
الأدوات التقليدية في مجال علوم البيانات هي لغات مثل R و Python - صيغة بناء مريحة وعدد كبير من المكتبات للتعلم الآلي ومعالجة البيانات تتيح لك الحصول بسرعة على بعض حلول العمل. ومع ذلك ، هناك حالات تصبح فيها قيود هذه الأدوات عقبة كبيرة - أولاً وقبل كل شيء ، إذا كان من الضروري تحقيق أداء عالٍ في سرعة المعالجة و / أو العمل مع مجموعات البيانات الكبيرة حقًا. في هذه الحالة ، يتعين على الأخصائي الرجوع على مضض إلى مساعدة "الجانب المظلم" وتوصيل الأدوات بلغات البرمجة "الصناعية": Scala و Java و C ++ .
لكن هل هذا الجانب مظلم؟ على مدار سنوات التطوير ، قطعت أدوات علم البيانات "الصناعي" شوطًا طويلًا ، وهي اليوم مختلفة تمامًا عن إصداراتها الخاصة قبل 2-3 سنوات. دعونا نحاول استخدام مثال مهمة SNA Hackathon 2019 لمعرفة مدى توافق النظام البيئي Scala + Spark مع Python Data Science.
ضمن إطار SNA Hackathon 2019 ، يحل المشاركون مشكلة فرز موجز الأخبار لمستخدم شبكة اجتماعية في واحد من "التخصصات" الثلاثة: استخدام البيانات من النصوص أو الصور أو سجلات الميزات. في هذا المنشور ، سننظر في كيفية حل مشكلة في Spark على أساس سجل من العلامات باستخدام أدوات تعلم الآلة الكلاسيكية.
في حل المشكلة ، سنذهب بالطريقة القياسية التي يمر بها أي متخصص في تحليل البيانات عند تطوير نموذج:
- سنقوم بتحليل بيانات البحث ، بناء الرسوم البيانية.
- نقوم بتحليل الخصائص الإحصائية للعلامات في البيانات ، وننظر في اختلافاتهم بين مجموعات التدريب والاختبار.
- سنقوم بإجراء اختيار مبدئي للميزات بناءً على الخصائص الإحصائية.
- نحسب الارتباطات بين العلامات والمتغير المستهدف ، بالإضافة إلى الارتباط المتبادل بين العلامات.
- سنقوم بتشكيل المجموعة النهائية من الميزات ، وتدريب النموذج والتحقق من جودته.
- دعونا نحلل الهيكل الداخلي للنموذج لتحديد نقاط النمو.
خلال "رحلتنا" ، سنتعرف على أدوات مثل مفكرة Zeppelin التفاعلية ، ومكتبة تعلم آلة Spark ML وملحقها PravdaML ، وحزمة GraphX الرسومية ، ومكتبة التصور فيغاس ، وبالطبع Apache Spark بكل مجدها: ) تتوفر جميع نتائج التعليمات البرمجية والتجربة على منصة Zepl دفتر الملاحظات التعاونية.
تحميل البيانات
إن خصوصية البيانات الموضوعة في SNA Hackathon 2019 هي أنه من الممكن معالجتها مباشرة باستخدام Python ، لكنها صعبة: البيانات الأصلية معبأة بكفاءة عالية بفضل إمكانيات تنسيق عمود Apache Parquet وعند فك ضغطها في الذاكرة "بواسطة الجبين" ، يتم فك ضغطها في عدة عشرات من الجيجابايت. عند العمل مع Apache Spark ، ليست هناك حاجة لتحميل البيانات بشكل كامل في الذاكرة ، تم تصميم بنية Spark لمعالجة البيانات على شكل أجزاء ، والتحميل من القرص حسب الحاجة.
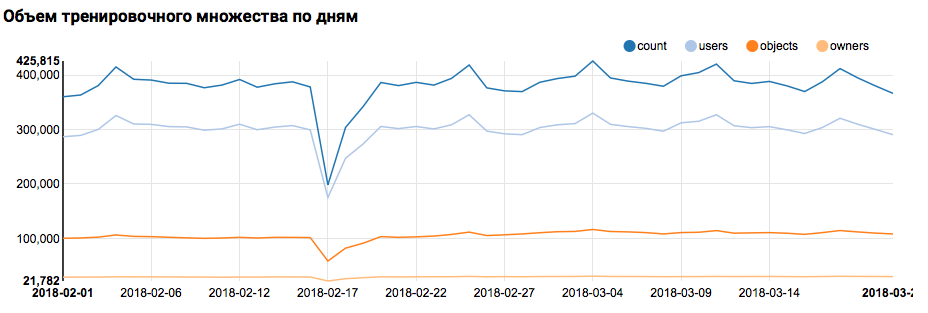
لذلك ، فإن الخطوة الأولى - التحقق من توزيع البيانات حسب اليوم - يتم تنفيذها بسهولة بواسطة أدوات محاصر:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
ماذا سيعرض الرسم البياني المقابل في زيبلين:
يجب أن أقول أن بناء جملة Scala مرن جدًا ، وقد يبدو الرمز نفسه ، على سبيل المثال ، كما يلي:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
يجب تقديم تحذير هام هنا: عند العمل في فريق كبير ، حيث يتعامل الجميع مع كتابة كود Scala حصريًا من وجهة نظرهم الخاصة ، يكون التواصل أكثر صعوبة. لذلك من الأفضل تطوير مفهوم موحد لأسلوب الشفرة.
لكن العودة إلى مهمتنا. أظهر تحليل بسيط يوميًا وجود نقاط غير طبيعية يومي 17 و 18 فبراير. ربما في هذه الأيام قد تم جمع بيانات غير كاملة وقد يكون توزيع السمات متحيزًا. ينبغي أن يؤخذ هذا في الاعتبار في مزيد من التحليل. بالإضافة إلى ذلك ، من اللافت للنظر أن عدد المستخدمين الفريدين قريب جدًا من عدد الكائنات ، لذلك فمن المنطقي دراسة توزيع المستخدمين بأعداد مختلفة من الكائنات:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
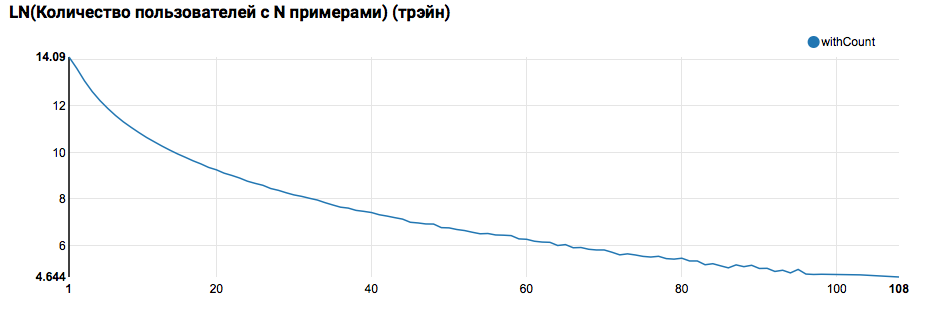
من المتوقع أن ترى توزيعًا قريبًا من الأسي ، وذيل طويل جدًا. في مثل هذه المهام ، كقاعدة عامة ، من الممكن تحقيق تحسن في جودة العمل من خلال تقسيم النماذج للمستخدمين ذوي مستويات مختلفة من النشاط. للتحقق مما إذا كان الأمر يستحق القيام بذلك ، قارن توزيع عدد الكائنات حسب المستخدم في مجموعة الاختبار:
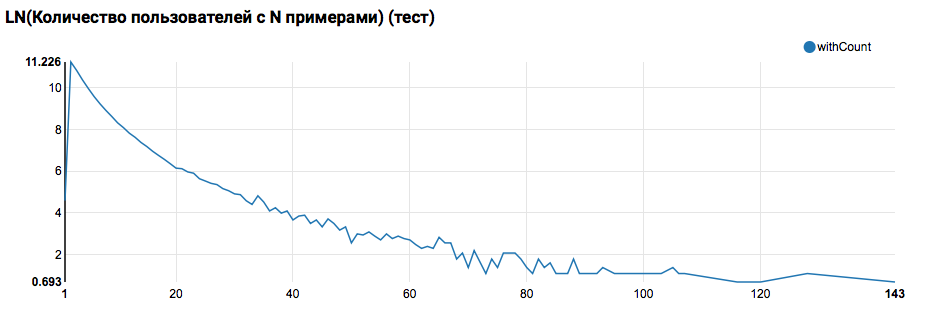
تشير المقارنة مع الاختبار إلى أن مستخدمي الاختبار لديهم كائنين على الأقل في السجلات (نظرًا لأن مشكلة التصنيف قد تم حلها على hackathon ، فهذا شرط ضروري لتقييم الجودة). في المستقبل ، أوصي بالنظر عن كثب إلى المستخدمين في مجموعة التدريب ، والتي نعلن عن وظيفة معرف المستخدم بها مع عامل تصفية:
يجب أيضًا تقديم ملاحظة مهمة: من وجهة نظر تعريف UDF أن استخدام Spark من تحت Scala / Java ومن تحت Python مختلف تمامًا. بينما يستخدم رمز PySpark الوظيفة الأساسية ، يعمل كل شيء بالسرعة تقريبًا ، ولكن عندما تظهر الوظائف المهجورة ، فإن أداء PySpark يتحلل بترتيب من حيث الحجم.
أول خط أنابيب ML
في الخطوة التالية ، سنحاول حساب الإحصاءات الأساسية عن الإجراءات والسمات. لكن لهذا نحتاج إلى قدرات SparkML ، لذا سننظر أولاً في بنيتها العامة:

تم بناء SparkML على أساس المفاهيم التالية:
- المحول - يأخذ مجموعة بيانات كمدخلات ويعيد مجموعة معدلة (تحويل). كقاعدة عامة ، يتم استخدامه لتنفيذ خوارزميات ما قبل وما بعد المعالجة ، واستخراج المعالم ، ويمكن أن تمثل أيضًا نماذج ML الناتجة.
- مقدّر - يأخذ مجموعة بيانات كمدخلات ، ويعيد المحول (مناسب). بطبيعة الحال ، يمكن أن مقدّر تمثل خوارزمية ML.
- خط الأنابيب هو حالة خاصة لـ Estimator ، وتتكون من سلسلة من المحولات والمقدرات. عندما يتم استدعاء الأسلوب ، يمر fit عبر السلسلة ، وإذا رأى محولًا ، فإنه يطبقه على البيانات ، وإذا رأى مقدرًا ، فإنه يدرب المحول ويطبقه على البيانات ويذهب أبعد من ذلك.
- PipelineModel - نتيجة Pipeline تحتوي أيضًا على سلسلة من الداخل ، ولكن تتكون حصريًا من محولات. وفقا لذلك ، PipelineModel نفسه هو أيضا محول.
مثل هذا النهج في تشكيل خوارزميات ML يساعد على تحقيق هيكل وحدات واضح واستنساخ جيد - يمكن حفظ كل من النماذج وخطوط الأنابيب.
بادئ ذي بدء ، سنقوم ببناء خط أنابيب بسيط نحسب به إحصاءات توزيع الإجراءات (حقل الملاحظات) للمستخدمين في مجموعة التدريب:
val feedbackAggregator = new Pipeline().setStages(Array(
في خط الأنابيب هذا ، يتم استخدام وظيفة PravdaML بنشاط - المكتبات التي تحتوي على كتل مفيدة ممتدة لـ SparkML ، وهي:
- يستخدم MultinominalExtractor لتشفير حرف من النوع "مجموعة من السلاسل" في متجه وفقًا لمبدأ hot-one. هذا هو المقدر الوحيد في خط الأنابيب (لإنشاء تشفير ، يجب عليك جمع خطوط فريدة من مجموعة البيانات).
- يستخدم VectorStatCollector لحساب إحصائيات المتجهات.
- يستخدم VectorExplode لتحويل النتيجة إلى تنسيق مناسب للتصور.
ستكون نتيجة العمل عبارة عن رسم بياني يوضح أن الفئات الموجودة في مجموعة البيانات غير متوازنة ، ومع ذلك ، فإن عدم التوازن للفئة التي أعجبت بالهدف ليس متطرفًا:

يوضح تحليل التوزيع المماثل بين المستخدمين المشابهين للاختبار (لديهم "موجب" و "سلبي" في السجلات) أنه متحيز للفئة الموجبة:
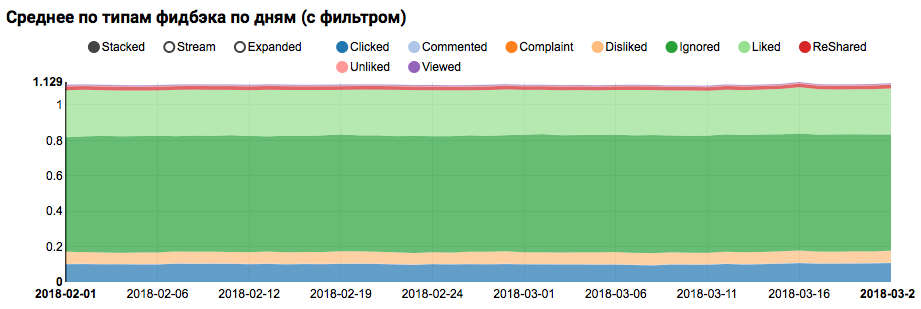
التحليل الإحصائي للعلامات
في المرحلة التالية ، سنقوم بإجراء تحليل مفصل للخصائص الإحصائية للسمات. هذه المرة نحتاج إلى ناقل أكبر:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
منذ الآن نحن بحاجة إلى العمل ليس مع حقل منفصل ، ولكن مع كل السمات في وقت واحد ، سوف نستخدم اثنين من الأدوات المساعدة PravdaML أكثر فائدة:
- يسمح لك NullToDefaultReplacer باستبدال العناصر المفقودة في البيانات بقيمها الافتراضية (0 للأرقام ، خطأ للمتغيرات المنطقية ، إلخ). إذا لم تقم بهذا التحويل ، فستظهر قيم NaN في المتجهات الناتجة ، وهو أمر مميت بالنسبة للعديد من الخوارزميات (على سبيل المثال ، يمكن لـ XGBoost البقاء على قيد الحياة). بديل عن استبدال الأصفار يمكن استبداله بالمتوسطات ، يتم تطبيق ذلك في NaNToMeanReplacerEstimator.
