إن معرفة طريقة واحدة فقط للتجريد عبر الإنترنت تحل المشكلة على المدى القصير ، ولكن كل الطرق لها نقاط قوتها وضعفها. الوعي بهذا يوفر الوقت ويساعد على حل المشكلة بشكل أكثر كفاءة.

تتحدث العديد من الموارد عن الطريقة الحقيقية الوحيدة لاسترداد البيانات من صفحة ويب. لكن الحقيقة هي أنه يمكنك استخدام العديد من الحلول والأدوات.
- ما هي الخيارات لاستخراج البيانات بطريقة برمجية من صفحة الويب؟
- إيجابيات وسلبيات كل نهج؟
- كيفية استخدام الموارد السحابية لزيادة درجة الأتمتة؟
سوف تساعد المقالة في الحصول على إجابات لهذه الأسئلة.
أفترض أنك تعرف بالفعل طلبات
HTTP ،
DOM (نموذج كائن المستند) ،
HTML ،
محددات CSS و
Async JavaScript .
إذا لم يكن الأمر كذلك ، فإنني أنصحك بالتعمق في النظرية ، ثم العودة إلى المقال.
محتوى ثابت
مصادر HTMLلنبدأ بأبسط الطرق.
إذا كنت تخطط لالغاء صفحات الويب ، فهذا هو أول شيء تبدأ به. سوف يتطلب القليل من طاقة الكمبيوتر والحد الأدنى من الوقت.
ومع ذلك ، لا يعمل هذا إلا إذا كانت شفرة مصدر HTML تحتوي على البيانات التي تستهدفها. لاختبار ذلك في Chrome ، انقر بزر الماوس الأيمن على الصفحة وحدد عرض رمز الصفحة. يجب أن تشاهد الآن شفرة مصدر HTML.
بمجرد العثور على البيانات ، اكتب
محدد CSS ينتمي إلى عنصر الالتفاف بحيث يكون لديك رابط لاحقًا.
للتنفيذ ، يمكنك إرسال طلب HTTP GET إلى عنوان URL للصفحة واستعادة شفرة مصدر HTML مرة أخرى.
في
Node ، يمكنك استخدام أداة
CheerioJS لتحليل HTML الخام واسترداد البيانات باستخدام محدد. سيبدو الرمز كالتالي:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
محتوى ديناميكي
في كثير من الحالات ، لا يمكنك الوصول إلى المعلومات من تعليمات HTML البرمجية الخام نظرًا لأن DOM يتم التحكم فيه بواسطة جافا سكريبت الذي يعمل في الخلفية. مثال نموذجي على ذلك هو SPA (تطبيق أحادي الصفحة) ، حيث يحتوي مستند HTML على الحد الأدنى من المعلومات ويملأه JavaScript في وقت التشغيل.
في هذه الحالة ، يكون الحل هو إنشاء DOM وتنفيذ البرامج النصية الموجودة في شفرة مصدر HTML ، كما يفعل المستعرض. بعد ذلك ، يمكن استخراج البيانات من هذا الكائن باستخدام محددات.
متصفحات مقطوعة الرأسالمتصفح مقطوعة الرأس هو نفسه المتصفح العادي ، فقط بدون واجهة مستخدم. يتم تشغيله في الخلفية ، ويمكنك التحكم فيه برمجيًا بدلاً من النقر والكتابة من لوحة المفاتيح.
Puppeteer هي واحدة من أكثر المتصفحات مقطوعة الرأس شعبية. هذه مكتبة Node سهلة الاستخدام توفر واجهة برمجة تطبيقات عالية المستوى لإدارة Chrome في وضع عدم الاتصال. يمكن تهيئتها لتعمل بدون رأس ، وهي مريحة للغاية أثناء التطوير. الشفرة التالية تفعل نفس الشيء كما كان من قبل ، لكنها ستعمل مع الصفحات الديناميكية:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
بالطبع ، يمكنك أن تفعل أشياء أكثر إثارة للاهتمام مع Puppeteer ، لذلك تحقق من
الوثائق . إليك مقتطف من الكود الذي يتنقل في عنوان URL ، ويلتقط لقطة شاشة ويحفظها:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
يحتاج المستعرض إلى طاقة حوسبية أكثر بكثير من إرسال طلب GET بسيط وتحليل الاستجابة. لذلك ، التنفيذ بطيء نسبيا. ليس ذلك فحسب ، ولكن أيضًا إضافة مستعرض كتبعية يجعل الحزمة ضخمة.
من ناحية أخرى ، هذه الطريقة مرنة للغاية. يمكنك استخدامه للتنقل في الصفحات ومحاكاة النقرات وحركات الماوس واستخدام لوحة المفاتيح أو ملء النماذج أو إنشاء لقطات شاشة أو إنشاء صفحات PDF وتنفيذ الأوامر في وحدة التحكم وتحديد العناصر لاستخراج محتوى النص. في الأساس ، كل ما يمكن القيام به يدويا في المتصفح.
بناء DOMسوف تعتقد أنه ليس من الضروري محاكاة متصفح كامل فقط لإنشاء DOM. في الواقع ، هذا صحيح ، على الأقل في ظروف معينة.
Jsdom هي مكتبة Node تقوم بتوزيع HTML التي يتم إرسالها ، تمامًا كما يفعل المستعرض. ومع ذلك ، هذا ليس مستعرضًا ، ولكنه
أداة لإنشاء DOM من رمز مصدر HTML معين ، وكذلك لتنفيذ تعليمات JavaScript البرمجية في HTML.
بفضل هذا التجريد ، يمكن تشغيل Jsdom بشكل أسرع من متصفح مقطوع الرأس. إذا كان الأمر أسرع ، فلماذا لا تستخدمه بدلاً من المتصفحات مقطوعة الرأس طوال الوقت؟
اقتباس من الوثائق :
غالبًا ما يواجه الأشخاص مشكلات أثناء تحميل البرامج النصية بشكل غير متزامن عند استخدام jsdom. تقوم العديد من الصفحات بتحميل البرامج النصية بشكل غير متزامن ، لكن من المستحيل تحديد وقت حدوث ذلك ، وبالتالي متى يتم تشغيل التعليمات البرمجية والتحقق من بنية DOM الناتجة. هذا هو الحد الأساسي.
يظهر هذا الحل في المثال. كل 100 مللي ثانية ، يتم التحقق مما إذا كان عنصر قد ظهر أو حدث مهلة (بعد ثانيتين).
كما أنه غالبًا ما يعطي رسائل خطأ عندما لا تقوم Jsdom بتنفيذ بعض ميزات المستعرض على الصفحة ، مثل: "
خطأ: لم يتم التنفيذ: window.alert ..." أو "خطأ: لم يتم التنفيذ: window.scrollTo ... ". يمكن أيضًا حل هذه المشكلة مع بعض الحلول (
لوحات المفاتيح الافتراضية ).
هذا هو عادةً مستوى API أقل من Puppeteer ، لذلك تحتاج إلى تنفيذ بعض الأشياء بنفسك.
هذا يعقد الاستخدام قليلاً ، كما يتضح من المثال. تقدم
Jsdom حلاً سريعًا لنفس الوظيفة.
دعونا نلقي نظرة على المثال نفسه ، ولكن باستخدام
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
الهندسة العكسيةJsdom هو حل سريع وسهل ، ولكن يمكنك جعله أكثر بساطة.
هل نحن بحاجة إلى نموذج DOM؟
تتكون صفحة الويب التي تريد إزالتها من نفس HTML و JavaScript ، وهي نفس التقنيات التي تعرفها بالفعل. وبالتالي ،
إذا وجدت جزءًا من الشفرة تم الحصول على البيانات المستهدفة منه ، يمكنك تكرار نفس العملية للحصول على نفس النتيجة .
لتبسيط الأشياء ، قد تكون البيانات التي تبحث عنها:
- جزء من شفرة مصدر HTML (كما يمكن رؤيته من الجزء الأول من المقال) ،
- جزء من ملف ثابت المشار إليه في مستند HTML (على سبيل المثال ، سطر في ملف javascript) ،
- استجابة لطلب شبكة (على سبيل المثال ، أرسلت بعض تعليمات JavaScript البرمجية طلب AJAX إلى خادم استجاب بسلسلة JSON).
يمكن الوصول إلى مصادر البيانات هذه باستخدام استعلامات الشبكة . لا يهم إذا كانت صفحة الويب تستخدم HTTP أو WebSockets أو أي بروتوكول اتصال آخر ، لأنها كلها قابلة للتكرار من الناحية النظرية.
بمجرد العثور على مورد يحتوي على بيانات ، يمكنك إرسال طلب شبكة مماثل إلى نفس الخادم مثل الصفحة الأصلية. نتيجةً لذلك ، سوف تحصل على إجابة تحتوي على البيانات المستهدفة ، والتي يمكن استخراجها بسهولة باستخدام تعبيرات منتظمة ، وأساليب السلسلة ، JSON.parse ، إلخ.
بعبارة بسيطة ، يمكنك استخدام المورد الذي توجد عليه البيانات ، بدلاً من معالجة وتحميل جميع المواد. وبالتالي ، يمكن حل المشكلة الموضحة في الأمثلة السابقة بطلب HTTP واحد بدلاً من التحكم في مستعرض أو كائن JavaScript معقدة.
يبدو هذا الحل بسيطًا من الناحية النظرية ، لكن في معظم الحالات قد يستغرق وقتًا طويلًا ويتطلب خبرة في صفحات الويب والخوادم.
ابدأ بمراقبة حركة مرور الشبكة. إحدى الأدوات الرائعة لذلك هي علامة تبويب
الشبكة في Chrome DevTools . سترى جميع الطلبات الصادرة مع الإجابات (بما في ذلك الملفات الثابتة ، طلبات أجاكس ، وما إلى ذلك) للتكرار من خلالها والبحث عن البيانات.
إذا تم تغيير الإجابة عن طريق أي رمز قبل عرضها على الشاشة ، فإن العملية ستكون أبطأ. في هذه الحالة ، يجب عليك العثور على هذا الجزء من التعليمات البرمجية وفهم ما يجري.
كما ترون ، قد تتطلب هذه الطريقة عملًا أكثر بكثير من الطرق الموضحة أعلاه. من ناحية أخرى ، فإنه يوفر أفضل أداء.
يوضح الرسم البياني وقت التشغيل وحجم الحزمة المطلوبة مقارنة بـ Jsdom و Puppeteer:
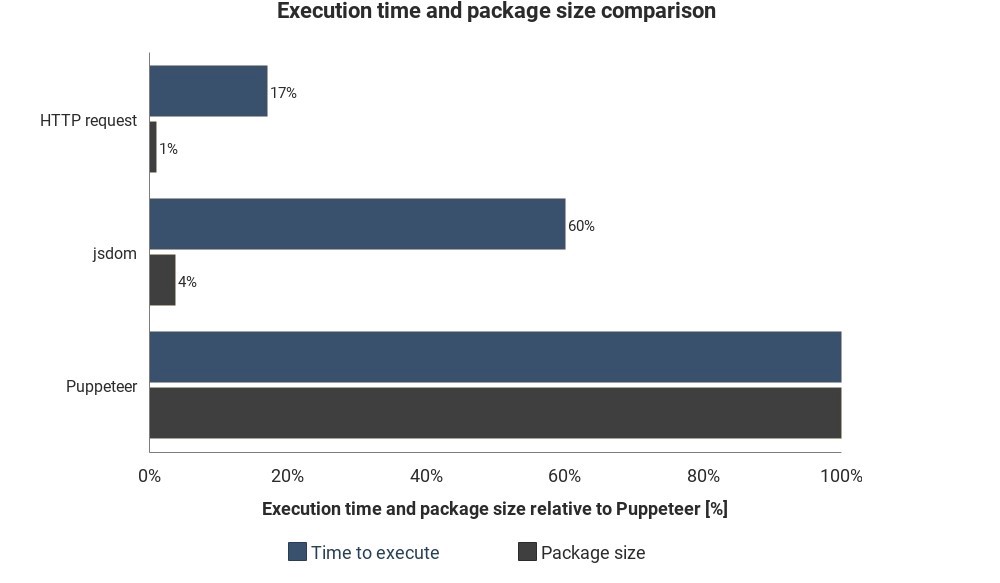
لا تستند النتائج إلى قياسات دقيقة وقد تختلف ، ولكنها تظهر اختلافات تقريبية جيدة بين هذه الطرق.
تكامل الخدمة السحابية
افترض أنك قمت بتنفيذ أحد هذه الحلول. إحدى الطرق لتنفيذ البرنامج النصي هي تشغيل الكمبيوتر وفتح الجهاز وبدء تشغيله يدويًا.
لكنه سيصبح مزعجًا وغير كفء ، لذلك سيكون من الأفضل أن تتمكن فقط من تحميل البرنامج النصي على الخادم وسيتم تنفيذه بشكل منتظم وفقًا للإعدادات.
يمكن القيام بذلك عن طريق بدء الخادم الفعلي وتحديد القواعد عند تنفيذ البرنامج النصي. في حالات أخرى ، تكون وظيفة السحابة طريقة أسهل.
وظائف السحاب هي مخازن مصممة لتنفيذ التعليمات البرمجية التي تم تنزيلها عند حدوث حدث. هذا يعني أنك لست بحاجة إلى إدارة الخوادم ، ويتم ذلك تلقائيًا من خلال مزود الخدمة السحابية.
يمكن أن يكون المشغل جدولًا ، وطلب شبكة ، والعديد من الأحداث الأخرى. يمكنك حفظ البيانات التي تم جمعها في قاعدة بيانات أو كتابتها إلى
صفحة Google أو إرسالها عبر
البريد الإلكتروني . كل هذا يتوقف على خيالك.
مزودي السحابة المشهورين -
خدمات الويب من Amazon (AWS) و
Google Cloud Platform (GCP) و
Microsoft Azure :
يمكنك استخدام هذه الخدمات مجانًا ، ولكن ليس لفترة طويلة.
إذا كنت تستخدم Puppeteer ، فإن
ميزات Google Cloud هي الحل الأسهل. يتجاوز حجم الحزمة بتنسيق Headless Chrome (130 ميغابايت تقريبًا) الحد الأقصى المسموح به لحجم الأرشيف في AWS Lambda (50 ميجابايت). هناك العديد من الطرق لجعلها تعمل مع Lambda ، لكن وظائف GCP
تدعم Chrome افتراضيًا
دون رأس ، تحتاج فقط إلى تضمين Puppeteer كتبعية في
package.json .
إذا كنت ترغب في معرفة المزيد حول ميزات السحابة بشكل عام ، تحقق من معلومات هندسة الخادم. تم بالفعل كتابة العديد من البرامج التعليمية الجيدة حول هذا الموضوع ، ومعظم مقدمي الخدمة لديهم وثائق سهلة الفهم.