يعمل ألكساندر روبن في Percona وقد أجرى في
HighLoad ++ أكثر من مرة ، وهو مألوف لدى المشاركين كخبير في MySQL. من المنطقي أن نفترض أننا اليوم سوف نتحدث عن شيء متعلق MySQL. هذا صحيح ، لكن جزئيًا فقط ، لأننا سنتحدث أيضًا عن
إنترنت الأشياء . ستكون القصة نصف مسلية ، خاصة الجزء الأول منها ، حيث ننظر إلى الجهاز الذي ابتكره ألكساندر لجني المشمش. هذه هي طبيعة المهندس الحقيقي - إذا كنت تريد الفاكهة ، فإنك تشتري رسومًا.

قبل التاريخ
بدأ كل شيء برغبة بسيطة في زراعة شجرة فواكه في منطقتها. قد يبدو الأمر بسيطًا جدًا - يمكنك الحضور إلى المتجر وشراء الشتلات. لكن في أمريكا ، السؤال الأول الذي يطرحه البائعون هو مقدار ضوء الشمس الذي ستتلقاه الشجرة. بالنسبة إلى ألكساندر ، اتضح أن هذا لغز غامض - من غير المعروف تمامًا كم أشعة الشمس في الموقع.
لمعرفة ذلك ، يمكن للطالب الخروج إلى الفناء كل يوم ، ومعرفة مقدار أشعة الشمس ، وكتابته في دفتر ملاحظات. ولكن هذا ليس هو الحال - من الضروري تجهيز كل شيء وأتمتة.
خلال العرض التقديمي ، تم تشغيل العديد من الأمثلة وتشغيلها على الهواء مباشرة. تريد صورة أكثر اكتمالا مما في النص ، والتحول إلى مشاهدة الفيديو.لذلك ، من أجل عدم تسجيل ملاحظات الطقس في دفتر ملاحظات ، هناك عدد كبير من الأجهزة لأشياء الإنترنت - Raspberry Pi ، Raspberry Pi الجديدة ، Arduino - الآلاف من المنصات المختلفة. لكنني اخترت جهازًا يسمى
الجسيمات الفوتون لهذا المشروع. إنه سهل الاستخدام للغاية ، ويكلف 19 دولارًا على الموقع الرسمي.
الشيء الجيد في الجسيمات فوتون هو:
- 100 ٪ حل سحابة.
- أي أجهزة استشعار مناسبة ، على سبيل المثال ، لاردوينو. كلهم تكلف أقل من دولار.
لقد صنعت هذا الجهاز ووضعته على العشب على الموقع. أنه يحتوي على سحابة جهاز الجسيمات ووحدة التحكم. يتصل هذا الجهاز عبر نقطة اتصال Wi-Fi ويرسل البيانات: الضوء ودرجة الحرارة والرطوبة. استمر الاختبار لمدة 24 ساعة على بطارية صغيرة ، وهو أمر جيد للغاية.
علاوة على ذلك ، لا أحتاج فقط إلى قياس الإضاءة وما إلى ذلك ونقلها إلى الهاتف (وهو أمر جيد حقًا - أستطيع أن أرى في الوقت الفعلي نوع الإضاءة لدي) ، ولكن أيضًا
لتخزين البيانات . لهذا ، بطبيعة الحال ، كخبير محنك في MySQL ، اخترت MySQL.
كيف نكتب البيانات في MySQL
اخترت مخططًا معقدًا إلى حد ما:
- أحصل على بيانات من وحدة التحكم في الجسيمات ؛
- يمكنني استخدام Node.js لكتابتها إلى MySQL.
أنا أستخدم Particle JS API ، والتي يمكن تنزيلها من موقع Particle. أقوم بإنشاء اتصال مع MySQL وأكتب ، أي أقوم فقط بإدخال قيم INTO. هذا خط أنابيب.
وبالتالي ، يقع الجهاز في الفناء ، ويتصل عبر Wi-Fi بجهاز التوجيه المنزلي ويستخدم بروتوكول MQTT لنقل البيانات إلى الجسيمات. ثم المخطط: البرنامج على Node.js يعمل على الجهاز الظاهري ، الذي يستقبل البيانات من الجسيمات ويكتبها إلى MySQL.
بالنسبة للمبتدئين ، قمت ببناء الرسوم البيانية من البيانات الأولية في R. توضح الرسوم البيانية أن درجة الحرارة والإضاءة ترتفع أثناء النهار ، وتسقط ليلاً ، وترتفع الرطوبة - وهذا أمر طبيعي. ولكن هناك أيضًا ضوضاء على الرسم البياني ، وهو أمر نموذجي لأجهزة Internet of Things. على سبيل المثال ، عندما يزحف أحد الأخطاء إلى جهاز ويغلقه ، يمكن للمستشعر نقل بيانات غير ملائمة تمامًا. سيكون هذا مهمًا لمزيد من الدراسة.
الآن دعنا نتحدث عن MySQL و JSON ، والتي تغيرت في العمل مع JSON من MySQL 5.7 إلى MySQL 8. ثم سأعرض عرضًا تجريبيًا أستخدم MySQL 8 له (في وقت التقرير لم يكن هذا الإصدار جاهزًا للإنتاج بالفعل ، تم إصدار إصدار ثابت بالفعل).
الخلية تخزين البيانات
عندما نحاول تخزين البيانات المستلمة من أجهزة الاستشعار ، فكرنا الأول هو
إنشاء جدول في MySQL :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
يوجد هنا لكل مستشعر ولكل نوع بيانات عمود: الضوء ، درجة الحرارة ، الرطوبة.
هذا منطقي بما فيه الكفاية ، ولكن
هناك مشكلة - ليست مرنة . لنفترض أننا نريد إضافة مستشعر آخر وقياس شيء آخر. على سبيل المثال ، يقوم بعض الأشخاص بقياس البيرة المتبقية في البرميل. ماذا تفعل في هذه الحالة؟
alter table sensor_wide add water level double ...;
كيفية الانحراف من أجل إضافة شيء إلى الجدول؟ تحتاج إلى عمل جدول بديل ، ولكن إذا قمت بإجراء جدول بديل في MySQL ، فأنت تعلم ما أتحدث عنه - هذا أمر صعب تمامًا. يعد تغيير الجدول في MySQL 8 و MariaDB أبسط بكثير ، ولكن هذه مشكلة كبيرة تاريخيا. لذلك إذا كنا بحاجة إلى إضافة عمود ، على سبيل المثال ، باسم البيرة ، فلن يكون الأمر بهذه البساطة.
مرة أخرى ، تظهر أجهزة الاستشعار ، تختفي ، ماذا يجب أن نفعل مع البيانات القديمة؟ على سبيل المثال ، نتوقف عن تلقي معلومات حول الإضاءة. أم أننا بصدد إنشاء عمود جديد - كيفية تخزين ما لم يكن هناك من قبل؟ النهج القياسي لاغٍ ، ولكن التحليل لن يكون مناسبًا للغاية للتحليل.
خيار آخر هو مخزن مفتاح / القيمة.
MySQL تخزين البيانات: مفتاح / قيمة
سيكون هذا
أكثر مرونة : في المفتاح / القيمة سيكون هناك اسم ، على سبيل المثال ، درجة الحرارة ، وبالتالي ، البيانات.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
في هذه الحالة ، تظهر
مشكلة أخرى - لا توجد أنواع . لا نعرف ما نقوم بتخزينه في حقل "البيانات". يجب أن نعلنها كحقل نص. عندما أقوم بإنشاء جهاز إنترنت الأشياء الخاص بي ، أعرف نوع المستشعر الموجود ، وبالتالي النوع ، ولكن إذا كنت بحاجة إلى تخزين بيانات شخص آخر في نفس الجدول ، فلن أعرف البيانات التي يتم جمعها.
يمكنك تخزين العديد من الجداول ، ولكن إنشاء جدول جديد بالكامل لكل جهاز استشعار ليس جيدًا جدًا.
ما الذي يمكن عمله؟ - استخدم JSON.
MySQL تخزين البيانات: JSON
والخبر السار هو أنه في MySQL 5.7 ، يمكنك تخزين JSON كحقل.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
قبل ظهور MySQL 5.7 ، قام الناس أيضًا بتخزين JSON ، ولكن كحقل نصي. يتيح لك الحقل JSON في MySQL تخزين JSON نفسه بكفاءة أكبر. بالإضافة إلى ذلك ، بناءً على JSON ، يمكنك إنشاء أعمدة وفهارس افتراضية بناءً عليها.
المشكلة الطفيفة الوحيدة هي
أن الجدول سوف ينمو في الحجم أثناء التخزين . ولكن بعد ذلك نحصل على الكثير من المرونة.
يعد حقل JSON أفضل لتخزين JSON من حقل النص لأنه:
- يوفر التحقق التلقائي من المستند . أي إذا حاولنا كتابة شيء غير صالح هناك ، فسيحدث خطأ.
- هذا هو تنسيق التخزين الأمثل . يتم تخزين JSON في تنسيق ثنائي ، مما يسمح لك بالتبديل من وثيقة JSON إلى أخرى - ما يسمى تخطي.
لتخزين البيانات في JSON ، يمكننا ببساطة استخدام SQL: إنشاء INSERT ، ووضع "البيانات" هناك والحصول على البيانات من الجهاز.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
عرض
للتدليل (
هنا بدايته في الفيديو) ، يستخدم المثال جهازًا افتراضيًا به SQL.

أدناه جزء من البرنامج.
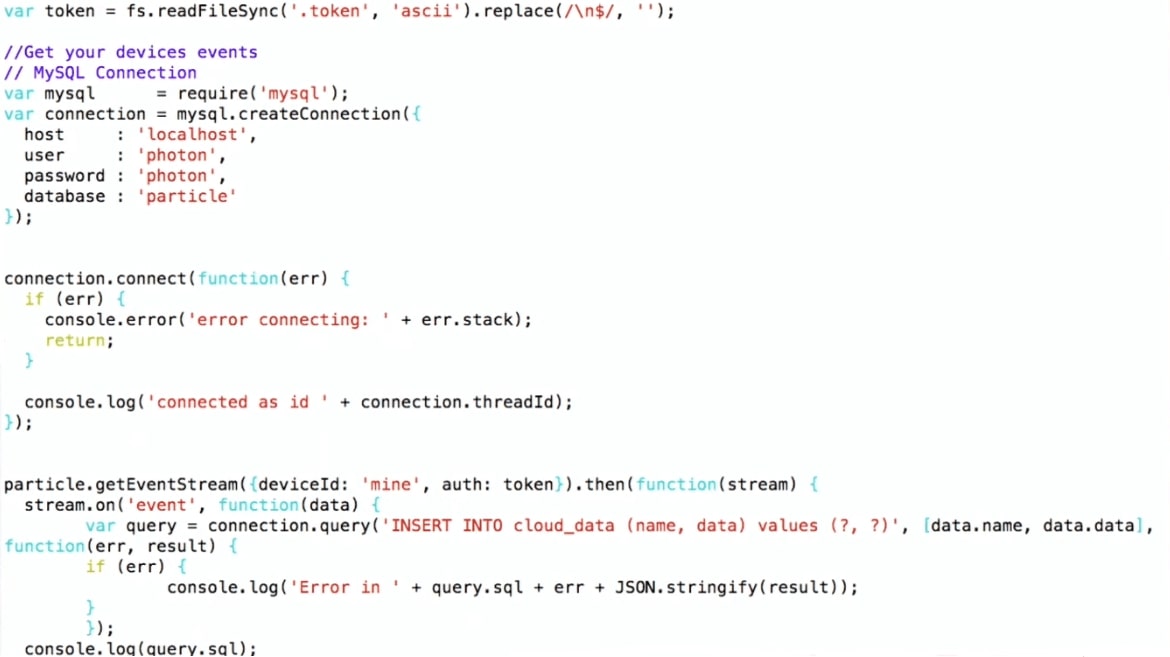
أقوم
INSERT INTO cloud_data (name, data) ، يمكنني الحصول على البيانات بالفعل بتنسيق JSON ، ويمكنني أن
INSERT INTO cloud_data (name, data) مباشرة إلى MySQL كما هي ، دون التفكير في ما هو بداخلها.
كما اتضح فيما بعد ، باستخدام هذه السحابة ، يمكنك الوصول ليس فقط إلى بيانات جهازي ، ولكن عمومًا
كل البيانات التي تستخدمها هذه الجسيمات. يبدو أن العمل حتى الآن. يرسل الأشخاص الذين يستخدمون Particle Photon في جميع أنحاء العالم بعض البيانات: الباب مفتوحًا أمام المرآب ، أو ما تبقى من الجعة كذا وكذا ، أو أي شيء آخر. لا يُعرف مكان وجود هذه الأجهزة ، ولكن يمكن الحصول على هذه البيانات. الفرق الوحيد هو أنه عندما أحصل على بياناتي ، أكتب شيئًا مثل:
deviceId: 'mine' .
عندما نقوم بتشغيل الشفرة ، نحصل على دفق من بعض البيانات من أجهزة شخص آخر تقوم بعمل ما.
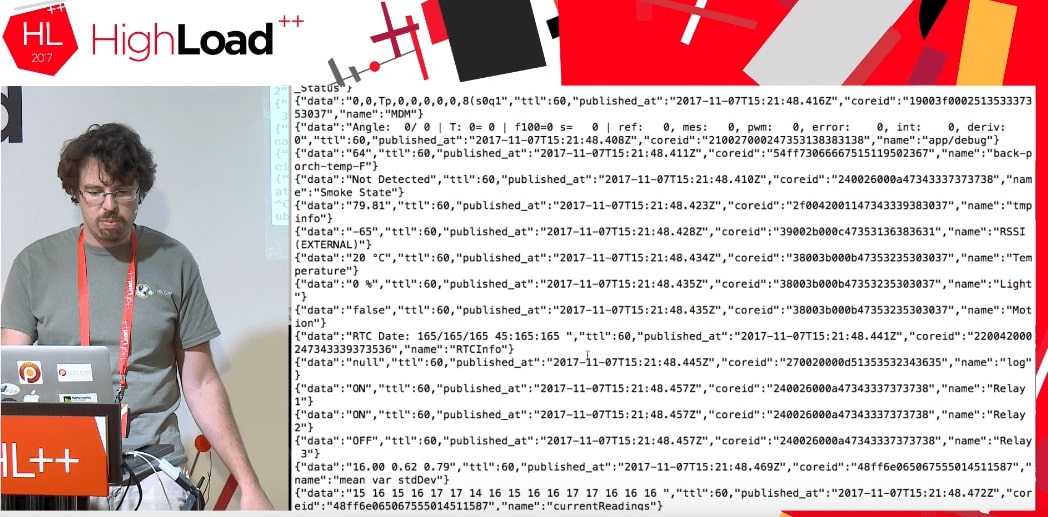
لا نعرف مطلقًا ما هي هذه البيانات: TTL ، المنشور_التالي ، الجوهر ، حالة الباب (الباب مفتوح) ، الترحيل.
هذا مثال رائع. افترض أنني أحاول وضع هذا في MySQL في بنية بيانات عادية. يجب أن أعرف ما هو الباب ، ولماذا يفتح ، وما هي المعايير العامة التي يمكن أن يستغرقها. إذا كان لديّ JSON ، فأكتبه مباشرةً على MySQL كحقل JSON.
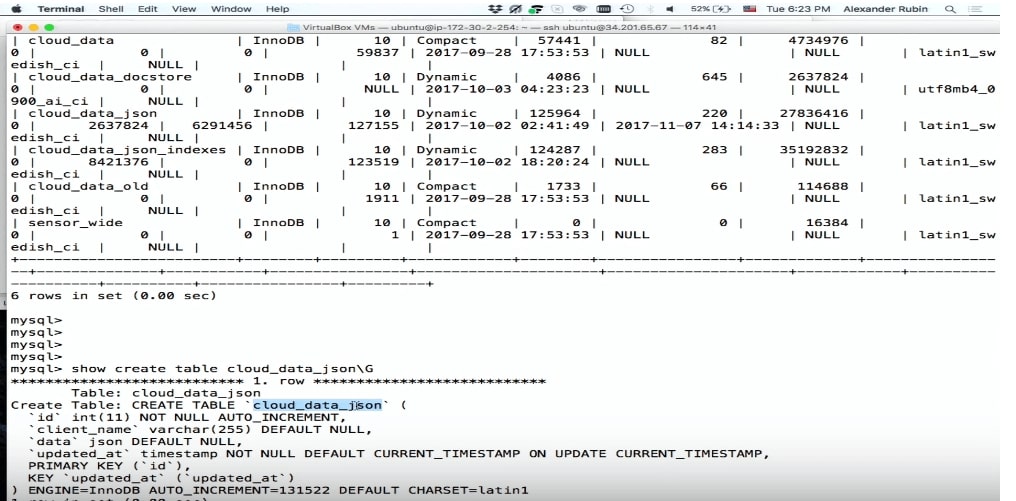
من فضلك ، لقد تم تسجيل كل شيء.
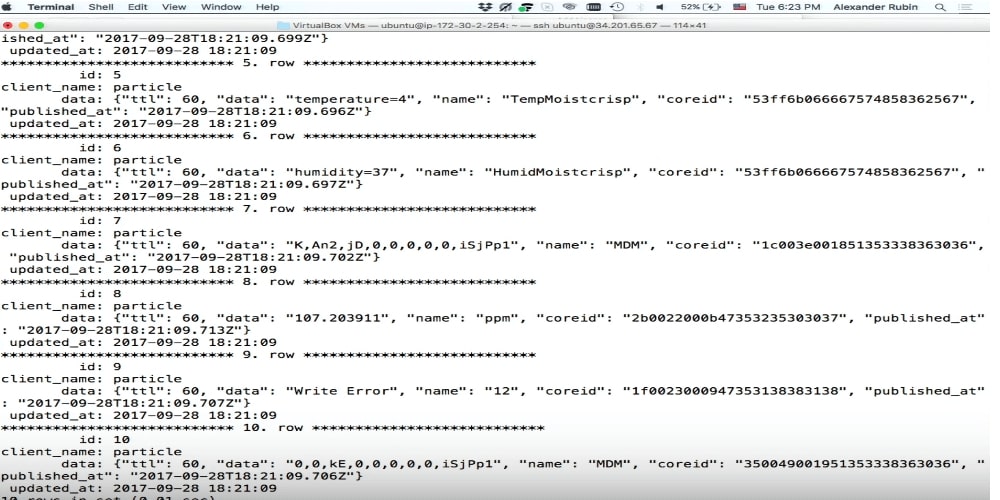
مخزن الوثائق
يعد مخزن المستندات محاولة في MySQL لتوفير مساحة تخزين لـ JSON. أنا حقاً أحب SQL ، وأنا على دراية بها ، يمكنني تقديم أي استعلام SQL ، إلخ. لكن الكثيرين لا يحبون SQL لأسباب متعددة ، ويمكن أن يكون متجر المستندات حلاً لهم ، لأنه يمكنك من خلاله الاستخراج من SQL والاتصال بـ MySQL وكتابة JSON مباشرةً هناك.

هناك احتمال آخر ظهر في MySQL 5.7: استخدام بروتوكول مختلف ، ومنفذ مختلف ، وهناك حاجة أيضًا إلى برنامج تشغيل آخر. بالنسبة إلى Node.js (في الواقع ، لأي لغة برمجة - PHP أو Java أو ما إلى ذلك) ، فإننا نتصل بـ MySQL باستخدام بروتوكول مختلف ويمكننا نقل البيانات بتنسيق JSON. مرة أخرى ، لا أعرف ما لدي في هذا JSON - معلومات حول الأبواب أو أي شيء آخر ، أنا فقط أتخلص من البيانات في MySQL ، ثم سنكتشفها.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
إذا كنت ترغب في تجربة هذا ، فيمكنك تكوين MySQL 5.7 بحيث يفهم ويسمع على المنفذ المناسب Document Store أو X DevAPI. اعتدت موصل nodejs.
هذا مثال على ما أكتب هناك: البيرة ، وما إلى ذلك. بالتأكيد لا أعرف ما الذي يوجد. نحن الآن نكتبها ونحللها لاحقًا.

النقطة التالية من برنامجنا هي كيفية معرفة ما هناك؟
تخزين بيانات MySQL: فهارس JSON +
هناك ميزة رائعة في JSON و MySQL 5.7 يمكنها سحب الحقول من JSON. هذا هو السكر النحوي في وظيفة JSON_EXTRACT. أعتقد أن هذا مريح للغاية.
البيانات الموجودة في حالتنا هي اسم العمود الذي تم تخزين JSON فيه ، والاسم هو حقلنا. الاسم والبيانات المنشورة - هذا هو كل ما يمكننا سحبه بهذه الطريقة.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
في هذا المثال ، أريد أن أرى ما كتبته في جدول MySQL ، والسجلات العشر الأخيرة. أقوم بتقديم هذا الطلب وأحاول تنفيذه. لسوء الحظ ،
هذا سوف يعمل لفترة طويلة جدا .
بطريقة منطقية ، لن تستخدم MySQL أي فهارس في هذه الحالة. نقوم بسحب البيانات من JSON ونحاول تطبيق نوع من المرشحات والفرز. في هذه الحالة ، نحصل على استخدام filesort.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
استخدام filesort هو سيء للغاية ، بل هو نوع خارجي.
والخبر السار هو أنه يمكنك اتخاذ خطوتين لتسريع ذلك.
الخطوة 1. إنشاء عمود الظاهري
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
أقوم بإجراء EXTRACT ، أي سحب البيانات من JSON وبناءً عليها أقوم بإنشاء عمود افتراضي. لا يتم تخزين العمود الظاهري في MySQL 5.7 وفي MySQL 8 - إنه فقط القدرة على إنشاء عمود منفصل.
أنت تسأل كيف هو ، قلت أن ALTER TABLE هو مثل هذه العملية الطويلة. لكن هنا ليس سيئًا للغاية.
إنشاء عمود افتراضي سريع . هناك نقص ، ولكن في الواقع ، يوجد في MySQL قفل لجميع عمليات DDL. ALTER TABLE هي عملية سريعة إلى حد ما ، ولا تقوم بإعادة إنشاء الجدول بأكمله.
لقد أنشأنا عمودًا افتراضيًا هنا. اضطررت إلى تحويل التاريخ ، لأنه في JSON يتم تخزينه بتنسيق ISO ، ولكن هنا يستخدم MySQL تنسيقًا مختلفًا تمامًا. لإنشاء عمود ، قمت بتسميته ، وأعطته نوعًا وقلت أنني سأقوم بالتسجيل هناك.
لتحسين الاستعلام الأصلي ، تحتاج إلى سحب المنشور والاسم. منشور منشور بالفعل ، الاسم أسهل - فقط قم بعمل عمود افتراضي.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
الخطوة 2. إنشاء فهرس
في الكود أدناه ، أقوم بإنشاء فهرس على المنشور _at وتنفيذ الاستعلام:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
يمكنك أن ترى أن MySQL يستخدم الفهرس بالفعل. هذا هو الأمثل من قبل النظام. في هذا المثال ، لا يتم فهرسة البيانات والاسم. يستخدم MySQL الترتيب حسب البيانات ، ولأن لدينا فهرسًا على المنشور_at ، فإنه يستخدمه.
علاوة على ذلك ، يمكنني استخدام نفس السكر في بناء الجملة
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") بدلاً من المنشور
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") ترتيب بالترتيب. لا يزال MySQL يفهم أن هناك فهرس في هذا العمود والبدء في استخدامه.
هناك بالفعل مشكلة صغيرة مع هذا. لنفترض أنني أريد فرز البيانات ليس فقط حسب المنشور ، ولكن أيضًا بالاسم.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
إذا كان جهازك يعالج عشرات الآلاف من الأحداث في الثانية الواحدة ، فلن يقدم المنشور_at نوعًا جيدًا ، حيث ستكون هناك تكرارات. لذلك ، نضيف فرزًا آخر حسب اسم_البيانات. هذا استعلام نموذجي ليس فقط لإنترنت الأشياء: أعطني الأحداث العشر الأخيرة ، ولكن رتبها حسب التاريخ ، ثم ، على سبيل المثال ، حسب الاسم الأخير للشخص بترتيب تصاعدي. للقيام بذلك ، في المثال أعلاه ، يوجد حقلان ويتم تحديد مفتاحي فرز: تنازلي وتصاعدي.
بادئ ذي بدء ، في هذه الحالة ، لن يستخدم MySQL الفهارس. في هذه الحالة بالذات ، يقرر MySQL أن الفحص الكامل للجدول سيكون أكثر ربحية من استخدام الفهرس ، ومرة أخرى يتم استخدام عملية الملفات البطيئة للغاية.
الجديد في MySQL 8.0
تنازلي / تصاعدي
في MySQL 5.7 ، لا يمكن تحسين مثل هذا الاستعلام ، إلا إذا كان ذلك على حساب أشياء أخرى. في MySQL 8 ، كانت هناك فرصة حقيقية لتحديد الفرز لكل حقل.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
الشيء الأكثر إثارة للاهتمام هو أن المفتاح التنازلي / التصاعدي بعد اسم الفهرس منذ فترة طويلة في SQL. حتى في الإصدار الأول من MySQL 3.23 ، يمكنك تحديد المنشور تنازليًا أو المنشور تصاعديًا. تقبل MySQL هذا ،
لكنها لم تفعل شيئًا ،
أي أنه يتم فرزه دائمًا في اتجاه واحد.
في MySQL 8 ، تم إصلاح هذا والآن هناك مثل هذه الميزة. يمكنك إنشاء حقل بترتيب تنازلي مع فرز افتراضي.
دعنا نعود ثانية وننظر إلى المثال من الخطوة 2 مرة أخرى.
لماذا يعمل ، وإلا فإنه لا؟ يعمل هذا لأنه في فهارس MySQL عبارة عن شجرة B ، ويمكن قراءة فهارس B-tree من البداية ومن النهاية. في هذه الحالة ، يقرأ MySQL الفهرس من النهاية وكل شيء على ما يرام. لكن إذا فعلنا تنازليًا وصعوديًا ، فلن تتمكن من القراءة. يمكنك القراءة بنفس الترتيب ، لكن
لا يمكنك الجمع بين نوعين - تحتاج إلى إعادة الترتيب.
نظرًا لأننا نقوم بتحسين حالة محددة للغاية ، يمكننا إنشاء فهرس لها وتحديد نوع معين: هنا publish_at تنازلي ، data_name تصاعدي. يستخدم MySQL هذا الفهرس ، وسيكون كل شيء جيدًا وسريعًا.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
هذه هي سمة من سمات MySQL 8 ، والتي أصبحت الآن ، وقت النشر ، متاحة بالفعل وجاهزة للاستخدام في الإنتاج.
نتائج الانتاج
هناك شيئان أكثر إثارة للاهتمام أرغب في عرضهما:
1. طباعة جميلة ، وهذا هو ، إخراج جميل من البيانات إلى الشاشة. باستخدام SELECT العادي ، لن يتم تنسيق JSON.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2. يمكننا القول أن MySQL ستنتج النتيجة في شكل صفيف JSON أو كائن JSON ، وحدد الحقول ، ومن ثم سيتم تنسيق الإخراج كـ JSON.
البحث عن النص الكامل داخل مستندات JSON
إذا كنا نستخدم نظام تخزين مرنًا ولا نعرف ماذا يوجد داخل JSON ، فسيكون من المنطقي استخدام البحث عن النص الكامل.
لسوء الحظ ،
البحث عن النص الكامل له حدوده . أول ما جربته هو فقط إنشاء مفتاح النص الكامل. حاولت أن أفعل هذا الشيء:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
لسوء الحظ هذا لا يعمل. حتى في MySQL 8 ، فإن إنشاء فهرس نص كامل ببساطة عن طريق حقل JSON أمر مستحيل للأسف. بالطبع ، أود الحصول على هذه الوظيفة - ستكون القدرة على البحث على الأقل عن طريق مفاتيح JSON مفيدة للغاية.
ولكن إذا لم يكن ذلك ممكنًا بعد ، فلنقم بإنشاء عمود افتراضي. في حالتنا ، يوجد حقل بيانات ، وسيكون من المثير للاهتمام أن نرى ما بداخلنا.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
لسوء الحظ ، هذا لا يعمل أيضًا -
لا يمكنك إنشاء فهرس نص كامل في عمود افتراضي .
إذا كان الأمر كذلك ، فلنقم بإنشاء عمود مخزن. يسمح لك MySQL 5.7 بإعلان عمود كحقل مخزن.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
في الأمثلة السابقة ، أنشأنا أعمدة افتراضية غير مخزنة ، لكن الفهارس يتم إنشاؤها وتخزينها. في هذه الحالة ، كان علي أن أخبر MySQL أن هذا هو عمود STORED ، أي أنه سيتم إنشاؤه وسيتم نسخ البيانات إليه. بعد ذلك ، أنشأ MySQL فهرس نص كامل ، لهذا كان علينا إعادة إنشاء الجدول. ولكن هذا القيد هو في الواقع بحث InnoDB و InnoDB عن النص الكامل: يجب عليك إعادة إنشاء الجدول لإضافة معرف بحث عن النص الكامل.
ومن المثير للاهتمام ، في MySQL 8 ، كان هناك
تشفير UTF8 MB4 جديد للرموز . بالطبع ، ليس تمامًا بالنسبة لهم ، ولكن لأنه في UTF8MB3 هناك بعض المشكلات في اللغات الروسية والصينية واليابانية وغيرها.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
وفقًا لذلك ، يجب على MySQL 8 تخزين بيانات JSON في UTF8MB4. ولكن سواء كان ذلك بسبب حقيقة أن Node.js يتصل بـ Device Cloud ، وأن هناك شيئًا ما مكتوبًا هناك بشكل غير صحيح ، أو أنه خطأ في الإصدار التجريبي ، لم يحدث هذا. لذلك ، كان عليّ تحويل البيانات قبل كتابتها إلى عمود مخزن.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
بعد ذلك ، تمكنت من إنشاء بحث كامل النص في حقلين: على اسم JSON وعلى بيانات JSON.
ليس فقط إنترنت الأشياء
JSON ليس فقط إنترنت الأشياء. يمكن استخدامه لأشياء أخرى مثيرة للاهتمام:
- الحقول المخصصة (CMS) ؛
- الهياكل المعقدة ، إلخ ؛
يمكن تنفيذ بعض الأشياء بسهولة أكبر باستخدام نظام تخزين بيانات مرن. تم تقديم مثال ممتاز في Oracle OpenWorld: حجوزات السينما. من الصعب جدًا تنفيذ ذلك في النموذج العلائقي - تحصل على العديد من الجداول التابعة ، الصلات ، إلخ. من ناحية أخرى ، يمكننا تخزين الغرفة بأكملها كهيكل JSON ، على التوالي ، كتابتها إلى MySQL في جداول أخرى واستخدامها بالطريقة المعتادة: إنشاء فهارس على أساس JSON ، إلخ.
يتم تخزين الهياكل المعقدة بشكل مريح في تنسيق JSON.
هذه هي الشجرة التي تم زرعها بنجاح. لسوء الحظ ، بعد بضع سنوات ، أكلت الغزلان ، لكن هذه قصة مختلفة تمامًا.
هذا التقرير هو مثال ممتاز على كيفية نمو قسم كامل من موضوع واحد في مؤتمر كبير ، ثم حدث منفصل منفصل. في حالة إنترنت الأشياء ، حصلنا على InoThings ++ - مؤتمر للمهنيين في سوق إنترنت الأشياء ، والذي سيعقد للمرة الثانية في 4 أبريل.
يبدو أن الحدث الرئيسي للمؤتمر هو اجتماع المائدة المستديرة "هل نحن بحاجة إلى معايير وطنية على إنترنت الأشياء؟" ، والتي ستُستكمل عضويا بتقارير تطبيقية شاملة. تعرف على ما إذا كانت الأنظمة المحملة بكثافة تتحرك بشكل صحيح إلى IIoT.