- AutoAssembler عبارة عن أداة مساعدة قوية للغاية تقوم بتحليل تخطيط الجدول ولكل عمود تحديد نظام vectorization يطابق نوع العمود.
باستخدام خط الأنابيب الناتج ، نحسب الإحصائيات لثلاث مجموعات (التدريب ، التدريب باستخدام فلتر المستخدم والاختبار) وحفظها في ملفات منفصلة:
بعد تلقي ثلاث مجموعات بيانات مع إحصائيات السمات ، نقوم بتحليل الأشياء التالية:
- هل لدينا علامات على وجود انبعاثات كبيرة.
- يجب أن تكون هذه العلامات محدودة ، أو يجب تصفية السجلات الخارجية. - هل لدينا علامات مع وجود انحياز كبير للمتوسط بالنسبة إلى الوسيط.
- يحدث مثل هذا التحول في كثير من الأحيان في وجود توزيع الطاقة ، فمن المنطقي لوغاريتم هذه العلامات. - هل هناك تحول في متوسط التوزيعات بين التدريب واختبار مجموعات.
- كيف تملأ بإحكام المصفوفة ميزة لدينا.
لتوضيح هذه الجوانب ، سيساعدنا هذا الطلب:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
في هذه المرحلة ، يكون السؤال المرئي أمرًا ملحًا: من الصعب عرض جميع الجوانب على الفور باستخدام أدوات Zeppelin العادية ، وتبدأ أجهزة الكمبيوتر المحمولة التي تحتوي على عدد كبير من الرسوم البيانية في التباطؤ بشكل ملحوظ بسبب DOM المتضخمة. يمكن لمكتبة Vegas - DSL في Scala لبناء مواصفات vega-lite حل هذه المشكلة. لا يوفر Vegas إمكانيات تصوير أكثر ثراءً (قابلة للمقارنة مع matplotlib) ، بل يرسمها أيضًا على Canvas دون تضخيم DOM :).
ستبدو مواصفات المخطط الذي نحن مهتمون به كما يلي:
vegas.Vegas(width = 1024, height = 648)
يجب أن يكون المخطط أدناه كما يلي:
- يُظهر محور X تحول مراكز التوزيع بين مجموعات الاختبار والتدريب (أقرب إلى 0 ، كانت العلامة أكثر ثباتًا).
- يتم رسم النسبة المئوية للعناصر غير الصفرية على طول المحور ص (كلما زاد عدد البيانات الموجودة في العدد الأكبر من النقاط حسب السمة).
- يوضح الحجم إزاحة المتوسط بالنسبة إلى الوسيط (كلما كانت النقطة أكبر ، زاد توزيع قانون الطاقة على الأرجح).
- يشير اللون إلى الانبعاثات (الأكثر احمرارًا ، والمزيد من الانبعاثات).
- حسنًا ، يتميز النموذج بوضع المقارنة: باستخدام مرشح مستخدم في مجموعة التدريب أو بدون مرشح.
