وصف المقال الأول
محرك فهرسة PostgreSQL ، والثاني تناول
واجهة أساليب الوصول ، ونحن الآن على استعداد لمناقشة أنواع معينة من الفهارس. لنبدأ مع مؤشر التجزئة.
هاش
هيكل
النظرية العامة
تتضمن الكثير من لغات البرمجة الحديثة جداول التجزئة كنوع البيانات الأساسي. في الخارج ، يشبه جدول التجزئة صفيفًا عاديًا مفهرسًا مع أي نوع بيانات (على سبيل المثال ، سلسلة) بدلاً من رقم صحيح. مؤشر التجزئة في PostgreSQL منظم بطريقة مماثلة. كيف يعمل هذا؟
كقاعدة عامة ، تحتوي أنواع البيانات على نطاقات كبيرة جدًا من القيم المسموح بها: كم عدد السلاسل المختلفة التي يمكن أن نتصورها في عمود من النوع "نص"؟ في الوقت نفسه ، كم عدد القيم المختلفة التي يتم تخزينها بالفعل في عمود نص في بعض الجداول؟ عادة ، ليس الكثير منهم.
فكرة التجزئة هي ربط عدد صغير (من 0 إلى
N − ، قيم
N في المجموع) بقيمة أي نوع بيانات. جمعية مثل هذا يسمى
وظيفة التجزئة . يمكن استخدام الرقم الذي تم الحصول عليه كفهرس للصفيف العادي حيث سيتم تخزين الإشارات إلى صفوف الجدول (TIDs). تسمى عناصر هذه المصفوفة
دلاء جدول التجزئة - يمكن لمجموعة واحدة أن تخزن العديد من TID إذا ظهرت نفس القيمة المفهرسة في صفوف مختلفة.
وكلما كانت دالة التجزئة توزع قيم المصدر بواسطة الجرافات ، كلما كانت أفضل. ولكن حتى دالة هاش جيدة ستنتج في بعض الأحيان نتائج متساوية لقيم مصدر مختلفة - وهذا ما يسمى
تصادم . لذلك ، يمكن لمجموعة واحدة تخزين TIDs المقابلة لمفاتيح مختلفة ، وبالتالي ، يجب إعادة فحص TIDs التي تم الحصول عليها من الفهرس.
على سبيل المثال فقط: ما دالة التجزئة للسلاسل التي يمكن أن نفكر بها؟ اجعل عدد المجموعات يبلغ 256. على سبيل المثال ، رقم الجرافة ، يمكننا أن نأخذ رمز الحرف الأول (بافتراض ترميز حرف أحادي البايت). هل هذه وظيفة تجزئة جيدة؟ من الواضح ، لا: إذا كانت كل السلاسل تبدأ بنفس الحرف ، فسوف تدخل جميعها في مجموعة واحدة ، وبالتالي فإن التوحيد غير وارد ، وستحتاج جميع القيم إلى إعادة الفحص ، ولن يكون التجزئة ذا معنى. ماذا لو نلخص رموز جميع الشخصيات modulo 256؟ سيكون هذا أفضل بكثير ، ولكن أبعد ما يكون عن المثالية. إذا كنت مهتمًا بالوظائف الداخلية لهذه دالة التجزئة في PostgreSQL ، فراجع تعريف hash_any () في
hashfunc.c .
هيكل الفهرس
دعنا نعود إلى مؤشر التجزئة. بالنسبة إلى قيمة بعض أنواع البيانات (مفتاح الفهرس) ، تتمثل مهمتنا في العثور على TID المطابق بسرعة.
عند الإدراج في الفهرس ، لنحسب دالة التجزئة للمفتاح. ترجع دالات التجزئة في PostgreSQL دائمًا نوع "عدد صحيح" ، والذي يتراوح بين 2
32 إلى 4 مليارات قيمة. عدد الجرافات في البداية يساوي اثنين ويزيد ديناميكيًا لضبط حجم البيانات. يمكن حساب رقم الجرافة من شفرة التجزئة باستخدام حساب البت. وهذا هو دلو حيث سنضع TID لدينا.
ولكن هذا غير كافٍ حيث يمكن وضع أرقام TID المطابقة لمفاتيح مختلفة في نفس المجموعة. ماذا سنفعل؟ من الممكن تخزين القيمة المصدر للمفتاح في مجموعة ، بالإضافة إلى TID ، لكن هذا سيزيد بشكل كبير من حجم الفهرس. لتوفير مساحة ، بدلاً من مفتاح ، يقوم الجرافة بتخزين رمز تجزئة المفتاح.
عند البحث من خلال الفهرس ، نقوم بحساب دالة التجزئة للمفتاح والحصول على رقم المجموعة. الآن يبقى أن نستعرض محتويات الدلو وأن نرجع فقط أرقام TID المطابقة لرموز التجزئة المناسبة. يتم ذلك بكفاءة حيث يتم ترتيب أزواج "رمز التجزئة - TID" المخزنة.
