
ربما يكون Apache Spark اليوم هو النظام الأساسي الأكثر شعبية لتحليل البيانات ذات الحجم الكبير. يتم تقديم مساهمة كبيرة في شعبيتها من خلال إمكانية استخدامه من تحت بيثون. في الوقت نفسه ، يوافق الجميع على أن أداء Python و Scala / Java يشبهان ، في إطار واجهة برمجة التطبيقات (API) القياسية ، ولكن لا توجد وجهة نظر واحدة فيما يتعلق بالوظائف المعرفة من قبل المستخدم (الوظيفة المحددة من قبل المستخدم ، UDF). دعنا نحاول معرفة كيفية زيادة التكاليف العامة في هذه الحالة ، وذلك باستخدام مثال مهمة التحقق من حل SNA Hackathon 2019 .
كجزء من المسابقة ، يحل المشاركون مشكلة فرز موجز الأخبار لشبكة اجتماعية وتحميل الحلول في شكل مجموعة من القوائم المصنفة. للتحقق من جودة الحل الذي تم الحصول عليه ، أولاً ، لكل من القوائم المحملة ، يتم حساب ROC AUC ، ثم يتم عرض متوسط القيمة. يرجى ملاحظة أنك تحتاج إلى حساب لا ROC AUC مشترك واحد ، ولكن حساب شخصي لكل مستخدم - لا يوجد تصميم جاهز لحل هذه المشكلة ، لذلك سيكون عليك كتابة وظيفة متخصصة. سبب وجيه لمقارنة النهجين في الممارسة العملية.
كمنصة مقارنة ، سوف نستخدم حاوية سحابية مع أربعة نوى وإطلاق Spark في الوضع المحلي ، وسنعمل معها من خلال Apache Zeppelin . لمقارنة الوظيفة ، سنظهر نفس الرمز في PySpark و Scala Spark. [هنا] لنبدأ بتحميل البيانات.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
عند استخدام واجهة برمجة التطبيقات القياسية ، تكون الهوية الكاملة تقريبًا للشفرة جديرة بالملاحظة ، حتى الكلمة الرئيسية val . وقت التشغيل لا يختلف كثيرا. الآن دعونا نحاول تحديد UDF التي نحتاجها.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
عند تنفيذ وظيفة محددة ، من الواضح أن Python تكون أكثر إيجازًا ، ويعزى ذلك بشكل أساسي إلى القدرة على استخدام وظيفة scikit-Learn المضمنة. ومع ذلك ، هناك لحظات غير سارة - يجب عليك تحديد نوع القيمة المرجعة بشكل صريح ، في حين يتم تحديدها في Scala تلقائيًا. دعنا ننفذ العملية:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
يبدو الرمز متطابقًا تقريبًا ، ولكن النتائج غير مشجعة.

تم تنفيذ PySpark لمدة دقيقة ونصف بدلاً من ثانيتين على Scala ، أي أن Python أصبح 45 مرة أبطأ . أثناء التشغيل ، يُظهر أعلى 4 عمليات بيثون نشطة تعمل بكامل طاقتها ، وهذا يشير إلى أن قفل المترجم العالمي لا يخلق مشاكل هنا. ولكن! ربما تكمن المشكلة في التطبيق الداخلي لبرنامج scikit-learn - دعونا نحاول إعادة إنتاج رمز Python حرفيًا ، دون اللجوء إلى المكتبات القياسية.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

التجربة تظهر نتائج مثيرة للاهتمام. من ناحية ، مع هذا النهج ، كانت الإنتاجية مستوية ، ولكن من ناحية أخرى ، اختفت اللاكونية. قد تشير النتائج التي تم الحصول عليها إلى أنه عند العمل في Python باستخدام وحدات C ++ إضافية ، تظهر النفقات العامة الهامة للتبديل بين السياقات. بالطبع ، هناك حمل مماثل عند استخدام JNI في Java / Scala ، لكنني لم أضطر إلى التعامل مع أمثلة تدهور 45 مرة عند استخدامها.
للحصول على تحليل أكثر تفصيلًا ، سنقوم بإجراء تجربتين إضافيتين: استخدام Python خالص بدون Spark لقياس المساهمة من استدعاء الحزمة ، ومع زيادة حجم البيانات في Spark لإطفاء النفقات العامة والحصول على مقارنة أكثر دقة.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
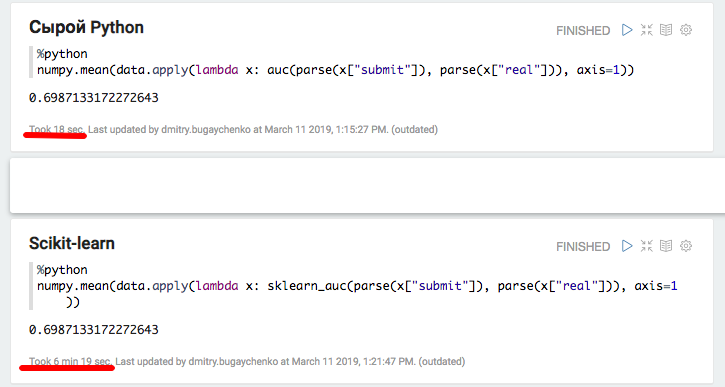
أكدت التجربة مع Python و Pandas المحلية افتراض وجود حمل كبير عند استخدام حزم إضافية - عند استخدام scikit-learning ، تنخفض السرعة بأكثر من 20 مرة. ومع ذلك ، 20 ليس 45 - دعونا نحاول "تضخيم" البيانات ومقارنة أداء Spark مرة أخرى.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

تُظهر المقارنة الجديدة ميزة السرعة لتطبيق Scala على Python بنسبة 7-8 مرات - 7 ثوانٍ مقابل 55. أخيرًا ، دعونا نجرب "الأسرع في Python" - numpy لحساب مجموع الصفيف:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
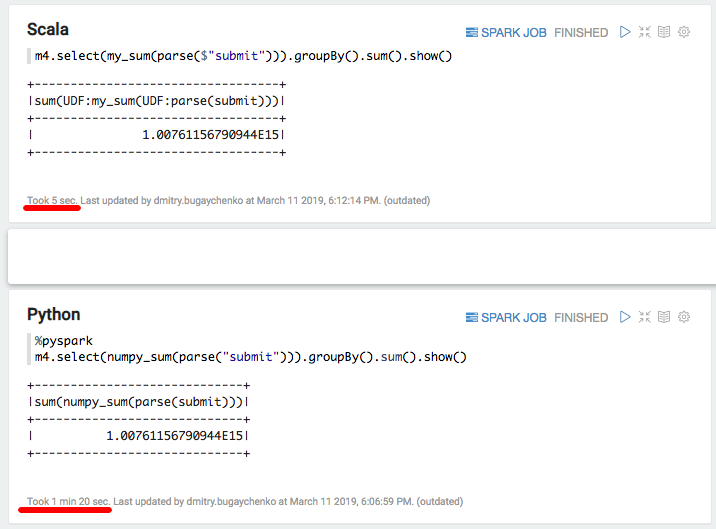
مرة أخرى تباطؤ كبير - 5 ثوان من سكالا مقابل 80 ثانية من بيثون. بإيجاز ، يمكننا استخلاص النتائج التالية:
- بينما تعمل PySpark في إطار واجهة برمجة التطبيقات القياسية ، يمكن أن تكون قابلة للمقارنة بسرعة في Scala.
- عندما يظهر منطق محدد في شكل وظائف محددة من قبل المستخدم ، فإن أداء PySpark يتناقص بشكل ملحوظ. مع وجود معلومات كافية ، عندما يتجاوز وقت معالجة كتلة البيانات عدة ثوانٍ ، يكون تنفيذ Python 5-10 أبطأ بسبب الحاجة إلى نقل البيانات بين العمليات وهدر الموارد عند تفسير Python.
- إذا ظهر استخدام وظائف إضافية تم تنفيذها في وحدات C ++ ، فستظهر تكاليف مكالمة إضافية ، ويزيد الفرق بين Python و Scala ما بين 10 إلى 50 مرة.
نتيجة لذلك ، على الرغم من كل سحر بيثون ، فإن استخدامه مع سبارك لا يبدو دائمًا مبررًا. إذا لم يكن هناك الكثير من البيانات لجعل Python ذات أهمية كبيرة ، فعليك التفكير فيما إذا كانت هناك حاجة إلى Spark هنا؟ إذا كان هناك الكثير من البيانات ، لكن المعالجة تحدث في إطار Spark SQL API القياسي ، فهل Python مطلوبة هنا؟
إذا كان هناك الكثير من البيانات وغالبًا ما يتعين عليك التعامل مع المهام التي تتجاوز حدود واجهة برمجة تطبيقات SQL ، فعندئذٍ من أجل القيام بنفس المقدار من العمل عند استخدام PySpark ، سيكون عليك زيادة الكتلة في بعض الأحيان. على سبيل المثال ، بالنسبة إلى Odnoklassniki ، فإن تكلفة النفقات الرأسمالية لمجموعة Spark سترتفع بمئات الملايين من الروبل. وإذا حاولت الاستفادة من القدرات المتقدمة لمكتبات بايث للنظم الإيكولوجية ، أي أن خطر التباطؤ لا يكون في بعض الأحيان فحسب ، بل هو أمر ضخم.
يمكن الحصول على بعض التسارع باستخدام الوظيفة الجديدة نسبيًا للوظائف المتجهة. في هذه الحالة ، لا يتم تغذية صف واحد لإدخال UDF ، ولكن حزمة من عدة صفوف في شكل Dataframe Pandas. ومع ذلك ، فإن تطوير هذه الوظيفة لم يكتمل بعد ، وحتى في هذه الحالة سيكون الفرق كبيرًا .
سيكون البديل هو الحفاظ على فريق واسع من مهندسي البيانات ، قادرًا على تلبية احتياجات علماء البيانات بسرعة مع وظائف إضافية. أو لتغمر نفسك في عالم Scala ، لأنه ليس بالأمر الصعب: توجد العديد من الأدوات الضرورية بالفعل ، تظهر برامج التدريب التي تتجاوز PySpark.