
حتى الآن ، يمكن لأي طالب درس في الشبكات العصبية أن يتعرف على الشخصيات الكورية. أعطه عينة وجهاز كمبيوتر مع بطاقة فيديو ، وبعد فترة من الوقت سوف يجلب لك شبكة تتعرف على الأحرف الكورية دون أخطاء تقريبًا.
ولكن مثل هذا الحل سيكون له عيوب عديدة:
أولاً ، هناك عدد كبير من العمليات الحسابية الضرورية ، والتي تؤثر على وقت التشغيل أو الطاقة المطلوبة (وهي مهمة جدًا للأجهزة المحمولة). في الواقع ، إذا كنا نريد التعرف على 3000 حرف على الأقل ، فسيكون هذا هو حجم الطبقة الأخيرة من الشبكة. وإذا كان إدخال هذه الطبقة هو 512 على الأقل ، فسنحصل على 512 * 3000 مضاعفات. كثير جدا
ثانيا ، الحجم. ستزن نفس الطبقة الأخيرة من المثال السابق 512 * 3001 * 4 بايت ، أي حوالي 6 ميجابايت. هذه طبقة واحدة فقط ، ستزن الشبكة بالكامل عشرات الميجابايت. من الواضح أن هذه ليست مشكلة كبيرة لجهاز كمبيوتر سطح المكتب ، ولكن لن يكون الجميع على استعداد لتخزين الكثير من البيانات على الهاتف الذكي للتعرف على لغة واحدة.
ثالثًا ، ستوفر مثل هذه الشبكة نتائج غير متوقعة على الصور التي ليست أحرفًا كورية ، ولكنها تُستخدم مع ذلك في النصوص الكورية. في الظروف المختبرية ، هذا ليس بالأمر الصعب ، ولكن بالنسبة للتطبيق العملي للتكنولوجيا ، يجب حل هذه المشكلة بطريقة أو بأخرى.
ورابعا ، المشكلة هي عدد الأحرف: 3000 على الأرجح كافية ، على سبيل المثال ، لتمييز شريحة لحم من خيار البحر المقلي في قائمة المطعم ، ولكن في بعض الأحيان هناك نصوص أكثر تعقيدا. سيكون من الصعب تدريب الشبكة على عدد أكبر من الشخصيات: لن يكون الأمر أبطأ فحسب ، بل ستكون هناك أيضًا مشكلة في جمع عينة التدريب ، نظرًا لأن عدد الأحرف يتناقص بشكل كبير. بالطبع ، يمكنك الحصول على صور من الخطوط وزيادةها ، لكن هذا لا يكفي لتدريب شبكة جيدة.
واليوم سوف أخبرك كيف تمكنا من حل هذه المشاكل.
كيف تعمل الكتابة الكورية؟
الكتابة الكورية ، الهانغول ، عبارة عن تقاطع بين الكتابة الصينية والأوروبية. في الخارج ، هذه هي أحرف مربعة تشبه الحروف الهيروغليفية ، وفي صفحة واحدة من النص يمكنك حساب أكثر من مائة حرف فريد. من ناحية أخرى ، إنها الكتابة الصوتية ، أي ، بناءً على تسجيل الأصوات. هناك أبجدية تحتوي على 24 حرفًا (بالإضافة إلى أنه يمكنك إضافة عدد من المطبوعات والدفث). ولكن ، على عكس الأبجدية اللاتينية أو السيريلية ، لا تتم كتابة الأصوات في سطر ، ولكن يتم دمجها في مجموعات. على سبيل المثال ، إذا كتبنا بنفس الطريقة ، فيمكن كتابة عبارة "Hello، Habr" في ثلاث كتل مثل هذه:
يمكن أن تتكون كل كتلة من حرفين أو ثلاثة أو أربعة أحرف. في هذه الحالة ، يأتي الحرف الساكن دائمًا أولاً ، ثم حرفًا واحدًا أو حرفين ، وفي النهاية يمكن أن يكون هناك حرف ساكن آخر. هناك عدة طرق مختلفة لدمج الحروف في كتل ، أي في كتل مختلفة ، الحرف الثاني ، على سبيل المثال ، سوف يقف في أماكن مختلفة.
تُظهر الصورة أدناه كتلتين تشكلان معًا كلمة "هانغول". يشار إلى الحرف الأول من كل كتلة باللون الأحمر ، يتم تمييز حروف العلة باللون الأزرق ، ويتم تمييز الحرف الأخير باللون الأخضر.
مصدر الصورة: ويكيبيديا.تعديل كتلة الهانغول
وهذا يعني أنه يمكن وصف كتلة Hangul واحدة بالصيغة: Ci V [V] [Cf] ، حيث Ci هي الحرف الساكن الأولي (ربما مزدوج) ، V هي حرف العلة ، و Cf هي الحرف الساطع الأخير (يمكن أن يكون أيضًا مزدوجًا). مثل هذا التمثيل غير مريح للاعتراف به ، لذلك نغيره.
أولا ، الجمع بين كل من حروف العلة. نحصل على الصيغة Ci V '[Cf] ، حيث V' - جميع الخيارات الممكنة لدمج الحروف ، مع مراعاة عدم وجود الحرف الثاني. نظرًا لوجود 10 أحرف العلة في اللغة ، يتوقع المرء أنه نتيجة لذلك لدينا 10 * (10 + 1) خيارات ، ولكن في الممارسة العملية ليست كلها ممكنة ، يتم الحصول على 21 فقط.
علاوة على ذلك ، قد لا تكون الرسالة الأخيرة. أضف إلى العديد من الحروف المتوقعة في النهاية واحدة فارغة. ثم نحصل على الصيغة Ci V 'Cf *. وهكذا ، اتضح الآن أن الرمز الكوري يتكون دائمًا من ثلاثة "أحرف". يمكنك معرفة الشبكة.
نحن نبني شبكة
الفكرة هي أنه بدلاً من التعرف على الشخصية بأكملها ، سوف نتعرف على الأحرف الفردية فيها. وبالتالي ، بدلاً من واحد softmax ضخم في النهاية ، نحصل على ثلاثة رؤوس صغيرة ، حجم كل منها بضع عشرات. أنها تتوافق مع "الحروف" الأولى والثانية والثالثة في مقطع لفظي. نتيجة لذلك ، حصلنا على البنية التالية:
الصورة القابلة للنقر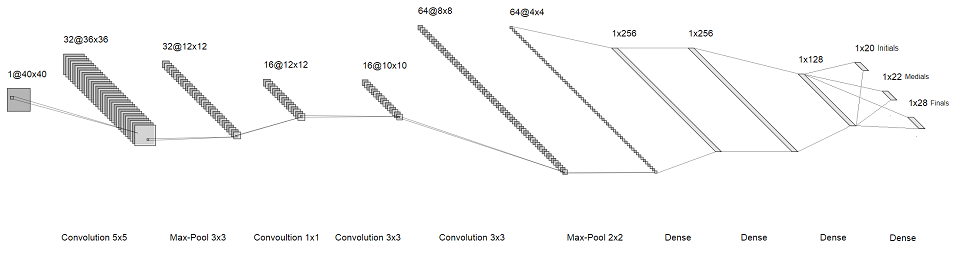
نحن ندرب ونعمل على عينة منفصلة. الجودة جيدة ، الشبكة سريعة ، وتزن قليلاً. دعونا نحاول إخراجها من المختبر إلى العالم الحقيقي.
نحن نحل المشاكل
سنواجه المشكلة الأولى على الفور: في بعض الأحيان تدخل الصور التي ليست أحرف كورية على الإطلاق في المدخلات ، وتتصرف الشبكة عليها بشكل غير متوقع. يمكنك بالطبع تدريب شبكة أخرى تميز الكتل الكورية عن أي شيء آخر ، لكننا سنجعلها أسهل.
دعونا نفعل الشيء نفسه الذي فعلناه مع المجموعة الثالثة من الحروف: إضافة إخراج لعدم وجود خطاب. ستبدو صيغة الرمز هكذا: Ci * V '* Cf *. وفي مجموعة التدريب ، سنضيف جميع أنواع القمامة - الأحرف الصينية ، الأحرف غير الصحيحة ، الحروف الأوروبية ، وسنعمل على تعليم الشبكة لتمييز ثلاثة أحرف فارغة عليها.
نحن ندرب ، اختبار. إنه يعمل ، لكن المشاكل لا تزال قائمة. اتضح أنه في كثير من الأحيان ، على سبيل المثال ، تقع هذه الصور في الشبكة:
هذه هي الكتلة الكورية الصحيحة التي تم تعليق سعر واحد عليها. ومن الواضح أن الشبكة تعثر عليهم تمامًا على الحروف الثلاثة التي تتكون منها الكتلة. هذه مجرد صورة غير صحيحة ، ونحن بحاجة إلى الإشارة إليها. من الخطأ إعادة الحروف الفارغة هنا ، كما هي في الصورة. دعونا نحاول تطبيق ما أثبت بالفعل أنه جيد: إضافة نتيجتين أخريين للتعرف على علامات الترقيم اللزجة هذه. في كل منها ، سيكون هناك ناتج إضافي واحد لموقف لا يوجد فيه شيء غير ضروري في الصورة ، ولكن بالإضافة إلى ذلك ، من الضروري إضافة إخراج واحد إضافي للوضع "هناك علامة ترقيم ، ولكن لم يتم التعرف عليها ، وربما القمامة."
المدربين من السيء في مثل هذه الشبكة التعرف على علامات الترقيم: فهي تميز فاصلة من قوس ، لكنها بالفعل صعبة من نقطة ما. يمكنك زيادة تعقيد الشبكة ، ولكن لا تريد ذلك. سنتعامل مع التعرف على علامات الترقيم في وقت لاحق ، ولكن في الوقت الحالي ، سنعطي ببساطة ما إذا كان هناك شيء ما أم لا. هذه الشبكة تعلمت جيدا.
لقد اكتشفنا علامات الترقيم الملصقة ، لكن ماذا لو ، على العكس من ذلك ، جزء من المفتاح مفقود في الصورة؟ كانت هناك كلمة من حرفين ، لكننا قمنا بتقسيمها إلى أحرف بشكل غير صحيح:
الشبكة هنا دون أي مشاكل تحدد الرسالة المركزية. ستكون هذه نوعية مفيدة للغاية إذا كانت مهمتنا هي التعرف على مجموعة مختارة من الأحرف فقط ، ولكن في العالم الواقعي سيكون ذلك ضارًا: عندما نقطع السلسلة إلى أحرف بشكل غير صحيح ، يجب أن نمرر هذه المعلومات أعلاه ، لأنه بخلاف ذلك يتم التعرف على القطعة المتبقية كنوع من علامات الترقيم ، وفي النص الناتج ، سيكون هناك حرف إضافي.
لحل هذه المشكلة ، سوف نستخدم ما تبقى من بعض التجارب القديمة منذ سنوات عديدة. لقد ظهرت فكرة التعرف على الحروف الكورية بالحروف منذ فترة طويلة جدًا ، وقد بذلت المحاولات الأولى حتى قبل عصر الشبكات العصبية ، لكنها لم تجد تطبيقًا عمليًا. ولكن منذ ذلك الحين ، بقيت أشياء مثيرة للاهتمام:
- تحديد مكان كل كتلة فيها بريد إلكتروني.
- جودة عالية ، وإن كانت سريعة ، مع استبعاد هذه الحروف من الرموز.
بعد إزالة الغبار من الغبار ، بمساعدة هذا الصنف ، سننشئ عددًا كافيًا من هذه الصور الإشكالية بدون أحد الحروف ، وسنعمل على تعليم الشبكة خصيصًا للإجابة على أنها حرف فارغ.
هذا كل شيء ، لم تعد هناك مشاكل في التعرف على الشخصيات الكورية ، ولكن الحياة تضع العصي في العجلات مرة أخرى.
