سوف أتحدث في هذه المقالة عن الألغام المزروعة تحت الأداء ، وكذلك عن اكتشافها (ويفضل حتى قبل الانفجار) وإزالتها.
ما هو لي؟
لنبدأ بما يكمن في أصول أي معرفة - بالتعريف. قال القدماء إن التسمية بشكل صحيح تعني الفهم بشكل صحيح. أعتقد أنه من الأفضل التعبير عن تعريف المنجم قيد الأداء من خلال مقارنته بخطأ واضح ، على سبيل المثال ، هذا:
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
يدرك حتى المطورون المبتدئون أن الخطوط غير قابلة للتغيير ، وأن لصقها معًا في حلقة لا يعني إضافة بيانات إلى ذيل سطر موجود ، ولكن إنشاء سطر جديد مع كل مرور. إذا كنت مخطئًا ، فعندئذ لا تحبط - فإن "الفكرة" ستحذرك فورًا من الخطر ، وسيغمر "السونار" التجمع الخاص بك بالتأكيد.
لكن هذا الكود سوف يجذب انتباهًا أقل ، وستظل الفكرة ( قبل الإصدار 2018.2 ) صامتة:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
المشكلة هنا هي نفسها: مغلفات الأنواع البسيطة غير قابلة للتغيير ، مما يعني إضافة 5 وحدات إلى رقم الكائن يعني إنشاء غلاف جديد وكتابة الرقم 6 فيه.
النكتة هنا هي وجود في Java تمثيلان لأنواع معينة من البيانات - بسيطة وممتعة ، بالإضافة إلى التحويل التلقائي بواسطة اللغة نفسها. ولهذا السبب ، يعتقد العديد من مطوري المبتدئين شيئًا من هذا القبيل: "حسنًا ، التنفيذ يحولهم بطريقة ما إلى هناك بمفرده ، إنه مجرد رقم."
في الواقع ، ليس كل شيء في غاية البساطة. خذ المعيار وحاول إضافة الأرقام بالطريقة المحددة:
فجأة ، تم إصداره بسعر رخيص جدًا (يشار إليه فيما يلي بـ JDK 11 ، ما لم ينص صراحة على خلاف ذلك) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
قارن مع نوع بسيط:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
من هنا نشتق أحد تعريفات الألغام تحت الأداء - هذا الكود الذي لا يلفت النظر ، لا يتم اكتشافه (على الأقل في الوقت الذي صادفته) من قبل المحللين الاستاتيكيين ، لكن يمكن أن يتباطأ في بعض الاستخدامات. في حالتنا ، بينما لا يتجاوز المجموع 127 كائنًا مأخوذة من ذاكرة التخزين المؤقت و Long أبطأ من 4 مرات فقط. ومع ذلك ، بالنسبة لمجموعة من الحجم 100 ، تكون السرعة أقل 10 مرات تقريبًا.
أشياء صغيرة كبيرة
في بعض الأحيان يصبح التغيير البسيط ، الذي لا يغير معنى التنفيذ تقريبًا ، في بعض الحالات الفرامل القوية.
لنفترض أن لدينا رمز:
كيف يبدو منطق الأسلوب؟
لا تتسرع في التجسس ، والتفكيرهذا هو ConcurrentHashMap::computeIfAbsent !
لدينا "ثمانية" ، ويمكننا تحسين التعليمات البرمجية بشكل قاطع: استبدل 6 أسطر بواحد ، مما يجعل الكود أقصر وأسهل للفهم. بالمناسبة ، من المحتمل أن يشير خبراء multithreading إلى تحسن آخر ConcurrentHashMap::computeIfAbsent ، ولكن بعد ذلك بقليل ؛)
دعونا نجعل فكرة رائعة تتحقق:
تجمع ، بدأ ، بكىلمشاهدة الحجم الكامل ، انقر بزر الماوس الأيمن على الصورة وحدد "فتح صورة في علامة تبويب جديدة"
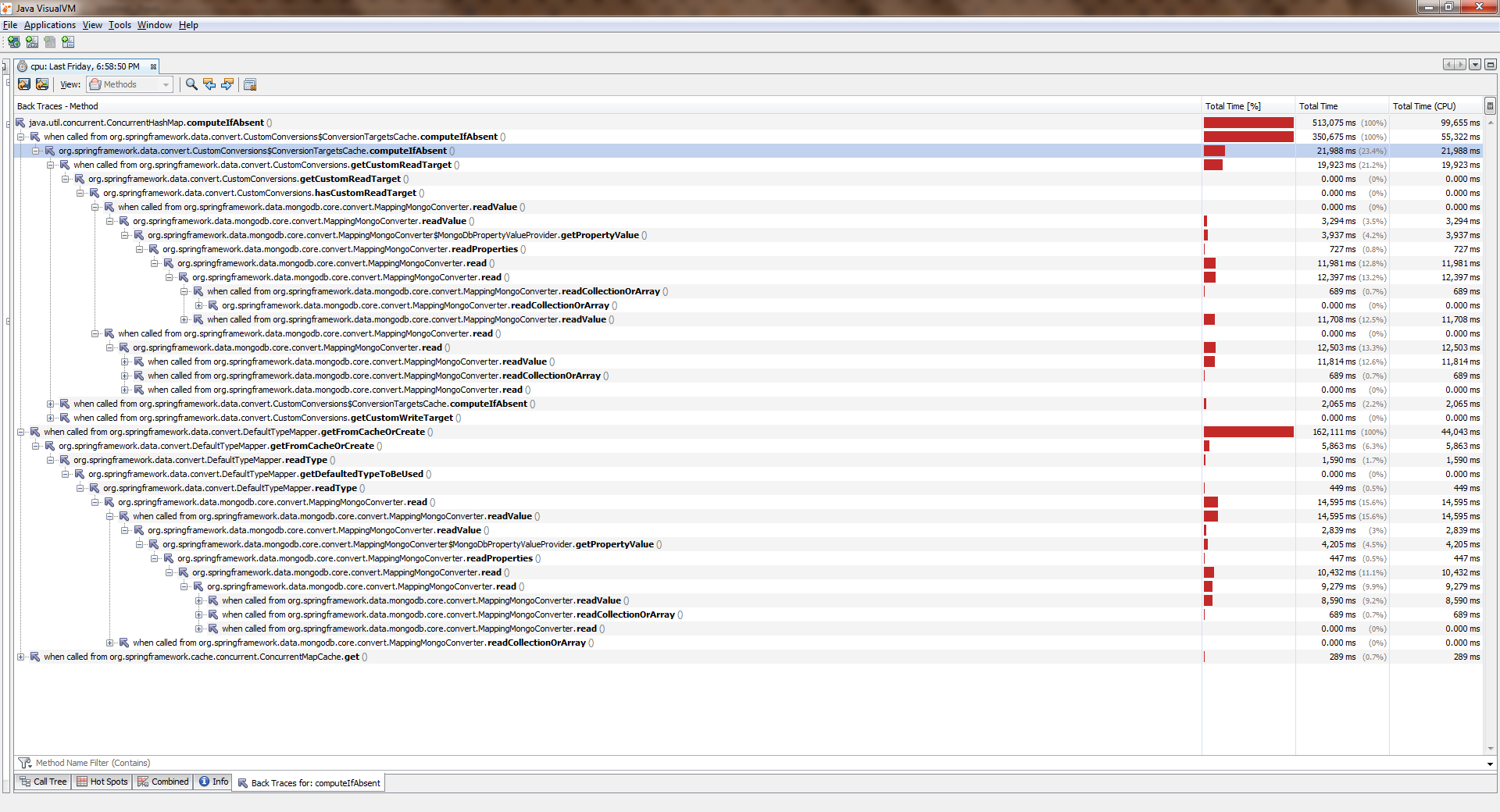
بينما كان التطبيق يعمل مع موضوع واحد ، كل شيء كان أكثر أو أقل جيدة. تيارات أصبحت أكثر وأصبحت أسوأ بكثير. ConcurrentHashMap::computeIfAbsent أنه ConcurrentHashMap::computeIfAbsent حظر ConcurrentHashMap::computeIfAbsent ، حتى إذا تمت إضافة المفتاح بالفعل إلى القاموس . وأصبح هذا هو السبب وراء وجود خطأ كبير في Spring Date Mongo.
يمكنك التحقق من ذلك بقياس بسيط ("ثمانية"). إليكم استنتاجه:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
هل يمكن اعتبار هذا خطأً واضحًا من قبل المطورين؟ في رأيي المتواضع ، لا ، لا. الوثائق تقول:
قد يتم حظر بعض محاولات التحديث على هذه الخريطة بواسطة مؤشرات ترابط أخرى أثناء إجراء عملية الحساب ، لذلك يجب أن يكون الحساب قصيرًا وبسيطًا ، ويجب ألا يحاول تحديث أي تعيينات أخرى لهذه الخريطة.
بمعنى آخر ، يقوم ConcurrentHashMap::computeIfAbsent بإغلاق الخلية التي تحتوي على المفتاح من العالم الخارجي (على عكس ConcurrentHashMap::get ) ، وهذا صحيح بشكل عام ، لأنه يسمح لك بتفادي السباق أثناء استدعاء الأسلوب من مؤشرات ConcurrentHashMap::computeIfAbsent مختلفة عندما لم تتم إضافة المفتاح بعد.
من ناحية أخرى ، في وضع التشغيل الأكثر شيوعًا ، لا يتم حساب القيمة ومدى ربطها بالمفتاح إلا عند المكالمة الأولى ، وتعيد جميع المكالمات اللاحقة القيمة المحسوبة مسبقًا فقط. لذلك ، من المنطقي تغيير المنطق بحيث يتم ضبط القفل فقط عند التغيير. تم صنعه هنا .
في الإصدارات الأحدث (> 8) ، أصبح ConcurrentHashMap::computeIfAbsent :
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
انتبه إلى غدارة هذا المثال: المحتوى الدلالي لم يتغير كثيرًا ، لأنه من النظرة الأولى استخدمنا بناء جملة أكثر تقدمًا. في الوقت نفسه ، بينما يتم تشغيل التطبيق في موضوع واحد ، لا يشعر المستخدم بالفرق تقريبًا! هذه هي الطريقة التي تبدو غير ضارة التغييرات الخنزير الألغام تحت أدائنا.
لماذا كتبت "بدون تغيير تقريبًا"ConcurrentHashMap::computeIfAbsent للتبادل دائمًا مع تعبير getAndPut ، لأن ConcurrentHashMap::computeIfAbsent هي عملية ذرية. في نفس الرمز
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
بسبب عدم وجود التزامن الخارجي ، يظهر سباق . إذا كانت الدالة التي تم تمريرها إلى ConcurrentHashMap::computeIfAbsent المحدد تُرجع دائمًا نفس القيمة ، فهذا يعد سباقًا "آمنًا" ، وأكثر ما نواجهه هو حساب القيمة نفسها 2 مرات أو أكثر. إذا لم تكن هناك ضمانات من هذا القبيل ، فإن البديل الميكانيكي محفوف بانهيار في التطبيق. كن حذرا!
هذه الأيدي لم تغير أي شيء
يحدث أيضًا أن الكود لا يتغير على الإطلاق ، ولكن فجأة يبدأ في التباطؤ.
تخيل أننا نواجه مهمة تحويل عناصر الصفيف إلى مجموعة. الأكثر منطقية هو استخدام Collection::addAll ، لكن الحظ السيئ - فهو يقبل المجموعة:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
أسهل طريقة هي التفاف الصفيف في Arrays::asList . سوف تتحول شيء من هذا القبيل
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
أثناء التدقيق اللغوي ، من المحتمل أن يخبرنا الزملاء الواعيون بالأداء أن هناك مشكلتين في هذا الكود مرة واحدة:
- التفاف صفيف في قائمة (كائن إضافي)
- إنشاء مكرر (كائن إضافي آخر) ويمر عبره
في الواقع ، في تنفيذ مرجع Collection::addAll سنرى هذا:
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
لذلك يتم إنشاء التكرار هنا ويتم فرز العناصر باستخدامه. لذلك ، يقدم الرفاق ذوي الخبرة حلهم:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
داخل الكود ، يبدو تمامًا أكثر إنتاجية:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
أولاً ، لم يتم إنشاء مكرر. ثانياً ، يمر الممر في دورة العد المعتادة ، إضافة إلى أن المصفوفات تتلاءم جيدًا في ذاكرات التخزين المؤقت ، حيث توجد عناصرها في الذاكرة بالتتابع (مما يعني أنه سيكون هناك عدد قليل من حالات فقدان ذاكرة التخزين المؤقت) ، والوصول إليها عن طريق الفهرس سريع للغاية. حسنا ، لا يتم إنشاء قائمة المجمع سواء. هذا يبدو جيدا وسليما.
أخيرًا ، يستشهد الزملاء بـ "النسبة القصوى": الوثائق. وهناك ، يقول اللون الرمادي باللون الأبيض (أو الأخضر باللون الأسود):
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
بمعنى أن المطورين أنفسهم (ومن الذي ينبغي عليهم تصديقه ، إن لم يكن هم؟) ، اكتب أنه بالنسبة لمعظم التطبيقات ، تعمل طريقة الأداة المساعدة بشكل أسرع بكثير . وهو أسرع حقًا. في بعض الاحيان
سوف يساعد المعيار ، الذي HashSet لـ HashSet على G8 ، على HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
يبدو أن الرفاق الأكثر خبرة كانوا على حق. تقريبا.
في الإصدارات اللاحقة (على سبيل المثال ، في 11) سوف تتلاشى تألق طريقة الأداة المساعدة إلى حد ما:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
يمكن أن نرى أننا لا نتحدث عن أي "أسرع بكثير". وإذا كررنا تجربة ArrayList -a ، فقد اتضح أن طريقة الأداة المساعدة تبدأ في خسارة الكثير (كلما زاد قوة):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
لا يوجد شيء غير متوقع هنا ، حيث تم تصميم ArrayList حول صفيف ، لذلك أعاد المطورون تحديد أسلوب Collection::addAll بعيد النظر:
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
عاد الآن إلى مناجمنا. افترض أننا قبلنا الحل المقترح بشأن تصحيح التجارب المطبعية وتركنا هذا الكود:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
في الوقت الحالي ، كل شيء على ما يرام ، ولكن بعد إضافة وظائف جديدة ، تصبح الطريقة في بعض الأحيان ساخنة وتبدأ في التباطؤ. نفتح أكواد المصدر - الكود لم يتغير. كمية البيانات هي نفسها. و غرق الأداء كثيرا. هذا هو نوع آخر من الألغام.
كشف المصحح وابحث عن الجميل:

يرجى ملاحظة: أننا لم نغير الخوارزمية ، ولم يتغير مقدار البيانات التي تمت معالجتها ، لكن طبيعتها تغيرت وبدأت مشكلة في الأداء في الكود لدينا:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
في المصفوفات الكبيرة ، يكون الفرق بين Collections::addAll و Collection::addAll متواضعًا 500 مرة. الحقيقة هي أن قائمة COWList لا تقوم فقط بتوسيع الصفيف الموجود ، ولكنها تنشئ واحدة جديدة في كل مرة يتم فيها إضافة عناصر:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
على من يقع اللوم؟
المشكلة الرئيسية هنا هي أن أسلوب Collections::addAll يقبل واجهة ، بينما لا addAll طريقة addAll على addAll . بدون هيئة - لا يوجد عمل ، لذلك ، تتم كتابة الوثائق بناءً على التنفيذ الموجود في AbstractCollection::addAll ، وهي خوارزمية معممة تنطبق على جميع المجموعات. هذا يعني أن تطبيقات أكثر تحديداً لهياكل البيانات الموجودة في مستوى أقل من التجريد يمكن أن يغير هذا السلوك.
الآن إنسانيا Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
المزيد عن التجريدات
بما أننا نتحدث عن مستويات التجريد ، فسأخبركم بمثال واحد من الحياة.
دعونا نقارن هاتين الطريقتين لحفظ العدد التاسع من الكيانات في قاعدة البيانات:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
للوهلة الأولى ، لا ينبغي أن يكون أداء كلتا الطريقتين مختلفًا تمامًا ، لأن
- في كلتا الحالتين سيتم تخزين نفس عدد الكيانات في قاعدة البيانات
- إذا تم أخذ المفتاح من التسلسل ، فسيكون عدد المكالمات هو نفسه
- كمية البيانات المنقولة هي نفسها
SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
النقطة المظلمة هنا هي طريقة flush() . لماذا البكم؟ يبدو لي أن الكشف عنها في واجهة JpaRepository كان خطأ للمطورين. سأحاول تبرير فكري. عادةً ، لا يتم استخدام هذه الطريقة من قِبل المطور على الإطلاق ، لأن الدعوة إلى EntityManager::flush مرتبطة بإتمام معاملة يتحكم فيها Spring:
يرجى ملاحظة: EntityManager هو جزء من مواصفات JPA المنفذة في السبات EntityManager (واجهة الجلسة وفئة SessionImpl ، على التوالي). Spring Date هو إطار يعمل على رأس ORM ، في هذه الحالة ، أعلى Hibernate. اتضح أن JpaRepository::saveAndFlush تتيح لنا الوصول إلى المستويات الأدنى من واجهة برمجة التطبيقات ، على الرغم من أن مهمة الإطار تتمثل في إخفاء التفاصيل ذات المستوى المنخفض (الموقف مشابه إلى حد ما للقصة غير الآمنة في JDK).
في حالتنا ، عند استخدام JpaRepository::saveAndFlush ندخل في الطبقات السفلى من التطبيق ، وبالتالي نكسر شيئًا ما.
خذ وقتك لإلقاء نظرة خاطفة ، فكر بنفسكقدرة السبات على إرسال البيانات على دفعات مقطوعة ، أحد مضاعفات إعداد jdbc.batch_size ، المحدد في application.yml :
spring: jpa: properties: hibernate: jdbc.batch_size: 500
يعتمد عمل Hibernate على الأحداث ، لذلك عندما تقوم بحفظ 1000 كيان من هذا القبيل
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
استدعاء repository.save(e) لا يحفظ على الفور. بدلاً من ذلك ، يتم إنشاء حدث في قائمة الانتظار. عند الانتهاء من المعاملة ، يتم دمج البيانات باستخدام EntityManager::flush ، والذي يقسم عمليات الإدراج / التحديثات إلى حزم متعددة من jdbc.batch_size ويقوم بإنشاء طلبات منها. في حالتنا ، jdbc.batch_size: 500 ، لذا فإن توفير 1000 كيان في الواقع يعني طلبين فقط.
ولكن مع التفريغ اليدوي للدورة في كل تمريرة للدورة
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
يتم مسح قائمة الانتظار وحفظ 1000 كيان يعني 1000 استفسار.
وبالتالي ، فإن التدخل في الطبقات السفلى من التطبيق يمكن أن يصبح منجمًا بسهولة ، وليس فقط منجمًا للإنتاجية (انظر غير الآمن واستخدامه غير المنضبط).
كم تبطئ؟ خذ أفضل حالة (بالنسبة لنا) - قاعدة البيانات على نفس المضيف مثل التطبيق. قياس بلدي يظهر الصورة التالية:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
من الواضح ، إذا كانت قاعدة البيانات موجودة على مضيف بعيد ، فإن تكلفة نقل البيانات ستقل بشكل متزايد من الأداء مع نمو حجم البيانات.
وهكذا ، فإن العمل على مستوى خاطئ من التجريد يمكن أن يخلق بسهولة قنبلة موقوتة. بالمناسبة ، في أحد مقالاتي السابقة تحدثت عن محاولة غريبة لتحسين StringBuilder - أ: لم أكن ناجحًا فقط عند محاولة الدخول في مستوى أكثر تجريدًا من التعليمات البرمجية.
حدود حقول الألغام
هيا نلعب صابر؟ البحث عن الألغام:
وجدت ذلك؟ تحقق من الإجابة الصحيحة. يصرخ الناقد: "هل أنت تمزح معي؟ لكن هل هناك فقط لصق من سطرين؟ ماذا يعني هذا في E. الدموي؟" واسمحوا لي أن أسترعي انتباهكم إلى حقيقة أنني لم أسلط الضوء على عملية ربط الأوتار فحسب ، ولكن أيضًا اسم الفئة واسم الأسلوب. في الواقع ، لا يتمثل خطر الإلتصاق بالسلاسل في الإلتصاق بحد ذاته ، بل في ما يحدث في الطريقة التي تنشئ المفاتيح لذاكرة التخزين المؤقت ، أي في بعض السيناريوهات ، سيكون لدينا الكثير من الوصول إلى هذه الطريقة ، مما يعني الكثير من خطوط القمامة.
لذلك ، يجب إنشاء رسالة خطأ فقط عند طرح هذا الخطأ بالفعل:
وبالتالي ، فإن حقول الألغام لها حدود - وهذا هو مقدار البيانات ، وتيرة الوصول إلى الطريقة ، وما إلى ذلك المؤشرات الكمية ، عند الوصول إلى وتجاوز أي عيب بسيط يصبح ذا دلالة إحصائية.
من ناحية أخرى ، هذه هي الميزة ، إلى نقطة التقاطع التي لا تعطي تعقيد الكود تحسينًا كبيرًا (قابلًا للقياس).
هذا استنتاج آخر للمطور: في معظم الحالات ، الخداع شرير ، مما يؤدي إلى مضاعفات لا معنى لها من الكود. في 99 حالة من أصل 100 ، لم نربح شيئًا.
يجب أن نتذكر أن هناك دائما
القضية المائة
إليكم الكود الذي قدمه نيتزان فاكارت في مقاله "مفاجأة القراءة المتقلبة" :
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
عندما ننشئ التجربة ، سنكتشف فرقًا مذهلاً بين طريقتين للتكرار على صفيف:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
هنا ، يمكن للمطور عديم الخبرة أن يقدم مثل هذا الاستنتاج الواضح والمعياري: المرور عبر صفيف باستخدام بناء الجملة الجديد يعمل بشكل أسرع من دورة العد. هذا هو الاستنتاج الخاطئ ، لأنه يستحق تغيير طريقة goodOldLoop :
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
وأدائها مشابه sweetLoop طريقة sweetLoop "الأسرع":
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? ? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .