مرحبا يا هبر! أوجه انتباهكم إلى ترجمة للمقالة التي أجراها رودي جيلمان وكاثرين وانغ بديهية RL: مقدمة إلى Advantage-Actor-Critic (A2C) .

أخصائي التعلم المعزز (RL) أنتجوا العديد من البرامج التعليمية الممتازة. معظم ، ومع ذلك ، وصف RL من حيث المعادلات الرياضية والرسوم البيانية مجردة. نود أن نفكر في الموضوع من منظور مختلف. RL نفسه مستوحى من كيفية تعلم الحيوانات ، فلماذا لا تترجم آلية RL الكامنة مرة أخرى إلى ظواهر طبيعية تهدف إلى المحاكاة؟ يتعلم الناس أفضل من خلال القصص.
هذه هي قصة نموذج الممثل الناقد (A2C). يعد نموذج الناقد الموضوع نموذجًا شائعًا لنموذج تدرج السياسة ، وهو بحد ذاته خوارزمية RL تقليدية. إذا فهمت A2C ، فأنت تفهم RL العميق.
بعد اكتساب فهم بديهي لـ A2C ، تحقق من:
الرسوم التوضيحية
في RL ، يتحرك العميل ، الثعلب Klyukovka ، عبر الولايات التي تحيط بها الإجراءات ، في محاولة لتعظيم المكافآت أثناء الرحلة.
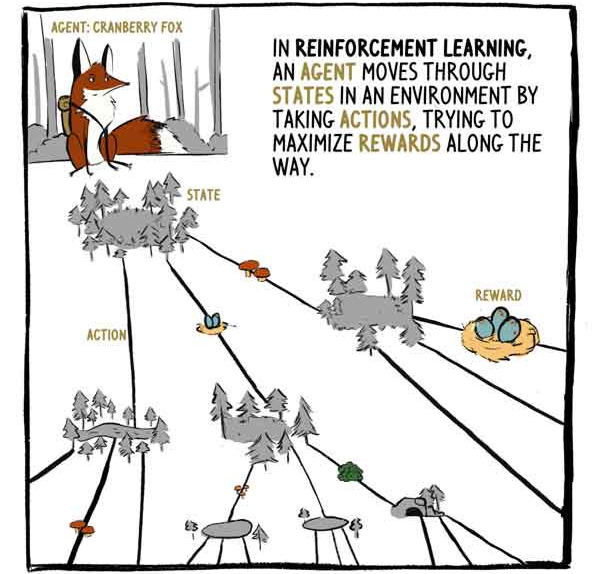
يتلقى A2C مدخلات الحالة - مدخلات المستشعر في حالة Klukovka - ويولد ناتجين:
1) تقييم مقدار المكافأة التي سيتم تلقيها ، بدءًا من لحظة الحالة الحالية ، باستثناء المكافأة الحالية (الحالية).
2) توصية بشأن الإجراءات التي يجب اتخاذها (السياسة).
الناقد: واو ، يا له من وادي رائع! سيكون يوما مثمرا للبحث عن الطعام! أراهن اليوم أنني سأجمع 20 نقطة قبل غروب الشمس.
"الموضوع": هذه الزهور تبدو جميلة ، أشعر بشغف ل "أ".

طرز RL العميقة هي آلات رسم خرائط المدخلات والمخرجات ، مثل أي نموذج تصنيف أو انحدار آخر. بدلاً من تصنيف الصور أو النص ، فإن نماذج RL العميقة تجلب الحالات إلى الإجراءات و / أو الحالات إلى قيم الحالة. A2C يفعل كلاهما.


هذه المجموعة من عمل الدولة المكافأة هي ملاحظة واحدة. سوف تكتب هذا السطر من البيانات إلى دفتر يومياتها ، لكنها لن تفكر فيه حتى الآن. سوف تملأها عندما تتوقف عن التفكير.
يربط بعض المؤلفين المكافأة 1 بالخطوة الزمنية 1 ، بينما يربطها الآخرون بالخطوة 2 ، لكنهم جميعًا يأخذون في الاعتبار نفس المفهوم: ترتبط المكافأة بالحالة ، ويسبقها الإجراء مباشرة.

ربط يكرر العملية مرة أخرى. أولاً ، إنها تتفهم محيطها وتقوم بتطوير وظيفة V (S) وتوصية للعمل.
الناقد: يبدو هذا الوادي عاديًا. الخامس (ق) = 19.
الموضوع: تبدو خيارات العمل متشابهة جدًا. أعتقد أنني سوف أذهب إلى المسار "C".
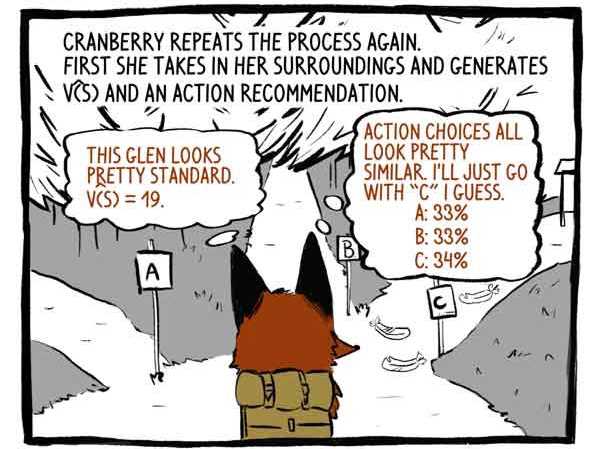
ثم يتصرف.

يتلقى مكافأة من +20! ويسجل الملاحظة.

هي تكرر العملية مرة أخرى.

بعد جمع ثلاث ملاحظات ، توقف Klyukovka عن التفكير.
تنتظر العائلات النموذجية الأخرى حتى نهاية اليوم (مونت كارلو) ، بينما يفكر آخرون بعد كل خطوة (خطوة واحدة).
قبل أن تتمكن من إعداد الناقد الداخلي لها ، تحتاج Klukovka إلى حساب عدد النقاط التي ستتلقاها بالفعل في كل ولاية.
لكن اولا!
دعونا نلقي نظرة على كيفية قيام ابن عم كلوكوفكا ، ليس مونتي كارلو ، بحساب المعنى الحقيقي لكل ولاية.
لا تعكس نماذج Monte Carlo تجربتها حتى نهاية اللعبة ، وبما أن قيمة الحالة الأخيرة هي صفر ، فمن السهل جدًا العثور على القيمة الحقيقية لهذه الحالة السابقة كمجموع المكافآت التي تم تلقيها بعد هذه اللحظة.
