عندما جاء المشاركون في برنامج
HighLoad ++ إلى تقرير
ألكساندر كراسينيكوف ، كانوا يأملون في معرفة ما يتعلق بمعالجة 1600000 حدث في الثانية. لم تتحقق التوقعات ... لأنه خلال الإعداد للأداء ، ارتفع هذا الرقم إلى 1800،000 - لذلك ، على HighLoad ++ ، الواقع يتجاوز التوقعات.
منذ 3 سنوات ، أخبر ألكساندر كيف قاموا ببناء نظام معالجة أحداث شبه حقيقي قابل للتطوير على Badoo. منذ ذلك الحين ، تطورت ، ونمت وحدات التخزين في هذه العملية ، وكان من الضروري حل مشاكل التحجيم والتسامح مع الخطأ ، وفي مرحلة ما كانت هناك حاجة إلى تدابير جذرية -
تغيير في المكدس التكنولوجي .

من فك التشفير ، سوف تتعلم كيف استبدلت في Badoo حزمة Spark + Hadoop بـ ClickHouse ،
وحفظت الأجهزة 3 مرات وزادت من التحميل 6 مرات ، ولماذا وما هي الوسائل لجمع الإحصاءات في المشروع ، ثم ماذا تفعل بهذه البيانات.
نبذة عن المتحدث: ألكساندر كراشينيكوف (
ألكسكرش ) - رئيس قسم هندسة البيانات على Badoo. وهو يشارك في البنية التحتية BI ، وتوسيع نطاق أعباء العمل ، ويدير الفرق التي تبني بنية تحتية لمعالجة البيانات. يحب كل شيء موزع: Hadoop ، سبارك ، ClickHouse. أنا متأكد من أن الأنظمة الموزعة الرائعة يمكن إعدادها من OpenSource.
جمع الاحصاءات
إذا لم يكن لدينا بيانات ، فنحن أعمى ولا يمكننا إدارة مشروعنا. هذا هو السبب في أننا بحاجة إلى إحصاءات -
لرصد جدوى المشروع. نحن ، كمهندسين ، يجب أن نسعى جاهدين لتحسين منتجاتنا ، وإذا
كنت ترغب في تحسينها ، فقم بقياسها. هذا هو شعاري في العمل. بادئ ذي بدء ، هدفنا هو الفوائد التجارية.
توفر الإحصائيات
إجابات عن أسئلة العمل . المقاييس الفنية هي مقاييس تقنية ، لكن العمل مهتم أيضًا بالمؤشرات ، كما يجب أخذها في الاعتبار.
إحصائيات دورة الحياة
أقوم بتحديد دورة حياة الإحصاءات بـ 4 نقاط ، سوف نناقش كل منها على حدة.
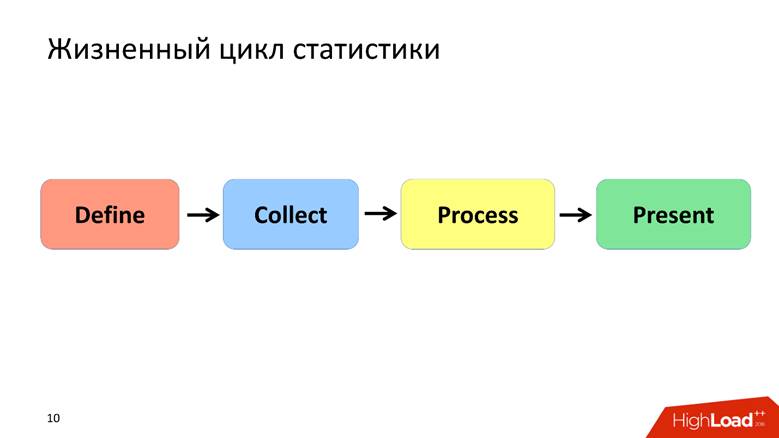
تحديد المرحلة - إضفاء الطابع الرسمي
في التطبيق ، نجمع العديد من المقاييس. بادئ ذي بدء ، هذه هي
مقاييس العمل . إذا كانت لديك خدمة صور ، على سبيل المثال ، فأنت تتساءل عن عدد الصور التي يتم تحميلها يوميًا ، في الساعة ، في الثانية. تعتبر المقاييس التالية
"شبه تقنية" : استجابة تطبيق أو موقع جوال أو تشغيل API أو مدى سرعة تفاعل المستخدم مع موقع أو تثبيت تطبيق أو UX.
تتبع سلوك المستخدم هو المقياس الثالث المهم. هذه أنظمة مثل Google Analytics و Yandex.Metrics. لدينا نظام التتبع الرائع لدينا ، والذي نستثمر فيه كثيرًا.
في عملية العمل مع الإحصاءات ، يشارك العديد من المستخدمين - هؤلاء هم المطورين وتحليلات الأعمال. من المهم أن يتحدث الجميع اللغة نفسها ، لذلك يجب أن توافق.
من الممكن التفاوض شفهياً ، لكن من الأفضل بكثير أن يحدث هذا بشكل رسمي - في بنية واضحة للأحداث.
