، والذي يسمح لنا بالعمل مع قاعدة البيانات والتدفقات ، وإدارة التفاعل بين العميل والخادم ، إلخ. DB - Redis و PostgreSQL (
كتب زميلي
حول كيفية انتقالنا من قاعدة بيانات إلى أخرى ).
من حيث منطق الأعمال ، يحتوي التطبيق على:
- العمل مع لوحات مخصصة ومحتواها ؛
- وظيفة لتسجيل المستخدم ، وإنشاء وإدارة المجالس ؛
- مولد الموارد المخصصة. على سبيل المثال ، يعمل على تحسين الصور الكبيرة التي تم تحميلها إلى التطبيق بحيث لا تبطئ من عملائنا ؛
- العديد من عمليات الدمج مع خدمات الجهات الخارجية.
في عام 2011 ، عندما بدأنا للتو ، كان Miro بالكامل على نفس الخادم. كان لديه كل شيء: Nginx ، الذي كان php للموقع قيد التشغيل ، تطبيق Java وقواعد البيانات.
تم تطوير المنتج وعدد المستخدمين والمحتوى الذي أضافوه إلى اللوحات ، وبالتالي زاد التحميل على الخادم أيضًا. نظرًا لوجود عدد كبير من التطبيقات على الخادم الخاص بنا ، في هذه اللحظة ، لم نتمكن من فهم ما الذي يوفر بالضبط الحمل وبالتالي لم نتمكن من تحسينه ، ولإصلاح ذلك ، قسمنا كل شيء إلى خوادم مختلفة ، وحصلنا على خادم ويب ، خادم مع تطبيقنا وخادم قاعدة البيانات.
لسوء الحظ ، بعد مرور بعض الوقت ، ظهرت المشكلات مرة أخرى ، حيث استمر التحميل في التطبيق في الزيادة. ثم فكرنا في كيفية توسيع نطاق البنية التحتية.

بعد ذلك ، سأتحدث عن الصعوبات التي واجهناها في تطوير المجموعات وتوسيع نطاق تطبيقات Java والبنية التحتية.
نطاق البنية التحتية أفقيا
بدأنا من خلال جمع المقاييس: استخدام الذاكرة ووحدة المعالجة المركزية ، والوقت الذي يستغرقه تنفيذ استعلامات المستخدم ، واستخدام موارد النظام ، والعمل مع قاعدة البيانات. من المقاييس ، كان من الواضح أن توليد موارد المستخدم كان عملية لا يمكن التنبؤ بها. يمكننا تحميل المعالج 100٪ وانتظر عشرات ثوان حتى يتم كل شيء. طلبات المستخدمين للوحات أيضا في بعض الأحيان أعطت تحميل غير متوقع. على سبيل المثال ، عندما يختار المستخدم ألف عنصر واجهة مستخدم ويبدأ بنقلها تلقائيًا.
بدأنا في التفكير في كيفية توسيع نطاق هذه الأجزاء من النظام وتوصلنا إلى حلول واضحة.
نطاق العمل مع المجالس والمحتوى . يقوم المستخدم بفتح اللوحة مثل هذا: يفتح المستخدم العميل → يشير إلى اللوحة التي يريد فتحها - يتصل بالخادم - يتم إنشاء دفق على الخادم - يتصل جميع مستخدمي هذه اللوحة بدفق واحد - يحدث أي تغيير أو إنشاء عنصر واجهة مستخدم ضمن هذا الدفق. اتضح أن كل العمل مع اللوحة مقيد بشدة بالتدفق ، مما يعني أنه يمكننا توزيع هذه التدفقات بين الخوادم.
مقياس تكوين موارد المستخدم . يمكننا إخراج الخادم لتوليد الموارد بشكل منفصل ، وسيتلقى رسائل للتوليد ، ومن ثم نرد أن كل شيء يتم إنشاؤه.
يبدو أن كل شيء بسيط. ولكن بمجرد أن بدأنا دراسة هذا الموضوع بعمق أكبر ، اتضح أننا بحاجة إلى حل بعض المشكلات غير المباشرة بالإضافة إلى ذلك. على سبيل المثال ، إذا انتهت صلاحية المستخدم للاشتراك المدفوع ، فيجب علينا إخطارهم بذلك ، بغض النظر عن اللوحة التي يعملون بها. أو ، إذا قام المستخدم بتحديث إصدار المورد ، فأنت بحاجة إلى التأكد من مسح ذاكرة التخزين المؤقت بشكل صحيح على جميع الخوادم وإعطاء الإصدار الصحيح.
لقد حددنا متطلبات النظام. والخطوة التالية هي لفهم كيفية وضع هذا موضع التنفيذ. في الواقع ، كنا بحاجة إلى نظام يسمح للخوادم في المجموعة بالتواصل مع بعضها البعض وعلى أساس أننا سوف ندرك جميع أفكارنا.
الكتلة الأولى من خارج منطقة الجزاء
لم نختار الإصدار الأول من النظام ، لأنه تم تنفيذه جزئيًا بالفعل في النظام الأساسي للشريك الذي استخدمناه. في ذلك ، كانت جميع الخوادم متصلة ببعضها البعض عبر TCP ، وباستخدام هذا الاتصال ، يمكننا إرسال رسائل RPC إلى واحد أو جميع الخوادم في وقت واحد.
على سبيل المثال ، لدينا ثلاثة خوادم ، وهي متصلة ببعضها البعض عبر TCP ، وفي Redis لدينا قائمة بهذه الخوادم. نبدأ خادمًا جديدًا في المجموعة - يضيف نفسه إلى القائمة في قائمة Redis → - يقرأ القائمة للتعرف على جميع الخوادم الموجودة في الكتلة - يتصل بها جميعًا.
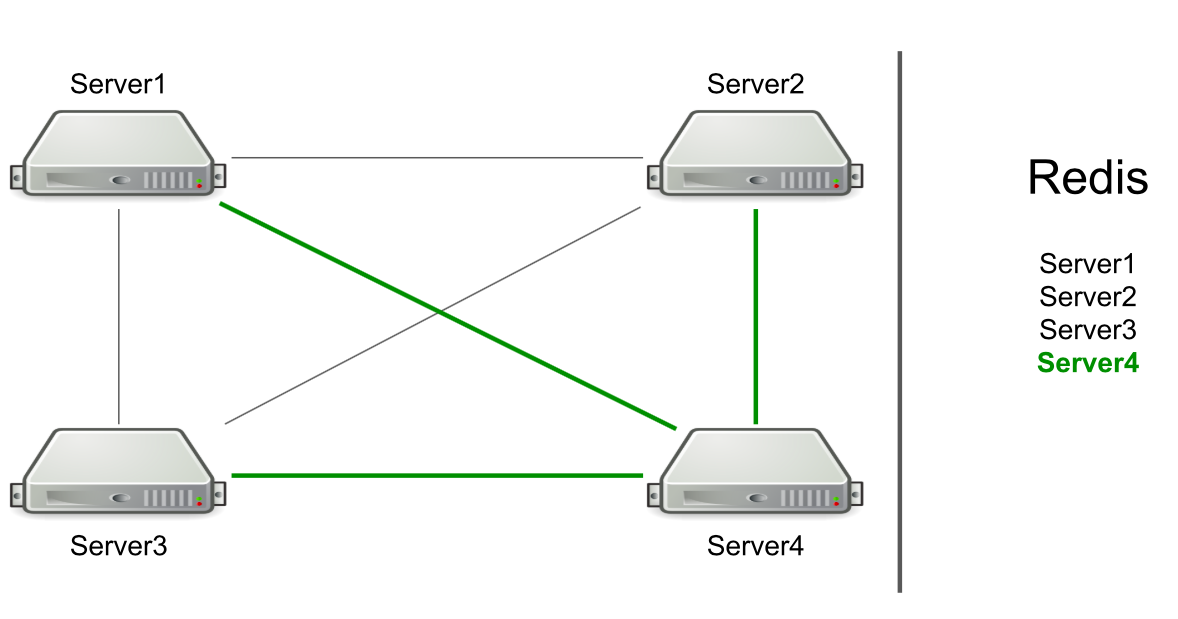
استنادًا إلى RPC ، تم بالفعل تطبيق دعم مسح ذاكرة التخزين المؤقت وإعادة توجيه المستخدمين إلى الخادم المرغوب. كان يتعين علينا القيام بجيل من موارد المستخدم وإبلاغ المستخدمين بحدوث شيء ما (على سبيل المثال ، انتهت صلاحية الحساب). لتوليد الموارد ، اخترنا خادمًا تعسفيًا وأرسلنا إليه طلبًا للتوليد ، ولإخطارات حول انتهاء صلاحية الاشتراك ، أرسلنا أمرًا إلى جميع الخوادم على أمل أن تصل الرسالة إلى الهدف.
يحدد الخادم نفسه الجهة التي ترسل الرسالة
يبدو كميزة ، وليس مشكلة. لكن الخادم يركز فقط على الاتصال بخادم آخر. إذا كانت هناك اتصالات ، فهناك مرشح لإرسال رسالة.
تكمن المشكلة في أن الخادم رقم 1 لا يعرف أن رقم الخادم 4 تحت التحميل الكبير في الوقت الحالي ولا يمكنه الإجابة عليه بسرعة كافية. نتيجة لذلك ، تتم معالجة طلبات الخادم رقم 1 ببطء أكثر مما يمكن.
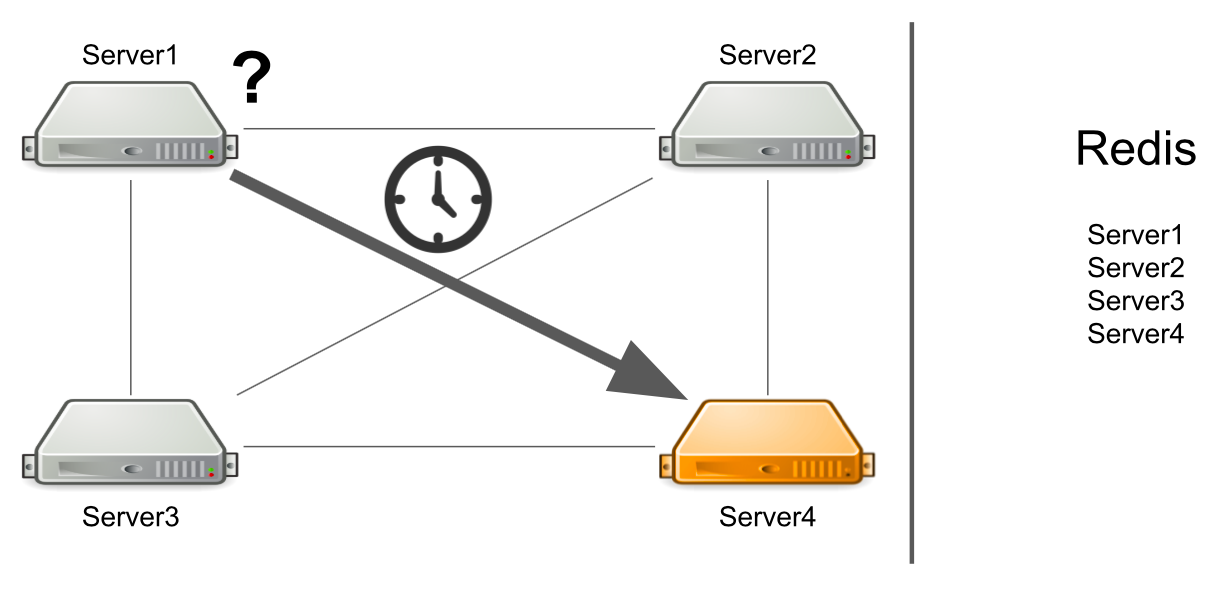
لا يعرف الخادم أن الخادم الثاني متجمد
ولكن ماذا لو لم يتم تحميل الخادم بشدة ، ولكن بشكل عام يتجمد؟ علاوة على ذلك ، فهي معلقة حتى لا تعود الحياة. على سبيل المثال ، لقد استنفدت جميع الذاكرة المتاحة.
في هذه الحالة ، لا يعرف الخادم رقم 1 ما المشكلة ، لذلك يستمر في انتظار الإجابة. لا تعرف الخوادم المتبقية في المجموعة أيضًا عن الموقف مع الخادم رقم 4 ، لذلك سترسل الكثير من الرسائل إلى الخادم رقم 4 وتنتظر الرد. لذلك سوف يكون حتى وفاة رقم الخادم 4.
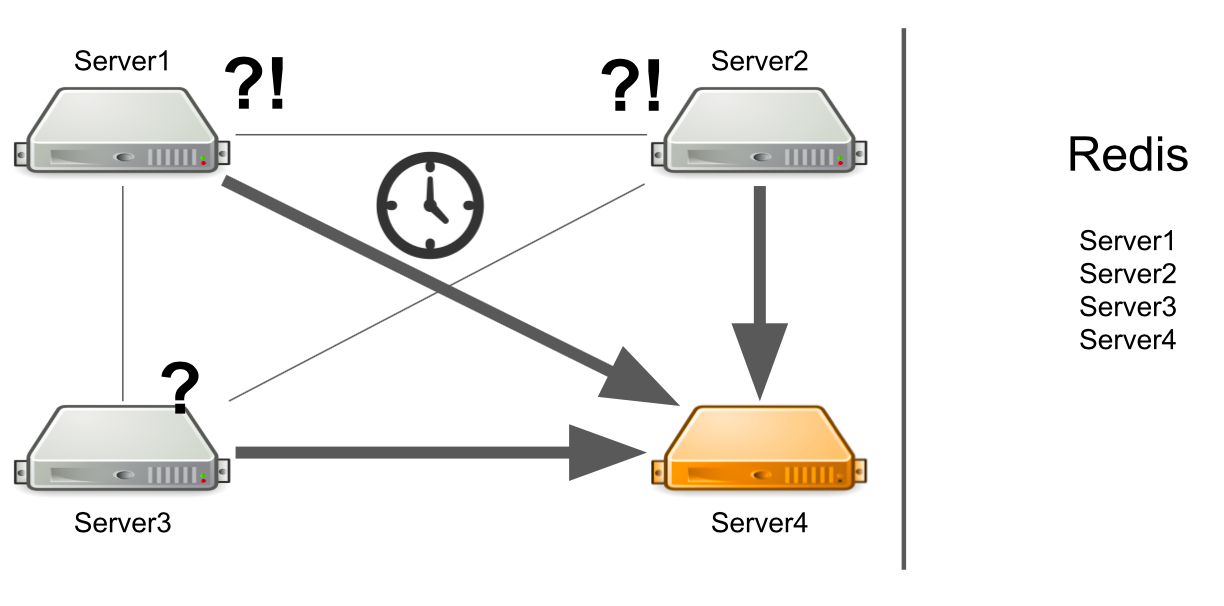
ما يجب القيام به يمكننا إضافة فحص حالة الخادم بشكل مستقل إلى النظام. أو يمكننا إعادة توجيه الرسائل من خوادم "مريضة" إلى خوادم "صحية". كل هذا سيستغرق الكثير من الوقت للمطورين. في عام 2012 ، كانت لدينا خبرة قليلة في هذا المجال ، لذلك بدأنا في البحث عن حلول جاهزة لجميع مشاكلنا في وقت واحد.
وسيط الرسائل. Activemq
قررنا التوجه في اتجاه وسيط الرسائل لتكوين الاتصال بين الخوادم بشكل صحيح. اختاروا ActiveMQ بسبب القدرة على تكوين تلقي الرسائل على المستهلك في وقت معين. صحيح أننا لم نغتنم هذه الفرصة أبدًا ، لذلك يمكننا اختيار RabbitMQ ، على سبيل المثال.
نتيجة لذلك ، قمنا بنقل نظام الكتلة بالكامل إلى ActiveMQ. ماذا أعطت:
- لم يعد الخادم يحدد لنفسه من يتم إرسال الرسالة ، لأن كل الرسائل تمر عبر قائمة الانتظار.
- تكوين خطأ التسامح. لقراءة قائمة الانتظار ، يمكنك تشغيل لا واحد ، ولكن عدة خوادم. حتى لو سقط أحدهم ، سيستمر النظام في العمل.
- ظهرت الخوادم أدوارًا ، مما سمح بتقسيم الخادم حسب نوع التحميل. على سبيل المثال ، يمكن لمصدر مورد الاتصال فقط بقائمة انتظار لقراءة الرسائل لتوليد الموارد ، ويمكن للخادم ذي اللوحات الاتصال بقائمة انتظار للوحات المفتوحة.
- هل قام RPC بالاتصال ، أي يحتوي كل خادم على قائمة انتظار خاصة به ، حيث ترسل الخوادم الأخرى الأحداث إليه.
- يمكنك إرسال رسائل إلى جميع الخوادم من خلال Topic ، والتي نستخدمها لإعادة تعيين الاشتراكات.
يبدو المخطط بسيطًا: جميع الخوادم متصلة بالوسيط ، وهي تدير التواصل بينهما. كل شيء يعمل ، يتم إرسال الرسائل وتلقيها ، يتم إنشاء الموارد. ولكن هناك مشاكل جديدة.
ماذا تفعل عندما تكذب جميع الخوادم الضرورية؟
لنفترض أن الخادم رقم 3 يريد إرسال رسالة لإنشاء موارد في قائمة انتظار. إنه يتوقع أن تتم معالجة رسالته. لكنه لا يعلم أنه لسبب ما لا يوجد مستلم واحد للرسالة. على سبيل المثال ، تعطل المستلمون بسبب خطأ.
طوال فترة الانتظار ، يرسل الخادم الكثير من الرسائل مع طلب ، ولهذا السبب تظهر قائمة انتظار الرسائل. لذلك ، عندما تظهر الخوادم العاملة ، فإنها تُجبر أولاً على معالجة قائمة الانتظار المتراكمة ، والتي تستغرق وقتًا. من جانب المستخدم ، يؤدي هذا إلى حقيقة أن الصورة التي تم تحميلها من قبله لا تظهر على الفور. إنه غير مستعد للانتظار ، لذلك يترك اللوحة.
ونتيجة لذلك ، فإننا ننفق سعة الخادم على توليد الموارد ، ولا يحتاج أي شخص إلى النتيجة.
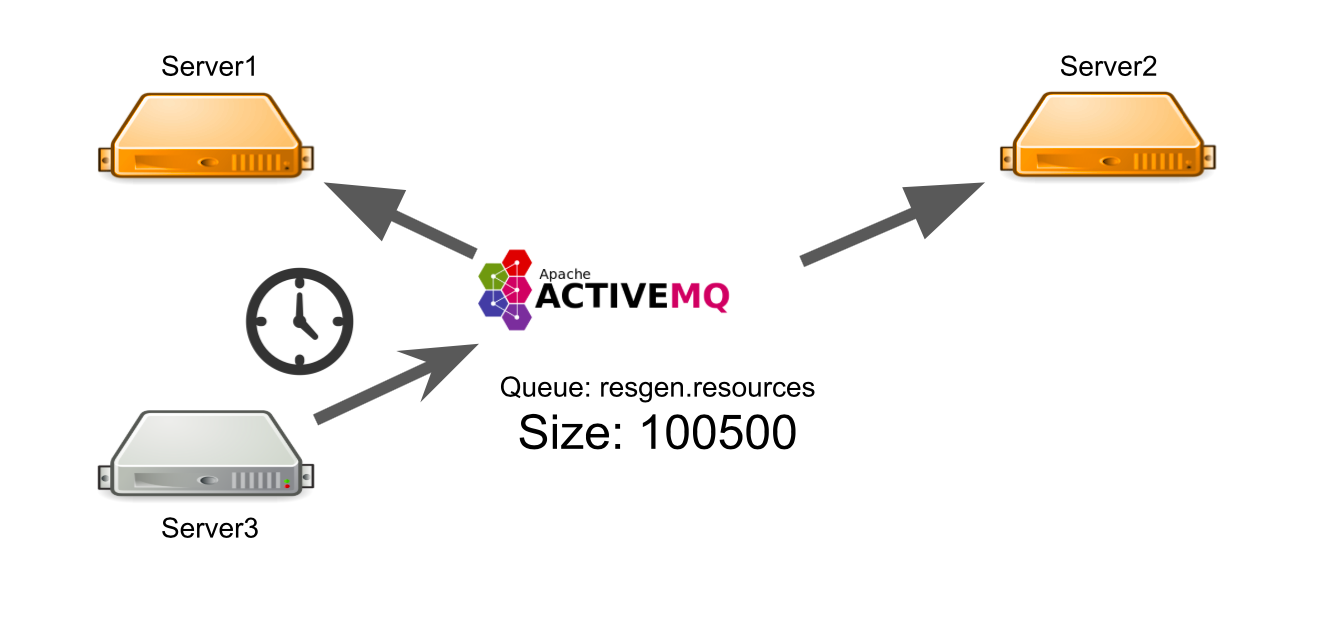
كيف يمكنني حل المشكلة؟ يمكننا إعداد المراقبة ، والتي ستعلمك بما يحدث. ولكن منذ اللحظة التي تبلغ فيها المراقبة عن شيء ما ، وحتى اللحظة التي نفهم فيها أن خوادمنا سيئة ، فإن الوقت سوف يمر. هذا لا يناسبنا.
خيار آخر هو تشغيل خدمة الاكتشاف ، أو سجل للخدمات التي تعرف الخوادم التي تعمل بها الأدوار. في هذه الحالة ، سوف نتلقى رسالة خطأ على الفور في حالة عدم وجود خوادم مجانية.
بعض الخدمات لا يمكن تحجيمها أفقيا
هذه مشكلة من التعليمات البرمجية المبكرة الخاصة بنا ، وليس ActiveMQ. دعني أريك مثالاً:
Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER);
لدينا خدمة للعمل مع حقوق المستخدم على اللوحة: يمكن أن يكون المستخدم هو مالك اللوحة أو محررها. يمكن أن يكون هناك مالك واحد فقط على السبورة. لنفترض أن لدينا سيناريو حيث نريد نقل ملكية لوحة من مستخدم إلى آخر. في السطر الأول ، نحصل على المالك الحالي للوحة ، وفي السطر الثاني - نأخذ المستخدم الذي كان المحرر ، ويصبح الآن المالك. علاوة على ذلك ، المالك الحالي نضع دور المحرر ، والمحرر السابق - دور المالك.
دعونا نرى كيف سيعمل هذا في بيئة متعددة الخيوط. عندما يقوم مؤشر الترابط الأول بتثبيت دور EDITOR ويحاول مؤشر الترابط الثاني أخذ المالك الحالي ، فقد يحدث أن المالك غير موجود ، ولكن هناك محرران.
والسبب هو عدم التزامن. يمكننا حل المشكلة عن طريق إضافة كتلة التزامن على السبورة.
synchronized (board) { Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER); }
لن يعمل هذا الحل في الكتلة. يمكن أن تساعدنا قاعدة بيانات SQL في ذلك بمساعدة المعاملات. ولكن لدينا Redis.
حل آخر هو إضافة الأقفال الموزعة إلى الكتلة بحيث تكون المزامنة داخل الكتلة بالكامل ، وليس خادم واحد فقط.
نقطة واحدة من الفشل عند دخول المجلس
نموذج التفاعل بين العميل والخادم هو حالة. لذلك يجب علينا تخزين حالة اللوحة على الخادم. لذلك ، قمنا بدور منفصل للخوادم - BoardServer ، الذي يعالج طلبات المستخدمين المتعلقة باللوحات.
تخيل أن لدينا ثلاثة من بورد سيرفر ، واحد منهم هو الرئيسي. يرسل المستخدم له طلب "افتح لي اللوحة ذات المعرف = 123" → يبحث الخادم في قاعدة البيانات الخاصة به عما إذا كانت اللوحة مفتوحة وأي خادم هو عليه. في هذا المثال ، اللوحة مفتوحة.
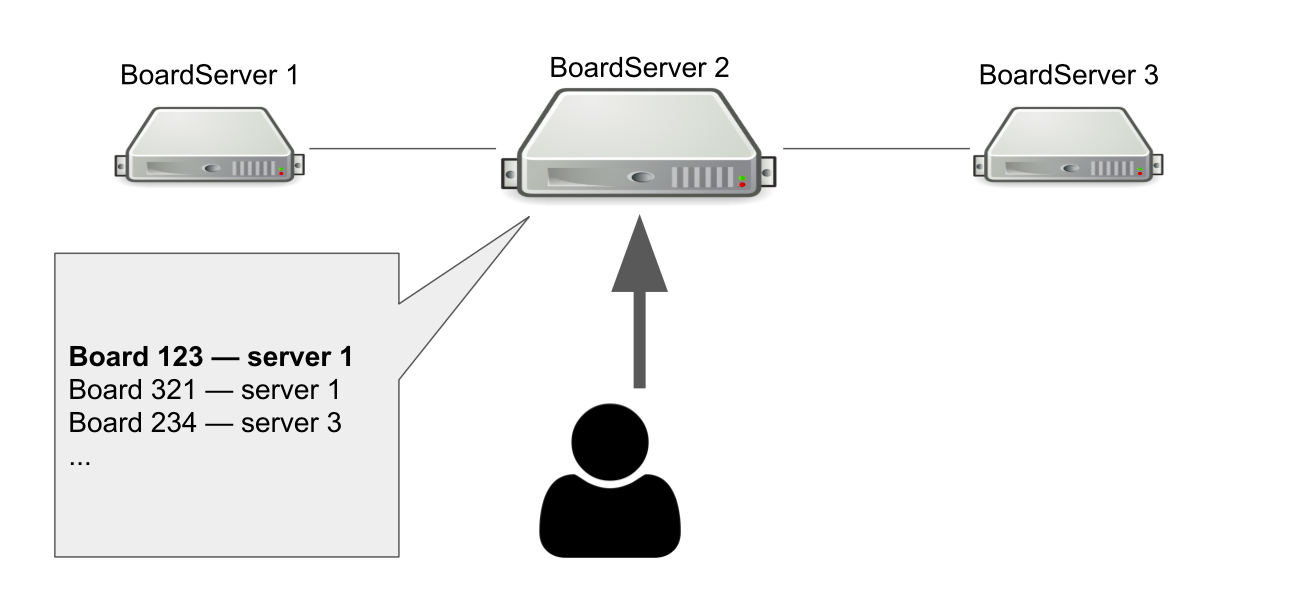
يرد الخادم الرئيسي الذي تحتاجه للاتصال بالخادم رقم 1 → الذي يتصل به المستخدم. من الواضح ، إذا توفي الخادم الرئيسي ، فلن يتمكن المستخدم من الوصول إلى لوحات جديدة بعد الآن.
إذن لماذا نحتاج إلى خادم يعرف أين المجالس مفتوحة؟ بحيث لدينا نقطة واحدة من القرار. إذا حدث شيء للخوادم ، فيجب أن نفهم ما إذا كانت اللوحة متوفرة فعليًا لإزالة اللوحة من السجل أو إعادة فتحها في مكان آخر. قد يكون من الممكن تنظيم ذلك بمساعدة النصاب القانوني ، عندما تحل عدة خوادم مشكلة مماثلة ، لكن في ذلك الوقت لم تكن لدينا المعرفة اللازمة لتنفيذ النصاب بشكل مستقل.
التبديل إلى Hazelcast
بطريقة أو بأخرى ، تعاملنا مع المشاكل التي نشأت ، لكنها قد لا تكون أجمل طريقة. نحن الآن بحاجة إلى فهم كيفية حلها بشكل صحيح ، لذلك قمنا بصياغة قائمة من المتطلبات لحل نظام المجموعة الجديد:
- نحتاج إلى شيء يراقب حالة جميع الخوادم وأدوارها. نسميها اكتشاف الخدمة.
- نحتاج إلى تأمين نظام المجموعة يساعد على ضمان الاتساق عند تنفيذ الاستعلامات الخطيرة.
- نحتاج إلى بنية بيانات موزعة تضمن أن اللوحات موجودة على خوادم معينة وإبلاغنا إذا حدث خطأ ما.
كان عام 2015. اخترنا Hazelcast - In-Memory Data Grid ، وهو نظام مجموعة لتخزين المعلومات في ذاكرة الوصول العشوائي. ثم اعتقدنا أننا وجدنا حلاً معجزة ، الكأس المقدسة لعالم التفاعل العنقودي ، إطار معجزة يمكنه فعل كل شيء ويجمع بين هياكل البيانات الموزعة ، الأقفال ، رسائل وقوائم RPC.
كما هو الحال مع ActiveMQ ، قمنا بنقل كل شيء تقريبًا إلى Hazelcast:
- توليد موارد المستخدم من خلال ExecutorService ؛
- قفل موزعة عند تغيير الحقوق ؛
- أدوار وسمات الخوادم (اكتشاف الخدمة) ؛
- سجل واحد للوحات مفتوحة ، إلخ.
طبولوجيا البندق
يمكن تكوين Hazelcast في اثنين من الطوبولوجيا. الخيار الأول هو Client-Server ، عندما يكون الأعضاء متواجدين بشكل منفصل عن التطبيق الرئيسي ، فإنهم يشكلون أنفسهم كتلة ، وتتصل جميع التطبيقات بهم كقاعدة بيانات.
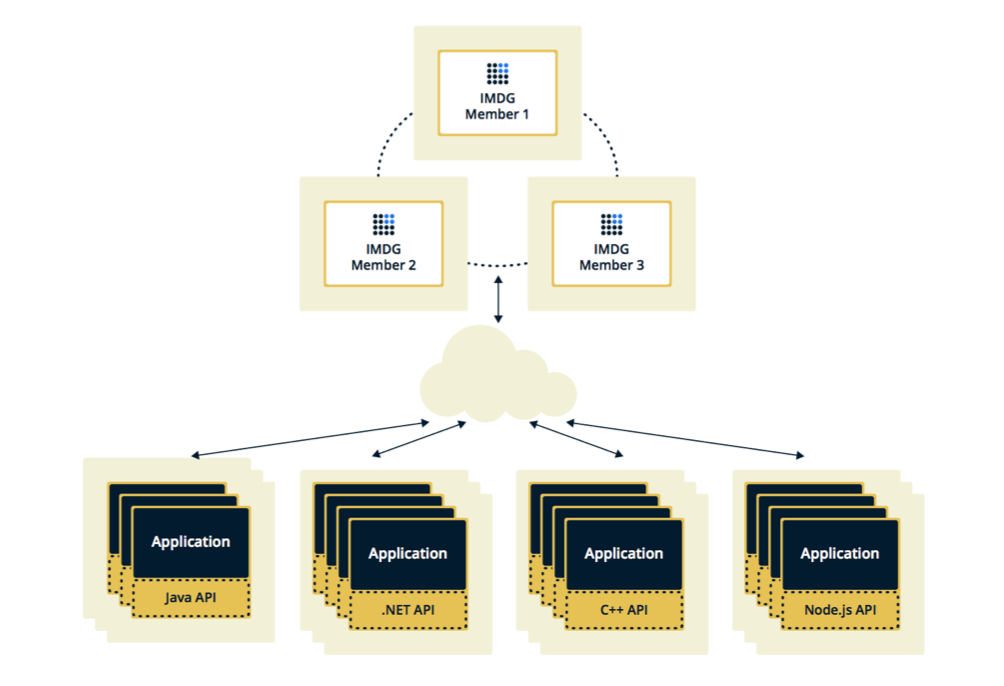
يتم تضمين الهيكل الثاني ، عندما يتم تضمين أعضاء Hazelcast في التطبيق نفسه. في هذه الحالة ، يمكننا استخدام عدد أقل من الحالات ، يكون الوصول إلى البيانات أسرع ، لأن البيانات ومنطق العمل نفسه في نفس المكان.
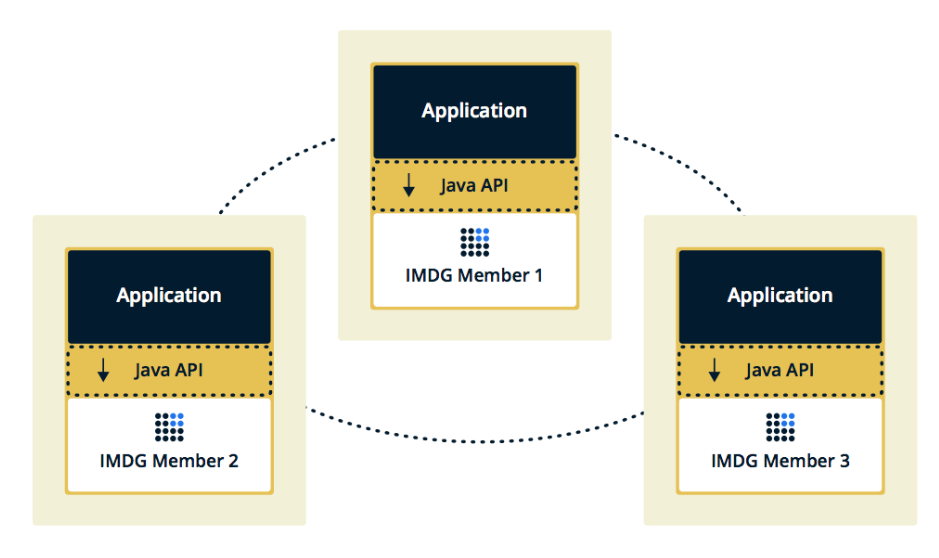
لقد اخترنا الحل الثاني لأننا اعتبرناه أكثر فاعلية واقتصادية للتنفيذ. فعال ، لأن سرعة الوصول إلى بيانات Hazelcast ستكون أقل ، لأن ربما هذه البيانات على الخادم الحالي. اقتصادية ، لأننا لسنا بحاجة إلى إنفاق الأموال على حالات إضافية.
توقف الكتلة عند توقف العضو
بعد أسبوعين من تشغيل Hazelcast ، ظهرت مشاكل على المنتج.
في البداية ، أظهرت المراقبة التي أجريناها أن أحد الخوادم بدأ في تحميل الذاكرة بشكل تدريجي. بينما كنا نشاهد هذا الخادم ، بدأت بقية الخوادم في التحميل أيضًا: نمت وحدة المعالجة المركزية ، ثم RAM ، وبعد كل خمس دقائق ، استخدمت جميع الخوادم جميع الذاكرة المتوفرة.
في هذه المرحلة في لوحات المفاتيح شاهدنا هذه الرسائل:
2015-07-15 15:35:51,466 [WARN] (cached18) com.hazelcast.spi.impl.operationservice.impl.Invocation: [my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7 2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService', op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783, waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0, tryCount=250, tryPauseMillis=500, invokeCount=1, callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
هنا ، يتحقق Hazelcast لمعرفة ما إذا كانت العملية التي تم إرسالها إلى خادم "الموت" الأول قيد التقدم. حاول Hazelcast مواكبة والتحقق من حالة العملية عدة مرات في الثانية الواحدة. ونتيجة لذلك ، قام ببريد مزعج جميع الخوادم الأخرى بهذه العملية ، وبعد بضع دقائق خرجت من الذاكرة ، وقمنا بجمع العديد من سجلات جيجابايت من كل منها.
تكرر الوضع عدة مرات. اتضح أن هذا خطأ في الإصدار 3.5 من Hazelcast ، حيث تم تنفيذ آلية نبضات القلب ، والتي تتحقق من حالة الطلبات. لم يتحقق من بعض الحالات الحدودية التي واجهناها. اضطررت إلى تحسين التطبيق حتى لا تقع في هذه الحالات ، وبعد بضعة أسابيع قام Hazelcast بإصلاح الخطأ في المنزل.
بشكل متكرر إضافة وإزالة أعضاء من Hazelcast
العدد التالي الذي اكتشفناه هو إضافة أعضاء من Hazelcast وإزالتهم.
أولاً ، سوف أصف بإيجاز كيف يعمل Hazelcast مع الأقسام. على سبيل المثال ، هناك أربعة خوادم ، ويقوم كل واحد بتخزين جزء من البيانات (في الشكل بألوان مختلفة). الوحدة هي القسم الأساسي ، والشرح هو القسم الثانوي ، أي نسخة احتياطية من القسم الرئيسي.

عند إيقاف تشغيل الخادم ، يتم إرسال الأقسام إلى خوادم أخرى. في حالة وفاة الخادم ، لا يتم نقل الأقسام منه ، ولكن من تلك الخوادم التي لا تزال حية وتحتفظ بنسخة احتياطية من هذه الأقسام.
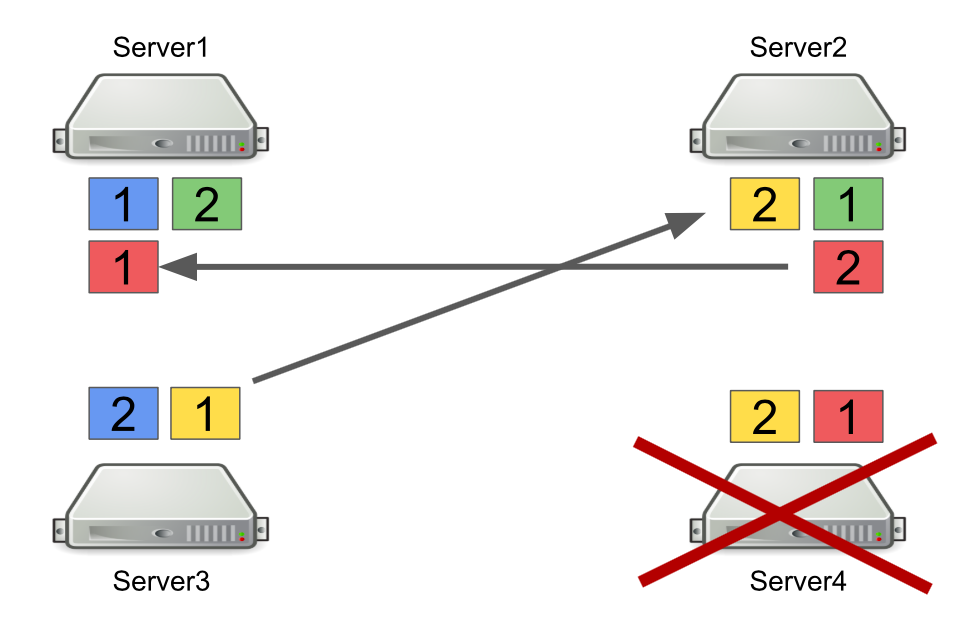
هذه هي آلية موثوقة. المشكلة هي أننا غالبًا ما نقوم بتشغيل وإيقاف الخوادم لموازنة التحميل ، كما أن أقسام إعادة التوازن تستغرق وقتًا أيضًا. وكلما زاد عدد الخوادم قيد التشغيل والمزيد من البيانات التي نقوم بتخزينها في Hazelcast ، زاد الوقت اللازم لإعادة توازن الأقسام.
بالطبع ، يمكننا تقليل عدد النسخ الاحتياطية ، أي أقسام الثانوية. لكن هذا ليس آمناً ، لأن شيئًا ما سيحدث بالتأكيد.
الحل الآخر هو التبديل إلى طبولوجيا Client-Server بحيث لا يؤثر تشغيل الخوادم وإيقاف تشغيلها على مجموعة Hazelcast الأساسية. لقد حاولنا القيام بذلك ، واتضح أن طلبات RPC لا يمكن تنفيذها على العملاء. دعنا نرى لماذا.
للقيام بذلك ، خذ بعين الاعتبار مثال إرسال طلب RPC واحد إلى خادم آخر. نحن نأخذ ExecutorService ، والذي يسمح لك بإرسال رسائل RPC ، ونقوم بالتقديم بمهمة جديدة.
hazelcastInstance .getExecutorService(...) .submit(new Task(), ...);
تبدو المهمة نفسها كفئة Java عادية تنفذ Callable.
public class Task implements Callable<Long> { @Override public Long call() { return 42; } }
المشكلة هي أن عملاء Hazelcast لا يمكن أن يكونوا فقط تطبيقات Java ، ولكن أيضًا تطبيقات C ++ و .NET وغيرها. بطبيعة الحال ، لا يمكننا إنشاء وتحويل فئة Java الخاصة بنا إلى نظام أساسي آخر.
يتمثل أحد الخيارات في التبديل إلى استخدام طلبات http في حال أردنا إرسال شيء من خادم إلى آخر والحصول على إجابة. ولكن بعد ذلك سيتعين علينا التخلي جزئياً عن البندق.
لذلك ، كحل ، اخترنا استخدام قوائم الانتظار بدلاً من ExecutorService. للقيام بذلك ، طبقنا بشكل مستقل آلية لانتظار تنفيذ عنصر في قائمة الانتظار ، والذي يعالج حالات الحدود ويعيد النتيجة إلى الخادم الطالب.
ماذا تعلمنا
وضع المرونة في النظام. المستقبل يتغير باستمرار ، لذلك لا توجد حلول مثالية. للقيام بذلك بشكل صحيح ، لا يعمل "اليمين" ، ولكن يمكنك محاولة أن تكون مرناً وتضعه في النظام. هذا سمح لنا بتأجيل القرارات المعمارية المهمة حتى اللحظة التي لم يعد من المستحيل قبولها.
روبرت مارتن في الهندسة النظيفة يكتب عن هذا المبدأ:
"هدف المهندس هو إنشاء نموذج للنظام يجعل السياسة أهم عنصر ، والتفاصيل غير المتعلقة بالسياسة. سيؤخر هذا ويؤخر اتخاذ القرارات بشأن التفاصيل. "
الأدوات والحلول العالمية غير موجودة. إذا بدا لك أن هناك إطار عمل يحل جميع مشاكلك ، فمن المرجح أن هذا ليس كذلك. لذلك ، عند تنفيذ أي إطار ، من المهم أن نفهم ليس فقط المشكلات التي ستحلها ، بل وأيضًا المشاكل التي ستجلبها.
لا تعيد كتابة كل شيء على الفور. إذا كنت تواجه مشكلة في الهندسة المعمارية ويبدو أن الحل الصحيح الوحيد هو كتابة كل شيء من نقطة الصفر ، انتظر. إذا كانت المشكلة خطيرة حقًا ، فابحث عن حل سريع وشاهد كيف سيعمل النظام في المستقبل. على الأرجح ، لن تكون هذه هي المشكلة الوحيدة في الهندسة المعمارية ، مع مرور الوقت ستجد المزيد. وفقط عند اختيار عدد كافٍ من مناطق المشكلات ، يمكنك البدء في إعادة بيع المباني. فقط في هذه الحالة سيكون هناك مزايا أكثر من قيمتها.