والحقيقة هي أنه بالإضافة إلى أحرف الهانجول ، تتكون النصوص الكورية أيضًا من عدد كبير من الأحرف الأخرى: علامات الترقيم ، الأحرف الأوروبية (على الأقل الأرقام) والأحرف الصينية. لكنها تحدث بشكل طبيعي أقل بكثير في كثير من الأحيان. سنقسمهم إلى مجموعتين: الهيروغليفية وكل شيء آخر ، وسوف نقوم بتدريب شبكتنا لكل منهم. وسنقوم بتصنيف بسيط ، والذي وفقًا لنتائج شبكة التعرف على الحروف الكورية وبعض الإشارات الأخرى (هندسية ، في المقام الأول) سوف يجيب عما إذا كانت هناك حاجة لإطلاق واحدة على الأقل ، وإذا كان الأمر كذلك ، أي واحد. يجب أن تتعرف على بعض الشخصيات الأوروبية ، لذا ستكون الشبكة صغيرة ، ولكن بالنسبة إلى الحروف الهيروغليفية ... يحفظ أنها نادراً ما توجد في النصوص ، لذا دعنا نلف مصنفنا بحيث نادراً ما يقترح التعرف عليها.
بشكل عام ، مع هاتين الشبكتين ، تنشأ مشكلة الإجابة المناسبة في صور ليست رموزًا تم تدريبها عليها ، لكننا سنتحدث عن كيفية حل هذه المشكلة في وقت آخر.
إجراء التجارب
أول واحد . هناك قاعدتان للصور ، دعنا نسميهما Real و Synthetic. يتكون Real من صور حقيقية يتم الحصول عليها من المستندات الممسوحة ضوئيًا ، والصور الاصطناعية - التي تم الحصول عليها من الخطوط. في القاعدة الأولى هناك صور لكتل 2374 (البقية نادرة جدًا) ، ومن الخطوط حصلنا على جميع الأحرف 11172 الممكنة. دعونا نحاول تدريب الشبكة على الكتل الموجودة في Real (سنلتقط الصور من كلا القاعدتين) ، ونختبر تلك الموجودة في Synthetic فقط. النتائج:

وهذا يعني ، في حوالي 60٪ من الحالات ، أن الشبكة قادرة على التعرف على تلك الكتل ، وهي أمثلة لم ترها على الإطلاق أثناء التدريب. كان من الممكن أن تكون الجودة أعلى ، إن لم تكن بسبب مشكلة واحدة: من بين الأحرف الأخيرة ، هناك حروف نادرة جدًا ، وخلال التدريب ، شاهدت الشبكة عددًا قليلاً جدًا من صور الكتل فيها. هذا ما يفسر الجودة المنخفضة في العمود الأخير. إذا كان من الممكن اختيار المجموعات 2374 التي ندرس عليها ، بطريقة مختلفة ، فمن المرجح أن تكون الجودة أعلى بشكل ملحوظ.
الثانية واحد . قارن شبكتنا بشبكة "طبيعية" تحتوي على softmax في النهاية. أرغب في جعله بحجم 11172 ، لكن لا يمكننا العثور على عدد كاف من الصور الحقيقية للكتل النادرة ، لذا فنحن نقصر أنفسنا على 2374. تعتمد جودة وسرعة هذه الشبكة على حجم الطبقات المخفية. سنقوم بالتدريس فقط على Real ، ونختبرها (على الجانب الآخر ، بالطبع).

وهذا هو ، حتى لو قصرنا أنفسنا على التعرف على كتل 2374 فقط ، فإن شبكتنا أسرع وفي نفس المستوى من حيث الجودة.
ثالثا . لنفترض أننا تمكنا من الوصول إلى قاعدة ضخمة تضم جميع الكتل الكورية البالغ عددها 11172. إذا قمنا بتدريب شبكة مع softmax عليها ، فكم من الوقت ستعمل في الوقت المحدد؟ يعد إجراء جميع التجارب أمرًا مكلفًا ، لذلك سننظر فقط في شبكة ذات 256 طبقة مخفية من الأحجام:

نحصل على النتائج
بدونهم ، لن يحدث شيء
أعرب عن امتناني لزميلي جورا تشولينين ، المؤلف الأصلي للفكرة. تم
تسجيل براءة اختراع في روسيا ، بالإضافة إلى ذلك ، تم
تقديم طلب مماثل لدى مكتب البراءات الأمريكي (USPTO). شكراً جزيلاً للمطور Misha Zatsepin الذي نفذ كل هذا وأجرى جميع التجارب.
يوري فاتلين ،
رئيس مجموعة النصوص المعقدة