إضفاء الطابع الرسمي على هيكل الأحداث التجارية عندما يقول المطور عدد التسجيلات لدينا ، يدرك المحلل أنه تم تزويده بمعلومات ليس فقط عن العدد الإجمالي للتسجيلات ، ولكن أيضا حسب البلد والجنس وغيرها من المعالم. ويتم إضفاء الطابع الرسمي على جميع هذه المعلومات وهي
في المجال العام لجميع مستخدمي الشركة . يحتوي الحدث على هيكل مكتوب ووصف رسمي. على سبيل المثال ، نقوم بتخزين هذه المعلومات بتنسيق
Protocol Buffers .
وصف الحدث "التسجيل":
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
يحتوي حدث التسجيل على معلومات حول
المستخدم والحقل ووقت الحدث
وبلد تسجيل المستخدم. هذه المعلومات متاحة للمحللين ، وفي المستقبل ، يفهم العمل ما نجمعه.
لماذا أحتاج إلى وصف رسمي؟
الوصف الرسمي هو
التوحيد للمطورين والمحللين وقسم المنتج. ثم تتخلل هذه المعلومات وصف المنطق التجاري للتطبيق. على سبيل المثال ، لدينا نظام داخلي لوصف العمليات التجارية وفيه شاشة لدينا ميزة جديدة.
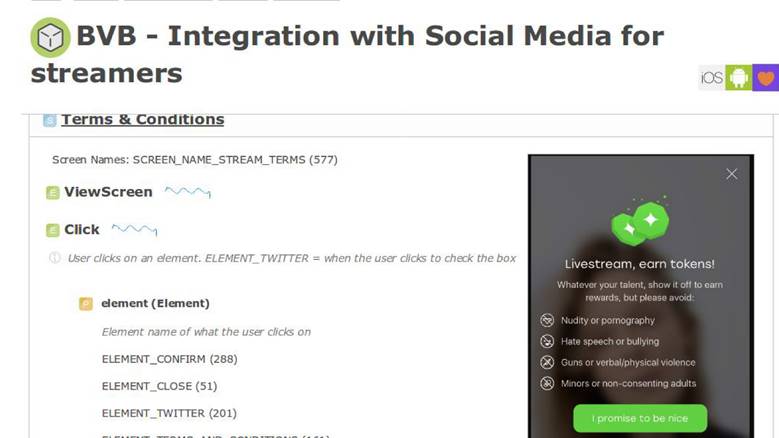
في
وثيقة متطلبات المنتج ، يوجد قسم يتضمن التعليمات بأنه عندما يتفاعل المستخدم مع التطبيق بهذه الطريقة ، يجب أن نرسل حدثًا بنفس المعلمات تمامًا. بعد ذلك ، سنكون قادرين على التحقق من صحة ميزاتنا ، وأننا قمنا بقياسها بشكل صحيح. يسمح لنا الوصف الرسمي بفهم كيفية حفظ هذه البيانات في قاعدة بيانات: NoSQL أو SQL أو غيرها. لدينا
مخطط بيانات ، وهذا رائع.
في بعض الأنظمة التحليلية التي يتم تقديمها كخدمة ، لا يوجد سوى 10 إلى 15 حدثًا في التخزين السري. ارتفع عددنا في بلدنا بأكثر من 1000 ولن يتوقف -
من المستحيل العيش بدون تسجيل واحد .
تحديد ملخص المرحلة
قررنا أن
الإحصائيات - وهذا أمر مهم ووصفنا مجالًا معينًا - وهذا جيد ، يمكنك العيش عليه.
جمع المرحلة - جمع البيانات
قررنا إنشاء النظام بحيث يحدث حدث تجاري - عند التسجيل ، وإرسال رسالة ، مثل - في نفس الوقت الذي يتم فيه حفظ هذه المعلومات ، نرسل بشكل منفصل حدثًا إحصائيًا معينًا.
في الكود ، يتم إرسال الإحصاءات في وقت واحد مع الحدث التجاري.
تتم معالجته بشكل مستقل تمامًا عن مخازن البيانات التي يعمل فيها التطبيق ، لأن
تدفق البيانات يمر عبر خط أنابيب معالجة منفصل.الوصف عبر EDL:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
لدينا وصف لحدث التسجيل. يتم إنشاء واجهة برمجة التطبيقات تلقائيًا ، ويمكن للمطورين الوصول إليها من التعليمات البرمجية ، والتي تتيح لك في 4 سطور إرسال إحصائيات.
واجهة برمجة التطبيقات القائمة على EDL:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
تسليم الحدث
هذا هو نظامنا الخارجي. نقوم بذلك لأن لدينا خدمات رائعة توفر واجهة برمجة تطبيقات (API) للتعامل مع بيانات الصورة ، حول شيء آخر. يقومون جميعًا بتخزين البيانات في قواعد بيانات جديدة رائعة ، مثل Aerospike و CockroachDB.
عندما تحتاج إلى إنشاء نوع من التقارير ، لا يتعين عليك الذهاب والقتال: "يا شباب ، كم من هذا لديك وكم؟" - يتم إرسال جميع البيانات في تدفق منفصل. ناقل معالجة - نظام خارجي. من سياق التطبيق ، نقوم بربط جميع البيانات من مستودع تخزين منطق الأعمال ، ونرسلها إلى خط أنابيب منفصل.
تفترض مرحلة التجميع توافر خوادم التطبيقات. لدينا هذا PHP.
