مرحبا بالجميع! لقد حان فصل الربيع ، مما يعني أنه لا يزال هناك أقل من شهر قبل بدء دورة
مطور بايثون . سيتم تخصيص منشورنا لهذا المقرر.

 المهام:
المهام:- تعرف على الهيكل الداخلي لبيثون ؛
- فهم مبادئ بناء شجرة بناء جملة مجردة (AST) ؛
- كتابة رمز أكثر كفاءة في الوقت والذاكرة.
توصيات أولية:- الفهم الأساسي للمترجم (AST ، الرموز ، الخ).
- معرفة بيثون.
- المعرفة الأساسية لل C.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
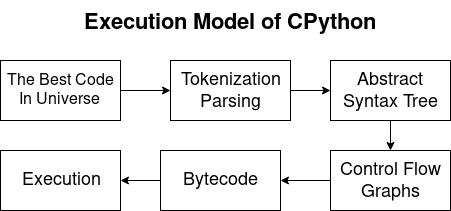
CPython نموذج التنفيذبيثون هي لغة مترجمة ومترجمة. وبالتالي ، يقوم برنامج التحويل البرمجي Python بإنشاء الرموز الثانوية ، ويقوم المترجم بتنفيذها. خلال المقالة سننظر في المشكلات التالية:
- تحليل و رمزية:
- التحول في AST.
- التحكم في تدفق الرسم البياني (CFG) ؛
- Bytecode
- يعمل على الجهاز الظاهري CPython.
تحليل و رمزية.
قواعد اللغة.النحوي يحدد دلالات اللغة بيثون. إنه مفيد أيضًا في الإشارة إلى الطريقة التي يجب أن يفسر بها المحلل اللغوي. تستخدم قواعد لغة Python بناء جملة مماثل لنموذج Backus-Naur الممتد. لديها قواعدها الخاصة للمترجم من لغة المصدر. يمكنك العثور على ملف القواعد في دليل "cpython / Grammar / Grammar".
وفيما يلي مثال لقواعد اللغة ،
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
تحتوي التعبيرات البسيطة على تعبيرات وقوس صغيرة ، وينتهي الأمر بسطر جديد. تبدو التعبيرات الصغيرة مثل قائمة التعبيرات التي تستورد ...
بعض التعبيرات الأخرى :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
رمزية (Lexing)Tokenization هي عملية الحصول على دفق بيانات نصية وتقسيمها إلى الرموز المميزة للكلمات المهمة (للمترجم الفوري) مع بيانات تعريف إضافية (على سبيل المثال ، حيث يبدأ الرمز المميز وينتهي ، وما هي قيمة السلسلة لهذا الرمز المميز).
الرموزالرمز المميز هو ملف رأس يحتوي على تعريفات لجميع الرموز المميزة. يوجد 59 نوعًا من الرموز في Python (Include / token.h).
فيما يلي مثال لبعضهم ،
تراها إذا قسمت بعض رموز بايثون إلى رموز.
رمزية مع CLIهنا هو ملف tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
ثم نقوم بترميزها باستخدام الأمر python -m tokenize وما يلي هو الإخراج:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
هنا الأرقام (على سبيل المثال ، 1.4-1.13) تُظهر مكان بدء الرمز المميز ومكان انتهائه. رمز التشفير هو دائمًا الرمز المميز الأول الذي نتلقاه. يقدم معلومات حول تشفير الملف المصدر ، وإذا كانت هناك أي مشاكل في ذلك ، فإن المترجم الشفهي يرمي استثناءً.
تشريع مع tokenize.tokenizeإذا كنت بحاجة إلى الرمز
المميز للملف من التعليمات البرمجية الخاصة بك ، يمكنك استخدام الوحدة النمطية
للرمز المميز من
stdlib .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
نوع الرمز المميز هو
معرفه في ملف رأس
token.h. السلسلة هي قيمة الرمز. إظهار البداية والنهاية حيث يبدأ الرمز المميز وينتهي ، على التوالي.
في لغات أخرى ، يتم الإشارة إلى الكتل بين قوسين أو عبارات بداية / نهاية ، لكن بيثون يستخدم المسافات البادئة ومستويات مختلفة. علامات المسافة البادئة و DEDENT وتشير المسافة البادئة. هذه الرموز مطلوبة لبناء أشجار تحليل علائقية و / أو أشجار بناء جملة مجردة.
جيل المحللجيل المحلل - عملية تنشئ محلل وفقا لقواعد معينة. ومن المعروف المولدات محلل PGen. Cpython واثنين من المولدات محلل. واحد هو الأصلي (
Parser/pgen ) وإعادة كتابة واحدة في الثعبان (
/Lib/lib2to3/pgen2 ).