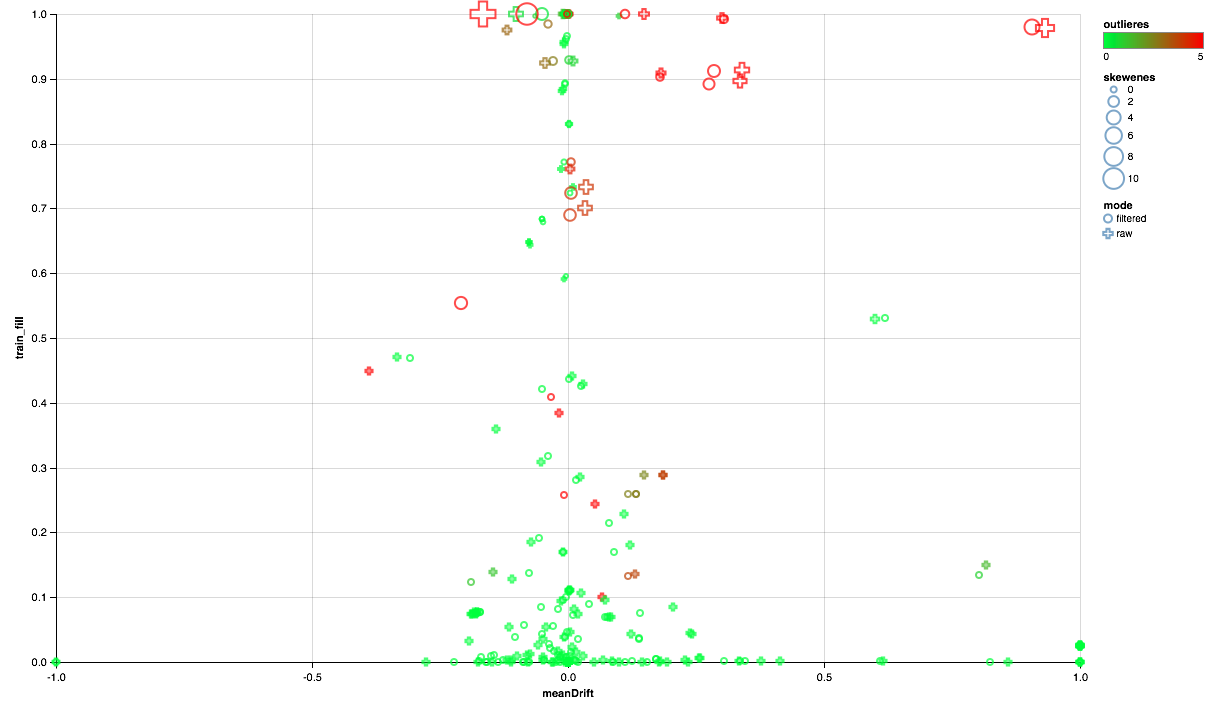
لذلك ، يمكننا استخلاص النتائج التالية:
- تحتاج بعض العلامات إلى مرشح للانبعاثات - سنحدد الحد الأقصى للقيم المئوية التسعين.
- تظهر بعض العلامات توزيعة قريبة من الأسي - سنتخذ اللوغاريتم.
- لا يتم تقديم بعض الميزات في الاختبار - سنستبعدها من التدريب.
تحليل الارتباط
بعد الحصول على فكرة عامة حول كيفية توزيع السمات وكيفية ارتباطها بين التدريب واختبار مجموعات ، دعونا نحاول تحليل الارتباطات. للقيام بذلك ، قم بتكوين مستخرج الميزة استنادًا إلى الملاحظات السابقة:
من بين الأجهزة الجديدة في خط الأنابيب هذا ، تجذب الأداة المساعدة SQLTransformer الانتباه ، مما يسمح بتحويلات SQL التعسفية لجدول الإدخال.
عند تحليل الارتباطات ، من المهم تصفية الضوضاء الناتجة عن الارتباط الطبيعي للميزات الساخنة. للقيام بذلك ، أود أن أفهم ما هي عناصر المتجه التي تتوافق مع أعمدة المصدر. يتم إنجاز هذه المهمة في Spark باستخدام بيانات تعريف العمود (المخزنة مع البيانات) ومجموعات السمات. يتم استخدام كتلة التعليمات البرمجية التالية لتصفية أزواج من أسماء السمات التي تأتي من نفس العمود من النوع String:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
إن وجود مجموعة بيانات مع عمود متجه في متناول اليد ، يعد حساب الارتباطات المتقاطعة باستخدام Spark أمرًا بسيطًا للغاية ، لكن النتيجة هي مصفوفة ، حيث يتعين عليك نشرها قليلاً في مجموعة من الأزواج:
val pearsonCorrelation =
وبالطبع ، التصور: سنحتاج مرة أخرى إلى مساعدة فيغاس لرسم خريطة حرارة:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
والنتيجة هي الأفضل للبحث في Zepl-e . لفهم عام:
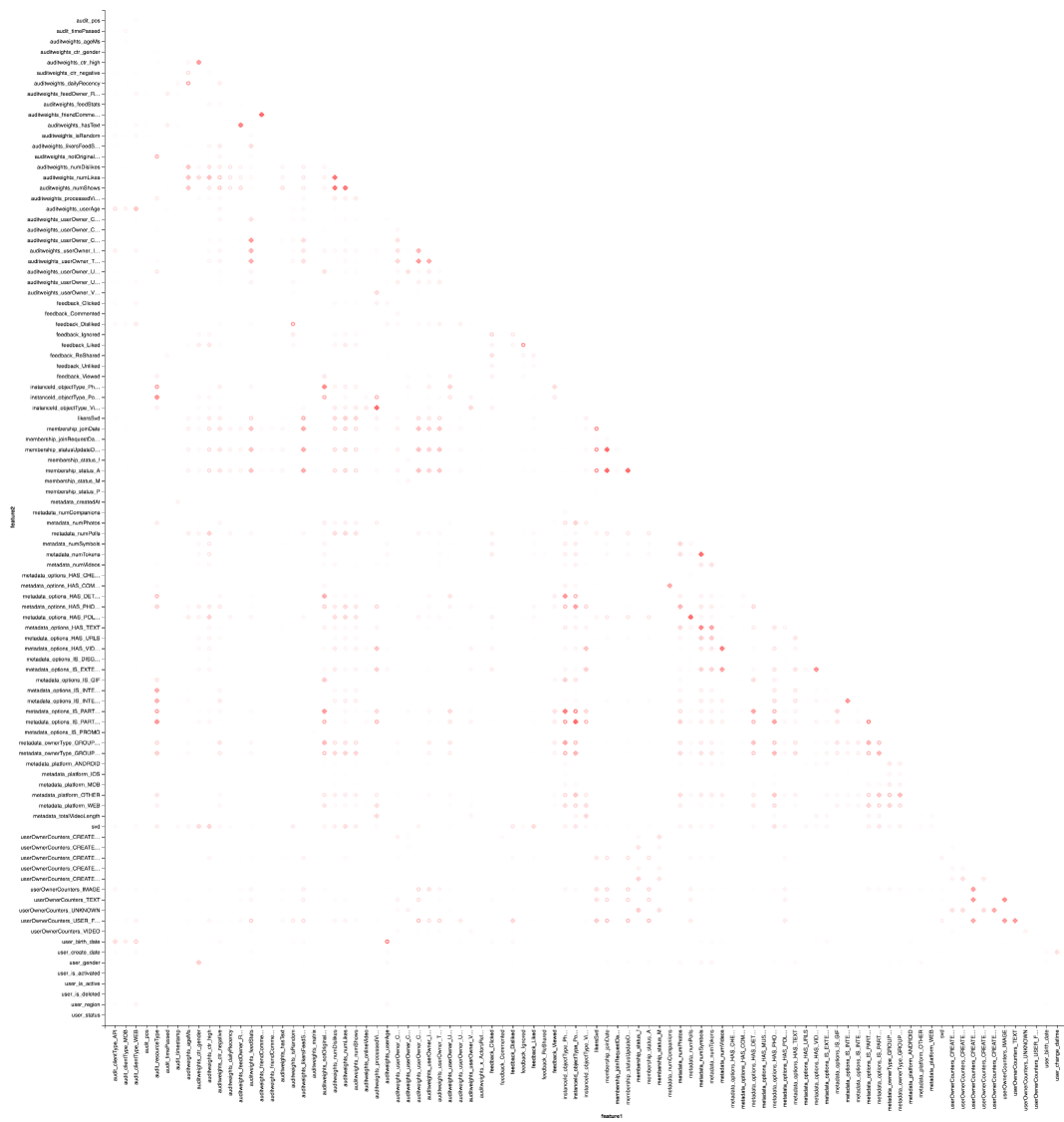
توضح خريطة الحرارة أن هناك بعض الارتباطات بوضوح. دعنا نحاول تحديد كتل الميزات الأكثر ارتباطًا ، لذلك نستخدم مكتبة GraphX : نحول مصفوفة الارتباط إلى رسم بياني ، نقوم بتصفية الحواف حسب الوزن ، وبعد ذلك نجد المكونات المتصلة ونترك المكونات غير القابلة للتحلل فقط (من أكثر من عنصر واحد). يشبه هذا الإجراء أساسًا تطبيق خوارزمية DBSCAN وهو كما يلي:
يتم تقديم النتيجة في شكل جدول:
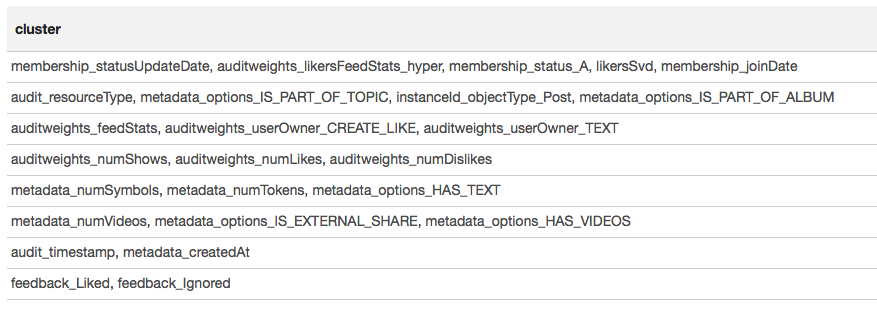
استنادًا إلى نتائج التجميع ، يمكننا أن نستنتج أن المجموعات الأكثر ارتباطًا تتشكل حول العلامات المرتبطة بعضوية المستخدم في المجموعة (membership_status_A) ، وكذلك حول نوع الكائن (مثيلId_objectType). للحصول على أفضل نمذجة تفاعل الإشارات ، من المنطقي تطبيق تجزئة النموذج - لتدريب نماذج مختلفة لأنواع مختلفة من الكائنات ، بشكل منفصل للمجموعات التي يكون المستخدم فيها وليس كذلك.
تعلم الآلة
نحن نقترب من الشيء الأكثر إثارة للاهتمام - التعلم الآلي. خط أنابيب التدريب لأبسط نموذج (الانحدار اللوجستي) باستخدام ملحقات SparkML و PravdaML كما يلي:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
هنا نرى ليس فقط العديد من العناصر المألوفة ، ولكن أيضًا العديد من العناصر الجديدة:
- LogisticRegressionLBFSG هو مقدر مع التدريب الموزعة من الانحدار اللوجستي.
- من أجل تحقيق أقصى قدر من الأداء من خوارزميات ML الموزعة. يجب توزيع البيانات على النحو الأمثل عبر الأقسام. سوف تساعد الأداة المساعدة UnwrappedStage.repartition في هذا الأمر ، بإضافة عملية إعادة تقسيم إلى خط الأنابيب بطريقة لا يتم استخدامها إلا في مرحلة التدريب (بعد كل شيء ، عند بناء التوقعات ، لم تعد ضرورية).
- بحيث النموذج الخطي يمكن أن يعطي نتيجة جيدة. يجب تغيير حجم البيانات ، حيث تكون الأداة المساعدة Scaler.scale مسؤولة. ومع ذلك ، فإن وجود تحويلين خطيين متتاليين (التوسع والضرب بأوزان الانحدار) يؤدي إلى نفقات غير ضرورية ، ومن المرغوب فيه انهيار هذه العمليات. عند استخدام PravdaML ، سيكون الإخراج نموذجًا نظيفًا باستخدام تحويل واحد :).
- حسنًا ، بالطبع ، بالنسبة لهذه الطرز ، فإنك تحتاج إلى عضو مجاني ، نضيفه باستخدام عملية Interceptor.intercept.
يوفر خط الأنابيب الناتج ، المطبق على جميع البيانات ، لكل مستخدم AUC 0.6889 (يتوفر رمز التحقق من الصحة على Zepl ). الآن يبقى تطبيق جميع أبحاثنا: تصفية البيانات ، تحويل الميزات ، ونماذج القطاع. سيبدو خط الأنابيب النهائي كما يلي:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
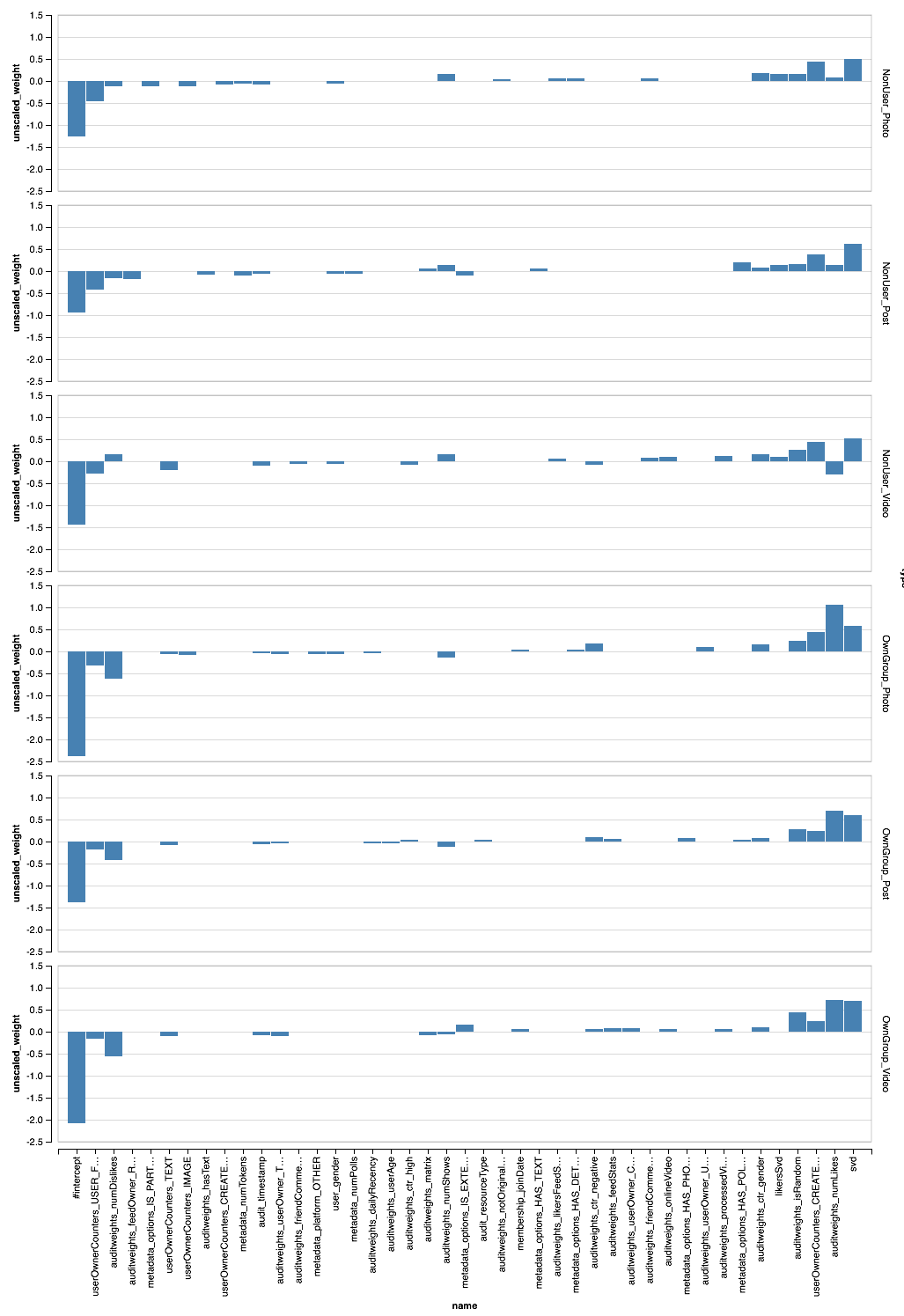
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
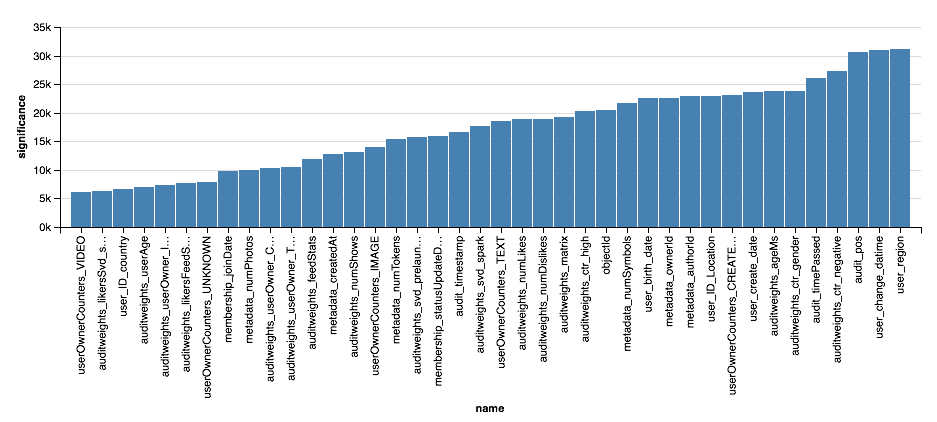
, , XGBoost, , . . , XGBoost , , .
النتائج
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .