يستخدم حاليا التصور وتحليل البيانات على نطاق واسع في صناعة الاتصالات السلكية واللاسلكية. على وجه الخصوص ، يعتمد التحليل اعتمادًا كبيرًا على استخدام البيانات الجغرافية المكانية. ربما يرجع ذلك إلى حقيقة أن شبكات الاتصالات نفسها مشتتة جغرافيا. وفقًا لذلك ، يمكن أن يكون تحليل مثل هذه التشتت ذا قيمة هائلة.
البيانات
لتوضيح خوارزمية التجميع k-mean ، سنستخدم قاعدة البيانات الجغرافية لخدمة WiFi العامة المجانية في نيويورك. مجموعة البيانات متاحة في بيانات مدينة نيويورك المفتوحة. على وجه الخصوص ، يتم استخدام خوارزمية التجميع k-الوسائل لتكوين مجموعات استخدام WiFi استنادًا إلى بيانات خطوط الطول والعرض.
يتم استخراج بيانات خطوط الطول والعرض من مجموعة البيانات نفسها باستخدام لغة البرمجة R:
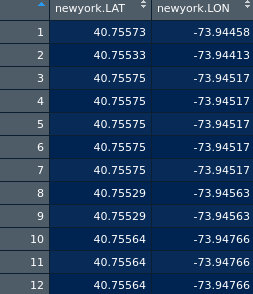
هنا قطعة من البيانات:
نحدد عدد المجموعات
بعد ذلك ، نحدد عدد الكتل التي تستخدم الكود أدناه ، والتي توضح النتيجة في الرسم البياني.
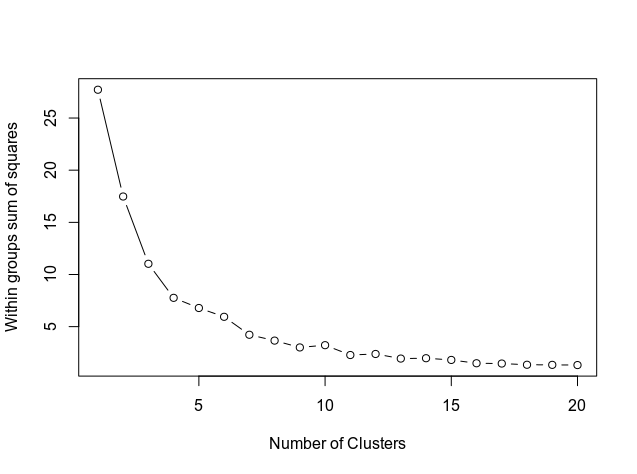
يوضح الرسم البياني كيف يتم محاذاة المنحنى عند حوالي 11. لذلك ، هذا هو عدد الكتل التي سيتم استخدامها في نموذج الوسائل k.
تحليل K- يعني
يتم تحليل الوسائل K:
تحتوي مجموعة بيانات newyorkdf على معلومات حول خطوط الطول والعرض وتسمية الكتلة:
> newyorkdf
newyork.lat newyork.lon fit.cluster
1 40.75573 -73.94458 1
2 40.75533 -73.94413 1
3 40.75575 -73.94517 1
4 40.75575 -73.94517 1
5 40.75575 -73.94517 1
6 40.75575 -73.94517 1
...
80 40.84832 -73.82075 11
هنا توضيح واضح:
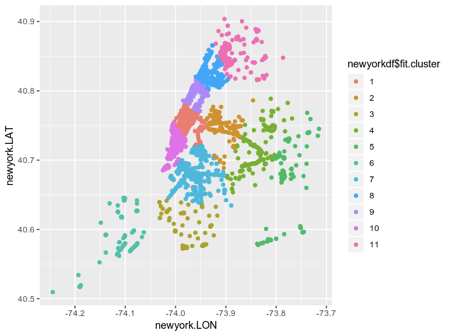
هذا الرسم التوضيحي مفيد ، لكن التصور سيكون أكثر قيمة إذا قمت بتراكبه على خريطة نيويورك نفسها.

يعطي هذا النوع من التجميع فكرة ممتازة عن بنية شبكة WiFi في المدينة. يشير هذا إلى أن المنطقة الجغرافية التي تميزها المجموعة 1 تظهر الكثير من حركة مرور WiFi. من ناحية أخرى ، قد يشير عدد الاتصالات الأقل في المجموعة 6 إلى انخفاض حركة مرور WiFi.
لا تعلمنا التجميعات K-Means لوحدها أن حركة مرور مجموعة معينة مرتفعة أو منخفضة. على سبيل المثال ، عندما يكون للمجموعة 6 كثافة سكانية عالية ، لكن سرعات الإنترنت المنخفضة تؤدي إلى عدد أقل من الاتصالات.
ومع ذلك ، توفر خوارزمية التجميع هذه نقطة انطلاق ممتازة لمزيد من التحليل وتسهل عملية جمع المعلومات الإضافية. على سبيل المثال ، باستخدام هذه الخريطة كمثال ، يمكنك إنشاء فرضيات تتعلق بالمجموعات الجغرافية الفردية. المقال الأصلي
هنا .