ترجمة إزالة الغموض عن الشبكات العصبية التلافيفية . الشبكات العصبية التلافيفية.
الشبكات العصبية التلافيفية.في العقد الماضي ، شهدنا تطورات مذهلة وغير مسبوقة في رؤية الكمبيوتر. اليوم ، يمكن لأجهزة الكمبيوتر التعرف على الكائنات في الصور وإطارات الفيديو بدقة 98 ٪ ، متقدما بالفعل على شخص بنسبة 97 ٪. كانت وظائف العقل البشري هي التي ألهمت المطورين لإنشاء وتحسين تقنيات التعرف.
ما إن أجرى أخصائيو الأعصاب تجارب على القطط ووجدوا أن الأجزاء نفسها من الصورة تنشط نفس أجزاء دماغ القط. أي عندما تنظر القطة إلى الدائرة ، يتم تنشيط منطقة ألفا في دماغها ، وعندما تنظر إلى المربع ، يتم تنشيط منطقة بيتا. وخلص الباحثون إلى أنه في دماغ الحيوانات توجد مناطق من الخلايا العصبية تستجيب لخصائص الصورة. بمعنى آخر ، ترى الحيوانات البيئة من خلال الهندسة العصبية متعددة الطبقات للمخ. وكل مشهد ، تمر كل صورة عبر كتلة غريبة من اختيار العلامات ، وعندها فقط تنتقل إلى الهياكل الأعمق للدماغ.
بناءً على ذلك ، طور علماء الرياضيات نظامًا يتم فيه محاكاة مجموعات من الخلايا العصبية تعمل على خصائص صور مختلفة وتتفاعل مع بعضها البعض لتكوين صورة مشتركة.
استرداد الخصائص
تم تحويل فكرة مجموعة من الخلايا العصبية المنشطة المزودة ببيانات إدخال محددة إلى تعبير رياضي لمصفوفة متعددة الأبعاد تلعب دور محدد لمجموعة من الخصائص - يطلق عليها اسم عامل التصفية أو النواة. يبحث كل مرشح من هذا القبيل عن بعض الخصوصية في الصورة. على سبيل المثال ، قد يكون هناك مرشح لتحديد الحدود. ثم يتم نقل الخصائص التي تم العثور عليها إلى مجموعة أخرى من المرشحات التي يمكنها تحديد خصائص المستوى الأعلى للصورة ، على سبيل المثال ، العيون والأنف ، إلخ.
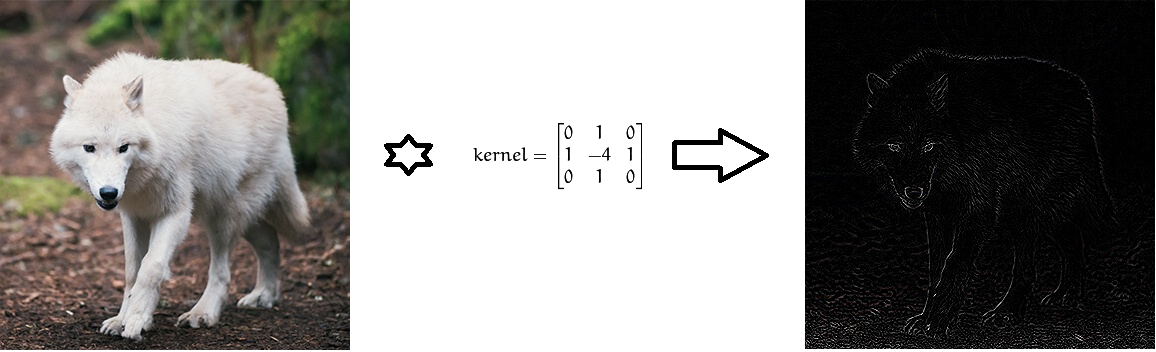 الإلتفاف في الصورة باستخدام مرشحات Laplace لتحديد الحدود.
الإلتفاف في الصورة باستخدام مرشحات Laplace لتحديد الحدود.من وجهة نظر الرياضيات ، بين صورة الإدخال ، المقدمة في شكل مصفوفة بكثافة البكسل ، والمرشح ، نقوم بإجراء عملية تحويل ، مما ينتج عنه خريطة خاصية تسمى (خريطة المعالم). ستكون هذه الخريطة بمثابة مدخلات لطبقة التصفية التالية.
لماذا الإلتواء؟
الإلتواء هو عملية تحاول فيها الشبكة ترميز إشارة الإدخال من خلال مقارنتها بالمعلومات المعروفة سابقًا. إذا كانت إشارة الدخل تشبه الصور السابقة للقطط ، والشبكات المعروفة بالفعل ، فسيتم تقليل الإشارة المرجعية "القط" إلى الحد الأدنى - مختلطة - مع إشارة الدخل. تنتقل الإشارة الناتجة إلى الطبقة التالية. في هذه الحالة ، تشير إشارة الدخل إلى تمثيل ثلاثي الأبعاد للصورة في شكل شدة بكسل RGB ، وتتعلم النواة الإشارة المرجعية "cat" للتعرف على القطط.
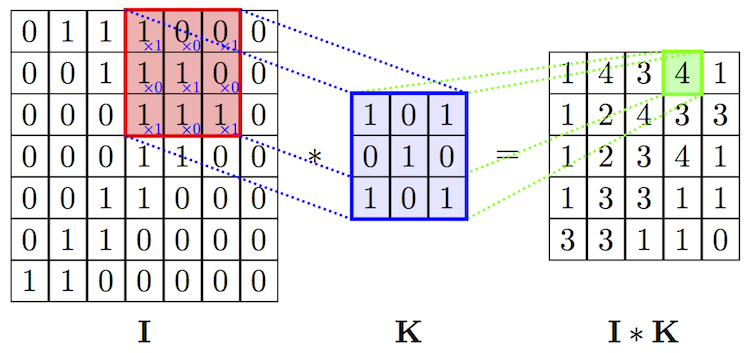 عملية الالتواء صورة وتصفية. المصدر
عملية الالتواء صورة وتصفية. المصدرعملية الالتواء لها خاصية ممتازة للترجمة الثابتة. هذا يعني أن كل مرشح الالتواء يعكس مجموعة معينة من الخصائص ، على سبيل المثال ، العينين والأذنين ، وما إلى ذلك ، وتتعلم خوارزمية الشبكة العصبية التلافيفية لتحديد أي مجموعة من الخصائص تتوافق مع مرجع ، على سبيل المثال ، القط. لا تعتمد شدة إشارة الخرج على موقع الخصائص ، ولكن على وجودها. لذلك ، يمكن تصوير القط في أشكال مختلفة ، لكن لا تزال الخوارزمية تتعرف عليه.
تجمع
باتباع مبدأ الدماغ البيولوجي ، تمكن العلماء من تطوير جهاز رياضي لاستخراج الخصائص. ولكن بعد تقييم العدد الإجمالي للطبقات والخصائص التي تحتاج إلى تحليل لتتبع الأشكال الهندسية المعقدة ، أدرك العلماء أن أجهزة الكمبيوتر لن تمتلك ذاكرة كافية لتخزين جميع البيانات. علاوة على ذلك ، يزداد حجم موارد الحوسبة المطلوبة بشكل كبير مع زيادة عدد الخصائص. لحل هذه المشكلة ، تم تطوير تقنية تجميع. فكرتها بسيطة للغاية: إذا كانت منطقة معينة تحتوي على خصائص واضحة ، فيمكننا رفض البحث عن خصائص أخرى في هذه المنطقة.
 مثال على تجميع القيمة القصوى.
مثال على تجميع القيمة القصوى.لا تؤدي عملية التجميع إلى توفير الذاكرة ومعالجة الطاقة فحسب ، بل تساعد أيضًا على مسح الصور من الضوضاء.
طبقة المستعبدين بالكامل
حسنًا ، لماذا ستكون الشبكة العصبية سهلة الاستخدام إذا كان يمكنها تحديد مجموعات خصائص الصورة فقط؟ نحن بحاجة إلى تعليمها بطريقة أو بأخرى كيفية تصنيف الصور. والنهج التقليدي لتشكيل الشبكات العصبية سوف يساعدنا في هذا. على وجه الخصوص ، يمكن تجميع خرائط الخصائص التي تم الحصول عليها على الطبقات السابقة في طبقة مرتبطة بالكامل بجميع التسميات التي أعددناها للتصنيف. هذه الطبقة الأخيرة ستحدد احتمالات مطابقة كل فصل. واستنادا إلى هذه الاحتمالات النهائية ، يمكننا أن نعزو الصورة إلى بعض الفئات.
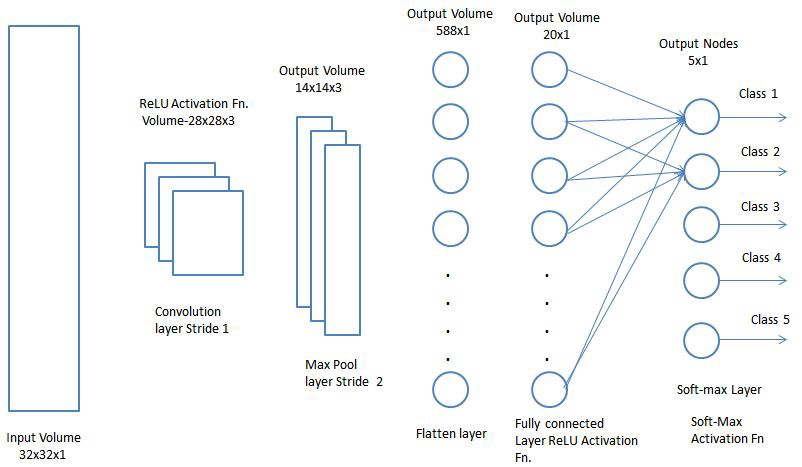 طبقة المستعبدين بالكامل. المصدر
طبقة المستعبدين بالكامل. المصدرالعمارة النهائية
الآن يبقى فقط الجمع بين جميع المفاهيم التي درستها الشبكة في إطار واحد - الشبكة العصبية التلافيفية (Convolution Neural Network، CNN). يتكون CNN من سلسلة من الطبقات التلافيفية التي يمكن دمجها مع طبقات التجميع لإنشاء خريطة خاصية يتم تمريرها إلى طبقات متصلة تمامًا لتحديد احتمالات مطابقة أي فئات. لاستعادة الأخطاء التي نحصل عليها ، يمكننا تدريب هذه الشبكة العصبية حتى الحصول على نتائج دقيقة.
الآن وبعد أن فهمنا المنظورات الوظيفية لشبكة CNN ، دعونا نلقي نظرة فاحصة على جوانب استخدام CNN.
الشبكات العصبية التلافيفية
 طبقة تلافيفية.
طبقة تلافيفية.الطبقة التلافيفية هي لبنة البناء الرئيسية لشبكة CNN. تتضمن كل طبقة من هذه الطبقات مجموعة من المرشحات المستقلة ، يبحث كل منها عن مجموعة الخصائص الخاصة به في الصورة الواردة.
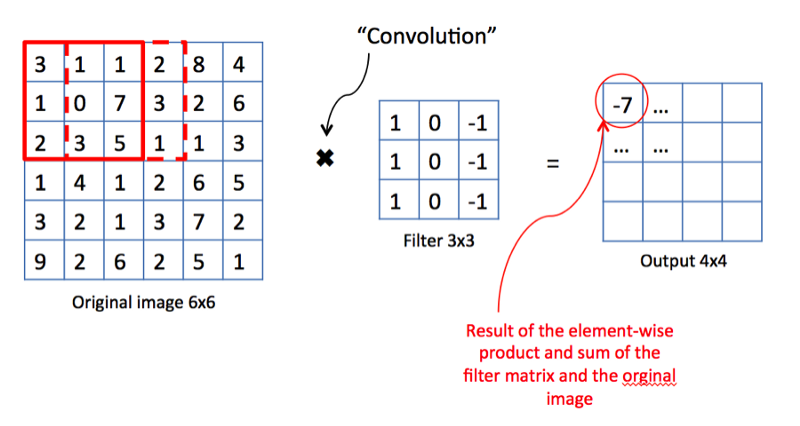 عملية الالتواء. المصدر
عملية الالتواء. المصدرمن وجهة نظر الرياضيات ، نأخذ مرشحًا ذي حجم ثابت ، ونثبته على الصورة ونحسب منتج العددية للمرشح وقطعة من صورة الإدخال. يتم وضع نتائج العمل في خريطة الممتلكات النهائية. ثم ننقل الفلتر إلى اليمين ونكرر العملية ، ونضيف أيضًا نتيجة الحساب إلى خريطة الممتلكات. بعد دمج الصورة بأكملها بمساعدة مرشح ، نحصل على خريطة خاصية ، وهي عبارة عن مجموعة من العلامات الواضحة ويتم تغذيتها كمدخلات في الطبقة التالية.
خطوات كبيرة
الخطوة هي مقدار تعويض الإزاحة. في الرسم التوضيحي أعلاه ، نقوم بتغيير المرشح بعامل 1. ولكن في بعض الأحيان تحتاج إلى زيادة حجم الإزاحة. على سبيل المثال ، إذا كانت وحدات البكسل المجاورة مرتبطة بقوة مع بعضها البعض (خاصة على الطبقات السفلية) ، فمن المنطقي تقليل حجم المخرجات باستخدام الخطوة المناسبة. ولكن إذا كانت الخطوة كبيرة جدًا ، فسيتم فقد الكثير من المعلومات ، لذا كن حذرًا.
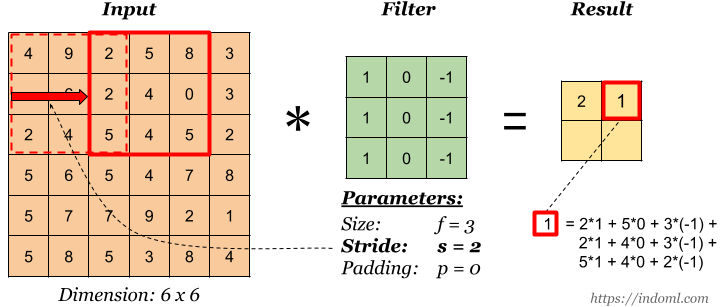 الخطوة هي 2. المصدر .
الخطوة هي 2. المصدر .الحشو
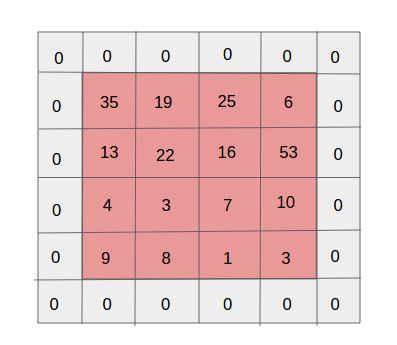 الحشو طبقة واحدة. المصدر
الحشو طبقة واحدة. المصدرواحدة من الآثار الجانبية للخطو هو الانخفاض المستمر في خريطة الممتلكات حيث يتم إجراء المزيد من التلفازات الجديدة. قد يكون هذا غير مرغوب فيه لأن "التخفيض" يعني فقد المعلومات. لجعله أكثر وضوحًا ، انتبه لعدد مرات تطبيق المرشح على الخلية في المنتصف وفي الزاوية. اتضح أنه بدون سبب تعتبر المعلومات الموجودة في الجزء الأوسط أكثر أهمية منها عند الحواف. ولاستخراج معلومات مفيدة من الطبقات السابقة ، يمكنك إحاطة المصفوفة بطبقات من الأصفار.
تقاسم المعلمة
لماذا نحتاج إلى شبكات تلافيفية إذا كان لدينا بالفعل شبكات عصبية جيدة للتعلم العميق؟ من الجدير بالذكر أنه إذا استخدمنا شبكات التعلم العميقة لتصنيف الصور ، فسيكون عدد المعلمات في كل طبقة أكبر ألف مرة من الشبكة العصبية التلافيفية.
 مشاركة المعلمات في شبكة عصبية تلافيفية.
مشاركة المعلمات في شبكة عصبية تلافيفية.