
سوف أشارك قصة حول مشروع صغير: كيفية العثور على إجابات المؤلف في التعليقات دون معرفة من هو صاحب المنشور.
لقد بدأت مشروعي بأقل قدر من المعرفة بالتعلم الآلي وأعتقد أنه لن يكون هناك شيء جديد للمتخصصين هنا. هذه المادة ، إلى حد ما ، عبارة عن مجموعة من المقالات المختلفة ، وفيها سأخبرك كيف اقتربت من المهمة ، في الكود يمكنك أن تجد أشياء وحيل صغيرة مفيدة في معالجة اللغة الطبيعية.
كانت بياناتي الأولية كما يلي: قاعدة بيانات تحتوي على 2.5 مليون مادة وسائط و 39.5 مليون تعليق عليها. بالنسبة إلى منشورات 1M ، بطريقة أو بأخرى ، كان مؤلف المادة معروفًا (هذه المعلومات إما كانت موجودة في قاعدة البيانات أو تم الحصول عليها عن طريق تحليل البيانات لأسباب غير مباشرة). على هذا الأساس ، تم إنشاء مجموعة بيانات من سجلات 215K تم ترميزها.
في البداية ، كنت أستخدم مقاربة إرشادية تستند إلى الذكاء الطبيعي وترجمت إلى استعلامات SQL مع البحث عن نص كامل أو تعبيرات منتظمة. أبسط أمثلة على النص المراد تحليله: "شكرًا لك على التعليق" أو "شكرًا لك على التقييم الجيد" ، هذا هو المؤلف في 99.99٪ من الحالات ، و "شكرًا لك على العمل" أو "شكرًا لك!" إرسال المواد عن طريق البريد. شكرا لك! - مراجعة عادية. مع مثل هذا النهج ، يمكن تصفية المصادفات الواضحة فقط ، باستثناء حالات الأخطاء المطبعية العادية أو عندما يكون المؤلف في حوار مع المعلقين. لذلك ، فقد تقرر استخدام الشبكات العصبية ، جاءت هذه الفكرة ليس من دون مساعدة من صديق.
تسلسل نموذجي للتعليقات ، أي منهم هو المؤلف؟
طريقة تحديد درجة اللونية للنص تم اتخاذها كأساس ، والمهمة بسيطة بالنسبة لنا في فئتين: المؤلف وليس المؤلف. لتدريب الموديلات ، استخدمت
خدمة من Google توفر أجهزة افتراضية مزودة بوحدة معالجة رسومات (GPU) وواجهة كوكب المشتري.
أمثلة على الشبكات الموجودة على الإنترنت:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
على الخطوط التي تم مسحها من علامات html والأحرف الخاصة ، أعطوا حوالي 65-74٪ من الدقة ، والتي لم تختلف كثيرًا عن رمي العملة المعدنية.
هناك نقطة مهمة تتمثل في أن محاذاة تسلسل الإدخال من خلال
pad_sequences(x_train, maxlen=max_len, padding='pre') أعطت فرقًا كبيرًا في النتائج. في حالتي ، كانت أفضل نتيجة هي الحشو = "مشاركة".
والخطوة التالية هي استخدام الليمون ، الذي أعطى على الفور زيادة في الدقة تصل إلى 80 ٪ ، وهذا يمكن أن تعمل على مزيد من. الآن المشكلة الرئيسية هي المقاصة الصحيحة للنص. على سبيل المثال ، تم تحويل الأخطاء المطبعية في كلمة "Thank you" (تم اختيار الأخطاء المطبعية حسب عدد مرات الاستخدام) إلى تعبير عادي (تراكمت هذه التعبيرات من نصف إلى عشرين).
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
هنا ، أود أن أعرب عن شكر خاص للأشخاص المهذبين بشكل مفرط الذين يرون أنه من الضروري إضافة هذه الكلمة إلى كل جملة من الجمل.
كان من الضروري تخفيض نسبة الأخطاء المطبعية ، لأن عند الخروج من lemmatizer يعطون كلمات غريبة ونفقد المعلومات المفيدة.
ولكن هناك بطانة فضية ، لقد سئمنا من التعامل مع الأخطاء المطبعية ، والتعامل مع تنظيف النصوص المعقدة ، واستخدمت التمثيل المتجه للكلمات - word2vec. الطريقة المسموح بها لترجمة جميع الأخطاء المطبعية والأخطاء المطبعية والمرادفات إلى متجهات متباعدة عن كثب.

الكلمات وعلاقاتها في الفضاء المتجه.
تم تبسيط قواعد التنظيف بشكل كبير (آها ، رواة القصص) ، تم تقسيم جميع الرسائل وأسماء المستخدمين إلى جمل وتحميلها إلى ملف. نقطة مهمة: نظرًا لاختصار المعلقين لدينا ، من أجل بناء متجهات عالية الجودة ، تحتاج الكلمات إلى معلومات سياقية إضافية ، على سبيل المثال ، من المنتدى ويكيبيديا. تم تدريب ثلاثة نماذج على الملف الناتج: word2vec الكلاسيكي ، Glove و FastText. بعد العديد من التجارب ، استقر أخيرًا على FastText ، باعتباره مجموعات الكلمات الأكثر تمييزًا نوعيًا في حالتي.
جلبت كل هذه التغييرات دقة مستقرة 84-85 في المئة.
أمثلة نموذجية def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
و 6 المزيد من النماذج في
التعليمات البرمجية . بعض النماذج مأخوذة من الشبكة ، ويتم اختراع بعضها بشكل مستقل.
وقد لوحظ أن التعليقات المختلفة تبرز على نماذج مختلفة ، مما دفع فكرة استخدام مجموعات النماذج. أولاً ، جمعت المجموعة يدويًا ، واخترت أفضل أزواج من الطرز ، ثم صنعت مولدًا. من أجل تحسين البحث الشامل ، أخذت الرمز الرمادي كأساس.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
مع المجموعة "أصبحت الحياة أكثر متعة" والنسبة المئوية الحالية من دقة النموذج في مستوى 86-87 ٪ ، ويرتبط ذلك أساسا مع تصنيف نوعية رديئة من بعض المؤلفين في مجموعة البيانات.

المشاكل التي قابلتها:
- مجموعة بيانات غير متوازنة. كان عدد تعليقات المؤلفين أقل بكثير من المعلقين الآخرين.
- الطبقات في العينة تذهب في ترتيب صارم. خلاصة القول هي أن البداية والمتوسطة والنهاية تختلف اختلافًا كبيرًا في جودة التصنيف. هذا واضح للعيان في عملية التعلم على جدول التدبير f1.
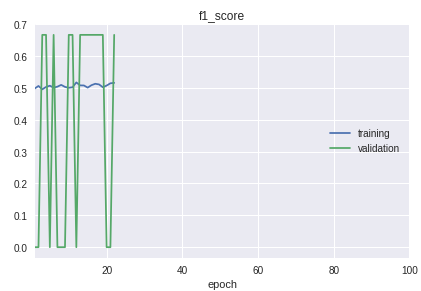
بالنسبة للحل ، تم تصنيع دراجة للفصل بين عينات التدريب والتحقق من الصحة. على الرغم من أنه في الممارسة العملية ، يكفي إجراء train_test_split من مكتبة sklearn.
الرسم البياني لنموذج العمل الحالي:

نتيجة لذلك ، حصلت على نموذج له تعريف واثق للمؤلفين من التعليقات القصيرة. سيتم ربط المزيد من التحسين بتنظيف ونقل نتائج تصنيف البيانات الحقيقية إلى مجموعة البيانات التدريبية.
كل الشفرة مع تفسيرات إضافية موجودة في
المستودع .
كتذييل: إذا كنت بحاجة إلى تصنيف كميات كبيرة من النص ،
فقم بإلقاء نظرة على نموذج
VDCNN "الشبكة العصبية
التوافيقية العميقة جدًا" (
تطبيق على keras) ، وهذا هو تناظر ResNet للنصوص.
المواد المستخدمة:
•
نظرة عامة على دورات التعلم الآلي•
تحليل الإلتواء باستخدام الإلتواء•
الشبكات التلافيفية في البرمجة اللغوية العصبية•
المقاييس في التعلم الآليhttps://ld86.imtqy.com/ml-slides/unbalanced.html•
نظرة داخل النموذج