النقل
هذا نظام فرعي يسمح لنا بإرسال ما قمنا به من سياق التطبيق إلى خط أنابيب آخر. يتم اختيار النقل فقط من الاحتياجات الخاصة بك ، وهذا يتوقف على الوضع في المشروع.
النقل له خصائص ، والأول هو
ضمانات التسليم. خصائص النقل: على الأقل مرة واحدة ، بالضبط مرة واحدة ، يمكنك اختيار إحصائيات لمهامك ، بناءً على مدى أهمية هذه البيانات. على سبيل المثال ، بالنسبة لأنظمة الفوترة ، من غير المقبول أن تظهر الإحصاءات عددًا أكبر من المعاملات - فهذه أموال ، وهذا غير ممكن.
المعلمة الثانية هي
روابط لغات البرمجة. يجب أن نتفاعل بطريقة ما مع النقل ، لذلك يتم تحديده وفقًا للغة المكتوبة بالمشروع.
المعلمة الثالثة هي
قابلية التوسع. نظرًا لأننا نتحدث عن ملايين الأحداث في الثانية الواحدة ، سيكون من الجيد أن نضع في الاعتبار قابلية التطوير المستقبلية.
هناك العديد من خيارات النقل: تطبيقات RDBMS ، Flume ، Kafka أو LSD. نستخدم
LSD - هذه هي طريقتنا الخاصة.
بث مباشر خفي
LSD لا علاقة له بالمواد المحظورة. هذا البرنامج عبارة عن برنامج
خفي حيوي وسريع للغاية لا يوفر أي وكيل للكتابة إليه. يمكننا ضبطها ، لدينا
تكامل مع الأنظمة الأخرى : HDFS ، Kafka - يمكننا إعادة ترتيب البيانات المرسلة. ليس لدى LSD مكالمة شبكة على INSERT ، ويمكنك التحكم في طبولوجيا الشبكة فيه.
الأهم من ذلك ، هذا هو
Badoo's مفتوحة المصدر - لا يوجد سبب لعدم الثقة في هذا البرنامج.
إذا كانت شيطانًا مثاليًا ، فبدلاً من Kafka ، سنناقش LSD في كل مؤتمر ، ولكن كل LSD لديها ذبابة في المرهم. لدينا قيودنا الخاصة التي نرتاح معها:
ليس لدينا دعم النسخ المتماثل في LSD ولديه
مرة واحدة على الأقل ضمان التسليم. أيضًا ، بالنسبة للمعاملات المالية ، ليس هذا هو النقل الأنسب ، لكنك تحتاج عمومًا إلى التواصل مع المال حصريًا من خلال قواعد البيانات "الحمضية" - التي تدعم
ACID .
جمع ملخص المرحلة
استنادًا إلى نتائج السلسلة السابقة ، تلقينا
وصفًا رسميًا للبيانات ، وقمنا بإنشاء
واجهة برمجة تطبيقات ممتازة ومريحة
لمُرسلي الأحداث منهم ، وتوصلنا إلى كيفية
نقل هذه البيانات
من سياق التطبيق إلى خط أنابيب منفصل . بالفعل ليست سيئة ، ونحن نقترب من المرحلة المقبلة.
مرحلة العملية - معالجة البيانات
قمنا بجمع البيانات من التسجيلات والصور التي تم تحميلها واستطلاعات الرأي - ماذا تفعل مع كل هذا؟ من هذه البيانات ، نريد الحصول على
مخططات ذات تاريخ طويل
وبيانات خام . تتفهم الرسوم البيانية كل شيء - لست بحاجة إلى أن تكون مطورًا لفهم من منحنى أن إيرادات الشركة تنمو. نحن نستخدم البيانات الأولية للإبلاغ عبر الإنترنت والمخصص. للحالات الأكثر تعقيدًا ، يرغب محللوننا في إجراء استفسارات تحليلية حول هذه البيانات. كل من تلك وظيفة ضرورية بالنسبة لنا.
الرسوم البيانية
الرسوم البيانية تأتي في أشكال كثيرة.
أو ، على سبيل المثال ، رسم بياني له سجل يعرض البيانات لمدة 10 سنوات.
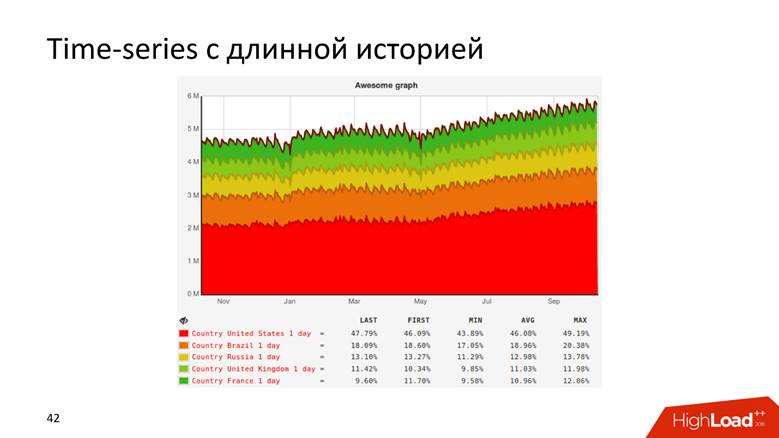
الرسوم البيانية هي حتى من هذا القبيل.
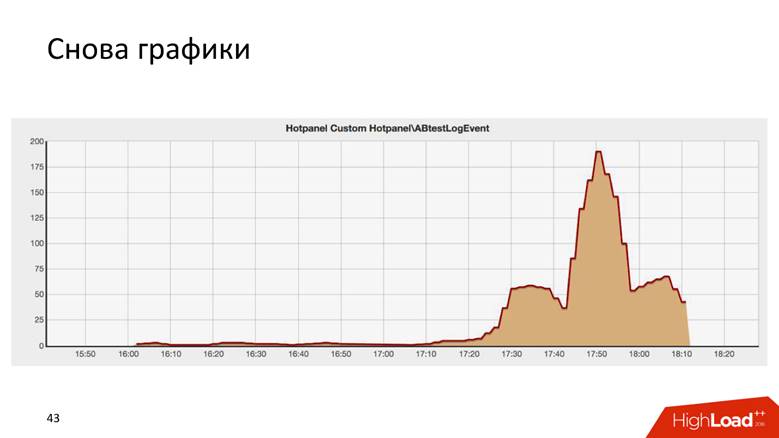
هذه هي نتيجة بعض اختبارات AB ، وهي تشبه بشكل مدهش مبنى كرايسلر في نيويورك.
هناك طريقتان لرسم رسم بياني:
استعلام للبيانات الأولية وسلسلة زمنية . كلا النهجين لهما عيوب ومزايا ، ونحن لن نتطرق إليها بالتفصيل. نحن نستخدم
نهجًا مختلطًا : نحافظ على ذيل قصير من البيانات الأولية للإبلاغ عن العمليات ، وسلسلة زمنية للتخزين طويل الأجل. يتم حساب الثاني من الأول.
كيف نمت إلى 1.8 مليون حدث في الثانية الواحدة
إنها قصة طويلة - لا يحدث ملايين من RPS في يوم واحد. بادوو شركة لها عقد من التاريخ ، ويمكننا القول أن نظام معالجة البيانات نما مع الشركة.
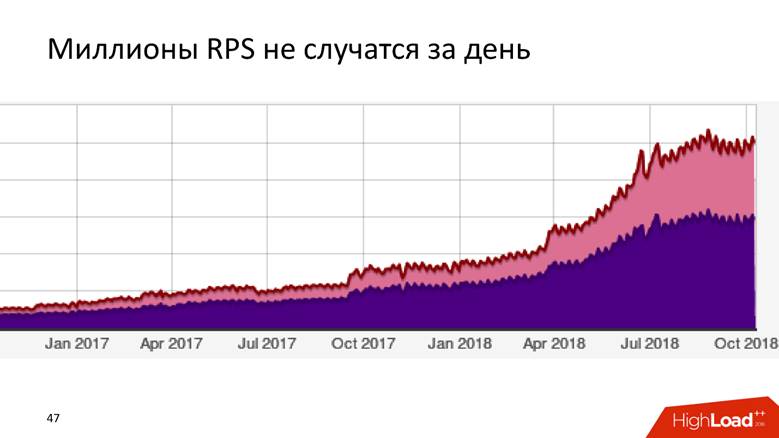
في البداية لم يكن لدينا شيء. بدأنا في جمع البيانات - لقد تحولت إلى
5000 حدث في الثانية. مضيف MySQL واحد ولا شيء غير ذلك! أي DBMS علائقية سوف تتعامل مع هذه المهمة ، وسوف تكون مريحة معها: سيكون لديك المعاملات - وضع البيانات ، وتلقي الطلبات منه - كل شيء يعمل بشكل جيد وبصحة جيدة. لذلك عشنا لفترة من الوقت.
في مرحلة ما ، حدث التقاسم الوظيفي: بيانات التسجيل - هنا ، وحول الصور - هناك. لذا ، عشنا ما يصل إلى
200000 حدث في الثانية وبدأنا في استخدام طرق مختلفة مدمجة: لتخزين البيانات غير الخام ، ولكن
المجمعة ، ولكن حتى الآن داخل قاعدة البيانات العلائقية. نقوم بتخزين العدادات ، ولكن جوهر معظم قواعد البيانات ذات الصلة هو أنه سيكون من المستحيل عندئذٍ تنفيذ
استعلام DISTINCT على هذه البيانات - لا يسمح نموذج جبري للعدادات بحساب DISTINCT.
لدينا في Badoo شعار
"قوة لا يمكن وقفها" . نحن لن نتوقف ونمت أكثر. في اللحظة التي تجاوزنا فيها عتبة
200000 حدث في الثانية ، قررنا إنشاء وصف رسمي تحدثت عنه أعلاه. قبل ذلك ، كانت هناك بعض الفوضى ، والآن لدينا سجل منظم للأحداث: بدأنا في توسيع نطاق النظام ،
متصلا Hadoop ، جميع البيانات دخلت
جداول Hive.Hadoop عبارة عن حزمة برامج ضخمة ونظام ملفات. بالنسبة للحوسبة الموزعة ، يقول Hadoop ، "ضع البيانات هنا ، سأسمح لك بإجراء استفسارات تحليلية عليها." لقد فعلنا ذلك - كتبنا
حسابًا منتظمًا لجميع الرسوم البيانية - اتضح أنه جيد. لكن المخططات ذات قيمة عندما يتم تحديثها بسرعة - مرة واحدة يوميًا ، فإن مشاهدة تحديث المخطط ليست ممتعة للغاية. إذا طرحنا شيئًا يؤدي إلى حدوث خطأ فادح في الإنتاج ، فإننا نود أن نرى المخطط يتراجع على الفور ، وليس كل يوم. لذلك ، بدأ النظام بأكمله في التدهور بعد بعض الوقت. ومع ذلك ، أدركنا أنه في هذه المرحلة ، يمكنك التمسك بكومة التقنية المحددة.
بالنسبة لنا ، كانت Java جديدة ، وقد أحببنا ذلك ، وفهمنا ما يمكن القيام به بطريقة مختلفة.
في المرحلة من 400000 إلى
800000 حدث في الثانية ، استبدلنا Hadoop في أنقى صوره وخلية Hive ، حيث قام مسؤول تنفيذ الاستعلامات التحليلية ، مع
Spark Streaming ، بكتابة
خريطة عامة / تقليل وحساب إضافي للقياسات. منذ 3 سنوات
قلت كيف فعلنا ذلك. بعد ذلك بدا لنا أن سبارك ستعيش إلى الأبد ، لكن الحياة قضت بخلاف ذلك - واجهنا قيود Hadoop. ربما لو كانت لدينا ظروف أخرى ، فسنواصل العيش مع Hadoop.
هناك مشكلة أخرى ، بالإضافة إلى حساب الرسوم البيانية على Hadoop ، وهي استعلامات SQL المكونة من أربعة طوابق والتي كان يقودها المحللون ، ولم يتم تحديث الرسوم البيانية بسرعة. والحقيقة هي أن هناك مهمة صعبة إلى حد ما مع معالجة البيانات التشغيلية ، بحيث يكون الوقت الحقيقي وسريع وبارد.
يخدم Badoo مركزان للبيانات يقعان على جانبي المحيط الأطلسي - في أوروبا وأمريكا الشمالية. لإنشاء تقرير موحد ، تحتاج إلى إرسال بيانات من أمريكا إلى أوروبا. في مركز البيانات الأوروبي نحافظ على جميع إحصاءات الإحصاءات ، لأن هناك قوة حسابية أكبر.
إن جولة ذهابًا وإيابًا بين مراكز البيانات التي تبلغ حوالي
200 مللي ثانية - الشبكة حساسة إلى حد ما - لا يكون تقديم طلب إلى وحدة تحكم أخرى (DC) مختلفًا عن الذهاب إلى الحامل التالي.
عندما بدأنا في إضفاء الطابع الرسمي على الأحداث والمطورين ، وتورط مدراء المنتجات ، أعجب الجميع بكل شيء - كان هناك
نمو هائل للأحداث . في هذا الوقت ، حان الوقت لشراء الحديد في المجموعة ، لكننا لم نرغب حقًا في القيام بذلك.
عندما تجاوزنا ذروة
800000 حدث في الثانية ، اكتشفنا ما قام Yandex بتحميله إلى OpenSource
ClickHouse ، وقررنا تجربته.
لقد ملأوا مجموعة من المخاريط بينما كانوا يحاولون القيام بشيء ما ، ونتيجة لذلك ، عندما كان كل شيء يعمل ، قاموا باستقبال بوفيه صغير حول أول مليون حدث. من المحتمل أن يكون ClickHouse قد أنهى التقرير.
فقط خذ ClickHouse وتعيش معه.
لكن هذا ليس مثيرًا للاهتمام ، لذلك سنواصل الحديث عن معالجة البيانات.
كليك هاوس
ClickHouse عبارة عن ضجيج خلال العامين الماضيين ولا يلزم تقديمه: فقط في HighLoad ++ في عام 2018 أتذكر
خمسة تقارير حول هذا الموضوع ، فضلاً عن الندوات والاجتماعات.
تم تصميم هذه الأداة لحل تلك المهام التي حددناها لأنفسنا تمامًا. هناك
تحديث حقيقي ورقائق تلقيناها في وقت واحد من Hadoop: النسخ المتماثل والمشاركة. لم يكن هناك أي سبب لعدم محاولة ClickHouse ، لأنهم فهموا أنه مع تطبيق Hadoop ، فقد كسرنا بالفعل القاع. الأداة رائعة ، والتوثيق عادة ما يكون حريقًا - لقد كتبت هناك بنفسي ، وأنا حقًا أحب كل شيء ، وكل شيء رائع. ولكن كان علينا حل عدد من القضايا.
كيفية تحويل التدفق الكامل للأحداث في ClickHouse؟ كيفية الجمع بين البيانات من اثنين من مراكز البيانات؟ من حقيقة أننا وصلنا إلى المشرفين وقلنا: "يا شباب ، دعنا نثبت برنامج ClickHouse" ، لن يجعلوا الشبكة سُمكها مرتين ، ويكون التأخير هو النصف. لا ، لا تزال الشبكة رفيعة وصغيرة مثل الراتب الأول.
كيفية تخزين النتائج ؟ في Hadoop ، فهمنا كيفية رسم الرسومات - ولكن كيف نفعل ذلك على ClickHouse السحري؟ عصا سحرية غير المدرجة.
كيفية تقديم النتائج لتخزين السلاسل الزمنية؟
كما قال محاضرتي في المعهد ، فكر في 3 مخططات بيانات: استراتيجية ومنطقية ومادية.
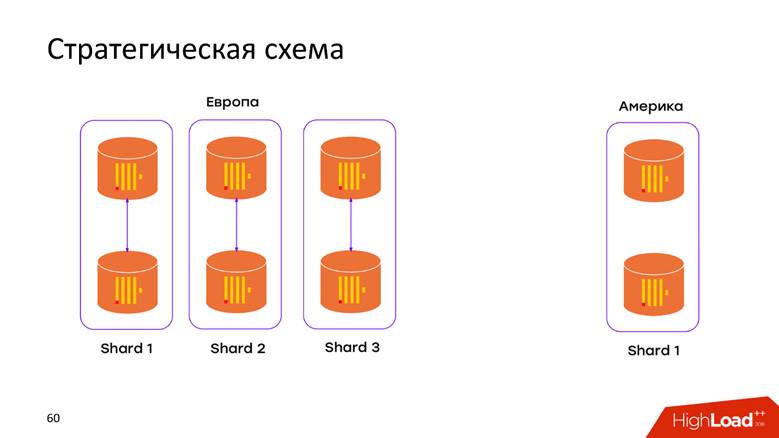
مخطط التخزين الاستراتيجي
لدينا
2 مراكز البيانات . لقد تعلمنا أن ClickHouse لا يعرف شيئًا عن البلدان النامية ، وقد اخترعنا المجموعة في كل العاصمة. الآن
لا تنتقل البيانات عبر كابل المحيط الأطلسي - يتم تخزين جميع البيانات التي حدثت في العاصمة محليًا في نظامها. عندما نريد تقديم طلب على البيانات المدمجة ، على سبيل المثال ، لاكتشاف عدد التسجيلات الموجودة في كلا DC ، يتيح لنا ClickHouse هذه الفرصة. الكمون المنخفض وتوافر الطلب - مجرد تحفة!
مخطط التخزين الفعلي
مرة أخرى ، الأسئلة: كيف ستندرج بياناتنا في نموذج العلاقة ClickHouse ، ما الذي يجب القيام به حتى لا تفقد النسخ المتماثل والمشاركة؟ كل شيء موصوف على نطاق واسع في
وثائق ClickHouse ، وإذا كان لديك أكثر من خادم ،
فستصادف هذه المقالة. لذلك ، لن نتعمق في ما هو موجود في الدليل: النسخ المتماثل والمشاركة والاستعلام لجميع البيانات على القطع.
منطق التخزين
المخطط المنطقي هو الأكثر إثارة للاهتمام. في خط أنابيب واحد نقوم بمعالجة الأحداث غير المتجانسة. هذا يعني أن لدينا مجموعة
من الأحداث غير المتجانسة : التسجيل ، الصوت ، تحميل الصور ، المقاييس الفنية ، تتبع سلوك المستخدم - كل هذه الأحداث لها
سمات مختلفة تمامًا. على سبيل المثال ، نظرت إلى الشاشة على هاتف محمول - أحتاج إلى معرف شاشة ، لقد قمت بالتصويت لصالح شخص ما - يجب أن تفهم ما إذا كان التصويت مؤيدًا أم لا. كل هذه الأحداث لها سمات مختلفة ، يتم رسم رسوم بيانية مختلفة عليها ، ولكن يجب معالجة كل هذا في خط أنابيب واحد. كيفية وضعه في نموذج ClickHouse؟
النهج رقم 1 - في جدول الحدث. في هذا النهج الأول ، استندنا إلى التجربة المكتسبة من MySQL - لقد أنشأنا
قرصًا لكل حدث في ClickHouse. هذا يبدو منطقيا إلى حد ما ، ولكن واجهنا عددا من الصعوبات.
ليس لدينا أي قيود على أن الحدث سوف يغير هيكله عندما يتم إصدار بناء اليوم. يمكن أن يتم هذا التصحيح من قبل أي مطور. المخطط قابل للتغيير بشكل عام في جميع الاتجاهات.
الحقل المطلوب الوحيد هو
حدث الطابع الزمني وما كان الحدث. كل شيء آخر يتغير على الطاير ، وبالتالي ، فإن هذه اللوحات تحتاج إلى تعديل. لدى ClickHouse القدرة على تنفيذ
ALTER على كتلة ، ولكن هذا إجراء دقيق دقيق يصعب أتمتة لجعله يعمل بسلاسة. لذلك ، هذا ناقص.
لدينا أكثر من ألف حدث مختلف ، مما يعطينا
معدل إدراج عالي لكل جهاز - نسجل باستمرار جميع البيانات في الألف جدول. ل ClickHouse ، وهذا هو نمط مضاد. إذا كان لدى بيبسي شعار - "العيش في رشفات كبيرة" ، فعندها ClickHouse -
"عيش دفعة كبيرة" . إذا لم يتم ذلك ، فسيتم اختناق النسخ المتماثل ، يرفض ClickHouse قبول إدخالات جديدة - وهو مخطط غير سار.
