واجهة
في
المقالة الأولى ، ذكرنا أن طريقة الوصول يجب أن توفر معلومات عن نفسها. دعونا ننظر في هيكل واجهة طريقة الوصول.
خصائص
يتم تخزين جميع خصائص طرق الوصول في جدول "pg_am" ("am" تعني طريقة الوصول). يمكننا أيضًا الحصول على قائمة بالطرق المتاحة من نفس الجدول:
postgres=# select amname from pg_am;
amname -------- btree hash gist gin spgist brin (6 rows)
على الرغم من أنه يمكن بشكل صحيح إحالة المسح المتسلسل إلى طرق الوصول ، إلا أنه ليس مدرجًا في هذه القائمة لأسباب تاريخية.
في إصدارات PostgreSQL 9.5 أو أقل ، تم تمثيل كل خاصية بحقل منفصل من جدول "pg_am". بدءًا من الإصدار 9.6 ، يتم الاستعلام عن الخصائص بوظائف خاصة ويتم فصلها إلى عدة طبقات:
- خصائص طريقة الوصول - "pg_indexam_has_property"
- خصائص فهرس معين - "pg_index_has_property"
- خصائص الأعمدة الفردية في الفهرس - "pg_index_column_has_property"
يتم فصل طبقة طريقة الوصول وطبقة الفهرس مع التركيز على المستقبل: اعتبارًا من الآن ، ستظل جميع الفهارس التي تعتمد على طريقة وصول واحدة لها نفس الخصائص دائمًا.
الخصائص الأربعة التالية هي تلك الخاصة بطريقة الوصول (بمثال "btree"):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name) from pg_am a, unnest(array['can_order','can_unique','can_multi_col','can_exclude']) p(name) where a.amname = 'btree' order by a.amname;
amname | name | pg_indexam_has_property --------+---------------+------------------------- btree | can_order | t btree | can_unique | t btree | can_multi_col | t btree | can_exclude | t (4 rows)
- can_order.
تتيح لنا طريقة الوصول تحديد ترتيب الفرز للقيم عند إنشاء فهرس (ينطبق فقط على "btree" حتى الآن). - can_unique
دعم القيد الفريد والمفتاح الأساسي (ينطبق فقط على "btree"). - can_multi_col.
يمكن بناء فهرس على عدة أعمدة. - can_exclude
دعم استبعاد القيد باستثناء.
تتعلق الخصائص التالية بفهرس (دعنا نفكر في أحد
الخصائص الموجودة على سبيل المثال):
postgres=# select p.name, pg_index_has_property('t_a_idx'::regclass,p.name) from unnest(array[ 'clusterable','index_scan','bitmap_scan','backward_scan' ]) p(name);
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | t (4 rows)
- قابل للذوبان.
إمكانية إعادة ترتيب الصفوف وفقًا للفهرس (التجميع باستخدام الأمر CLUSTER) الذي يحمل نفس الاسم. - index_scan.
دعم مسح مؤشر. على الرغم من أن هذه الخاصية قد تبدو غريبة ، إلا أنه لا يمكن لكل الفهارس إرجاع TIDs واحداً تلو الآخر - بعض النتائج تُرجع كلها مرة واحدة وتدعم المسح النقطي فقط. - الصورة النقطية.
دعم المسح النقطي. - الى الوراء.
يمكن إرجاع النتيجة بترتيب عكسي للواحد المحدد عند إنشاء الفهرس.
أخيرًا ، فيما يلي خصائص العمود: postgres=# select p.name, pg_index_column_has_property('t_a_idx'::regclass,1,p.name) from unnest(array[ 'asc','desc','nulls_first','nulls_last','orderable','distance_orderable', 'returnable','search_array','search_nulls' ]) p(name);
name | pg_index_column_has_property --------------------+------------------------------ asc | t desc | f nulls_first | f nulls_last | t orderable | t distance_orderable | f returnable | t search_array | t search_nulls | t (9 rows)
- تصاعدي ، تنازلي ، nulls_first ، nulls_last ، قابلة للترتيب.
ترتبط هذه الخصائص بترتيب القيم (سنناقشها عندما نصل إلى وصف فهارس "btree"). - distance_orderable.
يمكن إرجاع النتيجة بترتيب الفرز المحدد بواسطة العملية (ينطبق فقط على فهارس GiST و RUM حتى الآن). - قابل للإرجاع
إمكانية استخدام الفهرس دون الوصول إلى الجدول ، أي دعم عمليات المسح للفهرس فقط. - search_array.
دعم البحث عن العديد من القيم باستخدام التعبير " index -field IN ( list_of_constants )" ، وهو نفس " indexed-field = ANY ( array_of_constants )". - search_nulls.
إمكانية البحث بواسطة IS NULL وشروط NOT NULL.
لقد ناقشنا بالفعل بعض الخصائص بالتفصيل. بعض الخصائص خاصة بطرق وصول معينة. سنناقش هذه الخصائص عند النظر في هذه الأساليب المحددة.
فئات المشغل والأسر
بالإضافة إلى خصائص طريقة الوصول المكشوفة من خلال الواجهة الموصوفة ، هناك حاجة إلى معلومات لمعرفة أنواع البيانات وعوامل التشغيل التي تقبلها طريقة الوصول. تحقيقا لهذه الغاية ، يقدم PostgreSQL مفاهيم
فئة المشغل وعائلة المشغل .
تحتوي فئة المشغل على مجموعة صغيرة من العوامل (وربما وظائف إضافية) لفهرس للتعامل مع نوع بيانات معين.
يتم تضمين فئة المشغل في بعض أسرة المشغل. علاوة على ذلك ، يمكن أن تحتوي عائلة المشغل المشتركة على عدة فئات للمشغلين إذا كانت لديهم نفس الدلالات. على سبيل المثال ، تتضمن عائلة "integer_ops" فئات "int8_ops" و "int4_ops" و "int2_ops" لأنواع "bigint" و "integer" و "smallint" ، بأحجام مختلفة ولكن بنفس المعنى:
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'integer_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype -------------+----------+----------- integer_ops | int2_ops | smallint integer_ops | int4_ops | integer integer_ops | int8_ops | bigint (3 rows)
مثال آخر: تتضمن عائلة "datetime_ops" فئات المشغلين لمعالجة التواريخ (سواء مع الوقت أو بدونه):
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'datetime_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype --------------+-----------------+----------------------------- datetime_ops | date_ops | date datetime_ops | timestamptz_ops | timestamp with time zone datetime_ops | timestamp_ops | timestamp without time zone (3 rows)
يمكن لعائلة المشغل أيضًا تضمين مشغلين إضافيين لمقارنة قيم الأنواع المختلفة. يتيح التجميع في العائلات للمخطط استخدام فهرس للتنبؤات بقيم من أنواع مختلفة. يمكن أن تحتوي الأسرة أيضًا على وظائف مساعدة أخرى.
في معظم الحالات ، لا نحتاج إلى معرفة أي شيء عن عائلات وفئات المشغلين. عادة ما نقوم فقط بإنشاء فهرس ، باستخدام فئة مشغل معينة بشكل افتراضي.
ومع ذلك ، يمكننا تحديد فئة المشغل بشكل صريح. هذا مثال بسيط على ما إذا كانت المواصفات الصريحة ضرورية: في قاعدة بيانات تحتوي على ترتيب مختلف عن C ، لا يدعم الفهرس العادي عملية LIKE:
postgres=# show lc_collate;
lc_collate ------------- en_US.UTF-8 (1 row)
postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ----------------------------- Seq Scan on t Filter: (b ~~ 'A%'::text) (2 rows)
يمكننا التغلب على هذا القيد من خلال إنشاء فهرس مع فئة المشغل "text_pattern_ops" (لاحظ كيف تغيرت الحالة في الخطة):
postgres=# create index on t(b text_pattern_ops); postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ---------------------------------------------------------------- Bitmap Heap Scan on t Filter: (b ~~ 'A%'::text) -> Bitmap Index Scan on t_b_idx1 Index Cond: ((b ~>=~ 'A'::text) AND (b ~<~ 'B'::text)) (4 rows)
كتالوج النظام
في ختام هذه المقالة ، نقدم مخططًا مبسطًا للجداول في كتالوج النظام المرتبط مباشرةً بفئات المشغلات والأسر.