"المولد الأصلي كان أول رمز كتبته لبيثون"
جويدومن الاقتباس أعلاه ، يصبح من الواضح أن
pgen هو أهم شيء في لغة البرمجة. عند استدعاء pgen (في
Parser / pgen ) ، فإنه ينشئ ملف رأس وملف C (المحلل اللغوي نفسه). إذا نظرت إلى الكود C الذي تم إنشاؤه ، فقد يبدو ذلك بلا معنى ، لأن مظهره ذي معنى اختياري. أنه يحتوي على الكثير من البيانات الثابتة والهياكل. بعد ذلك ، سنحاول شرح مكوناته الرئيسية.
DFA (آلة الحالة المحددة)يعرّف المحلل اللغوي DFA واحد لكل nonmminal. يتم تعريف كل DFA كمجموعة من الحالات.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
لكل DFA ، هناك مجموعة بداية التي تظهر الرموز المميزة الخاصة غير الطرفية يمكن أن تبدأ.
الشرطيتم تعريف كل ولاية من خلال مجموعة من التحولات / الحواف (الأقواس).
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
التحولات (الأقواس)يحتوي كل صفيف انتقال رقمين. الرقم الأول هو اسم الانتقال (تسمية القوس) ، فإنه يشير إلى رقم الرمز. الرقم الثاني هو الوجهة.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
الأسماء (التسميات)هذا جدول خاص يعين هوية الشخصية إلى اسم الانتقال.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
الرقم 1 يتوافق مع جميع المعرفات. وبالتالي ، يحصل كل منهم على أسماء انتقال مختلفة ، حتى إذا كان لديهم جميعًا نفس رقم الحرف.
مثال بسيط:افترض أن لدينا رمزًا يخرج "Hi" إذا كان 1 - صحيحًا:
if 1: print('Hi')
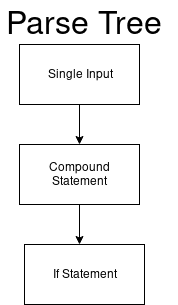
يعتبر المحلل اللغوي هذا الرمز منفردًا.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
ثم تبدأ شجرة التحليل الخاصة بنا في العقدة الجذرية لإدخال لمرة واحدة.

وقيمة DFA لدينا (single_input) هي 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
سيبدو مثل هذا:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2} ،
} ؛
هنا
arc_0_0 يتكون من ثلاثة عناصر. الأول هو
NEWLINE ، والثاني هو
simple_stmt ، والأخير هو
compound_stmt .
بالنظر إلى المجموعة الأولية من
simple_stmt يمكننا أن نستنتج أنه لا يمكن لـ
simple_stmt أن يبدأ بـ
if . ومع ذلك ، حتى لو لم يكن سطرًا جديدًا ، فيمكن أن يبدأ المركب_stmt مع ذلك. وبالتالي ، نذهب من آخر
arc ({4;2}) ونضيف عقدة المركب_stmt إلى شجرة التحليل وقبل الانتقال إلى الرقم 2 ، ننتقل إلى DFA الجديد. حصلنا على شجرة تحليل محدثة:

يوزّع DFA الجديد عبارات مركبة.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
ونحصل على ما يلي:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
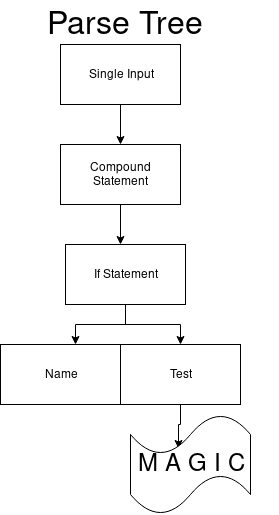
فقط القفزة الأولى يمكن أن تبدأ
if . نحصل على شجرة تحليل محدثة.
ثم نقوم مرة أخرى بتغيير DFA و DFA التالي.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
نتيجة لذلك ، حصلنا على الانتقال الوحيد مع التعيين 97. إنه يتزامن مع الرمز المميز
if .
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
عندما نتحول إلى الحالة التالية ، وتبقى في نفس DFA ، فإن arcs_41_1 التالي يحتوي أيضًا على انتقال واحد فقط. هذا صحيح لمحطة الاختبار. يجب أن يبدأ برقم (على سبيل المثال ، 1).
هناك انتقال واحد فقط في arc_41_2 يحصل على رمز النقطتين (:).

حتى نحصل على مجموعة يمكن أن تبدأ بقيمة طباعة. أخيرًا ، انتقل إلى arcs_41_4. الانتقال الأول في المجموعة هو تعبير elif ، والثاني هو تعبير آخر ، والثالث هو للحالة الأخيرة. ونحصل على المنظر النهائي لشجرة التحليل.
 بيثون واجهة للمحلل.
بيثون واجهة للمحلل.
يسمح لك Python بتحرير شجرة التحليل للتعبيرات باستخدام وحدة نمطية تسمى المحلل اللغوي.
>>> import parser >>> code = "if 1: print('Hi')"
يمكنك إنشاء شجرة بناء جملة محددة (شجرة بناء الجملة ، CST) باستخدام parser.suite.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
ستكون قيمة الإخراج قائمة متداخلة. تحتوي كل قائمة في الهيكل على عنصرين. الأول هو معرف الشخصية (0-256 - الطرفيات ، 256+ - غير الطرفية) والثاني هو سلسلة الرموز المميزة للجهاز.
شجرة بناء جملة مجردةفي الواقع ، فإن شجرة بناء الجملة المجردة (AST) هي تمثيل هيكلي للكود المصدري في شكل شجرة ، حيث يشير كل رأس إلى أنواع مختلفة من بنيات اللغة (التعبير ، المتغير ، المشغل ، إلخ.)
ما هي الشجرة؟الشجرة هي بنية بيانات لها قمة جذر كنقطة انطلاق. يتم تخفيض رأس الجذر بواسطة الفروع (التحولات) وصولاً إلى رؤوس أخرى. كل قمة ، باستثناء الجذر ، لها قمة رأس فريدة.
يوجد اختلاف معين بين شجرة بناء الجملة المجردة وشجرة التحليل.
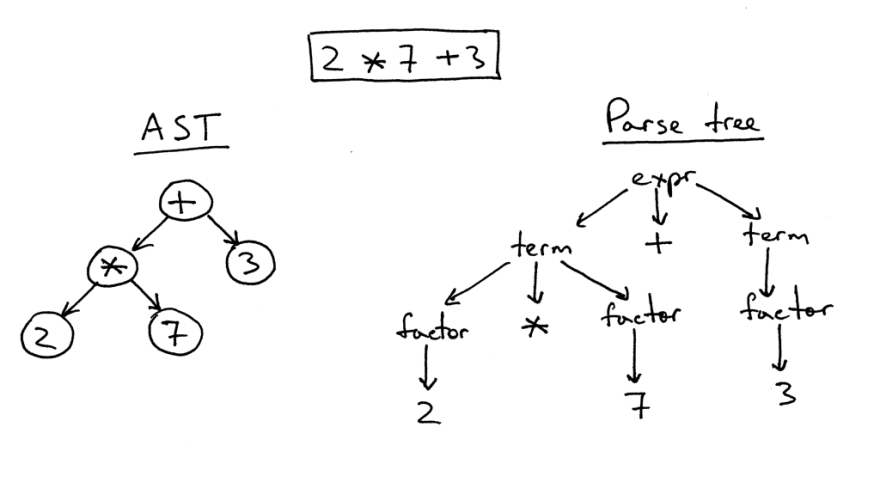
على اليمين توجد شجرة تحليل للتعبير 2 * 7 + 3. هذه هي حرفيا صورة مصدر واحد لواحد في شكل شجرة. جميع التعبيرات والمصطلحات والقيم مرئية على ذلك. ومع ذلك ، فإن مثل هذه الصورة معقدة للغاية بالنسبة لجزء بسيط من الشفرة ، لذلك يمكننا ببساطة إزالة جميع التعبيرات النحوية التي اضطررنا إلى تحديدها في الشفرة للحسابات.
تسمى هذه الشجرة المبسطة شجرة بناء الجملة المجردة (AST). على اليسار في الشكل يظهر بالضبط لنفس الكود. تم تجاهل كل تعبيرات بناء الجملة لتسهيل فهمها ، ولكن تذكر أن بعض المعلومات قد فقدت.
مثال
تقدم Python وحدة AST مدمجة للعمل مع AST. لإنشاء تعليمة برمجية من أشجار AST ، يمكنك استخدام الوحدات الخارجية ، على سبيل المثال
Astor .
على سبيل المثال ، ضع في الاعتبار نفس الرمز كما كان من قبل.
>>> import ast >>> code = "if 1: print('Hi')"
للحصول على AST ، نستخدم طريقة ast.parse.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
حاول استخدام طريقة
ast.dump للحصول على شجرة بناء جملة أكثر قابلية للقراءة.
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
يعتبر AST عمومًا أكثر بصرية وسهولة الفهم من شجرة التحليل.
التحكم في التدفق غراف (CFG)الرسوم البيانية للتحكم في التدفق هي رسوم بيانية اتجاهية تقوم بنمذجة تدفق البرنامج باستخدام الكتل الأساسية التي تحتوي على تمثيل وسيط.
عادةً ما تكون CFG هي الخطوة السابقة قبل الحصول على قيم شفرة الإخراج. يتم إنشاء الشفرة مباشرة من الكتل الأساسية باستخدام بحث متعمق في CFG ، بدءًا من القمم.
BytecodePython bytecode عبارة عن مجموعة وسيطة من الإرشادات التي تعمل في جهاز Python الظاهري. عند تشغيل التعليمات البرمجية المصدر ، يقوم Python بإنشاء دليل يسمى __pycache__. يقوم بتخزين التعليمات البرمجية المترجمة من أجل توفير الوقت في حالة إعادة تشغيل الترجمة.
النظر في وظيفة بيثون بسيطة في func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
say_hello كائن
say_hello هو وظيفة.
>>> type(say_hello) <class 'function'>
لديها سمة
__code__ .
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
كائنات التعليمات البرمجيةكائنات التعليمات البرمجية هي هياكل بيانات غير قابلة للتغيير تحتوي على التعليمات أو البيانات الأولية اللازمة لتنفيذ التعليمات البرمجية. ببساطة ، هذه هي تمثيلات لشفرة بيثون. يمكنك أيضًا الحصول على كائنات التعليمات البرمجية عن طريق ترجمة أشجار بناء الجملة المجردة باستخدام طريقة
الترجمة .
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
كل كائن رمز له سمات تحتوي على معلومات معينة (مسبوقة بـ co_). هنا نذكر فقط عدد قليل منهم.
co_nameلبداية - اسم. في حالة وجود وظيفة ، يجب أن يكون لها اسم ، على التوالي ، سيكون هذا الاسم هو اسم الوظيفة ، وهو موقف مشابه للفئة. في مثال AST ، نستخدم وحدات ، ويمكننا أن نعلم المترجم بالضبط ما نريد تسميته. فليكن مجرد
module .
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnamesهذه مجموعة تحتوي على جميع المتغيرات المحلية ، بما في ذلك الوسائط.
>>> say_hello.__code__.co_varnames ('name',)
التعاونمجموعة تحتوي على جميع القيم الحرفية والقيم الثابتة التي وصلنا إليها في نص الوظيفة. تجدر الإشارة إلى قيمة بلا. لم نقم بتضمين لا شيء في نص الوظيفة ، لكن Python أشار إليها ، لأنه إذا بدأت الوظيفة في التنفيذ وتنتهي دون تلقي أي قيم إرجاع ، فسوف تُرجع بلا.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
Bytecode (كود_المشترك)ما يلي هو رمز وظيفتنا.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
هذه ليست سلسلة ، هذا كائن بايت ، أي سلسلة بايت.
>>> type(bytecode) <class 'bytes'>
الحرف الأول المطبوع هو "t". إذا طلبنا قيمتها الرقمية ، فسوف نحصل على ما يلي.
>>> ord('t') 116
116 هو نفس رمز الكود [0].
>>> assert bytecode[0] == ord('t')
بالنسبة لنا ، قيمة 116 لا تعني شيئًا. لحسن الحظ ، يوفر Python مكتبة قياسية تسمى dis (من التفكيك). من المفيد عند العمل مع قائمة opname. هذه قائمة بجميع إرشادات رمز البايت ، حيث يكون كل فهرس هو اسم التعليمات.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
دعونا إنشاء وظيفة أخرى أكثر تعقيدا.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
ونكتشف أول تعليمات في bytecode.
>>> dis.opname[bytecode[0]] 'LOAD_FAST
يتكون بيان LOAD_FAST من عنصرين.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
يحدث تعليمة Loadfast 0 للبحث عن أسماء المتغيرات في المجموعة ودفع عنصر بفهرس صفري إلى tuple في مكدس التنفيذ.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
يمكن تفكيك الكود الخاص بنا باستخدام dis.dis وتحويل الكود الجانبي إلى طريقة عرض مألوفة. هنا الأرقام (2،3،4) هي أرقام الأسطر. يتم توسيع كل سطر من التعليمات البرمجية في بيثون كمجموعة من التعليمات.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
مهلةCPython عبارة عن آلة افتراضية موجهة نحو المكدس ، وليست مجموعة من السجلات. هذا يعني أن شفرة Python يتم تجميعها لجهاز ظاهري بهيكل مكدس.
عند استدعاء وظيفة ، يستخدم Python مجموعتين معًا. الأول هو مكدس التنفيذ ، والثاني هو مكدس الكتلة. تحدث معظم الاستدعاءات في مكدس التنفيذ ؛ تقوم مجموعة الكتل بتتبع عدد الكتل النشطة حاليًا ، وكذلك المعلمات الأخرى المتعلقة بالكتل والنطاقات.
نحن نتطلع إلى تعليقاتك على المواد وندعوكم إلى
عقد ندوة عبر الإنترنت حول هذا الموضوع: "حررها: الجوانب العملية لإصدار برامج موثوقة" ، والتي سيجريها معلمنا ، مبرمج نظام الإعلان في Mail.Ru ،
ستانيسلاف ستوبنيكوف .