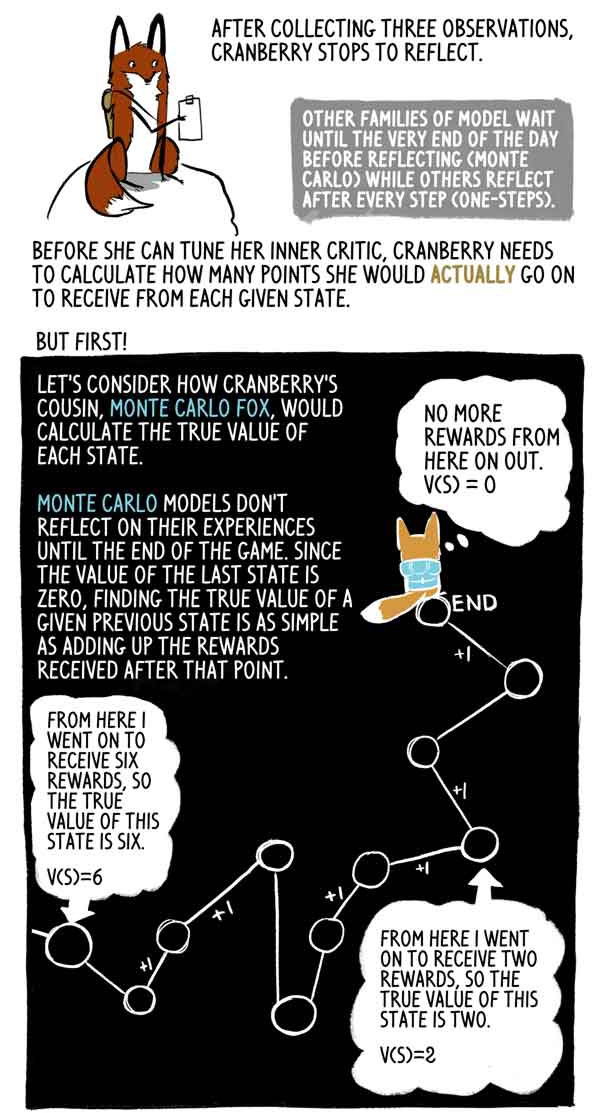
في الواقع ، هذه مجرد عينة تشتت عالية V (S). يمكن للوكيل متابعة مسار مختلف من الحالة نفسها بسهولة ، وبالتالي الحصول على مكافأة كلية مختلفة.
لكن Klyukovka يذهب ، ويتوقف ويعكس عدة مرات حتى ينتهي اليوم. إنها تريد أن تعرف عدد النقاط التي ستحصل عليها بالفعل من كل ولاية إلى نهاية اللعبة ، لأن هناك عدة ساعات متبقية حتى نهاية اللعبة.
حيث تعمل شيئًا ذكيًا حقًا - يقدر الثعلب Klyukovka عدد النقاط التي ستتلقاها عن الحالة الأخيرة في هذه المجموعة. لحسن الحظ ، لديها تقييم صحيح لحالتها - ناقدها.
باستخدام هذا التقييم ، يمكن لـ Klyukovka حساب القيم "الصحيحة" للحالات السابقة تمامًا كما يفعل الثعلب مونت كارلو.
يقوم Lis Monte Carlo بتقييم العلامات المستهدفة ، مما يجعل نشر المسار وإضافة مكافآت إلى الأمام من كل ولاية. تقوم A2C بقطع هذا المسار واستبداله بتقييم ناقدها. هذا الحمل الأولي يقلل من تباين النتيجة ويسمح لتشغيل A2C بشكل مستمر ، وإن كان عن طريق إدخال انحياز صغير.

غالبًا ما يتم تخفيض المكافآت لتعكس حقيقة أن المكافآت أصبحت الآن أفضل مما كانت عليه في المستقبل. للبساطة ، Klukovka لا يقلل من مكافآتها.

بإمكان Klukovka الآن الاطلاع على كل صف من البيانات ومقارنة تقديرات قيم الدولة بقيمها الفعلية. إنها تستخدم الفرق بين هذه الأرقام لإتقان مهارات التنبؤ بها. كل ثلاث خطوات طوال اليوم ، يجمع Klyukovka تجربة قيمة تستحق الدراسة.
"أنا سيئة التصنيف الدول 1 و 2. ماذا فعلت خطأ؟ نعم! في المرة القادمة التي أرى فيها ريشًا كهذا ، سأزيد من V (S).
قد يبدو من الجنون أن تتمكن Klukovka من استخدام تصنيف V (S) لها كأساس لمقارنته بتوقعات أخرى. لكن الحيوانات (بما في ذلك لنا) تفعل هذا طوال الوقت! إذا شعرت أن الأمور تسير على ما يرام ، فلست بحاجة إلى إعادة تدريب الإجراءات التي أدت بك إلى هذه الحالة.

من خلال تقليص المخرجات المحسوبة واستبدالها بتقدير أولي للحمولة ، استبدلنا التباين الكبير لـ Monte Carlo بانحياز صغير. تعاني نماذج RL عادةً من التشتت العالي (الذي يمثل جميع المسارات الممكنة) ، وعادة ما يستحق هذا الاستبدال ذلك.
يكرر كلوكوفكا هذه العملية طوال اليوم ، حيث يجمع ثلاث ملاحظات حول مكافأة الدولة للعمل والتفكير فيها.
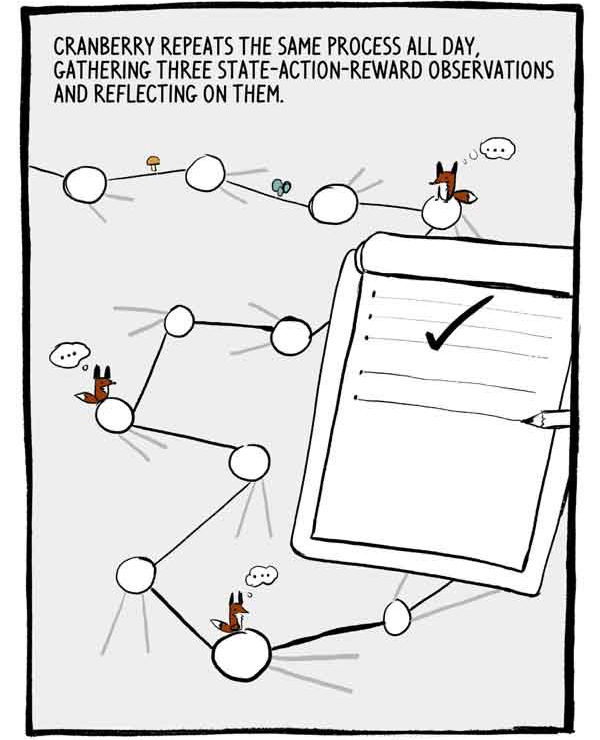
كل مجموعة من ثلاث ملاحظات هي عبارة عن سلسلة صغيرة متصلة من بيانات التدريب المسمى. لتقليل هذا الارتباط التلقائي ، يقوم العديد من A2Cs بتدريب العديد من الوكلاء بشكل متوازٍ ، مما يزيد من خبرتهم معًا قبل إرسالها إلى شبكة عصبية مشتركة.

اليوم يقترب أخيرًا من نهايته. فقط خطوتين اليسار.
كما قلنا سابقًا ، يتم التعبير عن توصيات إجراءات Klukovka في نسبة مئوية من الثقة حول قدراتها. بدلاً من مجرد اختيار الخيار الأكثر موثوقية ، يختار Klukovka من هذا التوزيع من الإجراءات. هذا يضمن أنها لا توافق دائمًا على الإجراءات الآمنة ، ولكن يحتمل أن تكون متواضعة.
قد أشعر بالأسف ، ولكن ... في بعض الأحيان ، واستكشاف أشياء غير معروفة ، يمكنك الوصول إلى اكتشافات جديدة ومثيرة ...

لمزيد من تشجيع البحث ، يتم طرح قيمة تسمى الانتروبي من وظيفة الخسارة. Entropy تعني "نطاق" توزيع الإجراءات.
- يبدو أن اللعبة قد آتت أكلها!

أم لا؟
في بعض الأحيان يكون العامل في حالة تؤدي فيها جميع الإجراءات إلى نتائج سلبية. A2C ، ومع ذلك ، تتكيف بشكل جيد مع المواقف السيئة.


عندما غرقت الشمس ، انعكست Klyukovka على المجموعة الأخيرة من الحلول.

تحدثنا عن كيفية إعداد Klyukovka ناقده الداخلي. لكن كيف تقوم بضبط "موضوعها" الداخلي؟ كيف تتعلم اتخاذ مثل هذه الخيارات الرائعة؟
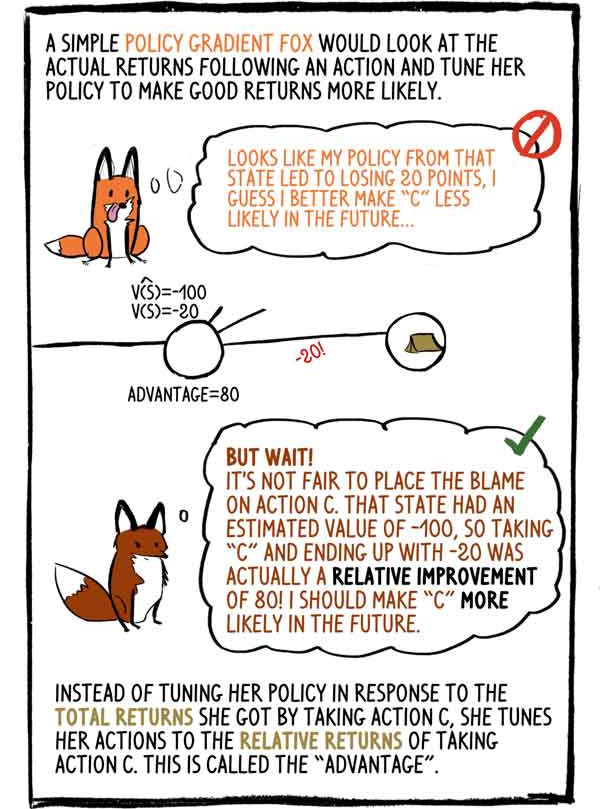
تبحث سياسة التدرج الثعلب البسيط في التفكير في الدخل الفعلي بعد الإجراء وتعديل سياستها لجعل الدخل الجيد أكثر احتمالا: - يبدو أن سياستي في هذه الحالة أدت إلى خسارة 20 نقطة ، وأعتقد أنه من الأفضل القيام في المستقبل بـ "C" أقل احتمالا.
- لكن انتظر! من الظلم إلقاء اللوم على العمل "C". كان لهذه الحالة قيمة تقديرية تبلغ -100 ، لذا فإن اختيار "C" وتنتهي بـ -20 كان في الواقع تحسنًا نسبيًا بلغ 80! لا بد لي من جعل "C" أكثر احتمالا في المستقبل.
بدلاً من تعديل سياستها استجابةً لإجمالي الإيرادات التي حصلت عليها من خلال اختيار الإجراء C ، تقوم بضبط عملها على الإيرادات النسبية من الإجراء C. وهذا ما يسمى "الميزة".
ما نسميه ميزة هو مجرد خطأ. كميزة ، يستخدم Klukovka لجعل الأنشطة التي كانت جيدة بشكل مدهش ، على الأرجح. كخطأ ، تستخدم نفس المبلغ لدفع ناقدها الداخلي لتحسين تقييمها لقيمة الوضع.
الموضوع يستفيد من:
- "واو ، التي عملت بشكل أفضل مما كنت أعتقد ، يجب أن يكون الإجراء C فكرة جيدة."
يستخدم الناقد الخطأ:
"لكن لماذا فوجئت؟ ربما لا ينبغي عليّ تقييم هذا الشرط بشكل سلبي. "
الآن يمكننا أن نوضح كيف يتم حساب إجمالي الخسائر - نقوم بتقليل هذه الوظيفة إلى الحد الأدنى لتحسين نموذجنا.
"الخسارة الكلية = خسارة النشاط + خسارة القيمة - الانتروبيا"
يرجى ملاحظة أنه لحساب التدرجات من ثلاثة أنواع مختلفة نوعيا ، نأخذ القيم "من خلال واحد". هذا فعال ، لكن يمكن أن يجعل التقارب أكثر صعوبة.

مثل كل الحيوانات ، حيث يكبر Klyukovka ، فإنه سوف يشحذ قدرته على التنبؤ بقيم الولايات ، واكتساب المزيد من الثقة في تصرفاته ، وغالبا ما يفاجأ الجوائز.
وكلاء RL ، مثل Klukovka ، لا ينتجون فقط جميع البيانات اللازمة ، بل يتفاعلون ببساطة مع البيئة ، ولكن أيضًا يقومون بتقييم الملصقات المستهدفة بأنفسهم. هذا صحيح ، نماذج RL تحديث الدرجات السابقة لتتناسب بشكل أفضل مع الدرجات الجديدة والمحسنة.
يقول الدكتور ديفيد سيلفر ، رئيس مجموعة RL في Google Deepmind: AI = DL + RL. عندما يستطيع عميل مثل Klyukovka ضبط ذكائه الخاص ، فإن الاحتمالات لا حصر لها ...