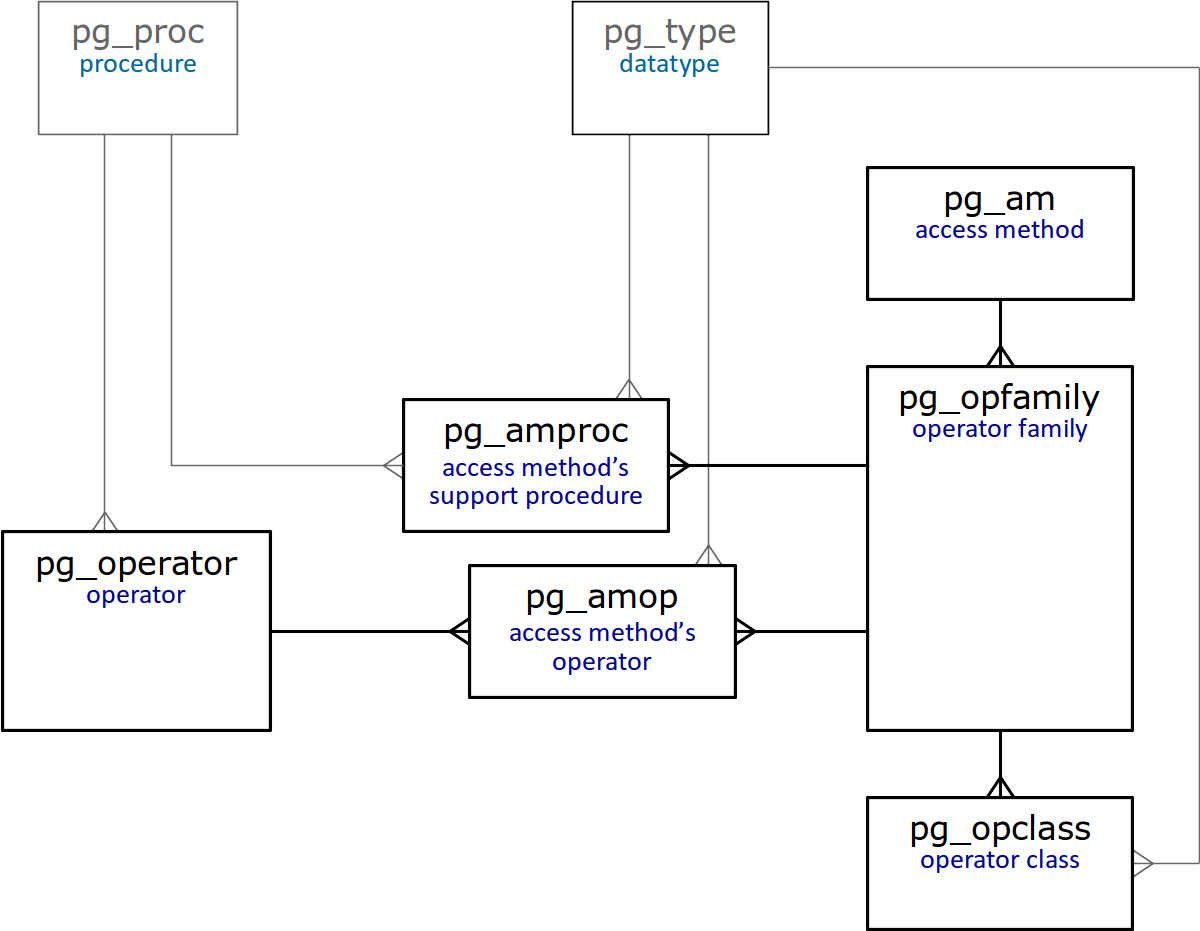
وغني عن القول أن كل هذه الجداول
موصوفة بالتفصيل .
يتيح لنا كتالوج النظام العثور على إجابات لعدد من الأسئلة دون النظر إلى الوثائق. على سبيل المثال ، ما هي أنواع البيانات التي يمكن لطريقة وصول معينة معالجتها؟
postgres=# select opcname, opcintype::regtype from pg_opclass where opcmethod = (select oid from pg_am where amname = 'btree') order by opcintype::regtype::text;
opcname | opcintype ---------------------+----------------------------- abstime_ops | abstime array_ops | anyarray enum_ops | anyenum ...
ما المشغلات التي تحتويها فئة المشغل (وبالتالي ، يمكن استخدام الوصول إلى الفهرس لحالة تتضمن مثل هذا المشغل)؟
postgres=# select amop.amopopr::regoperator from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'btree' and amop.amoplefttype = opc.opcintype;
amopopr ----------------------- <(anyarray,anyarray) <=(anyarray,anyarray) =(anyarray,anyarray) >=(anyarray,anyarray) >(anyarray,anyarray) (5 rows)
اقرأ على .