النهج رقم 2 - طاولة واسعة . حاول رجال سيبيريا الانزلاق بالمنشار على السكك الحديدية وتطبيق نموذج بيانات مختلف. نصنع جدولًا يحتوي على
ألف عمود ، حيث يحتوي كل حدث على أعمدة مخصصة لبياناته. لدينا
جدول متفرق ضخم - لحسن الحظ ، هذا لم يتجاوز بيئة التطوير ، لأنه من البداية ، أصبح من الواضح أن المخطط سيئ للغاية ، ولن نفعل ذلك.
لكن ما زلت أرغب في استخدام مثل هذا البرنامج الرائع للبرامج ، وأكثر من ذلك بقليل حتى النهاية - وسيكون ما تحتاجه.
النهج رقم 3 - الجدول العام. لدينا جدول ضخم واحد نقوم فيه بتخزين البيانات في صفائف ، لأن ClickHouse يدعم
أنواع البيانات غير القياسية. بمعنى أننا نبدأ عمودًا يتم فيه تخزين أسماء السمات ، وعمود منفصل به صفيف يتم تخزين قيم السمات فيه.
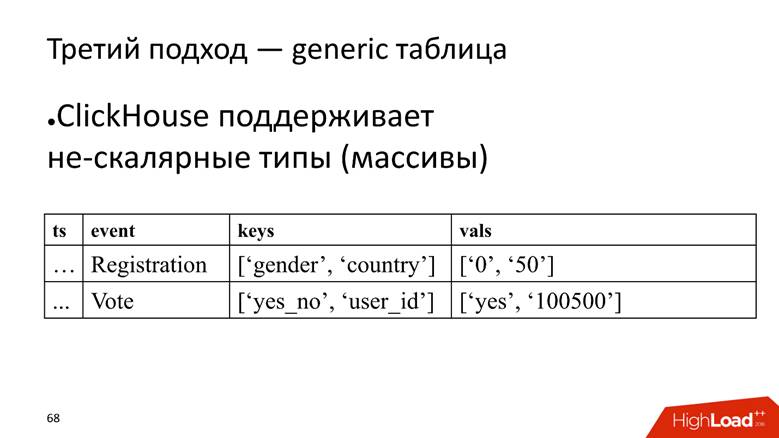
ClickHouse هنا يؤدي مهمتها بشكل جيد للغاية. إذا كان علينا فقط إدخال البيانات ، فمن المحتمل أن نضغط 10 مرات إضافية في التثبيت الحالي.
ومع ذلك ، فإن ذبابة في المرهم هو أنه أيضا مضاد للنمط ل ClickHouse -
لتخزين صفيف سلاسل . يعد هذا أمرًا سيئًا لأن صفيف الصفوف تشغل
مساحة أكبر على القرص - فهي تتقلص بشكل أسوأ من الأعمدة البسيطة
وتصعب معالجتها . ولكن لمهمتنا ، نحن نغمض أعيننا عن هذا ، لأن المزايا تفوق.
كيفية جعل اختيار من هذا الجدول؟ مهمتنا هي حساب التسجيلات المصنفة حسب الجنس. تحتاج أولاً إلى العثور في صفيف على الموضع الذي يتوافق مع عمود النوع ، ثم الصعود إلى عمود آخر بهذا الفهرس والحصول على البيانات.
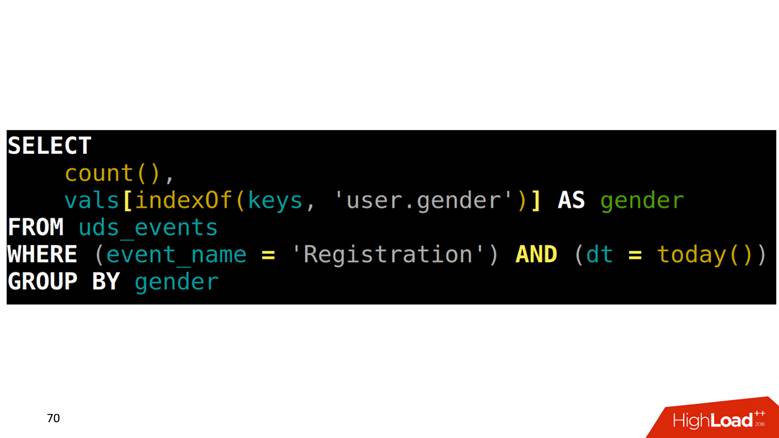
كيفية رسم الرسوم البيانية على هذه البيانات
نظرًا لأن جميع الأحداث موصوفة ، فهي تحتوي على بنية صارمة ، فإننا نقوم بتكوين استعلام SQL مكون من أربعة طوابق لكل نوع من الأحداث ، وننفذه ونحفظ النتائج في جدول آخر.
المشكلة هي أنه لرسم نقطتين متجاورتين على الرسم البياني ، تحتاج إلى
مسح الجدول بأكمله . مثال: نحن ننظر إلى التسجيل في اليوم الواحد. هذا الحدث من السطر العلوي إلى الأخير قبل الأخير. الممسوحة ضوئيا مرة واحدة - ممتازة. بعد 5 دقائق ، نريد أن نرسم نقطة جديدة على المخطط - مرة أخرى ، نقوم بمسح نطاق البيانات الذي يتقاطع مع المسح السابق ، وهكذا لكل حدث. تبدو منطقية ، لكنها لا تبدو رائعة.
بالإضافة إلى ذلك ، عندما نأخذ بعض الأسطر ، نحتاج أيضًا إلى
قراءة النتائج تحت التجميع . على سبيل المثال ، هناك حقيقة أن خادم الله تم تسجيله في الدول الاسكندنافية وكان رجلاً ، ونحن بحاجة إلى حساب الإحصائيات الموجزة: كم عدد التسجيلات ، وعدد الرجال ، وعددهم من الناس ، وعددهم من النرويج. يسمى هذا من حيث قواعد البيانات التحليلية
ROLLUP و CUBE و
GROUPING SETS - تحويل سطر واحد إلى عدة.
كيفية علاج
لحسن الحظ ، لدى ClickHouse أداة لحل هذه المشكلة ، وهي
الحالة المتسلسلة للوظائف التجميعية . هذا يعني أنه يمكنك مسح جزء من البيانات مرة واحدة وحفظ هذه النتائج. هذه هي
ميزة القاتل . قبل 3 سنوات فعلنا هذا بالضبط في Spark و Hadoop ، ومن الرائع أنه بالتوازي معنا ، قامت أفضل عقول Yandex بتطبيق التناظرية في ClickHouse.
طلب بطيء
لدينا طلب بطيء - لحساب المستخدمين الفريدين لهذا اليوم والأمس.
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
في المستوى المادي ، يمكننا أن نجعل SELECT للولاية ليوم أمس ، والحصول على تمثيلها الثنائي ، وحفظه في مكان ما.
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
لليوم ، نحن فقط نغير الشرط الذي سيكون عليه اليوم:
'yyy' AS ts و
WHERE dt = today() و timestamp سوف نسميها "xxx" و "yyy". , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
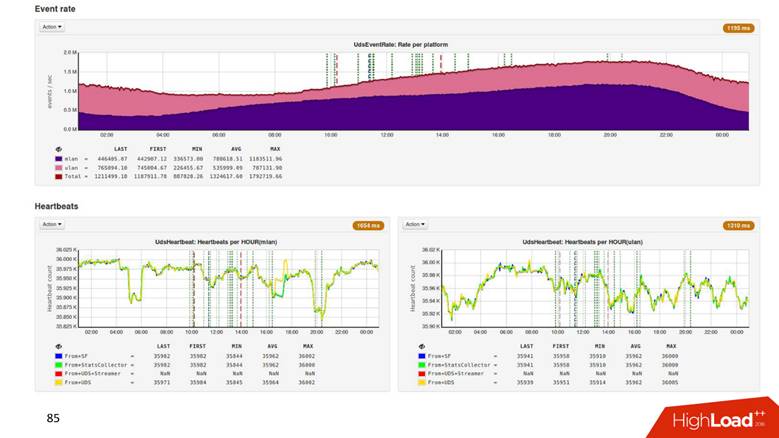
8 ClickHouse , 6 - , 2 : 2 — , .
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
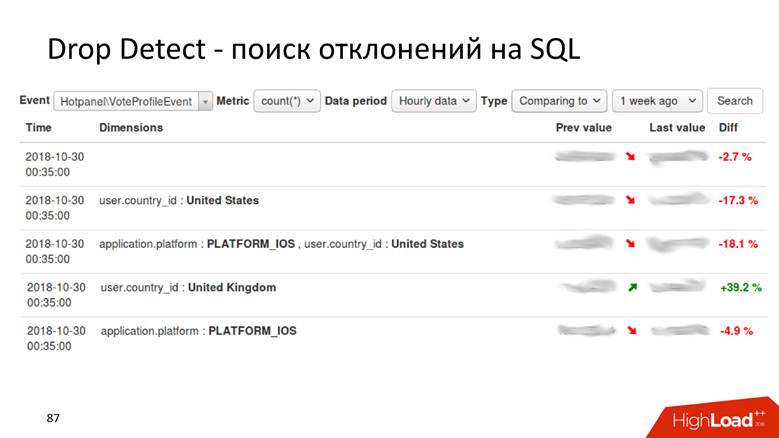
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
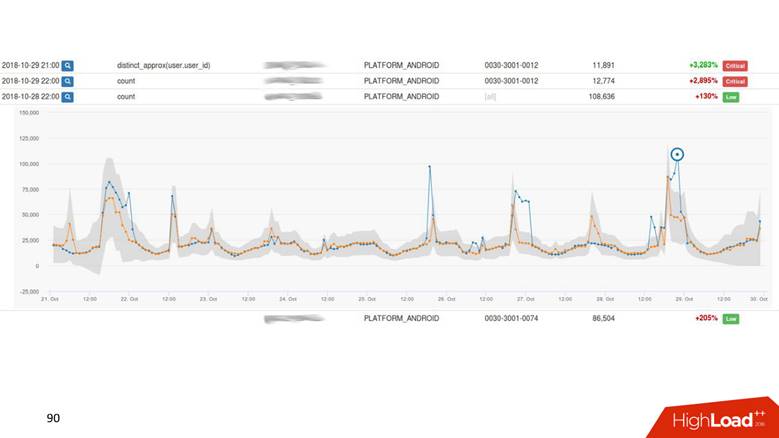
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .