مرحباً هبر.
بعد نشر تصنيف المقالات لعامي
2017 و
2018 ، كانت الفكرة التالية واضحة - جمع تصنيف عام لجميع السنوات. ولكن مجرد جمع الروابط سيكون مبتذلاً (على الرغم من أنه مفيد أيضًا) ، لذلك تقرر توسيع معالجة البيانات وجمع بعض المعلومات المفيدة.

التقييمات والإحصاءات وقليل من شفرة المصدر في بيثون تحت القط.
معالجة البيانات
يمكن لأولئك المهتمين بالنتائج على الفور تخطي هذا الفصل. في هذه الأثناء ، سنكتشف كيف يعمل.
كما البيانات المصدر ، هناك ملف CSV من النوع التالي تقريبا:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
يستغرق فهرس جميع المقالات في هذا النموذج 42 ميغابايت ، ولجمعه استغرق حوالي 10 أيام لتشغيل البرنامج النصي على Raspberry Pi (تم التنزيل في دفق واحد مع توقف مؤقتًا حتى لا يثقل كاهل الخادم). الآن دعونا نرى ما هي البيانات التي يمكن استخراجها من كل هذا.
جمهور الموقع
لنبدأ بحديث بسيط نسبيًا - سنقوم بتقييم جمهور الموقع طوال السنوات. لتقدير تقريبي ، يمكنك استخدام عدد التعليقات على المقالات. قم بتنزيل البيانات وعرض رسم بياني لعدد التعليقات.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
البيانات تبدو شيء مثل هذا:

النتيجة مثيرة للاهتمام - اتضح أنه منذ عام 2009 ، لم ينمو الجمهور النشط للموقع (أولئك الذين يتركون تعليقات على المقالات). على الرغم من أن جميع موظفي تكنولوجيا المعلومات هم فقط هنا؟
بما أننا نتحدث عن الجمهور ، فمن المثير للاهتمام أن نتذكر أحدث ابتكارات هبر - إضافة نسخة باللغة الإنجليزية من الموقع. ادرج المقالات مع "/ en /" داخل الرابط.
df = df[df['link'].str.contains("/en/")]
والنتيجة مثيرة للاهتمام أيضًا (المقياس العمودي يتم تركه كما هو):

بدأت الزيادة في عدد المنشورات في 15 يناير 2019 ، عندما أعلن
مرحبا العالم! أو هابر باللغة الإنجليزية ، قبل عدة أشهر من نشر هذه المقالات الثلاثة:
1 و
2 و
3 . ربما كان اختبار بيتا؟
معرفات
النقطة المهمة التالية ، والتي لم نتطرق إليها في الأجزاء السابقة ، هي مقارنة معرفات المقالات وتواريخ النشر. تحتوي كل مقالة على رابط من النوع
habr.com/en/post/N ، وترقيم المقالات من النهاية إلى النهاية ، والمقال الأول له المعرف 1 ، والمقال الذي تقرأه هو 441740. يبدو أن كل شيء بسيط. لكن ليس حقا. تحقق من مراسلات التواريخ والمعرفات.
قم بتحميل الملف إلى Pandas Dataframe ، وحدد التواريخ والمعرف ، ورسمها:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
والنتيجة مفاجئة - فالمعرفات لا تؤخذ دائمًا في صف واحد ، كما هو مفترض أصلاً ، هناك "حدود" ملحوظة.
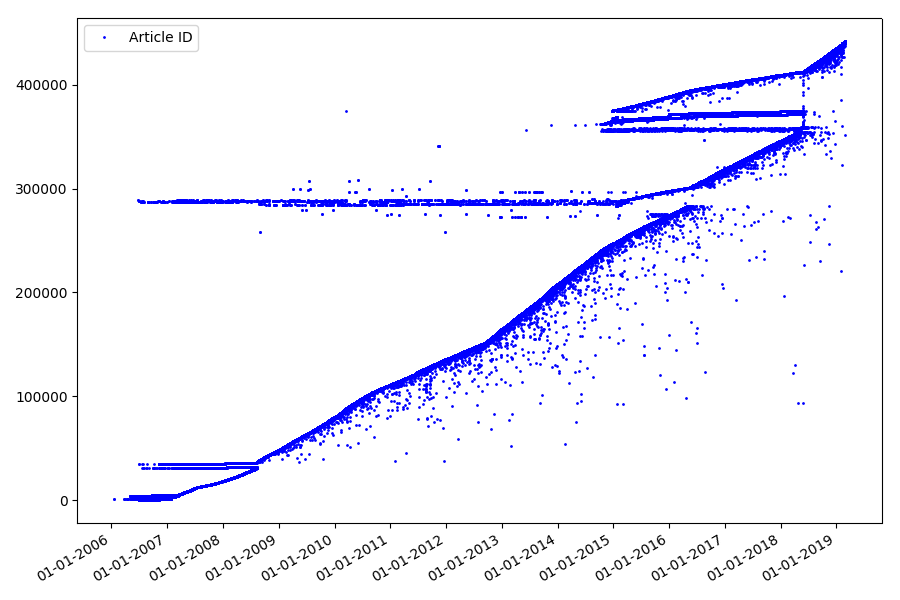
بسببهم جزئياً ، كان لدى الجمهور أسئلة حول التصنيفات لعامي 2017 و 2018 - لم يؤخذ المحلل في الاعتبار مثل هذه المقالات ذات المعرف "الخطأ". لماذا من الصعب جدا القول ، وليس مهم جدا.
ما يمكن أن تكون مثيرة للاهتمام حول معرفات؟ هناك فرضية لا يمكنني إثباتها رسميًا ، لكن يبدو ذلك واضحًا. يتم تعيين معرف وقت كتابة مسودة المقالة ، ومن الواضح أن تاريخ النشر سيأتي لاحقًا. يقوم شخص ما بنشر المقال في نفس اليوم ، ويقوم شخص ما بنشر المادة في وقت لاحق. لماذا كل هذا؟ دعنا نضع المعرفات على المحور X ، والتواريخ عموديًا ، ونرى جزءًا من الرسم البياني بمزيد من التفاصيل:
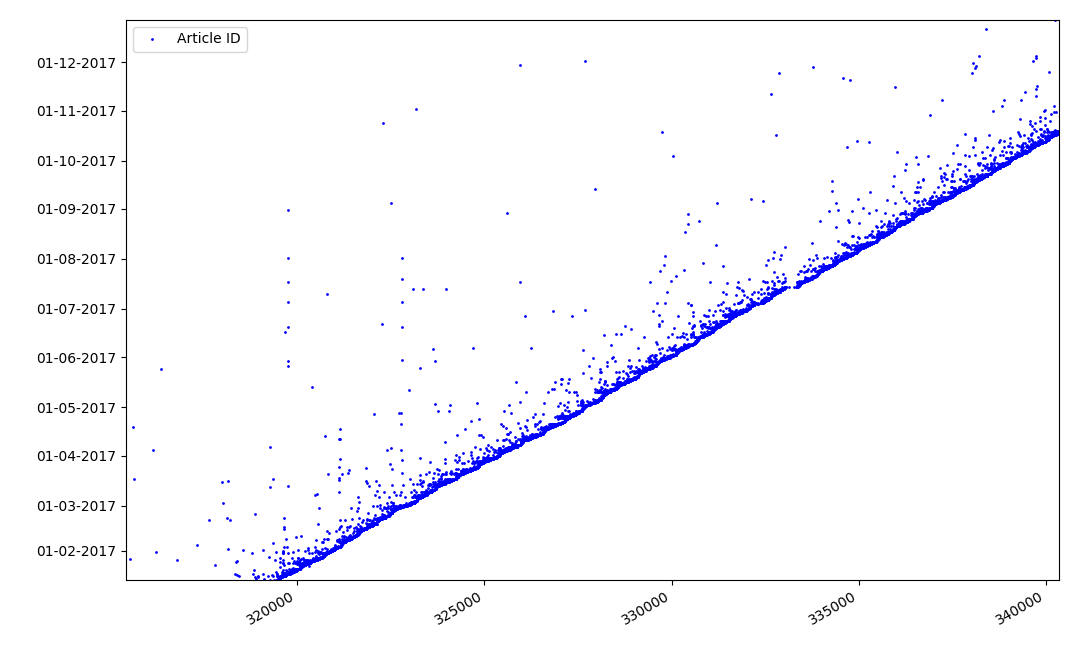
النتيجة - نرى سحابة من النقاط فوق الخط الصلب ، والتي توضح لنا توزيع الوقت
طوال مدة إنشاء المقالات . كما ترون ، الحد الأقصى يقع على الفاصل الزمني ما يصل إلى 1-2 أسابيع. يتم إنشاء معظم المقالات تقريبًا في مدة لا تزيد عن شهر واحد ، على الرغم من أن بعض المقالات يتم نشرها بعد بضعة أشهر من إنشاء المسودة (بالطبع ، هذا لا يضمن لنا أن المؤلف قد عمل على المقال لعدة أشهر يوميًا ، ولكن النتيجة لا تزال مثيرة للاهتمام للغاية).
تاريخ ووقت النشر
النقطة المثيرة للاهتمام ، وإن كانت بديهية ، هي وقت نشر المقالات.
إحصائيات المخرجات في أيام العمل:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
اعتماد عدد المقالات على وقت النشر في أيام الأسبوع:
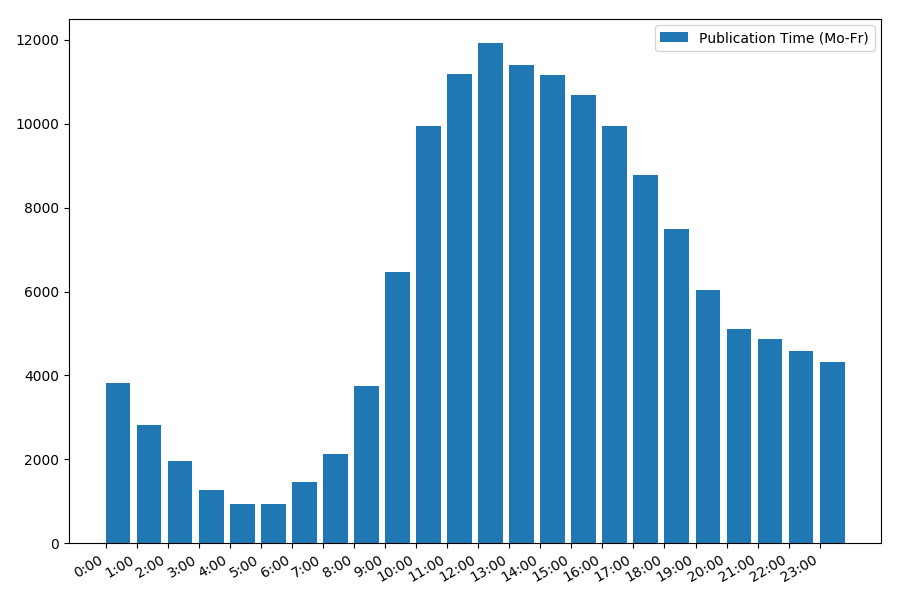
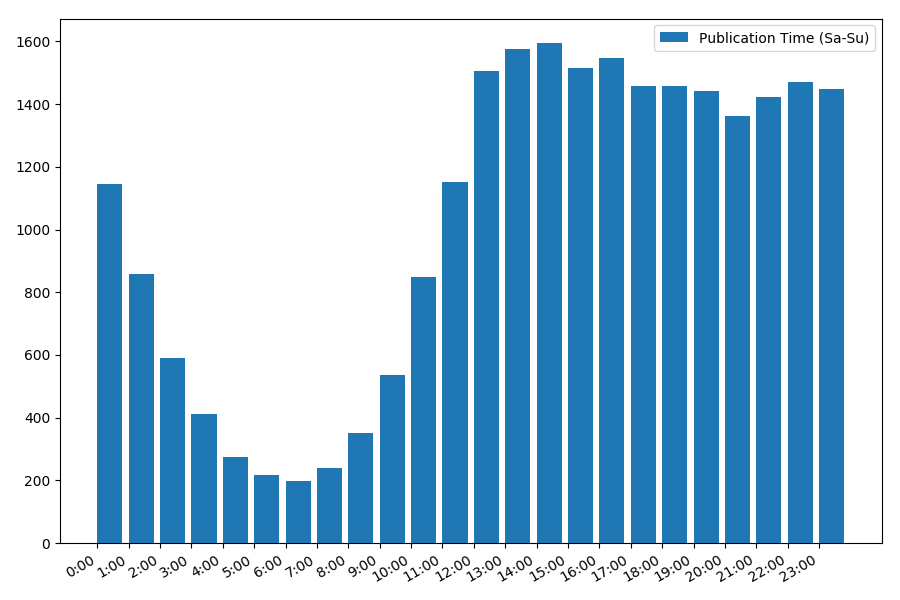
الصورة مثيرة للاهتمام ، معظم المنشورات تقع على ساعات العمل. لا تزال مثيرة للاهتمام ، بالنسبة لمعظم المؤلفين كتابة المقالات هي الوظيفة الرئيسية ، أم أنهم يفعلون ذلك فقط خلال ساعات العمل؟ ؛) لكن جدول التوزيع في عطلة نهاية الأسبوع يعطي صورة مختلفة:
نظرًا لأننا نتحدث عن التاريخ والوقت ، فلنرى متوسط قيمة المشاهدات وعدد المقالات حسب يوم الأسبوع.
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
النتيجة مثيرة للاهتمام:
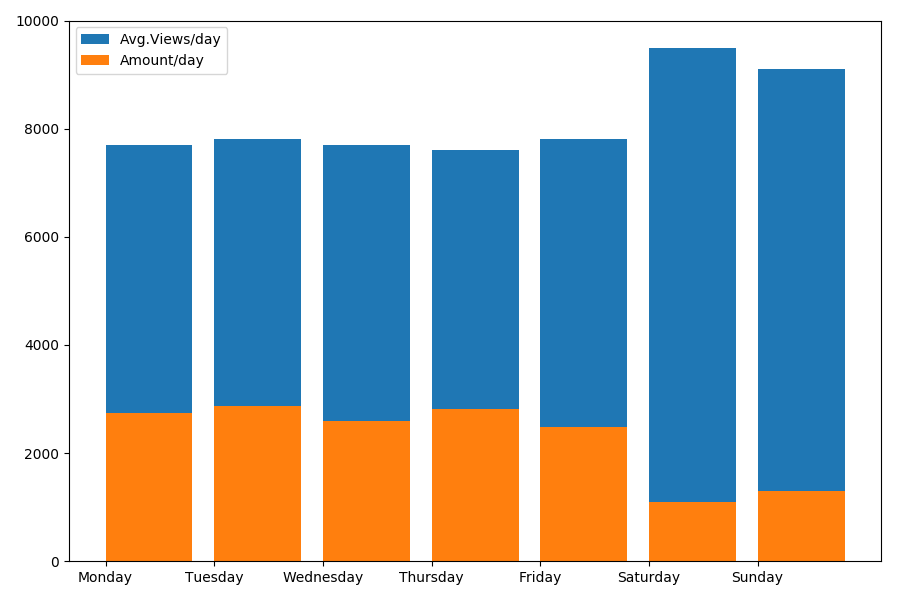
كما ترون ، يتم نشر عدد أقل بشكل ملحوظ من المقالات في عطلة نهاية الأسبوع. ولكن بعد ذلك ، تكتسب كل مقالة مزيدًا من المشاهدات ، لذا يبدو أن نشر المقالات في عطلة نهاية الأسبوع أمر مستحسن للغاية (كما هو موضح في
الجزء الأول ، لا تزيد مدة الحياة النشطة للمقال عن 3-4 أيام ، لذلك فإن أول يومين لهما أهمية بالغة).
ربما تكون المقالة طويلة جدًا. النهاية في
الجزء الثاني .