ومع ذلك ، قد يحدث مفتاحان مختلفان ليس فقط للوصول إلى مجموعة واحدة ، ولكن أيضًا للحصول على نفس رموز التجزئة ذات الأربع بايتات - لم يتخلص أحد من التصادم. لذلك ، تطلب طريقة الوصول من محرك الفهرسة العام التحقق من كل TID عن طريق إعادة التحقق من الحالة في صف الجدول (يمكن للمحرك القيام بذلك مع فحص الرؤية).
تعيين بنيات البيانات إلى الصفحات
إذا نظرنا إلى فهرس كما تم عرضه من قِبل مدير ذاكرة التخزين المؤقت المخزن المؤقت بدلاً من منظور تخطيط الاستعلام وتنفيذه ، اتضح أنه يجب تجميع جميع المعلومات وكافة صفوف الفهرس في صفحات. يتم تخزين صفحات الفهرس هذه في ذاكرة التخزين المؤقت المخزنة ويتم إخلاؤها من هناك بنفس الطريقة تمامًا مثل صفحات الجدول.
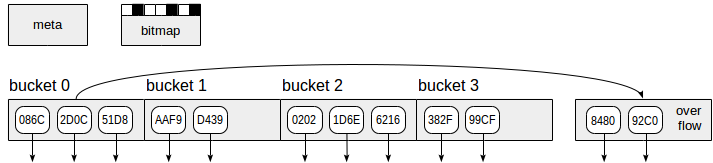
يستخدم مؤشر التجزئة ، كما هو موضح في الشكل ، أربعة أنواع من الصفحات (المستطيلات الرمادية):
- صفحة التعريف - رقم الصفحة صفر ، والتي تحتوي على معلومات حول محتويات الفهرس.
- صفحات المجموعة - الصفحات الرئيسية في الفهرس ، والتي تخزن البيانات كأزواج "كود التجزئة - TID".
- صفحات الفائض - منظمة بنفس طريقة صفحات الجرافة وتستخدم عندما تكون صفحة واحدة غير كافية لمجموعة.
- صفحات الصورة النقطية - التي تتعقب صفحات الفائض الواضحة حاليًا ويمكن إعادة استخدامها للمجموعات الأخرى.
تمثل الأسهم السفلية التي تبدأ من عناصر صفحة الفهرس TID ، أي إشارات إلى صفوف الجدول.
في كل مرة يزيد الفهرس ، ينشئ PostgreSQL على الفور ضعف عدد الدلاء (وبالتالي ، الصفحات) التي تم إنشاؤها مؤخرًا. لتجنب تخصيص هذا العدد الكبير من الصفحات دفعة واحدة ، جعل الإصدار 10 زيادة الحجم أكثر سلاسة. بالنسبة للصفحات الزائدة ، يتم تخصيصها تمامًا عند الحاجة وتتبعها في صفحات الصورة النقطية ، والتي يتم تخصيصها أيضًا عند الحاجة.
لاحظ أن مؤشر التجزئة لا يمكن أن ينقص في الحجم. إذا قمنا بحذف بعض الصفوف المفهرسة ، فلن يتم إرجاع الصفحات التي تم تخصيصها مرة واحدة إلى نظام التشغيل ، ولكن سيتم إعادة استخدامها فقط للبيانات الجديدة بعد VACUUMING. الخيار الوحيد لتقليل حجم الفهرس هو إعادة بنائه من نقطة الصفر باستخدام أمر REINDEX أو VACUUM FULL.
مثال
دعونا نرى كيف يتم إنشاء مؤشر التجزئة. لتجنب وضع جداولنا الخاصة ، من الآن فصاعدًا ، سنستخدم
قاعدة البيانات التجريبية للنقل الجوي ، وهذه المرة سننظر في جدول الرحلات الجوية.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN ---------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (flight_no = 'PG0001'::bpchar) -> Bitmap Index Scan on flights_flight_no_idx Index Cond: (flight_no = 'PG0001'::bpchar) (4 rows)
ما يزعج التطبيق الحالي لمؤشر التجزئة هو أن العمليات مع الفهرس لا يتم تسجيلها في سجل الكتابة المسبق (الذي يحذر PostgreSQL منه عند إنشاء الفهرس). نتيجة لذلك ، لا يمكن استرداد فهارس التجزئة بعد الفشل وعدم المشاركة في النسخ المتماثلة. علاوة على ذلك ، مؤشر التجزئة أقل بكثير من "B-tree" في التنوع ، وكفاءته مشكوك فيها أيضًا. لذلك من غير العملي الآن استخدام مثل هذه الفهارس.
ومع ذلك ، سيتغير هذا في وقت مبكر من خريف هذا العام (2017) بمجرد إصدار الإصدار 10 من PostgreSQL. في هذا الإصدار ، حصل مؤشر التجزئة أخيرًا على دعم لسجل الكتابة المسبقة. بالإضافة إلى ذلك تم تحسين تخصيص الذاكرة وجعل العمل المتزامن أكثر كفاءة.
هذا صحيح. منذ أن حصلت على فهارس PostgreSQL 10 للدعم الكامل ويمكن استخدامها دون قيود. لم يتم عرض التحذير بعد الآن.
دلالات التجزئة
لكن لماذا نجا مؤشر التجزئة تقريبًا من ولادة PostgreSQL إلى 9.6 غير صالحة للاستعمال؟ الشيء هو أن DBMS تستفيد بشكل كبير من خوارزمية التجزئة (على وجه التحديد ، لوصلات وتجمعات التجزئة) ، ويجب أن يكون النظام على دراية بوظيفة hash لتطبيقها على أنواع البيانات. لكن هذه المراسلات ليست ثابتة ، ولا يمكن تعيينها مرة واحدة وإلى الأبد لأن PostgreSQL يسمح بإضافة أنواع جديدة من البيانات بسرعة. وهذه طريقة وصول بواسطة hash ، حيث يتم تخزين هذه المراسلات ، وتمثل ارتباطًا بين الوظائف المساعدة وعائلات المشغلين.
demo=# select opf.opfname as opfamily_name, amproc.amproc::regproc AS opfamily_procedure from pg_am am, pg_opfamily opf, pg_amproc amproc where opf.opfmethod = am.oid and amproc.amprocfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_procedure;
opfamily_name | opfamily_procedure --------------------+-------------------- abstime_ops | hashint4 aclitem_ops | hash_aclitem array_ops | hash_array bool_ops | hashchar ...
على الرغم من أن هذه الدالات غير موثقة ، إلا أنه يمكن استخدامها لحساب رمز التجزئة لقيمة نوع البيانات المناسب. على سبيل المثال ، وظيفة "hashtext" إذا تم استخدامها لعائلة مشغل "text_ops":
demo=# select hashtext('one');
hashtext ----------- 127722028 (1 row)
demo=# select hashtext('two');
hashtext ----------- 345620034 (1 row)
خصائص
دعونا نلقي نظرة على خصائص فهرس التجزئة ، حيث توفر طريقة الوصول هذه للنظام معلومات حول نفسه. قدمنا استفسارات
آخر مرة . الآن لن نتجاوز النتائج:
name | pg_indexam_has_property ---------------+------------------------- can_order | f can_unique | f can_multi_col | f can_exclude | t name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | t name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
لا تحتفظ دالة التجزئة بعلاقة الترتيب: إذا كانت قيمة دالة التجزئة لمفتاح واحد أصغر من المفتاح الآخر ، فمن المستحيل إجراء أي استنتاجات حول كيفية ترتيب المفاتيح نفسها. لذلك ، بشكل عام ، يمكن لمؤشر التجزئة أن يدعم العملية الوحيدة "تساوي":
demo=# select opf.opfname AS opfamily_name, amop.amopopr::regoperator AS opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_operator;
opfamily_name | opfamily_operator ---------------+---------------------- abstime_ops | =(abstime,abstime) aclitem_ops | =(aclitem,aclitem) array_ops | =(anyarray,anyarray) bool_ops | =(boolean,boolean) ...
وبالتالي ، لا يمكن لمؤشر التجزئة إرجاع البيانات المطلوبة ("can_order" ، "قابلة للترتيب"). مؤشر التجزئة لا يعالج NULLs لنفس السبب: العملية "يساوي" لا معنى لـ NULL ("search_nulls").
نظرًا لأن مؤشر التجزئة لا يخزن المفاتيح (ولكن فقط رموز التجزئة الخاصة بهم) ، لا يمكن استخدامه للوصول إلى الفهرس فقط ("يمكن إرجاعه").
لا تدعم طريقة الوصول هذه فهارس متعددة الأعمدة ("can_multi_col") أيضًا.
الداخلية
بدءًا من الإصدار 10 ، سيكون من الممكن البحث في فهرس التجزئة الداخلي من خلال ملحق "
pageinspect ". هذا ما سيبدو عليه:
demo=# create extension pageinspect;
صفحة التعريف (نحصل على عدد الصفوف في الفهرس ورقم المجموعة الأقصى المستخدم):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type ---------------- metapage (1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket ---------+----------- 33121 | 127 (1 row)
صفحة دلو (نحصل على عدد tuples الحية و tuples الميت ، أي تلك التي يمكن الفراغ):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type ---------------- bucket (1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items ------------+------------ 407 | 0 (1 row)
و هكذا. لكن من الصعب تحديد معنى جميع الحقول المتاحة دون فحص الكود المصدري. إذا كنت ترغب في القيام بذلك ، يجب أن تبدأ بـ
README .
اقرأ على .